
Machine Memory: The Math That Matters

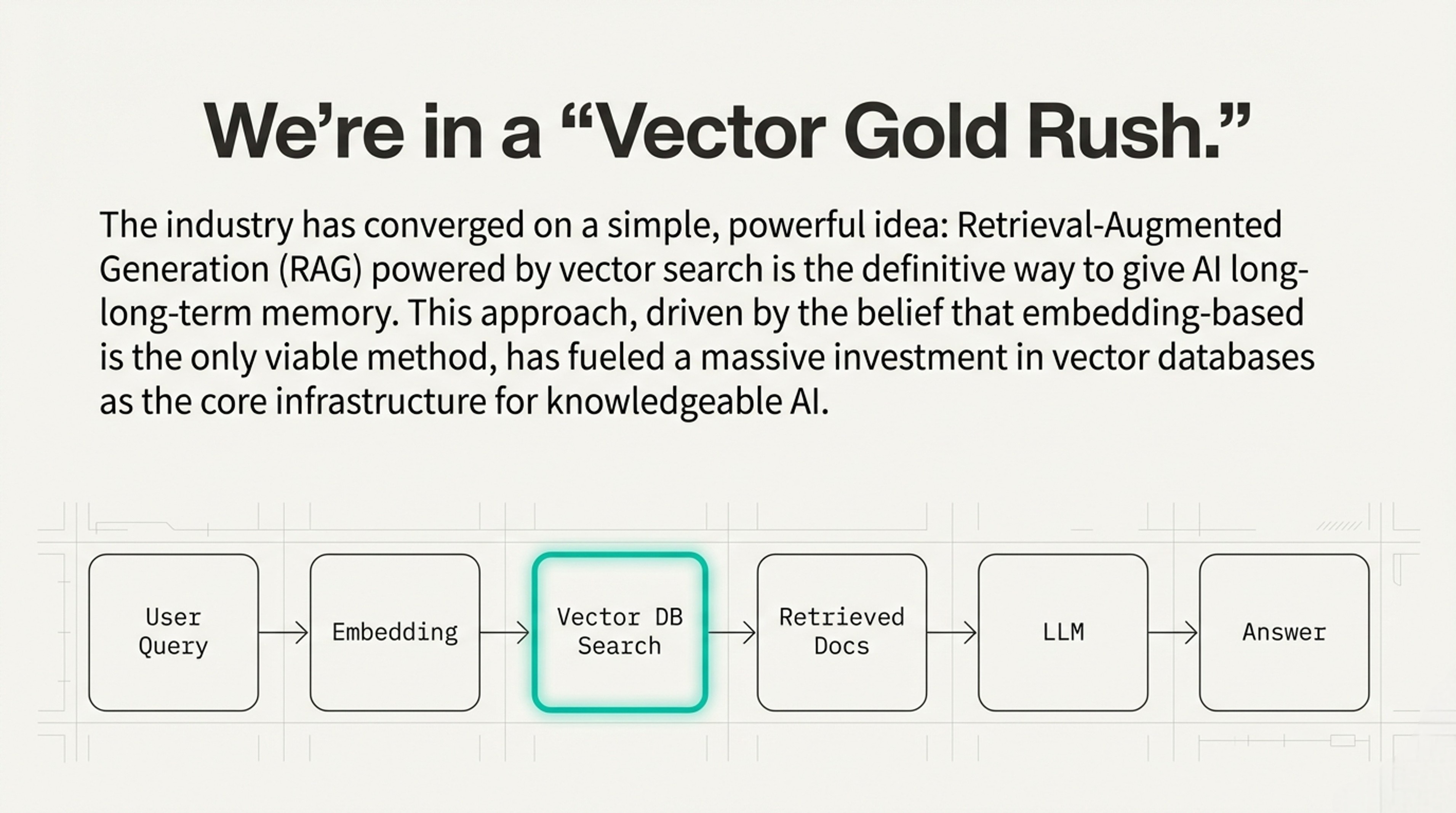
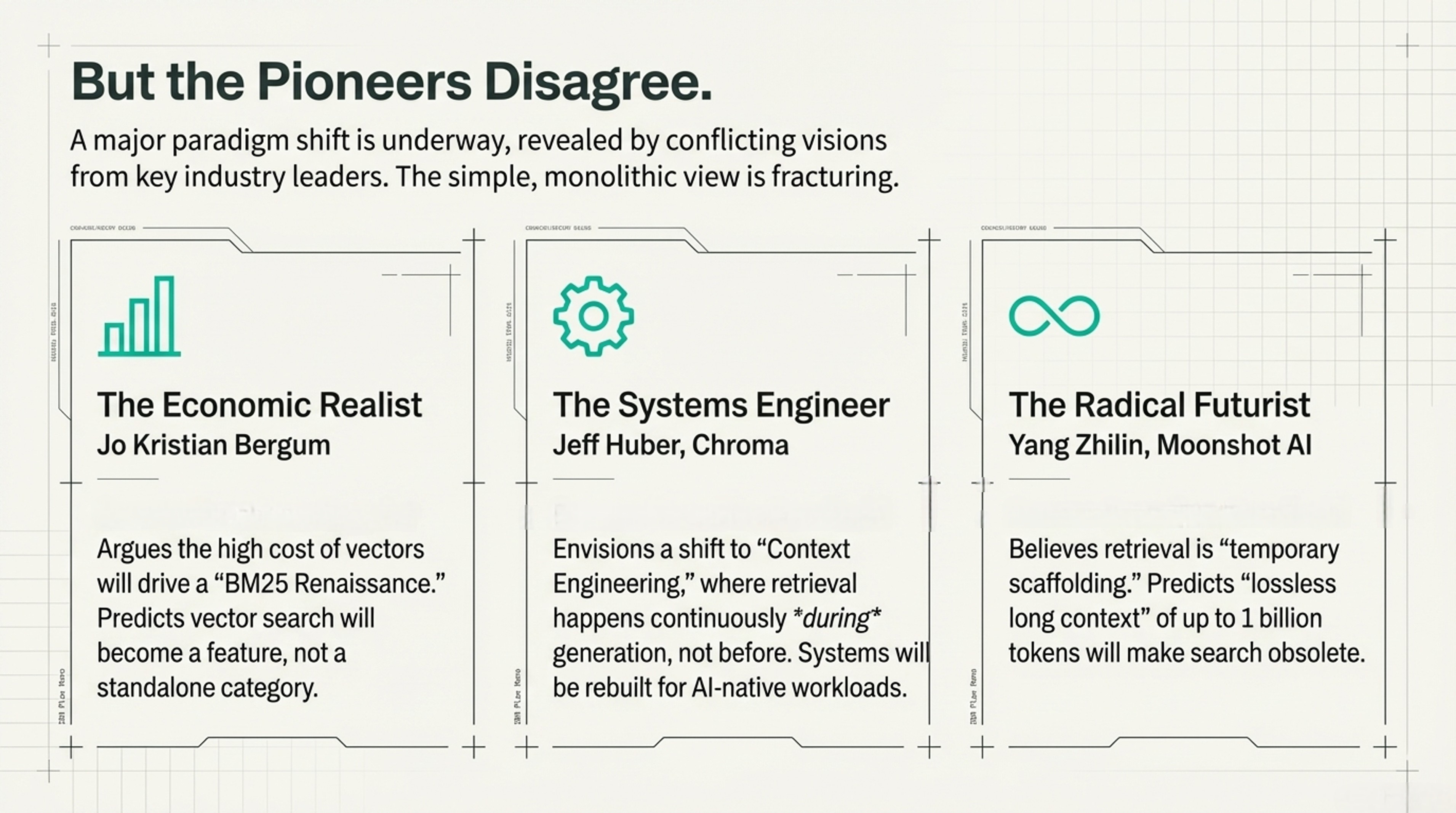
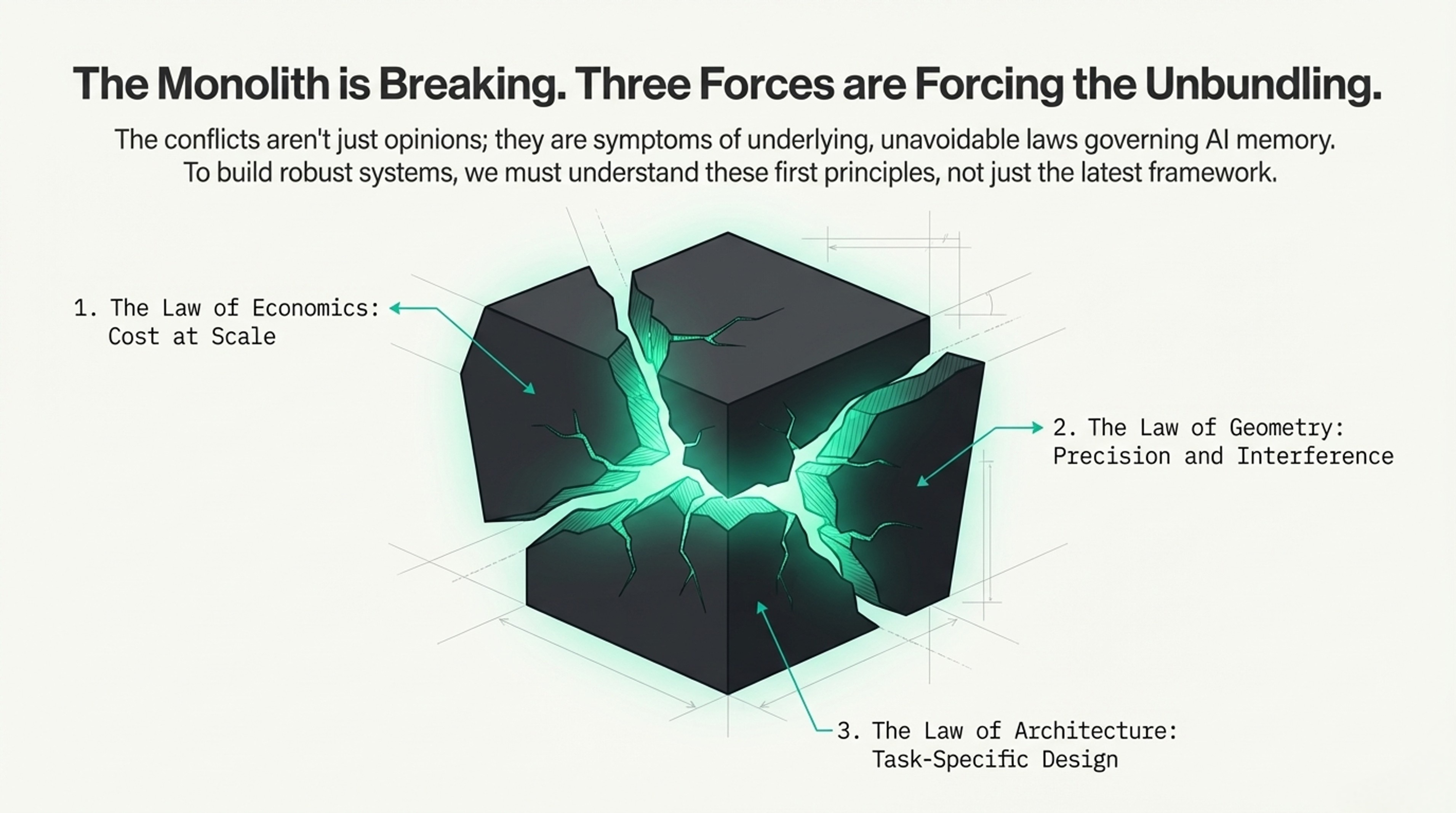
Cracks in the “Vector Gold Rush”

A few parting thoughts as we see 2025 out, and welcome a brand new 2026 in.
On Machine Memory which is going to be such an interesting space to watch.
This builds on a prior:
https://interestingengineering.substack.com/p/From-BM25-to-Agentic-RAG-the-evolution
And this: https://arxiv.org/abs/2512.13564 (Memory In The Age of AI Agents: Form Function and Dynamics)
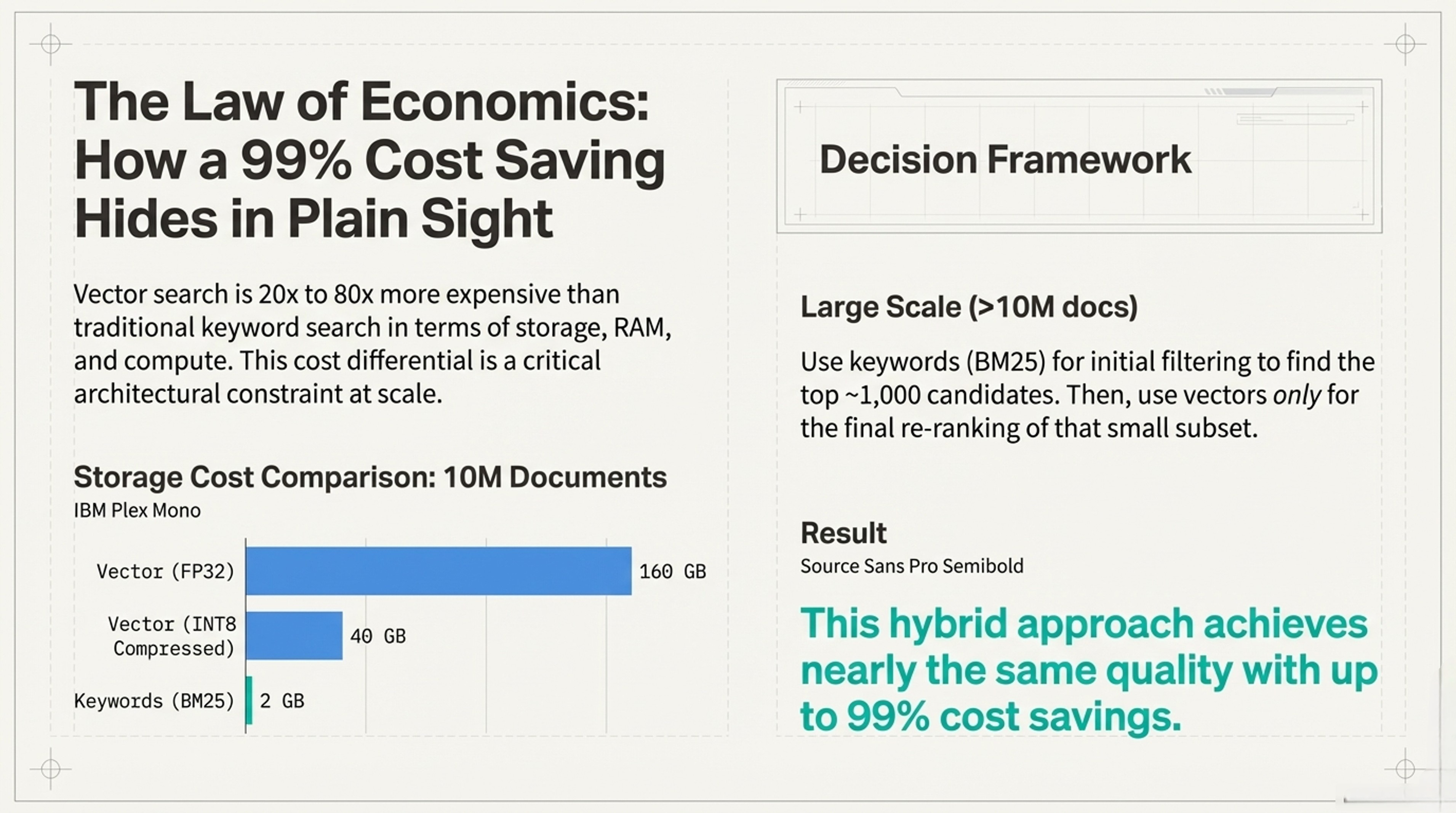
Framework 1: Vector Economics
The Cost Reality Check
The Calculation
Storage = Documents × Dimensions × Bytes per number
Example: 10 million documents
├─ Standard quality (FP32): 160 GB
├─ Compressed (INT8): 40 GB
└─ Keywords only (BM25): 2 GB
Ratio: Vector search costs 20-80× more than keywordsWhat are "dimensions"? Each word/phrase becomes a list of numbers (like coordinates). More numbers = more precision but more storage. Standard is 768 numbers per item; high-end is 4,096.
What This Tells Us
Vector search is expensive at scale. Not just disk space—also RAM, backups, and compute.
Decision Framework
Small scale (<1M documents)
→ Pure vector search is fine
Large scale (>10M documents)
→ Use keywords for filtering (find top 1,000)
→ Use vectors only for final ranking (top 10)
Result: 99% cost savings, minimal quality lossFramework 2: The Welch Bound
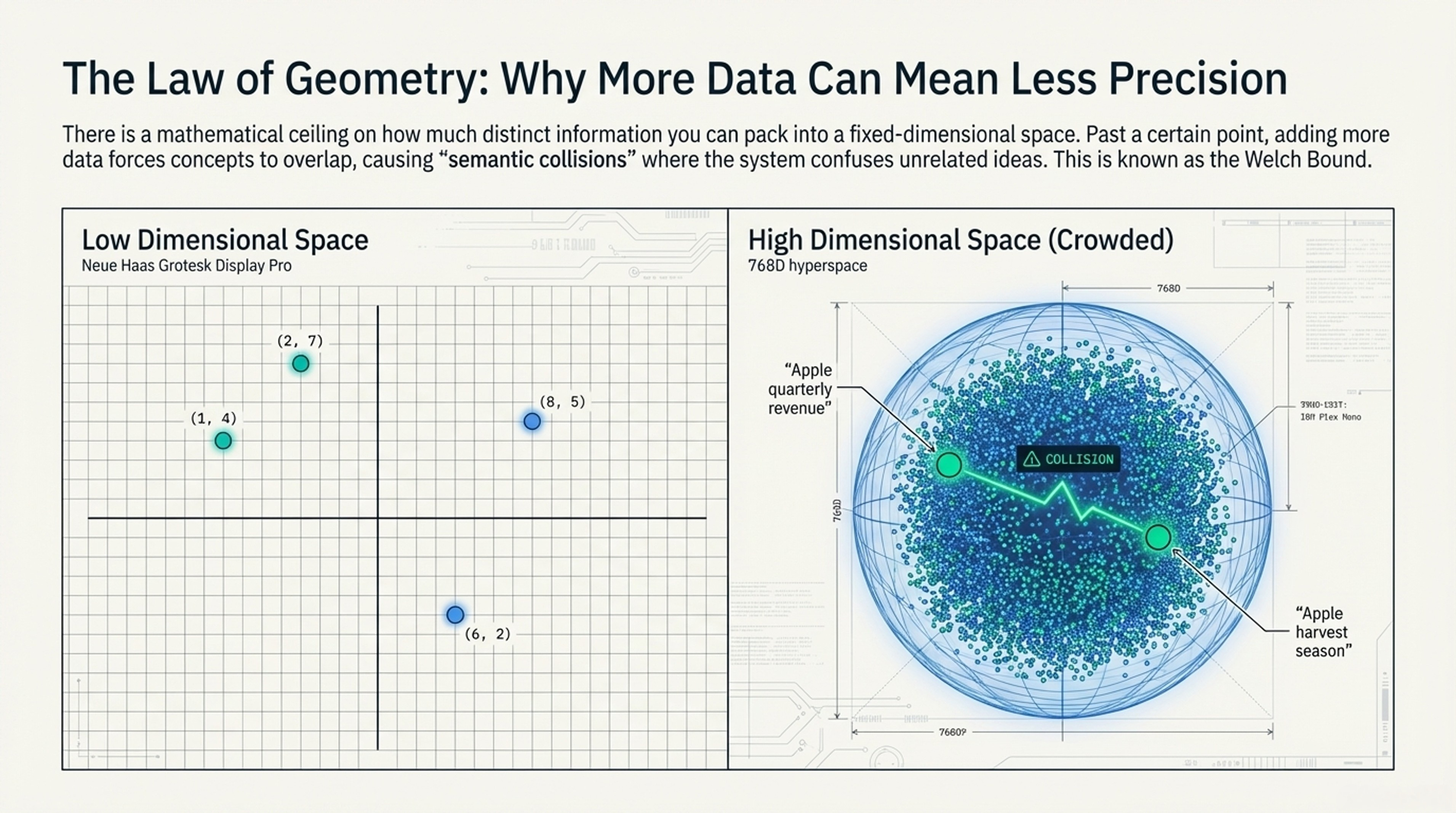
Why Cramming More Data Backfires
The Problem
Think of dimensions as a coordinate system:
- 2D space: Can fit ~4 distinct points before crowding
- 768D space: Can fit ~590,000 distinct points
Add 10M points to 768D space?
→ Forced overlap (like musical chairs)
→ Different things start looking similar
→ "Semantic collisions"The Interference Effect
As you add more items:
├─ Space gets crowded
├─ Items forced to sit close together
└─ System confuses "similar vectors" with "relevant results"
Example gone wrong:
Query: "Apple quarterly revenue"
Bad match retrieved: "Apple harvest season"
Why? Both have "Apple" + numbers → vectors too similarWhat This Tells Us
There's a mathematical ceiling. You can't just add more data and expect better results—the geometry works against you.
Decision Framework
High precision needed (legal, medical, finance):
→ Use more dimensions (1,536 or 4,096)
→ Add hard filters (e.g., "price must be < $2000")
→ Use specialized encoders for different data types
General search (lower stakes):
→ Standard dimensions (768) OK
→ Accept some noise
→ Clean up with rerankingWhat's reranking? A second, smarter pass that re-orders your top results for better accuracy.
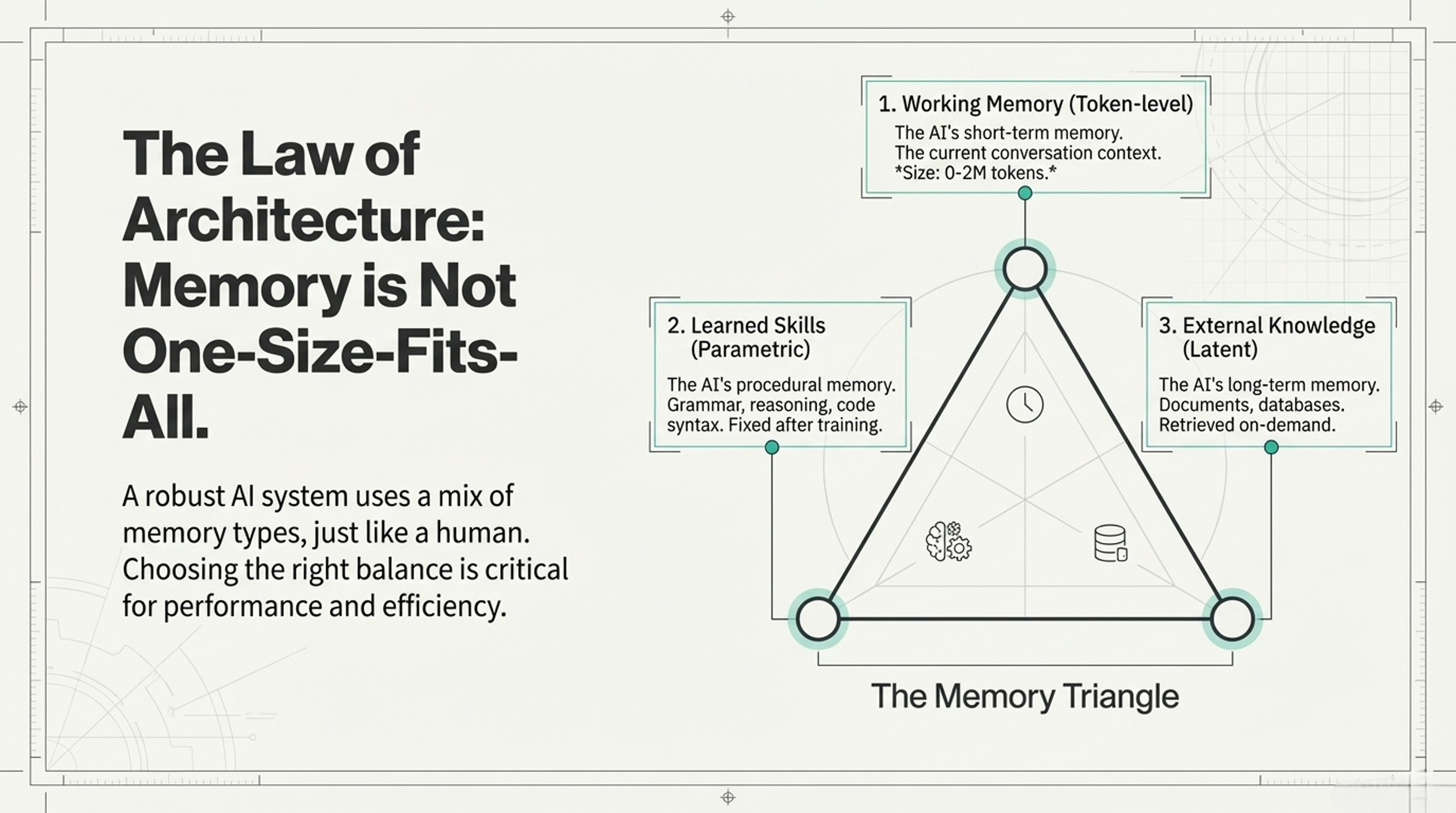
Framework 3: The Memory Triangle
Three Types of Machine Memory
The Components
1. WORKING MEMORY (Token-level)
- Like human short-term memory
- What's in the current conversation
- Size: 0-200K words typical
2. LEARNED SKILLS (Parametric)
- Like human procedural memory
- Grammar, reasoning patterns, code syntax
- Fixed after training
3. EXTERNAL KNOWLEDGE (Latent)
- Like human long-term facts
- Documents, databases, past conversations
- Retrieved on-demandTask-Specific Balance
Personal Assistant:
├─ 70% working (remember our conversation)
├─ 20% external (your preferences saved)
└─ 10% skills (language ability)
Research Agent:
├─ 30% working (current analysis)
├─ 60% external (papers, data, reports)
└─ 10% skills (reasoning ability)
Code Generator:
├─ 40% working (current file context)
├─ 10% external (documentation lookup)
└─ 50% skills (syntax, patterns)What This Tells Us
Different tasks need different memory mixes. One-size-fits-all fails.
Decision Framework
Building a chatbot?
→ Maximize working memory
Building a research tool?
→ Maximize external knowledge retrieval
Building a code assistant?
→ Maximize learned skills (fine-tune on code)Framework 4: Continuous vs Discrete Retrieval
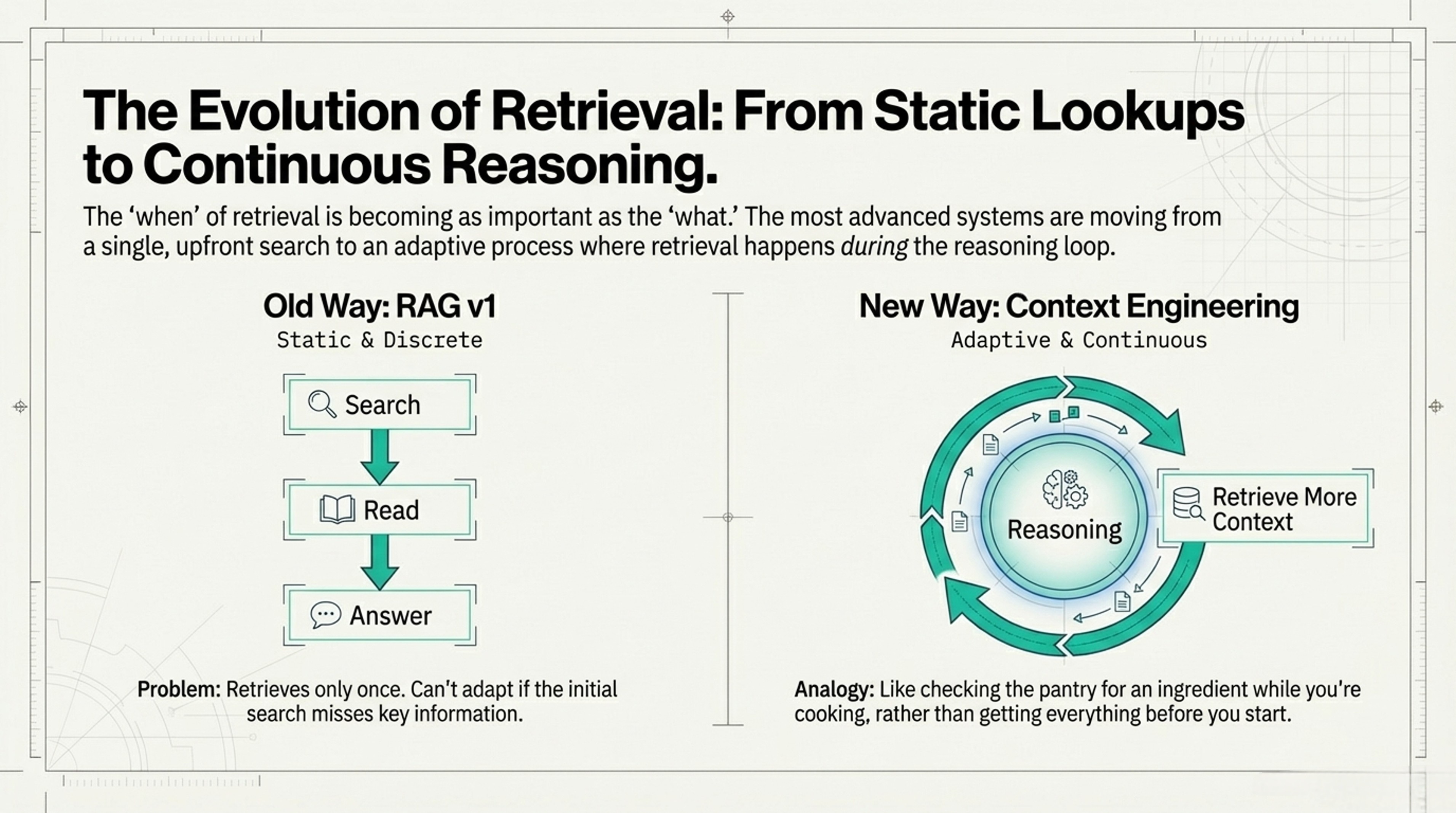
When to Look Things Up
Old Way (RAG v1)
Step 1: Look up documents [WAIT]
Step 2: Read documents + question to AI [WAIT]
Step 3: Generate answer
Problem: Retrieves once, can't adapt if initial search misses somethingNew Way (Context Engineering)
While AI is thinking:
├─ Monitor: "Am I uncertain?"
├─ If yes: Pause and retrieve more context
├─ Update understanding
└─ Continue reasoning
Result: Retrieval happens DURING thinking, not beforeThe Math
Old way: Quality depends on one initial search
New way: Quality improves continuously as AI reasons
Like the difference between:
- Getting all ingredients before cooking (old)
- Checking pantry AS you cook when needed (new)Decision Framework
Simple lookups (hours, weather, definitions):
→ Old RAG (cheaper, good enough)
Complex reasoning (research, analysis, multi-step):
→ Continuous retrieval (better results)
→ Retrieve when AI detects uncertaintyFramework 5: Context Maximalism
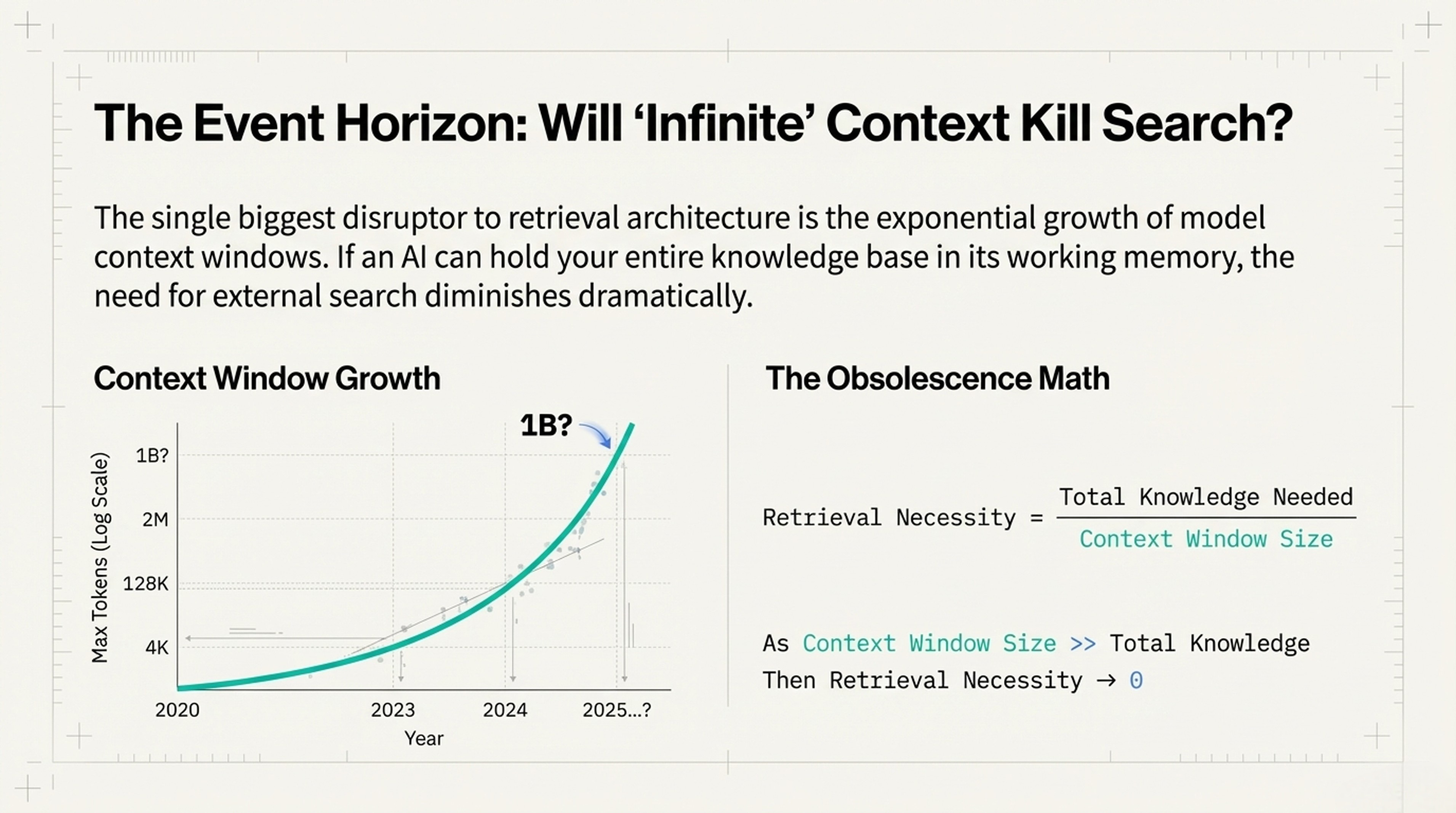
Will Infinite Memory Kill Search?
The Scaling Trend
Context Window = How much text AI can "hold in mind"
2020: 4,000 words
2023: 128,000 words
2024/5: 2,000,000 words
2026: ???
Prediction: 1 billion words possibleThe Obsolescence Math
Retrieval Necessity = Knowledge Needed / Context Size
When context >> knowledge:
Retrieval Necessity → Almost zero
Example:
- Need: 100,000 words of company docs
- Have: 1,000,000 word context window
- Solution: Just load everything, no search neededWhat This Tells Us
If AI can hold your entire knowledge base in "working memory," why search at all? Just load everything once.
Decision Framework
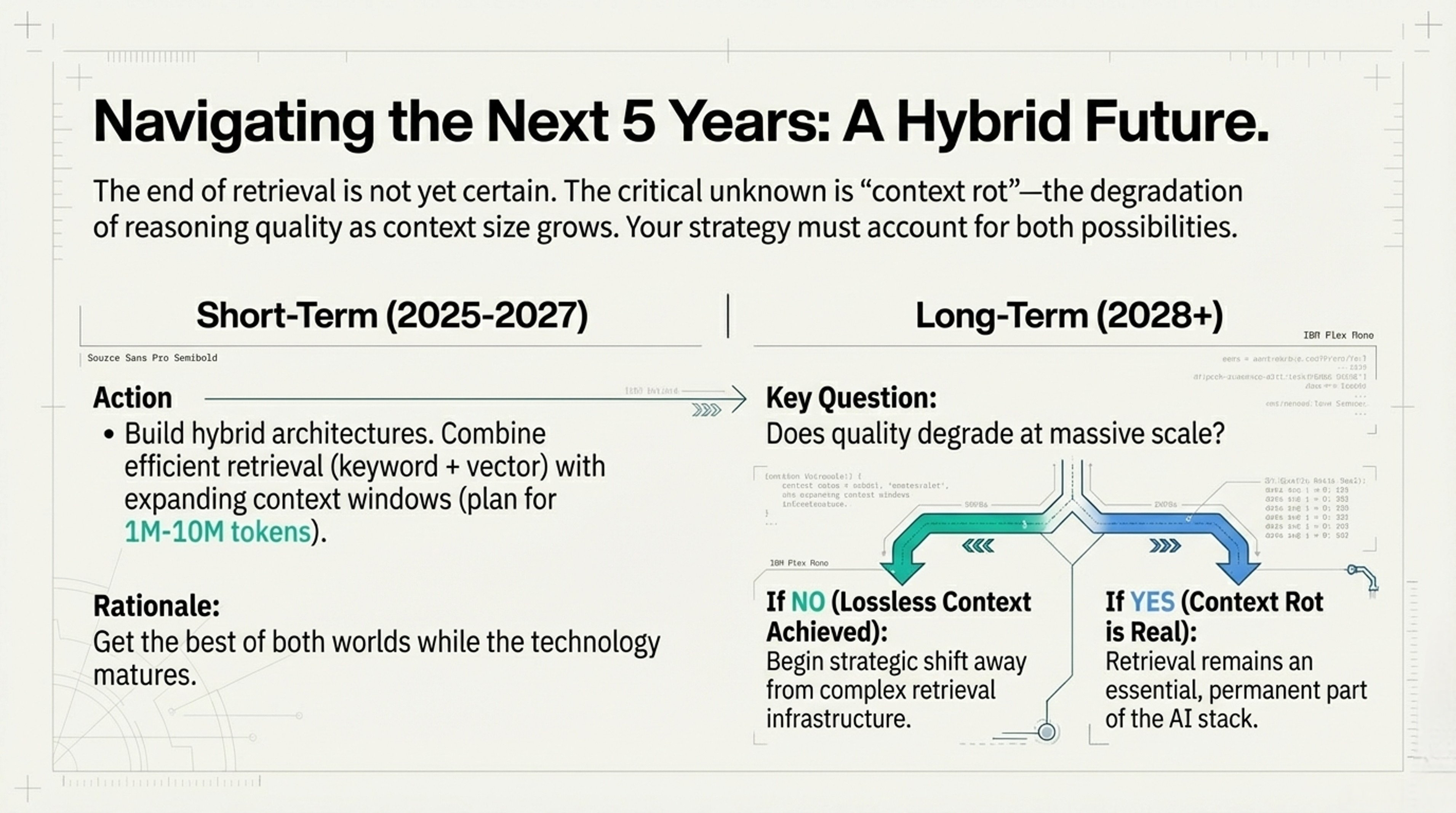
Short-term (2025-2027):
→ Build hybrid: retrieval + expanding context
→ Plan for 1M-10M word windows
Long-term (2028+):
→ Watch for "context rot" (does quality degrade?)
→ IF unlimited context works without degradation:
→ Shift away from retrieval infrastructure
→ IF quality still degrades:
→ Retrieval remains essential foreverWhat's "context rot"? When AI's performance drops as you feed it more text—like human attention span failing with too much information.
Quick Decision Matrix

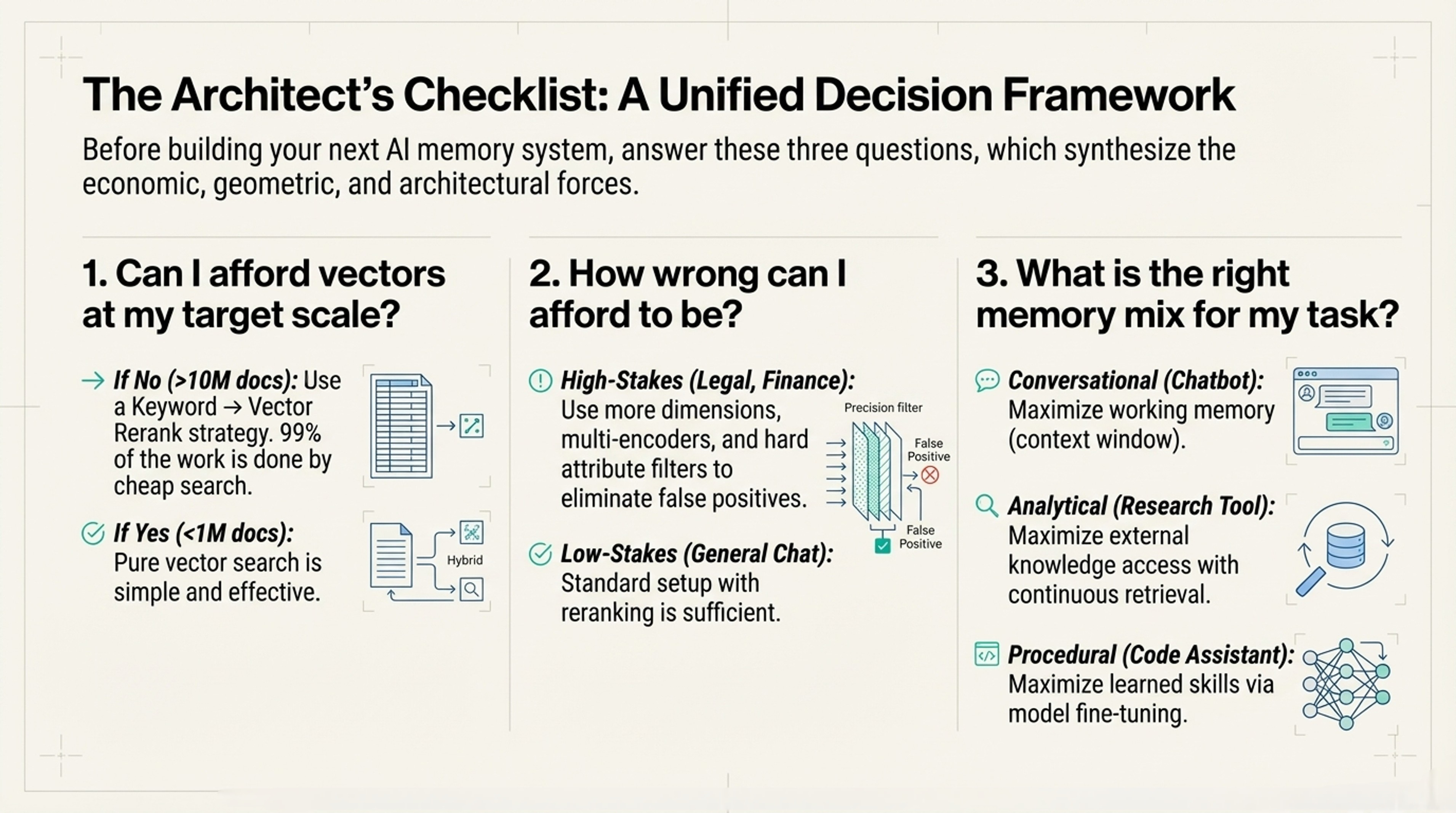
The Three-Question Test
Before building any memory system:
1. Can I afford vectors at my scale?
Cost = (Storage + Compute) × Scale
IF expensive:
Use keywords for 99% of work
Use vectors only for final 1%2. How wrong can I be?
High-stakes (medical, legal):
→ Need extra dimensions + hard filters
Low-stakes (general chat):
→ Standard setup fine3. How fast does my knowledge change?
Static knowledge:
→ Train it into the model (parametric)
Evolving knowledge:
→ Store externally, retrieve as neededThe Core Insight
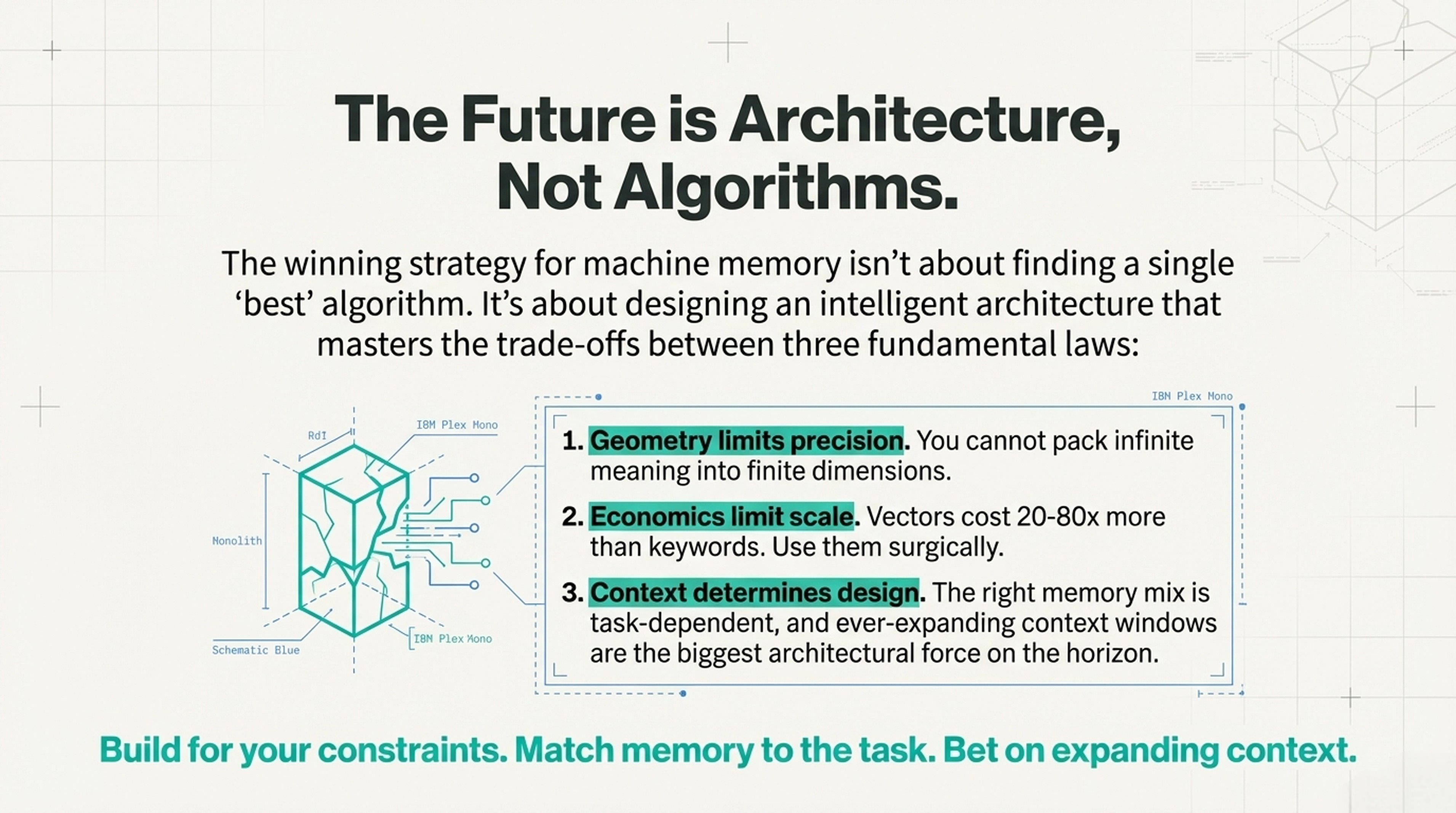
Machine memory follows three laws:
Geometry limits precision (can't pack infinite meaning into finite dimensions)
Economics limit scale (vectors cost 20-80× more than keywords)
Context determines architecture (bigger windows = less retrieval needed)
Your strategy?
Match memory type to task requirements
Use expensive methods (vectors) only where needed
Bet on expanding context windows long-term
Ultimately recognition that the future isn't the fanciest algorithm—it's the right memory architecture for your constraints and timeline.



I also note an interesting paper MEMEvolve: https://arxiv.org/abs/2512.13564
Which gives a fresh view on the frameworks above which describe the design space. MemEvolve navigates that space automatically using Pareto optimization over (Performance, Cost, Delay).
In essence it's meta-learning for memory architecture—the system that learns how to learn.
MemEvolve: Meta-Evolution of Memory Systems
Core Problem: Current AI agent memory systems use fixed architectures (like always storing tips, or always building tool libraries). But different tasks need different memory strategies—what works for web browsing fails for math reasoning.
The Insight: The best human learners don't just remember—they adapt how they learn based on the subject. You memorize poems but derive formulas for math. Current agents are "skillful learners" (they extract insights), but MemEvolve makes them "adaptive learners" (they evolve their learning strategy itself).
How It Works: The Math
The Dual-Evolution Process
Traditional agents (single evolution):
M_{t+1} = Ω(M_t, ε_τ)
Where:
M_t = Memory state at time t
Ω = Fixed memory architecture (never changes)
ε_τ = Experience from trajectory τMemEvolve (dual evolution):
Inner Loop (Experience Evolution):
M^(k)_{t+1,j} = Ω^(k)_j(M^(k)_{t,j}, ε_τ)
↓
For each memory architecture candidate j,
populate it with new experiences
Outer Loop (Architecture Evolution):
{Ω^(k+1)_{j'}} = F({Ω^(k)_j}, {F^(k)_j})
↓
Evolve the memory architectures themselves
based on performance feedbackThe Four-Component Modular Design
Any memory system Ω decomposes as:
Ω = (E, U, R, G)
Where:
E = Encode (trajectory → structured memory)
U = Store (commit to database)
R = Retrieve (context-aware recall)
G = Manage (consolidate/forget)Example evolution:
Iteration 1: Basic system
E: Store raw trajectories
U: JSON database
R: Semantic search
G: None
↓ (Meta-evolve based on failures) ↓
Iteration 3: Cerebra system
E: Extract 5 abstraction levels (steps→tools→strategies)
U: Graph database with relationships
R: Hybrid semantic + tool matching + LLM guard
G: Node pruning + edge consolidationThe Selection Math (Pareto Ranking)
Fitness vector for each candidate:
F^(k)_j = (Perf^(k)_j, -Cost^(k)_j, -Delay^(k)_j)
Step 1: Non-dominated sorting
Rank candidates by Pareto dominance:
- A dominates B if better in ≥1 dimension, not worse in any
Step 2: Within same Pareto rank, sort by Perf^(k)_j
Step 3: Select top-K as "parents"
P^(k) = Top-K(ρ^(k)_j, Perf^(k)_j)This ensures you keep systems that balance quality AND efficiency.
Diagnose-and-Design Evolution
For each parent Ω^(k)_p:
1. Diagnosis: Analyze failure patterns
Input: Trajectories T^(k)_p with outcomes
Process: LLM examines:
- Where did retrieval fail?
- Were encodings too vague?
- Was storage inefficient?
Output: Defect profile D(Ω^(k)_p)2. Design: Generate S variants
Ω^(k+1)_{p,s} = Design(Ω^(k)_p, D(Ω^(k)_p), s)
Modify only valid components:
- Change E: "3 levels → 5 levels of abstraction"
- Change U: "JSON → Graph database"
- Change R: "Add LLM guard to filter noise"
- Change G: "Add consolidation every 10 tasks"How This Applies to The Above Frameworks
1. Resolves the Vector Economics vs Quality Tradeoff
Framework 1 (Vector Economics) says: Use cheap BM25 for filtering, expensive vectors only for reranking.
MemEvolve adds: The memory system learns when to use which retrieval method based on task feedback.
Initial system (Iteration 0):
R = Semantic vector search only
Cost = $0.141/task, Perf = 69%
Evolved system (Iteration 3):
R = Hybrid: BM25 filter → Vector rerank → LLM guard
Cost = $0.136/task, Perf = 74%It discoveres the economic optimization automatically through meta-evolution.
2. Breaks Through the Welch Bound Limitation
Framework 2 (Welch Bound) says: You can't pack infinite meaning into fixed dimensions—collisions happen.
MemEvolve adds: Instead of fighting geometry, store memory at multiple abstraction levels to avoid compression loss.
Basic system: Single embedding per trajectory
Problem: Collapses "how I solved this" + "what tools worked"
+ "what failed" into ONE vector → information loss
Evolved Cerebra system:
E = Multi-level encoding:
Level 1: Raw steps (fine-grained)
Level 2: Tool sequences (medium)
Level 3: Strategy patterns (abstract)
Level 4: Meta-insights (highest)
Each level gets separate storage → no forced compressionThis sidesteps the Welch Bound by creating hierarchical memory spaces instead of cramming everything into one vector space.
3. Dynamically Balances the Memory Triangle
Framework 3 (Memory Triangle) says: Different tasks need different mixes of token/parametric/latent memory.
MemEvolve adds: The system auto-tunes the balance based on what works.
Task: Web research (from benchmark)
Initial guess: 50% token, 30% latent, 20% parametric
After evolution discovers:
E = Store domain-specific guidance (latent)
R = Provide stage-aware context (token + latent hybrid)
G = Prune outdated web patterns (manage latent)
Result: 60% latent, 35% token, 5% parametric
(Because web tasks need fresh external knowledge > conversation history)4. Implements Your "Continuous Retrieval" Vision
Framework 4 (Context Engineering) says: Retrieval should happen DURING generation, not before.
MemEvolve's Lightweight system (Figure 8) does exactly this:
Step 1: Planning stage
Memory provides: Anti-ambiguity tips, Planning advice
Step 2: Execution stage
Memory provides: Tool-use suggestions, Context reminders
Step 3: Verification stage
Memory provides: Common failure patterns, Validation checks
This is continuous retrieval—memory adapts to generation phase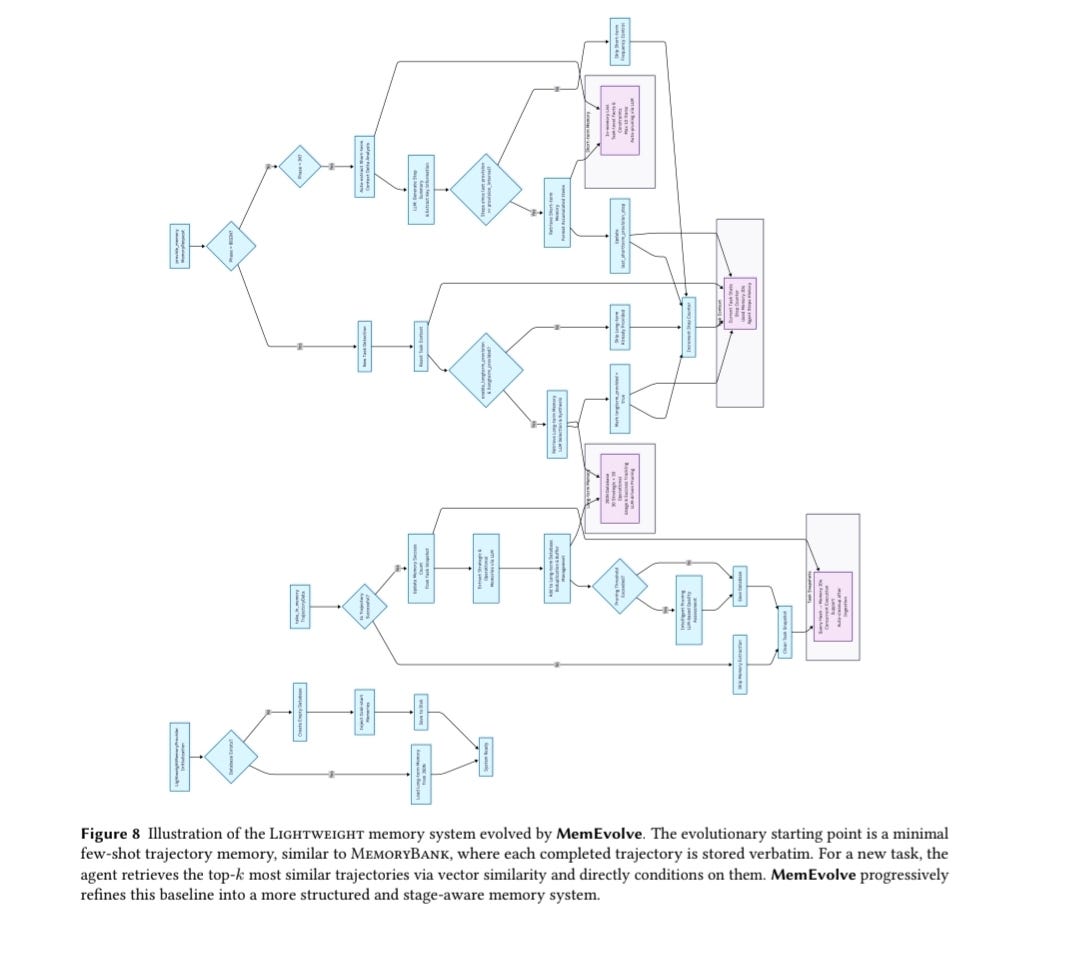
5. Prepares for Context Maximalism
Framework 5 (Context Maximalism) says: Unlimited context might make retrieval obsolete.
MemEvolve's position: Even with infinite context, you still need intelligent memory organization.
Problem: Loading 1M tokens of raw experience into context
Reality: Context rot—performance degrades with noise
MemEvolve solution:
G (Manage) = Consolidate redundant experiences
E (Encode) = Abstract into principles, not raw text
R (Retrieve) = Synthesize relevant subset
Even with 1B token context, you don't want RAW memory—
you want STRUCTURED, PRUNED, ABSTRACTED memoryThe Unified Framework Integration
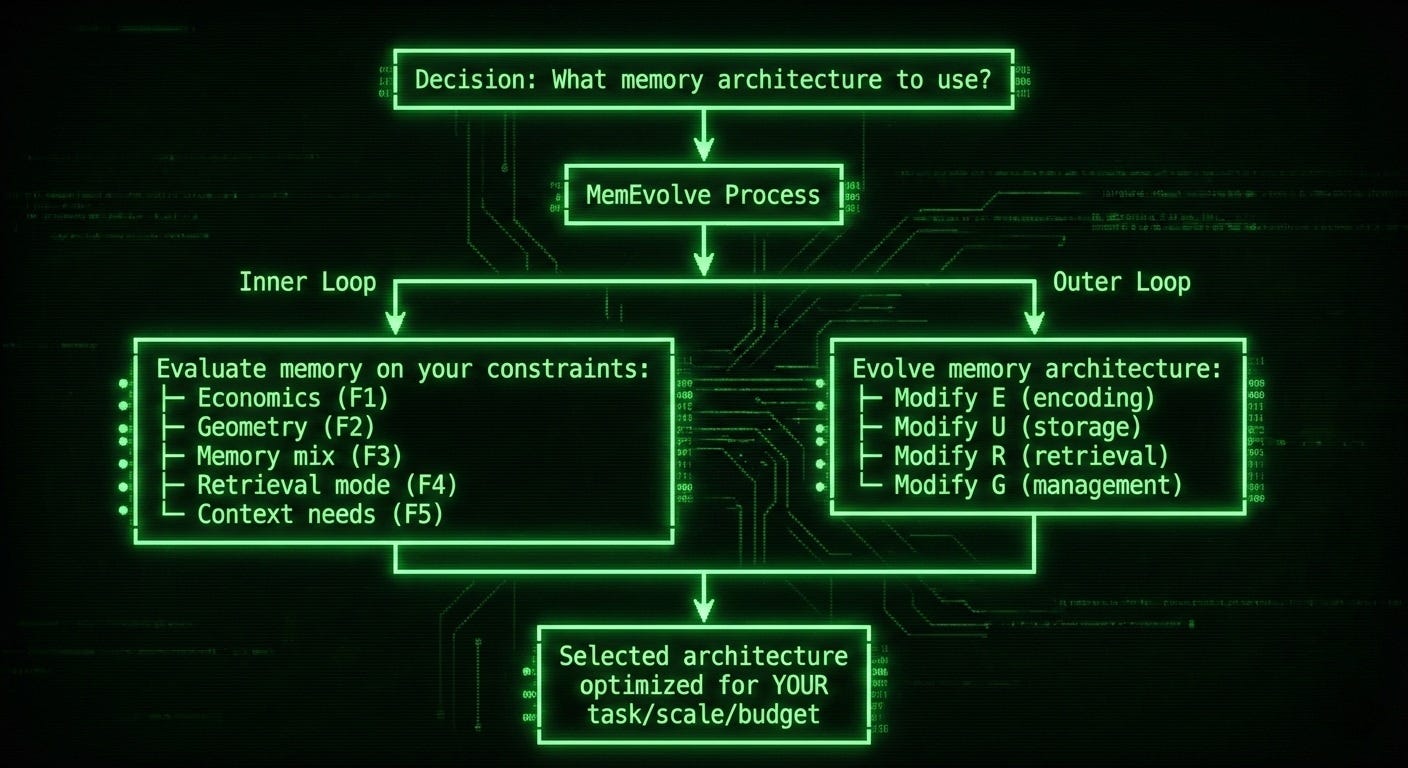
5 Frameworks + MemEvolve = Adaptive Memory Engine
┌─────────────────────────────────────────────────┐
│ Decision: What memory architecture to use? │
└─────────────────────────────────────────────────┘
↓
┌───────────┴───────────┐
│ MemEvolve Process │
└───────────┬───────────┘
↓
┌───────────────┼───────────────┐
│ │
Inner Loop Outer Loop
│ │
↓ ↓
Evaluate memory Evolve memory
on your constraints: architecture:
├─ Economics (F1) ├─ Modify E (encoding)
├─ Geometry (F2) ├─ Modify U (storage)
├─ Memory mix (F3) ├─ Modify R (retrieval)
├─ Retrieval mode (F4) └─ Modify G (management)
└─ Context needs (F5)
│ │
└───────────────┬───────────────┘
↓
Selected architecture
optimized for YOUR
task/scale/budgetPractical Application: Decision Matrix + MemEvolve
Before MemEvolve (Manual decision):
IF cost-limited → Use BM25 hybrid
IF precision-critical → Use multi-encoder
IF future-betting → Use context engineering
With MemEvolve (Automated meta-learning):
Step 1: Start with baseline (e.g., BM25 hybrid)
Step 2: Inner loop (60 tasks)
Measure: Perf, Cost, Delay
Feedback: "BM25 fails on 30% of queries needing semantic understanding"
Step 3: Outer loop (meta-evolution)
Diagnosis: "Need semantic matching for ambiguous queries"
Design: Add vector rerank for top 100 BM25 results
Step 4: Next iteration
New system: BM25 (95% of work) + Vectors (5% of queries)
Result: 15% better performance, only 2% cost increase
Continue evolving for 3 iterations...The Bottom Line
MemEvolve solves the meta-problem: Instead of you manually picking which memory strategy to use based on your 5 frameworks, the system learns which strategy works through dual evolution.
How it uses the frameworks:
Vector Economics → Learns cost-effective retrieval mixes
Welch Bound → Discovers hierarchical encodings to avoid collisions
Memory Triangle → Auto-tunes token/parametric/latent ratios
Continuous Retrieval → Evolves stage-aware memory provision
Context Maximalism → Prepares structured memory for large contexts
Key insight: Frameworks describe the design space. MemEvolve navigates that space automatically using Pareto optimization over (Performance, Cost, Delay).
It's meta-learning for memory architecture—the system that learns how to learn.