
Engineering Solutions to the AI Power Crisis: Deconstructing the Colossus Blueprint
Engineering Creative Solutions to the "Many Peaks and Valleys" of AI Power Demand


As someone who has spent a career at the intersection of finance, investment, large-scale infrastructure and technology, I have listened to, and watched the recent discourse surrounding Artificial Intelligence and its energy requirements with a growing sense of discomfort and curiosity. The prevailing narrative, reinforced by credible analysis and public anxiety, is that we are rapidly approaching a hard wall—a fundamental limit where our ability to generate power cannot keep pace with AI's exponential demand for computation.
Many see this - “the power wall” - as an insurmountable constraint that will cap the progress of AI.
I see this view in fundamentally different ways, whilst acknowledging the issues at hand. To me, the challenge we face is not a crisis of resources, but a crisis of imagination and execution. It is not a physics problem; it is an engineering problem. The constraints are not in the availability of energy, but in our antiquated, sclerotic processes for building the infrastructure to harness and deliver it. The recent AI Action Plan from the Trump administration and the June RAND Report on AI power requirements correctly identify the symptoms—grid strain, permitting bottlenecks, a potential power deficit—but often miss the diagnosis. The true bottleneck is a deficit in engineering velocity and a failure to approach these challenges from first principles.
To make this case, I will deconstruct what I consider to be the most important infrastructure project of the current AI era: xAI's "Colossus" supercomputer in Memphis, Tennessee. In its breathtaking speed and audacious methodology, the Colossus project provides a powerful counter-narrative. It is a real-world blueprint for a new way of thinking about and building the hyperscale systems that will power our future. By examining its approach to power generation, cooling, and the deep technical stack that makes it coherent, I will argue that the perceived energy constraints on AI are limited only by our capacity to implement and execute. If we can engineer systems with the speed and ingenuity demonstrated in Memphis, the concerns of a power-limited AI future will be revealed as a failure of engineering will, not a fact of the world.
Note: Whilst AI Investments are expected to require multi-year capital expenditure requirements, how each company commercializes and eventually generates commensurate returns is still subject to study. My focus in writing this (at least for now) - is trying to understand how to address the engineering challenges that AI faces, especially it power needs. Nothing covered in this written piece should be taken as recommendations for investment advice, in any way or form.
The Perceived Power Wall: Deconstructing the AI Energy Bottleneck
To appreciate the novelty of the new engineering paradigm, we must first understand the scale of the problem as defined by the conventional model.
The June RAND Report, "Assessing the United States' Additional AI Power Capacity by 2030," provides a sobering, data-driven baseline for this challenge. It paints a picture of a nation whose energy infrastructure development is struggling to keep pace with the voracious, and rapidly accelerating, demands of AI.
The report's central finding is a projected chasm between supply and demand. By 2030, the United States is forecast to add a net total of only 82 GW of available power capacity. This is composed of 33 GW from Front-of-the-Meter (FTM) sources—traditional power plants connected to the main grid—and 49 GW from Behind-the-Meter (BTM) sources like rooftop solar and on-site batteries. This modest increase in supply is set against a backdrop of wildly escalating AI demand, with forecasts for additional data center power needs by 2030 ranging from a conservative 34 GW to a staggering 253 GW.
Even at the low end of these projections, the grid's expansion appears insufficient; at the high end, it is catastrophically inadequate.
However, the true bottleneck identified by the report is not a lack of potential projects, but a systemic failure to bring them online. The U.S. has over 2,600 GW of proposed generation and storage projects currently languishing in interconnection queues. The core issue is a procedural paralysis that results in an abysmal completion rate. Historical data reveals that only 14% of the FTM capacity proposed between the years 2000 and 2018 was ever successfully built and connected to the grid. This points to an entrenched, multi-decade problem of regulatory and bureaucratic friction that stifles the very development needed to power the next industrial revolution. The AI Action Plan itself acknowledges this stagnation, noting that "American energy capacity has stagnated since the 1970s" and that the grid requires profound upgrades to support the AI buildout.
This supply-side challenge is further compounded by the quality of the power being added. The RAND report makes a crucial distinction between a power plant's "nameplate capacity"—its theoretical maximum output—and its "effective capacity," which is the reliable, dispatchable power it can be counted on to deliver during peak demand. Most new projects in the queue are intermittent renewables like wind and solar. While vital for decarbonization, these sources have low Capacity Accreditation Factors (CAFs), meaning a 100 MW solar farm might only contribute 10-20 MW of effective capacity to meet the firm, 24/7 load profile that an AI training cluster demands. This mismatch between the intermittent nature of new supply and the constant, high-intensity demand of AI workloads exacerbates the perceived deficit.
The conventional analysis, therefore, correctly identifies a looming crisis born from a slow, inefficient, and mismatched energy development pipeline. But this is where the analysis must go deeper. The data clearly shows that the "energy crisis" is a misnomer; it is, more accurately, an interconnection and permitting crisis. The problem is not a scarcity of fuel or a lack of proposed projects, but a systemic inability to approve, build, and connect them in a timely manner.
Furthermore, the grid's problem is not merely one of raw capacity but also of flexibility. Traditional grid planning is predicated on relatively stable, predictable load growth. AI training, however, introduces a completely new load profile characterized by extreme volatility. A single training run can cause power demand to spike by hundreds of megawatts in minutes, then fall just as quickly as the computation phase ends and a data-shuffling phase begins. The research on Colossus's power consumption patterns confirms these "many peaks and valleys," which are managed by on-site battery storage.
The traditional grid, with its slow-ramping baseload power plants, is simply not designed to handle such "spiky" demand. This technical mismatch means that simply adding more conventional power plants to the grid is an incomplete solution. The nature of the AI workload demands a new power architecture—one that is co-located, highly responsive, and engineered specifically for the task.

The Colossus Blueprint: A First-Principles Approach to Hyperscale Infrastructure
While the conventional view fixates on the constraints of the existing system, the xAI Colossus project in Memphis provides a powerful real-world demonstration of what is possible when those constraints are not accepted as given, but are instead treated as engineering problems to be solved. The project's timeline and methodology represent a radical departure from the traditional, sequential, and risk-averse model of infrastructure development. It is a case study in applying a first-principles, "move fast and break things" philosophy to the world of physical infrastructure.
The Colossus story is best understood as a phased, iterative deployment, much like an agile software project, designed to get a "minimum viable product"—in this case, a functional supercomputer—online as quickly as possible, with subsequent phases focused on scaling and optimization.

Phase 1: Emergency Standalone Deployment
The project began with a critical constraint: the existing grid connection at the chosen site, a former Electrolux factory, could provide only 8 MW of power, a fraction of what was needed. The traditional approach would have involved waiting years for the local utility to plan and build a new substation and transmission lines. Instead, xAI engineered a bypass. They immediately deployed 14 mobile, truck-mounted gas generators, providing an additional 35 MW of on-site power—enough to bring the initial cluster of 32,000 NVIDIA H100 GPUs online. This was enabled by a shrewd understanding of the regulatory environment, leveraging a loophole that allows such (temporary) generators to operate for up to 364 days without a full permit. The result of this parallelized, first-principles approach was staggering: the initial 100,000-GPU cluster was conceived and made operational in just 122 days.

Phase 2: Hybrid Standalone-to-Grid Transition
With the initial cluster operational and generating value, Phase 2 focused on scaling. The mobile generators were supplemented by a fleet of 35 larger gas turbines, bringing total on-site generation capacity to 420 MW, augmented by a large installation of Tesla Megapack battery systems to buffer the volatile AI workloads. Critically, this phase was not just about scaling on-site power; it was about solving the long-term grid dependency. Instead of waiting for the utility, xAI invested $35 million of its own capital to build a new, permanent substation for the local grid operator. This single move fundamentally changed the dynamic, transforming xAI from a mere consumer of public infrastructure into a partner in its development.
Phase 3: Symbiotic Grid-Supportive Relationship
Once the new substation came online, providing reliable and sufficient grid power, the project entered its optimization phase. The 35 gas turbines, which had served their purpose as a bridging solution, were now oversized and inefficient. In response, xAI began removing approximately half of them, right-sizing its on-site capacity to around 210 MW. This remaining capacity was repurposed to serve as a high-availability backup and a peak-shaving resource. The turbines' ability to ramp up and down in seconds makes them a perfect complement to the grid, able to handle the sudden demand spikes of AI training without stressing the public infrastructure.
Furthermore, xAI's relationship with the grid was formalized in a contract that contains a remarkable provision: the company is obligated to disconnect its facility from the grid during times of emergency or system-wide strain. This transforms the data center from a potential liability during a crisis into a "grid-supportive" asset that enhances regional energy security.
The radical time compression achieved by this model is best illustrated by a direct comparison with the traditional approach, as shown in Table 1.

This blueprint reveals a fundamentally different philosophy. Where the traditional model sees a static, monolithic project to be planned and executed in a rigid sequence, the xAI model sees a dynamic, software-like system.
→Phase 1 was the Minimum Viable Product (MVP) to get compute online.
→Phase 2 involved scaling with a temporary solution while building the permanent fix (the substation).
→Phase 3 is optimization and refactoring (removing excess turbines).
This is the application of an agile development lifecycle to physical infrastructure, enabling continuous deployment and adaptation.
The Transition From Temporary to Long-Term Engineering Strategy
The reliance on gas turbines was always intended as a temporary, albeit massive, bridge. The long-term strategy involved the construction of dedicated, high-capacity grid infrastructure.
Substation #63 (Phase 1 Power): In May 2025, a major milestone was reached when the first new permanent substation, designated #63, became operational. This substation provides 150 MW of stable grid power directly from the MLGW and Tennessee Valley Authority (TVA) networks. The activation of Substation #63 provided sufficient power for the full Phase 1 operation, allowing xAI to begin the process of demobilizing approximately half of its controversial gas turbine fleet.
Substation #22 (Phase 2 Power): To support the Phase 2 expansion to 200,000 GPUs and beyond, a second substation, #22, is currently under construction, with a planned completion date in the Fall of 2025. While its capacity is not always explicitly detailed in isolation, the consistent reporting of a 300 MW total power goal for the completed site strongly indicates that Substation #22 will also deliver
150 MW of capacity. This will bring the total permanent grid supply for the Colossus 1 facility to 300 MW, at which point the remaining gas turbines are expected to be fully removed or relegated to a purely emergency backup role.
This model also demonstrates a powerful strategic principle: internalizing and solving external dependencies. The primary dependency was the slow-moving utility. By building its own power plant, xAI took control of its own timeline. This came at a cost, both financial and in terms of community backlash over the unpermitted turbines. However, by then investing in public grid infrastructure, xAI converted a long-term liability (grid strain) and a short-term public relations problem into a strategic asset and a partnership with the utility.
This is the essence of first-principles engineering: breaking a problem down to its fundamental constraints and building the solution yourself, even if that solution lies outside your core business. Caution: If managed well! In doing so, the data center evolves from being a problem for the grid into being part of the grid's solution. This approach is explicitly endorsed by the AI Action Plan, which calls for removing "bureaucratic red tape" and creating "Streamlined Permitting for Data Centers" to enable precisely this kind of rapid, private-sector-led buildout.
The Stability Layer: The Role of Tesla Megapacks
A crucial component of the permanent power solution is the integration of a large-scale Battery Energy Storage System (BESS) utilizing Tesla Megapacks. A 150 MW Megapack system was brought online concurrently with Substation #63. This BESS is not intended for primary, long-duration power but serves several critical functions that are vital for both the data center and the local grid:
Power Quality and Stability: Given that AI training workloads are notoriously "spiky," with power demand fluctuating rapidly and dramatically; The Megapack system acts as a buffer, absorbing these spikes and smoothing the load profile presented to the utility grid, preventing instability.
Backup and Resilience: In the event of a grid outage, the 150 MW battery system can provide instantaneous backup power, allowing the supercomputer to ride through short-duration disturbances and maintain operational continuity.
Grid Services: xAI has contractually agreed to make the BESS available for demand-response programs. During times of peak grid demand across the community, MLGW can draw power from the Megapacks, enhancing the reliability and resilience of the local energy supply for all customers.
Engineering the AI Engine: Coherence at Unprecedented Scale
The engineering challenge of building a system like Colossus extends far beyond simply supplying power and cooling.
The true complexity lies in making over 100,000 individual GPUs operate as a single, coherent supercomputer—an "AI engine" capable of training models with hundreds of billions or even trillions of parameters. This requires a deeply integrated stack of hardware, networking, and software, all co-designed to solve one of the most demanding computational problems in the world. Understanding this stack is crucial, as it reveals that the physical infrastructure is not just a container for the compute, but an active and essential component of the computational architecture itself.
The Interconnect Fabric: The System's Nervous System
At the heart of any large-scale GPU cluster is the interconnect fabric—the network that allows the GPUs to communicate. A GPU is useless if it is starved of data, and at this scale, the communication bottleneck, not raw processing power, becomes the primary limiting factor on performance. The Colossus architecture, like other modern AI supercomputers, employs a sophisticated, hierarchical networking strategy to overcome this barrier.
Intra-Node Communication (The Spinal Cord): Within a single server chassis, which typically houses eight GPUs, communication is handled by NVIDIA's NVLink technology. NVLink is a direct, point-to-point interconnect between GPUs, offering staggering bandwidth—up to 1.8 TB/s in its latest generation. This is orders of magnitude faster than the standard PCIe bus. Its most critical function is enabling a unified, coherent memory space across all GPUs in the node, allowing them to share data and work on parts of the same problem as if they were a single, massive GPU. This high-speed, low-latency connection is the bedrock upon which fine-grained parallelization strategies are built.
Inter-Node Communication (The Global Network): To connect the thousands of individual server nodes into a single cluster, a different networking technology is required. This layer is typically built using either InfiniBand or high-performance, AI-optimized Ethernet, such as NVIDIA's Spectrum-X platform. These technologies are designed for the massive scale and low-latency requirements of supercomputing. They feature critical capabilities like
Remote Direct Memory Access (RDMA), which allows a GPU on one server to directly access the memory of a GPU on another server, bypassing the CPUs and operating systems on both ends, dramatically reducing communication overhead and latency.The network topology is also meticulously designed, often using a "fat-tree" or "dragonfly" architecture to ensure that any two nodes in the cluster can communicate with high bandwidth and a minimal number of "hops".
This hierarchical design—NVLink for dense, local communication and InfiniBand/Ethernet for sprawling, global communication—is not an accident. It is a physical architecture that is co-designed to mirror the structure of the parallelization algorithms that run on it.
The Software Stack and Parallelization Strategies: The System's Brain
The hardware is only half of the equation. The "engineering art", lies in the software orchestration layer that makes all these disparate components work in concert. For Grok, xAI developed a custom training stack built on the JAX and Rust programming languages. This choice signals a focus on performance and low-level control, moving beyond more common frameworks like PyTorch to wring every last drop of efficiency out of the hardware.
The open-sourced architecture of the Grok-1 model reveals a 314-billion-parameter Mixture-of-Experts (MoE) design. In an MoE model, only a fraction of the model's total parameters (or "experts") are activated for any given input, making it more computationally efficient to train and run than a dense model of the same size. To train such a massive model, a combination of four distinct parallelization strategies must be employed simultaneously, as illustrated in the conceptual flow diagram below.
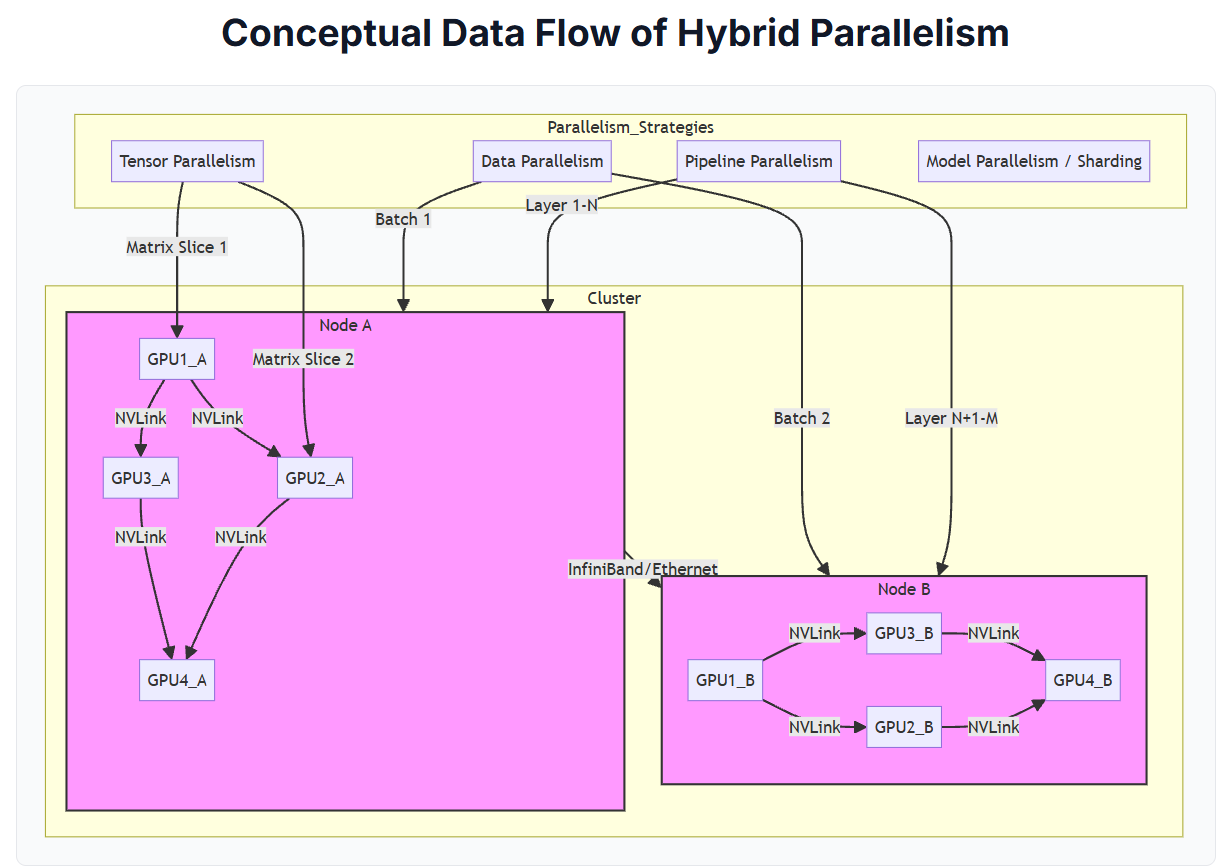
Figure 1: Conceptual Data Flow of Hybrid Parallelism. This diagram illustrates how different parallelization strategies map onto the physical hardware. Data Parallelism distributes data batches across nodes. Pipeline Parallelism assigns different model layers to different nodes. Tensor Parallelism splits individual computations across GPUs within a node via high-speed NVLink. Model Parallelism (not explicitly drawn) involves sharding the model's weights across all available GPUs.
Data Parallelism: The simplest form, where the model is replicated on each node (or group of nodes), and each node processes a different batch of training data.
Pipeline Parallelism: The model's layers are split sequentially across different nodes. Node A processes the first set of layers and passes its output to Node B, which processes the next set, and so on, creating a "pipeline."
Tensor Parallelism: This is the most fine-grained approach, where a single mathematical operation (like a large matrix multiplication) is split across multiple GPUs within a single node. This is only possible because of the extreme bandwidth of NVLink.
Model Parallelism (or Sharding): The model's parameters (weights) are themselves too large to fit in a single GPU's memory. They are "sharded" or distributed across the memory of all GPUs in the cluster.
Mastering the interplay of these four strategies is the core software challenge of large-scale AI. The optimal strategy is a complex function of the model architecture, the hardware, and the specific network topology. This is the essence of hardware/software co-design: the system is designed as a holistic unit, where every layer of the stack is optimized with an awareness of the layers above and below it.16
The Imperative of Resilience
Finally, at the scale of a 100,000-GPU cluster, the engineering paradigm must shift fundamentally from optimizing for pure performance to optimizing for resilience. In a system of this size, "something fails every few minutes". These are not rare events; they are a constant operational reality. Failures can range from a single GPU memory error to a faulty network link or a complete server failure.
If a single failure halts the entire training job, days or weeks of computation, costing millions of dollars, could be lost. Therefore, the software stack must be designed with fault tolerance as a primary feature. This involves sophisticated techniques like in-memory checkpointing, where the model's state is frequently saved to allow for a quick restart, and redundant computations that can mask the failure of a single node. The system's scheduler must be intelligent enough to detect a failed node, pull it out of the cluster, and seamlessly re-route work to other available resources without human intervention.
At hyperscale, the most elegant algorithm is worthless if the system that runs it is brittle. The ability to train continuously, despite constant hardware failures, is a profound systems engineering challenge that only a handful of organizations have truly mastered.
For example, for all the outstanding model performance(s) in the GPT models from OpenAI - they rely on hardware cohesion mostly facilitated by Microsoft’s Azure. Or Anthropic from Amazon’s AWS. So what Musk (and his team) achieved scaling Collosus in the time he did, and playing catch-up with his Grok models, has been hands down impressive!
Taming the Inferno: A New Paradigm in Power, Cooling, and Sustainability
The immense computational density of an AI supercomputer like Colossus generates an equally immense amount of heat in a very small space.
Managing this thermal load, along with the volatile power demands, requires a physical engineering approach that is as innovative as the software stack.
Here again, the Colossus project demonstrates a first-principles approach, moving beyond traditional data center designs to create a symbiotic system that optimizes power, cooling, and water usage holistically.
Power Management: Buffering the Spikes
As previously discussed, AI training workloads are intensely "spiky," creating rapid and massive fluctuations in power demand. To manage this, the Colossus facility pairs its on-site gas turbines with a large installation of Tesla Megapacks. These utility-scale battery systems serve as a critical buffer. When the GPUs ramp up for a heavy computation phase, drawing a massive load, the Megapacks can discharge instantly to meet the surge, preventing a sudden shock to either the on-site generators or the local grid. When the computational load drops, the Megapacks can absorb surplus power from the generators, recharging in preparation for the next spike. This active power management system smooths the data center's overall load profile, making it a much more stable and predictable partner for the utility grid while ensuring the compute cluster always has the instantaneous power it requires.
Advanced Cooling: From Air to Liquid
Traditional data centers rely on air cooling, using massive computer room air conditioning (CRAC) units to chill the entire volume of the data hall—a brute-force and highly inefficient approach. For the extreme compute density of AI servers, where a single rack can draw over 100 kW of power, air cooling is simply no longer viable.
Colossus instead employs a direct-to-chip (DLC) liquid cooling system, provided by Supermicro. In a DLC system, liquid coolant is circulated through pipes directly to "cold plates" that sit on top of the hottest components—the GPUs and CPUs. The liquid absorbs heat far more efficiently than air and carries it away to be cooled externally. This approach offers transformative benefits, as detailed in Table 2.
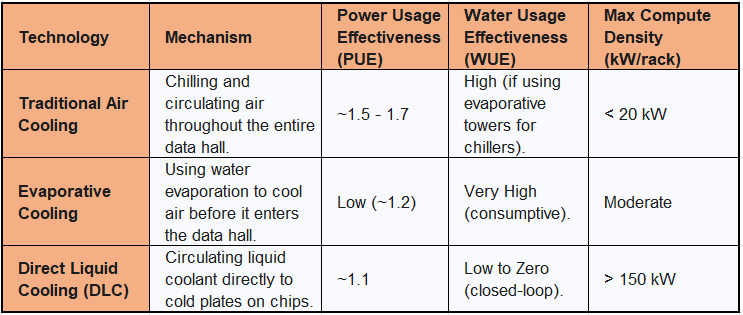
The efficiency gains are dramatic. Supermicro's DLC solutions can reduce a data center's total power consumption by up to 40% by eliminating the need for energy-intensive CRAC units and chillers. Furthermore, because liquid cooling is so effective, it can operate with warmer water—up to 45°C (113°F). This means that in many climates, the heat can be rejected to the ambient air using simple dry coolers, drastically reducing or even eliminating the need for evaporative cooling towers and their associated water consumption. This direct link between cooling technology and efficiency in both power and water consumption is a cornerstone of modern, sustainable data center design.
The Water Solution: Engineering a Sustainable Source
The most profound innovation in the Colossus physical plant, however, is its solution to the water problem. Data center water consumption is a major source of environmental concern and community opposition, particularly in water-scarce regions. The initial plans for Colossus, which projected a water demand of over 5 million gallons per day, drew intense criticism in Memphis, a city that prides itself on the purity of its drinking water drawn from the Memphis Sands Aquifer.
xAI's response is a masterclass in engineering a solution that transforms a critical liability into a sustainable asset. The company built the world's largest ceramic membrane bioreactor (MBR) on-site. This state-of-the-art facility will take untreated municipal wastewater from a neighboring treatment plant and purify it to a standard suitable for use in the data center's cooling loops. The system is designed to supply up to 13 million gallons per day (MGD) of recycled water.
The strategic implications of this are immense. First, it completely decouples the data center's operations from the local potable water supply, neutralizing the primary environmental and political objection to the project. Second, the MBR plant is deliberately oversized. It produces more treated water than Colossus itself requires, with the surplus being made available to other local industries. This creates a positive externality, actively reducing the overall industrial draw on the precious Memphis aquifer and turning xAI's infrastructure into a shared community resource. This is a third-order engineering solution: it solves the technical cooling problem, it resolves the political water-rights problem, and it creates a net environmental benefit for the entire region.
This is not to say the project's execution has been flawless. The "move fast and break things" approach, particularly the initial deployment of unpermitted gas turbines, broke community trust and resulted in significant, valid backlash over air quality, noise, and a lack of transparency in a historically disadvantaged, majority-Black community. This experience serves as a crucial lesson: the "engineering problem" of scaling AI is not confined to watts and water flow. It must also encompass social and political engineering. A truly scalable and replicable blueprint must integrate community engagement, regulatory strategy, and environmental justice as core design requirements from the outset, not as reactive measures after the fact. Nonetheless, the proactive and ambitious engineering of the water and grid solutions demonstrates a commitment to solving these complex challenges at a fundamental level.
The Path Forward: A Replicable Blueprint for an Era of Abundant Compute
The Colossus project is more than just a single data center; it is a prototype for a new model of AI infrastructure development. By synthesizing the lessons learned in Memphis, we can derive a replicable blueprint that not only addresses the energy challenge but also paves the way for a future of abundant, sustainable compute. This blueprint is built on two core principles: transforming the data center from a grid liability into a grid asset, and embracing the next generation of power technology to achieve true energy independence.
The Data Center as a Grid Asset
The traditional relationship between a data center and a utility is parasitic; the data center is a massive, unpredictable load that strains the grid. The Colossus model inverts this relationship, transforming the data center into an active, symbiotic partner. With its on-site, rapid-response generation (gas turbines), integrated energy storage (Tesla Megapacks), and sophisticated control systems, the data center is uniquely positioned to provide valuable grid stabilization services.
These services, often grouped under the umbrella of Demand Response, allow the data center to modulate its power consumption and even export power back to the grid to help maintain stability. For example:
Peak Shaving: During periods of high regional demand (e.g., a hot summer afternoon), the data center can disconnect from the utility and run entirely on its own generation, reducing the overall peak load that the utility must serve.
Frequency Regulation: The grid must maintain a precise frequency (60 Hz in the U.S.). Deviations can cause instability. The data center's batteries can charge or discharge in milliseconds to absorb or inject power, helping to smooth out these fluctuations.
Spinning Reserve: The on-site turbines can be kept in a "spinning" state, ready to ramp up to full power in seconds to cover for the unexpected failure of a large power plant elsewhere on the grid.
By participating in these markets, the data center not only enhances grid reliability for all users but also creates a new revenue stream, monetizing its investment in power infrastructure. This transforms the data center from a simple cost center into a dynamic energy asset.
The Nuclear Endgame: Small Modular Reactors
While on-site gas turbines provide an effective solution today, the ultimate endgame for providing clean, reliable, 24/7 baseload power for AI is nuclear energy, specifically Small Modular Reactors (SMRs). SMRs represent a paradigm shift in nuclear technology, moving away from massive, bespoke, site-built plants toward smaller, factory-produced, and scalable modules.
Their suitability for powering AI data centers is unparalleled:
Reliable Baseload Power: SMRs operate with capacity factors exceeding 90%, providing the constant, carbon-free power that AI workloads require, independent of weather conditions.
Small Footprint: An SMR power plant requires a fraction of the land area of a solar or wind farm of equivalent effective capacity, making it ideal for co-location with a data center campus.
Scalability: The modular design allows capacity to be added incrementally—a 300 MW module at a time—perfectly matching the phased growth of a data center.
The technology and commercial momentum are building rapidly. NuScale Power's design was the first to receive certification from the U.S. Nuclear Regulatory Commission (NRC), and the first commercial units are expected to come online around 2030. Major technology companies are already making strategic moves, with Microsoft, Google, and Amazon all signing deals to procure nuclear power for their data centers.
Economically, SMRs are projected to be highly competitive. While first-of-a-kind units will be expensive, analyses project a Levelized Cost of Energy (LCOE) in the range of $40 to $90 per MWh for mature deployments. This is competitive with natural gas and becomes highly favorable when compared to the full system cost of intermittent renewables, which must include the added expense of long-duration energy storage and expanded transmission infrastructure.
The primary obstacle remains regulatory. The current licensing framework was designed for large, traditional reactors, and adapting it for SMRs is a complex and lengthy process, despite efforts like the NRC's proposed "Part 53" rule to create a new, risk-informed framework.
The true significance of the Colossus blueprint becomes clear in this context. The operational model being pioneered today with on-site gas and batteries is a perfect transitional architecture for a future powered by SMRs. It establishes the paradigm of behind-the-meter, baseload generation with integrated storage for load balancing and grid services. A utility can forge a partnership with a data center using this model today. When SMRs become commercially viable post-2030, the gas turbines can be swapped out for SMR modules with minimal disruption to the established operational and business relationship. The engineering and strategic groundwork being laid now directly paves the way for the nuclear-powered AI factories of tomorrow.
The Relentless Focus on Engineering Velocity & Verticle Integration
The narrative of an impending AI energy crisis is built on a fragile premise: that we will continue to build the future's infrastructure using the methods of the past. The evidence from the xAI Colossus project fundamentally challenges this premise. It demonstrates that when approached from first principles, with a relentless focus on engineering velocity and vertical integration, the perceived barriers of power, permitting, and physical construction can be overcome at a speed previously thought impossible.
This is not merely about building faster; it is about thinking differently. It is about treating infrastructure as a dynamic, adaptable system, not a static monument. It is about internalizing external dependencies and engineering holistic solutions that span from the power plant to the software stack. It is about transforming liabilities, be they grid instability or environmental impact, into strategic assets through superior engineering. And this actually makes me quite hopeful about the future of AI.
The ultimate scaling law for Artificial Intelligence will not be defined by computational theory alone. It will be a co-design loop that tightly integrates the AI models themselves, the specialized hardware they run on, and the physical infrastructure—the power, cooling, and networking—that underpins it all. The companies that will lead this new industrial revolution are those that master this full-stack engineering challenge. The "energy crisis" is, in reality, an engineering execution deficit. The Colossus blueprint, for all its contentious beginnings, provides a powerful and tangible roadmap for how to close that gap. The future of AI will not be limited by a lack of power, but by a lack of will to engineer the systems that can deliver it.
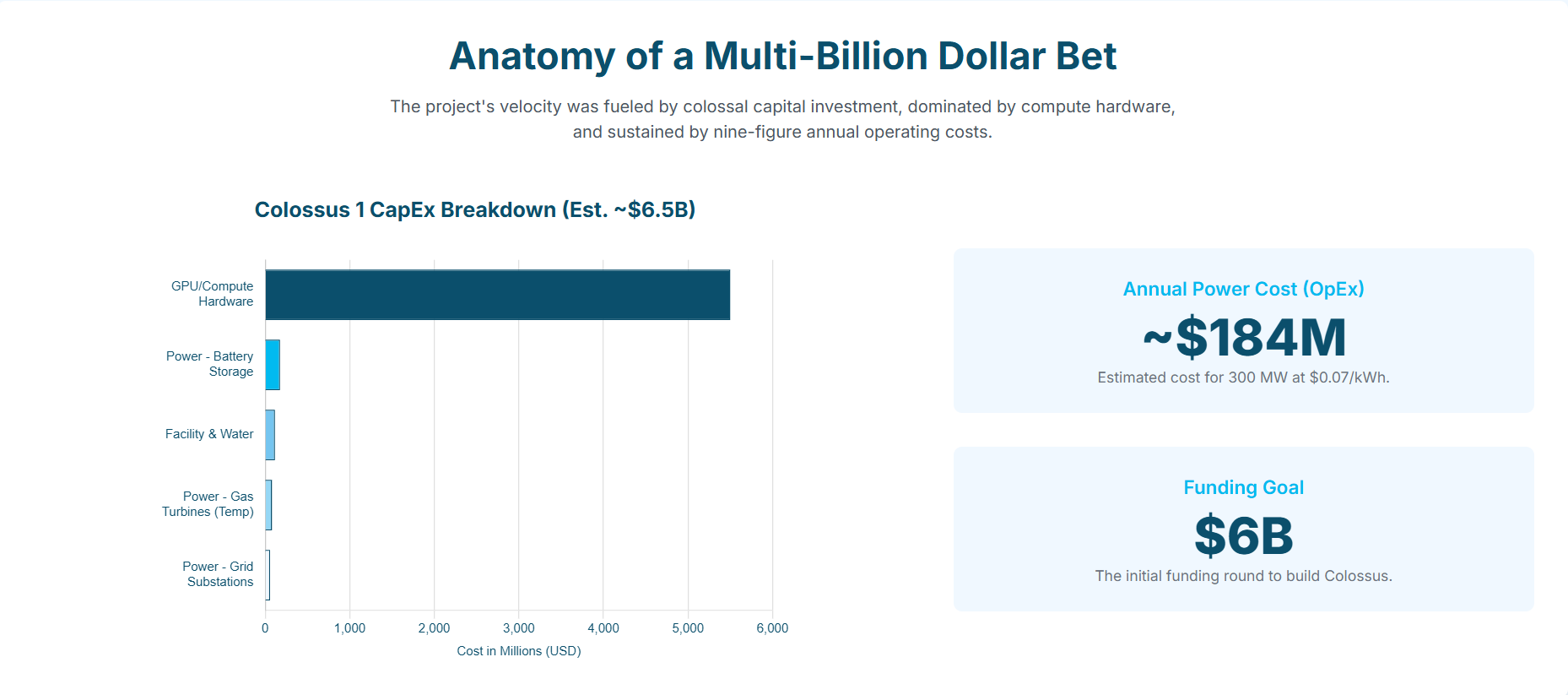
An Estimated Financial Breakdown of Project Colossus
So how much for such high-levels of engineering pursuit? The construction and operation of the Colossus supercomputer represents a financial undertaking of immense scale, involving multi-billion-dollar capital expenditures and nine-figure annual operating costs. This section attempts to break down the key financial components of the project, fueled by one of the most aggressive fundraising campaigns in the technology sector.
Capital Expenditures (CapEx): Deconstructing the Multi-Billion-Dollar Investment
The primary driver of capital expenditure for Project Colossus is the procurement of advanced computing hardware, followed by significant investments in the facility and its supporting power infrastructure.
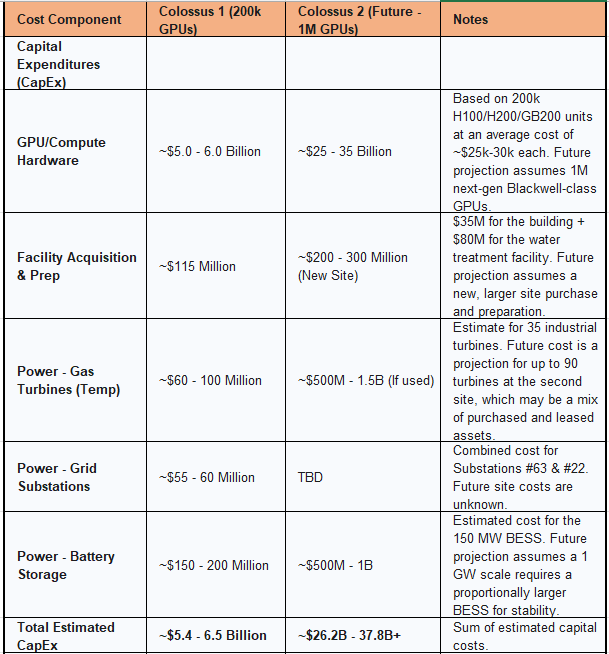
Compute Hardware (GPUs): This category constitutes the single largest expense. For Phase 1, which initially involved 100,000 NVIDIA H100 GPUs, the cost of the processors alone is estimated at approximately $2.5 billion, based on a market price of around $25,000 per unit. The total cost for the complete Phase 1 build-out, including the servers, high-speed networking fabric, storage, and other essential hardware, is estimated to be between $3 billion and $4 billion. The
Phase 2 expansion to 200,000 total GPUs was described as another "multibillion-dollar deal," with the final cost contingent on the specific mix of H100, H200, and newer GB200 chips procured.Facility Acquisition and Retrofit: xAI's decision to utilize a brownfield site provided significant time savings but still required substantial investment. The company purchased the 785,000-square-foot former Electrolux factory for $35 million. To support the immense cooling requirements of the supercomputer, which are projected to reach 1 million gallons of water per day, xAI also planned its build of a dedicated wastewater processing and "greywater" facility at an additional cost of $80 million.
Infrastructure Investment: The Cost of On-Site Generation and Grid Interconnection
A unique aspect of Colossus's financial profile is the massive investment in what was initially a "temporary" power solution, alongside the permanent grid infrastructure.
Gas Turbines: The cost of the on-site gas turbine fleet represents a significant, and highly unusual, capital outlay for a data center. Based on publicly available market pricing for new 2.5 MW mobile natural gas generators, which can be around $1.7 million per unit, the initial deployment of 14 units would have cost approximately $24 million. Scaling the fleet to 35 units could have pushed this capital cost to nearly $60 million. If the larger, 12 MW industrial turbines were used to reach the 422 MW capacity, the investment would be substantially higher. For context, building a new, permanent 422 MW gas-fired power plant at current industry rates of roughly $2,400 per kilowatt would cost over $1 billion. This comparison starkly illustrates why xAI opted for the logistically complex but more rapidly deployable (and likely leased or second-hand) mobile and industrial units, despite their lower efficiency.
Grid Substations: xAI is directly funding the construction of its permanent grid connections. The company pays for the construction of the 150 MW Substation #63, a project with an estimated cost of $24 million, for which it will be gradually reimbursed by MLGW through credits on its monthly power bills. Reports also indicate a total commitment of $55 million for the two substations ($35 million for the first and $20 million for the second), making the total investment in grid interconnection approximately $55-60 million.
Battery Storage: The 150 MW Tesla Megapack BESS represents another major capital investment. While the exact price is not public, based on industry data for similar utility-scale battery projects, the cost for a system of this size and capacity (likely around 300 MWh, assuming a 2-hour duration) is estimated to be in the range of $150 million to $200 million.
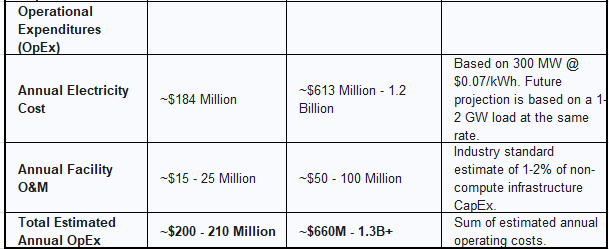
Operational Expenditures (OpEx): Estimating the Annual Cost of Power
Once operational, the single largest recurring cost for the Colossus facility is electricity. At its full planned capacity of 300 MW for the Colossus 1 site, the supercomputer will be a voracious consumer of energy.
A straightforward calculation reveals the scale of this operational expense:
Annual energy consumption: 300 MW×8,760 hours/year=2,628,000 MWh/year
Assuming a conservative, negotiated industrial electricity rate of $0.07 per kWh (or $70 per MWh), the estimated annual electricity bill for the fully operational Colossus 1 facility is approximately $184 million.
This figure is broadly consistent with other industry estimates. An analysis found on a public forum, after correcting for a calculation error in the original post, suggested that a 100 MW data center paying a very low rate of $0.05 per kWh would have an annual power bill of around $44 million.42 Extrapolating this to 300 MW yields an annual cost of $132 million, making the $184 million estimate based on a more typical industrial rate highly plausible.
Funding the Ambition: An Overview of xAI's Capital Raises
The colossal expenditures on Project Colossus are being fueled by an equally colossal fundraising effort, positioning xAI as one of the most capital-intensive startups in history.
After an initial raise of $134.7 million in late 2023, xAI launched a major funding round in May 2024, seeking $6 billion at an $18 billion valuation. This capital was earmarked for the initial build-out of Colossus and the acquisition of GPUs. However, the financial demands have continued to escalate. More recent reports indicate that xAI is seeking up to $12 billion in additional funding to finance the development of the even larger Colossus 2 facility.
The company's burn rate reflects this aggressive investment cycle. Projections show that xAI could spend approximately $13 billion in the year 2025 alone, a figure that underscores the immense and ongoing cash flow required to build and operate AI infrastructure at the frontier of the industry.
Estimated Cost Analysis for Colossus (Phases 1 & 2):
The Future Trajectory: Colossus 2 and the Quest for Gigawatt-Scale AI
The completion of the 300 MW Colossus 1 facility is not the endpoint of xAI's ambition, but rather a stepping stone towards a future of truly gigawatt-scale AI. The company's future plans involve a second, even larger supercomputer and a radical approach to securing the vast amounts of power required, signaling a fundamental shift in the relationship between technology companies and the energy sector.

The Million-GPU Supercluster: Projecting the Power and Cost of Colossus 2
xAI is already moving forward with plans for a second massive data center in Memphis, located in the Whitehaven neighborhood and referred to as "Colossus 2". This facility is designed to dwarf its predecessor in both computational power and energy consumption.
The initial plans for Colossus 2 call for the installation of 550,000 NVIDIA GB200 and GB300 chips, which would bring xAI's total operational cluster to well over 750,000 GPUs. This is part of a broader ambition to scale the Memphis supercluster to over 1 million total GPUs.
The power requirements for such a facility are staggering. Based on the power consumption of next-generation NVIDIA Blackwell-series GPUs and a standard Power Usage Effectiveness (PUE) ratio of 1.4 to account for cooling and other overhead, a 1-million-GPU cluster is projected to consume between 1,000 MW (1 GW) and 1,960 MW (1.96 GW) of continuous power. This power draw is equivalent to the output of one to two full-scale nuclear power plants and represents a significant fraction of the entire peak energy demand of the city of Memphis.
To meet this extraordinary demand, documents obtained by environmental groups reveal that xAI is evaluating the installation of between 40 and 90 methane gas turbines at the Colossus 2 site. This on-site power plant would be capable of generating up to 1.56 GW of electricity, once again using fossil-fuel-based generation as a means to achieve speed and bypass grid constraints.
The Imported Power Plant: A Radical Solution to the National Energy Bottleneck
The most dramatic element of xAI's future energy strategy is the confirmed plan to purchase an entire power plant from an overseas location and physically ship it to the United States. This unprecedented logistical maneuver is a direct response to a fundamental bottleneck in the domestic energy landscape.
The plant is reported to be a 2 GW natural gas combined-cycle gas turbine (CCGT) facility. The strategic rationale behind this move is singular: speed. The permitting, approval, and construction process for a new utility-scale power plant in the U.S. is a protracted affair that can easily take five to ten years. For a company operating on the aggressive timelines of the AI industry, such a delay is untenable. Importing a pre-existing or modular power plant, while logistically daunting and fraught with its own regulatory hurdles, is seen as a viable, if extreme, method to circumvent this multi-year bottleneck and secure a dedicated, gigawatt-scale power source on a compressed timeline.
The recently released AI Action Plan points to removing many of these bottlenecks - a boon for Musk’s daring import plan.
This decision marks a pivotal moment. It signifies a paradigm shift where a technology company, driven by its insatiable demand for power, is forced to vertically integrate into utility-scale energy production and international logistics. xAI is no longer just a consumer of electricity; it is actively becoming a private, grid-scale power generator. This transforms the company into a de facto unregulated industrial utility, a development with profound implications for energy markets, regulatory oversight, and national infrastructure policy. The financialization of compute (and of course energy - which is already relevant) compounds the benefits for financial market participants. I can imagine many trading desks already seeing the evolution and planning big for this.
The 50 Million GPU Horizon: Projecting Future Power Needs and the Limits of Scaling
Beyond Colossus 2, Elon Musk has articulated a far grander, long-term vision for xAI: to deploy the equivalent of 50 million H100 GPUs for AI compute within five years.
While future generations of GPUs will undoubtedly offer greater computational performance per watt, the sheer scale of this ambition pushes the boundaries of what is physically and economically feasible. A literal deployment of 50 million H100-class processors would consume a staggering 35 GW of power. Even accounting for aggressive efficiency gains in future hardware generations (such as NVIDIA's speculative "Rubin" and "Feynman" architectures), analysts project that a cluster with 50 million H100-equivalents of compute power would still require between 4.5 GW and 9.5 GW of electricity. This is an amount of power equivalent to the output of four to nine modern nuclear power reactors, dedicated to a single company's AI initiatives.
Achieving this level of power procurement and delivery presents a monumental challenge that may define the ultimate limits of scaling AI using current technological paradigms. It raises interesting insights and of course fundamental questions about engineering the AI Stack, global energy supply, resource allocation, and the environmental cost of pursuing artificial general intelligence. Seeking dominance (in any field), has it’s price to pay….
References:
An analysis of how collosus was built and contrast - my notes
Inside the 100K GPU xAI Colossus Cluster that Supermicro Helped Build for Elon Musk - Page 4 of 4 - ServeTheHome, https://www.servethehome.com/inside-100000-nvidia-gpu-xai-colossus-cluster-supermicro-helped-build-for-elon-musk/4/
NAACP to sue xAI over Memphis data center pollution | AFRO American Newspapers, https://afro.com/xai-data-center-pollution-lawsuit/
A Memphis Community's Clean Air Battle With Elon Musk's xAI Supercomputer, https://www.momscleanairforce.org/xai-in-memphis/
Large-Scale GPU Clusters based on Silicon Photonic Network | imec, https://www.imec-int.com/en/work-at-imec/job-opportunities/large-scale-gpu-clusters-based-silicon-photonic-network
What is the Difference Between NVLink and InfiniBand? | AI FAQ - Jarvis Labs, https://jarvislabs.ai/ai-faqs/what-is-the-difference-between-nvlink-and-infiniband
The Ultimate Guide to Nvidia NVLink: Maximizing GPU Performance - FiberMall, https://www.fibermall.com/blog/nvidia-nvlink.htm
GPU Cluster Explained: Architecture, Nodes and Use Cases - Scale Computing, https://www.scalecomputing.com/resources/what-is-a-gpu-cluster
How Ethernet Outpaces InfiniBand in AI Networking - fibermall.com, https://www.fibermall.com/blog/how-ethernet-outpaces-infiniband-in-ai.htm
NVIDIA HGX Platform, https://www.nvidia.com/en-us/data-center/hgx/
Why do you need Infiniband for Large Scale GPU Clusters… | by Shubham Mishra - Medium, https://medium.com/@shubhammishra892/why-would-you-need-infiniband-for-large-scale-gpu-clusters-07929ede7e59
Open Release of Grok-1 - xAI, https://x.ai/news/grok-os
xai-org/grok-1: Grok open release - GitHub, https://github.com/xai-org/grok-1
Distributed Training: Guide for Data Scientists - neptune.ai, https://neptune.ai/blog/distributed-training
Infra for Distributed Model Training of LLM: Part One— Parallel-Training | by ming gao, https://medium.com/@ming.gao.gm/distributed-model-training-at-scale-part-one-parallel-training-9a96508c741f
AI and Systems Co-Design, https://aisystemcodesign.github.io/
Software-Hardware Co-design for Fast and Scalable Training of Deep Learning Recommendation Models - arXiv, https://arxiv.org/pdf/2104.05158
AI HW SW CoDesign - Open Compute Project, https://www.opencompute.org/projects/ai-hw-sw-codesign
Revisiting Reliability in Large-Scale Machine Learning Research Clusters - arXiv, https://arxiv.org/html/2410.21680v1
Fault-Tolerant Hybrid-Parallel Training at Scale with Reliable and Efficient In-memory Checkpointing - arXiv, https://arxiv.org/html/2310.12670v3
Build a Customizable HPC Platform With Enhanced GPU Fault Tolerance S72096 | GTC 2025 | NVIDIA On-Demand, https://www.nvidia.com/en-us/on-demand/session/gtc25-s72096/
Efficiently Scale LLM Training Across a Large GPU Cluster with Alpa and Ray, https://developer.nvidia.com/blog/efficiently-scale-llm-training-across-a-large-gpu-cluster-with-alpa-and-ray/
How xAI turned a factory shell into an AI 'Colossus' for Grok 3 - R&D World, https://www.rdworldonline.com/how-xai-turned-a-factory-shell-into-an-ai-colossus-to-power-grok-3-and-beyond/
xAI Colossus - Supermicro, https://www.supermicro.com/en/featured/xai-colossus
Inside the 100K GPU xAI Colossus Cluster that Supermicro Helped Build for Elon Musk, https://www.supermicro.com/CaseStudies/Success_Story_xAI_Colossus_Cluster.pdf
Liquid Cooling for Supermicro Servers, https://www.supermicro.com/white_paper/white_paper_Liquid-Cooling-Solutions.pdf
A guide to data center cooling: Future innovations for sustainability - Digital Realty, https://www.digitalrealty.com/resources/articles/future-of-data-center-cooling
What cooling systems are commonly used in hyperscale data centers? - Quora, https://www.quora.com/What-cooling-systems-are-commonly-used-in-hyperscale-data-centers
Data Center Water Usage: A Comprehensive Guide - Dgtl Infra, https://dgtlinfra.com/data-center-water-usage/
Modern datacenter cooling, https://datacenters.microsoft.com/wp-content/uploads/2023/05/Azure_Modern-Datacenter-Cooling_Infographic.pdf
supermicro dlc-2 architecture reduces data center power, space, water, and costs, https://www.supermicro.com/white_paper/White_Paper_Supermicro_DLC-2.pdf
Supermicro's DLC-2, the Next Generation Direct Liquid-Cooling Solutions, Aims to Reduce Data Center Power, Water, Noise, and Space, Saving on Electricity Cost by up to 40%, and Lowering TCO by up to 20% - The Tribune, https://www.tribuneindia.com/news/business/supermicros-dlc-2-the-next-generation-direct-liquid-cooling-solutions-aims-to-reduce-data-center-power-water-noise-and-space-saving-on-electricity-cost-by-up-to-40-and-lowering-tco-by-up-to-2/
Supermicro DLC-2 Cuts Data Center Power Costs 40% With Next-Gen Liquid Cooling | SMCI Stock News, https://www.stocktitan.net/news/SMCI/supermicro-s-dlc-2-the-next-generation-direct-liquid-cooling-q2fbshwnzhj9.html
Supermicro's new Liquid Cooling Solution for AI Data Centres - AI Magazine, https://aimagazine.com/articles/supermicros-plans-to-scale-technology-for-ai-data-centres
A typical data centre can use between 11 million and 19 million litres of water per day., https://www.reddit.com/r/datacenter/comments/1ijrjns/a_typical_data_centre_can_use_between_11_million/
Data Centers and Water Consumption | Article | EESI, https://www.eesi.org/articles/view/data-centers-and-water-consumption
Data centers draining resources in water-stressed communities - The University of Tulsa, https://utulsa.edu/news/data-centers-draining-resources-in-water-stressed-communities/
xAI Supercomputer - Protect our Aquifer, https://www.protectouraquifer.org/issues/xai-supercomputer
Elon Musk's supercomputer sparks Memphis water supply concerns, https://waterdaily.com/elon-musks-supercomputer-sparks-memphis-water-supply-concerns/
XAI Campus in Memphis May Use 1M Gallons of Auqifer Drink Water per Day | Hacker News, https://news.ycombinator.com/item?id=40604287
The AI energy crisis: Why chatbots are using up our drinking water - Finextra Research, https://www.finextra.com/the-long-read/1411/the-ai-energy-crisis-why-chatbots-are-using-up-our-drinking-water
Elon Musk's xAI Announces "Sustainable" Cooling Technology for Memphis Data Center Amid Environmental Criticism - AInvest, https://www.ainvest.com/news/elon-musk-xai-announces-sustainable-cooling-technology-memphis-data-center-environmental-criticism-2507/
Elon Musk's xAI Unveils 'Sustainable' Way To Cool Memphis Data Center - Dailymotion, https://www.dailymotion.com/video/x9n700e
CERAFILTEC partners with xAI for the world's largest AI supercomputer data centre and ceramic MBR | Water & Wastewater Asia, https://waterwastewaterasia.com/cerafiltec-partners-with-xai-for-the-worlds-largest-ai-supercomputer-data-centre-and-ceramic-mbr/
xAI unveils ceramic membrane bioreactor cooling system for Memphis data center, https://sp-edge.com/updates/47637
xAI and CERAFILTEC partner for sustainable water at the world's largest AI data center, https://smartwatermagazine.com/news/smart-water-magazine/xai-and-cerafiltec-partner-sustainable-water-worlds-largest-ai-data-center
CERAFILTEC and xAI Cooperate in Sustainable Water Management for the World's Largest AI Supercomputer Data Center and Ceramic MBR, https://www.cerafiltec.com/cerafiltec-and-xai-worlds-largest-ai-supercomputer-data-center-and-ceramic-mbr/
Elon Musk's xAI Unveils 'Sustainable' Way To Cool Memphis Data Center Amid Criticism From Environmental Rights Groups - Webull, https://www.webull.com/news/13180748490499072
“Musk Is Scamming the City of Memphis”: Meet Two Brothers Fighting Colossus, Musk's xAI Data Center | Democracy Now!, https://www.democracynow.org/2025/4/25/elon_musk_xai_memphis_tennessee
Memphis residents fight xAI expansion over pollution, health fears - Straight Arrow News, https://san.com/cc/memphis-residents-fight-xai-expansion-over-pollution-health-fears/
xAI's Memphis Neighbors Push for Facts and Fairness | TechPolicy.Press, https://www.techpolicy.press/xais-memphis-neighbors-push-for-facts-and-fairness/
xAI Brings the “Move Fast and Break Things” Mindset to Memphis, https://cleanenergy.org/news/xai-brings-the-move-fast-and-break-things-mindset-to-memphis/
Evolving data centers into valuable grid assets: the power of demand response, https://www.enelnorthamerica.com/insights/blogs/evolving-data-centers-into-grid-assets
Rebuttal: Data Centers as Grid Assets, Not Liabilities | Enchanted Rock, https://enchantedrock.com/rebuttal-data-centers-as-grid-assets-not-liabilities/
Grid Intelligence: The Unsung Role of Data Centers in Power Resilience, https://www.datacenterfrontier.com/energy/article/55292788/grid-intelligence-the-unsung-role-of-data-centers-in-power-resilience
How data centers support the power grid with ancillary services? | Enel X Taiwan, https://www.enelx.com/tw/en/resources/how-data-centers-support-grids
How data centers facilitate the clean energy transition and help grid reliability while doing it, https://www.renewableenergyworld.com/power-grid/how-data-centers-facilitate-the-clean-energy-transition-and-help-grid-reliability-while-doing-it/
Data Centers as a Grid - Eaton, https://www.eaton.com/us/en-us/company/news-insights/energy-transition/data-centers-as-a-grid.html
3 Steps to Turning Data Center Energy Hogs Into Grid Assets - Tech Insights - EEPower, https://eepower.com/tech-insights/3-steps-to-turning-data-center-energy-hogs-into-grid-assets/
Dynamic Grid Support: How UPS systems in data centres are balancing energy use, https://interface.media/blog/2024/06/14/dynamic-grid-support-how-ups-systems-in-data-centres-are-balancing-energy-use/
Sustainable Grid through Distributed Data Centers Spinning AI Demand for Grid Stabilization and Optimization© 2025 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale - arXiv, https://arxiv.org/html/2504.03663v1
Nuclear energy's role in powering data center growth - Deloitte, https://www.deloitte.com/us/en/insights/industry/power-and-utilities/nuclear-energy-powering-data-centers.html
Addressing the Data Center Energy Crisis with SMRs | by CELI - Medium, https://medium.com/@celions/addressing-the-data-center-energy-crisis-with-smrs-165887f36c7c
White paper argues for SMRs over renewables for data centers - American Nuclear Society, https://www.ans.org/news/article-6460/white-paper-argues-for-smrs-over-renewables-for-data-centers/
On-Site Nuclear Power: SMRs Create New Opportunities for Colocation Data Centers, https://www.lastenergy.com/blog/smrs-colocation-data-centers
What is SMR? The Ultimate Guide to Small Modular Reactors - CarbonCredits.com, https://carboncredits.com/the-ultimate-guide-to-small-modular-reactors/
The Economics of Small Modular Reactors - March 2021 - Nuclear Energy Institute, https://www.nei.org/CorporateSite/media/filefolder/advanced/SMR-Start-Economic-Analysis-2021-(APPROVED-2021-03-22).pdf
NuScale Power - Wikipedia, https://en.wikipedia.org/wiki/NuScale_Power
NuScale Power's Small Modular Reactor (SMR) Achieves Standard Design Approval from U.S. Nuclear Regulatory Commission for 77 MWe, https://www.nuscalepower.com/press-releases/2025/nuscale-powers-small-modular-reactor-smr-achieves-standard-design-approval-from-us-nuclear-regulatory-commission-for-77-mwe
Trump's AI plan calls for massive data centers. Here's how it may affect energy in the US, https://apnews.com/article/trump-artificial-intelligence-energy-data-centers-f216660b80f992ae303b348dac0b2f87
Google Turns to Nuclear to Power Energy-Hungry Data Centers - Earth.Org, https://earth.org/google-turns-to-nuclear-to-power-energy-hungry-data-centers/
Will Small Modular Reactors Surpass Regulatory and Supply Chain Hurdles to Fill the Need for Stable, Baseload Power? | Cleantech Group, https://www.cleantech.com/will-small-modular-reactors-surpass-regulatory-and-supply-chain-hurdles-to-fill-the-need-for-stable-baseload-power/
Generation IV / Economic Modelling Compares Costs Of SMR To Conventional PWR, https://www.nucnet.org/news/economic-modelling-compares-costs-of-smr-to-conventional-pwr-10-4-2020
Nuclear Small Modular Reactors (SMRs) for Data Centers: Transforming Energy Infrastructure in Europe | Platform Markets Group: Remarkable high-end tech events, https://www.platform-markets.com/insights/nuclear-small-modular-reactors-smrs-data-centers-transforming-energy-infrastructure-europe
New Approaches to Meeting Data Centers' Energy Demands: Distributed Energy & Small Modular Reactors, https://www.datacenterfrontier.com/sponsored/article/55277935/new-approaches-to-meeting-data-centers-energy-demands-distributed-energy-small-modular-reactors
How Does SMR Cost Compare to Renewables? - Energy → Sustainability Directory, https://energy.sustainability-directory.com/question/how-does-smr-cost-compare-to-renewables/
www.nuscalepower.com, https://www.nuscalepower.com/exploring-smrs/smr-101/how-smrs-gain-design-approval-in-the-u.s#:~:text=These%20include%20the%20need%20for,protocols%20for%20smaller%2C%20distributed%20reactors.
How SMRs Gain Design Approval in the U.S. | NuScale Power, https://www.nuscalepower.com/exploring-smrs/smr-101/how-smrs-gain-design-approval-in-the-u.s
Think small: Why America should bet on small modular reactors | Utility Dive, https://www.utilitydive.com/news/small-modular-reactors-smr-policy-gaster-itif/749583/
U.S. Nuclear Regulatory Commission Proposes New Licensing Framework for Advanced Reactors | Environmental and Energy Brief, https://environmentalenergybrief.sidley.com/2024/11/08/u-s-nuclear-regulatory-commission-proposes-new-licensing-framework-for-advanced-reactors/