
From BM25 to Agentic RAG: The Evolution of Machine Memory
How retrieval transformed from keyword matching to the cognitive backbone of AI


I used to think about retrieval in the context of “search” e.g. like “google search”, 10 blue links, and I personally considered those more than acceptable - results-wise, they met my requirements. However, today, retrieval has evolved beyond search to become, in essence, the memory architecture of AI.
The story of retrieval is fundamentally the story of how machines learned to remember—and more importantly, how they learned to forget the right things while remembering what matters. What, I guess, began as simple keyword matching has evolved into sophisticated memory systems that rival human cognition in their complexity.
Each breakthrough solving critical problems while revealing new fundamental constraints.
These are a few of my incomplete notes to remind me of the evolutionary road retrieval has taken. I break it down into 6 Modules:
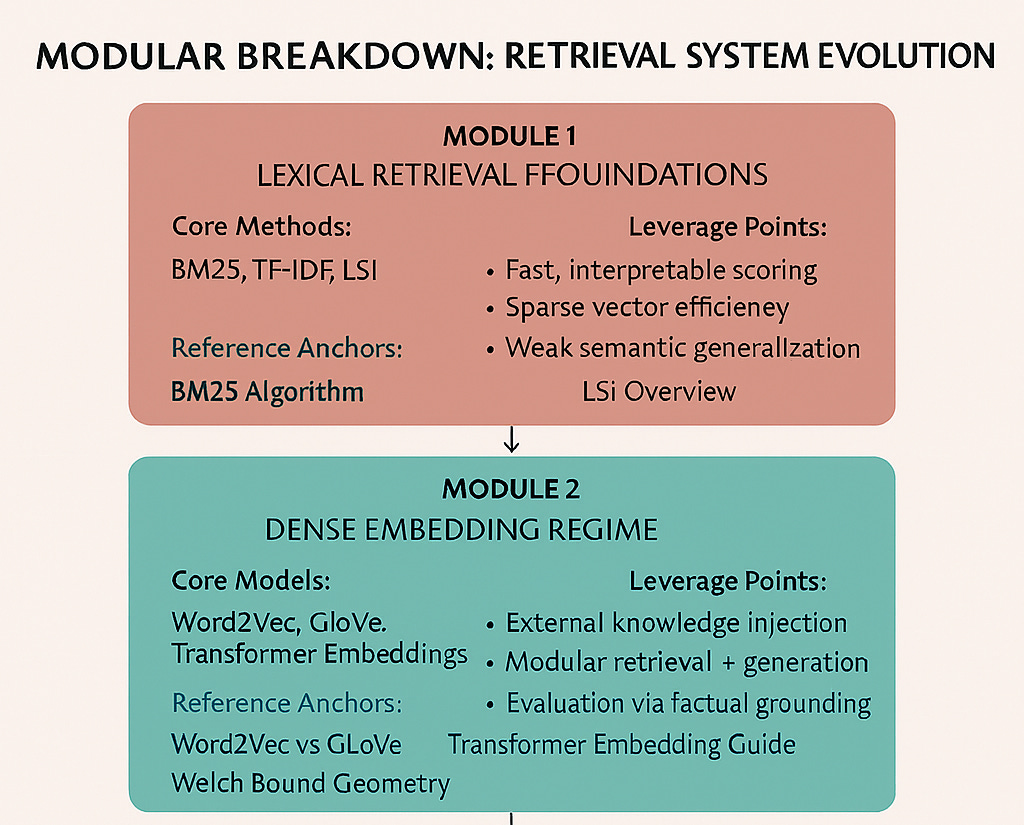


Module A: The Foundation Years
The Era of Exact Matches (1990s-2000s)
In the early days, information retrieval was beautifully simple and frustratingly literal. BM25 (Best Matching 25) dominated the landscape, scoring documents based on term frequency balanced against term rarity across the corpus. The mathematics were elegant: rare terms that appeared frequently in a document signaled relevance.
What worked:
Blazingly fast execution
Perfectly interpretable results
Excellent precision for exact terminology matches
Robust performance on well-defined queries
The cracks:
Catastrophic failure on synonyms and paraphrases
No understanding of semantic relationships
Brittle handling of context and nuance
Consider this often-used example: A user searching for “best pizza in New York” would successfully retrieve “Top 10 Pizza Spots in NYC” but completely miss “Brooklyn’s most acclaimed pizzeria”—even if the second document was objectively more relevant and higher quality.
Latent Semantic Indexing (LSI) emerged as an early attempt to solve semantic blindness. By analyzing statistical co-occurrence patterns across large corpora, LSI could learn that “pizzeria” and “pizza” were semantically related. This was revolutionary—the first system that could capture meaning beyond exact word matches.
But LSI’s statistical approach often created spurious connections. The algorithm might learn to associate “Brooklyn Bridge” with “pizza” simply because both frequently appeared in New York tourism documents, leading to semantically confused results.
These early systems established a pattern that would persist: each solution to retrieval’s problems would introduce new, often subtler challenges.
Module 2: The Geometric Revolution
Embeddings: When Words Became Vectors (2013-2017)
The neural revolution reframed retrieval as a fundamentally geometric problem. Instead of treating words as discrete symbols, Word2Vec and GloVe embedded them as points in high-dimensional space where semantic similarity corresponded to geometric proximity.
The famous example king - man + woman ≈ queen wasn’t just a clever demo—it revealed that relational meaning could be encoded as vector arithmetic. Suddenly, analogies, semantic relationships, and conceptual similarities had mathematical representations.
The breakthrough: Static embeddings captured semantic relationships with unprecedented sophistication. “Car” and “automobile” naturally clustered together, while “bank” (financial) and “bank” (river) remained appropriately distant.
The limitation: Context collapsed. “Bank” had exactly one representation, forcing the model to average across all possible meanings. This worked reasonably well for general queries but failed catastrophically when precision mattered.
Contextual Understanding Arrives (2017+)
And then, came - Transformers solving the context problem by making embeddings dynamic. The same word could have radically different vector representations depending on its surrounding context:
“I deposited money in the bank“ → financial services vector
“We sat by the river bank“ → natural geography vector
This contextual sensitivity enabled semantic search—the ability to match meaning rather than just words. Users could search for “companies with strong environmental practices” and retrieve documents about “corporate sustainability initiatives” even when no exact terms overlapped.
But this sophistication came with new challenges:
Compression loss: Dense vectors necessarily compress rich semantic information into fixed-size representations
Similarity confusion: High cosine similarity between vectors didn’t guarantee actual relevance
Probabilistic uncertainty: Retrieval became fundamentally probabilistic rather than deterministic
Module 3: The RAG Revolution
When Language Models Met Memory
As large language models exploded in capability, their fundamental limitations became equally apparent:
Knowledge cutoffs: Models couldn’t access information beyond their training data. Many of us remember this time circa 2022-early 2024 (I say this in the past tense, because with tools, training data easily gets updated information when “search” is included - many of the newer models today have such capabilities).
Hallucination: When uncertain, models would confidently generate plausible-sounding but false information
Update costs: Incorporating new knowledge required expensive retraining
Retrieval-Augmented Generation (RAG) emerged as an elegant solution, treating external knowledge bases as augmented memory:
Query encoding: Convert user questions into vector representations
Similarity search: Find semantically similar document chunks in the vector database
Context augmentation: Inject retrieved information into the language model’s context
Grounded generation: Generate responses based on both parametric knowledge and retrieved evidence
Example in action:
User asks: “When did the iPhone first launch?”
RAG retrieves: “The iPhone was announced by Steve Jobs at Macworld 2007...”
LLM responds: “The iPhone first launched in 2007, when Steve Jobs unveiled it at the Macworld Conference & Expo in January.”
Without RAG, the model might confidently hallucinate “2009” or refuse to answer due to uncertainty.
Retrieval as Cognitive Architecture
RAG fundamentally reframed how we think about machine cognition:
Parameters = Long-term memory (grammar, facts, reasoning patterns)
Context window = Working memory (immediate attention and processing)
Vector database = External memory/library (searchable knowledge repository)
RAG pipeline = Memory retrieval mechanism (the pathway connecting queries to stored knowledge)
This cognitive metaphor proved remarkably powerful. Just as humans seamlessly blend recalled facts with reasoning, RAG systems could combine parametric knowledge with dynamically retrieved information.
Hitting the Walls
The Emerging Cracks in Vector Paradise
As RAG systems deployed at scale, fundamental limitations became apparent:
Semantic Drift: High vector similarity doesn’t guarantee relevance. A query about “Apple revenue in 2023” might also sometimes retrieve documents about “Apple fruit harvest in 2023” due to shared terminology, despite completely different domains.
Information Loss: Fixed-size embeddings compress rich, multidimensional information into standard vector lengths (typically 512-4096 dimensions). Complex documents with multiple themes, arguments, or data types suffer significant information loss.
Multi-hop Reasoning Failure: The LIMIT dataset exposed a critical weakness: when queries required reasoning across multiple pieces of information, even state-of-the-art embedding models achieved recall@100 below 20%. Simple questions like “What was the population of the capital of France in 1990?” required connecting “capital of France” → “Paris” → “1990 population data”—a chain that consistently broke vector retrieval.
Scale Challenges: A modest 50 million document collection with 4096-dimensional embeddings requires approximately 762GB of memory before any indexing structures—and that’s just for storage, not the additional overhead needed for efficient similarity search.
The Welch Bound: Mathematics as Destiny
Beneath these practical limitations lies a deeper mathematical constraint: the Welch Bound. This theorem defines the maximum number of orthogonal (non-interfering) vectors that can exist in a fixed-dimensional space.
As we attempt to encode more semantic features into embeddings:
Interference increases: Vectors become more similar to each other
Discriminative power decreases: The embedding space becomes “crowded”
Retrieval precision drops: Subtle but important differences get lost in the noise
The Welch Bound isn’t just a technical limitation—it represents a fundamental cognitive ceiling. No matter how sophisticated our embedding techniques become, geometry itself constrains how much distinct information can be packed into fixed-dimensional representations.
Module 4: Breaking Through the Barriers
Interpretability: Understanding the Black Box
Recent breakthroughs in embedding interpretability have revealed surprising insights. Research from Google and Stanford demonstrated that DB-KSVD, a 20-year-old sparse dictionary learning algorithm, achieves nearly identical performance to modern Sparse Autoencoders (SAEs) on feature extraction tasks.
This convergence suggests that the performance ceiling isn’t architectural—it’s geometric. Both approaches hit the same mathematical limits imposed by high-dimensional vector spaces.
Matryoshka Training offers a promising path forward by enforcing feature diversity across embedding layers. Like Russian nesting dolls, each layer encodes progressively more abstract representations:
Layer 1: Basic token-level features
Layer 2: Phrase-level semantics
Layer 3: Document-level themes
Layer 4: Abstract conceptual relationships
This hierarchical approach reduces feature interference while preserving semantic richness at multiple levels of abstraction.
Retrieval-Native Solutions: Theory Meets Practice
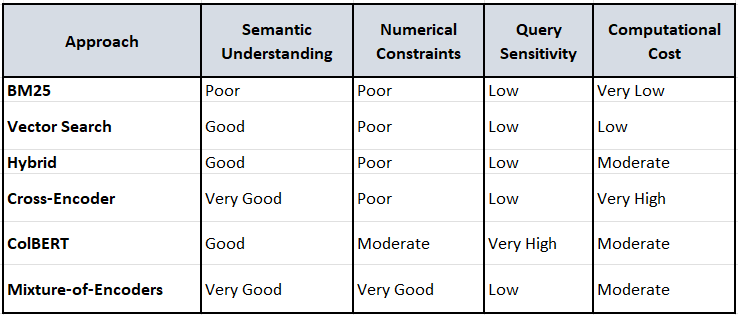
The community has developed several architectural innovations to work within geometric constraints, though recent empirical benchmarking reveals significant gaps between theoretical promise and practical performance:
Cross-Encoders abandon the embedding paradigm entirely, scoring query-document pairs through joint neural networks. Recent benchmarks show mixed results:
Strengths: Superior semantic alignment - can distinguish between “luxury” and “affordable” better than bi-encoders
Critical limitations: Still struggle with numerical constraints (”price lower than 2000”), often prioritizing semantic similarity over factual accuracy
Computational cost: Requires evaluating each query-document pair individually, creating scalability bottlenecks
Multi-Vector Models like ColBERT represent documents as collections of vectors, enabling fine-grained token-level matching:
Breakthrough capability: Better numerical constraint handling than single-vector approaches
Persistent weakness: Extreme sensitivity to query phrasing - “apartment for 5 guests with price lower than 2000” succeeds where “places with price lower than 2000 for 5 guests” fails
Architectural insight: Late interaction through MaxSim aggregation can be dominated by strong lexical matches, missing nuanced semantic requirements
Hybrid Search combines BM25 precision with embedding semantics:
Reality check: Recent benchmarks reveal that combining two imperfect approaches rarely produces satisfactory results for structured data
Core limitation: Neither BM25 nor vector search reliably handles numerical constraints, so linear combinations inherit both limitations
Tuning complexity: Optimal alpha values require dataset-specific calibration and may not generalize
The Multi-Modal Challenge: Empirical evidence suggests the fundamental issue isn’t architectural but representational - compressing structured data (numerical, categorical, textual) into homogeneous embeddings loses critical attribute relationships.
Semantic Chunking preserves conceptual boundaries rather than using arbitrary text windows, though its effectiveness depends heavily on the underlying retrieval method’s ability to interpret the preserved structure.
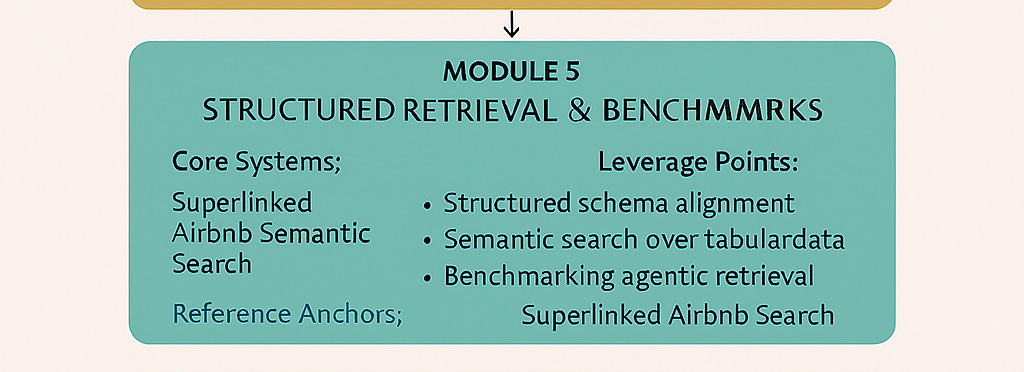
Module 5: Beyond Vector Search - Mixture of Encoders
The Structured Data Challenge
Recent empirical research reveals a critical blind spot in the retrieval evolution narrative: the assumption that more sophisticated algorithms automatically yield better results. The Superlinked Airbnb benchmark provides compelling evidence that architectural sophistication means little without proper data representation.
The benchmark tested multiple retrieval approaches on 3,350 Stockholm Airbnb listings, revealing that the fundamental challenge isn’t geometric constraints or context windows—it’s the heterogeneous nature of structured data. Real-world queries like “apartment for 5 guests with price lower than 2000 and review rating bigger than 4.5” combine:
Numerical constraints (price thresholds, guest capacity)
Semantic concepts (”luxury” vs “affordable”)
Categorical filters (accommodation type, amenities)
Contextual preferences (location, ambiance)
Traditional embeddings compress all these modalities into homogeneous vector representations, creating what researchers term “attribute relationship loss”—the inability to preserve distinct semantic, numerical, and categorical relationships within single embeddings.
The Mixture of Encoders Breakthrough
Superlinked’s mixture-of-encoders architecture represents a fundamental shift from homogeneous to heterogeneous representation:
Specialized Encoding by Modality:
Text fields: Semantic embeddings via transformer models
Numerical fields: Quantitative embeddings with logarithmic scaling and directional preferences
Categorical fields: Discrete similarity spaces with explicit category relationships
Temporal fields: Time-aware embeddings that understand recency and seasonality
LLM-Powered Query Interpretation: Instead of converting natural language directly to vectors, the system uses large language models to:
Parse complex queries into structured components
Assign dynamic weights to different attributes based on user intent
Apply hard filters for non-negotiable constraints
Generate contextual search parameters that respect both explicit and implicit preferences
Results demonstrate remarkable improvements:
100% constraint satisfaction on numerical queries (vs. <20% for traditional approaches)
Complete semantic separation between contradictory concepts (”luxury” vs “affordable” with zero overlap)
Query phrasing independence - results remain consistent regardless of constraint ordering
Multi-modal understanding - simultaneously processing price preferences, semantic concepts, and categorical requirements
Challenging the Vector Database Paradigm
For this follow work by Jo Kristian Bergum. Empirical evidence seems to support Jo Kristian Bergum’s economic critique of the Vector Database Paradigm, while revealing additional architectural limitations:
The Compression Problem: Single-vector approaches inherently lose information when encoding multi-modal data. The benchmark’s t-SNE visualization shows semantically similar listings clustering together even when they violate specific numerical constraints—a fundamental failure of compressed representations.
The Interaction Problem: Even multi-vector approaches like ColBERT suffer from interaction blindness—individual token vectors cannot capture relationships between different attribute types (e.g., how price relates to luxury perception).
The Context Problem: Cross-encoders improve semantic matching but still struggle with structured constraints because they process query-document pairs as homogeneous text rather than structured attribute relationships.
The Agentic Future
From Pipelines to Reasoning Systems
The latest evolution transforms RAG from a simple pipeline into a multi-agent reasoning system, though the Superlinked benchmark reveals that even agentic approaches must grapple with the fundamental representation challenges:
→Retriever Agents iteratively refine queries, breaking complex questions into targeted sub-queries and routing them to appropriate knowledge sources. However, empirical evidence suggests that query refinement alone cannot overcome representational limitations—if the underlying retrieval method cannot handle numerical constraints, agent-based query decomposition merely distributes the failure across multiple sub-queries.
→Evaluator Agents assess retrieved content for relevance, factual accuracy, and completeness before passing information to generation stages. The benchmark data indicates these agents face the same semantic-vs-structural trade-offs, often prioritizing semantically similar but factually incorrect results over precise constraint satisfaction.
→Planner Agents orchestrate complex multi-hop workflows, maintaining coherent reasoning chains across multiple retrieval and generation steps. Recent research suggests these planning capabilities depend heavily on the quality of underlying retrieval—sophisticated orchestration cannot compensate for fundamentally flawed memory access patterns.
The Context vs. Retrieval Tension in Practice
And then there is Yang Zhilin of Moonshot AI. Yang Zhilin’s vision of unlimited context windows faces a critical challenge revealed by the structured data benchmark: even with infinite context, the attribute relationship problem persists. Compressing heterogeneous data types into homogeneous token sequences may lose crucial structural relationships regardless of context length.
The benchmark demonstrates that queries requiring simultaneous numerical constraints and semantic understanding (”luxury apartments under $2000”) challenge even the most sophisticated context engineering approaches. This suggests that Jeff Huber’s (of Chroma) context engineering framework, while valuable, must account for modality-specific processing rather than treating all information as equivalent contextual tokens.
Note: Both Yang Zhilin, Jo Kristin Bergum and Jeff Huber are spoken about further below.
Evaluation: Beyond Simple Metrics
Traditional retrieval metrics like recall@k and precision@k prove inadequate for modern agentic systems. New frameworks like RAGAS (Retrieval-Augmented Generation Assessment) evaluate:
Faithfulness: How well does the generated answer stick to retrieved facts?
Context Precision: Are the retrieved documents actually relevant?
Answer Relevance: Does the final response address the user’s actual question?
Context Recall: Was all necessary information successfully retrieved?
The LIMIT dataset specifically targets multi-hop reasoning failures, revealing that current systems still struggle with questions requiring inference across multiple knowledge sources.
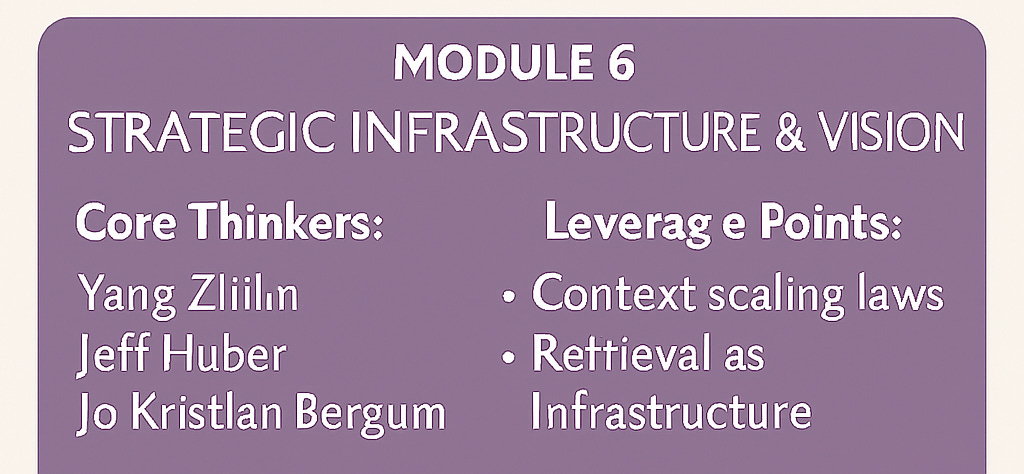
Module 6: Industry Voices and Alternative Futures
As the technical evolution of retrieval unfolds, three prominent industry voices offer compelling—and sometimes contradictory—perspectives on where we might be heading. Their insights reveal alternative futures that may diverge significantly from the current RAG-centric trajectory.
Yang Zhilin (CEO, Moonshot AI): The Context Maximalist
Yang Zhilin advocates for a radical “tech vision” that could make retrieval obsolete entirely. His core thesis: “Lossless long context is everything.” This isn’t just about longer context windows—it’s about fundamentally reimagining how AI systems access and use information.
The Vision: Yang sees the evolution from Word2Vec to Transformers as a continuous expansion of effective context length, destined to reach “tens of thousands or even millions of characters” through lossless compression. His bold prediction: “With a context length of 1 billion, today’s problems will cease to be problems.”
Key Principles:
AI as Scaling Laws: Yang asserts that “AI is fundamentally a pile of scaling laws”—that scaling up compute and data is the only approach that consistently works after decades of AI research
User Data as the Ultimate Model: He believes the “scale-up effect of user data will ultimately surpass the base model itself,” emphasizing personalized interaction history over traditional fine-tuning
Inference as Training: Yang envisions a future where models generate synthetic data for continuous self-improvement, fundamentally changing the compute paradigm and dramatically reducing alignment costs
Organizational Philosophy: Yang advocates for lean, efficient AGI development that doesn’t require massive workforces, emphasizing the importance of “unlearning” past successful experiences for new AI entrepreneurs.
The Moonshot Strategy: Rather than competing on retrieval sophistication, Moonshot AI differentiates through user-centricity and their tech vision of unlimited context, believing this will create superior personalized AI experiences.
Jeff Huber (Founder & CEO, Chroma): The Context Engineer
Jeff Huber approaches the future from a pragmatic engineering perspective, focusing on making AI development “engineering rather than alchemy” through robust infrastructure and systematic approaches to context management.
The Framework: Huber champions “context engineering” as the critical discipline of determining “what should be in the context window at any given LLM generation step.” This involves:
Inner Loop: Immediate context filling for current queries
Outer Loop: Long-term improvement of context selection strategies
Technical Insights:
RAG Critique: Huber dislikes the “RAG” terminology for creating false constraints and implying single dense vector search when effective systems require sophisticated hybrid approaches
Context Rot Reality: He identifies “context rot”—performance degradation with increased token length—as a real problem that marketing around “needle in a haystack” benchmarks obscures
Future Architecture: Huber anticipates retrieval systems that “stay in latent space” with “continual retrieval during generation” rather than discrete pipeline stages
Infrastructure Vision: Through Chroma, Huber builds “modern search infrastructure for AI” using distributed system primitives (Rust, multi-tenancy, storage/compute separation) optimized for AI workloads rather than human search patterns.
Hybrid Approach: He advocates multi-stage retrieval combining vector search, full-text search, and metadata filtering, with LLMs serving as rerankers to curate information—believing purpose-built rerankers may become obsolete as LLMs get cheaper and faster.
Organizational Culture: Huber emphasizes that companies “ship their culture,” advocating for slow, selective hiring for alignment and maintaining maniacal focus on contrarian visions rather than chasing market trends.
Jo Kristian Bergum: The Economic Realist
Bergum provides crucial economic analysis that challenges the assumption that more sophisticated equals better, highlighting the cost constraints that may drive a renaissance of classical methods.
The Cost Reality: Bergum’s analysis reveals the economic constraints of embedding-based retrieval at scale:
4096-dimension vectors require 16KB per document chunk
A modest 10 million document collection demands ~160GB just for embeddings
This excludes indexing overhead, backup storage, and operational complexity
BM25 storage requirements are two orders of magnitude smaller with no embedding inference costs
RAG Redefinition: Bergum clarifies that RAG is simply “augmenting the model with relevant context” and does not strictly require embeddings—challenging the vector-centric interpretation of retrieval-augmented generation.
The BM25 Renaissance: He positions BM25 as a “highly realistic and cost-effective solution” for reasoning-intensive retrieval, especially at scale, suggesting that classical keyword-based approaches enhanced by modern reranking may prove more sustainable than pure neural methods.
Hybrid Strategy: Bergum proposes using BM25 for initial candidate retrieval (fetching top 1000 documents) followed by LLM reranking—combining economic efficiency with semantic sophistication while avoiding massive storage requirements.
Market Analysis: He describes the “vector database gold rush” as driven by misconceptions that embedding-based similarity search was the only viable RAG method, observing convergence where pure vector engines add traditional search features while established databases integrate vector capabilities.
Key Insight: “Vector search isn’t a separate category but an essential capability in the modern search toolkit.” Bergum argues that dedicated search engines with decades of refinement in ranking mechanisms still offer superior quality for complex retrieval tasks than databases simply adding vector support.
The Economic Reality Check Revisited (Findings on BM25 by Superlinked)
However, the Superlinked benchmark adds crucial nuance to Bergum’s economic analysis. While BM25’s storage advantages remain valid, the performance gap for structured queries suggests that cost savings may come at the expense of user satisfaction. The benchmark reveals that:
BM25 Limitations Are Severe: On queries requiring both semantic understanding and numerical constraints, BM25 achieved near-zero constraint satisfaction. This isn’t just a minor degradation—it represents complete system failure for modern use cases.
Vector Storage Costs vs. Processing Costs: While Bergum correctly identifies embedding storage costs, the benchmark suggests that processing costs for mixture-of-encoders may be more manageable than initially expected. Superlinked’s approach requires storing multiple specialized encoders but achieves significantly better results than resource-intensive cross-encoder reranking.
The Hybrid Fallacy: The benchmark challenges the assumption that combining imperfect approaches yields better results. Hybrid search inherited limitations from both BM25 and vector search without addressing the core representational problems.
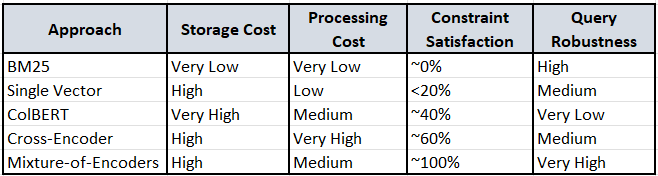
This data suggests that the economic optimization may not be linear—the cost of user dissatisfaction from poor constraint satisfaction could outweigh storage savings.
Three Paradigms in Tension
These industry perspectives reveal fundamentally different assumptions about the future of AI systems:
The Context Maximalist Paradigm (Yang): Unlimited context windows eliminate retrieval needs entirely. Success depends on solving context rot and achieving true lossless compression at scale. This paradigm suggests that current retrieval systems are temporary scaffolding for a future where models can hold arbitrary amounts of context without degradation.
The Infrastructure Engineering Paradigm (Huber): Sophisticated context engineering with hybrid retrieval systems represents the mature future of AI infrastructure. Success depends on building robust, multi-modal search systems that serve AI workloads efficiently while maintaining engineering discipline and systematic optimization.
The Economic Sustainability Paradigm (Bergum): Cost-driven evolution favors classical methods enhanced by modern capabilities over pure neural approaches. Success depends on balancing retrieval quality with operational economics, recognizing that the most elegant solution isn’t always the most viable one.
The Convergence Hypothesis: Rather than one paradigm winning completely, the successful systems may synthesize insights from all three:
Yang’s scaling philosophy applied to cost-effective architectures (Bergum’s constraint)
Huber’s engineering discipline applied to both unlimited context systems (Yang’s vision) and hybrid retrieval systems (Bergum’s pragmatism)
Economic sustainability (Bergum) driving technical choices in both context engineering (Huber) and scaling strategies (Yang)
The Future of Retrieval Will Not Be A Single Evolutionary Path; It Will Be A Landscape of Specialized Approaches, Optimized For Different Scales/Use Cases/Constraints
This synthesis suggests that the future of retrieval isn’t a single evolutionary path, but rather a landscape of specialized approaches optimized for different scales, use cases, and economic constraints.
The Hardware Reality
Memory as the New Compute
While much attention focuses on computational requirements (training GPT-4 required approximately 30,000 H100 GPUs), retrieval workloads are fundamentally memory bandwidth-bound:
Sparse retrieval methods require random access patterns across large indices
Multi-hop reasoning demands rapid access to diverse knowledge sources
Real-time applications need sub-second response times across terabyte-scale knowledge bases
Current GPU architectures optimize for dense computational workloads, but retrieval systems need:
High-bandwidth memory for rapid vector similarity search
Efficient sparse operations for hybrid retrieval methods
Low-latency storage for multi-hop reasoning workflows
The analogy is apt: if computational power is the steel framework of AI, memory bandwidth is the scaffolding. Without sufficient scaffolding, even the strongest structures collapse under load.
The Road Ahead - Synthesis and Future Directions
Emerging Frontiers Informed by Evidence
The industry voices and empirical benchmarks reveal that the future will likely evolve along multiple parallel dimensions rather than following a single linear progression:
Modality-Aware Architecture representing the most promising near-term direction. The Superlinked benchmark demonstrates that specialized encoding for different data types consistently outperforms homogeneous approaches. Future systems will likely:
Use dedicated encoders for numerical, textual, categorical, and temporal data
Employ LLM-powered query interpretation to bridge natural language and structured representations
Implement hard constraint filtering before semantic ranking to ensure factual accuracy
Qwen3-Omni (multi-modal) is an excellent case study already almost proving the point:
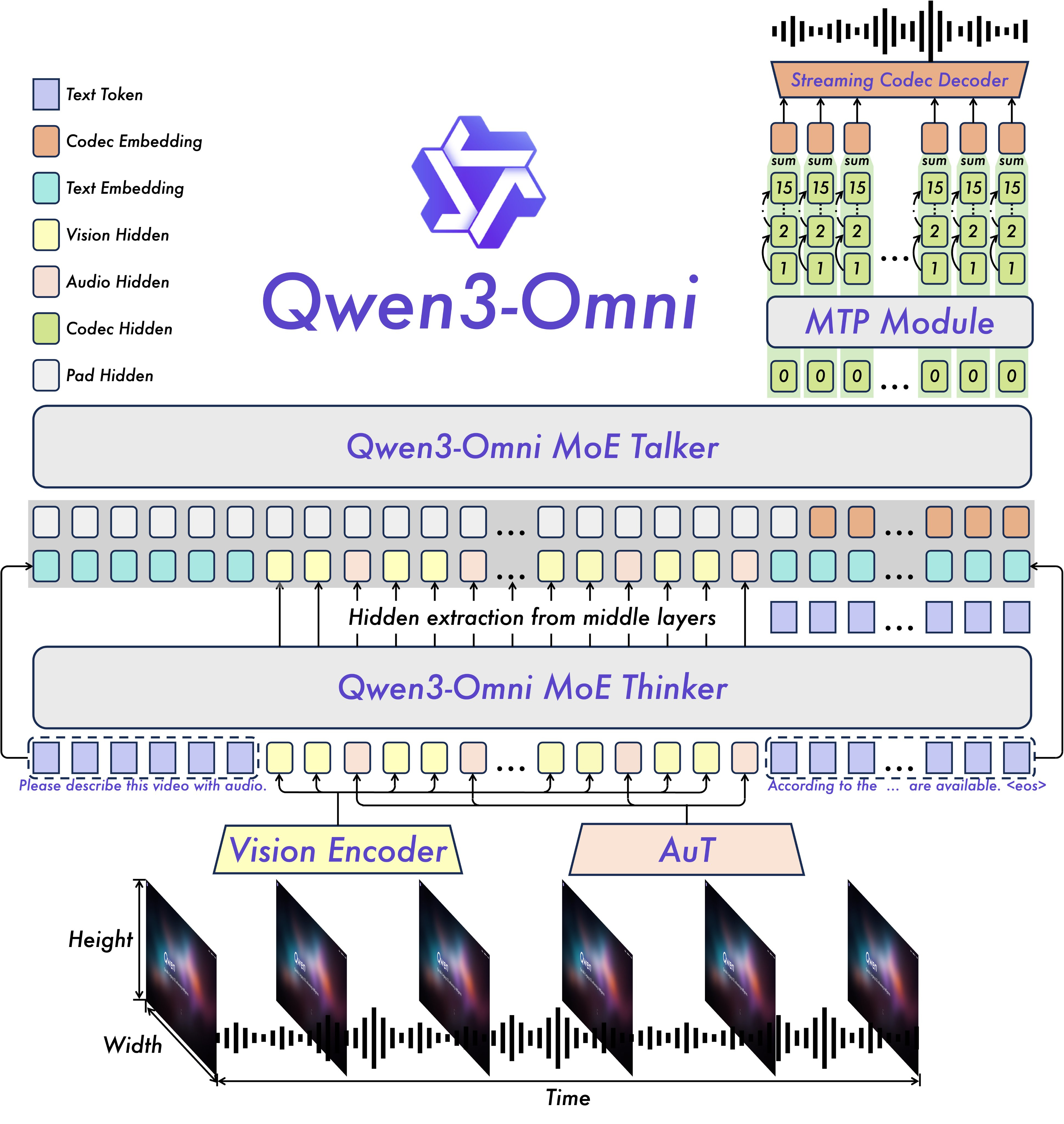
Dynamic Context Engineering following Huber’s framework but informed by structured data challenges. Rather than treating all context as equivalent tokens, future systems will need:
Modality-specific context optimization (numerical vs textual vs categorical information)
Adaptive context allocation based on query complexity and constraint types
Real-time context quality assessment to prevent “context rot” in heterogeneous data scenarios
Economic Sustainability with Performance Trade-offs acknowledging Bergum’s cost analysis while accounting for user satisfaction metrics:
Tiered architectures using fast, cheap methods (BM25) for initial filtering, followed by specialized encoders for final ranking
Cost-performance optimization curves that factor user dissatisfaction from poor constraint handling
Hybrid storage strategies balancing embedding costs against query success rates
Scale-Aware Scaling Laws building on Yang’s vision while recognizing representational constraints:
Context length scaling may not solve structured data problems without modality-aware processing
Scaling laws may need different coefficients for different data types and query complexities
“Inference as training” approaches must account for the structured nature of real-world data
The Convergence Hypothesis Refined
Rather than one paradigm dominating, successful systems will likely synthesize insights from all evolutionary stages while prioritizing different approaches based on specific constraints:
Personal AI Systems (Yang’s domain): Unlimited context with sophisticated modality-aware processing for individual user data and preferences.
Enterprise Search (Huber’s focus): Engineered context optimization with mixture-of-encoders for complex organizational knowledge bases.
Web-Scale Systems (Bergum’s concern): Economic hybrid approaches using cheap initial filtering followed by specialized reranking for constraint satisfaction.
Critical Questions Moving Forward
The evidence reveals several crucial questions that will determine retrieval’s future evolution:
Representation vs. Architecture: Can better architectures overcome representational limitations, or do we need fundamentally different encoding approaches?
Constraint Satisfaction vs. Semantic Similarity: How should systems balance exact constraint matching with semantic relevance when they conflict?
Query Robustness: Why do some approaches (mixture-of-encoders) achieve query-phrasing independence while others (ColBERT) remain highly sensitive?
Economic Optimization: What performance degradation is acceptable for significant cost savings, and how does this vary by use case?
Context Engineering Scalability: Can Huber’s systematic context management approaches scale to Yang’s unlimited context vision?
The Theoretical Horizon
Looking further ahead, several research directions show particular promise:
Quantum-Inspired Retrieval could potentially bypass classical geometric constraints through superposition-based representations, though practical implementations remain distant.
Neuro-Symbolic Integration combines neural pattern recognition with symbolic reasoning, potentially solving the multi-hop inference problem through hybrid architectures.
Lifelong Learning Retrieval systems that continuously adapt their memory organization based on usage patterns, becoming more efficient and accurate over time.
Memory, Economics, and the Future of Intelligence
The evolution from BM25 to agentic RAG represents more than technological progress—it traces the development of machine memory itself, while revealing the complex interplay between technical capability and economic reality. Each stage revealed new possibilities while exposing fundamental constraints, from geometric limitations to cost structures that may ultimately determine which approaches succeed.
The industry voices illuminate three critical tensions shaping the future:
Technical vs. Economic Optimization: The most sophisticated retrieval system means nothing if it’s too expensive to operate at scale. Bergum’s analysis suggests that classical methods enhanced by modern reranking may prove more sustainable than pure neural approaches.
Context vs. Retrieval: Yang’s vision of unlimited context windows challenges the fundamental premise that external memory is necessary. If context can truly scale without degradation, the entire retrieval industry becomes a temporary bridge technology.
Engineering vs. Alchemy: Huber’s emphasis on context engineering highlights that success requires systematic approaches to memory management, not just better algorithms. The future belongs to systems that can be engineered, debugged, and optimized—not just trained.
What we know is that:
Geometry constrains cognition: The Welch Bound and embedding limitations show that representation has mathematical limits
Economics shapes architecture: Cost considerations may drive a return to classical methods enhanced by modern capabilities
Context is everything: Whether through unlimited windows (Yang) or sophisticated engineering (Huber), context management is fundamental
Scale changes the game: Different approaches optimize for different scales, from personal AI (context-heavy) to enterprise systems (retrieval-heavy)
Modality matters: The mixture-of-encoders breakthrough proves that heterogeneous data requires heterogeneous representation
The systems that succeed will likely synthesize insights from all evolutionary stages: the precision of classical search, the semantic power of embeddings, the sophistication of modern reranking, and the economic realism that makes deployment sustainable.
Retrieval is no longer about finding documents—it’s about building machines that think with memory, meaning, and economic viability. The question isn’t whether machines can remember everything, but whether they can forget the right things while reasoning with what remains at a cost that makes sense. That balance—between storage and selection, between comprehensiveness and precision, between technical elegance and economic reality—will define the next era of artificial intelligence.
References:
🧠 Foundational Retrieval Methods
BM25 Algorithm Overview
GeeksforGeeks: What is BM25?
ADaSci: Understanding Okapi BM25Latent Semantic Indexing (LSI)
Meilisearch: What is LSI and how does it work?
Wikipedia: Latent Semantic Analysis
🔢 Embedding-Based Retrieval
Word2Vec vs GloVe Comparison
ML Journey: GloVe vs. Word2Vec
StackOverflow: Key differencesTransformer-Based Contextual Embeddings
Sling Academy: Context-Aware Embeddings with Transformers
🧩 Retrieval-Augmented Generation (RAG)
RAG Architecture Explained
GeeksforGeeks: RAG Architecture
Databricks: What is RAG?
📐 Mathematical Limits of Embeddings
Welch Bound and Vector Space Constraints
Wikipedia: Welch Bounds
arXiv: Geometry of the Welch Bounds
🧪 Sparse Feature Extraction
DB-KSVD vs Sparse Autoencoders
arXiv: DB-KSVD for High-Dimensional Embedding Spaces
GitHub: Awesome Sparse Autoencoders
🧠 Multi-Vector Retrieval Models
ColBERT and Late Interaction Models
Weaviate: Overview of ColBERT and Late Interaction
Hugging Face: ColBERT-XM Model Card
🏘️ Superlinked Benchmark & Structured Retrieval
Superlinked Airbnb Semantic Search
GitHub: Airbnb Semantic Search with Superlinked
🚀 Industry Perspectives
Yang Zhilin (Moonshot AI): Context Scaling Vision
KrAsia: Scaling Law and K0-Math
LessWrong: Interviews with Yang ZhilinJeff Huber (Chroma): Context Engineering
StartupHub: Chroma’s Thesis on AI InfrastructureJo Kristian Bergum: Vector Search Economics
iMarc: The Rise and Fall of Vector Databases
📊 Evaluation Frameworks
RAGAS: Retrieval-Augmented Generation Assessment
arXiv: RAGAS Evaluation Framework
Ragas Documentation
Brilliant stuff . Thank you .
Yes 🙏. How does one do so?