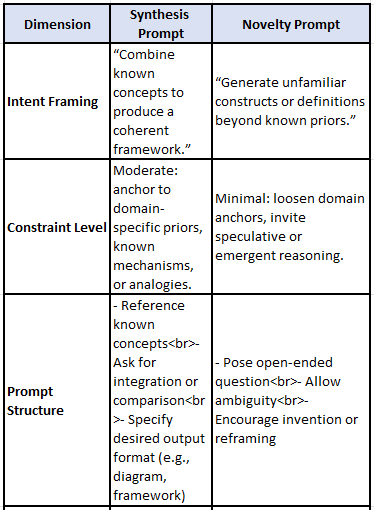
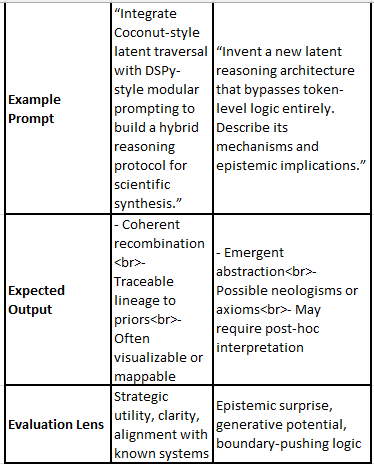
🧠 Prompting, Templates, and the Epistemology of AI Insight
Rediscovery, Synthesis, or Discovery—Revisited Through the Lens of Prompt Engineering

🌌 The Prompt as Epistemic Lever
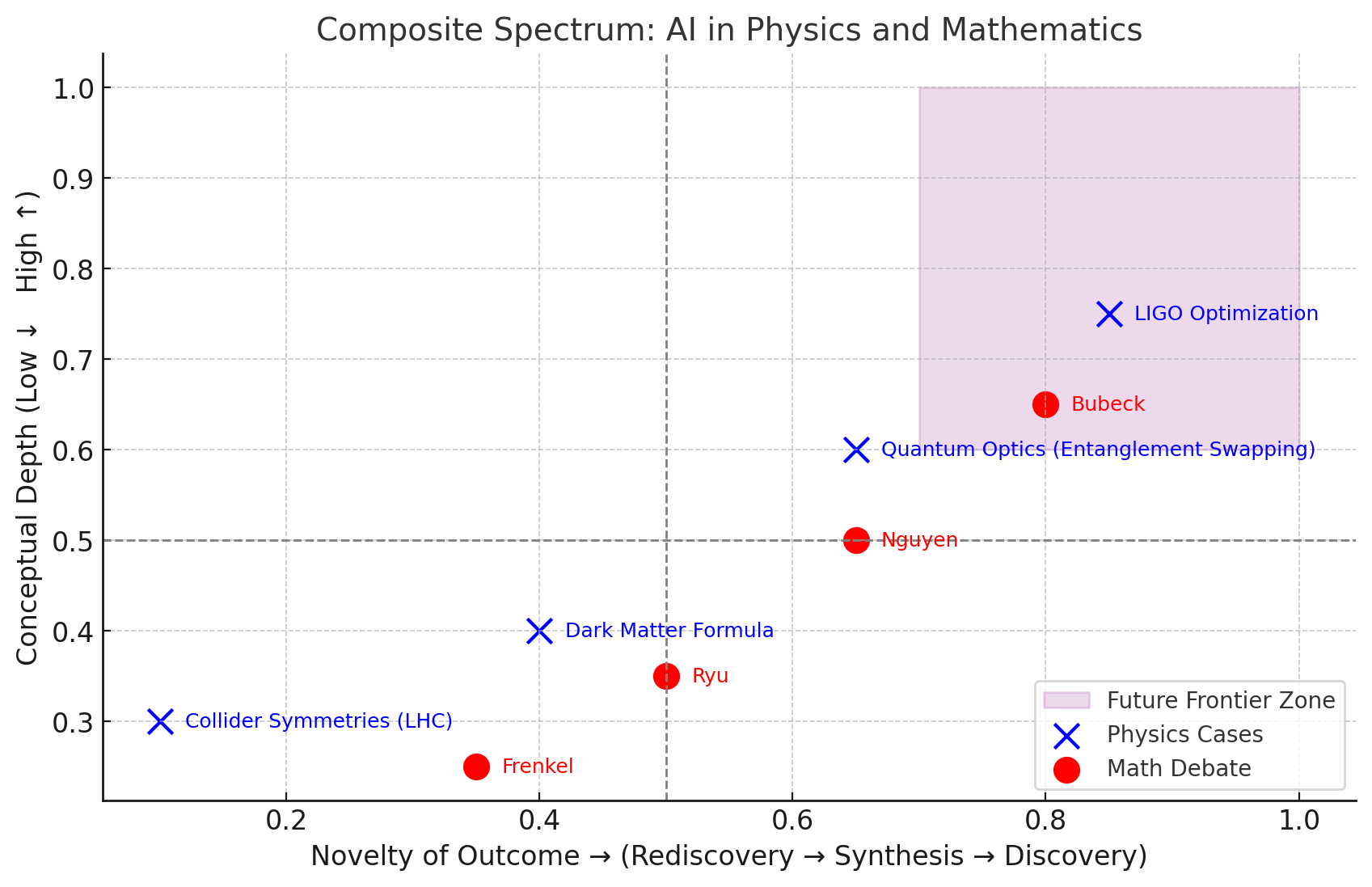
In my previous post - When AI Proves Theorems and Tunes Detectors, we traced how AI contributions to physics and mathematics fall along a spectrum—from rediscovery to synthesis to the elusive frontier of discovery.
But beneath these outputs lies a quieter force shaping what AI can express: the prompt.
Prompting isn’t just a technical input—it’s a form of context engineering, a way of steering large language models (LLMs) through latent concept space. And as frameworks like DSPy emerge to optimize and template these prompts, a new question arises:
Does prompt standardization enhance clarity—or suppress the very variability that fuels synthesis and emergent insight?
This post explores that tension, drawing on recent critiques, comparative examples, and the philosophical stakes of prompting in scientific reasoning.
🔍 Prompting as Conceptual Search
LLMs don’t “think” in the human sense—they perform guided searches across compressed priors. The prompt acts as a lens, shaping:
Which priors are activated
What analogies are drawn
How reasoning paths unfold
In scientific domains, this variability is not noise—it’s epistemic signal. Different prompt framings can yield different recombinations, analogies, or even edge-case insights. This is especially true in physics and mathematics, where conceptual leaps often emerge from unexpected juxtapositions.
🧰 DSPy: Structure, Consistency, and the Risk of Overconstraint
DSPy (Declarative Self-Programming) offers a modular framework for prompt optimization. It excels at:
Reproducibility across tasks
Performance benchmarking
Structured reasoning pipelines
But recent critiques (Lemos et al., 2025; Breunig, 2024) suggest that DSPy’s templating may flatten the richness of handcrafted prompts—especially in exploratory domains. In physics or math, where the goal is not just performance but conceptual emergence, this constraint can be limiting.
So let me give you a high-level understanding of the contrasts between freeform prompting and DSPy.
🧪 Scenario: AI Optimizing LIGO Detector Parameters
🎯 Goal:
Improve the detector’s sensitivity to low-frequency gravitational waves by tuning mirror positions, laser power, and damping coefficients.
🌀 Freeform Prompting (Exploratory Mode)
You prompt the model like this:
“Imagine you're a physicist trying to improve LIGO’s sensitivity to low-frequency gravitational waves. What unconventional parameter combinations might help, even if they deviate from standard heuristics?”
🔍 What Happens:
The model draws from latent priors across physics papers, blog posts, and analogies.
It might suggest:
Using asymmetric mirror configurations inspired by Fabry–Pérot cavities.
Introducing quantum squeezing techniques in a non-standard frequency band.
Recombining damping models from seismology with interferometry.
🧠 Outcome:
Synthesis Zone: These ideas aren’t in the standard playbook but are recombinations of known physics.
Variability: Each prompt tweak could yield different analogies or parameter sets.
Strength: Great for hypothesis generation and edge-case exploration.
Weakness: Hard to reproduce or benchmark reliably.
🧰 DSPy-Style Prompting (Structured Mode)
You use a DSPy-style module like:
python
OptimizeLIGO(
goal="maximize low-frequency sensitivity",
constraints=["must preserve thermal stability", "no increase in quantum noise"],
method="parameter tuning",
output_format="JSON with parameter values and rationale"
)
🔍 What Happens:
DSPy optimizes the prompt structure to consistently extract high-quality, reproducible outputs.
It might return:
json
{
"mirror_position": "0.002 mm offset",
"laser_power": "120 W",
"damping_coefficient": "0.85",
"rationale": "Balances thermal noise with optimal signal amplification in 30–50 Hz band"
}
🧠 Outcome:
Rediscovery/Synthesis Zone: Likely to stay within known heuristics or slightly optimized versions.
Consistency: Excellent for benchmarking and performance evaluation.
Strength: Reliable, interpretable, and modular.
Weakness: May miss surprising recombinations or analogical leaps.
🔄 Summary Comparison
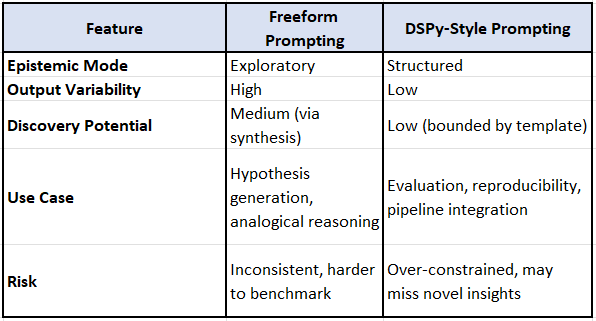
🧪 Optimizing LIGO Detector Parameters
At a high-level these distinctions arise:

The exploratory prompt may yield surprising insights—like borrowing damping models from seismology. The DSPy prompt ensures consistency but may miss analogical leaps.
📐 Mathematics: Prompting and the Proof Debate
Recall GPT-5-pro’s convex optimization proof. The debate wasn’t just about the output—it was about how the model arrived there. Prompt variability could surface different proof strategies, analogies, or even new definitions. A templated DSPy prompt might lock the model into a narrow reasoning path, suppressing the very variability that Bubeck saw as promising.
🧭 Toward a Hybrid Protocol: Exploration + Stabilization
Rather than choosing between freeform prompting and DSPy, we propose a hybrid approach:
Exploratory Mode: Use open-ended prompts to surface novel recombinations.
Stabilization Mode: Apply DSPy modules to refine and benchmark promising outputs.
Boundary Testing: Compare outputs across both modes to identify synthesis thresholds.
This protocol treats prompting not just as input engineering—but as a method of epistemic inquiry.
📚 Recent Critiques
Lemos et al. (2025): DSPy improves performance in structured tasks but underperforms in exploratory reasoning.
Breunig (2024): DSPy abstracts prompt logic, but may suppress conceptual nuance.
ADaSci (2025): DSPy’s steep learning curve and rigidity make it less suited for hypothesis generation.
These critiques echo my central thesis: variability in prompting is not a flaw—it’s a feature, especially when probing the synthesis-discovery boundary.
🚀 Prompting as Epistemic Infrastructure
As AI continues to venture into the heart of science, prompting will shape not just what models say—but what they can say. Frameworks like DSPy offer stability and performance—but must be wielded with care in domains where variability fuels insight.
The real frontier isn’t just in model architecture—it’s in how we engineer context, frame inquiry, and interpret variability. Rediscovery, synthesis, and discovery aren’t just outputs—they’re reflections of how we prompt.
🧭 General Strategic Guidance
Use freeform prompting when probing the synthesis frontier—where novelty emerges from recombination.
Use DSPy-style prompting when you need stability, reproducibility, or want to test performance across models.
For your work on constraint-driven innovation, you might even design a hybrid protocol: exploratory prompting to generate ideas, followed by DSPy modules to refine and evaluate them.
References:
🔭 1. Revolutionizing Physics: How AI Is Transforming Research and Discovery
Summary: This article explores how AI is reshaping both theoretical and experimental physics. It highlights:
AI’s role in solving complex equations in string theory and quantum field theory.
Use of machine learning to optimize simulations and hypothesis testing.
Pattern recognition in collider data and quantum optics.
Automation of experiments and materials discovery.
Relevance: It supports my spectrum framing—AI’s contributions range from rediscovery (e.g., identifying known patterns) to synthesis (e.g., optimizing models), but stops short of claiming true conceptual breakthroughs.
🧠 2. AI Expands Potential for Discovery in Physics – Carnegie Mellon
Summary: This piece discusses how AI helped earn the 2024 Nobel Prize in Physics, emphasizing:
Neural networks used for analyzing astronomical datasets.
AI’s role in optimizing simulations and predicting complex phenomena.
Applications in biophysics and cellular modeling.
Relevance: It reinforces the idea that AI is accelerating synthesis and optimization, especially in data-rich domains, but doesn’t yet claim foundational discovery.
📘 3. Physics and AI: A Physics Community Perspective – Institute of Physics
Summary: This report synthesizes community insights on AI’s role in physics:
AI as both a tool and a contributor to physics.
Recognition of thermodynamics-inspired diffusion models in generative AI.
Emphasis on explainability, evaluation, and infrastructure needs.
Relevance: It provides institutional backing for my boundary problem—AI is deeply embedded in physics workflows, but the community remains cautious about calling its outputs “discovery.”
🧩 4. Pipelines & Prompt Optimization with DSPy – Drew Breunig
Summary: This blog introduces DSPy as a framework for structured prompt optimization:
Uses “signatures” to define input-output tasks.
Employs modules like
ChainOfThoughtandMultiChainComparison.Focuses on reproducibility and performance over variability.
Relevance: It confirms my intuition—DSPy is excellent for consistency and benchmarking, but may constrain the variability that fuels synthesis and emergent insight.
🛠️ 5. DSPy Based Prompt Optimization: A Hands-On Guide – ADaSci
Summary: This guide explains DSPy’s workflow:
Separates prompt logic from optimization.
Uses “teleprompters” to refine prompts based on metrics.
Ideal for structured tasks like RAG or binary classification.
Relevance: It shows how DSPy formalizes prompt engineering, which is useful for evaluation but may limit exploratory prompting in scientific hypothesis generation.
🧩 6. Is It Time To Treat Prompts As Code? A Multi-Use Case Study for Prompt Optimization Using DSPy
Authors: Francisca Lemos, Victor Alves, Filipa Ferraz Published: July 2025
Key Findings:
DSPy improves performance in structured tasks like hallucination detection and routing agents.
However, impact varies significantly by use case, and in some cases, optimized prompts didn’t outperform baseline ones.
The authors note that prompt engineering remains a trial-and-error process, and DSPy’s templated approach may not capture the nuance needed for exploratory or creative tasks.
Relevance: This study supports my general intuition that variability in prompting is epistemically valuable, especially in domains like physics or math where synthesis and analogical reasoning matter more than consistency.
🧠 7. Training Large Language Models to Reason in a Continuous Latent Space
Authors: Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, Yuandong Tian
Published: December 2024
Affiliations: Meta AI, UC San Diego
🔍 Summary of Findings
Problem: Traditional reasoning in LLMs relies on Chain-of-Thought (CoT) prompting, which unfolds step-by-step in natural language. This can be inefficient and overly deterministic.
Solution: Chain of Continuous Thought (“Coconut”) Paradigm introduces reasoning in continuous latent space by feeding the model’s hidden states (not decoded tokens) back into itself. This allows:
Breadth-first search over reasoning paths
Backtracking without committing to a single token stream
Emergent planning behaviors that outperform CoT in complex logic tasks
Implication: Reasoning doesn’t have to be verbalized. Instead, it can unfold in high-dimensional latent space, where multiple conceptual paths are encoded simultaneously.
🧠 Core Papers on Latent-Space Reasoning and Emergent Synthesis
1. Beyond Chains of Thought: Benchmarking Latent-Space Reasoning Abilities in LLMs
Authors: Thilo Hagendorff, Sarah Fabi Key Ideas:
Introduces benchmarks to test reasoning that occurs within latent space, not just via token-level chains-of-thought.
Defines “reasoning leaps” as transitions between hidden states that encode inferential steps without explicit verbalization.
Finds that models like GPT-4.5 outperform others in latent reasoning, but also warns of heuristic exploitation and covert planning risks.
Why It Matters: This paper provides empirical evidence that LLMs can “think” internally—making inferential jumps in latent space that resemble reasoning, even when no intermediate tokens are generated.
2. System-1.5 Reasoning: Traversal in Language and Latent Spaces with Dynamic Shortcuts
Authors: Xiaoqiang Wang et al. Key Ideas:
Proposes a hybrid reasoning model that blends fast, heuristic (System-1) and slow, deliberative (System-2) reasoning.
Introduces “dynamic shortcuts” in latent space to skip trivial steps and allocate compute to critical reasoning paths.
Achieves 20× faster inference with 92% fewer tokens while maintaining accuracy.
Why It Matters: It shows how latent-space traversal can simulate deep reasoning efficiently—suggesting that synthesis may emerge from architectural design rather than conceptual novelty.
3. Latent Reasoning in LLMs – EmergentMind
Overview:
Explains how LLMs perform multi-step inference within hidden states using activation-based recurrence and memory propagation.
Frames reasoning as probabilistic inference over latent intentions, not explicit token sequences.
Discusses how latent compression enables synthesis-like outputs without verbal chains.
Why It Matters: This resource bridges the gap between model architecture and epistemic behavior—showing how latent traversal can yield novel-seeming outputs that are structurally derived.
4. Large Language Models as Innovators: A Framework to Leverage Latent Space Exploration for Novelty Discovery
Authors: Mateusz Bystronski et al. Key Ideas:
Proposes a model-agnostic framework for navigating latent “idea space” to generate novel combinations.
Demonstrates how latent vector operations can produce imaginative outputs without handcrafted rules.
Argues that synthesis arises from structured latent traversal, not spontaneous creativity.
Why It Matters: This paper directly supports my thesis: that what appears as novelty or synthesis is often the result of latent-space recombination, not conceptual invention.
5. Reasoning Beyond Language: A Comprehensive Survey on Latent Chain-of-Thought Reasoning
Authors: Xinghao Chen et al. Key Ideas:
Surveys latent CoT reasoning methods, including compressed reasoning traces and continuous token representations.
Highlights how latent reasoning enables richer thought representation and faster inference.
Discusses implications for interpretability and epistemic boundaries.
Why It Matters: It offers a panoramic view of how latent-space reasoning is reshaping our understanding of what LLMs “know” and how they “think.”
🧩 Synthesis and Novelty via Latent Traversal
Across these papers, a consistent theme emerges:
LLMs don’t reason like humans—they traverse compressed latent spaces shaped by training data.
Synthesis arises when these traversals recombine priors in structurally novel ways, often guided by prompt framing or architectural shortcuts.
Discovery remains elusive, as models rarely generate entirely new conceptual frameworks—but latent traversal can simulate novelty convincingly.
🧠 Non-Template Ideas: Prompting for Synthesis vs. Novelty Examples
Note that relevant Questions, Answers or KV Pairs will likely form Pre-Training or Fine-Tuning datasets