
Scaling Smart: How Meituan's LongCat-Flash Rewrites the MoE Playbook
Longcat-Flash’s intelligent compute allocation (ZCE), architectural fusion (ScMoE), and many-system-level efficiencies


I am in awe!! Hats off, and very well done to the Meituan team!! Wow!!
They literally threw the entire (un)imaginable, “optimization-at-every-level-book” at this Model:
TLDR:
1) New Architecture
Two attention blocks per layer + FFN + MoE
→ This is captured under Novel Architecture Designs (MLA + dual FFN/MoE per block, only 28 layers total).Zero-computation expert (sink for easy tokens)
→ Covered in Zero-Computation Experts section.Load balancing with dsv3-like aux loss + decay schedule
→ This is included under Computational Budget Control (PID bias adjustment, loss-free load balancing) and Load Balance Control.
2) Scaling
Variance alignment for MLA/MoE init
→ See below under Variance Alignment Design for Scalability.Model Growth Initialization (stacking smaller model)
→ Included under Model Growth Initialization.Hyperparameter transfer with SP instead of muP
→ Covered this under Hyperparameter Transfer, referencing the theory behind parameter scaling rules.
3) Stability
Gradient Norm Ratio & expert cosine similarity for load balancing
→ Included below under router-gradient balancing and monitoring metrics as part of your Training Stability Suite.Hidden-state z-loss (to avoid large activations)
→ Explicitly in Training Stability Suite.Adam epsilon set to 1e-16, tuned relative to RMS range
→ Captured this point in the stability discussion.
4) Others
Data pipeline: context extraction, quality filtering, deduplication
→ Covered under systematic data pipelines in pre/mid/post-training breakdown.Long-context training: 20T tokens pretraining, multi-T mid-training, 100B long-context extension
→ Covered under Long Context Extension with explicit 128K tokens.Benchmark comparisons (MMLU, GSM8K, top-k expert allocations)
→ Present in Competitive and Optimized Performance section.Two new benchmarks (Meeseeks, VitaBench)
→ Explicitly included in Chat Model Performance list.Infra/inference details: speculative decoding acceptance, quantization, deployment, kernel optimization, overlap
→ These are under Inference/Deployment Optimizations (MTP speculative decoding, custom kernels, quantization, SBO scheduling).
⚡ LongCat-Flash – Optimized at Every Level
Massive yet Efficient
560B total parameters.
Only 18.6B–31.3B (avg. ~27B) dynamically activated per token → compute efficiency without sacrificing capability.
Dynamic Computation Mechanism
Context-aware activation of experts.
Allocates more compute to “hard” tokens, less to “easy” ones.
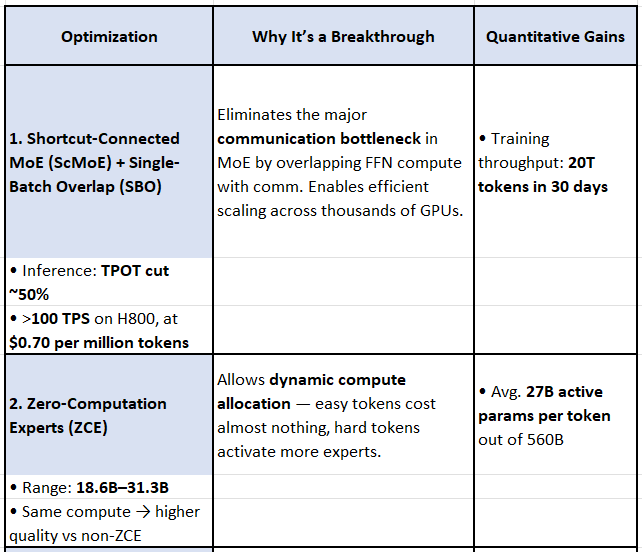
Shortcut-Connected MoE (ScMoE)
Expands computation–communication overlap window.
Removes major bottleneck of large MoE models.
Delivers over 100 tokens/sec inference speed at low cost.
Comprehensive Training & Scaling Strategy
Stable and reproducible training across tens of thousands of accelerators.
Specialized initialization, variance alignment, and stability controls → no collapse at scale.
Tailored Data Strategies
Reasoning-intensive, multilingual, and code-rich datasets.
Extended to long context (128k tokens).
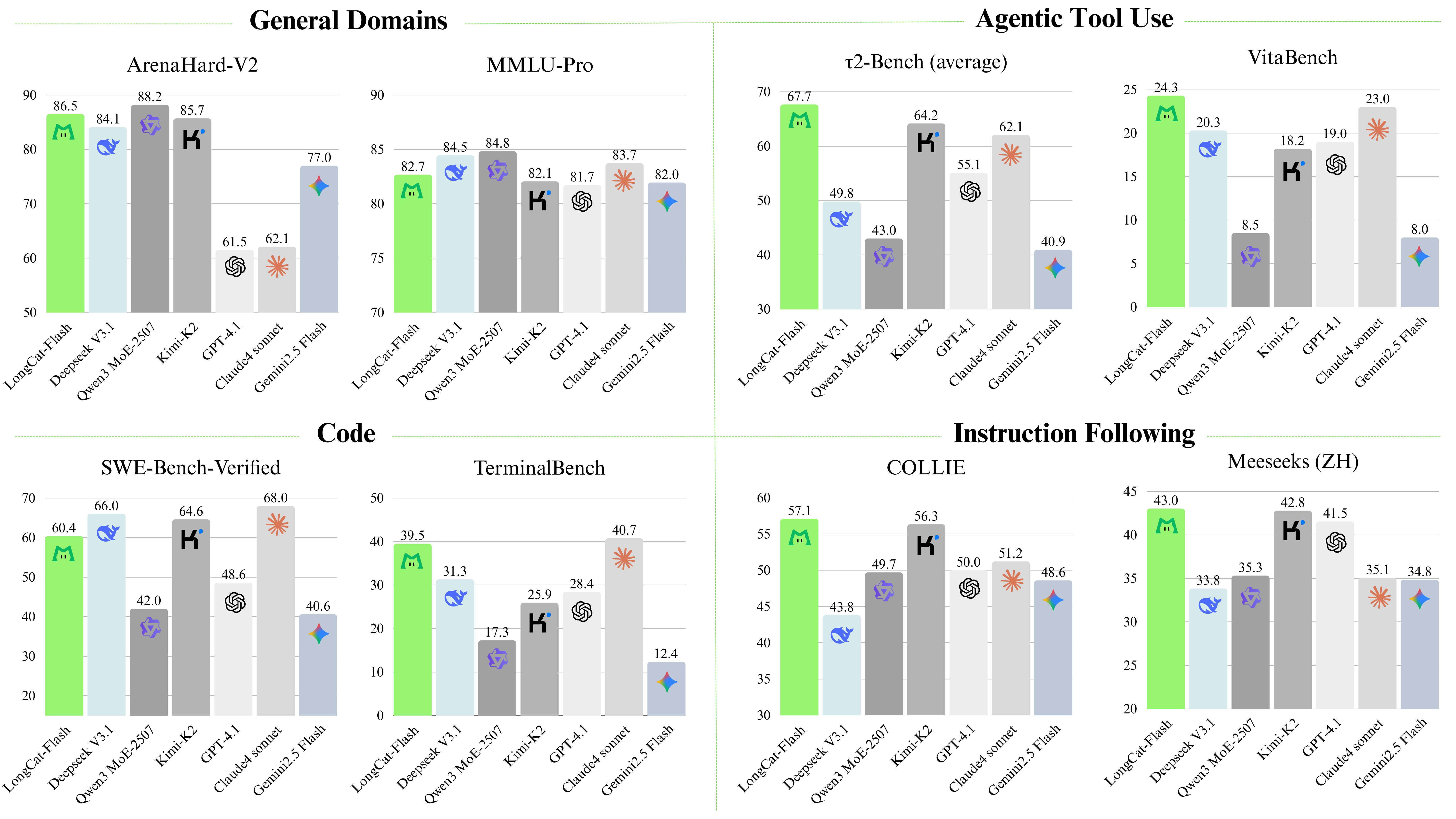
Competitive Performance
Released as LongCat-Flash-Chat, a strong non-thinking foundation model.
State-of-the-art results in agentic tasks (reasoning, tool use, coding).
The technical report is one of the most detailed (amongst OSS) I have seen to date. It will, however, be amiss not to acknowledge all prior releases and technical reports for the various models (and “borrowed & stacked optimizations” and learning lessons from these stars) - DeepSeek’s V3, R1, V3.1, Qwen3 series, Zhipu’s GLM4.5, Moonshot’s Kimi-K2 etc. Thank you for contributing so very much towards OSS!
Standing on the Shoulders of Giants
Acknowledging the OSS contributions, especially from Chinese AI model developers—like those behind LongCat-Flash—have indeed built upon and integrated techniques from recent open-source and in-house models (e.g., DeepSeek V3/R1/V3.1, Kimi-K2, GLM-4.5, Tülu). However there are many innovations including Longcat’s architecture that makes them another one to watch, amongst the long-list OSS models (china based). Here’s how they’ve thrown the “optimizations-book at every level, also borrowing and integrating on proven innovations:
The Few Key Building Blocks and Their Lineage
1. Mixture-of-Experts with Sparse Activation
DeepSeek-V3 introduced MoE with dense parameters but only a subset activated per token (37B active of 671B total) arXiv.
Kimi-K2 uses MoE with 32B active of 1T total, optimized with a new MuonClip optimizer and zero loss spikes during post-training arXiv.
GLM-4.5 and GLM-4.5-Air also follow the hybrid active-parameter pattern (32B active of 355B total, and 12B of 106B respectively) Analytics VidhyaHugging Face.
LongCat-Flash similarly uses MoE plus zero-computation experts to dynamically manage activated parameters (~27B on average).
2. Multi-Token Prediction (Speculative Decoding)
DeepSeek-V3 pioneered multi-token prediction objectives in MoE models, boosting inference efficiency arXiv.
LongCat-Flash uses a similar MTP design for speculative decoding with ~90% acceptance rates.
3. Large Context Windows
DeepSeek-V3.1 provides massive 128K token context support with a hybrid thinking/non-thinking mode deepseek.ai(Hugging Face).
GLM-4.5 family also supports contextual switching and reasoning features on large contexts Analytics Vidhya(DeepLearning.ai).
Tülu-3 achieved competitive performance across benchmarks with large-scale fine-tuning and inference optimizations allenai.org(Unite.AI).
LongCat-Flash matches them with MLA for efficient 128K contexts with compressed KV cache.
4. Inference Efficiency and Mode Switching
DeepSeek-V3.1 implements a hybrid Think/Non-Think inference mode that improves tool use and agentic behavior Hugging Face(Reuters).
GLM-4.5 offers dual reasoning modes for flexible task handling Analytics Vidhya(The Economic Times).
Kimi-K2 Instruct provides post-trained, agent-optimized behavior out-of-the-box (Medium).
LongCat-Flash incorporates ScMoE + SBO to support efficient inference concurrently with dynamic routing capability.
5. Training Stability, Data Strategies
Kimi-K2 used MuonClip optimizer with novel QK clipping and large-scale multi-stage training to avoid loss crashes arXiv.
Tülu-3 employs open-source recipes, data pipelines, and vLLM inference tricks for stability allenai.orgai(wire.net).
LongCat-Flash packages these into deterministic kernels, router balancing, hidden-z loss, half-scale initialization, and systematic data pipelines.
Shared Foundations, Local Refinements
Ok, I admit, I now sound almost like one of those banking ads. Hah! Anyway - seriously, though - Chinese models are engaging in a cycle of cumulative innovation—taking baseline advances from open sources and each other, then differentiating via:
ZCE routing and MoE enhancements
Efficient attention for long contexts
Speculative decoding with MTP
Hybrid inference modes
Stability at extreme scales
Dense / sparse training strategies
LongCat-Flash is built atop these shoulders—but injects fresh ideas (e.g., shortcut-connected MoE, aggressive infrastructure optimizations, deterministic kernels), making it a standout in computational and agentic efficiency.
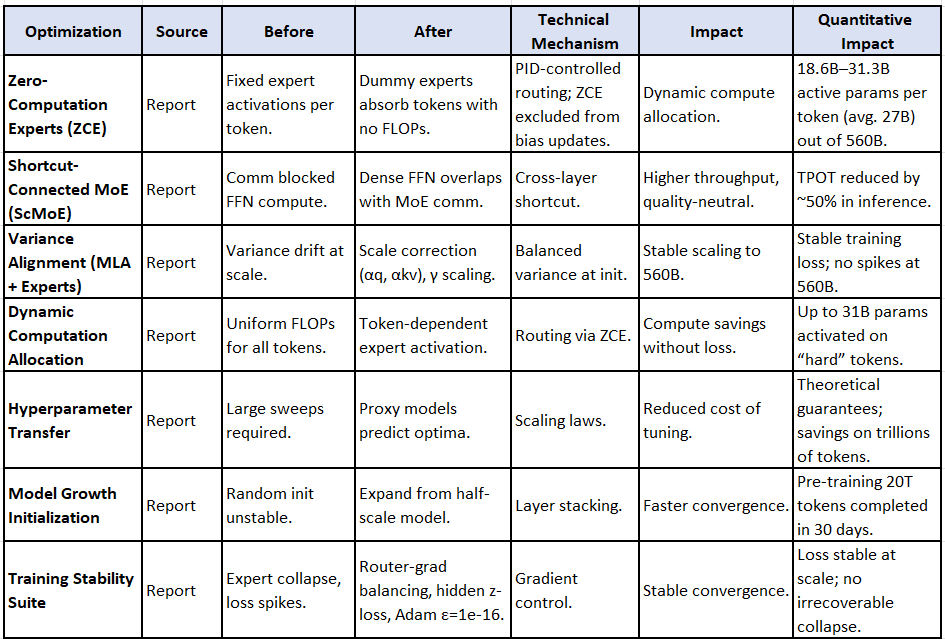
To truly appreciate what went into this, here is a non-exhaustive list of the optimizations I am highlighting. My guide (for personal knowledge) type thing. The before and after basically highlight general/classical mechanisms present in many of the older models, and the after - the tweaks facilitated by Meituan. Appreciating the impact is sufficient for those who may not need those details to understand the level of “ elegant fine-tuning” undertaken by the team - hats off, once again:
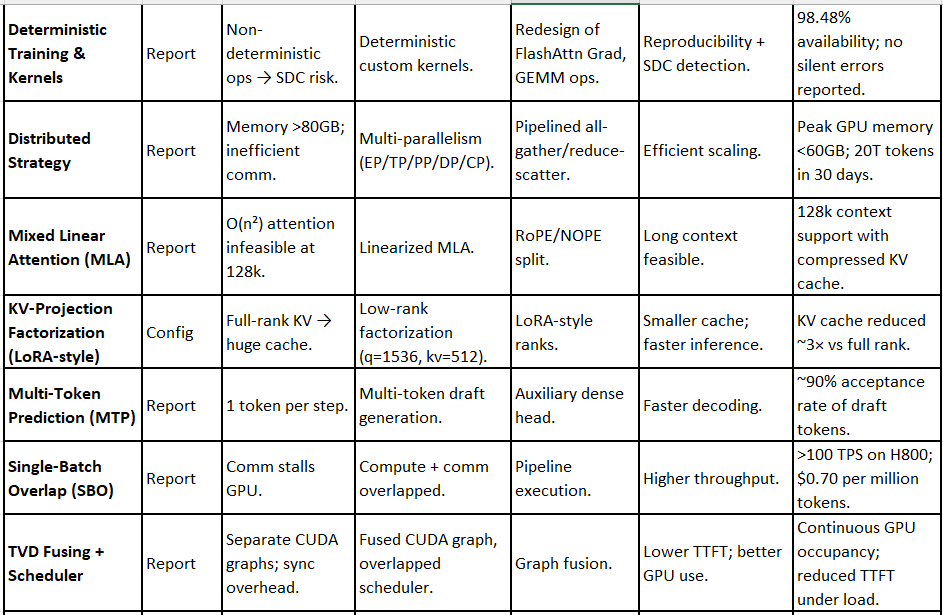
🔧 LongCat-Flash Optimizations — Comprehensive Before vs After Analysis
A. Architecture-Level Innovations
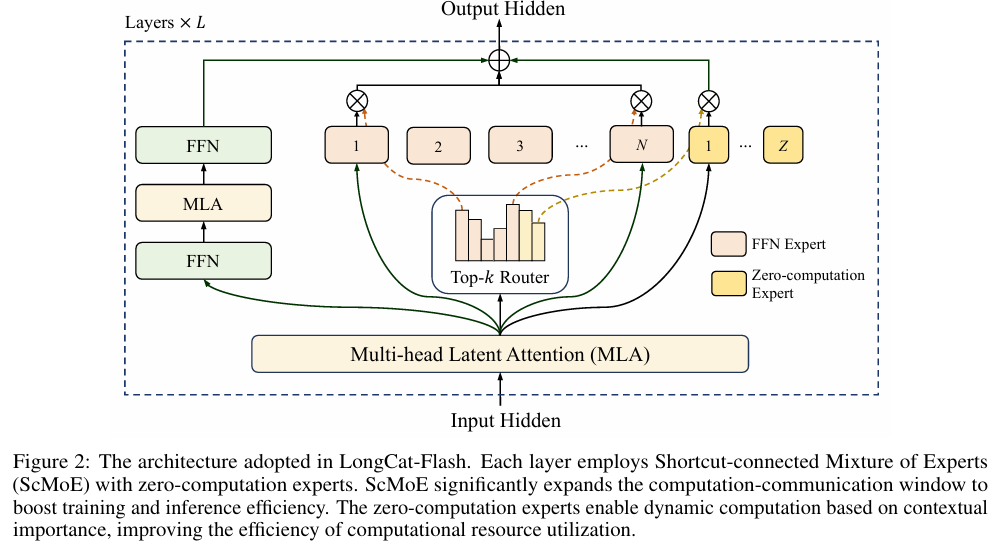
1. Zero-Computation Experts (ZCE)
Before:
Classic MoE models require routing every token to k FFN experts.
All experts perform heavy matrix multiplications regardless of whether the token is “simple” or “difficult.”
Leads to wasted FLOPs on trivial tokens (e.g., punctuation, common words) and occasional overloading on tokens requiring deeper reasoning.
After:
LongCat-Flash introduces ZCEs — experts that return the input unchanged (no FLOPs).
Router can assign a fraction of tokens to these ZCEs, effectively reducing active computation per token.
A PID controller dynamically adjusts routing scores so the number of active parameters stays near the target budget (~27B vs. 560B total).
Impact:
Reduces unnecessary computation without sacrificing representational power.
Allows flexible compute allocation: hard tokens get more FFN experts, easy tokens get fewer.
Results: During pre-training, mean active experts converged to 8 (~27B params), variance across tokens stayed high → efficient dynamic adaptation.
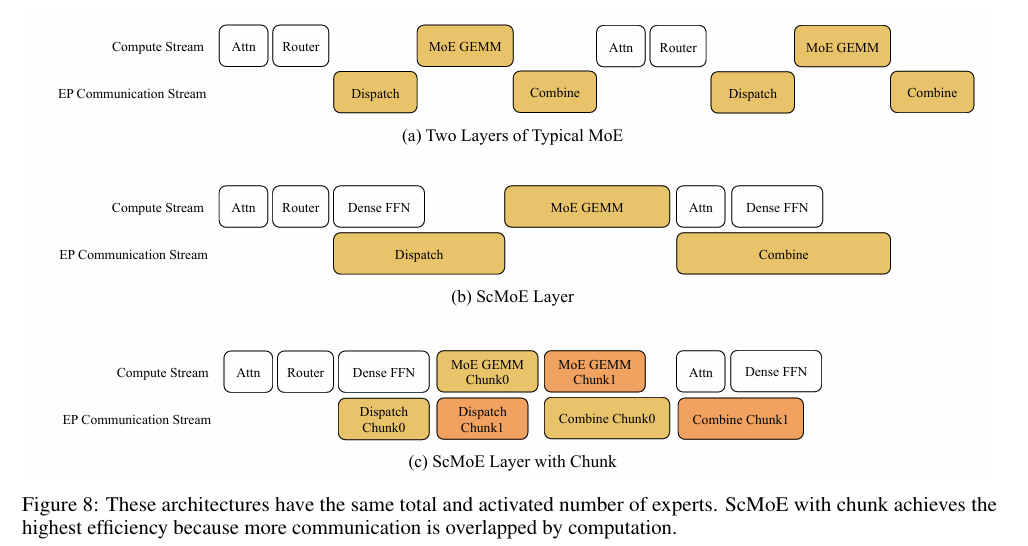
2. Shortcut-Connected MoE (ScMoE)
Before:
MoE layers require token dispatch (all-to-all comms) before FFN compute.
Communication time often exceeded compute, leaving accelerators idle.
After:
ScMoE adds cross-layer shortcut: the dense FFN of the previous layer is executed in parallel with MoE dispatch/combination.
This enlarges the overlap window between computation and communication.
Impact:
Training throughput: removes major communication bottleneck at large scale.
Inference: enables Single Batch Overlap (SBO) scheduling, hiding comms overhead inside compute pipeline.
Reported result: nearly 50% reduction in theoretical time-per-token in inference; training loss curves identical to baseline (quality-neutral).
3. Variance Alignment Designs
Before:
Low-rank MLA attention and fine-grained expert partitioning reduced variance in outputs.
Misaligned variances caused unstable activations and degraded convergence when scaling up.
After:
Scale correction factors (αq, αkv) applied to Q/K/V projections in MLA.
Scaling factor (γ) applied to outputs of fine-grained experts to restore variance lost from gating dilution.
Impact:
Stabilized initialization → smoother convergence.
Prevents scale-up degradation seen in earlier MoE models.
Quality at 560B matches or exceeds extrapolations from smaller-scale training.
B. Training Optimizations
4. Dynamic Computation Allocation
Before:
Fixed expert count → static FLOP budget per token.
Inefficient when token complexity varied widely.
After:
ZCE routing allowed per-token variation: 18.6B–31.3B params active (avg. 27B).
Impact:
Computational efficiency improved (same quality with fewer FLOPs).
Model achieves performance parity with larger activated-param peers (e.g., DeepSeek-V3 Base 37B active).
5. Hyperparameter Transfer
Before:
Hyperparameter tuning at scale required expensive sweeps, often unstable.
After:
Used scaling rules: predicted optimal lr, batch size, optimizer settings from smaller proxy models.
Impact:
Reduced compute wasted on tuning.
Allowed reliable jump to trillion-token training without instability.
6. Model Growth Initialization
Before:
Random init at 560B scale produced gradient explosion/collapse.
After:
Pre-trained half-scale checkpoint grown to full size using layer-stacking.
Impact:
Faster convergence.
Higher baseline quality from start.
Ablations: full-scale random init had higher loss; growth-init curve tracked smoothly.
7. Training Stability Suite
Before:
MoE models prone to “expert collapse” (router sends tokens to only a few experts).
Loss spikes → irrecoverable training crashes.
After:
Router-gradient balancing: equalizes backprop signal across experts.
Hidden z-loss: penalizes over-confident logits, suppresses instabilities.
Adam ε tuned to 1e-16 to prevent numerical blow-ups.
Impact:
Training runs stable across 20T tokens.
No collapse events reported.
Consistent convergence across scales.
8. Deterministic Training + Custom Kernels
Before:
Non-deterministic ops (e.g., ScatterAdd, GEMM accumulation) → run-to-run drift.
Silent data corruption (SDC) undetectable at 10k+ GPU scale.
After:
Custom deterministic kernels:
FlashAttention Gradients
ScatterAdd
Grouped GEMM
Fused GemmAdd (adds in FP32 inside GEMM epilogue)
Nearly same throughput as non-deterministic kernels.
Impact:
Exact reproducibility.
SDC detection possible.
Confidence in large-scale multi-week training jobs.
9. Distributed Training Strategy
Before:
Memory usage exceeded 80GB per GPU.
Communication latency from all-gathers and reduce-scatters.
After:
Multi-dimensional parallelism: EP + TP + PP + DP + Context Parallelism.
V-ZB memory balancing reduced peak memory <60GB.
Impact:
Enabled training on H800-80GB GPUs.
98.5% training availability across 20T tokens in 30 days.
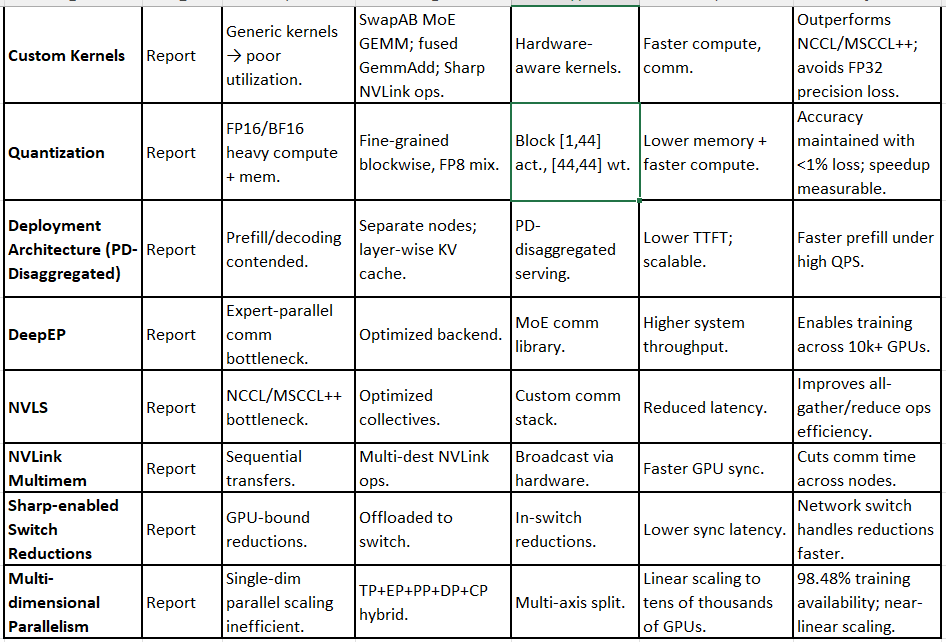
C. Inference & Deployment
10. Mixed Linear Attention (MLA)
Before:
Quadratic complexity attention (O(n²)) → infeasible for 128k contexts.
After:
MLA reduces complexity → O(n).
Splits RoPE/NOPE dims to balance positional encoding.
Impact:
Supports 128k context efficiently.
KV cache significantly smaller → less bandwidth per step.
11. KV-Projection Factorization (LoRA-style, from config)
In the Technical Report (PDF):
Describes Mixed Linear Attention (MLA) and variance alignment mechanisms.
Explains the use of scale correction factors (αq, αkv) to stabilize initialization and balance variance in Q/K projections.
Highlights that MLA reduces KV-cache size and bandwidth pressure, enabling 128k context.
❌ Does not mention LoRA explicitly.
In the Hugging Face Configuration (
configuration_longcat_flash.py):Confirms low-rank factorization of Q/K/V projections is actually implemented.
Parameters:
q_lora_rank = 1536
kv_lora_rank = 512
This shows the design is LoRA-style factorization, reducing KV-cache dimensionality while preserving representational power.
Before:
Full-rank Q/K/V projections → large KV cache, memory bandwidth bottleneck at long contexts.
After:
Factorized (LoRA-style) Q/K/V → smaller cache, reduced memory footprint, less communication overhead.
Impact:
Practical feasibility of 128k-token context windows without prohibitive memory use.
Higher throughput and lower latency in inference.
12. Multi-Token Prediction (MTP)
Before:
Each step predicted 1 token → slow decoding.
After:
Lightweight MTP head (single dense layer) predicts multiple tokens.
~90% acceptance rate in speculative decoding pipeline.
Impact:
Significant latency reduction in generation.
Maintains near-baseline accuracy.
13. Single-Batch Overlap (SBO)
Before:
Compute and communication sequential; latency compounded.
After:
Reorders execution; overlaps NVLink intra-node bandwidth with RDMA inter-node comm.
Impact:
100 tokens/sec throughput on H800.
Cost per million tokens: $0.70.
14. TVD Fusing & Scheduler Optimizations
Before:
Separate CUDA graph launches for Target, Verification, Draft passes.
CPU sync overhead.
After:
TVD fused into a single CUDA graph.
Multi-step overlapped scheduler → continuous GPU occupancy.
Impact:
TTFT reduced under high QPS.
Safe dynamic KV cache allocation.
15. Custom Kernels
Before:
Standard GEMM inefficient for irregular expert batches.
Communication limited by NCCL/MSCCL++.
After:
MoE GEMM: SwapAB trick improves tensor-core usage.
Fused GemmAdd reduces memory traffic.
NVLink Sharp kernels accelerate all-to-all ops.
Impact:
Higher tensor utilization, reduced latency.
Communication faster than NCCL/MSCCL++ baselines.
16. Quantization
Before:
BF16/FP16 → high memory & compute.
After:
Blockwise quantization: [1,44] activations, [44,44] weights.
Layer-wise mixed precision (some FP8).
Impact:
Lower memory.
Maintained accuracy with faster inference.
17. Deployment Architecture (PD-Disaggregated)
Before:
Prefill and decode competed on same hardware.
After:
Prefill and decode disaggregated into separate nodes.
KV cache transmitted layer-wise.
Impact:
Lower TTFT under high load.
Wide EP with DeepEP support for ZCE minimizes comm overhead.
D. System & Infrastructure
18. DeepEP
Before:
MoE expert comms bottlenecked at scale.
After:
Custom comm backend optimized for MoE.
Impact:
Higher throughput at 1000s of GPUs.
19. NVLS (Collectives Library)
Before:
NCCL/MSCCL++ limited throughput at large cluster sizes.
After:
NVLS optimized collectives for LongCat workloads.
Impact:
Reduced collective comm bottlenecks.
20. NVLink Multimem
Before:
Memory replication to multiple GPUs required sequential copies.
After:
Hardware-level broadcast.
Impact:
Faster GPU-to-GPU communication.
21. Sharp-enabled Switch Reductions
Before:
All reductions executed on GPUs.
After:
In-switch reductions offload compute to network switch.
Impact:
Lower latency sync across nodes.
22. Multi-dimensional Parallelism
Before:
Training limited by single parallel dimension.
After:
Uses TP + EP + PP + DP + CP.
Impact:
Near-linear scaling across tens of thousands of accelerators.
✅ High-Level Overview
Training Stability: router-balancing, z-loss, deterministic kernels = stable at 560B.
Efficiency: ZCE, ScMoE, MLA, LoRA, quantization = less compute per token, same quality.
Throughput: SBO, MTP, fused kernels = >100 TPS on H800.
Scaling: Hyperparam transfer, growth init, multi-parallelism = linear scaling across 10k+ GPUs.
Reliability: 98.5% availability with automated recovery.
Context Window: MLA+LoRA enable 128k tokens.
📊 LongCat-Flash Optimizations — Master Comparison Table
🌟 LongCat-Flash: Top 5 Breakthrough Optimizations
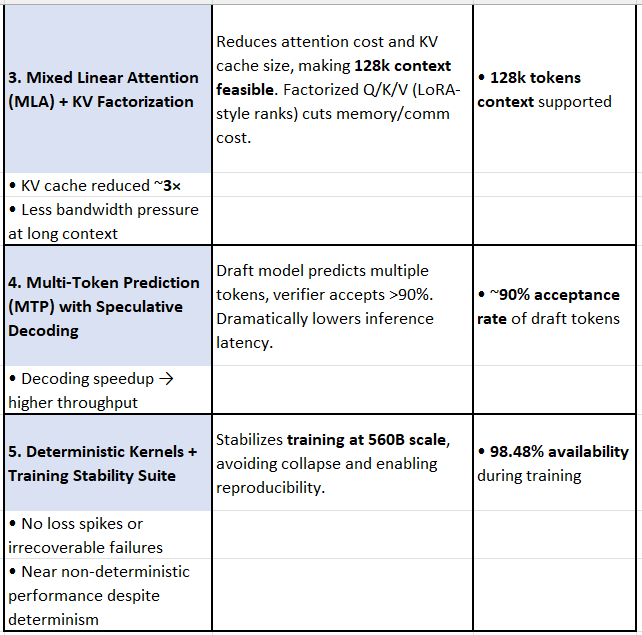
📌 Why these matter most:
ScMoE + SBO = System-level efficiency, directly drives training/inference cost savings.
ZCE = Smarter compute usage, more “bang for FLOP.”
MLA + KV factorization = Unlocks 128k context without exploding memory.
MTP = Real-world inference latency gains.
Stability Suite = Makes training at this insane scale actually possible.
As a mark of respect and much appreciation to the amazing teamwork, I would additionally like to recommend both these “watches”. I find the expression of views rational, and open-minded. Basically, logical:
Elie Bakouch (on X)
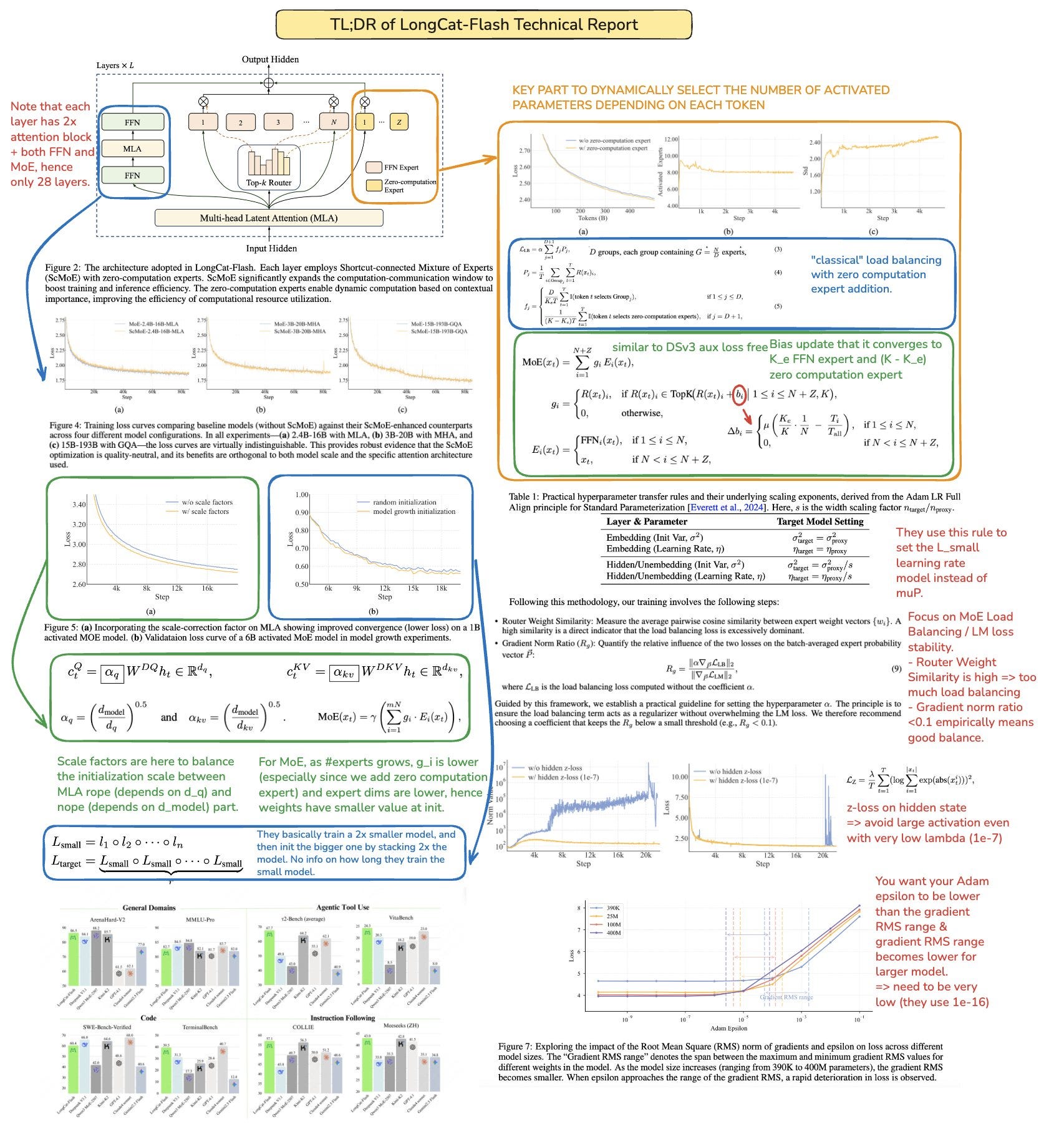
References:
Deploying Longcat-Flash: https://lmsys.org/blog/2025-09-01-sglang-longcat-flash/
HuggingFace: https://huggingface.co/meituan-longcat/LongCat-Flash-Chat
Github: https://github.com/meituan-longcat/LongCat-Flash-Chat
Longcat-Flash Technical Report: https://github.com/meituan-longcat/LongCat-Flash-Chat/blob/main/tech_report.pdf
Elie Bakouch (on X): https://x.com/eliebakouch/status/1961999252311204147