
DeepMind's AlphaGo to AlphaEvolve: The Thinking Game & The Alpha Models Redesigning Their Own World - Tabula Rasa To Recursive AI
Thinking About Thinking: The groundbreaking shift from an AI that learns to play games to one that invents new algorithms and optimizes the very systems that power it


1. The AlphaGo Legacy
Let me start with the obvious - I believe AGI/ASI is entirely possible and probable. Google DeepMind is why.
I've always been impressed with DeepMind, especially in the years leading up to its acquisition by Google. While Demis Hassabis's leadership and accomplishments are rightly celebrated, my focus has always been on the incredible work of the entire team. It's been fascinating to watch the evolution of their models, beginning with AlphaGo and its famous "Move 37," which demonstrated a creativity that transcended human intuition.
From there, the team's innovations have grown exponentially, with AlphaGo Zero revolutionizing self-play and learning from scratch, and AlphaZero generalizing that mastery across multiple games. This foundational work laid the groundwork for tackling real-world problems. And there have been very many.
We've seen their techniques, which have consistently evolved from reinforcement learning and deep neural networks, lead to breakthroughs like AlphaFold, which revolutionized protein structure prediction, and AlphaTensor, which discovered more efficient algorithms for matrix multiplication, leading to real-world optimizations for GPUs and TPUs.
This journey, culminating in the recent impressive algorithmic discovery of AlphaEvolve (which I have covered in several recent articles (yes, I was that optimistic and excited about it!!) - (1) From Overthinking To Evolution; (2) The Self Forging Mind; (3) AlphaEvolve The AI Self That Upgrades Itself; for RL (4) Pac-Man and The Ghost In The Machine; and for World Models Genie 3 (5) When AI Begins To Dream), truly showcase how the core principles developed in a game environment can be generalized to solve some of the most complex scientific and engineering challenges facing us today. There have been other recent releases like AlphaEarth and especially World Model Genie 3 (which I will not cover here, and will discuss when officially released). This journey continues and is impressive.
Most importantly, how technologies and discoveries build on each other. Reinforcement Learning (RL) has deep roots, and it has travelled a very long journey to what we witness today in AI models (of course, many other things like data chomping GPUs, memory advancements, various fine-tuning techniques etc are giving us better results and output, so it is never only one thing).
But still, I am not surprised by the orchestration and “agentic” characteristics being added, nor by the evolution of pattern learning to “reasoning” we see in chat models today.
Google DeepMind exemplifies “Reinforcement Learning”++ evolving with their various Alpha Models, and the parallel evolutions human beings are threading, in their own (thinking + jagged-edged discoveries), with all the various versions of AI Models.
2. Foundational Reinforcement Learning (RL) Models
The initial breakthroughs of the Alpha series in reinforcement learning, particularly in game environments, laid the groundwork for subsequent innovations across diverse domains. These models collectively established a powerful paradigm for AI development centered on self-improvement through extensive interaction with an environment.
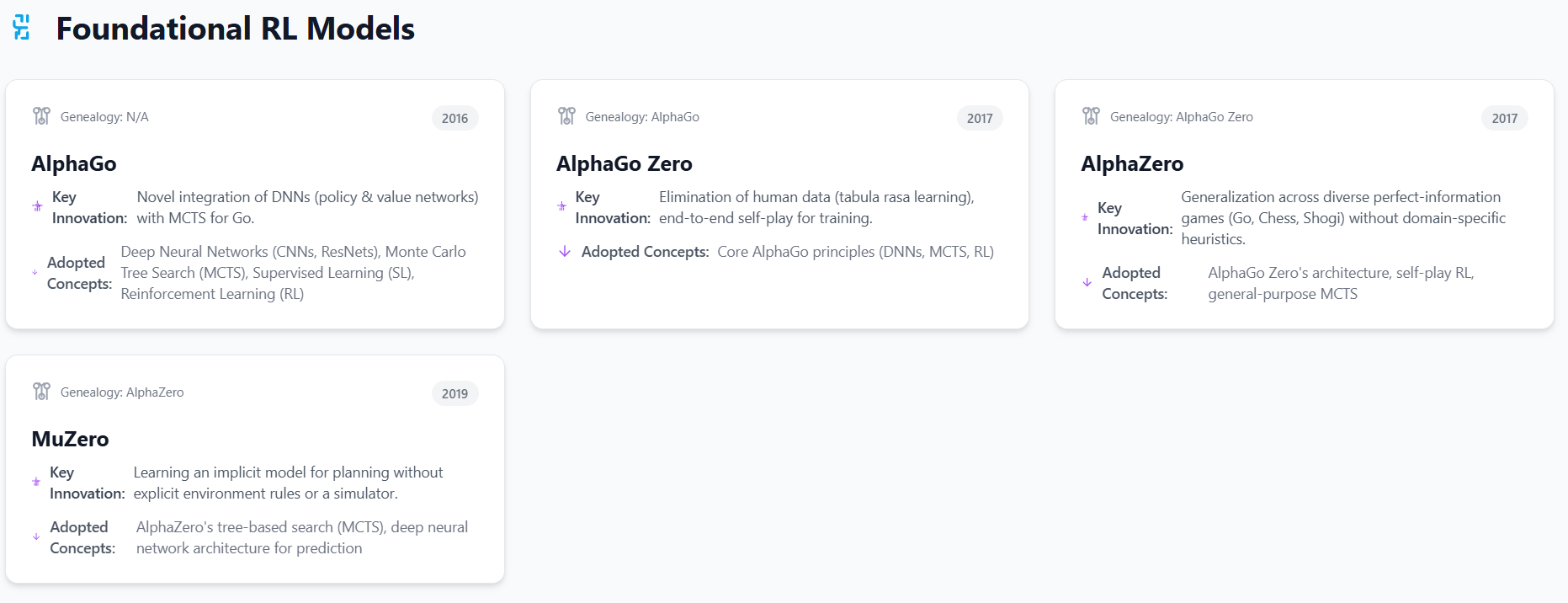
2.1. AlphaGo: The Pioneer of Game AI
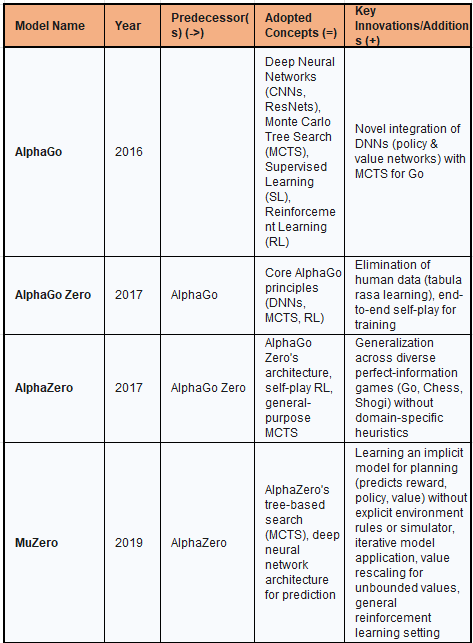
AlphaGo marked a significant milestone by being the first computer Go program to defeat a human professional Go player without handicaps on a full-sized 19x19 board. This achievement was particularly notable given Go's immense complexity, with an estimated number of possible board positions exceeding 2.1 × 10^170, making it far more challenging for AI than games like chess due to its vast search space.
AlphaGo adopted several established concepts from the field of artificial intelligence. It leveraged Deep Neural Networks (DNNs), specifically employing convolutional neural networks (CNNs) and residual networks (ResNets), to process the visual representation of board positions. CNNs are well-suited for image and pattern recognition tasks, while ResNets facilitate the training of very deep networks (by this I mean layers of the network) by addressing vanishing gradient problems. The system also incorporated Monte Carlo Tree Search (MCTS), a heuristic search algorithm designed to explore large game trees efficiently by combining random sampling with tree traversal. Its training process involved an initial phase of Supervised Learning (SL), where the policy network was trained on a large dataset of human expert Go games to mimic professional moves.
Following this, Reinforcement Learning (RL) was used, allowing AlphaGo to refine its strategies through self-play, learning from trial and error against itself.
The primary innovation introduced by AlphaGo was the novel integration of these DNNs with MCTS. The deep policy network guided the MCTS by suggesting promising moves, effectively narrowing down the vast search space, while the deep value network evaluated the quality of board positions, allowing MCTS to prune less favorable branches. This synergistic combination enabled AlphaGo to balance exploration of new strategies with exploitation of known good moves.
The triumph over Lee Sedol was a major upset, occurring approximately a decade earlier than anticipated by Go experts, underscoring the unexpected efficacy of this hybrid approach. This success demonstrated the powerful synergy of combining deep learning's pattern recognition capabilities with traditional tree search algorithms. The ability of this hybrid system to navigate an astronomically large state space more effectively than either component alone established a significant precedent for tackling future complex combinatorial problems in AI.
2.2. AlphaGo Zero: Self-Play Revolution
AlphaGo Zero dramatically refined its predecessor's approach by eliminating the dependency on human gameplay data, learning tabula rasa (from a blank slate) solely through self-play. This marked a profound step towards more general and autonomous AI systems, unconstrained by the biases or limitations inherent in human-generated data. Remember, this was circa 2017.
AlphaGo Zero adopted the core principles of AlphaGo, retaining the fundamental architecture of deep neural networks (policy and value networks) and the Monte Carlo Tree Search (MCTS) algorithm. The underlying neural network architecture, identical to that later used in AlphaZero, featured pairs of rectified batch-normalized convolutional layers with skip connections, which are crucial for stable and efficient training of deep models.
The most profound innovation introduced by AlphaGo Zero was the complete elimination of human data, guidance, or domain knowledge beyond the basic rules of Go. This tabula rasa approach allowed the AI to discover novel strategies unconstrained by human biases. The system continuously improved through end-to-end self-play, where the neural network learned to predict its own move selections and game outcomes, creating a self-reinforcing loop that led to rapid and superior performance. This approach enabled AlphaGo Zero to achieve superhuman performance, famously winning 100-0 against the original AlphaGo, a clear indication of its superior strategic depth. This outcome underscored that human expertise, while valuable for initial training, can also impose a "ceiling" on AI performance. By learning from scratch through self-play, the AI could explore the entire solution space and discover strategies that human players might never conceive, as exemplified by AlphaGo's "Move 37," which surprised human experts. This paradigm shift from learning from humans to learning beyond humans became a foundational philosophy for subsequent Alpha models.
2.3. AlphaZero: Generalizing Game Mastery
AlphaZero generalized the self-play reinforcement learning approach pioneered by AlphaGo Zero, mastering multiple perfect-information games—Go, Chess, and Shogi—without any domain-specific adjustments or human heuristics. This achievement demonstrated a significant stride towards a more general artificial intelligence capable of adapting to diverse rule-based environments.
AlphaZero explicitly adopted AlphaGo Zero's architecture and its self-play RL approach. The neural network architecture remained identical, featuring rectified batch-normalized convolutional layers with skip connections, which aid in increasing training speed and preventing issues like exploding gradients. It continued to employ a general-purpose Monte Carlo Tree Search (MCTS) algorithm, which evaluates positions non-linearly using deep neural networks and averages over position evaluations within a subtree to mitigate neural network errors. The training process relied entirely on self-play, starting from random moves and provided only with the game rules, allowing the system to learn optimal strategies independently.
The primary innovation of AlphaZero was its generalization across diverse games. It applied a single algorithm, without modification or handcrafted features, to achieve superhuman performance across structurally different games like Chess, Shogi, and Go. This demonstrated that the underlying RL framework and neural network architecture were robust enough to learn optimal strategies for a variety of complex, deterministic environments. Unlike previous game-playing programs that relied heavily on human-designed heuristics and domain-specific knowledge, AlphaZero operated solely on game rules, simulating all possible moves to learn optimal strategies. AlphaZero reliably won games against top human players and previous chess engines, showcasing its superior strategic capabilities. This success in generalizing across multiple complex games without game-specific modifications was a critical step towards the development of more general AI systems. The demonstration that foundational RL techniques, when combined with powerful neural networks and self-play, could learn optimal strategies for diverse, complex environments, moved the focus beyond single-task mastery. This laid the conceptual groundwork for applying similar principles to non-game domains, suggesting that the learned principles were not game-specific but rather fundamental strategies for sequential decision-making.
2.4. MuZero: Model-Based Learning Without Rules
MuZero further extended the advancements of AlphaZero by learning the underlying dynamics of game environments without explicit knowledge of their rules, making it adaptable across various games, including complex Atari games. This represented a significant leap towards tackling real-world problems where explicit rules or perfect simulators are unavailable.
MuZero adopted AlphaZero's tree-based search (MCTS), generalizing it to handle single-agent domains and intermediate rewards, a common characteristic of many real-world problems. The prediction function within MuZero's architecture also utilized the same neural network structure as AlphaZero.
MuZero's core innovation lies in its ability to learn an implicit model for planning. Instead of requiring a perfect simulator or explicit environment rules, MuZero learns a model that predicts only the quantities directly relevant to planning: the immediate reward, the action-selection policy, and the value function. This is achieved through three interconnected neural network components: a representation function that transforms observations into a hidden state, a dynamics function that predicts the next hidden state and immediate reward given an action, and a prediction function that outputs policy and value from the hidden state. The learned model is applied iteratively, updating a hidden state recurrently to predict future quantities. The entire system, encompassing representation, dynamics, and prediction functions, is trained end-to-end to accurately estimate policy, value, and reward. For environments with unbounded values, unlike the bounded values in board games, MuZero introduced value rescaling, which normalizes values to the maximum observed value, eliminating the need for environment-specific data for value estimation. MuZero was specifically designed for a more general RL setting, supporting single-agent domains and discounted intermediate rewards, which contrasts with AlphaZero's primary focus on two-player games with terminal rewards.
MuZero achieved state-of-the-art performance in 46 out of 60 Atari games and matched AlphaZero's superhuman performance in Go, Chess, and Shogi without needing to know their specific rules. This ability to learn and plan in environments without explicit rules or simulators is a profound step towards applying AI to real-world problems where dynamics are complex, noisy, or partially observable, such as robotics or industrial control. This progression moves AI from deterministic, rule-bound systems to adaptive, model-learning agents, significantly expanding the scope of solvable problems.
The application of MuZero to optimize YouTube video compression, known as MuZero Rate-Controller (MuZero-RC), further exemplifies its utility in complex, real-world, non-game domains.
Table: Foundational RL Models Genealogy & Core Innovations
3. Protein Structure Prediction & Design Models
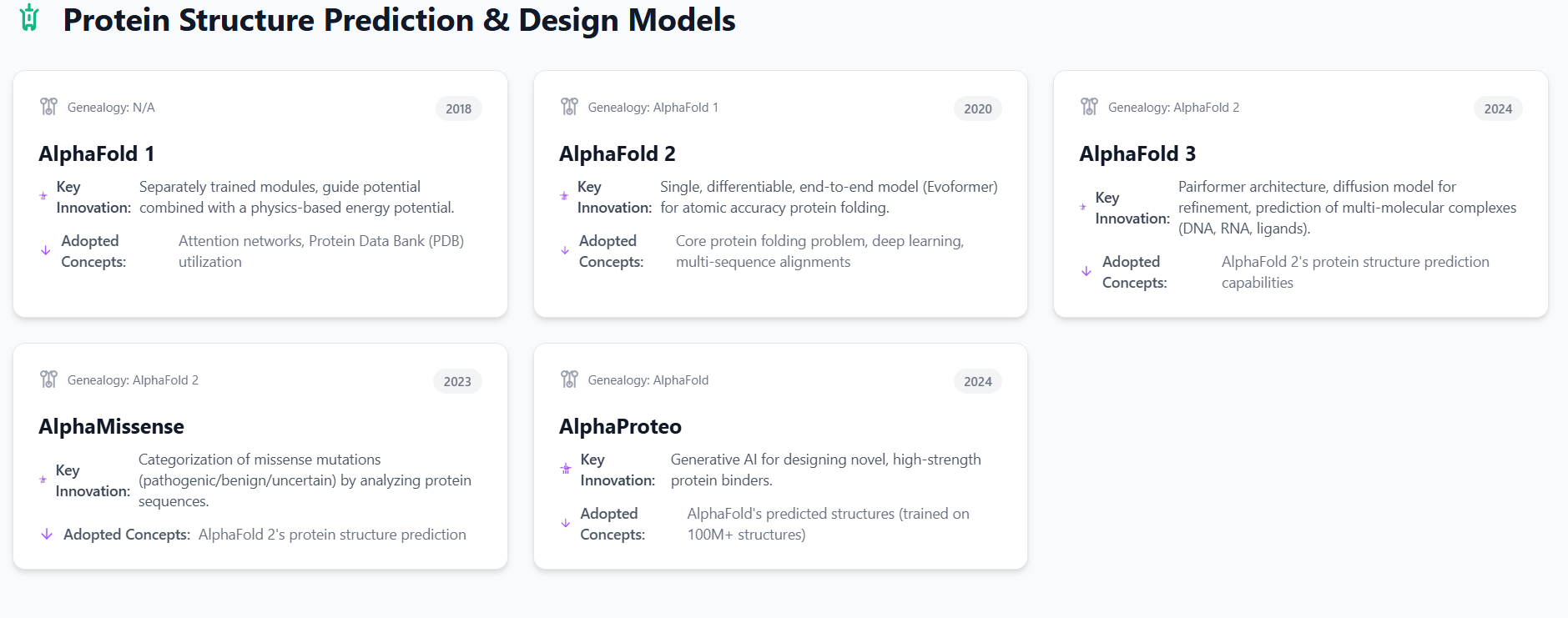
Following the successes in game theory, DeepMind extended its AI methodologies to the complex domain of molecular biology, specifically protein structure prediction and design. This expansion leverages advanced neural architectures to tackle problems fundamental to drug discovery and biological understanding.
3.1. AlphaFold 1: Initial Protein Folding Breakthrough
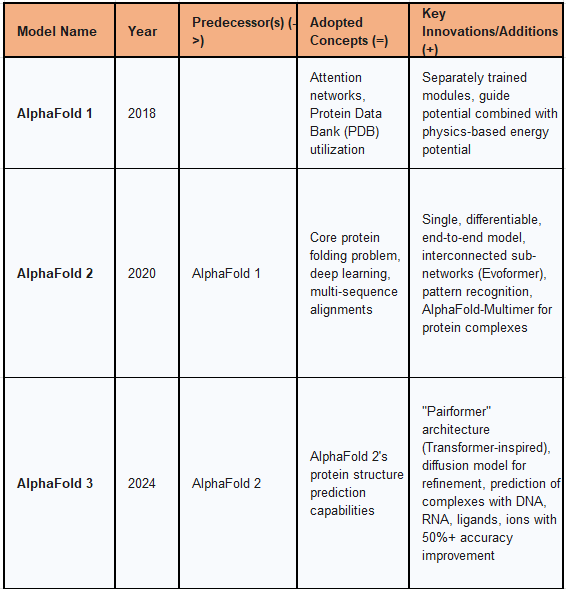
AlphaFold 1, released in 2018, represented DeepMind's initial foray into the critical problem of protein structure prediction, a challenge that had persisted for over 50 years. Predicting the three-dimensional structure of a protein from its amino acid sequence is crucial for understanding its biological function and role in diseases.
AlphaFold 1 was built upon prior work developed by various teams in the 2010s, which focused on analyzing large databanks of related DNA sequences to find correlated changes in residues. The program utilized a form of attention network, a deep learning technique that allows the AI to focus on specific parts of a larger problem and piece them together for an overall solution. It also relied on the vast repositories of protein data, such as the Protein Data Bank (PDB), for training.
The model's architecture involved a number of separately trained modules designed to produce a "guide potential," which was then combined with a physics-based energy potential to predict protein structures. This modular approach allowed for the integration of different computational methods to refine predictions. AlphaFold 1 demonstrated a significant step forward, showing that deep learning could contribute meaningfully to this long-standing biological problem.
3.2. AlphaFold 2: End-to-End Protein Structure Prediction
AlphaFold 2, unveiled in 2020, dramatically advanced the field of protein structure prediction, achieving accuracy competitive with experimental methods and being recognized as the best-performing method in the 14th Critical Assessment of protein Structure Prediction (CASP14). This model effectively replaced the initial AlphaFold 1 architecture.
AlphaFold 2 adopted the core problem of protein folding from AlphaFold 1 and continued to utilize deep learning techniques for its predictions. It was trained on over 170,000 proteins from the Protein Data Bank and leveraged multi-sequence alignments (MSA) to infer structural relationships.
The key innovation in AlphaFold 2 was its transition to a single, differentiable, end-to-end model based on pattern recognition, replacing AlphaFold 1's system of separately trained modules. Its architecture featured interconnected sub-networks, notably the "Evoformer" blocks, which consist of attention-based layers that iteratively refine both the MSA and a 2-D pair representation of amino acid relationships. A "Structure Module" then mapped these refined representations to 3D coordinates, effectively performing the actual folding. The Evoformer's ability to constantly communicate between MSA and pair representation towers was crucial for ensuring consistency and integrating both evolutionary and geometric information. The model also included an update in October 2021, named AlphaFold-Multimer, which expanded its training data to include protein complexes, enabling it to predict protein-protein interactions with approximately 70% accuracy. AlphaFold 2's ability to predict protein structures with atomic accuracy, even when no homologous structure was known, represented a major step-change for molecular biology. The AlphaFold Protein Structure Database (AlphaFold DB), a collaborative project with EMBL-EBI, provides open access to over 200 million protein structure predictions, dramatically accelerating scientific research by making high-quality 3D models readily available for almost every known protein sequence. While highly effective for predicting proteins in their "native" (folded) state, AlphaFold 2 exhibited limitations in predicting non-native protein structures, which are often critical for understanding drug binding mechanisms.
Noteworthy of course, that in October 2024 that both Demis Hassabis and John Jumper were awarded the Nobel Prize for Chemistry for their work developing AlphaFold.
3.3. AlphaFold 3: Multi-Molecular Complex Prediction
Announced in May 2024, AlphaFold 3 represents the latest evolution in DeepMind's protein prediction capabilities, co-developed with Isomorphic Labs. This iteration expands the scope of prediction beyond individual proteins to encompass complex biological assemblies.
AlphaFold 3 adopted the foundational protein structure prediction capabilities of AlphaFold 2, building upon its success in accurately modeling single proteins.
A significant architectural innovation in AlphaFold 3 is the introduction of the "Pairformer," a deep learning architecture inspired by the Transformer, which is described as similar to but simpler than AlphaFold 2's Evoformer. The initial predictions from the Pairformer module are then refined by a diffusion model. This diffusion model begins with a cloud of atoms and iteratively refines their positions, guided by the Pairformer's output, to generate a 3D representation of the molecular structure. This new approach enables AlphaFold 3 to predict the structures of complexes created by proteins with DNA, RNA, various ligands, and ions, moving beyond the single-chain protein focus of its predecessors. The new method shows a minimum 50% improvement in accuracy for protein interactions with other molecules compared to existing methods. This expansion into multi-molecular complex prediction is crucial for understanding intricate biological processes and is expected to significantly accelerate advanced drug design by providing more comprehensive structural insights.
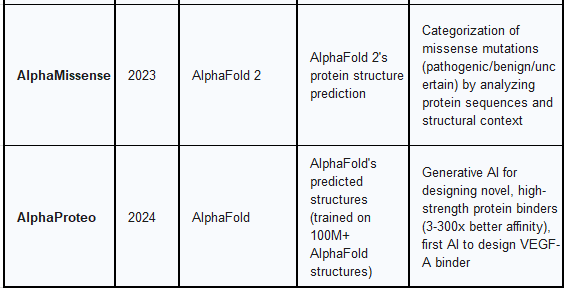
3.4. AlphaMissense: Genetic Variant Classification
AlphaMissense is an AI model developed by Google DeepMind in 2023, designed to classify the pathogenicity of missense mutations. It represents a direct application and extension of DeepMind's expertise in protein structure prediction to a critical problem in human genetics.
AlphaMissense explicitly builds on the AlphaFold 2 AI system. Its implementation involved forking the AlphaFold repository and modifying it for the specific task of missense variant prediction. It leverages AlphaFold 2's ability to predict structures for nearly all known proteins from their amino acid sequences.
The primary innovation of AlphaMissense is its capacity to categorize 'missense' mutations in different proteins as either 'likely pathogenic', 'likely benign', or 'uncertain', by producing a score that estimates the likelihood of a variant being pathogenic. The model analyzes related protein sequences and the structural context of variants to make these estimations. AlphaMissense predictions have been integrated into several EMBL-EBI resources, including Ensembl, UniProt, and the AlphaFold Database, making these AI-generated scores easily accessible to researchers. This integration allows for overlaying AlphaMissense predictions onto AlphaFold structures, providing additional context for understanding protein function and highlighting potential binding interfaces. This capability directly aids in improving patient diagnosis and developing better treatments by linking specific genetic variants to disease.
3.5. AlphaProteo: Novel Protein Design
AlphaProteo represents a significant advancement in generative AI for molecular biology, focusing on the design of novel proteins rather than just the prediction of their structures. This system aims to accelerate the creation of new biological tools and therapeutics.
AlphaProteo is heavily reliant on AlphaFold's predicted structures, having been trained on large amounts of protein data from the Protein Data Bank (PDB) and more than 100 million predicted structures from AlphaFold. This extensive training allowed AlphaProteo to learn the myriad ways molecules bind to each other, building on the structural understanding provided by AlphaFold.
The key innovation of AlphaProteo is its ability to generate novel, high-strength protein binders. Given the structure of a target molecule and preferred binding locations, AlphaProteo generates candidate proteins designed to bind to those targets. The system has achieved experimental success rates and binding affinities 3 to 300 times better than the best prior methods on several target proteins. Notably, it was the first AI tool to successfully design a protein binder for VEGF-A, a molecule associated with cancer and diabetes complications. This capability has broad applications, including accelerating drug development, cell and tissue imaging, disease understanding, and even crop resistance to pests. AlphaProteo's performance indicates its potential to drastically reduce the time needed for initial experiments involving protein binders, thereby speeding up the drug discovery process.
Table: Protein Structure & Design Models Genealogy & Core Innovations
4. Algorithmic & Mathematical Discovery Models
DeepMind's "Alpha" series has extended its self-play and reinforcement learning methodologies to abstract domains like mathematics and computer science, demonstrating AI's capacity for discovering novel algorithms and solving complex problems at a superhuman level. This progression marks a shift from optimizing existing solutions to autonomously generating new ones.
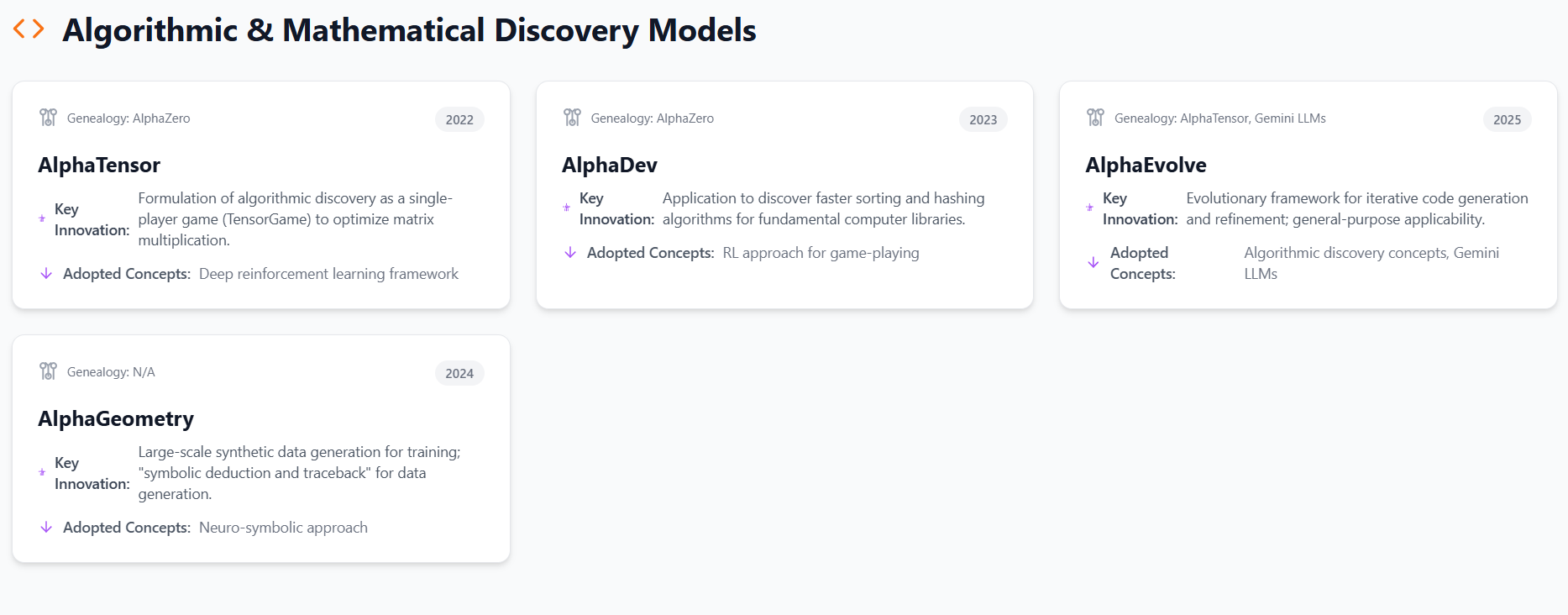
4.1. AlphaTensor: Matrix Multiplication Optimization
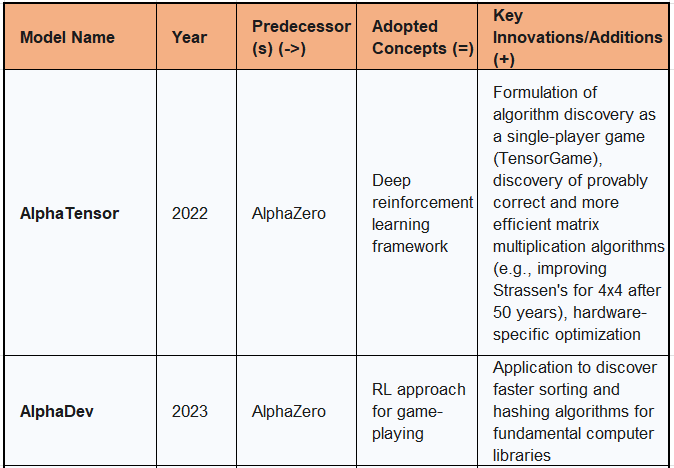
AlphaTensor, introduced in 2022, represents a groundbreaking application of reinforcement learning to the fundamental problem of discovering novel, efficient, and provably correct algorithms for matrix multiplication. Matrix multiplication is a core component in numerous computational tasks, from computer graphics to neural network training, making any efficiency gain highly impactful.
AlphaTensor explicitly builds upon the AlphaZero deep reinforcement learning framework. It leverages the self-play and tree-search mechanisms established in AlphaZero, adapting them to a new problem domain.
The central innovation of AlphaTensor is its formulation of the algorithm discovery problem as a single-player game, termed TensorGame. The objective within this game is to find tensor decompositions that correspond to efficient matrix multiplication algorithms. Through this game-playing approach, AlphaTensor discovered algorithms that outperform the state-of-the-art complexity for many matrix sizes. A particularly notable achievement was its improvement upon Strassen's two-level algorithm for 4x4 matrices in a finite field, the first such improvement in 50 years. Furthermore, AlphaTensor demonstrated flexibility by optimizing matrix multiplication for runtime on specific hardware, such as Nvidia V100 GPUs and Google TPU v2, achieving 10-20% faster multiplication for large matrices on these platforms. This capability to optimize for arbitrary objectives, including energy usage and numerical stability, highlights the system's adaptability. The ability to discover algorithms that surpass human-designed ones is a major step forward in the field of algorithmic discovery, showing that AI can generate original mathematical and computational knowledge.
4.2. AlphaDev: Algorithm Discovery for Core Computing
AlphaDev represents an advancement in DeepMind's algorithmic discovery efforts, specifically targeting the optimization of fundamental computer algorithms that underpin vast digital operations.
AlphaDev functions as an advancement of AlphaZero, applying its core reinforcement learning approach for game-playing to a new domain: finding the most rapid algorithms. This signifies a continuation of the strategy to adapt successful game-playing AI to real-world computational challenges.
The key innovation of AlphaDev is its ability to discover faster sorting and hashing algorithms. These are critical operations invoked trillions of times daily across various computing systems. By formulating the search for optimal algorithms as a unique single-player game, AlphaDev succeeded in revealing several compact sorting algorithms that surpassed those designed by humans. These discoveries have been assimilated over the previous year into one of the quintessential computer libraries, facilitating its daily use by millions of enterprises, developers, and users globally. This demonstrates the direct practical impact of AI in optimizing core computational infrastructure, leading to widespread efficiency gains.
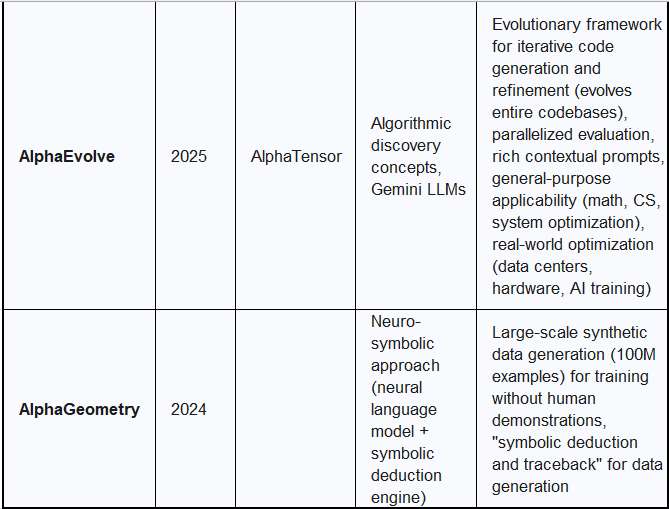
4.3. AlphaEvolve: General Algorithmic Discovery Agent
AlphaEvolve, unveiled in mid-2025, is a bleeding-edge AI agent designed to discover and optimize algorithms through a novel fusion of large language models (LLMs) and evolutionary computation. It represents a significant step beyond previous algorithmic discovery systems, capable of evolving entire codebases.
AlphaEvolve adopts concepts from AlphaTensor, particularly the framework of algorithmic discovery as an optimization problem. It also leverages the capabilities of Gemini LLMs (specifically Gemini 2.0 Flash and Gemini 2.0 Pro) for code generation and understanding complex problem specifications. I believe these were subsequently updated to the Gemini 2.5 Flash and Gemini 2.5 Pro versions.
The core innovation of AlphaEvolve is its evolutionary framework, which iteratively generates, evaluates, and refines algorithms through processes inspired by natural selection, such as mutation, selection, and crossover. Unlike earlier systems like FunSearch, which evolved single Python functions, AlphaEvolve can evolve entire code files, supporting hundreds of lines of code in any programming language. It employs parallelized evaluation to efficiently assess solutions, spending approximately 100 compute-hours per solution. The system uses rich contextual prompts, enriched with past trials, evaluation results, and LLM-generated feedback, to guide the evolution process and improve solution quality. AlphaEvolve's general-purpose applicability allows it to tackle problems across multiple domains, including mathematics, computer science, and system optimization, provided solutions are "machine-gradeable".
AlphaEvolve has demonstrated significant practical impact by optimizing Google's computing ecosystem, including data centers, hardware, and software. It discovered a scheduling heuristic for Google's Borg cluster manager that continuously recovers, on average, 0.7% of Google's worldwide compute resources. In hardware design, it proposed a Verilog rewrite for a highly optimized arithmetic circuit in a Tensor Processing Unit (TPU), which was integrated into an upcoming TPU model.
Beyond that, AlphaEvolve accelerated AI training and inference by finding smarter ways to divide large matrix multiplication operations, speeding up a vital kernel in Gemini's architecture by 23% and reducing Gemini's training time by 1%. It also achieved up to a 32.5% speedup for the FlashAttention kernel implementation in Transformer-based AI models.
In pure mathematics, AlphaEvolve found an algorithm to multiply 4x4 complex-valued matrices using 48 scalar multiplications, improving upon Strassen's 1969 algorithm, and established a new lower bound for the kissing number problem in 11 dimensions. This represents a significant advance over AlphaTensor, which specialized in matrix multiplication but only found improvements for binary arithmetic in 4x4 matrices. The ability of AI to contribute original insights in pure mathematics and optimize real-world infrastructure highlights a new era of AI-driven scientific and engineering discovery.
4.4. AlphaGeometry: Olympiad-Level Geometry Problem Solving
AlphaGeometry, introduced in 2024, is an AI system that solves complex geometry problems at a level approaching a human Olympiad gold-medalist. This achievement represents a breakthrough in AI's ability to reason logically and discover new mathematical knowledge.
AlphaGeometry adopts a neuro-symbolic approach, combining the predictive power of a neural language model + a rule-bound symbolic deduction engine. This hybrid architecture aims to leverage the strengths of both paradigms: the neural network provides intuitive guesses about potentially useful constructs, while the symbolic engine rigorously reasons using formal logic to derive a solution.
The primary innovation of AlphaGeometry is its method for generating a vast pool of synthetic training data, consisting of 100 million unique examples, which allows the system to be trained without any human demonstrations, sidestepping the data bottleneck often encountered in complex mathematical domains. This synthetic data generation process, termed "symbolic deduction and traceback," involves generating billions of random geometric diagrams, exhaustively deriving all relationships, finding proofs, and then working backward to identify necessary auxiliary constructs. This approach enables AlphaGeometry's language model to make effective suggestions for new constructs when faced with Olympiad problems.
AlphaGeometry solved 25 out of 30 Olympiad geometry problems within the standard time limit, matching the average human gold medalist's performance. The system's solutions have machine-verifiable structure while remaining human-readable, distinguishing it from brute-force coordinate system approaches. The subsequent AlphaGeometry2 (AG2) leverages the Gemini architecture for improved language modeling and a novel knowledge-sharing mechanism combining multiple search trees, boosting its solve rate to 84% for all 2000-2024 IMO geometry problems. This demonstrates AI's growing ability to reason logically and discover and verify new knowledge, marking an important milestone in developing deep mathematical reasoning for more advanced and general AI systems.
Table: Algorithmic & Mathematical Discovery Models Genealogy & Core Innovations
5. Hardware Design & Quantum Computing Models

DeepMind's "Alpha" series has also ventured into the highly specialized domains of hardware design and quantum computing, applying its core AI methodologies to accelerate complex engineering challenges and address fundamental limitations in advanced computing.
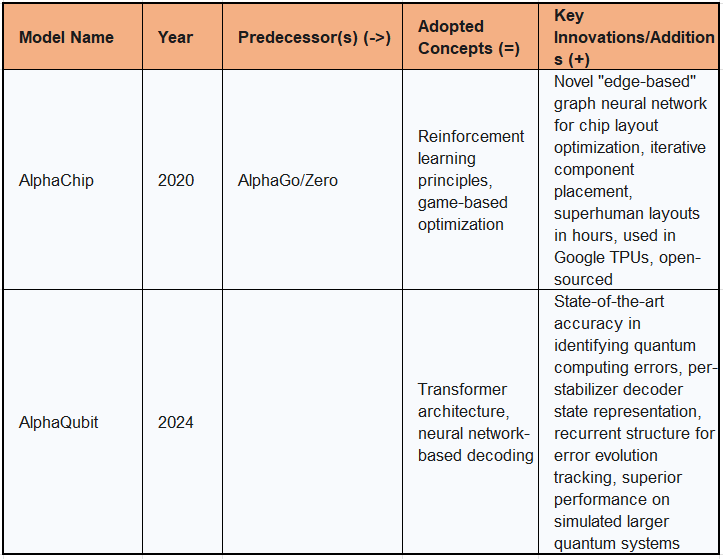
5.1. AlphaChip: AI for Chip Floorplanning
AlphaChip, first introduced as a preprint in 2020, stands as one of the first reinforcement learning approaches successfully applied to a real-world engineering problem: chip floorplanning. This system has dramatically accelerated and optimized the design of complex integrated circuits.
AlphaChip adopts reinforcement learning principles similar to those employed in AlphaGo and AlphaZero, framing the chip layout problem as a game. The agent learns by placing one circuit component at a time on a blank grid and receiving rewards based on the quality of the final layout.
The core innovation of AlphaChip is its use of a novel "edge-based" graph neural network. This architecture allows the model to learn the intricate relationships between interconnected chip components and to generalize this knowledge across different chip designs, enabling continuous improvement with each new layout. The system employs iterative learning and reward-based optimization, where it starts with a random layout and refines it based on feedback related to wire length, congestion, design rule violations, and timing constraints. AlphaChip generates superhuman or comparable chip layouts in hours, a task that traditionally required weeks or months of human effort. It has been used to design superhuman chip layouts in every generation of Google's Tensor Processing Units (TPUs) since its publication, contributing to significant gains in performance and energy efficiency (e.g., 67% less power consumption in Trillium TPU) and reducing wire lengths by up to 6%.
The open-sourcing of AlphaChip methodologies has fostered a proliferation of research in AI for chip design and enabled its extension to other critical stages like logic synthesis and macro selection. The economic impact is substantial, with potential savings of approximately $3.6 million per chip design due to reduced design time and hundreds of millions in power efficiency improvements for large data centers.
5.2. AlphaQubit: Quantum Error Correction
AlphaQubit, a collaborative effort between Google DeepMind and Google Quantum AI, addresses one of the most critical challenges in quantum computing: accurately identifying and correcting errors in fragile quantum bits (qubits). This breakthrough is essential for building reliable, large-scale quantum computers.
AlphaQubit's architecture draws heavily on the Transformer architecture, a deep learning model developed at Google that underpins many large language models. This signifies the adaptability of modern neural network designs to entirely new scientific domains. It functions as a neural network-based decoder.
The primary innovation of AlphaQubit is its ability to identify quantum computing errors with state-of-the-art accuracy. It uses consistency checks from logical qubits as input to predict whether a logical qubit has flipped. The model employs a per-stabilizer decoder state representation, which stores information about the syndrome history over time, allowing it to track error evolution patterns and learn temporal correlations in noise. This recurrently updated state representation enables AlphaQubit to maintain accuracy far beyond its training rounds, generalizing to experiments of at least 100,000 rounds. When tested on Sycamore quantum processors, AlphaQubit demonstrated significant improvements, making 6% fewer errors than highly accurate but slow tensor network methods and 30% fewer errors than faster correlated matching methods. Furthermore, AlphaQubit has shown superior performance on simulated quantum systems up to 241 qubits, indicating its scalability for future mid-sized quantum devices. The economic implications are substantial, with the potential to unlock hundreds of millions to low billions in value in the short to medium term, and to revolutionize sectors like life sciences and finance by enabling fault-tolerant quantum computing.
Table: Hardware & Quantum Computing Models Genealogy & Core Innovations
6. Genomic Understanding Models

DeepMind's "Alpha" series has extended its analytical capabilities to the human genome, aiming to decipher the complex interplay of DNA sequences and gene regulation. This represents a critical step towards personalized medicine and a deeper understanding of disease biology.
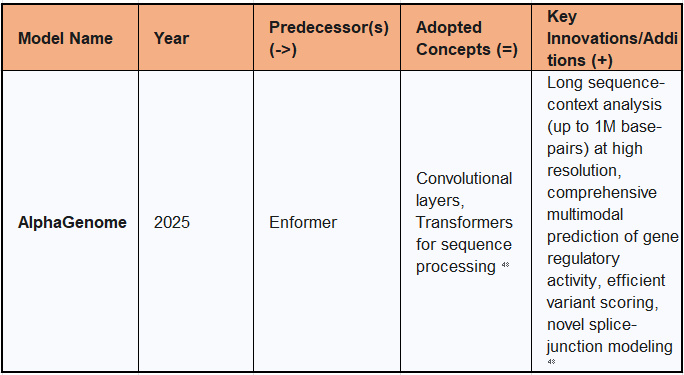
6.1. AlphaGenome: Comprehensive Genome Prediction
AlphaGenome, unveiled in mid-2025, is a new artificial intelligence tool designed to more comprehensively and accurately predict how single variants or mutations in human DNA sequences impact a wide range of biological processes regulating genes. It offers unprecedented insight into how genetic variants, both common and rare, affect gene regulation across the entire genome, including the vast non-coding regions that constitute most of our DNA.
AlphaGenome's architecture incorporates convolutional layers to initially detect short patterns in the genome sequence and Transformers to communicate information across all positions in the sequence. This combination leverages established deep learning components for sequential data processing. The model was trained with half the compute budget of its predecessor, Enformer, indicating efficiency improvements.
The key innovations of AlphaGenome include its long sequence-context analysis at high resolution, capable of analyzing up to 1 million DNA letters (base-pairs) and making predictions at the resolution of individual letters. This addresses a previous trade-off between sequence length and resolution in prior models. It provides comprehensive multimodal prediction, unlocking the ability to predict thousands of molecular properties characterizing gene regulatory activity. AlphaGenome also offers efficient variant scoring, allowing it to quickly assess the impact of a genetic variant on all these properties by contrasting mutated and unmutated sequences. A novel capability is its explicit modeling of splice-junction location and expression level directly from sequence, which is crucial for understanding rare genetic diseases caused by RNA splicing errors. AlphaGenome has achieved state-of-the-art performance across a wide range of genomic prediction benchmarks, outperforming or matching external models in most evaluations. This comprehensive predictive power is expected to be a valuable resource for the scientific community, aiding in pinpointing disease causes, interpreting functional impacts of variants, and ultimately driving new biological discoveries and the development of personalized treatments.
Table: Genomic Understanding Models Genealogy & Core Innovations
7. Cross-Cutting Innovations and Future Directions
The evolutionary trajectory of DeepMind's "Alpha" series reveals several powerful, recurring methodological themes that transcend specific applications, pointing towards a broader strategy for advancing artificial intelligence. These cross-cutting innovations are fundamental to the series' success and indicate future directions in AI research.
A central theme is the pervasive application of Reinforcement Learning (RL). From AlphaGo's mastery of Go to AlphaChip's optimization of chip layouts, RL provides a robust framework for complex decision-making and optimization problems, especially where explicit rules are unknown or difficult to formalize. The power of RL lies in its ability to learn through interaction and feedback, enabling AI systems to discover novel, superhuman strategies in environments where traditional rule-based or supervised learning approaches would fall short.
Complementing RL is the emphasis on Self-Play and Tabula Rasa Learning. Pioneered by AlphaGo Zero and generalized by AlphaZero, this paradigm allows AI to learn from scratch, unconstrained by human biases or limitations. This approach has consistently led to the discovery of strategies that surpass human intuition, as famously demonstrated by AlphaGo's "Move 37". This fundamental shift from "mimicry" to "discovery" allows AI to explore the entire solution space, leading to truly optimal and unexpected solutions.
The Evolution of Neural Network Architectures is another defining characteristic. Early models like AlphaGo utilized Convolutional Neural Networks (CNNs) and Residual Networks (ResNets). Subsequent models, particularly in the biological and algorithmic domains, increasingly adopted and specialized Transformers.
AlphaFold 2 and 3 feature the Evoformer and Pairformer (Transformer-inspired) architectures for protein structure prediction. AlphaQubit leverages Transformers for quantum error correction , and AlphaGenome incorporates them for genomic analysis. The latest algorithmic discovery agent, AlphaEvolve, integrates Gemini-powered Large Language Models (LLMs), which are fundamentally Transformer-based, for code generation and evolution. This progression reflects the adaptability and increasing versatility of Transformer architectures for handling complex sequential data and long-range dependencies across diverse scientific and engineering problems.
The strategic use of Synthetic Data Generation has emerged as a powerful technique to overcome data scarcity, a common bottleneck in many scientific domains. AlphaGeometry, for instance, generated 100 million synthetic examples to train its geometry problem-solving capabilities without relying on limited human demonstrations. Similarly, AlphaQubit utilized quantum simulators to generate hundreds of millions of examples for training its error decoder. This approach allows DeepMind to train models to superhuman levels even in domains where real-world, high-quality labeled data is prohibitively expensive or impossible to acquire.
The development of Neuro-Symbolic AI, exemplified by AlphaGeometry, represents an effort to combine the strengths of neural networks (intuition, pattern recognition) with symbolic engines (rigorous reasoning, verifiability). This hybrid approach is particularly well-suited for problems requiring both creative exploration and logical deduction, moving beyond the "black box" nature of purely neural models.
The overarching trajectory of the "Alpha" series clearly demonstrates a progression From Games to Real-World Scientific and Engineering Problems. The initial success in mastering complex games provided a controlled environment for developing and validating powerful RL and deep learning techniques. The subsequent transfer of these core methodologies to fundamental problems in biology (protein folding, drug design), mathematics (algorithmic discovery, geometry), and engineering (chip design, quantum error correction) highlights the generalizability and foundational nature of DeepMind's research. This signifies a profound shift from AI as a game-player to AI as a scientific and engineering collaborator.
These advancements carry significant Economic and Societal Implications. The "Alpha" models are designed to optimize highly complex, resource-intensive processes, leading to substantial cost savings and accelerated research and development. AlphaChip, for example, can save millions per chip design and hundreds of millions in power efficiency. AlphaEvolve's optimizations have recovered 0.7% of Google's worldwide compute resources and accelerated AI training significantly. AlphaFold's impact on drug discovery is expected to be transformative, with Isomorphic Labs securing multi-billion dollar partnerships. However, this rapid technological advancement also raises critical questions about the future of work.
While augmentation AI is shown to foster new work and raise wages for high-skilled occupations, there are concerns about job displacement, particularly for low-skilled roles. The concentration of such powerful AI tools within a few tech giants also necessitates careful consideration of ethical concerns, including data privacy and potential market concentration. DeepMind acknowledges these responsibilities, emphasizing secure and privacy-preserving AI development and engagement with governments and civil society to address potential risks. The ongoing development of these systems points towards a future where AI acts as a powerful augmentative force, driving innovation across various sectors, but also one that requires proactive governance and equitable access to ensure broad societal benefit.
8. Final Thoughts
The DeepMind "Alpha" series represents a compelling narrative of continuous innovation and generalization in artificial intelligence. What began as a groundbreaking demonstration of AI's capacity to master complex games through reinforcement learning and deep neural networks has systematically evolved into a suite of powerful tools addressing some of the most challenging scientific and engineering problems. The progression from AlphaGo's human-mimicking learning to AlphaGo Zero's tabula rasa self-play, and then AlphaZero's generalization across diverse game domains, established a robust foundation for autonomous learning. MuZero further refined this by learning environmental dynamics implicitly, freeing AI from the need for explicit rules or perfect simulators, thus expanding its applicability to complex real-world scenarios.
This foundational expertise in reinforcement learning and deep learning has been strategically transferred and adapted. In molecular biology, AlphaFold's evolution from predicting single protein structures (AlphaFold 1 and 2) to multi-molecular complexes (AlphaFold 3) has revolutionized structural biology and laid the groundwork for AI-driven drug discovery (AlphaMissense, AlphaProteo). In algorithmic and mathematical discovery, AlphaTensor, AlphaDev, and AlphaEvolve demonstrate AI's ability to autonomously generate novel, provably correct, and more efficient algorithms, surpassing human-designed benchmarks. AlphaGeometry showcases a powerful neuro-symbolic approach, combining neural intuition with symbolic rigor to solve Olympiad-level geometry problems through synthetic data generation.
Concurrently, AlphaChip has transformed hardware design, and AlphaQubit is making strides in quantum error correction, both leveraging reinforcement learning and advanced neural architectures to optimize highly complex engineering processes.
The consistent thread through the "Alpha" series is DeepMind's commitment to pushing the boundaries of general AI. This is achieved through methodological advancements such as sophisticated neural architectures (e.g., Transformers, Evoformer, Pairformer), the strategic use of self-play and synthetic data to overcome data limitations, and the integration of diverse AI paradigms like neuro-symbolic systems. The profound implications of these models extend beyond scientific breakthroughs, promising significant economic value through increased efficiency, accelerated research, and the potential to unlock new industries.
However, this transformative power also necessitates a vigilant focus on the societal impacts, including labor market dynamics and ethical considerations, to ensure that the benefits of advanced AI are realized responsibly and equitably. The "Alpha" series stands as a testament to the power of fundamental AI research to yield far-reaching, practical applications across the scientific and industrial landscape.
And of course, where and when you can: Watch “The Thinking Game”
Detailed Timeline: DeepMind's Alpha Series Evolution
2010s:
Prior to 2018: Various teams developed work on analysing large databanks of related DNA sequences to find correlated changes in residues, which AlphaFold 1 built upon.
2016:
AlphaGo: DeepMind releases AlphaGo, the first computer Go program to defeat a human professional Go player without handicaps on a full-sized 19x19 board. It innovates by integrating Deep Neural Networks (DNNs) with Monte Carlo Tree Search (MCTS) and uses Supervised Learning (SL) followed by Reinforcement Learning (RL) through self-play. Its victory over Lee Sedol occurs approximately a decade earlier than anticipated.
2017:
AlphaGo Zero: DeepMind introduces AlphaGo Zero, which dramatically refines AlphaGo's approach by learning tabula rasa (from a blank slate) solely through self-play, eliminating dependency on human gameplay data or domain knowledge beyond basic rules. It achieves superhuman performance, famously winning 100-0 against the original AlphaGo.
AlphaZero: This model generalises AlphaGo Zero's self-play RL approach, mastering Go, Chess, and Shogi without any domain-specific adjustments or human heuristics. It demonstrates that the underlying RL framework and neural network architecture are robust enough to learn optimal strategies for diverse, complex, deterministic environments.
2018:
AlphaFold 1: DeepMind releases its initial protein structure prediction model, AlphaFold 1. It utilises attention networks and the Protein Data Bank (PDB) and employs separately trained modules to produce a "guide potential" combined with a physics-based energy potential to predict protein structures.
2019:
MuZero: MuZero extends AlphaZero by learning the underlying dynamics of game environments without explicit knowledge of their rules, making it adaptable across various games, including complex Atari games. Its core innovation is learning an implicit model for planning, predicting only relevant quantities (reward, policy, value). MuZero achieves state-of-the-art performance in 46 out of 60 Atari games and matches AlphaZero's superhuman performance in Go, Chess, and Shogi. It is later applied to optimise YouTube video compression (MuZero Rate-Controller).
2020:
AlphaChip (Preprint): AlphaChip is first introduced as a preprint. It applies reinforcement learning to chip floorplanning, using a novel "edge-based" graph neural network and iterative learning to generate superhuman or comparable chip layouts in hours. It has since been used in every generation of Google's Tensor Processing Units (TPUs).
AlphaFold 2: Unveiled, AlphaFold 2 dramatically advances protein structure prediction, achieving accuracy competitive with experimental methods and being recognised as the best-performing method in CASP14. It transitions to a single, differentiable, end-to-end model based on pattern recognition, featuring "Evoformer" blocks.
October 2021:
AlphaFold-Multimer (Update to AlphaFold 2): An update to AlphaFold 2 expands its training data to include protein complexes, enabling it to predict protein-protein interactions with approximately 70% accuracy.
2022:
AlphaTensor: AlphaTensor applies deep reinforcement learning to discover novel, efficient, and provably correct algorithms for matrix multiplication. It formulates the problem as a single-player game (TensorGame) and improves upon Strassen's two-level algorithm for 4x4 matrices in a finite field, the first such improvement in 50 years. It also optimises for specific hardware (Nvidia V100 GPUs and Google TPU v2).
2023:
AlphaMissense: Google DeepMind develops AlphaMissense, an AI model that explicitly builds on AlphaFold 2 to classify the pathogenicity of missense mutations as 'likely pathogenic', 'likely benign', or 'uncertain'. Its predictions are integrated into EMBL-EBI resources.
AlphaDev: AlphaDev advances DeepMind's algorithmic discovery efforts by applying AlphaZero's reinforcement learning approach to discover faster sorting and hashing algorithms for fundamental computer libraries, which have been assimilated into essential computing libraries used by millions.
2024:
AlphaGeometry: Introduced, AlphaGeometry is an AI system that solves complex geometry problems at a level approaching a human Olympiad gold-medalist. It uses a neuro-symbolic approach and generates a vast pool of 100 million synthetic training examples without human demonstrations.
AlphaQubit: A collaborative effort between Google DeepMind and Google Quantum AI, AlphaQubit addresses quantum error correction using a Transformer architecture and a neural network-based decoder. It achieves state-of-the-art accuracy in identifying quantum computing errors and shows superior performance on simulated quantum systems.
May 2024: AlphaFold 3: Announced, AlphaFold 3 represents the latest evolution in protein prediction, co-developed with Isomorphic Labs. It expands beyond individual proteins to encompass complex biological assemblies, introducing the "Pairformer" architecture and a diffusion model for refinement. It predicts complexes with DNA, RNA, various ligands, and ions, showing a minimum 50% accuracy improvement for protein interactions with other molecules.
Mid-2025 (Projected/Anticipated):
AlphaEvolve: Unveiled, AlphaEvolve is an AI agent designed to discover and optimise algorithms through a fusion of large language models (LLMs, specifically Gemini LLMs) and evolutionary computation. It can evolve entire code files, supporting hundreds of lines of code in any programming language, and has demonstrated practical impact by optimising Google's computing ecosystem. It found a new lower bound for the kissing number problem in 11 dimensions.
AlphaGenome: Unveiled, AlphaGenome is a new AI tool designed to comprehensively and accurately predict how single variants or mutations in human DNA sequences impact gene regulation. It incorporates convolutional layers and Transformers, offers long sequence-context analysis at high resolution (up to 1 million DNA letters), and provides comprehensive multimodal prediction and efficient variant scoring.
AlphaProteo: AlphaProteo represents a significant advancement in generative AI for molecular biology, focusing on the design of novel proteins. Trained on AlphaFold's predicted structures, it generates novel, high-strength protein binders with experimental success rates 3 to 300 times better than prior methods, including the first AI tool to design a protein binder for VEGF-A.
Later 2025 (Projected/Anticipated):
AlphaGeometry2 (AG2): Leverages the Gemini architecture for improved language modeling and a novel knowledge-sharing mechanism combining multiple search trees, boosting AlphaGeometry's solve rate to 84% for all 2000-2024 IMO geometry problems.
Cast of Characters
DeepMind (Google DeepMind): A British artificial intelligence research laboratory, and a subsidiary of Google. It is the primary developer of all the "Alpha" series models detailed in the source, demonstrating a continuous drive towards more general, efficient, and impactful AI systems across diverse and challenging domains.
Isomorphic Labs: A Google DeepMind sister company that focuses on using AI to accelerate drug discovery. They co-developed AlphaFold 3.
Google Quantum AI: A research initiative by Google dedicated to developing quantum computers and quantum algorithms. They collaborated with DeepMind on AlphaQubit.
Lee Sedol: A renowned human professional Go player, famously defeated by DeepMind's AlphaGo in 2016, a milestone that occurred approximately a decade earlier than anticipated by Go experts.
Strassen (1969): Referencing Volker Strassen, a mathematician whose 1969 algorithm for matrix multiplication was improved upon by AlphaTensor for specific cases, marking the first such improvement in 50 years. The algorithm is also mentioned in relation to AlphaEvolve improving upon Strassen's algorithm for complex-valued matrices.
Ensembl, UniProt, AlphaFold Database (AlphaFold DB), DECIPHER (Databases/Resources): Key biological and genetic databases/resources that have integrated AlphaMissense predictions, making AI-generated scores accessible to researchers and aiding in understanding protein function and disease. AlphaFold DB also provides open access to over 200 million AlphaFold protein structure predictions.
Enformer: A predecessor model to AlphaGenome, on which AlphaGenome was trained with half the compute budget, indicating efficiency improvements.
Nvidia V100 GPUs & Google TPU v2 (Hardware Platforms): Specific hardware platforms for which AlphaTensor demonstrated flexibility by optimising matrix multiplication for runtime, achieving 10-20% faster multiplication for large matrices. Google TPUs are also mentioned as benefitting from AlphaChip in every generation since its publication.
VEGF-A (Vascular Endothelial Growth Factor A): A specific molecule associated with cancer and diabetes complications, for which AlphaProteo was the first AI tool to successfully design a protein binder, highlighting its potential in drug development.
References:
Deep Reinforcement Learning: A Chronological Overview and Methods - MDPI, https://www.mdpi.com/2673-2688/6/3/46
Mastering AlphaGo: The AI Revolution - Number Analytics, https://www.numberanalytics.com/blog/mastering-alphago-the-ai-revolution
AlphaGo Algorithm in Artificial Intelligence - GeeksforGeeks, https://www.geeksforgeeks.org/artificial-intelligence/alphago-algorithm-in-artificial-intelligence/
AlphaGo: Mastering the Game of Go with Deep Neural Networks and Tree Search, https://kam.mff.cuni.cz/~hladik/OS/Slides/Ha-GO-abs-2016.pdf
A summary of the DeepMind's general reinforcement learning ..., https://medium.com/@umerhasan17/a-summary-of-the-general-reinforcement-learning-game-playing-algorithm-alphazero-755f1de1ce38
Bridging the human–AI knowledge gap through concept discovery and transfer in AlphaZero, https://www.pnas.org/doi/10.1073/pnas.2406675122
Mastering the game of Go without human knowledge - PubMed, https://pubmed.ncbi.nlm.nih.gov/29052630/
A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play - PubMed, https://pubmed.ncbi.nlm.nih.gov/30523106/
Acquisition of chess knowledge in AlphaZero - PNAS, https://www.pnas.org/doi/10.1073/pnas.2206625119
(PDF) Reinforcement Learning in Strategy-Based and Atari Games ..., https://www.researchgate.net/publication/389056236_Reinforcement_Learning_in_Strategy-Based_and_Atari_Games_A_Review_of_Google_DeepMinds_Innovations
Mastering Atari, Go, Chess and Shogi by Planning with a Learned ..., https://arxiv.org/abs/1911.08265
Mastering Atari, Go, chess and shogi by planning with a learned model - PubMed, https://pubmed.ncbi.nlm.nih.gov/33361790/
Demystifying MuZero Planning: Interpreting the Learned Model - arXiv, https://arxiv.org/html/2411.04580v2
AlphaFold - Wikipedia, https://en.wikipedia.org/wiki/AlphaFold
Overview of the architecture - E-Learning@VIB, https://elearning.vib.be/courses/alphafold/lessons/the-alphafold-pipeline/topic/overview-of-the-architecture/
Understanding the significance and architecture of AlphaFold - The Rising Sea, http://therisingsea.org/notes/metauni/notes-li-alphafold.pdf
AlphaFold Protein Structure Database, https://alphafold.ebi.ac.uk/
Highly accurate protein structure prediction with AlphaFold - PubMed, https://pubmed.ncbi.nlm.nih.gov/34265844/
Great expectations – the potential impacts of AlphaFold DB | EMBL, https://www.embl.org/news/science/alphafold-potential-impacts/
Case study: AlphaFold uses open data and AI to discover the 3D protein universe | EMBL, https://www.embl.org/news/science/alphafold-using-open-data-and-ai-to-discover-the-3d-protein-universe/
google-deepmind/alphamissense - GitHub, https://github.com/google-deepmind/alphamissense
AlphaMissense data integrated into Ensembl, UniProt, DECIPHER and AlphaFold DB, https://www.ebi.ac.uk/about/news/technology-and-innovation/alphamissense-data-integration/
AlphaProteo generates novel proteins for health research - Edward Conard, https://www.edwardconard.com/macro-roundup/googledeepmind-has-developed-alphaproteo-an-ai-system-that-designs-proteins-that-bind-to-target-molecules-at-success-rates-3-to-300-times-better-than-the-best-prior-methods-potentially-acceleratin/?view=detail
AlphaProteo generates novel proteins for biology and health research - Google DeepMind, https://deepmind.google/discover/blog/alphaproteo-generates-novel-proteins-for-biology-and-health-research/
AlphaGenome: AI for better understanding the genome - Google DeepMind, https://deepmind.google/discover/blog/alphagenome-ai-for-better-understanding-the-genome/
AlphaGenome: How will Google DeepMind's AI model transform our understanding of the human genome? - Economy Middle East, https://economymiddleeast.com/news/alphagenome-how-will-google-deepminds-ai-model-transform-our-understanding-of-the-human-genome/
Discovering novel algorithms with AlphaTensor - Google DeepMind, https://deepmind.google/discover/blog/discovering-novel-algorithms-with-alphatensor/
Discovering faster matrix multiplication algorithms - ResearchBunny, https://www.researchbunny.com/papers/discovering-faster-matrix-multiplication-algorithms-with-reinforcement-learning-pjci
Discovering faster matrix multiplication algorithms with reinforcement learning - PubMed, https://pubmed.ncbi.nlm.nih.gov/36198780/
AlphaDev: Discovering Faster Sorting Algorithms with Reinforcement Learning - AI for Good, https://aiforgood.itu.int/event/alphadev-discovering-faster-sorting-algorithms-with-reinforcement-learning/
AlphaEvolve: A Gemini-powered coding agent for designing advanced algorithms, https://deepmind.google/discover/blog/alphaevolve-a-gemini-powered-coding-agent-for-designing-advanced-algorithms/
AlphaEvolve: DeepMind's Evolutionary Leap in Scientific Algorithmic Discovery, https://hackernoon.com/alphaevolve-deepminds-evolutionary-leap-in-scientific-algorithmic-discovery
AlphaEvolve: DeepMind's Gemini-Powered AI That Invents Algorithms and Breaks a 56-Year Record - TS2 Space, https://ts2.tech/en/alphaevolve-deepminds-gemini-powered-ai-that-invents-algorithms-and-breaks-a-56-year-record/
The Dawn of Algorithmic Evolution: AlphaEvolve and Its Transformative Impact - gekko, https://gpt.gekko.de/alphaevolve-impact-science-economy-society/
[2506.13131] AlphaEvolve: A coding agent for scientific and algorithmic discovery - arXiv, https://arxiv.org/abs/2506.13131
[2507.18074] AlphaGo Moment for Model Architecture Discovery - arXiv, https://arxiv.org/abs/2507.18074
google-deepmind/code_contests - GitHub, https://github.com/google-deepmind/code_contests
AlphaCode 2 Technical Report - Googleapis.com, https://storage.googleapis.com/deepmind-media/AlphaCode2/AlphaCode2_Tech_Report.pdf
2023: A year of groundbreaking advances in AI and computing - Google Research, https://research.google/blog/2023-a-year-of-groundbreaking-advances-in-ai-and-computing/
Gemini: A Family of Highly Capable Multimodal Models - Googleapis.com, https://storage.googleapis.com/deepmind-media/gemini/gemini_1_report.pdf
AlphaGeometry: An Olympiad-level AI system for geometry - Google DeepMind, https://deepmind.google/discover/blog/alphageometry-an-olympiad-level-ai-system-for-geometry/
AlphaGeometry Solves Geometry Problems at Olympiad Level - CIO Influence, https://cioinfluence.com/it-and-devops/alphageometry-solves-geometry-problems-at-olympiad-level/
Gold-medalist Performance in Solving Olympiad Geometry with AlphaGeometry2 - arXiv, https://arxiv.org/html/2502.03544v1
How AlphaChip transformed computer chip design - Google DeepMind, https://deepmind.google/discover/blog/how-alphachip-transformed-computer-chip-design/
Google DeepMind's AlphaChip Revolutionizes Chip Design With AI - All Tech Magazine, https://alltechmagazine.com/google-deepminds-alphachip-revolutionizes-chip-design-with-ai/
How Google Improves Computing Chip Design with Reinforcement Learning | by Devansh, https://machine-learning-made-simple.medium.com/how-google-improves-computing-chip-design-with-reinforcement-learning-d59fa5fb0f73
google-research/circuit_training - GitHub, https://github.com/google-research/circuit_training
AlphaQubit tackles one of quantum computing's biggest challenges - Google Blog, https://blog.google/technology/google-deepmind/alphaqubit-quantum-error-correction/
The Intersection of AI and Quantum Computing: A New Era of Innovation - HPCwire, https://www.hpcwire.com/2024/11/29/the-intersection-of-ai-and-quantum-computing-a-new-era-of-innovation/
How Google AI Used Machine Learning for Quantum Error Correction - Devansh - Medium, https://machine-learning-made-simple.medium.com/how-google-ai-used-machine-learning-for-quantum-error-correction-b7c927e0e17b
Quantum Meets AI: Pioneering the Future of Technology - AVP, https://avpcap.com/quantum-meets-ai-pioneering-the-future-of-technology/
The Revolutionary Impact of AlphaFold on Drug Discovery: Decoding the Mystery of Protein Folding - Lindus Health, https://www.lindushealth.com/blog/the-revolutionary-impact-of-alphafold-on-drug-discovery-decoding-the-mystery-of-protein-folding
Artificial Intelligence Speeding Discovery of New Drugs - News - The University of Maryland, Baltimore, https://www.umaryland.edu/news/archived-news/august-2024/ai-speeding-discovery-of-new-drugs.php
Augmenting or Automating Labor? The Effect of AI Development on New Work, Employment, and Wages - arXiv, http://arxiv.org/pdf/2503.19159
Displacement or Augmentation? The Effects of AI Innovation on Workforce Dynamics and Firm Value - American Economic Association, https://www.aeaweb.org/conference/2025/program/paper/BBsK4Zkd
AI to disrupt jobs, warns DeepMind CEO, as Gen Alpha faces new realities, https://dig.watch/updates/ai-to-disrupt-jobs-warns-deepmind-ceo-as-gen-alpha-faces-new-realities
Google DeepMind's AlphaEarth Model Aims to Transform Climate and Land Monitoring, https://www.hpcwire.com/off-the-wire/google-deepminds-alphaearth-model-aims-to-transform-climate-and-land-monitoring/
Google DeepMind - Wikipedia, https://en.wikipedia.org/wiki/Google_DeepMind
Transforming the Semiconductor Industry with AI-Driven Innovations - Accenture, https://www.accenture.com/us-en/blogs/high-tech/ai-revolution-semiconductor-industry
How to Invest in AlphaFold Stock - Nasdaq, https://www.nasdaq.com/articles/how-invest-alphafold-stock
Responsibility & Safety - Google DeepMind, https://deepmind.google/about/responsibility-safety/
Google DeepMind and healthcare in an age of algorithms - PMC - PubMed Central, https://pmc.ncbi.nlm.nih.gov/articles/PMC5741783/
AlphaFold - The Most Useful Thing AI Has Ever Done - YouTube,
DeepMind AlphaCode, https://alphacode.deepmind.com/
AlphaZero Explained · On AI, https://nikcheerla.github.io/deeplearningschool/2018/01/01/AlphaZero-Explained/
https://substack.com/@interestingengineering/note/c-174830711?r=223m94