
Nvidia's Extreme Co-Design
The Future of Computing Is No Longer Modular—it’s holistic, vertically integrated, and Deeply Collaborative? And SLMs Are The Future!

“Extreme co-design” is a term used by Jensen Huang. What does he mean?
Jensen Huang uses the term “extreme co-design” to describe a radical shift in how NVIDIA—and the broader AI ecosystem—builds computing systems. It’s not just about designing chips anymore. It’s about simultaneously co-engineering every layer of the stack: hardware, software, algorithms, data pipelines, and even the physical infrastructure.
For example:
🔧 Full-stack optimization
Hardware-software synergy: GPUs, interconnects, compilers, and frameworks like CUDA and TensorRT are designed together to maximize performance.
Model-aware hardware: Chips are tailored to the specific needs of large AI models (e.g., transformer architectures), not generic workloads.
🏭 AI factories as systems
Huang sees AI data centers as “AI factories”—massive, integrated systems that generate tokens (outputs) from data.
Extreme co-design means optimizing everything from power delivery and cooling to training throughput and inference latency.
🤝 Deep collaboration
NVIDIA works closely with hyperscalers (like Microsoft, Meta, OpenAI) to co-design systems that meet their unique needs.
This includes custom silicon, software stacks, and deployment strategies—all built in tandem.
📈 Strategic leverage
Huang argues that performance per watt, per dollar, and per square meter are now strategic metrics.
Extreme co-design allows NVIDIA to dominate not just in chip specs, but in system-level economics.
In essence, Huang’s “extreme co-design” is a declaration that the future of computing is no longer modular—it’s holistic, vertically integrated, and deeply collaborative. It’s how NVIDIA plans to stay ahead in the trillion-dollar AI race.
Suggested watch list:
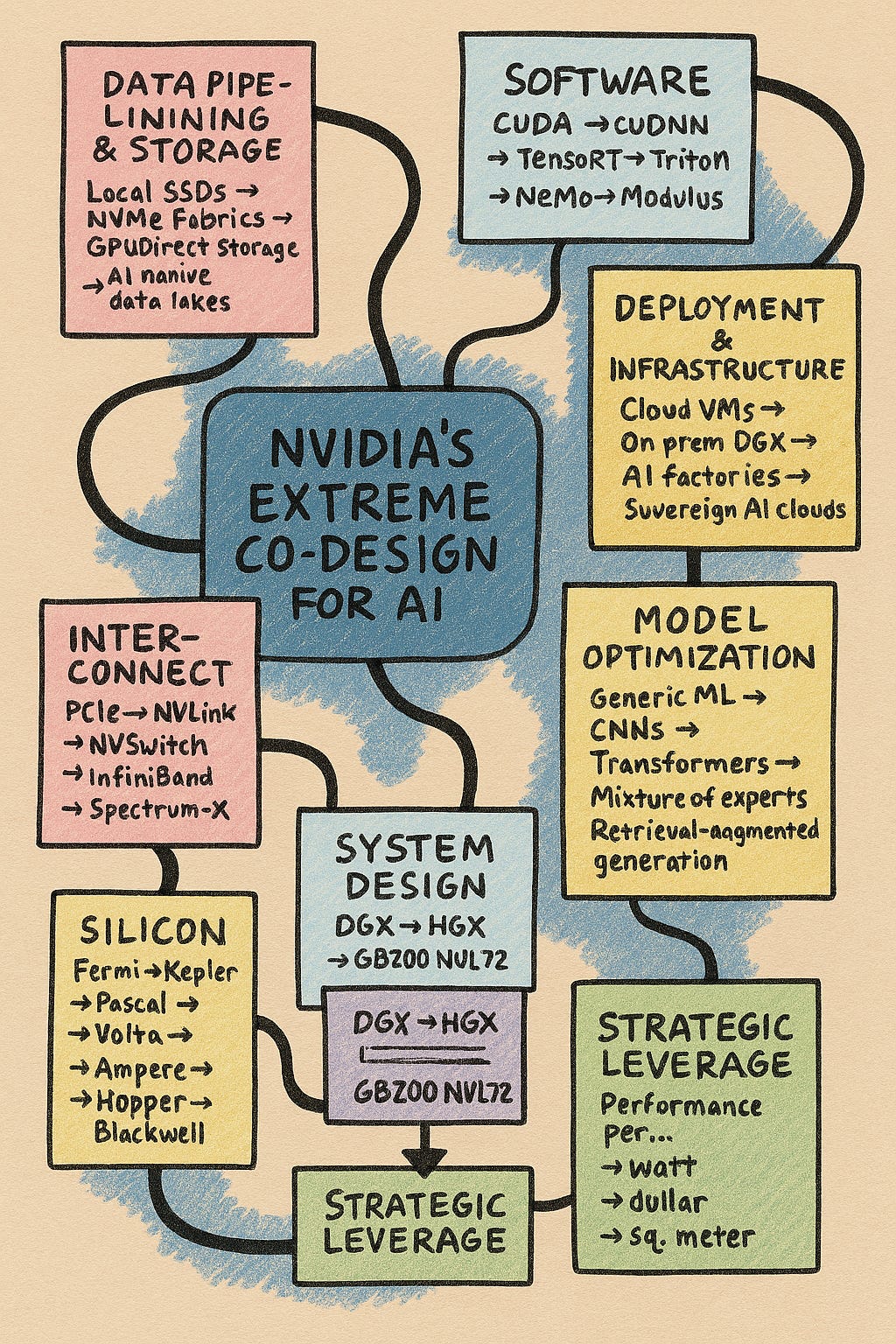
🧠 NVIDIA’s Extreme Co-Design Stack: Layered Breakdown
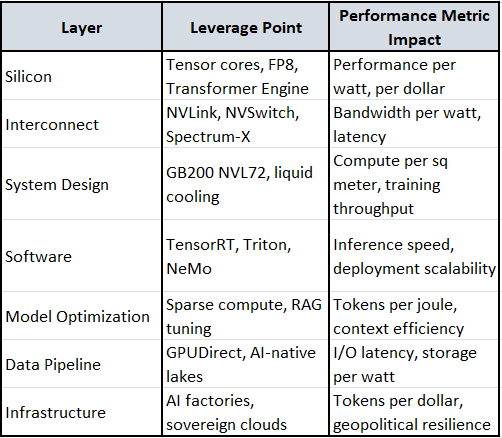
Each layer below is co-engineered with the others—no silos. The arrows show evolution, and the annotations explain why it matters.
1. Silicon Layer: GPU Architecture
Fermi → Kepler → Pascal → Volta → Ampere → Hopper → Blackwell
Shift: From general-purpose parallelism to AI-specialized tensor cores and FP8 precision. Even NVFP4 now.
Impact:
🚀 Performance per watt: Tensor cores deliver 10–100× speedups for matrix ops.
💰 Performance per dollar: Hopper’s Transformer Engine slashes training costs.
🧱 Performance per sq meter: Blackwell packs more compute into denser modules.
2. Interconnect & Memory
PCIe → NVLink → NVSwitch → InfiniBand → Spectrum-X
Shift: From CPU-centric data movement to GPU-GPU high-bandwidth fabrics.
Impact:
⚡ Latency: NVLink/NVSwitch reduce bottlenecks in multi-GPU training.
📶 Bandwidth per watt: InfiniBand + Spectrum-X optimize energy-efficient throughput.
🧠 Memory coherence: Enables unified memory pools across GPUs.
3. System Design: DGX → HGX → GB200 NVL72 → Rubin CPX
DGX-1 → DGX-2 → HGX A100 → HGX H100 → GB200 NVL72 -> RUBIN CPX
Shift: From workstation-scale to rack-scale AI supercomputers.
Impact:
🏭 Tokens per joule: GB200 NVL72 optimized for LLM inference at scale.
🧊 Thermal density: Liquid cooling and airflow redesigns boost compute per sq meter.
🧮 Training throughput: NVL72 delivers 30× faster GPT-4 training vs prior gen.
4. Software Stack
CUDA → cuDNN → TensorRT → Triton → NeMo → Modulus
Shift: From raw GPU programming to domain-specific AI frameworks.
Impact:
🧠 Model efficiency: TensorRT speeds up inference by 5–10×.
🔁 Reuse and modularity: Triton enables scalable deployment across models.
🧪 Scientific simulation: Modulus accelerates physics-informed neural nets.
5. Model-Aware Optimization
Generic ML → CNNs → Transformers → Mixture of Experts → Retrieval-Augmented Generation
Shift: Hardware and software tuned for specific model architectures.
Impact:
🧮 Tokens per watt: Transformer Engine in Hopper/Blackwell is optimized for attention ops.
🧠 Sparse compute: Mixture of Experts reduces active compute per token.
🔍 RAG efficiency: Co-design with memory and retrieval systems boosts context handling.
6. Data Pipeline & Storage
Local SSDs → NVMe fabrics → GPUDirect Storage → AI-native data lakes
Shift: From CPU-mediated I/O to direct GPU access to massive datasets.
Impact:
🚀 Throughput: GPUDirect cuts I/O latency by 10×.
📦 Storage per watt: Optimized data lakes reduce energy per training epoch.
🧠 Streaming efficiency: Enables real-time data ingestion for RLHF and fine-tuning.
7. Deployment & Infrastructure
Cloud VMs → On-prem DGX → AI Factories → Sovereign AI Clouds
Shift: From generic cloud compute to vertically integrated AI infrastructure.
Impact:
🏭 Tokens per dollar: AI factories deliver economies of scale.
🧱 Compute per sq meter: Custom racks and cooling maximize density.
🌍 Geopolitical resilience: Sovereign AI clouds enable national-scale autonomy.
🧭 Strategic Leverage Map
SLMs
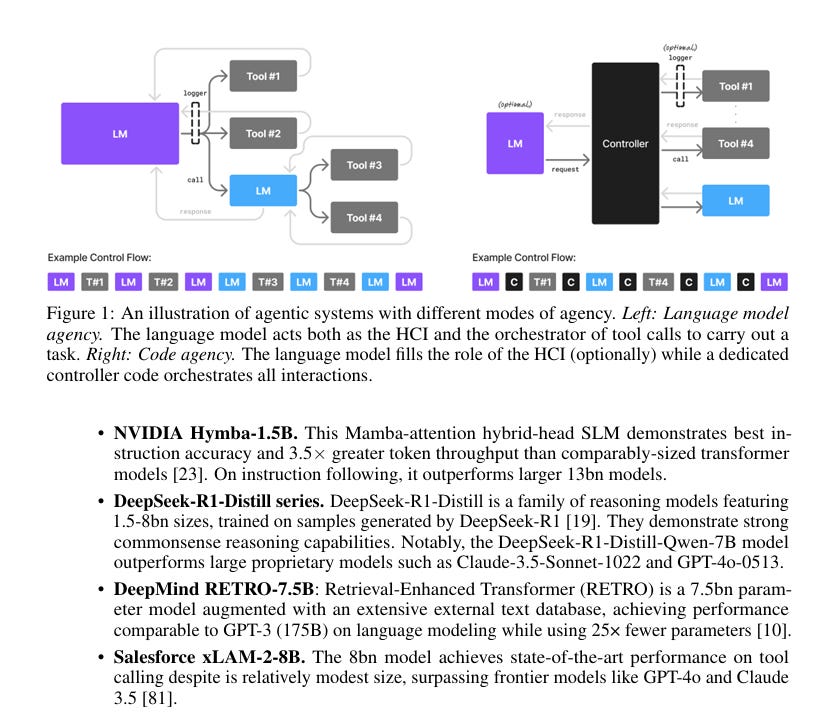
NVIDIA’s recent embrace of Small Language Models (SLMs) marks a strategic pivot—and it’s not just a technical choice, it’s a systems-level reframing of how AI agents should be built, deployed, and scaled.
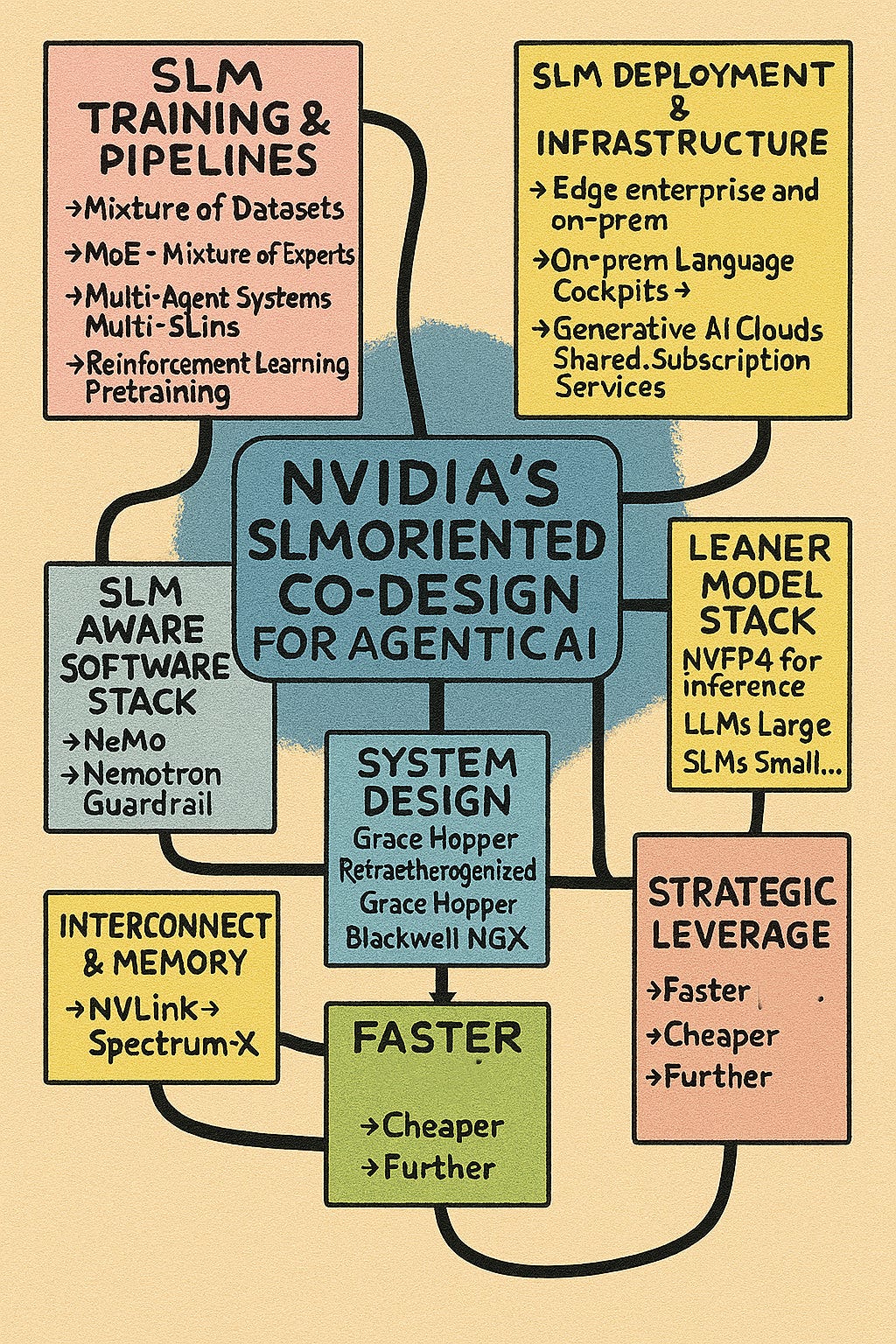
🧠 What NVIDIA Means by “SLMs Are the Future”
NVIDIA’s position paper, Small Language Models Are the Future of Agentic AI, outlines a clear thesis:
“Most agent tasks are narrow, repetitive, and structured. SLMs are sufficient, faster, cheaper, and more deployable than LLMs.”
They’re not abandoning LLMs—but they’re rearchitecting the AI stack around heterogeneous ecosystems where:
🔹 SLMs handle 70–90% of agent workloads (e.g., parsing commands, generating structured outputs, following instructions).
🔹 LLMs are reserved for strategic, multi-step reasoning or open-ended dialogue.
🧱 Strategic Context: Why This Matters
1. Performance per Watt / Dollar / Token
SLMs (1–8B parameters) require 10–30× less compute than LLMs.
They run faster, cheaper, and can be deployed on edge devices or local servers.
This aligns with NVIDIA’s extreme co-design ethos: optimize every layer for throughput and efficiency.
2. Agentic AI Workloads
Most enterprise agents don’t need GPT-4-level reasoning.
Tasks like GUI automation, data extraction, and tool orchestration are bounded and predictable.
SLMs excel at these with fewer hallucinations and tighter control.
3. Model-Stack Modularity
NVIDIA’s NeMo and Nemotron frameworks support SLM-first architectures.
You can fine-tune SLMs with ~100 examples to match LLM performance on narrow tasks.
This modularity enables plug-and-play agents with tailored behavior.
🧭 NVIDIA’s Leverage Strategy
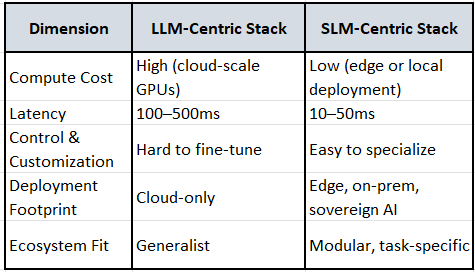
Recent Technical Upgrades
These aren’t just technical upgrades—they’re precision-level leverage points that reinforce NVIDIA’s entire co-design pyramid - NVFP4 and RLP.
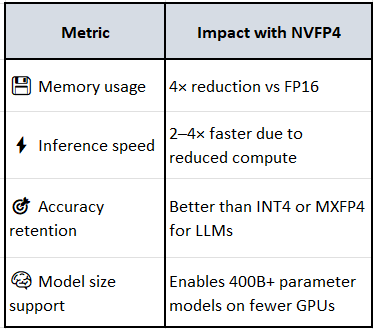
🔬 What is NVFP4?
NVFP4 is NVIDIA’s newest 4-bit floating point format, introduced with the Blackwell architecture. It’s designed for ultra-low precision inference with minimal accuracy loss, especially for large models.
🧠 Key Features:
4-bit format with shared FP8 scaling per 16-value block.
~25% memory footprint of FP16.
Accelerated hardware scaling on Blackwell Tensor Cores.
Lower accuracy degradation than other FP4 variants (e.g., MXFP4).
🔧 Strategic Impact:
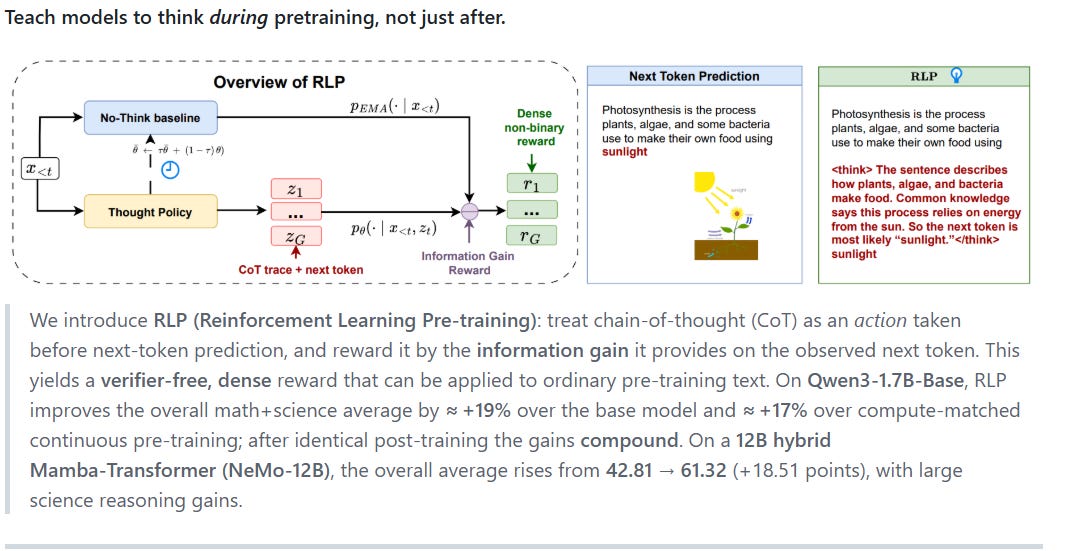
RLP—Reinforcement Learning Pre-Training—is one of NVIDIA’s most strategic breakthroughs in model training. It flips the conventional paradigm by embedding reasoning during pretraining, not just afterward.
🧠 What is RLP?
RLP treats chain-of-thought (CoT) as an action, and rewards it based on the information gain it provides for next-token prediction. Instead of just predicting the next word, the model is trained to think before predicting—and gets rewarded for useful intermediate reasoning.
🧩 “Verifier-free, dense reward that teaches models to think before predicting.” — NVIDIA Research source

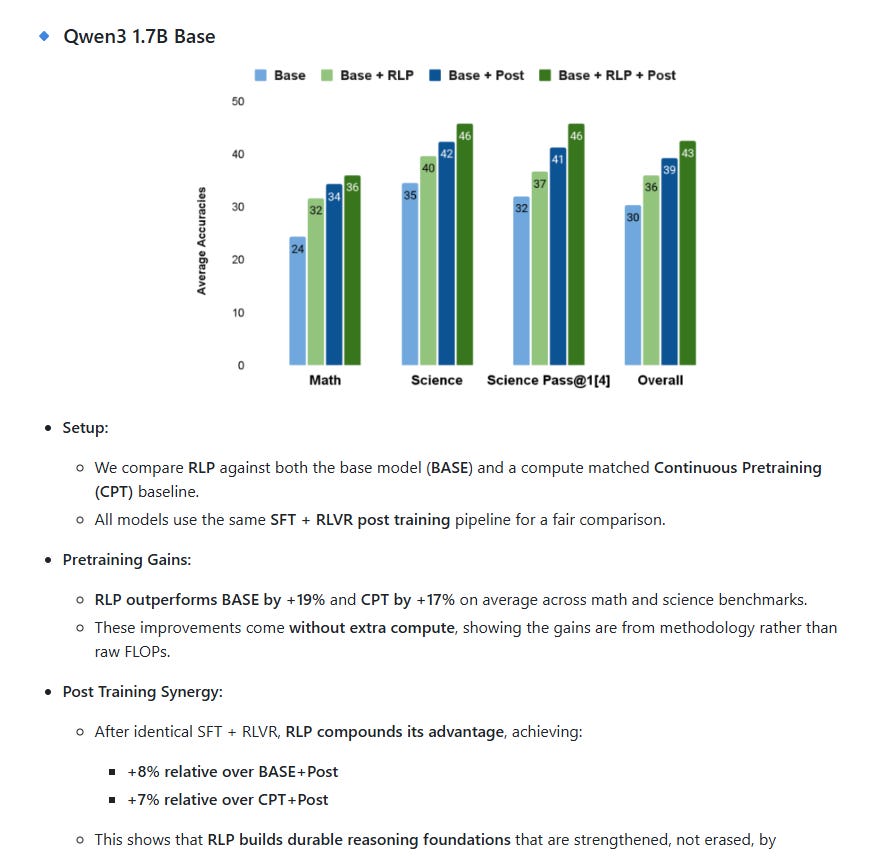
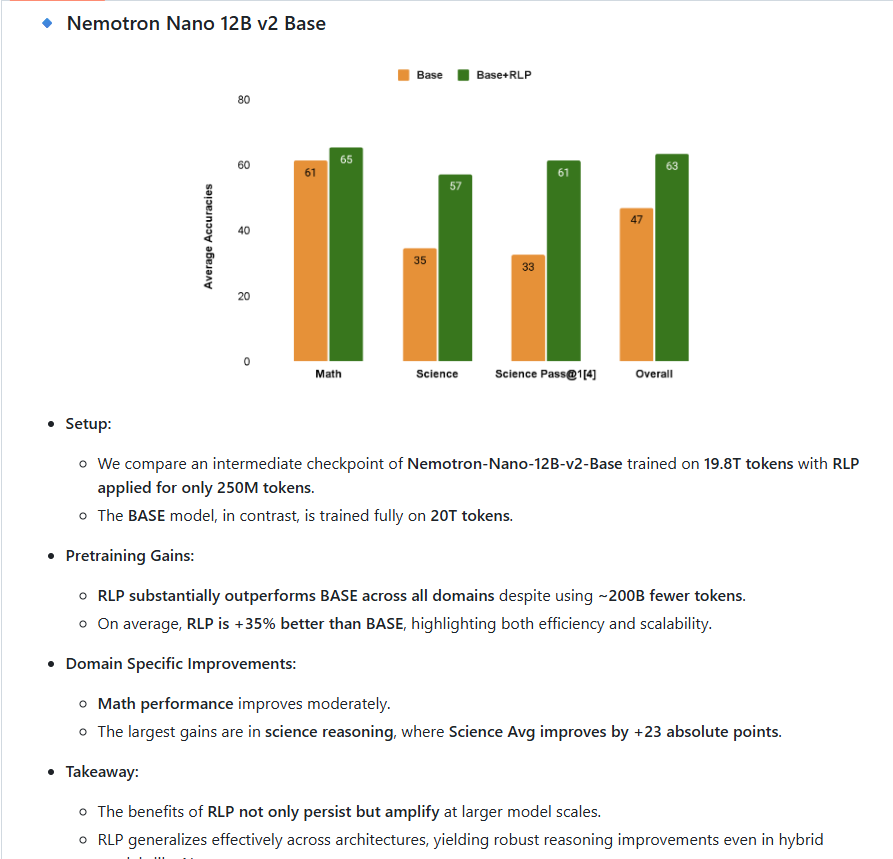
🔍 What NVIDIA Says About RLP’s Efficiency
From the official GitHub repository and technical blog:
“RLP improves performance over both the base model and a compute-matched continuous pretraining baseline. These improvements come without extra compute, showing the gains are from methodology rather than raw FLOPs.” — NVIDIA Research Team
🧠 Why It Works Without Extra Compute
RLP doesn’t add new modules or require external verifiers. Instead, it:
Treats chain-of-thought (CoT) as an action during pretraining.
Rewards CoT based on information gain for next-token prediction.
Uses dense, intrinsic rewards from the data itself—no extra supervision needed.
This means the model learns to “think before predicting” within the same training loop, making it compute-neutral but reasoning-enhanced.
🔍 How RLP Works
🧬 Training Objective:
CoT as action → model generates intermediate reasoning.
Reward = info gain → how much the CoT helps predict the next token.
No external verifier needed → reward is intrinsic to the data.
🧪 Results:
On Qwen3-1.7B: → +19% over base model → +17% over compute-matched continuous pretraining
On NeMo-12B hybrid: → Science reasoning score jumped from 42.81 → 61.32 (+18.5 pts)
🔹 Strategic Leverage

References for NVIDIA’s NVFP4 and Reinforcement Learning Pretraining (RLP) and SLMs:
🔢 NVFP4 (4-bit Floating Point Format)
Official NVIDIA Developer Blog
Introducing NVFP4 for Efficient and Accurate Low-Precision Inference
📎 developer.nvidia.com/blog/introducing-nvfp4-for-efficient-and-accurate-low-precision-inferenceResearch Paper on NVFP4 Pretraining
Pretraining Large Language Models with NVFP4 (ArXiv)
📎 arxiv.org/abs/2509.25149v1Macnica Technical Series
Getting Started with NVFP4 Inference on NVIDIA DGX™ B200
📎 macnica.co.jp/en/business/semiconductor/articles/nvidia/148013
🧠 Reinforcement Learning Pretraining (RLP)
NVIDIA Research GitHub Repository
RLP: Verifier-Free Reinforcement Learning Pretraining
📎 github.com/NVlabs/RLPNVIDIA Technical Overview
Teaching Models to Think Before Predicting
📎 developer.nvidia.com/blog/rlp-verifier-free-reinforcement-learning-pretraining
🧠 Nemotron Models
NVIDIA’s open family of reasoning-optimized foundation models, designed for agentic AI.
🔗 Official Overview
📎 Nemotron AI Models | NVIDIA Developer
Open weights, training data, and recipes
Strong performance in scientific reasoning, math, coding, OCR, and instruction following
Available in three tiers:
Nano: Edge and consumer GPU
Super: Single data center GPU
Ultra: Multi-agent enterprise deployments
🔗 Foundation Models for Agentic AI
📎 NVIDIA Nemotron | Foundation Models
Designed for enterprise-ready agents
Optimized for NeMo, TensorRT-LLM, and NIM microservices
Supports sovereign AI deployment and full-stack customization
🔗 Nemotron Nano 12B v2
📎 NVIDIA-Nemotron-Nano-12B-v2 | Hugging Face
Hybrid architecture: Mamba-2 + MLP + 6 Attention layers
Supports “reasoning budget” control during inference
Benchmarks:
AIME25: 76.25%
MATH500: 97.75%
GPQA: 64.48%
IFEVAL-Instruction: 89.81%
Trained using NeMo-RL and Megatron-LM
🧰 NeMo Framework
NVIDIA’s full-stack toolkit for building, training, and deploying LLMs and SLMs.
🔗 NeMo Developer Portal
Modular framework for pretraining, fine-tuning, and inference
Supports RLP (Reinforcement Learning Pretraining), SFT, and RLHF
Integrates with TensorRT-LLM, Triton, and Guardrails
🔗 NeMo GitHub
Source code, training recipes, and model configs
Includes support for speech, vision, and multimodal models
Actively updated with new agentic capabilities