
From Simulation to Deliberation: How CoMET and MAI-DxO Might Redefine AI’s Role in Healthcare Strategy and Diagnosis
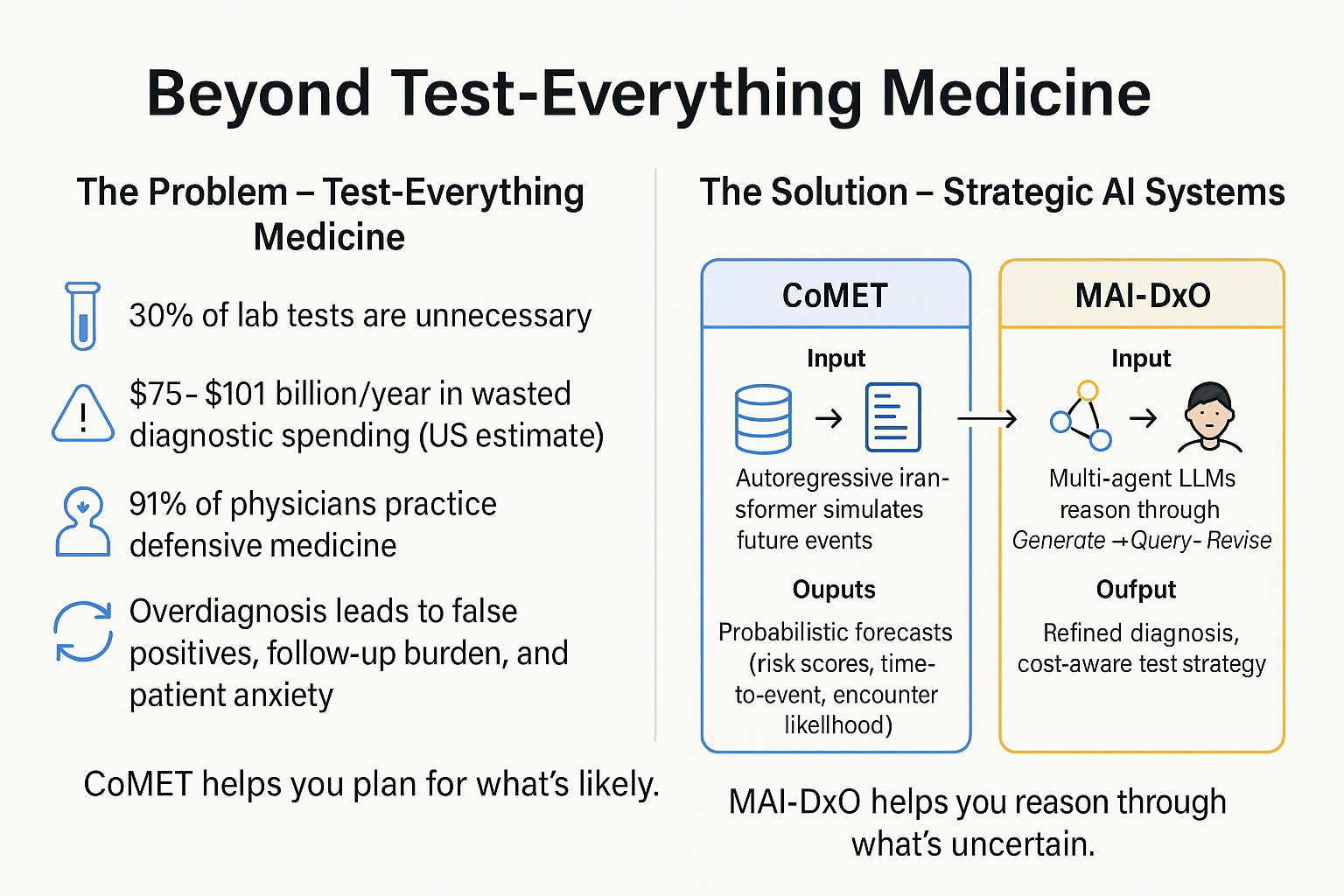
Re-Thinking The Hidden Costs of “Test-Everything” Medicine

The Hidden Costs of “Test-Everything” Medicine
The following reflects opinions and insights friends have shared with me, in the field of Specialized Medicine. It has made me think a lot, especially about the potential that builds up with reasoning models and agentic systems. I realize there have been just as many successes as failures. Therefore, nothing of what you are about to read is prescriptive in any way, but I hope it triggers discussions, trials, and tests for “fitness of application”, where relevant.
A few of you may have experienced something similar. Perhaps the experience has been the opposite, depending on which countries, regions etc that you inhabit. In any case, consider it one layer of the “many medical experience possibilities” one comes across in any lifetime.
Modern healthcare is increasingly burdened by diagnostic overuse—tests ordered not for clinical necessity, but out of habit, uncertainty, or defensive practice (in private practice, it sometimes helps chalk up the top-line, or mitigate legal liabilities; in public healthcare, it signifies attempts to mitigate mostly legal risks). A few recent studies have shown:
⚠️ Up to 1 in 3 laboratory tests are unnecessary, inflating costs and exposing patients to avoidable harm.
🧪 Preoperative testing and imaging for uncomplicated low back pain are among the most frequent low-value diagnostics, with overuse rates reaching 25–97% in some settings.
💰 In the U.S. alone, overuse contributes an estimated $75–$101 billion in wasted healthcare spending annually.
🩺 A staggering 91% of physicians admit to practicing defensive medicine, often ordering extra tests to avoid malpractice risk—even when they believe the tests are unnecessary.
This “test-everything” paradigm not only drains resources but also distorts clinical reasoning, leading to cascades of false positives, overdiagnosis, and diagnostic inertia.
🛡️ Forms of Defensive Medicine
Assurance Behavior:
Ordering unnecessary tests or procedures
Documenting excessively to prove adherence to guidelines
Example: A doctor orders a CT scan even when clinical signs don’t warrant it, just to avoid missing a rare diagnosis
Avoidance Behavior:
Steering clear of high-risk cases or procedures
Refusing to treat complex patients due to fear of litigation
Example: A surgeon declines to operate on a frail elderly patient despite potential benefit
⚖️ Why It Happens
Fear of malpractice lawsuits
Pressure from hospital policies or peer norms
Patient expectations for exhaustive testing
Lack of systemic support for clinical discretion3
📉 Consequences
Higher healthcare costs
Longer wait times
Overdiagnosis and overtreatment
Erosion of trust between patients and providers
In some regions, like the U.S., it’s driven by litigation risk. In others, like India, it’s also shaped by physical threats to practitioners and weak institutional backing
References:
Prevalence of Medical Overtesting
Overuse of Diagnostic Testing in Healthcare: A Systematic Review
Assessment of Overuse of Medical Tests And Treatments at US Hospitals Using Medicare Claims
Defensive Medicine: What It Is, Why It Happens, And How It Affects You As A Patient
🔍 Why CoMET and MAI-DxO Matter
Against this backdrop, CoMET and MAI-DxO offer radically different epistemic and operational approaches:
CoMET simulates population-level risk trajectories, helping planners anticipate emergent threats and allocate resources before crises unfold.
MAI-DxO, by contrast, orchestrates multi-agent diagnostic reasoning, solving complex cases with up to 4× the accuracy of physicians while reducing diagnostic costs by 20–28%5.
Together, they signal a shift from reactive overtesting to strategic, context-aware intelligence—where forecasting and diagnosis are not just faster, but potentially smarter.
I have covered MAI-DxO in these various articles: The End of The Monolith, Bending Cost Curves, Raising The Floor, The Evolution of AI, and When Algorithms Compete.
References:
The Path To Medical SuperIntelligence
Microsoft’s MAI-DxO is Beating Doctors At Diagnosis: But What Does That Really Mean For Healthcare?
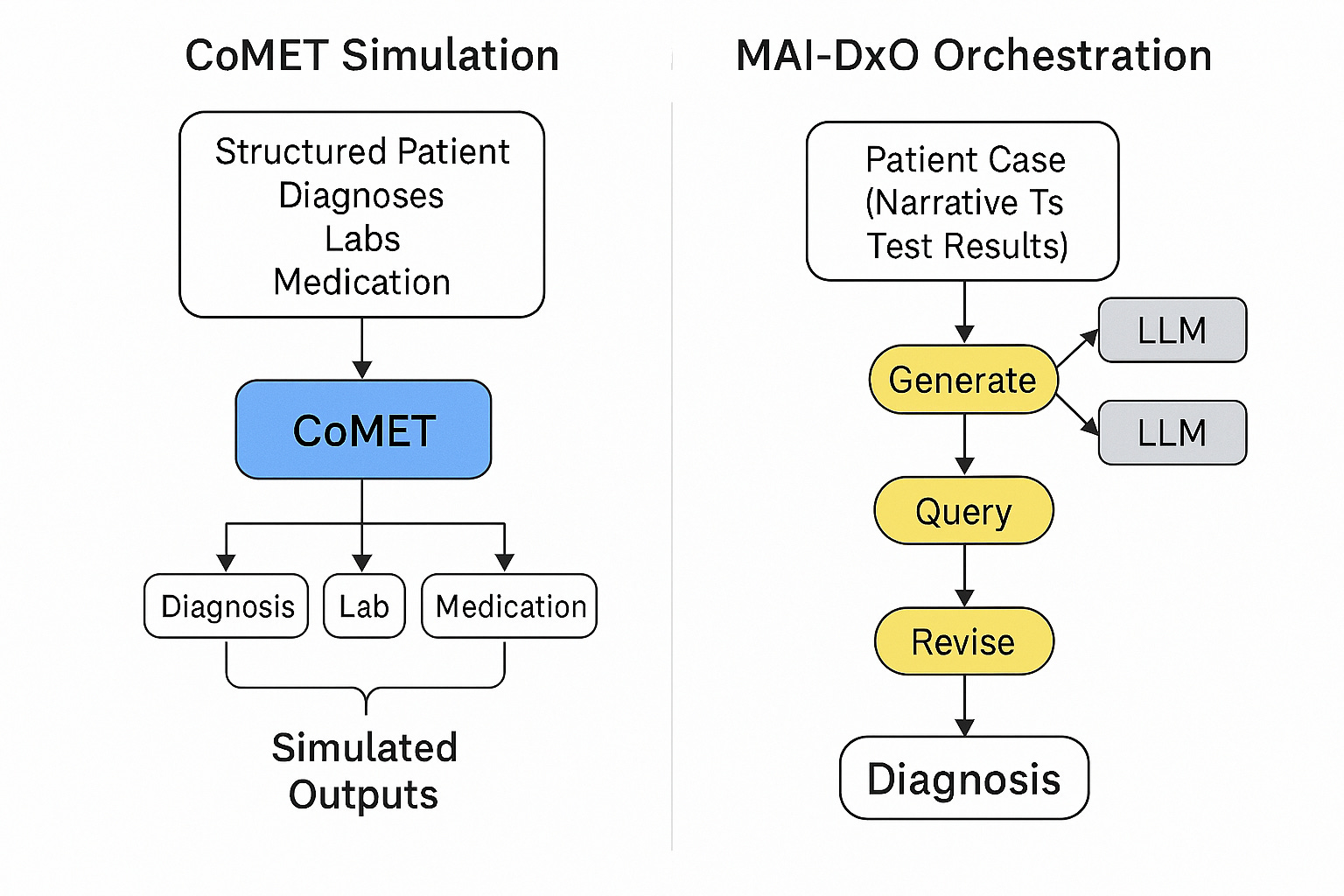
The diagram visually contrasts the CoMET simulated pipeline (left side) with the MAI-DxO multi-agent orchestration (right side), highlighting their distinct reasoning architectures:
CoMET flows from structured patient data → autoregressive simulation → probabilistic outputs (diagnosis, labs, meds).
MAI-DxO begins with a narrative case → sequential reasoning steps (generate, query, revise) → diagnostic output, with multiple LLMs contributing at each stage.
This layout makes their epistemic divergence clear: CoMET models what is likely to happen across populations, while MAI-DxO reasons what is most plausible in a specific case.
Beyond Automation, Toward Epistemic Partnership
These two systems (with participation of Microsoft researchers) —CoMET and MAI-DxO—are helping to reshape how we might think about clinical reasoning, healthcare planning, and diagnostic precision.
These aren’t just tools for automating tasks; they represent distinct epistemic paradigms: one simulates population-level futures, the other deliberates through individual diagnostic complexity.
Very significant of course, as hospitals grapple with rising costs, diagnostic uncertainty, and the need for scalable planning, the contrast between human-only interventions, automation, and AI-augmented reasoning becomes increasingly consequential.
I hope this article helps you explore how CoMET and MAI-DxO might operate, where they shine, and how they challenge the “test-everything” mentality that burdens many healthcare systems.
🧠 CoMET: Simulating the Future of Patient Trajectories
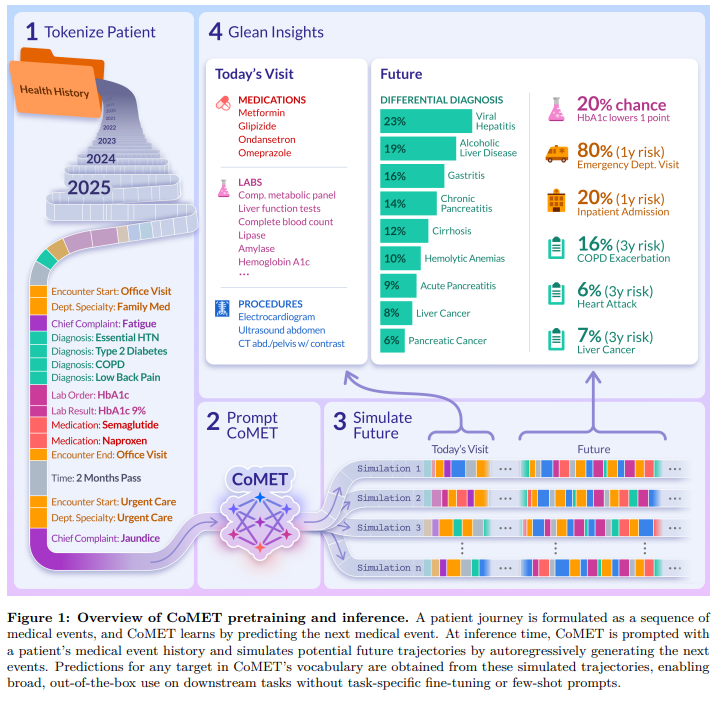
CoMET (Cosmos Medical Event Transformer) is a generative foundation model trained on over 115 billion structured medical events. It doesn’t diagnose—it simulates. By ingesting chronological sequences of diagnoses, labs, medications, and procedures, CoMET predicts what’s likely to happen next in a patient’s journey. I would expect some level of relevant fine-tuning, country and region-dependent, depending on application.
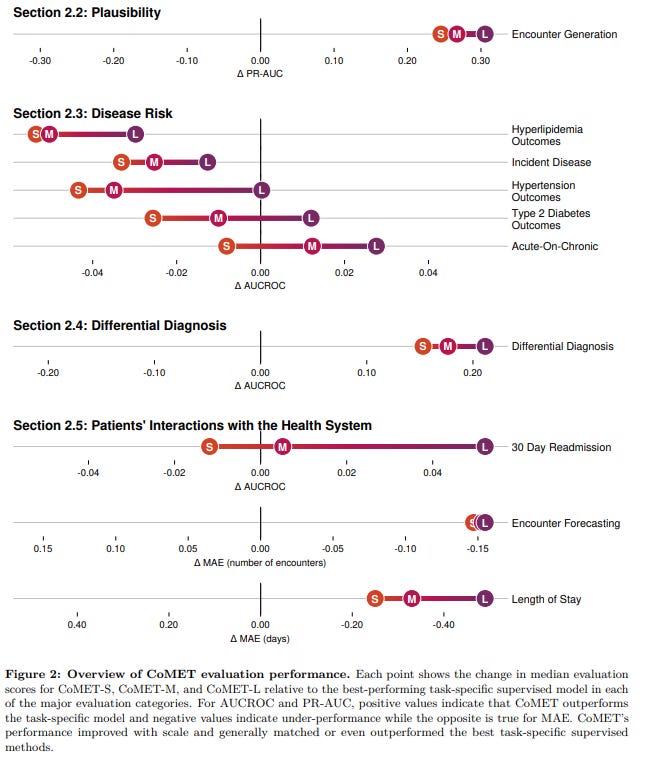
🔧 How It Works:
Decoder-only transformer trained autoregressively
Generates future medical events based on past structured data
No task-specific fine-tuning required
Outputs probabilistic forecasts: diagnoses, labs, medications, time-to-event distributions
🏥 Applications:
Hospital budgeting: Forecasting ER visits, medication switches, and service demand
Public health planning: Simulating disease progression across populations
Clinical decision support: Estimating risk trajectories for chronic conditions
Operational efficiency: Predicting missed follow-ups or readmission likelihood
CoMET is like a weather model for health—it doesn’t tell you what’s wrong today, but it helps you prepare for what’s likely tomorrow.
🧠 MAI-DxO: Orchestrating Diagnostic Reasoning
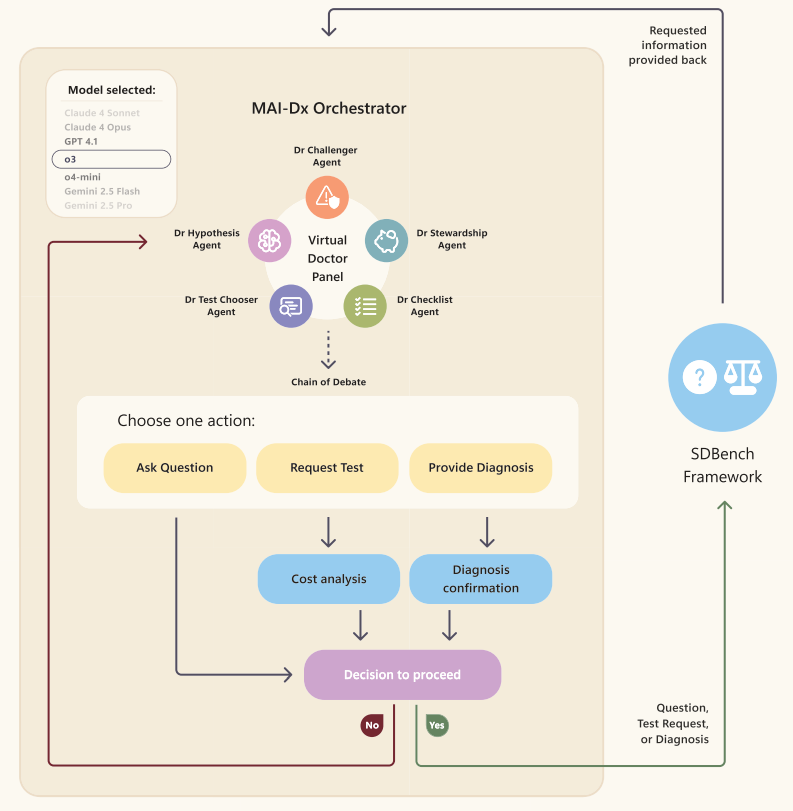
MAI-DxO (Medical AI Diagnostic Orchestrator) takes a different approach.
It’s a multi-agent system that coordinates multiple large language models (LLMs) to reason through complex diagnostic cases. Inspired by expert panels, MAI-DxO simulates the cognitive steps of a clinician: asking questions, ordering tests, revising hypotheses.
🔧 How It Works:
Sequential orchestration of LLMs (e.g., GPT-4o, Gemini, Claude)
Reasoning steps: Generate → Query → Revise
Cost-aware test ordering and hypothesis refinement
Achieves 85.5% diagnostic accuracy on NEJM challenge cases
🏥 Applications:
Acute diagnostic triage: Chest pain, fever, neurological symptoms
Rare disease identification: Navigating ambiguous presentations
Clinical education: Teaching diagnostic reasoning through AI panels
Cost optimization: Avoiding unnecessary tests via strategic deliberation
MAI-DxO doesn’t simulate futures—it thinks through the present, mimicking the deliberative process of seasoned clinicians.
👩⚕️ Human-Only Interventions: Strengths and Limitations
Traditional clinical workflows rely on human expertise, heuristics, and institutional protocols. While invaluable, they face several challenges. Here are a few:
⚠️ Limitations:
Cognitive overload: Clinicians juggle dozens of variables under time pressure
Bias and variability: Diagnostic decisions vary widely across providers
Overtesting: Defensive medicine leads to unnecessary tests and costs
Underutilized data: Structured EHR data often goes unanalyzed
🧠 Where AI Adds Value:
CoMET augments planning and forecasting, not decision-making
MAI-DxO enhances diagnostic reasoning, not clinical judgment
Both systems offer epistemic scaffolding, not replacement
Ultimately, decision-making and decision tree thinking sit with the licensed healthcare providers themselves. Consider these - “tools” or rather clever “helpers/assistants”. In all cases, I have consistently advocated strongly for the Human-in-the-Loop (HITL) elements to be applied always.
What does this synergy look like in practice, you might ask?
🧒 Amina’s Journey: A Case Study Across Time
Let’s follow a hypothetical patient, Amina, from adolescence to elder care, under hypothetical scenarios:
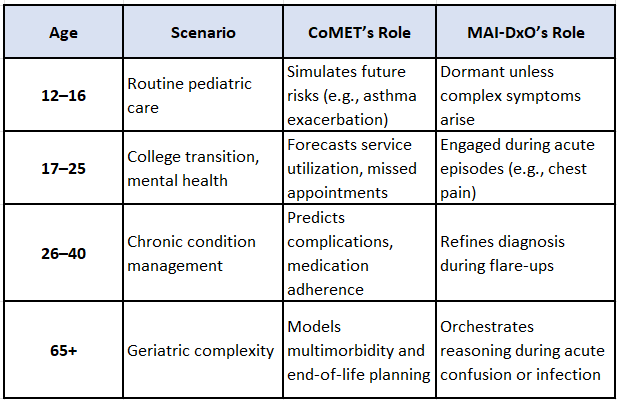
💡 Strategic Implications for Healthcare Systems
🏥 Planning & Budgeting:
CoMET enables scenario testing: What happens if statin adherence improves by 20%? What if outpatient capacity drops?
MAI-DxO helps optimize diagnostic pathways: Which tests yield the highest information gain per cost?
🧪 Testing Wisely:
Many hospitals default to test-everything strategies—driven by liability, uncertainty, or lack of decision support.
MAI-DxO challenges this by reasoning through necessity, reducing waste.
CoMET complements by forecasting downstream consequences of overtesting (e.g., false positives, follow-up burden).
🔍 Epistemic Contrast: Simulation vs Deliberation
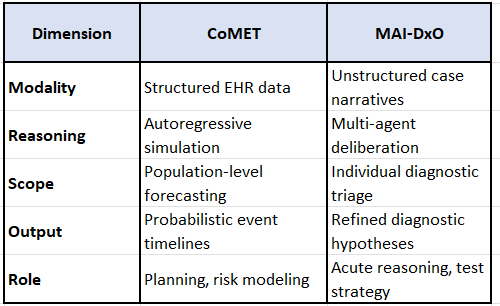
What About The Fidelity of Medical Reasoning In Large Language Models?
So are there any cautionary tales? Glad you asked! There was this recent detailed study, which is well worth reading, and I highly recommend (Note: I am quite sure there are and will be many others, so keep an eye out and follow up accordingly). So I will capture the main salient points, at least in context to CoMET and MAI-DxO:
⚠️ Limitations of the JAMA Article (in this context)
Sample Size: Only 68 questions tested—too narrow to generalize across clinical domains or reasoning types.
Evaluation Format: Multiple-choice with NOTA substitution doesn’t reflect real-world diagnostic complexity.
No Structured Data: CoMET operates on structured EHR event sequences; the article focuses on unstructured question-answering.
No Multi-agent Systems: MAI-DxO’s orchestration isn’t evaluated—yet it’s precisely the kind of reasoning architecture the article calls for.
No Simulation Models: CoMET’s autoregressive simulation pipeline is outside the scope of the article’s reasoning fidelity framework.
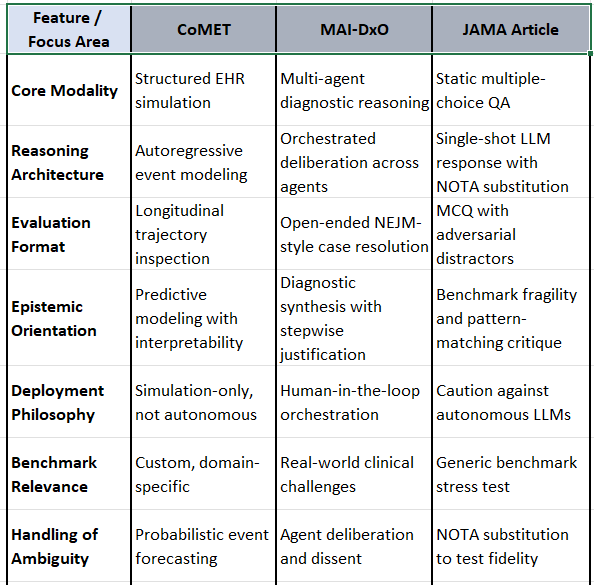

🧠 Why the JAMA Article Doesn’t Undermine CoMET or MAI-DxO
🔹 CoMET
Not an LLM: CoMET is a transformer-based simulation engine—not a language model—so the article’s critique of LLM reasoning fidelity is orthogonal.
No MCQ Format: CoMET doesn’t rely on multiple-choice answers or prompt engineering; it models clinical event trajectories.
Interpretability by Design: CoMET’s overlays and risk maps offer transparent insight into predictions, unlike the opaque outputs critiqued in the article.
🔹 MAI-DxO
Multi-agent Deliberation: MAI-DxO explicitly avoids brittle single-agent reasoning by orchestrating multiple agents with dissent and synthesis.
Real-world Case Format: It uses NEJM-style cases, not artificial MCQs, and requires stepwise justification—exactly what the article calls for.
Human-in-the-loop: MAI-DxO is not autonomous; it’s designed to augment clinician reasoning, not replace it.
⚠️ Limitations of the JAMA Article (in this context)
Narrow Format: MCQ-based NOTA substitution doesn’t reflect the complexity of real diagnostic reasoning.
No Multi-agent Evaluation: The article doesn’t test orchestrated systems like MAI-DxO, which are designed to overcome the very brittleness it critiques.
No Simulation Models: CoMET’s predictive simulation pipeline is outside the scope of the article’s reasoning fidelity framework.
No Structured Data Handling: The article focuses on unstructured QA, while CoMET and MAI-DxO operate on structured clinical inputs.
🧩 Strategic Conclusion
Having said that, the JAMA article is a valuable critique of overreliance on benchmark performance, but it’s definately not a refutation of CoMET or MAI-DxO.
In fact, both systems embody the very epistemic caution and architectural sophistication the article implicitly calls for.
CoMET offers simulation-based foresight with interpretability, and MAI-DxO operationalizes multi-agent reasoning with human oversight.
🧠 Toward Hybrid Intelligence in Medicine
From my point of view, CoMET and MAI-DxO aren’t just AI tools—they’re epistemic collaborators. CoMET helps us see what’s coming; MAI-DxO helps us understand what’s happening. Together, they offer a blueprint for hybrid intelligence in healthcare—where simulation informs strategy, and deliberation guides precision.
As hospitals move beyond automation toward strategic augmentation, these systems illuminate a future where AI doesn’t replace clinicians—it amplifies their insight.
No doubt there will be more such research in future. More interesting medical frontiers yet to be researched, but until then….
Have a great weekend all.