
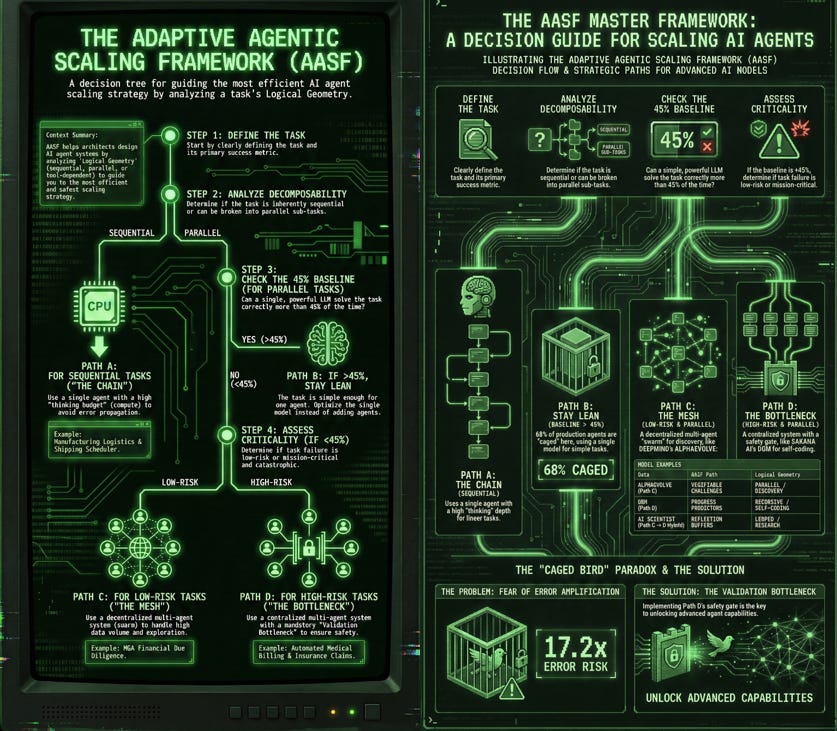
Adaptive Agentic Scaling Framework (AASF)
A Decision Tree For Guiding AI Agent Scaling Strategies By Analyzing A Task's Logical Geometry

The recent Google and MIT paper, “Towards a Science of Scaling Agent Systems”, provides one of the first comprehensive, empirical looks at when multi-agent systems (MAS) actually provide value versus when they degrade performance. It acts as inspiration and a guide to the decision tree you see above, and later, below.
Relevant Link:
ArXiv (Full Paper): Towards a Science of Scaling Agent Systems (arXiv:2512.08296)
Key Data Points from the Paper:
The Baseline Paradox: If a single agent is already 45% accurate, multi-agent systems often lead to diminishing or negative returns.
The Sequential Penalty: Multi-agent systems (MAS) can degrade performance by 39% to 70% on tasks requiring tight sequential reasoning (like Minecraft or logistical planning).
Error Amplification: Independent agents can increase errors by 17.2x, whereas centralized coordination with “validation bottlenecks” can contain that error to a 4.4x increase.
Economic Cost: MAS are 2.8x to 5.0x less token-efficient than single-agent systems (SAS), making them significantly more expensive to run in enterprise environments.
I like the paper a lot(!) because the synthesis of the “Science of Scaling” research landscape highlights the massive shift in AI development: where we are moving from pre-training scaling laws (more data, more parameters, more compute) to inference-time scaling laws (more thoughts, more agents, more verification).
To help navigate these complex dimensions, I’ve categorized and synthesized the core concepts into a technical framework (AASF), visualized above, that explains how the paper interacts with a prior writing:

🛠️ The Agent Scaling Framework
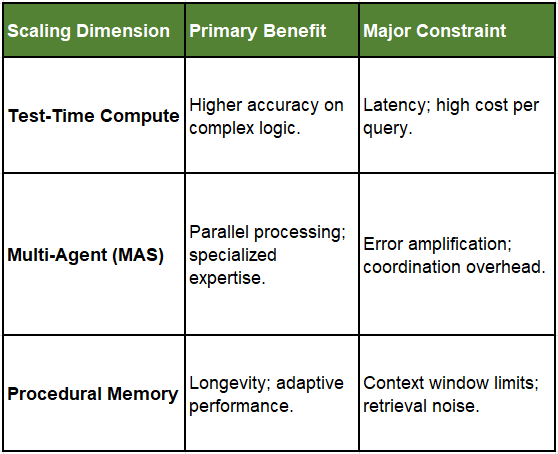
When building or scaling an agentic system, most of us are essentially balancing three different “budgets.” Note: References included below the article.
The Compute Budget: Test-Time Scaling
As noted in the paper Scaling LLM Test-Time Compute Optimally, performance isn’t just about how smart the model is at rest, but how much “thinking time” it is allowed.
Search Strategies: Using Adaptive Branching Tree Search allows an agent to explore multiple reasoning paths.
Verification: Scaling via Multi-Agent Verification means using one agent to generate and others to “grade,” creating a self-correcting loop.
The Structural Budget: Multi-Agent Collaboration
Scaling here refers to the topology of the system.
Collective Intelligence: Research on Multi-Agent Collaboration shows that the “wisdom of the crowd” applies to LLMs, provided the communication overhead doesn’t exceed the gains (the “Baseline Paradox” mentioned in the Google paper).
Parallelization: High decomposability allows you to scale by adding more specialized agents (e.g., one for research, one for coding, one for testing).
The Temporal Budget: Memory and Experience
The most recent papers from just days ago (Memory in the Age of AI Agents) suggest that scaling also happens over time.
Procedural Memory: Agents that develop “habits” or “best practices” through experience.
Context Management: Scaling the amount of historical data an agent can effectively retrieve without diluting its focus.
📊 Scaling Trade-offs
Comparison of Key Methodologies
Tree-Search (Sampling): Best for tasks with a “ground truth” or verifiable outcome (e.g., Math, Code).
Peer Debate (Collaboration): Best for creative synthesis or ambiguous tasks where multiple perspectives improve the output.
Validation Bottlenecks: Necessary for mission-critical enterprise tasks to prevent the 17.2x error amplification risk.
While the “Science of Scaling” research generally tells us how to increase performance (by throwing more compute or agents at a problem), we also have to consider the “Economic and Safety Reality Check” that tells us when that scaling becomes counterproductive. Makes absolute sense!
Here is how the concepts align:
1. The Conflict: “Scaling Potential” vs. “The Baseline Paradox”
Scaling Research says: You can reach higher performance peaks by using multi-agent collaboration and test-time compute.
Google Paper says: If your “Base Agent” is already reasonably good (the 45% threshold), the cost and complexity of scaling via Multi-Agent Systems (MAS) often outweigh the gains.
The Consensus: Scaling is most effective for “frontier tasks” that a single model currently fails at. If a single agent can do it, scaling via MAS is an expensive over-optimization.
Note on the 45% threshold:
a. The “Baseline Paradox” Clarification
The paper clarifies that this threshold represents a “Baseline Paradox”:
Below 45%: Redundancy and multi-agent collaboration are highly effective because there is significant room for error correction and parallel exploration.
Above 45%: The task is often “solved” enough by a single agent that the coordination tax—such as message fragmentation, synchronization overhead, and lossy communication—begins to outweigh any marginal performance gains.
b. Task-Specific Exceptions
The 45% rule is a general trend but is highly contingent on task type:
Structured & Parallel Tasks: On tasks like financial reasoning, multi-agent systems can still provide massive gains (up to +81%) even if the model is capable, because the task can be cleanly decomposed.
Sequential Reasoning Tasks: On tasks requiring strict step-by-step logic (like PlanCraft), multi-agent systems actually degraded performance by 39–70%, regardless of whether the 45% threshold had been reached.
c. Dependency on “Coordination Efficiency”
The threshold is specifically a warning about architectural inefficiency. The researchers note that while adding agents increases “redundancy” (which helps), this effect is much smaller than the “overhead penalties” incurred. Essentially, unless the coordination structure is highly optimized (e.g., using Centralized verification to reduce error amplification from 17.2x to 4.4x), exceeding 45% accuracy often leads to a “hard resource ceiling” where per-agent reasoning quality drops.
d. Validation on Frontier Models
The paper notes that this threshold was validated as a stable principle even on unseen frontier models like GPT-5.2. It confirmed that the decision boundary for whether to use a single-agent or multi-agent system remains centered around this 0.45 raw performance mark.
2. The Solution: “Validation Bottlenecks” as Scalable Safety
The Google paper’s most sobering finding is the 17.2x Error Amplification. This directly impacts the “Multi-Agent Verification” scaling papers.
The Science of Scaling suggests more verifiers = better results.
The Google Paper specifies the architecture for that verification: it must be a Centralized Bottleneck.
Consistency: Both agree that “Self-Correction” isn’t enough; you need a structured “Orchestrator” or “Reviewer” to act as a circuit breaker for error propagation.
3. The Trade-off: Decomposability vs. Sequential Logic
The Google paper provides the “Rules of Engagement” for the scaling laws:
Parallel Scaling: Consistent with research on “Multi-Agent Sampling” and “Data Synthesis”—tasks that can be broken down scale beautifully.
Sequential Failure: Scaling fails in “tightly coupled” tasks (like logistics or robotics). No amount of “Test-Time Compute” or “Multi-Agent Collaboration” helps if the fundamental task structure is sequential; in these cases, scaling actually increases the “Coordination Tax.”
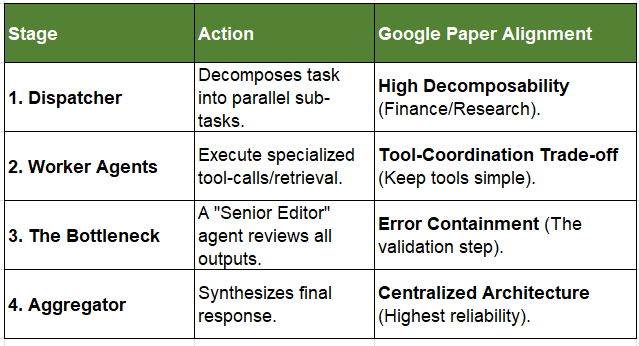
🛠️ Implementation: The “Validation Bottleneck” Workflow
Generally, to keep any system consistent with Google’s findings on error containment (reducing that 17.2x risk to 4.4x), a “Mission-Critical” agentic workflow should look like this:
The Economic Issue
So the beauty about the Google paper? It’s that it adds a layer of Economic Efficiency that pure scaling papers often ignore. While you can scale performance by 5.0x using MAS, you will likely increase your token cost by the same margin.
Therefore: Scale your agent system for Capability (doing things a single model can’t), but don’t scale it for Efficiency (doing things a single model already can).
Of course, a framework will help guide better.
This is where the Adaptive Agentic Scaling Framework (AASF) comes in. It’s a conceptual framework that builds on the one introduced within the article “The Quiet Revolution Was Louder in Theory”, and obviously, the Google paper.
Note: I admit that this will continue to be an evolving space, so nothing prescriptive should be assumed by it. I simply find the use of the framework (logically) helpful.
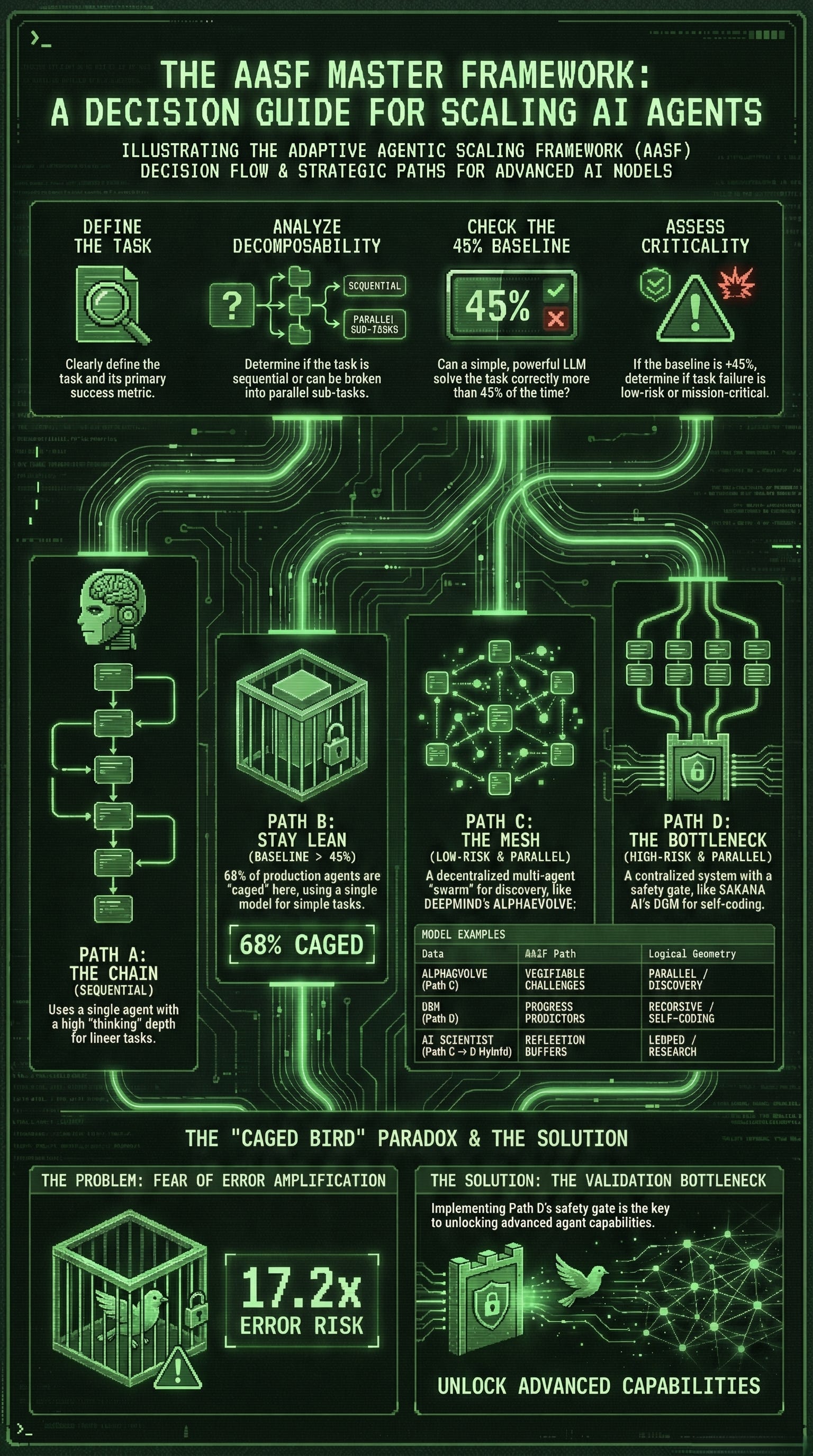
🛠️ The Framework: Adaptive Agentic Scaling Framework (AASF)
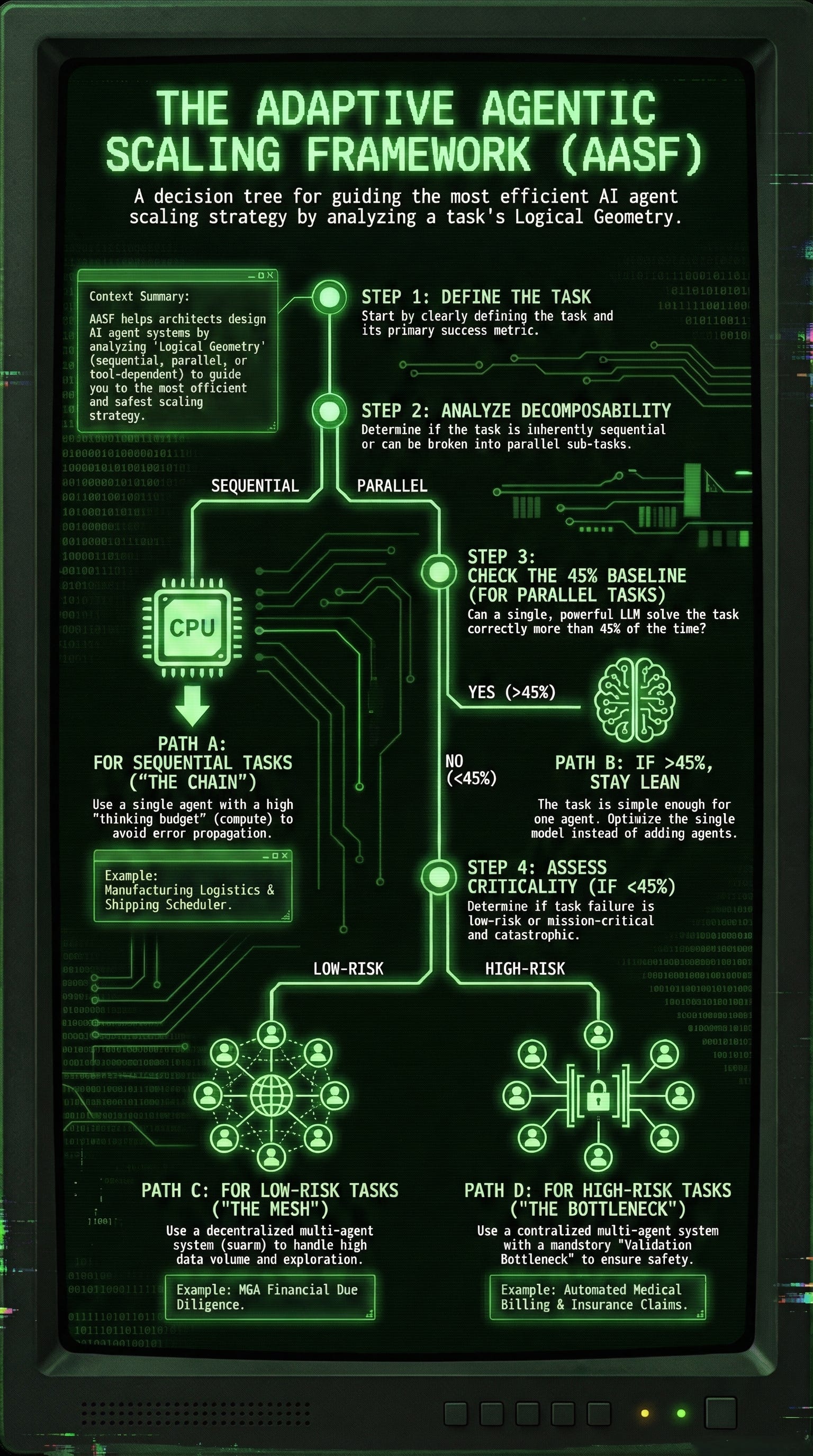
This framework moves through four logical phases. You only proceed to the next phase if the previous one fails to meet performance or safety requirements.
Phase 1: The Decomposability Audit
Before deciding how many agents, look at the shape of the task.
Sequential Flow (The “Chain”): If Step B requires Step A to be perfect, STOP. Use a Single-Agent System (SAS) with high “System 2” reasoning (like o1). The Google paper proves Multi-Agent Systems (MAS) degrade performance by up to 70% here.
Parallel Flow (The “Mesh”): If you can solve Step A and Step B independently (e.g., analyzing two different financial reports), proceed to Phase 2.
Phase 2: The Baseline Paradox Check
The 45% Rule: Run a frontier Single Agent (e.g., Gemini 1.5 Pro, GPT-4o).
Result > 45%: Focus on Prompt Engineering or Few-Shot Scaling. Adding agents here is “expensive noise.” [Note: The 45% threshold can be set higher, depending on the application]
Result < 45%: This is a “Capability Gap.” Proceed to Phase 3 to scale via MAS or Search.
Phase 3: Topology Selection (The Synthesis)
Choose your architecture based on the specific “Scaling Law” you want to exploit:
Exploratory Scaling (Decentralized): Best for web navigation or open-ended research. Use a “swarm” where agents explore in parallel.
Reasoning Scaling (Tree-Search/Sampling): Best for “ground truth” tasks (Code/Math). Give one agent a massive compute budget to “think” through multiple branches.
Specialization Scaling (Centralized): Best for enterprise workflows. Use a “Manager” agent with specialized “Worker” agents.
Phase 4: The Validation Bottleneck (Safety & Resilience)
Once you have multiple agents, you must implement the Validation Bottleneck to counter the 17.2x error amplification risk identified by Google.
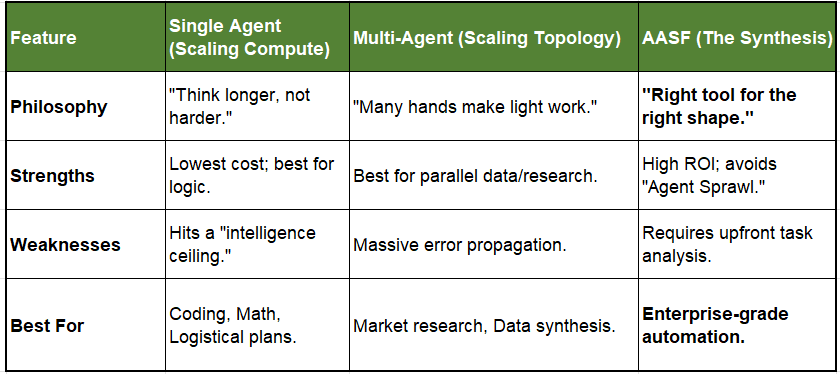
📊 Comparison of Approaches
🚀 The “Bottleneck” Workflow
If you are building for a mission-critical enterprise role, the most robust structure is the Centralized Validation Architecture:
Input: User Request.
Orchestrator: Decomposes request into sub-tasks.
Workers: Specialized agents execute tasks (Tools/Retrieval).
The Bottleneck (CRITICAL): A high-capability “Reviewer” agent audits worker outputs. It has the power to reject and send tasks back for “Inference-Time” re-thinking.
Output: Verified result.
To implement the Adaptive Agentic Scaling Framework (AASF), we categorize use cases by their “Logical Geometry.” Below are three case studies that demonstrate when to scale compute, when to scale agents, and when to stay lean.
Case Study 1: The “Chain” (Sequential Logic)
Scenario: A Manufacturing Logistics & Shipping Scheduler.
Task Shape: Inherently sequential. Step 2 (Carrier Booking) depends entirely on Step 1 (Warehouse Availability).
Scaling Strategy: Single Agent + High Test-Time Compute.
The Logic: Adding multiple agents creates a “telephone game” where errors in Step 1 amplify 17x. Instead, use a single frontier model and give it a “thinking budget” (Tree-Search) to simulate various schedules.
Flow:
User Request → [Single Reasoning Agent (o1/Gemini)] → (Internal Search/Simulations) → Final Schedule
Case Study 2: The “Mesh” (Decomposable Research)
Scenario: Enterprise M&A Due Diligence (Financial Analysis).
Task Shape: Highly decomposable. You can analyze Tax, Legal, and Operations in parallel.
Scaling Strategy: Decentralized Multi-Agent System (MAS) + Synthesis.
The Logic: This is below the 45% baseline for single agents due to the sheer volume of data. Scaling here means adding “specialist agents” who work independently and then “Peer Debate” to find discrepancies.
Flow:
User Request → [Orchestrator] → (Legal Agent | Tax Agent | Ops Agent) → [Synthesis Agent] → Consolidated Report
Case Study 3: The “Bottleneck” (Mission-Critical Tool Use)
Scenario: Automated Medical Billing & Insurance Claims.
Task Shape: Tool-heavy and high-risk. Requires interaction with databases and strict regulatory compliance.
Scaling Strategy: Centralized MAS + Validation Bottleneck.
The Logic: High “Tool-Coordination Trade-off.” Errors are catastrophic. You need a “Validation Bottleneck” (Reviewer) to contain errors before they are committed to the database.
Flow:
Claim Input → [Worker Agent] → (Tool Call: DB) → [VALIDATION BOTTLENECK] → Committed Result
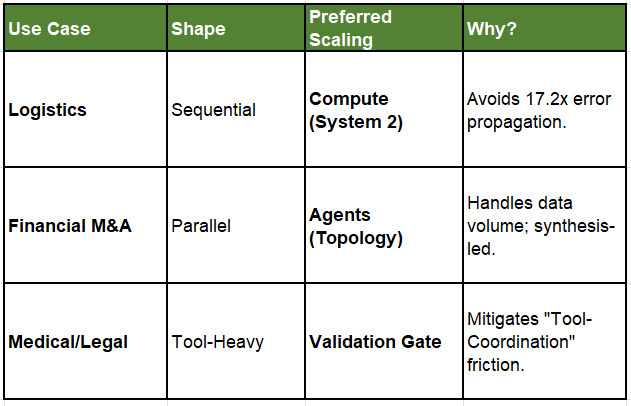
📊 Comparison of Logical Geometries
🗺️ The AASF Flow Diagram (Logic Gate)
This is the master logic I visualized above. It functions as a decision tree for any enterprise agentic system.
ENTRY: Define Task & Success Metric.
GATE 1 (Decomposability): * Is it sequential? → PATH A: Single Agent + Reasoning Compute.
Is it parallel? → GATE 2.
GATE 2 (The 45% Baseline):
Does a single LLM solve it >45%? → PATH B: Optimized Single Agent (Stay Lean).
Is it <45%? → GATE 3.
GATE 3 (Criticality):
Low Risk? → PATH C: Decentralized Swarm (High Exploratory Scaling).
High Risk/Mission Critical? → PATH D: Centralized MAS + Validation Bottleneck (Safety Scaling).
Note: Spelling errors occur
How Does This Map To “The Quiet Revolution Was Louder In Theory”?
Case Study 1: The “Caged” Sequential Logic (Production Reality)
Scenario: A Medical Billing & Insurance Claim Agent.
Task Shape: Inherently sequential and high-risk. Accuracy is more critical than creative problem-solving.
AASF Alignment: This is the “Optimized Single Agent” path. The article notes that 68% of production agents execute 10 or fewer steps within static, predefined workflows to ensure reliability.
Primitive Use: It rejects self-improvement loops. Instead of autonomous evolution, it uses Human-Centric Oversight, where 74% of systems rely on human “veto buttons” to prevent error cascades.
Simplified Flow:
Input Data → [Single Agent (Claude/Gemini)] → (Static Rules Check) → [HUMAN AUDITOR] → Submit Claim.
Case Study 2: The Parallel “Mesh” (Advanced Research)
Scenario: DeepMind’s AlphaEvolve or Sakana’s AI Scientist.
Task Shape: Highly decomposable and exploratory. These systems hypothesize, code, and test thousands of variants in parallel.
AASF Alignment: This represents the “Decentralized Multi-Agent System” scaled for maximum exploration.
Primitive Use:
Verifiable Self-Challenges: It uses automated evaluators to score candidate solutions.
Shared Multi-Agent Memory: AlphaEvolve uses a central database to store all generated solutions and scores, informing future generations.
Simplified Flow:
Problem Definition → [Evolutionary Orchestrator] → (Agent Zoo / Mutations) → [Shared Success Archive] → Optimized Solution.
Case Study 3: The “Bottleneck” (Mission-Critical Evolution)
Scenario: The Darwin Gödel Machine (DGM) for code generation.
Task Shape: Tool-heavy and self-referential. The agent edits its own source code to improve its performance.
AASF Alignment: This is a Centralized MAS with a Validation Bottleneck. While it explores “open-endedly,” every tweak is validated against empirical benchmarks (like SWE-bench) before being committed.
Primitive Use:
Reflection Buffers: It stores a history of failures and tried approaches to make reflective decisions for future modifications.
Intrinsic Progress Predictors: It uses performance metrics as reward signals to decide which code paths to pursue.
Simplified Flow:
Goal → [DGM Agent] → (Proposed Code Edit) → [AUTOMATED TEST BENCHMARK] → Committed Archive.
The Ultimate AASF x Quiet Revolution Flow
This master diagram synthesizes the article’s “5 Primitives” into a decision-making framework for building non-obsolete agents.
GATE 1: Logic Geometry
If Sequential (e.g., Medical Billing) → Use Reflection Buffers (Primitive A) but keep the workflow “caged” (<10 steps).
GATE 2: Capability Baseline
If single-agent accuracy is low → Use Self-Authored Training Data (Primitive B) or Verifiable Self-Challenges (Primitive C) to bootstrap the agent’s knowledge without human labeling.
GATE 3: Risk Level
If High Risk → Insert a Validation Bottleneck (Human-in-the-loop or Symbolic Solvers as “oracles”) to prevent hallucinations.
If Low Risk → Use Shared Multi-Agent Memory (Primitive D) to allow the system to learn at “cultural evolution” speeds.
FINAL STEP: Embodiment (If Physical)
Use Intrinsic Progress Predictors (Primitive E) so the system can practice and improve during downtime.
Bridging Gaps between Single Agent Systems (SAS) and Multi Agent Systems (MAS)
So the outcome we see - that most today’s production agents are technically “obsolete” by research standards because they meet zero of the five primitives, is expected. However, we can also see this “dumbing down” as a deliberate choice to prioritize reliability over elegance in the enterprise.
The AASF allows you to bridge this gap by selectively adding 1–2 primitives (like Reflection or Automated Testing) into workflows to increase intelligence without losing control.
I find it a useful checkpoint. No doubt we ourselves will be subject to “continual learning” with the various agentic systems that adapt and progress. Nothing is perfected, as yet. And yet, the potential is quite visible.
This reference list (below) aggregates the foundational research, industrial breakthroughs, and reality-check surveys discussed across the “Science of Scaling” and “Quiet Revolution” frameworks. I hope you find it helpful.
Architectural Reasoning RE-Check
Having re-reviewed the papers, I want to reason out the architectural choices behind categorizing AlphaEvolve under Path C (Decentralized Mesh), Darwin Gödel Machine (DGM) under Path D (Centralized + Validation Bottleneck), and AI Scientist as a Path C → D hybrid within the Adaptive Agentic Scaling Framework (AASF).
1. AlphaEvolve: Path C (Decentralized Mesh / Swarm)
AlphaEvolve is categorized as Path C because its architecture is designed for High Decomposability and parallel exploration.
Logic: It functions as a “zoo” or “swarm” of mutant programs that evolve in parallel across a wide computational surface.
Decentralized Nature: Unlike a single agent trying to reason its way to a solution, AlphaEvolve spawns a population of variants. It relies on Shared Multi-Agent Memory (a central database) to allow successful mutations to propagate across the mesh.
Path C Characteristics: It avoids “sequential failure” by exploring thousands of branches simultaneously, making it a classic decentralized mesh that scales through evolutionary diversity.
2. Darwin Gödel Machine (DGM): Path D (Centralized + Validation Bottleneck)
DGM is a Path D architecture because it engages in the highest-risk activity possible: Self-Modifying Code.
Logic: In the AASF, Path D is reserved for mission-critical tasks where error amplification (noted as 17.2x in the framework) must be contained.
The Bottleneck: DGM requires a strict Validation Gate—typically a “Symbolic Oracle” like a compiler or a formal benchmark (e.g., SWE-bench)—before any code edit is committed to its core.
Path D Characteristics: It uses Intrinsic Progress Predictors to decide which modifications are worth keeping, effectively acting as a centralized “Architect” that must pass through a mandatory verification bottleneck to prevent system collapse.
3. AI Scientist: Path C → D (The Hybrid Pipeline)
AI Scientist is a hybrid because it mirrors the full scientific lifecycle, moving from broad discovery to high-stakes verification.
The Path C Phase (Discovery): It uses Tree-Search and parallel node expansion to hypothesize and author experimental paths. This is an exploratory mesh behavior where multiple ideas are “alive” at once.
The Path D Phase (Synthesis/Verification): Once data is generated, it shifts to a “Validation Bottleneck” phase. It uses Reflection Buffers (reviewing its own papers) and Verifiable Self-Challenges (running ablations and bug detection) to ensure the final “Mission-Critical” output—the research paper—is sound.
Logic: It scales by increasing Test-Time Compute (running more experiments) in the mesh phase before funneling results into a centralized, leashed output.
References:
The Core Scaling Research (Science of Scaling)
These papers define the emerging frontier of scaling inference-time compute and agentic structure.
Towards a Science of Scaling Agent Systems (Dec 2025): The primary Google/MIT framework for principled agent design. ArXiv Link
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters: Seminal work on “System 2” thinking. ArXiv Link
Scaling Test-time Compute for LLM Agents: Systematic exploration of search and reasoning in agentic frameworks. ArXiv Link
Scaling Large Language Model-based Multi-Agent Collaboration: Investigates scaling properties of collective reasoning. ArXiv Link
Multi-Agent Verification: Scaling Test-Time Compute with Multiple Verifiers: Using specialist agents to evaluate outputs. ArXiv Link
Multi-Agent Sampling: Scaling Inference Compute for Data Synthesis: Scaling laws applied to tree-search collaboration. ArXiv Link
Memory in the Age of AI Agents: Memory as a core scaling dimension for autonomous behavior. ArXiv Link
Dynamic Procedural Memory: Enabling agents to evolve through experience. ArXiv Link
Efficient Agents: Building Effective Agents While Reducing Cost: Addressing the token-efficiency trade-offs in scaling. ArXiv Link
The “Quiet Revolution” Foundation (Self-Improvement)
Foundational work on “Reflection Buffers” and models that talk to themselves.
Reflexion (2023): Language agents using verbal reinforcement learning. ArXiv Link
Self-Refine (2023): Iterative refinement through self-critique. ArXiv Link
STaR (2022): Bootstrapping reasoning with self-generated traces. ArXiv Link
Self-Consistency (2022): Majority voting across multiple reasoning paths. ArXiv Link
Voyager (2023): Open-ended exploration in Minecraft with LLMs. ArXiv Link
Inner Monologue (2022): Embodied reasoning via language planning. ArXiv Link
The 2025 Industry Breakthroughs
Advanced agents that edit their own source code and conduct research.
AlphaEvolve (DeepMind, 2025): Gemini-powered evolutionary coder for advanced algorithms. DeepMind Blog
Darwin Gödel Machine (Sakana AI, 2025): Self-modifying coder inspired by open-ended evolution. ArXiv Link
AI Scientist-v2 (Sakana AI, 2025): Automating the full research cycle for under $15 per paper. Technical Report PDF
Self-Rewarding LMs (2025): Models that generate and grade their own training batches. ArXiv Link
Self-Improving Embodied Foundation Models: Robots using “steps-to-go” prediction as intrinsic rewards. ArXiv Link
Skepticism & Production Surveys (The Reality Check)
Critical analysis of why “caged” agents dominate the enterprise.
Measuring Agents in Production (Dec 2025): Survey of 306 practitioners on the “caged” reality of deployed agents. ArXiv Link
Can LLMs Really Reason and Plan? (Subbarao Kambhampati): The sobering view on “ersatz” reasoning in models. CACM Blog
LLMs Can’t Plan, But Can Help Planning in LLM-Modulo Frameworks: Advocates for symbolic safeguards in agentic loops. ArXiv Link
Better Ways to Build Self-Improving AI Agents (Yohei Nakajima): Practical design patterns for the “5 Primitives” of self-improvement. Manifesto Link