
Constraints to Innovations: Software & Architectural Elegance of the DeepSeek V3 Model
The Open Source Evolution & Path is Bright!

The evolution of AI models often hinges on the balance between hardware capabilities and software ingenuity. The beauty of model architecture applied successfully, creates even greater wonder, for many of those who “geek out” on such facts. And such was the case in December 26th 2024, when Deepseek V3 was released. A lot of further excitement has since ensued with the subsequent release of DeepSeek-R1. But I will focus my attention on the Base Model first - DeepSeek V3.
So how did DeepSeek V3, faced with the limitations imposed by the NVIDIA H800 GPU's hardware constraints (remember, the H800 was specifically introduced for the Chinese market to offer [a high-performance GPU] that met certain export compliance requirements, vs. its more powerful “cousin,” the H100), leverage software and model architecture innovations not only to maintain, but enhance performance efficiency? And at only $5.6 Million? Read also DeepSeek V3 and the actual cost of training a frontier model.
Please note that I will not debate the export compliance requirements or whether they work or otherwise - I am simply appreciating what to me, is in essence - An efficient technical model marvel, made (almost) perfect by it’s open sourcing (MIT License), for DeepSeek-R1 (which uses DeepSeek V3 as a base model), just released approximately 5 Days ago. So for now, the focus will be DeepSeek V3. If interested in the other views, here’s an interesting one: The Short Case For Nvidia’s Stock (I don’t necessarily subscribe to the view, because of Jevon’s Paradox etc but it is interestingly detailed (includes history) and worth a read).

What did they do that is so special, to reflect these Benchmark Metric results?
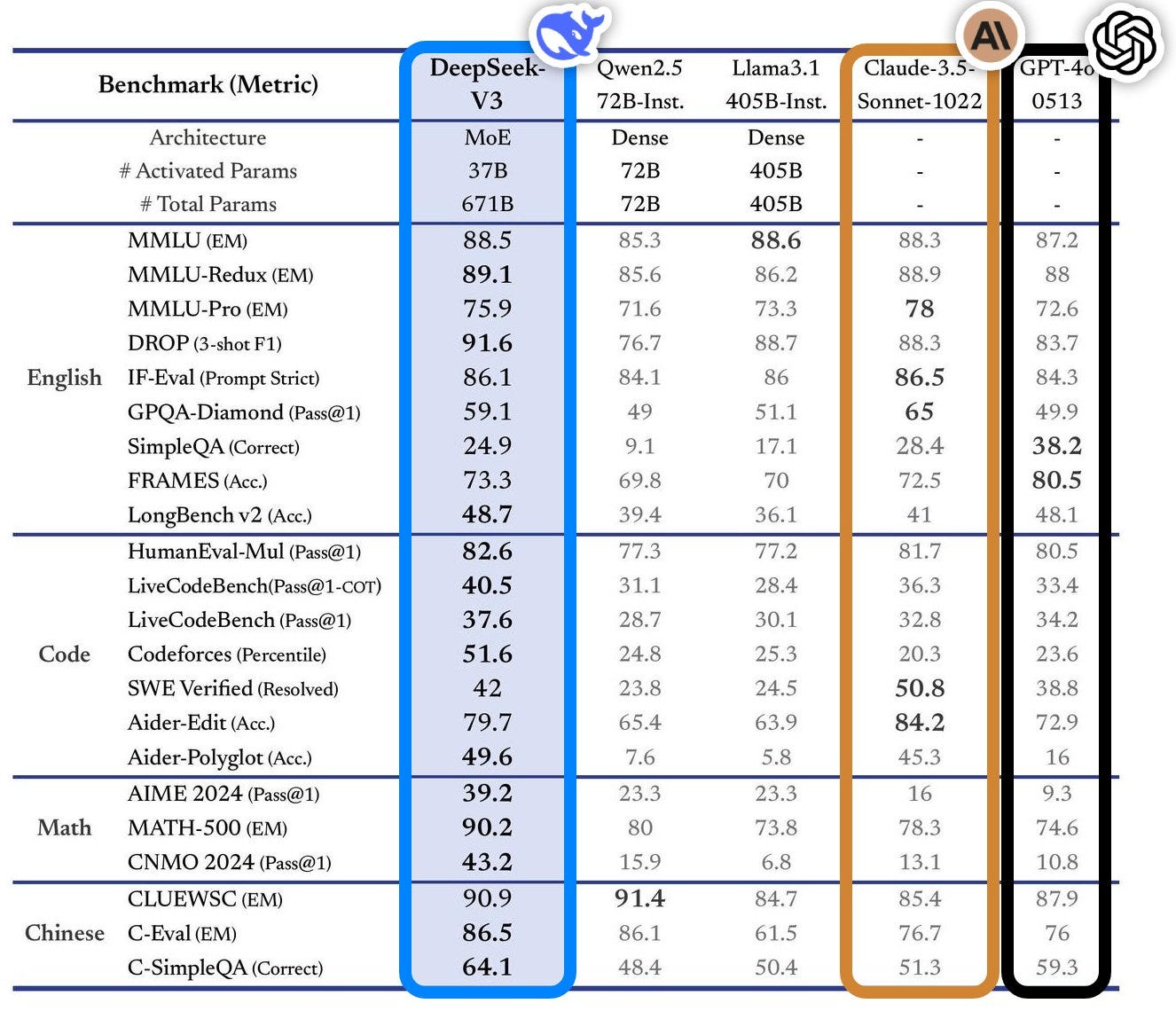
These are notes I have kept and will continue reviewing along the way. Note: For my friends who find the technical elements too much (many corporate directors sought a “layperson” understanding) I have included a brief explanation, further below (but perhaps walk along the technical bits first and try?).
The H100 vs the H800
First the specification variations (summarized) of the Hardware that DeepSeek V3 used - the H800 vs H100:
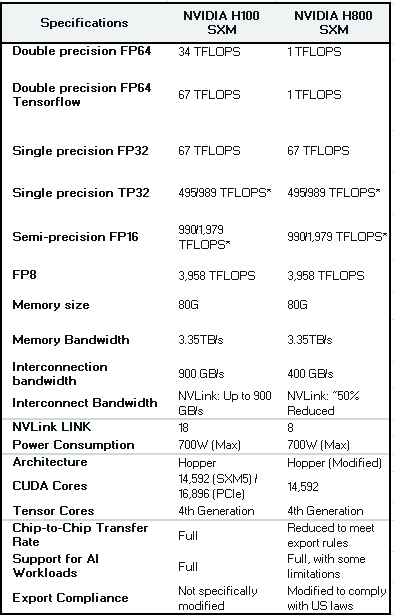
Based on information available from various sources (including Deepseek V3’s technical report), DeepSeek V3 made several model and architecture changes to optimize for the limitations of the NVIDIA H800 GPUs. Here are the key changes related to the H800 specifications (these were interpreted from the DeepSeek V3 Technical Report and other sources (to be added later):
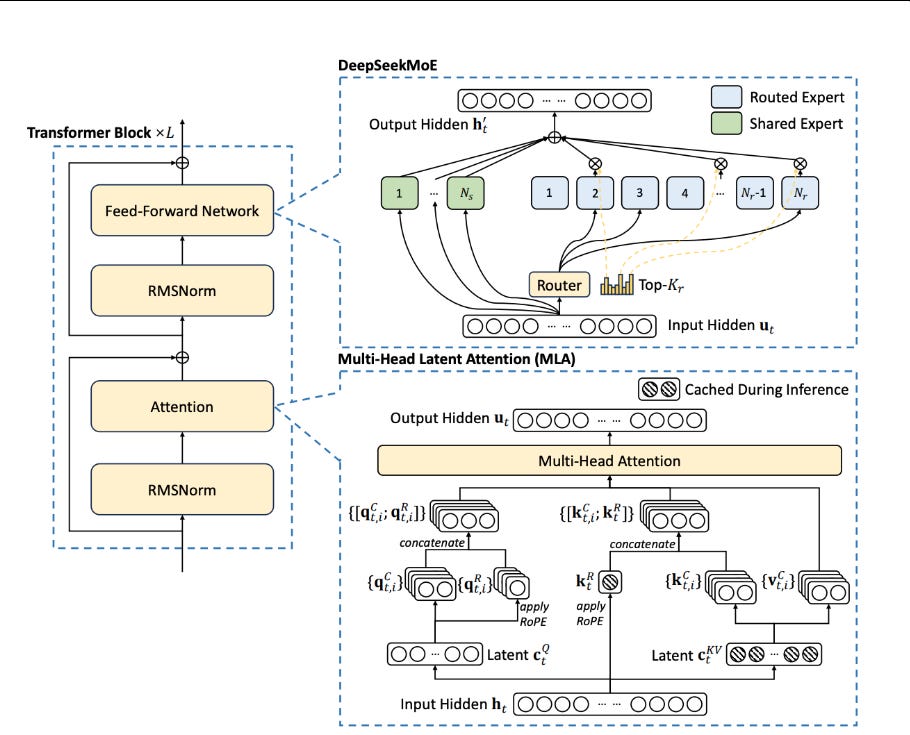
DualPipe Algorithm:
Purpose: To optimize the training process by overlapping computation with communication.
Details: DeepSeek V3 employed the DualPipe algorithm to overlap computation and communication phases within and across forward and backward micro-batches, thereby reducing pipeline inefficiencies. This was particularly crucial given the H800's reduced interconnect bandwidth. The algorithm ensured that while one part of the model was computing, another part was communicating, maximizing hardware utilization. For the Mixture-of-Experts (MoE) architecture, DualPipe minimized training bottlenecks by handling dispatch (routing tokens to experts) and combine (aggregating results) operations in parallel with computation. This was achieved through the use of customized PTX (Parallel Thread Execution) instructions, which involved writing low-level, specialized code optimized for NVIDIA CUDA GPUs. This optimization allowed the cluster to process 14.8 trillion tokens during pre-training with near-zero communication overhead, highlighting the effectiveness of this approach in managing the H800's limitations.
Custom GPU Communication Protocols:
Purpose: To enhance communication efficiency between GPUs.
Details: DeepSeek implemented custom communication protocols to further optimize data exchange, particularly by restricting each token's communication to a maximum of four nodes. This limitation reduced network traffic and ensured that communication and computation could overlap effectively, complementing the DualPipe algorithm. This was vital for managing the H800's fewer NVLink connections, ensuring efficient data transfer despite the hardware limitation. The custom protocols were tailored to the specific topology of GPU connections, minimizing communication overhead by transferring only necessary data.
FP8 Mixed Precision Training:
Purpose: To reduce memory usage and increase computation speed.
Details: DeepSeek adopted an FP8 mixed precision framework to significantly lower the memory footprint, which was beneficial for the H800's 80GB memory capacity. This approach allowed for faster computation by conducting key operations like matrix multiplications in FP8 precision, while sensitive components such as embeddings and normalization layers were kept in higher precision (BF16 or FP32) to maintain accuracy. This strategy not only reduced memory requirements but also ensured numerical stability, with the relative training loss error consistently under 0.25%. This balance between precision and efficiency was key in leveraging the hardware capabilities of the H800 without sacrificing model performance.
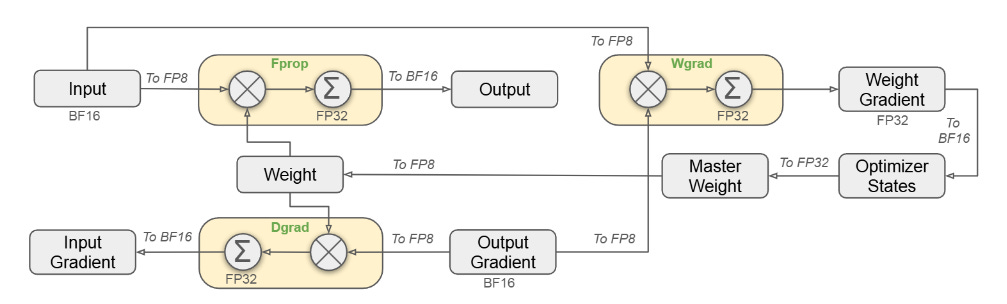
Mixed Precision Framework with FP8 Data Format Multi-Head Latent Attention (MLA):
Purpose: To reduce memory usage in attention mechanisms.
Details: MLA was introduced to use only 5-13% of the memory required by traditional Multi-Head Attention (MHA). This optimization was critical for managing the memory constraints of the H800, allowing for larger models or more complex tasks within the same memory limits. By focusing on efficiency, MLA optimized how multiple streams of information were processed, making it a crucial component in DeepSeek V3's architecture for memory efficiency.
DeepSeek MoE Sparse Structure:
Purpose: To save computing power and reduce costs through selective activation.
Details: This structure utilizes a Mixture-of-Experts (MoE) approach where only a small subset of the model's components ('experts') are activated for each task. The "sparse" aspect ensures that only necessary computations are performed, aligning with the H800's computational limitations. With a total of 671 billion parameters but only activating 37 billion for each token, this significantly reduced the computational load, making it suitable for the H800's reduced double precision (FP64) capabilities. The MoE structure was seamlessly integrated with the DualPipe algorithm to ensure efficiency in both computation and communication.
Memory Tensor Parallelism:
Purpose: To distribute model parameters efficiently across multiple GPUs.
Details: Memory Tensor Parallelism helps in managing memory constraints by spreading the model's parameters across GPUs in a way that optimizes memory usage. This technique allowed for processing larger models or batches without overwhelming the memory of individual GPUs, which was critical when working with the H800's memory limitations. By distributing the workload, Memory Tensor Parallelism complemented the other strategies, ensuring that the model could operate within the hardware constraints while maintaining performance.
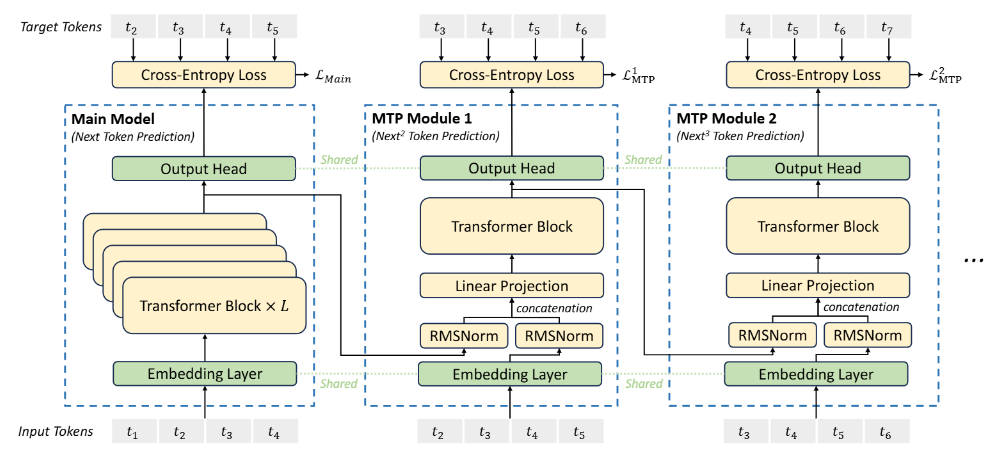
MTP as Multi-Token Prediction:
MTP trains language models to predict multiple tokens (e.g., 4 tokens) at each training step using independent output heads on a shared transformer backbone. This approach:
Improves sample efficiency by forcing the model to learn long-range dependencies and global context, especially beneficial for structured tasks like code generation138.
Accelerates inference via self-speculative decoding, where multiple heads generate candidate tokens in parallel, validated by the main model for correctness. For example, a 4-token MTP model achieves 3× faster inference speed compared to traditional next-token prediction167.
Excels in code and math tasks, with DeepSeek-V3 (using MTP) outperforming baseline models by up to 17% on MBPP and 12% on HumanEval
While MTP is not a form of tensor parallelism, it uses memory-efficient implementations to handle the computational overhead of multi-head predictions:
Sequential gradient computation: Gradients for each output head are calculated sequentially, avoiding simultaneous storage of all gradients. This reduces GPU memory usage from O(nV+d)O(nV+d) to O(V+d)O(V+d), where VV is the vocabulary size and dd is the model dimension157.
FP8 mixed-precision training: DeepSeek-V3 employs FP8 to reduce memory footprint and accelerate training, validated on large-scale models69.
DualPipe algorithm: Overlaps computation and communication during pipeline parallelism, minimizing memory bottlenecks
MTP Distinction from Tensor Parallelism
Tensor parallelism typically refers to splitting model parameters across GPUs to handle large-scale computations. In contrast:
MTP focuses on training objectives and inference acceleration rather than distributing model parameters.
The memory optimizations in MTP address gradient storage and low-precision training, not parallel tensor operations
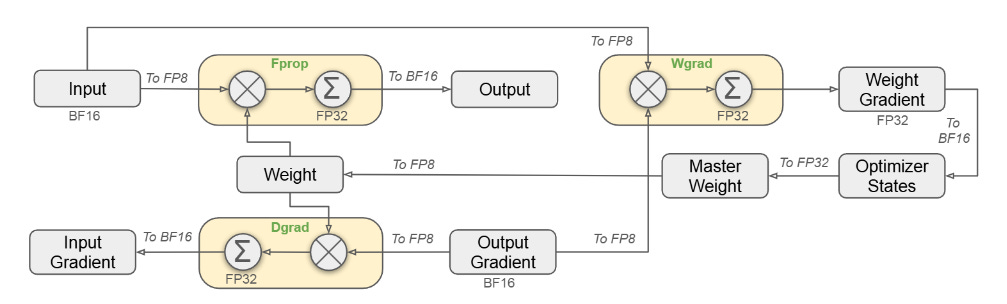
Limitations in Interconnection Bandwith and NVLink
The limitations in interconnection bandwidth and NVLink indeed mattered for DeepSeek V3 when adapting to the NVIDIA H800's specifications. The points were captured above but just to highlight, here's how these limitations were addressed:
Interconnection Bandwidth: The H800's reduced interconnection bandwidth compared to the H100 was a significant factor. DeepSeek V3 implemented the DualPipe Algorithm (point 1 above) to mitigate this by overlapping computation with communication, reducing the impact of slower data transfer rates. This algorithm ensures that while one part of the model is computing, another part is communicating, thus maximizing efficiency despite the bandwidth limitation.
NVLink: The reduction in NVLink connections from 18 in the H100 to 8 in the H800 also presented a challenge, particularly for multi-GPU communication in distributed training setups. To address this, DeepSeek developed custom multi-GPU communication protocols (point 2 above). These protocols were designed to optimize data transfer efficiency, ensuring that the reduced NVLink connections did not significantly hamper the overall performance of the model training process. Seperate note that the Mellanox investment by Nvidia was brilliant.
So, DeepSeek V3 managed to work around the limitations, ensuring that the model could still perform effectively even with the H800's hardware constraints. The focus was on optimizing the communication aspect of the training process to compensate for the hardware's reduced capabilities in this area.
DualPipe Algorithm and Custom GPU communication protocols
Both the DualPipe Algorithm and Custom GPU Communication Protocols are advanced techniques that address the H800's specific limitations. They ensure that despite its reduced capabilities in certain areas, the H800 can still perform effectively in large-scale AI training scenarios. How do they help?
The DualPipe Algorithm is a technique designed to optimize the training process in multi-GPU environments by overlapping computation and communication phases:
Pipeline Parallelism: Traditional pipeline parallelism in deep learning involves splitting a model across multiple GPUs, where each GPU processes different layers of the model sequentially. However, this can lead to idle time as one GPU waits for data from another.
DualPipe Approach: DualPipe extends this by creating two overlapping pipelines:
Forward Pipeline: When one GPU is computing the forward pass of a batch, another is already starting the forward pass of the next batch, reducing idle time.
Backward Pipeline: Similarly, during the backward pass (for gradient computation), computation and communication are overlapped. While one GPU computes gradients, another might be sending or receiving data.
Benefits:
Reduced Latency: By overlapping computation with communication, DualPipe reduces the overall time spent waiting for data transfer, which is particularly beneficial when dealing with lower interconnection bandwidth like that of the H800.
Improved Utilization: It ensures that GPUs are not sitting idle, maximizing hardware utilization.
Application: For the H800, where the interconnect bandwidth is a bottleneck, DualPipe helps by ensuring that the communication overhead does not significantly slow down the training process.
“In particular, dispatch (routing tokens to experts) and combine (aggregating results) operations were handled in parallel with computation using customized PTX (Parallel Thread Execution) instructions, which means writing low-level, specialized code that is meant to interface with Nvidia CUDA GPUs and optimize their operations.” ~ Tom’s Hardware
Customized PTX Instructions:
What This Is: PTX is an intermediate representation of CUDA code which is then compiled into machine code for NVIDIA GPUs. Customized PTX instructions involve writing low-level, specialized code that directly interfaces with the GPU's hardware to optimize operations at the thread level.
Purpose: The main goal here is to fine-tune the execution of operations within the GPU itself. This could involve optimizing how individual threads or groups of threads (warps) execute specific computations, potentially leading to better utilization of the GPU's compute resources, improved instruction throughput, or reducing the number of cycles needed for certain operations.
Application: This is more about optimizing the computation part of GPU operations. For instance, if there are specific mathematical operations or data handling routines that are frequently used by your application, writing custom PTX can make these operations more efficient by tailoring them to the exact capabilities of the GPU hardware.
Example: You might write custom PTX to optimize matrix multiplication for a specific GPU architecture, reducing the number of memory accesses or improving the efficiency of how data is moved within the GPU.
Custom GPU communication protocols refer to tailored methods of data exchange between GPUs, especially when standard protocols might not be optimal due to hardware limitations:
Standard vs. Custom: Standard protocols like NVLink or PCIe might not be fully optimized for specific workloads or hardware configurations. Custom protocols can be designed to:
Minimize Overhead: Reduce unnecessary data transfer steps or overhead that could slow down communication.
Optimize for Bandwidth: Tailor the communication to work efficiently with the available bandwidth, ensuring that data is sent in the most efficient manner possible.
Implementation:
Data Aggregation: Combining multiple small messages into larger ones to reduce the number of communication events, which can be particularly beneficial with lower bandwidth.
Topology Awareness: Designing protocols that are aware of the physical topology of the GPUs, ensuring data follows the fastest path possible, which is crucial when NVLink links are fewer.
Asynchronous Communication: Allowing computation and communication to proceed asynchronously, where possible, to hide communication latency.
Benefits in H800 Context:
Compensates for NVLink Reduction: With fewer NVLink links, custom protocols can ensure that the remaining connections are used more effectively.
Interconnection Bandwidth: By optimizing how data is transferred, custom protocols can mitigate some of the performance losses due to lower bandwidth.
Application: These protocols would be developed or adjusted to work within the constraints of the H800, ensuring that the model training on such hardware remains efficient. This might involve using libraries like NCCL or UCX in innovative ways or developing entirely new methods suited to the specific needs of the workload and hardware.
Note Key Differences:
Level of Abstraction: Customized PTX instructions work at a very low level, directly interfacing with the GPU's execution units, while custom GPU communication protocols operate at a higher level, managing inter-GPU data flow.
Focus: PTX focuses on computation efficiency within a single GPU, whereas communication protocols focus on the efficiency of data transfer between GPUs.
Implementation: PTX involves writing or modifying kernel code, whereas communication protocols might involve modifying or extending libraries like NCCL (NVIDIA Collective Communications Library) or using frameworks that handle multi-GPU communication.
Precedence of Similar Strategies in Other Models?
While the fundamental ideas behind these strategies have precedents in AI research, the specific implementations and optimizations for the H800's limitations by DeepSeek V3, particularly in terms of MLA, FP8, and the tailored applications of DualPipe, MTP and custom communication protocols (coming together), represent innovative applications or enhancements over existing practices.
DualPipe Algorithm:
Precedence: While the specific implementation of the DualPipe Algorithm as described for DeepSeek V3, focusing on the H800's limitations by overlapping computation and communication, wasn't mentioned (to my knowledge) in other models before its release, pipeline parallelism itself, which DualPipe builds upon, has been used in various forms. The idea of overlapping computation and communication in multi-GPU environments isn't new; however, the exact form tailored for the H800's constraints seems to be a novel application by DeepSeek V3.
Application: The general concept of pipeline parallelism predates DeepSeek V3, but the specific DualPipe approach as an optimization for the H800 wasn't highlighted in the provided sources for other models.
Custom GPU Communication Protocols:
Precedence: Custom communication protocols for optimizing GPU communication have indeed been used in various AI research contexts before DeepSeek V3. Libraries like NCCL are examples of efforts to optimize multi-GPU communication. However, the specific custom protocols tailored for the H800's configuration weren't detailed in other models before DeepSeek V3, making this application unique in its context.
Application: Custom communication protocols have been a part of distributed computing in AI, but the specific adaptations for the H800 weren't discussed in other models before DeepSeek V3.
FP8 Mixed Precision Training:
Precedence: Mixed precision training, particularly with FP16, has been widely adopted in AI training for efficiency gains. However, the move to FP8 precision as used by DeepSeek V3 represents a further step in this direction, focusing on even lower precision for certain operations. Before DeepSeek V3, while FP16 was common, FP8 was not as widely discussed in the context of training large language models, making this specific application somewhat innovative.
Application: Mixed precision with FP16 was common, but FP8's use for large-scale training like that of DeepSeek V3 was less prevalent or not highlighted in the provided sources before its release.
Multi-Head Latent Attention (MLA):
Precedence: Attention mechanisms, including Multi-Head Attention (MHA), have been fundamental in transformer models like BERT, GPT, etc. The specific MLA approach, reducing memory usage significantly, was not widely documented before DeepSeek V3's release. However, the broader research community had been exploring ways to optimize attention for efficiency, including memory efficiency, which aligns with the concept of MLA.
Application: While specific MLA wasn't necessarily mentioned, the optimization of attention mechanisms for efficiency was part of ongoing research, suggesting a foundation for such innovations.
DeepSeek MoE Sparse Structure:
Precedence: The Mixture-of-Experts (MoE) architecture has been explored before, with models like Google's Switch Transformers introducing routing tokens to specific experts. The 'sparse' aspect of activating only necessary experts for each task aligns with the general principles of MoE but was specifically tailored by DeepSeek V3 to manage computational efficiency within the H800's constraints.
Application: MoE has precedents in models like Switch Transformers, but the specific DeepSeek MoE Sparse implementation seems unique in its application to manage the H800's computational limits.
Memory Tensor Parallelism :
Precedence: Tensor parallelism, where model parameters are distributed across multiple GPUs, has been used in large-scale model training, notably by models like Megatron-LM. While Memory Tensor Parallelism as specifically described for DeepSeek V3 might not have been used in the same context or with the same focus on memory efficiency for the H800, the concept of distributing tensor computations across GPUs to manage memory has precedents.
Application: Tensor parallelism has been used in models like Megatron-LM, indicating precedence in the concept of distributing computations for efficiency.
Multi Token Prediction (MTP):
Research Precedence
Early Work on Multi-Token Prediction
2018-2020: Early research explored predicting multiple tokens in sequence-to-sequence models, particularly in machine translation and text generation. These studies demonstrated that multi-token prediction could improve training efficiency and model performance by forcing the model to learn longer-range dependencies.
2021: Meta (formerly Facebook AI) published foundational work on multi-token prediction for autoregressive models, showing that predicting multiple tokens simultaneously could reduce training time and improve sample efficiency.
Meta’s MTP Framework (2024)
Meta formalized MTP as a training technique for large language models (LLMs), introducing independent output heads for predicting multiple tokens in parallel. This approach was validated on tasks like code generation, where it significantly improved inference speed and accuracy.
Meta’s implementation demonstrated that MTP could achieve 3× faster inference compared to traditional next-token prediction, with minimal memory overhead.
Meta’s MTP paper: arXiv:2404.19737
A Non-Technical View of The Very Elegant Deepseek V3 Model
Many friends have been wondering about the “excitement” around these models. But found the technical reports a bit challenging. So I hope this helps, somewhat. As best I can.
Imagine you're trying to run a big, complex AI project on a computer that's like a slightly less powerful version of the latest top model, because of some rules that limit what kind of computing power can be used in certain places. This is what DeepSeek V3 faced with the H800 GPU. Here's how they made it work:
DualPipe Trick: Think of this like a relay race where runners pass the baton. While one runner (or in this case, part of the computer) is doing the work (computing), another is getting ready to take over (communicating data). This helps because the H800 isn't as fast at passing data around as the H100, so by doing this, they made sure the computer was always busy doing something useful, not waiting around.
Smart Data Chats: They created special rules for how different parts of the computer (GPUs) talk to each other. Since the H800 can't chat as well as the H100 (less connections), they made sure only the most important data was shared, and in the best way possible, like making sure friends in a group chat only talk when needed, so it's not too crowded.
Using Less Detailed Maps: Instead of using super detailed maps (high precision data), they used simpler ones (FP8 precision) where it was okay. This is like choosing a less detailed map when you're just trying to get from A to B in a city; it saves space and speeds things up.
Efficient Attention: They found a way to make the AI pay attention to what's important without using too much memory, kind of like teaching someone to focus on key points in a conversation without remembering every single word. This meant they could handle bigger AI tasks on the H800.
Selective Brain Use: Imagine your brain has different experts for different tasks. DeepSeek's AI only wakes up the experts that are needed for the job at hand, like calling only the plumber when you have a leak, not the whole repair crew. This saves energy and makes things faster.
Sharing the Load: They spread out the work across multiple GPUs like sharing a big puzzle among friends, so no one gets overwhelmed. This was important because the H800's memory can get full if you try to do too much at once.
MTP: MTP is like teaching the model to think ahead and predict multiple words or tokens at once, making it faster and more efficient at generating text or code. It’s a powerful technique that’s especially useful for tasks requiring long-range context and high-speed generation.
Effect and How to Think About It:
Effect: All these tricks made the H800 work almost as well as the H100 would for AI tasks, even though it's technically less powerful. It's like getting a slightly older car to perform like a new one by optimizing how you drive it and maintain it. And changing it’s engine and wiring. Technically all doable. With a little bit of effort (I liken it to blood and sweat). haha.
How to Think About It: Think of it like cooking a big meal in a kitchen with fewer appliances than you'd like. You have to be clever with how you use your oven, stove, and fridge, making sure you're not wasting time or space, so everything gets done efficiently. DeepSeek V3 did this with their AI model on the H800, making the best out of what they had.
So, even with less powerful hardware, through smart software and design, DeepSeek V3 was able to keep their AI model running efficiently, showing that innovation isn't just about having the best tools but also about using what you have in the smartest way possible.
The Elephant In The Room Questions
2 big ones. Imagine what they could/would do with 50,000 H100 GPUs….or more? And what were the data sources? Always useful technical updates from Teortaxes to follow:
https://x.com/teortaxesTex/status/1883640206945083486 or
But hey - doesn’t change the fact that what DeepSeek has done and shared (with detailed technical reports and licensing) is move of brilliance, after Meta’s Llama models (which no doubt will see even better performance metrics with Llama 4 etc, because of basically - equally replicable strategies and techniques).
All things said and done, the Open Source Community is rather fortunate. To try it, sign up here.
References:
DeepSeek V3 - The Six Million Dollar Model
DeepSeek V3 and the actual cost of training a frontier model - Nathan Lambert's Interconnects
I am not an AI nerd, but this is a brilliant use of resources and I imagine this sort of thinking will allow more economic and energy efficient data centers to be built. These are the real constraints.
Going to dig into this later when I have time, thank you for sharing!