
Not a Chip War. A Margin War
Owning The Price of Compute + The Price of Intelligence. The Ironwood Gambit: Google’s Margin War Against Nvidia




I · The Real Thesis
The “Nvidia Tax” Is a Business Model, Not a Benchmark Problem
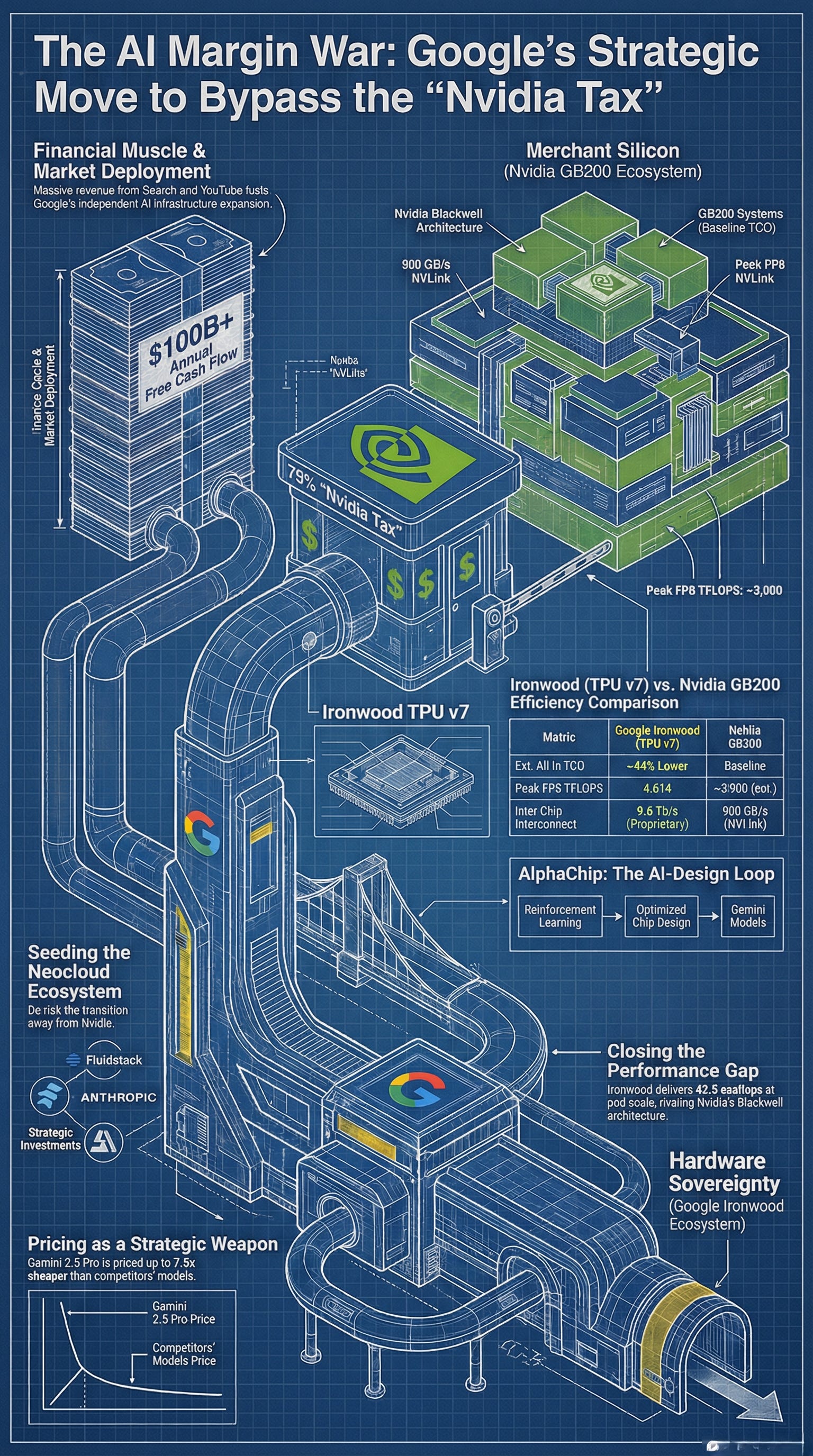
The conventional read of the WSJ’s February 20 report frames Google as a hardware underdog scrambling to grab share from Nvidia’s dominant position. That framing badly misses the point. Google isn’t trying to win a silicon horse race. It is attempting something far more structurally ambitious: the elimination of a ~75% gross-margin vendor from its own cost stack.
For any hyperscaler, paying Nvidia’s prices isn’t merely expensive—it represents a permanent transfer of economic surplus to a third party. Every dollar spent on an H100 or GB200 system enriches a supplier whose interests are not aligned with Google’s. The Ironwood TPU program, at its core, is Google’s attempt to reclassify AI compute from an external capital expenditure into an internal operational capability—the same playbook it used with server hardware, network switches, and submarine cable.

SemiAnalysis — “TPUv7: Google Takes a Swing at the 900lb Gorilla,” Nov 2025
That 44% TCO gap is not purely a hardware achievement. It reflects the compounded advantage of: stripping Nvidia’s margin from the BOM, eliminating the GPU’s general-purpose overhead that is irrelevant for AI workloads, and co-designing silicon and software in a single feedback loop that no merchant silicon vendor can replicate.
II · The Hardware
Ironwood: Closing the Gap Where It Matters
Introduced in April 2025 and made generally available in November, Google’s seventh-generation TPU—Ironwood—represents a qualitative shift in how seriously Google’s silicon competes at the frontier. Per chip: 4,614 FP8 TFLOPS, 192 GB HBM3e, 7.4 TB/s bandwidth. At pod scale, 9,216 chips deliver 42.5 exaflops—a figure that exceeds any existing supercomputer.

SemiAnalysis notes that Ironwood “nearly completely closes the gap” to Nvidia’s Blackwell on FLOPs, memory, and bandwidth—arriving only one to two quarters later than GB200. More critically, Ironwood’s architecture uses Google’s proprietary AlphaChip-designed layout (trained via reinforcement learning), a chip-design methodology no external customer of Nvidia or AMD has access to.
III · The Money Move
“Capital as a Service”: Manufacturing Demand That Doesn’t Exist Yet
Nvidia’s competitive moat is not just transistors. It is infrastructure lock-in: a generation of data centers built to its specifications, a software ecosystem (CUDA) with a decade of momentum, and a network of operators who have no alternative silicon to run. Google’s response isn’t to win those operators over on specs. It’s to build them—financially.
Google’s Capital Deployment Map (Feb 2026)

The Fluidstack deal is the most strategically interesting piece. CoreWeave—Fluidstack’s closest comparable—is essentially a leveraged Nvidia distribution arm: it borrows cheaply against GPU collateral and resells Nvidia compute at a premium. Google is attempting to create a parallel neocloud ecosystem where the underlying silicon is TPU, not GPU—effectively seeding its own CoreWeave before Nvidia’s distribution advantage can harden further.
IV · The Second Front
The Model Layer: Pricing as a Strategic Weapon, Not a Revenue Play
The silicon play is only half the story. Google is running an identical margin-compression strategy one layer up, at the model level—and the cash flow base that makes it possible has no precedent in AI history. With over $100B in annual free cash flow generated by Search, YouTube, and Cloud, Google’s profitability is structurally independent of whether anyone uses Gemini. That independence is itself a strategic asset, and it is being deployed deliberately.
Gemini 2.5 Pro is priced at approximately 7.5× cheaper than Anthropic’s Claude Opus on input tokens and 6× cheaper on output. For a company like Anthropic, whose commercial survival depends on aggressive model monetization, matching that pricing is existentially difficult. Google has no such constraint. It can afford to let Gemini function as a research vehicle rather than a revenue engine—its profitability never threatened by individual user preference. The pricing doesn’t need to make sense as a standalone business line, because Google is not a standalone AI business.

This reframes what Google is actually building toward. The chip investment, the neocloud ecosystem, the aggressive model pricing—these are not primarily moves to win market share in the consumer AI race. They are the infrastructure required to run long-horizon scientific experiments at a scale and cost that no external vendor would sustain. Google doesn’t need to win the chatbot market. It needs enough compute sovereignty to pursue problems where the payoff is measured in Nobel Prizes and new industries, not subscription revenue.

The model pricing table above clarifies something the hardware discussion often obscures: Google is not competing with Anthropic for the same customers at the same price points. Gemini’s architecture makes it a strong “naked reasoner”—optimized for high-volume, deep single-pass inference at low cost. Claude Opus is built for “equipped reasoning”—sustained agentic workflows, tool orchestration, and multi-step autonomous tasks that justify the premium. The apparent paradox of Google selling TPUs to Anthropic while pricing Gemini to undercut it resolves cleanly: they are not competing for the same workload. Google is the infrastructure; Anthropic is a tenant.
V · The Integrated Stack
The Moat Nvidia Cannot Copy: Hardware Designed by the Model Team
Nvidia builds generalist GPUs (Yes noted on the Blackwell’s and Rubin’s being tailored for inference but prior to this) and sells them to a fragmented market. Google builds TPUs that are co-designed by the same team running Gemini. That is not a marketing distinction. It is a compounding advantage with architectural consequences.

Google Cloud Blog — “3 Things to Know About Ironwood,” Nov 2025
This creates a reinforcing loop that external buyers cannot access: the chip layout is optimized by reinforcement learning (AlphaChip - note this is now a separately spun off Moonshot by the team who worked on it), trained on performance data from the actual models that will run on it. The chip improves the model. The model improves the chip design. Ironwood is the third consecutive TPU generation produced this way. Each iteration widens the gap between Google’s internal TCO and the open market price of Nvidia compute. Critically, AlphaChip’s ability to compress design cycles—shrinking what traditionally takes months into weeks—means Google’s silicon roadmap can iterate faster than a merchant vendor serving a heterogeneous customer base. That speed compounds directly into cost: faster generations mean more efficient chips sooner, which in turn enables more aggressive pricing at the model layer. The chain is: better chips faster → cheaper internal compute → cheaper external pricing → pressure on every competitor that still pays the Nvidia toll.
Separately, the recent promotion of Amin Vahdat—head of Google’s chip and network programs—to Chief Technologist for AI Infrastructure, reporting directly to Sundar Pichai, signals that this capability has become strategic at the CEO level. That is not how companies treat a supporting function.
VI · The Constraints
Real Risks That Could Break the Thesis
The case for Google’s strategy is not without friction. Four structural constraints bear watching:
Key Risk Factors
TSMC Allocation Priority — Nvidia remains TSMC’s largest customer. As foundry capacity for advanced nodes remains constrained by the global AI investment surge, Google risks being deprioritized in queue—regardless of order size or pricing.
HBM Supply Chain — Ironwood’s performance depends on HBM3e, currently in acute shortage globally. Both Samsung and SK Hynix are capacity-constrained, and Nvidia’s purchasing power gives it preferred vendor status. Google’s 1M-chip Anthropic commitment could face timing slippage.
Cloud Competitor Disinterest — AWS and Azure—among the largest GPU buyers globally—will not run competitors’ silicon at scale. Both have also developed proprietary chips (Trainium, Maia). Google’s addressable external market is structurally smaller than its ambition suggests.
CUDA’s Gravity Well — The developer ecosystem trained on CUDA represents years of inertia. JAX and XLA are excellent but require re-tooling. The transition cost is real, and most ML engineers default to GPU-first development environments.
The Middle East Crisis - escalating into a major impact war - affecting all forms of related trade and heightening business risks everywhere to slow development plans down.
None of these risks invalidate the strategy. They bound it. Google’s play works even at partial scale—if it captures frontier AI labs (Anthropic, potentially OpenAI, Meta) as anchor customers, the neocloud ecosystem has enough demand to sustain itself. It does not need AWS to buy TPUs. It needs enough external demand to justify continued investment in the silicon roadmap and to signal to the market that Nvidia is optional.

Constellation Research — Ironwood GA Analysis, 2025
VII · The Core Argument
This Is Infrastructure Colonialism—In Reverse
Nvidia’s power comes from having colonized the AI infrastructure layer before anyone else had a coherent alternative. Every data center built to its spec, every model trained on CUDA, every neocloud operator levered against GPU collateral—all of these are structural dependencies that compound over time. The longer they hold, the harder they become to displace.
Google’s strategy is not to win the benchmarks and hope customers migrate. It is to underwrite the migration itself—through equity stakes in neoclouds, financing for data center conversions, and anchor customer deals that de-risk the transition for organizations like Anthropic that need an alternative to GPU market concentration.
The WSJ frames this as Google “seeking to expand the market” for its chips. That is accurate but insufficient. Google is operating on two simultaneous fronts: compressing the margin on AI silicon via TPUs, and compressing the margin on AI inference via Gemini pricing—both funded by a cash flow base that no AI-native competitor can match. NVIDIA sets the price of compute. OpenAI and Anthropic set the price of intelligence. Google is trying to own both pricing mechanisms at once, and it is using $100B+ in annual free cash flow from businesses that predate the AI era to finance the campaign.
There is also a second motive that sits above the commercial logic entirely. DeepMind CEO Demis Hassabis has stated that Google’s primary goal is to solve intelligence first—and then use that intelligence to solve everything else. The “everything else” is drug discovery, new mathematics, physics, cryptography: problems where the payoff is not measured in subscription revenue but in Nobel Prizes and the creation of entirely new industries. Seen through that lens, the Ironwood program, the neocloud financing, the Anthropic deal—these are not just competitive moves. They are the infrastructure required to run experiments at a timescale and compute scale that no external vendor would sustain on Google’s behalf.
The commercial strategy and the scientific mission converge on the same requirement: sovereignty over the compute layer.
Whether the commercial strategy works will depend less on Ironwood’s benchmark scores—which are already competitive—and more on whether Google has the patience and financial endurance to sustain the subsidy until the ecosystem tips. With $93B in 2025 capex and $15.15B in quarterly cloud revenue growing at 34% YoY, the balance sheet can absorb the bet. The question is whether the strategy will hold its coherence across executive cycles and competitive counter-moves from Nvidia, which has every incentive to match Google’s financial commitments to neoclouds, dollar for dollar.
References
WSJ — “Google Is Exploring Ways to Use Its Financial Might to Take On Nvidia” — Raffaele Huang, Kate Clark, Berber Jin. Feb 20, 2026.
SemiAnalysis — “TPUv7: Google Takes a Swing at the 900lb Gorilla” — Nov 2025. Source for 44% TCO figure, Anthropic deal breakdown ($10B phase 1, $42B RPO phase 2), and performance benchmarks.
Google Cloud Blog — “Ironwood: The TPU for the Age of Inference” — Apr 2025. Ironwood specs, 42.5 EF Superpod performance, AlphaChip methodology.
Google Cloud Blog — “3 Things to Know About Ironwood” — Nov 2025. Integrated stack and AlphaChip co-design quote.
CNBC — “Google Unveils Ironwood, Seventh-Generation TPU” — Nov 2025. $93B capex figure and general availability announcement.
Constellation Research — “Google Cloud’s Ironwood Ready for General Availability” — 2025. Inference market competitiveness analysis.
YouTube Analysis — [Link to be added by author] — Demis Hassabis mission framing (3:42–3:49), model pricing differential (9:43–9:48), AlphaChip design cycle compression (7:40–7:46), scientific payoff thesis (22:50–23:04, 26:48–26:55). Naked reasoner vs. equipped reasoner distinction (11:24–11:29).
Alphabet Earnings — FY2024/25 Annual Report. Free cash flow base: $100B+ annually across Search, YouTube, and Google Cloud segments.
Nvidia Earnings — Q3 FY2026 (reported Nov 2025). Gross margin: ~74.6%. Source for “Nvidia Tax” framing.
The 44% TCO gap is huge. It also explains why inference pricing is so strange right now. If Google can strip Nvidia's margin from the BOM, that savings eventually filters into cheaper Gemini pricing. Meanwhile providers stuck on Nvidia hardware either eat the margin or pass the cost on. The Chinese providers chose a third path: subsidise aggressively, lock users in, raise prices later. Same playbook as the 2014 cloud wars but with state backing this time. Covered the full pattern and where it ends: https://sulat.com/p/the-real-cost-of-cheap-ai-inference