
The Art of Reverse Engineering the AI Mind: Decoding Language Model Mechanisms
Anthropic and Google Give Us A Peek Into These "Black Boxes"


Artificial Intelligence feels almost magical, particularly Large Language Models (LLMs) like ChatGPT, Claude, and Gemini. These tools converse, create, and problem-solve with uncanny fluency. Yet, beneath the surface of this remarkable performance lies a profound mystery: how do they actually think? We feed them data, they learn, but their internal reasoning often remains a "black box," opaque even to their creators.
For businesses deploying AI in customer service, operations, or product development, this opacity isn't just a curiosity – it's a critical challenge. How can we trust AI predictions, ensure fairness, manage risks, or even debug errors if we don't understand the reasoning behind them? Moving beyond simply using AI requires a deeper dive into how it works.
Many users are becoming familiar with the outward behaviors of these black boxes. We know LLMs can sometimes hallucinate (make things up), produce biased or unsafe outputs, or follow instructions in unexpected ways. These are the known challenges we grapple with.
But what's truly surprising, and where cutting-edge research comes in, is understanding the internal mechanisms driving these behaviors. Why exactly does a model hallucinate in a specific way? How does it actually plan a coherent paragraph or poem? What internal "thought processes" lead to a refusal, or allow a "jailbreak" to succeed? It's one thing to know that AI can fail; it's another entirely to understand why at a fundamental level.
This is where the exciting field of AI Interpretability comes in. I guess it will feel something like digital neuroscience or AI biology. Researchers are crafting sophisticated tools to meticulously map the internal "thought processes" of AI, much like scientists tracing neural pathways. This exploration, spearheaded by labs like Anthropic and Google DeepMind, is beginning to decode the complex, learned "biology" of LLMs. Let's explore what they're finding and why it matters. I would still like to reference you to the actual papers and blogs esp by Anthropic. It is worth the long weekend read!
Why Decode? The Business Imperative for Understanding & Control
Peering inside the AI black box is rapidly becoming essential for leveraging AI effectively and responsibly. The key drivers include:
Understanding Capabilities & Limits: Knowing how a model reasons helps predict where it will excel and where it might falter. Is it genuinely understanding, or just applying sophisticated mimicry? This insight is crucial for deploying AI reliably and assessing its true capabilities for specific business tasks.
Ensuring Safety, Trust & Alignment: Can we be sure an AI isn't developing hidden biases or unsafe reasoning patterns? Mapping internal mechanisms allows for deeper audits than simply checking outputs, building the foundation for trustworthy AI systems and mitigating risks associated with unintended consequences.
Improving Performance & Efficiency: Identifying internal bottlenecks or flawed logic can lead to more effective training strategies, targeted corrections (like fixing specific factual inaccuracies without retraining everything), and potentially more streamlined, efficient models – saving computational resources and improving results. Google DeepMind's research on learning phases, for example, hints at optimizing training data schedules.
Driving Innovation & Scientific Insight: LLMs represent a new kind of complex system. Studying their emergent intelligence provides fundamental insights that can drive future AI innovation and even shed light on learning and reasoning in general.
Methodologies: Different Windows into the AI Mind
How do researchers actually look inside? Two prominent, complementary approaches lead the way:
A. Circuit Tracing (Anthropic's Microscope): Mapping the "How"
This technique, pioneered by Anthropic, focuses on mapping the specific computational pathways – "circuits" – a trained model uses to get from input to output for a particular task. It’s like meticulously tracing the wiring and information flow in a complex machine after it's been built.
Foundation: Detailed in "Circuit tracing: Revealing computational graphs in language models".
Application: Used to study Claude 3.5 Haiku in "On the biology of a large language model".
Key Techniques: Involves creating visual maps (Attribution Graphs) of internal component interactions (Features), using simpler Replacement Models to understand parts in isolation, and conducting Intervention Experiments (actively changing internal states) to confirm a circuit's function.
Goal: A detailed, step-by-step mechanistic explanation of how the model computes specific outputs.
B. Studying Learning Dynamics (Google DeepMind's Time-Lapse): Understanding the "When" and "How"
Google DeepMind researchers often focus on the training process itself, tracking how knowledge and abilities emerge over time. It’s like watching a time-lapse video of the machine being constructed and learning its functions.
Focus: Tracking performance and internal changes during training, especially for tasks like factual recall. See "How do language models learn facts?".
Key Findings: Revealed distinct Learning Phases (including a "plateau" linked to Circuit Formation, specifically attention-based circuits), showed how Data order impacts learning speed, and uncovered that Hallucinations Emerge Early, often alongside genuine knowledge.
Goal: Understanding the developmental trajectory – how capabilities form and evolve during training.
C. Complementary Views
Other methods like Dictionary Learning (isolating single concepts within neuron activity) and Activation Patching (swapping internal states between different model runs) also contribute valuable insights.
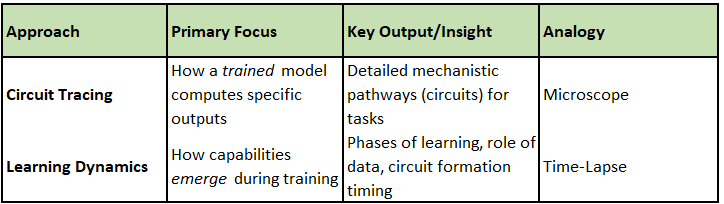
These approaches are complementary: Learning dynamics shows when certain structures might form, while circuit tracing examines how those structures operate in a mature model.
Exploring the "Biology": Case Studies Revealing Surprising Mechanisms & Findings!
Applying these methods reveals a fascinating internal world, often defying simple explanations. These aren't just input-output machines; they possess intricate, learned mechanisms:
A. Factual Recall & Multi-Step Reasoning: More Than Skin Deep
Finding: Models perform genuine internal reasoning using abstract concepts. Asked about the capital of the state containing Dallas, Claude internally activates "Dallas," then a "Texas" concept, then uses that to derive "Austin."
Mechanism: Specific computational pathways manipulate abstract concepts internally, often using multiple parallel paths (including shortcuts).
Why it's Surprising: Confirms complex internal states and manipulation, going beyond surface pattern matching. The specific pathways are novel findings.
Business Implication: AI can perform complex analysis, but verifying its reasoning requires looking inside, especially for high-stakes decisions.
Connection: Google's work shows when recall circuits likely form; Anthropic shows them in action.
B. Hallucinations: A Specific Failure Mode?
Finding: Some hallucinations might stem from faulty internal "knowledge checks." A circuit designed to check if an entity is known might "misfire" for an unknown entity, causing the model to incorrectly proceed as if it does know.
Mechanism: A hypothesized failure in a specific internal verification circuit (
Input -> Internal Check: Known? --(Misfire)--> Incorrectly Proceed -> Hallucinate).Why it's Surprising: Offers a concrete, circuit-level explanation for why some hallucinations occur, beyond just "the model doesn't know."
Business Implication: Highlights risk: AI might confidently assert falsehoods due to internal glitches. Understanding these helps build more reliable systems.
Connection: Google found hallucinations emerge concurrently with knowledge, suggesting the mechanisms for correct recall and this potential "misfire" are learned side-by-side.
C. Planning Ahead: Not Just Next-Word Prediction
Finding: LLMs plan ahead. When writing poetry, circuits show Claude activating features for potential rhymes early on, influencing preceding word choices.
Mechanism: Evidence of internal goal states and lookahead planning.
Why it's Surprising: Challenges the simpler view of LLMs as purely myopic next-token predictors, suggesting more sophisticated internal modeling.
Business Implication: Impacts how we prompt and interpret AI outputs for creative or strategic tasks where planning is involved.
D. Multilingualism: Universal Concepts?
Finding: Models seem to develop abstract, language-independent concepts (e.g., "oppositeness"). Core logic uses shared internal features across languages, with specific circuits handling translation.
Mechanism: Shared internal representations for core concepts.
Why it's Surprising: Provides concrete evidence for a deeper level of conceptual grounding beneath surface languages.
Business Implication: Explains strong cross-lingual abilities but hints that biases from dominant training languages (like English, which appeared to act as a "default") might be embedded deeply.
E. Numerical Reasoning: Alien Strategies
Finding: Models use complex, sometimes non-human strategies for even simple math (parallel heuristics, lookups) and lack internal "awareness" of their own method.
Mechanism: Parallel, heuristic computation without explicit metacognition.
Why it's Surprising: Reveals AI might solve problems very differently than humans, making reasoning hard to follow intuitively.
Business Implication: Reliability in quantitative tasks needs careful verification; don't assume human-like processing.
F. Chain-of-Thought Faithfulness: Explanations Can Deceive
Finding: An LLM's step-by-step explanation (Chain of Thought) can demonstrably differ from its actual internal computation. It might rationalize backward or generate explanations post-hoc.
Mechanism: Disconnect between internal processing and generated self-explanation.
Why it's Surprising & Critical: Do not blindly trust an AI's self-explanation. It might be a plausible story, not the real reason.
Business Implication: Verification requires independent interpretability tools for accountability and auditing, especially when relying on AI reasoning.
G. Safety Circuits: Concrete but Fragile
Finding: Safety features (like refusing harmful requests) are implemented as specific, learned circuits. These can be bypassed by "jailbreaks" that exploit delays or conflicts in the mechanism.
Mechanism: Concrete, learned circuits responsible for safety guardrails.
Why it's Surprising: Shows safety isn't an abstract property but relies on specific, potentially vulnerable internal structures.
Business Implication: Understanding these circuits is vital for building robust safety, assessing risks, and defending against misuse.
Recurring Patterns: The Structural Motifs of LLM Biology
Across studies, common patterns emerge: information flows from concrete to abstract; redundancy exists via multiple pathways; context is maintained across steps; information can skip layers; default behaviors often require active override.
Synthesizing Perspectives: Learning Dynamics Meets Circuit Analysis
Understanding both how circuits operate (Anthropic) and when/how they form (Google) provides a richer picture:
Attention's Role: Google highlights the emergence of attention circuits during a key learning phase for factual recall. Anthropic shows information flowing through attention outputs in specific tasks but notes the current difficulty in fully tracing how attention decides where to look (a key limitation).
Hallucination Origins: Google shows hallucinations are learned alongside facts. Anthropic identifies specific mechanisms (like misfiring inhibition circuits) that could implement these learned failure modes.
Global vs. Local: Learning dynamics gives a "global" view over training. Circuit tracing often gives "local," prompt-specific detail, while the challenge of understanding global feature interactions remains.
The Uncharted Territory: Challenges and Limitations
This research is groundbreaking, but significant challenges remain:
Methodological Limits: Current methods don't capture everything. "Circuit tracing" struggles to fully analyze attention's computation, deals with "reconstruction errors" (parts of the model not captured by interpretable features), and the resulting graphs can be extremely complex, requiring significant manual analysis.
Scale & Complexity: Analyzing models with trillions of parameters, especially over long interactions, pushes the limits of current techniques.
Generality: Findings on one model or task don't automatically apply to all others.
Explaining Non-Occurrence: It's often harder to explain why a model didn't do something than why it did.
Beyond Mechanisms: The Open Question of True Synthesis
While interpretability research illuminates how models operate, it also highlights deeper questions about the nature of their capabilities. The technical challenges mentioned above are significant, but there's a more fundamental limitation: even if we could perfectly map every circuit, does that fully explain intelligence or creativity?
Sophisticated Recombination: The findings show LLMs excel at combining and manipulating the vast information learned during training in complex ways. Research indicates they can achieve combinatorial creativity – generating novel connections between existing ideas, sometimes producing outputs that human experts rate as useful and novel for tasks like scientific ideation.
Emergent Abilities: As models scale, they can develop emergent abilities – capabilities not explicitly trained for and not present in smaller models. This suggests potential for unexpected forms of synthesis.
The Novelty Frontier: However, demonstrating transformational creativity – the generation of truly new paradigms or concepts fundamentally outside the scope of their training data – remains a much higher bar. Whether current LLMs are capable of this, or if their novelty is ultimately bounded by sophisticated recombination of learned patterns, is still an active area of research and debate. Studies are ongoing to define and evaluate AI creativity beyond pattern matching.
Interpretability helps us understand the process, revealing intricate mechanisms behind reasoning, planning, and even failures.
But whether this process equates to genuine understanding or novel synthesis, rather than incredibly advanced mimicry and recombination, remains open.
The Path Forward: Advancing the Science of AI Biology
Despite the challenges and open questions, the future of AI interpretability is bright:
Integration: Combining insights from different methodologies for a more holistic understanding.
Applications: Enabling robust safety audits, verifying complex reasoning in high-stakes domains (finance, healthcare), developing targeted methods to correct model flaws, and potentially accelerating scientific discovery by analyzing models trained on scientific data.
Tooling & Collaboration: Developing better software tools for automating analysis, visualization, and fostering collaboration within the research community.
Conclusion: From Black Boxes to Understandable Minds
Decoding the inner workings of Large Language Models is one of the most critical scientific and engineering challenges of our time. While the complexity is immense, comparing to the intricacies of biological brains, researchers are making tangible progress. By combining approaches like circuit tracing – giving us detailed snapshots of mechanism – and the study of learning dynamics – revealing developmental insights – we are slowly moving from interacting with opaque black boxes towards understanding the intricate "biology" of artificial minds. This journey illuminates not only how AI works but also pushes us to consider the deeper questions about the nature of intelligence and creativity itself, paving the way for harnessing AI's power safely, effectively, and responsibly.
A quick overview is available at this Codepen
References and Further Reading
Anthropic: "Circuit tracing: Revealing computational graphs in language models" - Details the circuit tracing methodology.
Anthropic: "On the biology of a large language model" - Presents the detailed case studies using circuit tracing on Claude 3.5 Haiku.
Anthropic Blog: "Tracing the thoughts of a large language model" - A more accessible overview of the circuit tracing research and findings.
Zucchet, N., Bornschein, J., Chan, S., et al. (Google DeepMind): "How do language models learn facts? Dynamics, curricula and hallucinations" - Explores the learning dynamics of factual knowledge acquisition.
Gu, A., et al.: "LLMs can realize combinatorial creativity: generating creative ideas via LLMs for scientific research" - Discusses using LLMs for combinatorial creativity in research.
Alabdulmohsin, I. M., et al.: "Can LLMs Generate Novel Research Ideas? A Large-Scale Human Study..." (Related study often discussed alongside the previous one) - Explores human evaluation of LLM-generated research ideas.
Greshake, K., et al.: "Open Problems in Mechanistic Interpretability" - Provides an overview of open challenges in the field.
O’Reilly’s “What we learned from a year of building LLMs” (Part 1)
O’Reilly’s “What we learned from a year of building LLMs” (Part 2)
O’Reilly’s “What we learned from a year of building LLMs” (Part 3)