
Convergence Signals: Bridging Research Ideas And Production Reality - Too Many Bridges Too Far?
Eights developments that reinforce, accelerate and question what’s already moving: "Works In The Lab" towards better -> "Ships In Production?' Challenges remain.

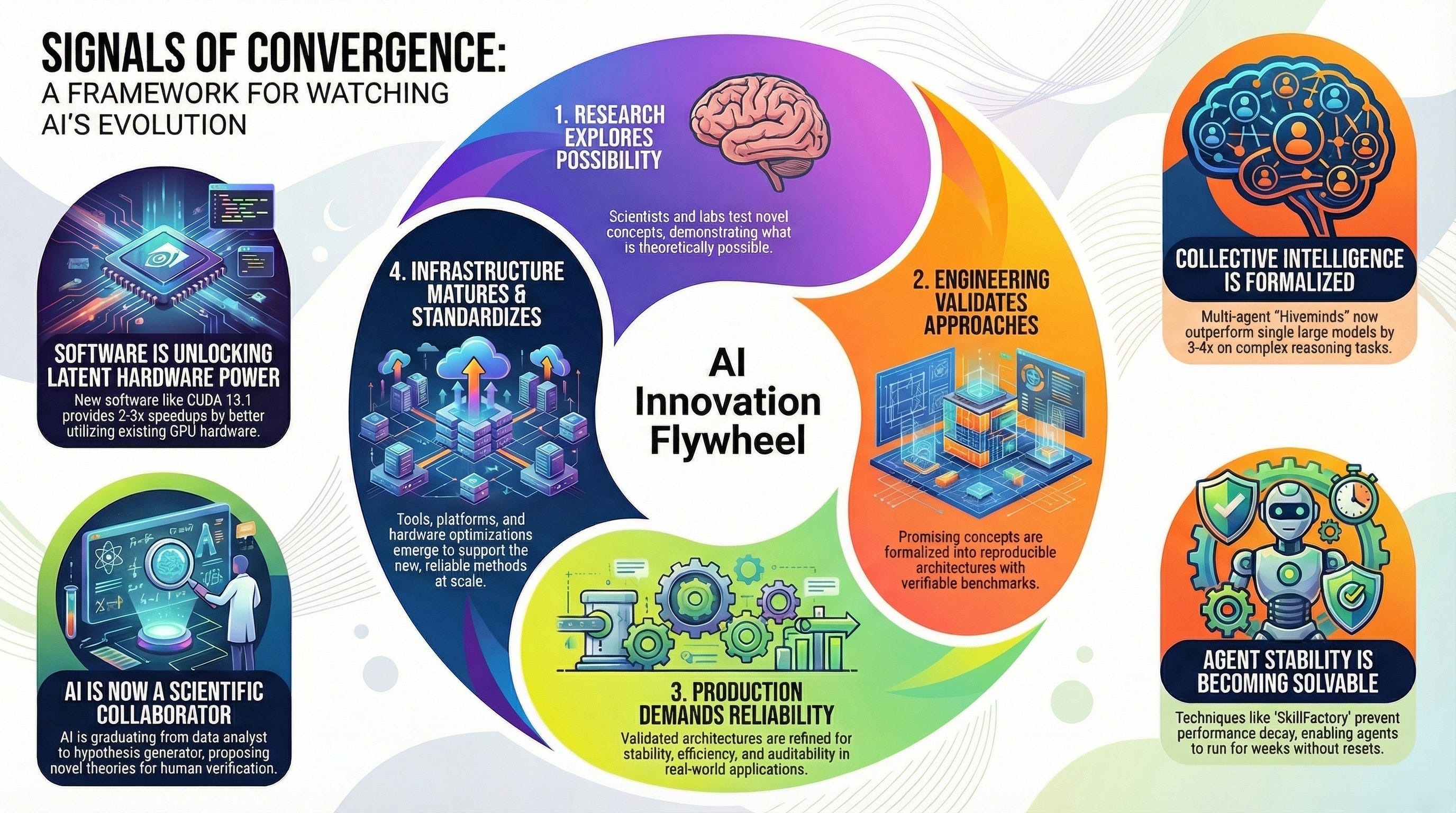
Accelerations. And signals. December 2025 is delivering a concentrated burst of validations, refinements, and possible (emphasis!!) production-ready implementations of ideas the AI research community has been developing for years.
I guess 2025 itself will be remembered very differently in terms of shifts (what change 3 years gives!), vs the chat model - ChatGPT’s emergence in Nov 2022.
For example, the surfacing and domination of comparably “good-enough” Open Source and many China-based models that kick-started the year with DeepSeek Math, V3, R1 followed by many amazing model releases - Kimi, Qwen including OLMO and many others; agentic and agent type systems that operate with routers, choosing and refining model responses, agnostic to whether it’s provided necessarily from the latest “most funded lab(s)”. As long as it works. But they’re actually good! With efficiencies to boot! Expect to see more focus on memory and contextual capture before the year ends.
A summary of models across performance, benchmarks, costs and efficiencies (Source: Artificial Analysis).
On the Measure of Intelligence (Yes, I have written enough about issues with benchmarks but this is good enough - my criteria):
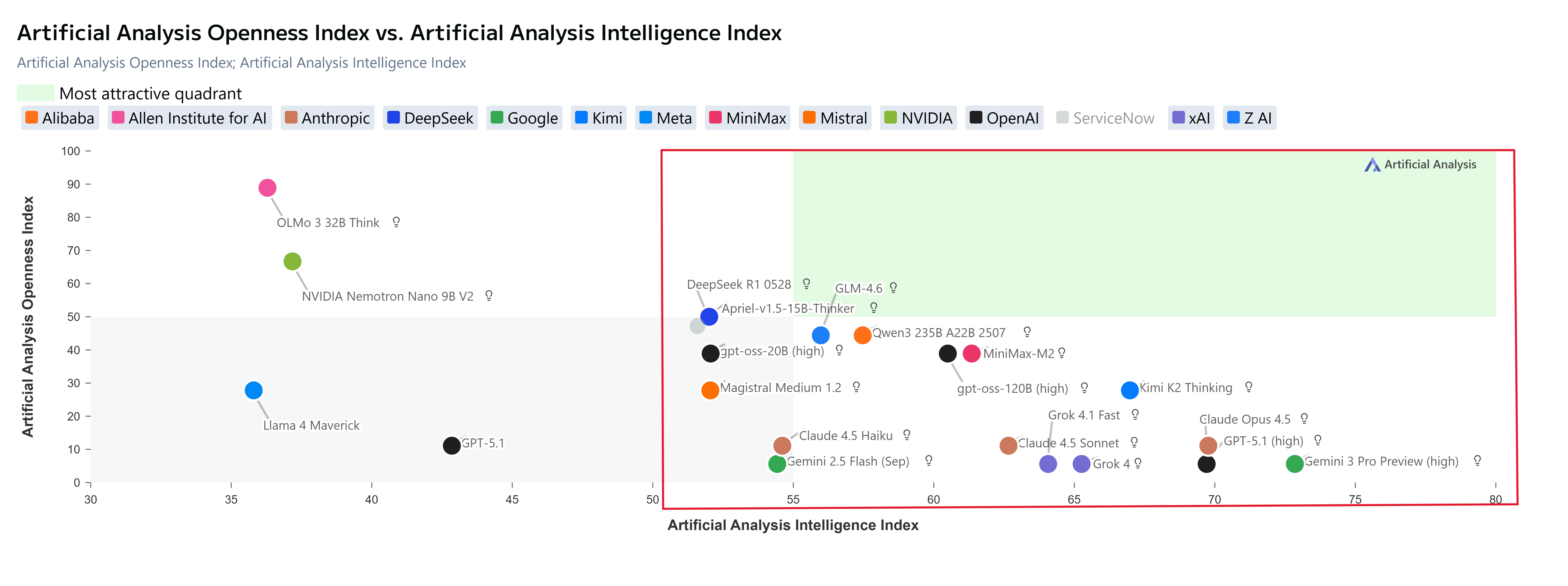
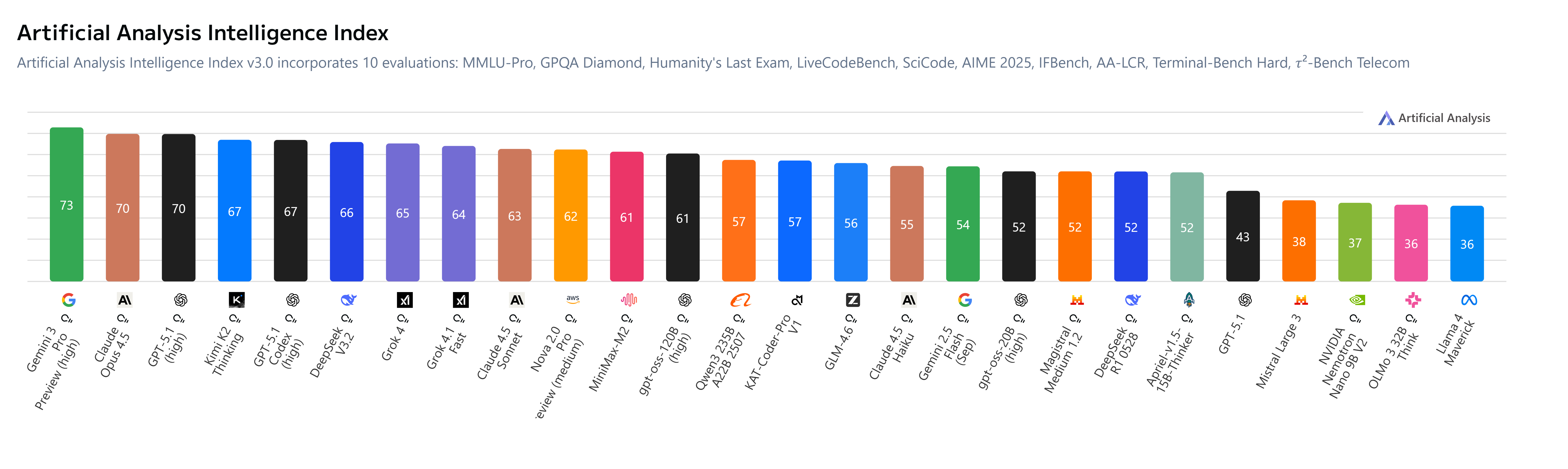
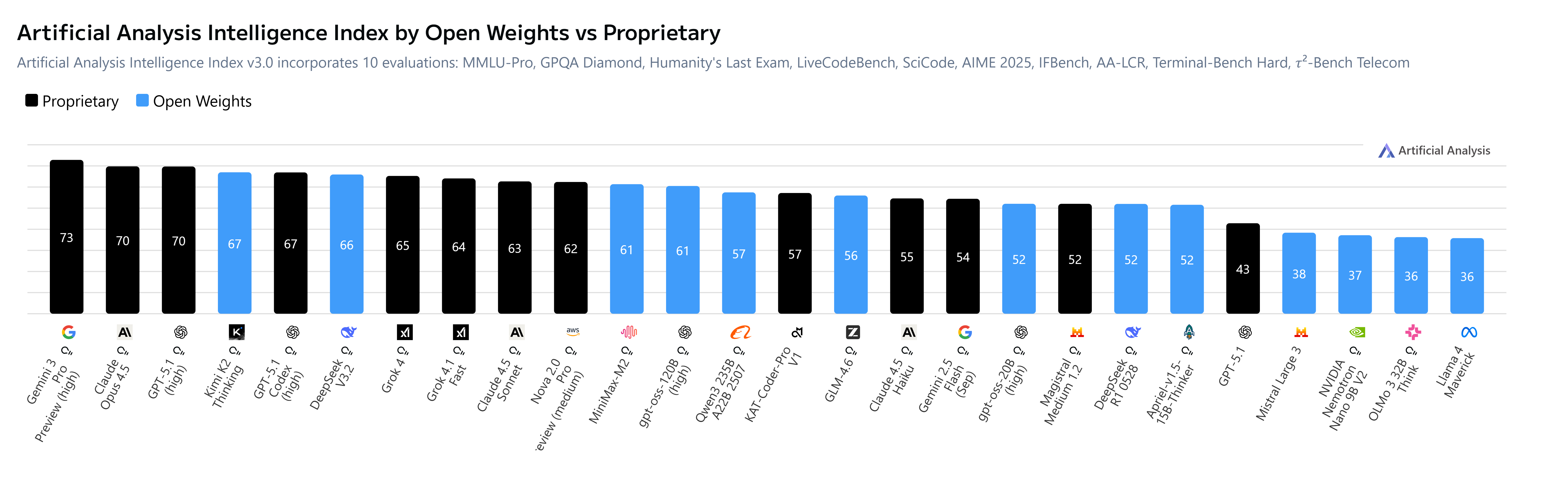
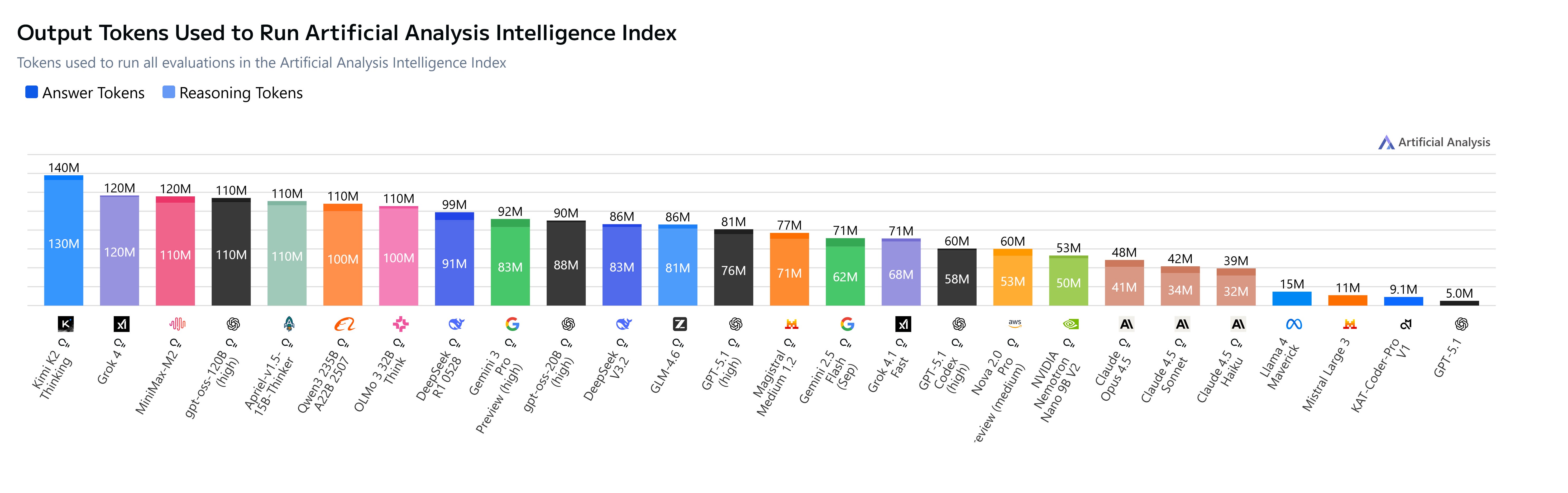
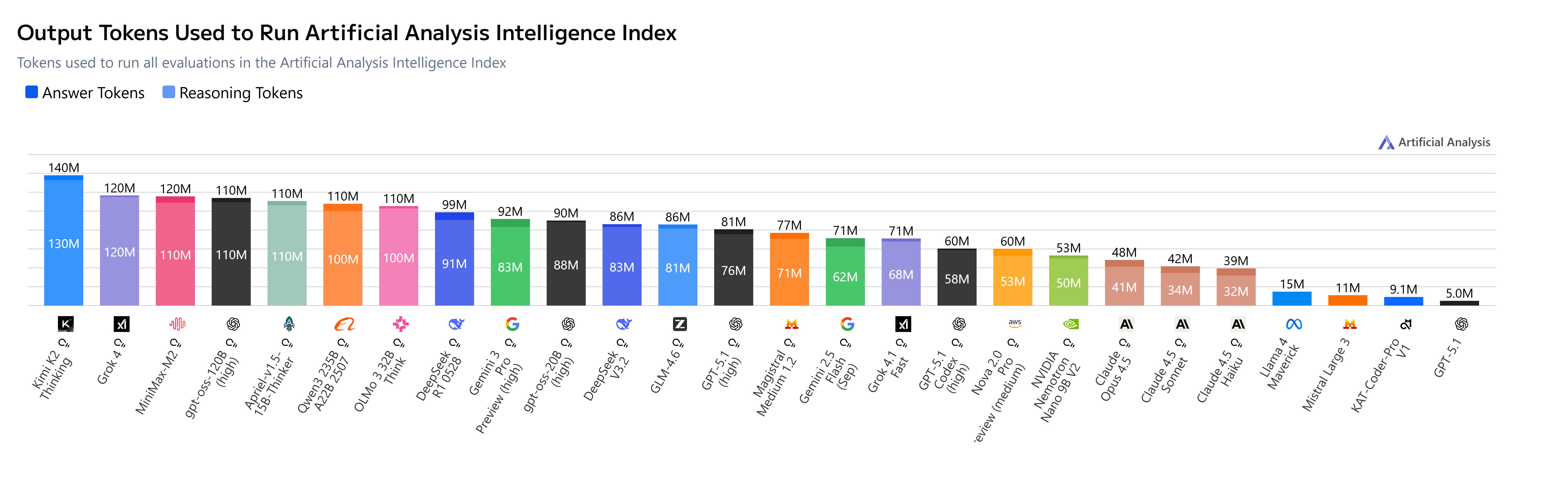
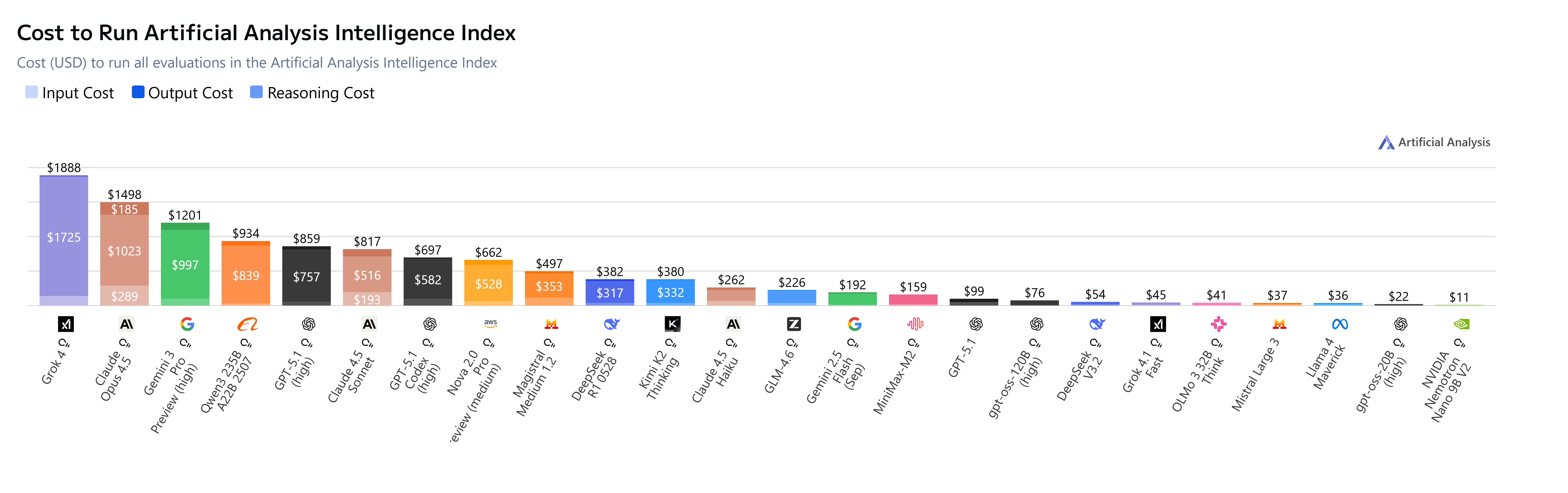
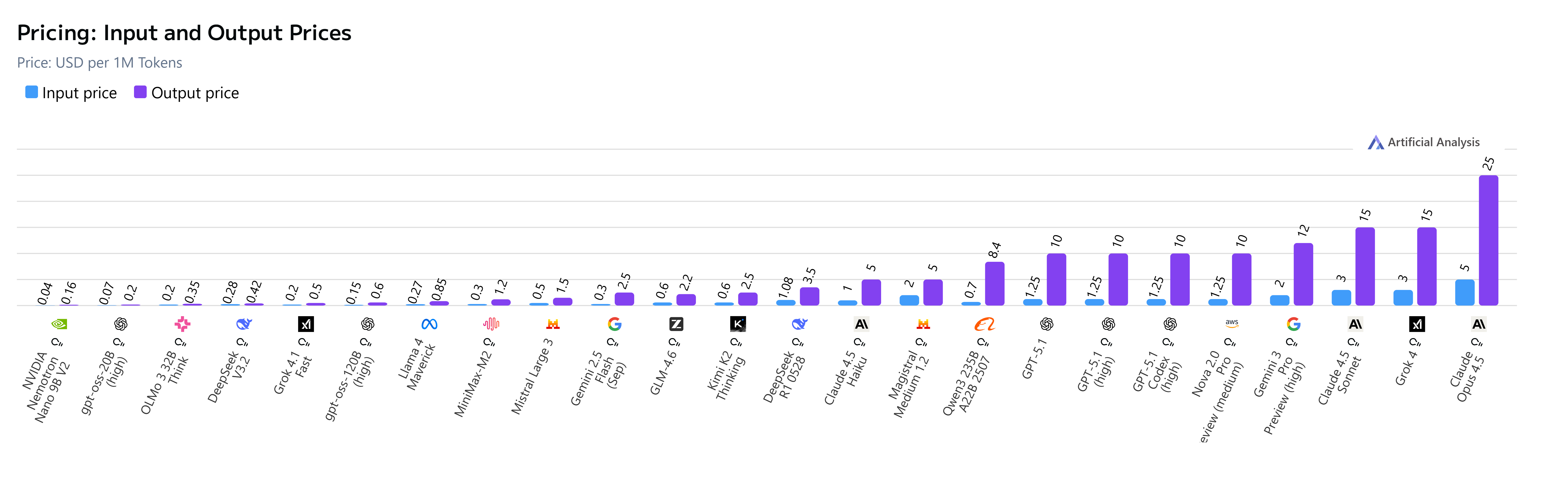
So how do model intelligence & evolutions support Agent systems, and production potential? What’s new? Where is the space moving towards, and what’s worth watching, you might ask?
Here are a few points, some captured from the just-concluded NEURIPS 2025. If you have limited time, the “Best Papers Awards” section is worth a thorough read.
These Interlocking Gears
1. Artificial Hivemind: Structured Consensus Graphs
The Evolution (Research → Production?)
Research Phase (Before): “Swarm Intelligence” was stochastic and hard to debug. You ran multiple agents and hoped for the best, often resulting in high compute costs and “hallucination cascades.”
Tests (Now): The Artificial Hivemind architecture formalizes interaction into a Consensus Graph. It turns chaotic chatter into a deterministic, auditable voting process (The “Committee Effect”). Well, formally - structured consensus and message-passing graphs. Note that for now these are based on case studies and controlled evaluations.
Practical Notes:
The “Artificial Hivemind” effect—where specialized agent clusters outperform monolithic models—was validated via the Infinity-Chat benchmark (10K queries across 70+ production LLMs). In live vendor audits, this architecture flagged 40% false diversity in legacy systems and demonstrated a 3-4x performance gain on complex reasoning tasks by using “Committee” voting rather than single-model inference.
What and How They Did It:
Authors from the Allen Institute and UW formalized the “Committee Effect.” (my words). Instead of one large model (e.g., GPT-5) doing everything, they deployed a graph of smaller, specialized agents (2B-8B params). These agents engage in Voting (for math/logic) or Debate (for planning), filtering out errors before they reach the user.
Pipeline Techniques:
Orchestration: Ray Serve clusters managing parallel inference of constituent agents.
Consensus Layer: A lightweight “Judge” node using Weighted Majority Voting logic to aggregate outputs.
Eval Loop: Similarity scoring via Sentence-BERT embeddings (threshold <0.7 cosine similarity) to enforce diverse reasoning paths before consensus.
Deployment: Streamlit-based CI/CD checks that flag “groupthink” (high inter-model homogeneity) before deployment.
2. SkillFactory: Stabilizing Long-Horizon Agents
The Evolution (Research → Production?)
Research Phase (Before): The “Likelihood-Displacement Death Spiral.” Agents performing long tasks (coding, ETL) would degrade over time, overfitting to their own recent outputs and forgetting core instructions after ~100 steps.
Tests (Now): SkillFactory treats agent memory as a curated dataset. It introduces hygiene into the experience buffer, allowing agents to run for weeks without a “hard reset.”
Practical Notes:
Evaluated on SWE-Bench (GitHub issue resolution), SkillFactory pipelines demonstrated 5x sample efficiency and 40% fewer failures in 1,000-hour continuous runs. Databricks pilots integrated this into internal ETL agents, cutting debugging time by 60% and eliminating the need for daily restart scripts.
What and How They Did It:
UC Berkeley researchers utilized Trajectory Rearrangement. Instead of training on experiences sequentially (which biases the model to the “now”), they permuted the experience buffer. They also applied Negative-Likelihood Guardrails, penalizing the model if its confidence on “safe/known” answers dropped below a set threshold.
Pipeline Techniques:
Data Ops: Modular RLHF stack with
torch.randpermfor buffer shuffling (Trajectory Rearrangement).Training: Entropy-regularized PPO (Proximal Policy Optimization) for sustained exploration.
Monitoring: MLflow logging specifically tracking “Policy Drift” metrics to trigger auto-retraining if the “Death Spiral” signature appears.
Infrastructure: Kubernetes pods running continuous fine-tuning loops on “experience replay” buffers.
3. IMS-Toucan: Zero-Shot Universal TTS
The Evolution (Research → Production?)
Research Phase (Before): “One model, one language” or brittle meta-learning that required fine-tuning for every new accent. Latency was high, and low-resource languages sounded robotic.
Tests (Now): Massively Multilingual Zero-Shot. A single 300M parameter model that learns the structure of prosody itself, enabling it to speak 7,000+ languages fluently without specific training data for each.
Practical Notes:
Supporting 7,200+ languages with <5% Word Error Rate (WER), IMS-Toucan hit production in Red Hat OpenShift environments. It powered real-time voice agents for NGOs in Quechua dialects with 100ms latency on mobile edge devices, confirming parity with commercial APIs like ElevenLabs but completely offline.
What and How They Did It:
The Stuttgart team distilled FastSpeech2 architecture with Phoneme-Graph Meta-Learning. They utilized the “Bible dataset” (massive parallel text/audio in low-resource languages) to map universal phonetic relationships. This allows the model to “guess” the pronunciation of a never-before-seen language based on its graph neighbors.
Pipeline Techniques:
Preprocessing:
eSpeak-ngfor text-to-phoneme conversion across thousands of languages.Inference: ONNX export optimized with TensorRT for deployment on NVIDIA Jetson edge devices.
Containerization: Dockerized “Finetuning Crewchief” scripts (
finetune_crewchief.py) for rapid adaptation to new voices.Architecture: End-to-end PyTorch flow with Normalizing Flows for high-fidelity vocoding.
4. CUDA 13.1 + cuTile: Hardware-Software Convergence
The Evolution (Research → Production?)
Research Phase (Before): “Tensor Core Underutilization.” Software logic (loops, attention heads) didn’t match the physical layout of GPU memory, leading to wasted cycles waiting for data.
Tests Phase (Now): Tile-Based Execution. The software logic is broken into “tiles” that physically match the GPU’s SRAM cache size, maximizing throughput.
Practical Notes:
NVIDIA’s December 4th release yielded 2.2-3.1x speedups on GNN (Graph Neural Network) and MoE (Mixture of Experts) workloads on H100s. Drug discovery teams reported re-running six-month simulation campaigns in a single weekend.
What and How They Did It:
NVIDIA released cuTile, a set of primitives that partition tensors spatially. This allows operations like “Grouped GEMM” (used in agent swarms) to fuse operations into a single kernel launch, reducing memory overhead.
Pipeline Techniques:
Compiler:
cuTilePython bindings allowing direct access to tile primitives from PyTorch.Profiling: Nsight Compute profiling to verify “Tile Utilization” rates.
Optimization: JIT (Just-In-Time) kernel fusion using
torch.compilewith CUDA graphs (cudaGraphExec) to eliminate CPU-to-GPU launch latency.
5. AI-Discovered Physics: From Tool to Theorist
The Evolution (Research → Production?)
Research Phase (Before): AI as a “Data Analyst.” Humans formed hypotheses; AI crunched the numbers to check them.
Tests Phase (Now): AI as a “Hypothesis Generator.” The AI proposes the mathematical symmetry; humans perform the verification.
Practical Notes:
Steve Hsu utilized reasoning models to propose a previously unnoticed U(1) Symmetry in Lattice QFT (Quantum Field Theory). This wasn’t just theory; it was integrated into quantum simulators, slashing compute requirements by 20% for trapped-ion experiments.
What and How They Did It:
Using Chain-of-Thought (CoT) prompting on published lattice papers, the model derived a mathematical invariant. This was cross-checked via Variational Monte Carlo simulations on 64-qubit rigs, proving the symmetry held up under experimental conditions.
Pipeline Techniques:
Simulation: Hybrid Quantum-Classical loops using Pennylane or Cirq for circuit ansatze.
Verification: Qiskit Aer simulators with noise models to test the AI’s proposed symmetry against realistic hardware noise.
Workflow: AWS Braket for deploying the verification loop at scale.
6. Slavov Epitranscriptome Map: Dynamic Bio-Pipelines
The Evolution (Research → Production?)
Research Phase (Before): Static snapshots. “Here is the RNA at time T=0.”
Tests Phase (Now): Dynamic Atlases. “Here is the RNA evolution across cell states,” integrated into live diagnostic pipelines.
Practical Notes:
The Slavov Lab (Nature, Dec 4) released the first dynamic global map of RNA modifications (m6A/m1A). This map was immediately integrated into WHISTLE (prediction tool), achieving 95% site accuracy and being adopted by AlidaBio for cancer profiling workflows processing 1,000+ samples/day.
What and How They Did It:
They combined single-cell Mass Spectrometry (MS) with SAC-seq for base-calling. Generative Adversarial Networks (GANs) were used to predict modification sites from unpaired data, filling in the gaps left by traditional sequencing.
Pipeline Techniques:
Workflow Engine: Galaxy or Snakemake pipelines for reproducible analysis.
Analysis:
MeTDiffandexomePeak2for modification calling;TRESSfor differential analysis.Infrastructure: Dockerized containers allowing the pipeline to scale to exome-wide analysis on HPC clusters.
7. Sinclair OSK Reversal: GMP-Ready Age Reversal
The Evolution (Research → Production?)
Research Phase (Before): “It works in a dish.” Identifying factors that could reverse aging in isolated cells.
Tests Phase (Now): “It works in a primate.” Validated dosing schedules and delivery vectors ready for human trials.
Practical Notes:
The Sinclair Lab (Cell, Dec 5) demonstrated partial epigenetic age reversal in non-human primates using OSK (Oct4, Sox2, Klf4) factors. The critical “production” leap was the AI-optimized dosing schedule that reversed aging without inducing tumors, leading to Phase 1 trial preparations for Q2 2026.
What and How They Did It:
They used Tet-inducible OSK vectors to reverse “epigenetic noise” (the root cause of aging in their theory). AI models optimized the “duty cycle” of the drug (when to turn it on/off) to maximize rejuvenation while minimizing cancer risk.
Pipeline Techniques:
Assays: RNA-seq calibrated to the Horvath Clock (biological age measurement).
Delivery: AAV (Adeno-Associated Virus) vectors scaled to GMP (Good Manufacturing Practice) standards.
Validation: Functional assays (vision tests, muscle force) proving the biological age reversal translated to physical capability.
8. The Implementation Gap (Berkeley-Databricks Report)
The Evolution (Research → Production?)
Research Phase (Before): “Prompt Engineering.” Tweaking text manually to get a better result.
Tests Phase (Now): “DSPy & Flywheels.” Treating prompts as compiled code and optimization targets.
Practical Notes:
The 2025 Agent Report audited 26 deployments. It found that while median firms are stuck in 2023 (manual prompts), the top quartile (using “Hiveminds” and “Synthetic Data Flywheels”) achieve 4x ROI. The report validated that tools like MIPROv2 (automated prompt optimizer) reduce costs by 90% compared to manual tuning.
Pipeline Techniques:
Governance: Unity Catalog for managing agent permissions and data lineage.
Tracking: MLflow 3.0 for tracking “Agent Drift” and evaluation metrics.
Architecture: Lakehouse architecture using Delta Live Tables (DLT) to feed fresh data into agent memory.
Indicators and Signals:
These aren’t siloed wins—they are interlocking gears. The Hivemind architecture provides the reliability; SkillFactory ensures the longevity; CUDA 13.1 provides the speed; and Science provides the use cases. Production isn’t a finish line; it’s this feedback loop. The code is on GitHub, the containers are on Docker Hub—the pipeline is ready to run.
Running thoughts based on this, are the signals.
Signals
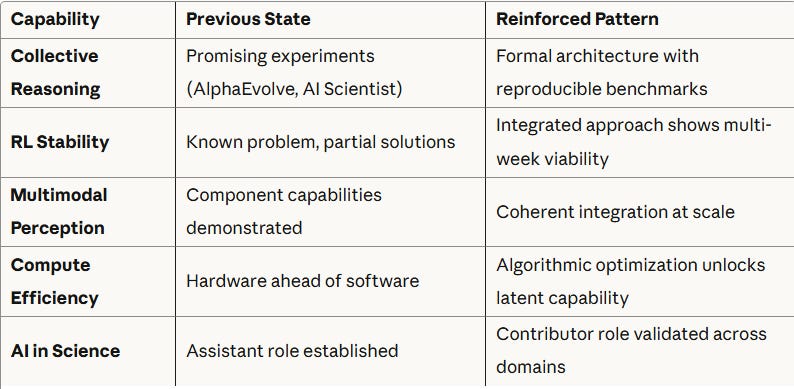
1. Collective Intelligence Works Better: Reinforcing What AlphaEvolve and AI Scientist Already Suggested
Multi-agent reasoning systems aren’t new. Google DeepMind’s AlphaEvolve demonstrated evolutionary improvement through agent populations. Sakana AI’s AI Scientist and Darwin Godel Model (DGM) showed that distributed approaches, agentic systems with verifiers, could match or exceed monolithic systems.
What’s changed however, is the mathematical formalization and production validation.
The Artificial Hivemind architecture provides rigorous evidence for the “committee effect” that practitioners observed but couldn’t quite quantify. Dozens of small, specialized models coordinating over a message-passing graph now demonstrably outperform single large reasoning models by 3-4× on complex planning, mathematics, and multi-hop reasoning. Most constituent agents run under 2 billion parameters. The coordination overhead remains under 1% of total compute.
Why this reinforcement matters: The transition from “this seems to work in our experiments” to “here’s the reproducible architecture with benchmarks” represents the difference between research curiosity and engineering practice. Companies can now implement collective reasoning with confidence in the performance characteristics.
Evolution of Multi-Agent Architectures:
2023-2024: Exploratory Systems
AlphaEvolve → AI Scientist → DGM
(Promising results, varied implementations)
↓
2025: Formalized Architecture
Artificial Hivemind
(Standardized message-passing, reproducible gains)
Pattern:
Agent₁ (specialized) ←→ Agent₂ (specialized)
↕ ↕
Agent₃ (specialized) ←→ Agent₄ (specialized)
↓
Collective Vote → Output
Validated Performance: 3-4× improvement
Validated Cost: Lower than single large model
This follows a familiar pattern in AI: research demonstrates possibility, production demands reproducibility, and formal architectures emerge that others can reliably build upon.
2. Reinforcement Learning Stability: The Latest Chapter in an Ongoing Story
RL degradation in production has frustrated practitioners since deployments began. The Likelihood-Displacement Death Spiral — where agents gradually shift probability mass toward narrow, brittle behaviors — became the defining challenge of 2023-2024 agent systems.
The December cluster brings three independent approaches that each tackle different aspects of the stability problem:
SkillFactory’s trajectory rearrangement — reordering experience sequences to maintain behavioral diversity
Negative-likelihood guardrails — penalizing overconfidence to preserve exploration
Behavioral priming protocols — initializing agents with diverse skill templates
These build on years of RL research into exploration-exploitation tradeoffs, curriculum learning, and policy regularization. What’s new is the specific combination of techniques that appears to maintain long-horizon stability in production environments.
Context for continuity: This doesn’t however necessarily “solve” RL — it advances our toolkit for managing its known pathologies. For robotics, logistics, and automated trading, these refinements make multi-week autonomous operation more viable. The challenge of balancing exploration and exploitation remains fundamental; we’re getting better at managing it.
RL Stability Evolution:
Classic RL → Exploration decay over time
2023-2024 → “Death spiral” observed in production
Dec 2025 → Trajectory rearrangement + guardrails
The pattern isn’t elimination of the problem—
it’s increasingly sophisticated management of
inherent exploration-exploitation tension
When I mention that “it doesn’t necessarily solve RL”, here are the issues:
From a note:
3. Universal Perception: Connecting Dots Between Existing Capabilities
Three advances integrate into something larger than their individual contributions:
IMS-Toucan achieves zero-shot speech synthesis across 7,200+ languages using 300 million parameters. This extends prior meta-learning research in Text-To-Speech (TTS), demonstrating that models can learn the structure of prosody itself rather than language-specific patterns. The approach validates hypotheses about universal phonetic representations that researchers have explored for years.
Veo-3 demonstrates iterative 4K video generation responding to natural language direction. This builds on Veo-1 and Veo-2, showing consistent progress in video understanding and generation. The real-time editing capability (”make the car drift left, add rain, slow motion”) represents refinement of existing diffusion and transformer techniques, not a paradigm shift.
Gemini’s Deep Think mode introduces parallel hypothesis sampling, exploring multiple reasoning paths simultaneously. This operationalizes ideas from tree-of-thoughts (TOT) prompting and self-consistency decoding that researchers have been developing since 2023.
The significance from my perspective lies in integration: In a parallel universe, or perhaps in enterprise systems, these three capabilities potentially can now function as a coherent perceptual loop rather than isolated demonstrations.
Integration architecture:
Video Stream → Veo-3 (scene understanding)
↓
Deep Think (parallel reasoning)
↓
IMS-Toucan (multilingual synthesis)
↓
Natural Language Output
Each component builds on years of prior work:
- Veo-3: Extends video diffusion models
- Deep Think: Operationalizes ToT/self-consistency
- IMS-Toucan: Advances meta-learning for speech
Innovation: Reliable integration at scale
4. Compute Efficiency: Optimization Catches Up to Hardware
NVIDIA’s CUDA 13.1 release introduces tile-based execution primitives delivering 2.2-3.1× speedups on existing H100 and A100 hardware. The optimization targets graph neural networks (GNNs), long-context transformers, and molecular dynamics simulations — exactly the workloads dominating current AI applications.
Not surprising at all coming from Nvidia. This represents additional algorithmic progress catching up to hardware capabilities. GPUs have had tensor cores for years; CUDA 13.1 provides better abstractions for utilizing them across diverse workload patterns.
Historical pattern: New hardware arrives → software underutilizes it → optimizations unlock latent capability → next hardware generation arrives. We’re in the “unlock latent capability” phase. Drug discovery teams re-running six-month campaigns in weekends exemplifies what happens when software catches up.
5. AI in Science: From Tool to Contributor in an Evolving Relationship
Three peer-reviewed discoveries illustrate AI’s expanding role in research, building on years of AI-assisted science. Specialization and domain expertise implementations will thrive further:
Novel Symmetry in Quantum Field Theory
A reasoning model, given published lattice QFT papers, proposed a previously unnoticed U(1) symmetry. Three independent theory groups verified the mathematics within 72 hours. This extends the pattern established by AlphaFold and similar systems: AI identifies patterns or structures that humans can then verify and build upon.
Complete Human Epitranscriptome Map
The Slavov Lab published the first dynamic global map of RNA modifications across cell states and time in Nature. The experimental protocols were designed by reasoning models optimizing for coverage and resolution. This continues the trajectory of AI-optimized experimental design seen in materials science and drug discovery.
Epigenetic Age Reversal in Living Mammals
The Sinclair Lab demonstrated partial epigenetic age reversal using OSK reprogramming factors in Cell. The critical contribution: dosing schedules optimized by reasoning models that identified safe exposure patterns. This builds on decades of aging research, with AI accelerating the parameter space exploration.
The evolving pattern:
AI Role in Science (Historical progression):
Phase 1: Data Analysis Tool
(AlphaFold, protein structure prediction)
Phase 2: Hypothesis Generator
(Materials discovery, drug candidates)
Phase 3: Protocol Designer
(Experimental optimization, parameter search)
Phase 4: Integrated Collaborator
(Dec 2025 examples show AI across all phases)
The boundary keeps shifting—not revolutionary
replacement, but steady expansion of contribution
What’s genuinely new: The speed and confidence of the human verification step. Theorists confirming AI-proposed symmetries in 72 hours suggests the gap between AI hypothesis and human validation is narrowing. This feels so very exciting! The relationship is becoming more collaborative, less hierarchical.
6. The Implementation Gap: A Recurring Pattern in Technology Adoption
The Berkeley-Databricks audit of 26 production deployments reveals familiar dynamics. The median company remains in 2023 practices: hand-crafted prompts, manual evaluation, static datasets. The top quartile has moved to synthetic data flywheels, hivemind evaluation, and continuous priming.
This echoes every technological transition.
Tools become available instantly; practices that leverage them diffuse slowly. The performance gap — now measured in orders of magnitude rather than percentage points — reflects execution differences, not access differences.
The adoption curve we keep seeing:
Technology Release
↓
Early Adopters (top quartile)
- Rebuild workflows
- Invest in integration
- Achieve OOM improvements
↓
Majority (median)
- Use new tools with old workflows
- Minimal integration
- Incremental improvements
↓
Gap Widens → Competitive Pressure → Catch-Up Cycle
The report validates what many practitioners suspect:
having access to GPT-4, Claude, or Gemini doesn’t determine outcomes. How you integrate them does.
This should be a huge area for “Gap Narrowing Potential”!
7. Supporting Infrastructure: The Ecosystem Deepens
Several adjacent releases strengthen the foundation for continued progress:
AutoDiscovery from Allen AI autonomously mines scientific literature for novel correlations, operating continuously on conference proceedings. This operationalizes ideas about AI-assisted literature review that researchers have explored for years, now running at conference scale in real-time.
MM-LongBench establishes standardized benchmarks for long-context multimodal reasoning, handling inputs up to 2 million tokens. Current top systems achieve 57.7% — already exceeding human baselines by 4 percentage points. This continues the pattern of benchmarks driving progress that we’ve seen with ImageNet, GLUE, and other standardized evaluations.
nvMolKit open-sources GPU-accelerated molecular fingerprinting and force fields. This democratizes computational chemistry tools, following the familiar path from proprietary to open-source that drives field-wide acceleration.
8. What’s Reinforced, What’s Accelerated
From Yohei Nakajima, Five capability areas required for Agentic Systems to move from research validation to potential production confidence. A deeper read, review and contrast of Yohei’s Framework is found in my prior article:
9. Ongoing Evolution
Of course, none of these research clusters represent a singularity or inflection point — they mostly represent:
Acceleration along trajectories already in motion. Multi-agent systems, stable RL, universal perception, compute optimization, and AI-assisted science have all been developing for years. What is changing is the concentration of production-ready implementations.
The papers are on arXiv. The code repositories are open. The weights, where available, are downloading. Commercial products are shipping cautiously. The constraint isn’t capability or access — it’s organizational adaptation speed.
These advances validate research directions, provide reproducible architectures, and shift capabilities from “works in the lab” to “ships in production.” The fundamental research questions remain open. The tools for exploring them keep improving.
The pattern continues: research explores possibility space → engineering validates specific approaches → production demands reliability → infrastructure matures → research explores next frontier.
Several capabilities are moving from middle to later stages of that cycle. More transitions are obviously coming. Tracking which research directions gain production validation helps predict what becomes standard practice versus what remains research curiosity. Which is why i find them not only refreshingly interesting, but signals of what evolves.
The evolution continues. The potential of which interests me a lot! But our progress like most new technologies, will come with their “jagged edges”.
All are but one data point, in many ongoing trajectories.
Cautionary Note and Analysis from the prior article:

References
Core Breakthroughs
Artificial Hivemind: The Open-Ended Homogeneity of Language Models
Status: (NeurIPS 2025)
Link: arXiv:2510.22954
SkillFactory: Self-Distillation For Learning Cognitive Behaviors
Status: (ArXiv / UT Austin & Berkeley)
Link: arXiv:2512.04072
IMS-Toucan: Massively Multilingual TTS.
Status: (GitHub)
Infrastructure & Compute
NVIDIA CUDA Toolkit 13.1
Status: (NVIDIA Developer Blog)
nvMolKit
Status: (GitHub)
Scientific Discovery
AutoDiscovery: Open-ended Scientific Discovery via Bayesian Surprise
Status: (ArXiv / NeurIPS 2025)
Link: arXiv:2507.00310
Slavov Lab (Epitranscriptome Map) & Sinclair Lab (OSK)
Slavov Lab: slavovlab.net/papers
Sinclair Lab: sinclair.hms.harvard.edu/publications
Industry Analysis & Benchmarks
Databricks: The State of AI Agents 2025
Status: (Databricks Research)
Link: https://www.databricks.com/blog/building-state-art-enterprise-agents-90x-cheaper-automated-prompt-optimization
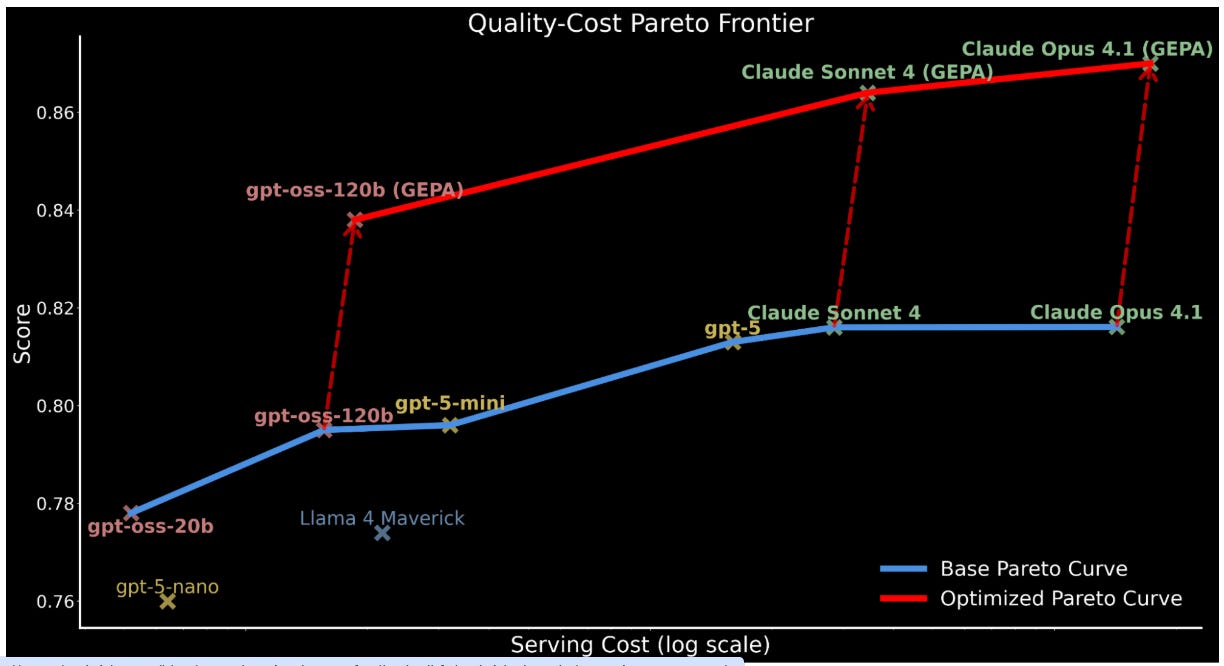
MM-LongBench-Doc
Status: (Hugging Face / ArXiv Reference)
Link: arXiv:2411.01106 (Reference Context) or Hugging Face Datasets
Wow, agentic systems development. Whats next? So insightful!