
The Harness Experiment
What Ten AI Architectures Teach About Intelligence, Instructions, and Why More Is Often Less

This is an account of a (fairly) controlled experiment — ten versions of the same task, ten different AI architectures, and several contradictions that get many working on agentic systems excited (but maybe shouldn’t). The most sophisticated system isn’t always the best. The simplest one won. What follows is more instructive than the results.
The Question Not Many Are Asking
Every week brings a new announcement about multi-agent AI systems, swarm intelligence, and the promise that coordinating multiple AI models will unlock capabilities beyond what any single model can achieve. The discourse has the texture of inevitability. More agents, more tools, more architectural complexity — this is the direction of travel, and questioning it feels like scepticism for its own sake.
But what if the question of how many agents you need is less important than the question of how clearly you tell one agent what to do?
That is the question this experiment was designed to answer. Not whether multi-agent systems are theoretically superior. Whether they are practically superior — on real tasks, with real measurement, against a clear baseline. The answer turned out to be considerably more nuanced than suggested.
“Humans steer. Agents Execute.” — Ryan Lopopolo, Technical Team, OpenAI
That quote captures the premise of what has become a new engineering discipline: harness engineering. The harness is everything that surrounds an AI model — the instructions, the tools, the memory systems, the verification loops, the architecture that determines what the model knows, what it can do, and when it decides it is finished. For much of 2025/26, building a harness meant adding more of each of those things.
The formula Hashimoto’s work gave us is simple: Agent = Model + Harness.
This experiment set out to measure whether more was, in fact, better. It is obviously limited by it’s scope, and yet, many learning points were taken.
Setting the Stage: What Was Built and Why
The project, which I am calling Harness Lab, was built to run a single fixed task through ten progressively more sophisticated AI architectures. The task was deliberately mundane: evaluate three logistics vendors across cost, reliability, and integration criteria, produce a scored comparison table, and recommend one vendor with justification.
The mundanity was intentional. I did not want a task so complex that only sophisticated architectures could handle it. I wanted a task that any competent system should be able to complete — and then watch what happened when I added layers on top of a system that was already competent.
The Task
Three vendors: FreightNova, LogiPath, and ChainCore. Three scoring criteria with fixed weights: cost at 35 percent, reliability at 40 percent, integration at 25 percent. Required output: a scored table, a weighted total for each vendor, a 200-word written recommendation naming one vendor, and a confidence rating. All vendor data was provided — no external knowledge required.
The correct answer was not ambiguous. In this test example, ChainCore had the highest weighted score (8.24), driven by its reliability premium (97.5% on-time rate versus 91-94%), a 2-hour incident recovery SLA against 4-12 hours for competitors, and the best integration depth. The task was designed to have a defensible right answer so the scoring could be meaningful.
The Infrastructure
The project ran inside VS Code with Claude Code as the outer runtime — the AI agent that read the specification, built all the project files, and executed each experiment. Every experiment shared the same foundation: a single API client file, a fixed rubric, a gold-standard answer, and a self-healing error recovery system.
The key architectural principle was the separation of concerns. To change the model, you edit one line. To change the task, you edit one file. The experiment layer — where different harness architectures were tested — was entirely isolated from the infrastructure layer. This is precisely the structure that Addy Osmani describes as Harness-as-a-Service: a platform layer that you configure, rather than rebuild.
┌─────────────────────────────────────────────────────────────┐
│ Claude Code (HaaS Runtime) │ ← Outer Harness-as-a-Service
│ • ReAct / Agent Loop │
│ • Tool Registry + Permission Gates │
│ • Context Assembly + Compaction │
│ • 3-Layer Memory System (in-context + MEMORY.md + files) │
│ • Sub-agent / Swarm Orchestration │
│ • Safety, Hooks, Streaming, Sandboxes │
│ • Persistent Filesystem + Execution Environment │
└──────────────────────────────▲──────────────────────────────┘
│ (Configure + Extend)
│
┌──────────────────────────────┴──────────────────────────────┐
│ Pre-Experiment Harness (Lab OS / Foundation) ← Standardized Configuration Surface
│ • shared/client.js (model routing) │
│ • shared/scorer.js + rubric system │
│ • shared/self_heal.js + logger │
│ • Root CLAUDE.md (constitution + lab-wide rules) │
│ • Memory conventions + task templates │
│ • Observability & results pipeline │
│ • Common tools & utilities │
└──────────────────────────────▲──────────────────────────────┘
│ (Swappable)
│
┌──────────────────────────────┴──────────────────────────────┐
│ Experiment Harness Layer (H1–H10) │ ← Domain-Specific Scaffolding
│ │
│ H1: Prompt + Constitution │
│ H2: Reflection + Self-Critique Loop │
│ H3: Sequential Tool-Use │
│ H4: Parallel Fan-Out + Merge │
│ H5: Eval + Revision Loop │
│ H6: Skill / Memory Crystallization │
│ H7: Model Routing / Tiered │
│ H8: HITL + Confidence Gating │
│ H9: Sub-Agent Swarm │
│ H10: Meta-Router / Adaptive │
└──────────────────────────────▲──────────────────────────────┘
│
┌──────────────────────────────┴──────────────────────────────┐
│ Core Model │
│ gpt-oss-120b / Claude Sonnet etc. │
└─────────────────────────────────────────────────────────────┘The folder structure looked like this:

Three metrics were tracked for each experiment. Alpha (α): quality score from 0 to 1, assessed by a separate AI judge against a detailed rubric. Lambda (λ): latency in milliseconds. Kappa (κ): total tokens consumed. The rubric measured reasoning quality, not structural completeness — a deliberate design choice that turned out to be critical, as we will see.
The First Mistake: When the Rubric Lies
The first run of the experiment produced an immediate problem, and the problem was not with the AI.
H1 — the bare model control, no system prompt, no tools, no structure — scored alpha of 1.0. Perfect. A system with no harness whatsoever had produced a flawless result on the first attempt.
This was not a finding. It was a measurement failure.
“If your evaluation gives everything a perfect score, you have not built a rubric. You have built a rubber stamp.”
The Scoring Problem (My Biggest Early Mistake)
Before running any experiment, I had instructed Claude Code (based on objectives) to build a judge — a second AI call that scores each output 0–1.
The original rubric had six yes/no checkboxes: Does it have a table? Does it name a vendor? Does it give a confidence rating?
H1 (the bare model with zero guidance) scored 1.0. Perfect.
That’s like grading an essay purely on whether it has paragraphs and a title. A student who writes beautifully structured nonsense aces it. The rubric was measuring presence of structure, not quality of reasoning.
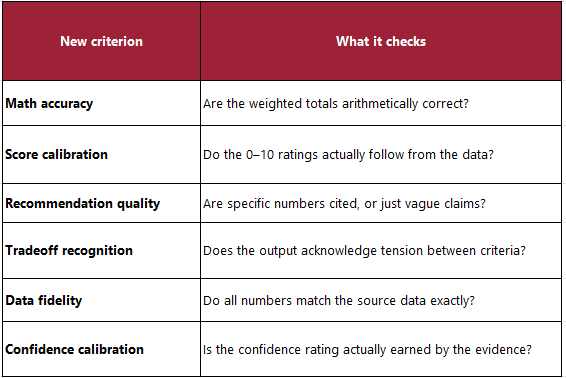
That was replaced with six gradient criteria — each scored 0.0 to 1.0 — focused on things that actually matter:
H1 re-scored to 0.665 — a realistic baseline with real headroom above it.
Bugs I Hit Along the Way
Two experiments scored 0.000 for reasons unrelated to the model’s quality:
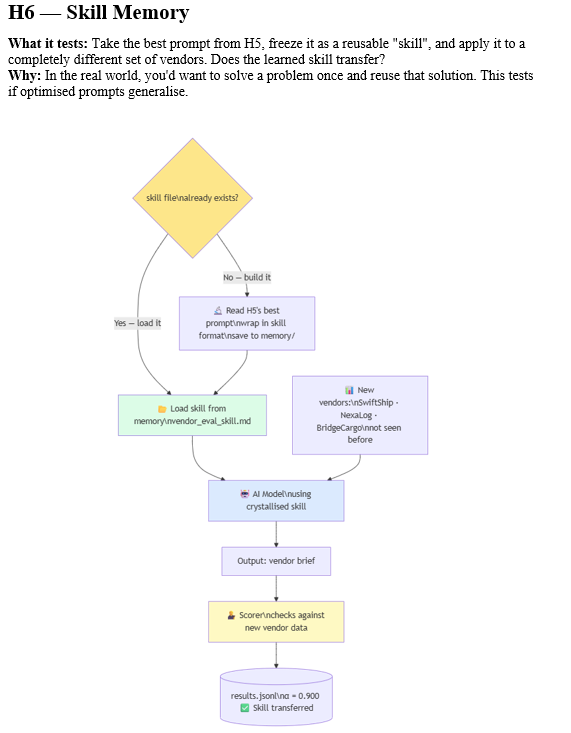
H6 (Skill Memory) — This experiment deliberately uses different vendors (SwiftShip, NexaLog, BridgeCargo) to test whether the skill transfers. The scorer was still checking against the original vendor list and flagged every number as invented. Fix: let the scorer accept the task’s own vendor data.
H8 (HITL) — The correction step told the model: “Return the corrected complete JSON output.” The model returned a tidy list of corrections — not the corrected vendor brief. Fix: explicitly say “return the full brief in the same format as the input, with fixes applied.”
Rebuilding the Rubric
The rubric was rebuilt from scratch before running any further experiments. The new version replaced binary structural checks with gradient quality criteria:
– Math accuracy: Are the weighted totals arithmetically correct? A score of 1.0 required all three vendors correctly calculated to two decimal places. Wrong formula, partial credit. No calculation, near zero.
– Score calibration: Are the raw 0-10 criterion scores defensible from the data, with consistent logic across vendors? Arbitrary or uniform scores dropped the result significantly.
– Recommendation quality: Does the justification cite specific numbers from the vendor data, not vague assertions? A recommendation that says ChainCore is reliable scores lower than one that cites a 97.5% on-time rate and a 2-hour SLA.
– Tradeoff recognition: Does the output acknowledge that the cheapest vendor is not the most reliable, or that the best-integrated vendor costs more? This is the reasoning quality marker.
– Data fidelity: Are all cited numbers exactly from the source data, with no invented statistics?
– Confidence calibration: Is the confidence rating calibrated to the actual certainty implied by the data?
The scorer prompt was also revised with an explicit anti-inflation instruction: a bare model output with no system prompt should score roughly 0.5 to 0.65 on this rubric. If the scorer was about to return above 0.80 for a plain unstructured output, it was instructed to reconsider its scores.
This is a lesson that applies well beyond this experiment.
Evaluation design is inseparable from experimental design. The harness you build around the model matters less than the harness you build around the measurement. A rubric that cannot detect quality differences between good and bad outputs will make every architecture look equally capable — which is precisely the kind of false equivalence that leads to bad decisions about AI system design.
The Experiments: What Actually Happened
With a working rubric in place, the ten experiments ran in sequence. What emerged was a story with a clear shape: quality peaked early, then complexity took over without improving results.
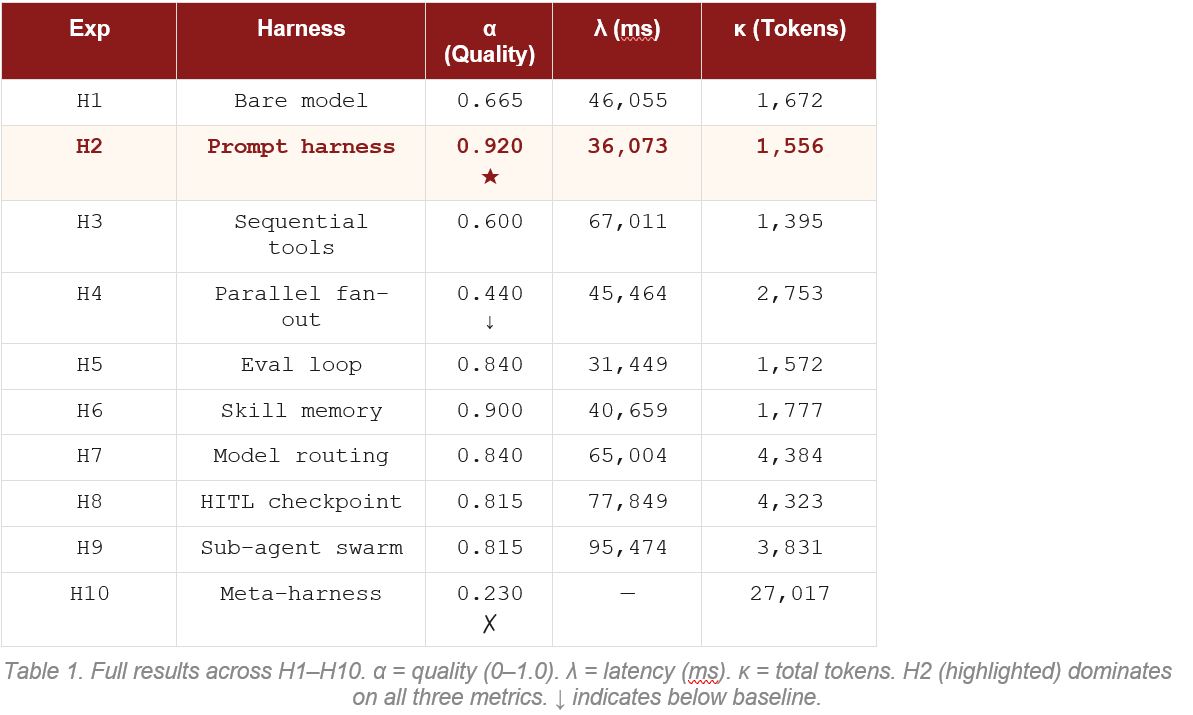
Table 1. Full results across H1–H10. α = quality (0–1.0). λ = latency (ms). κ = total tokens. H2 (highlighted) dominates on all three metrics. ↓ indicates below baseline.
H1: The Control (0.665)
The bare model without any harness structure scored 0.665. It produced a reasonable vendor evaluation — a table existed, a recommendation was made, ChainCore was correctly identified as the best choice. But the justification was thin, the weighted math had a minor error, and the confidence rating was present but miscalibrated. This is the floor. Everything above it represents harness contribution.
H2: The Prompt Harness (0.920) — The Peak
Adding a structured system prompt that specified the analyst role, the exact scoring weights, the required JSON output format, and an explicit anti-hallucination rule produced the best result in the entire experiment. Not second best. Best. By a substantial margin.
H2 was also the fastest experiment (36 seconds versus H1’s 46 seconds) and consumed the fewest tokens (1,556). In every measurable dimension — quality, speed, and cost — the structured prompt won.
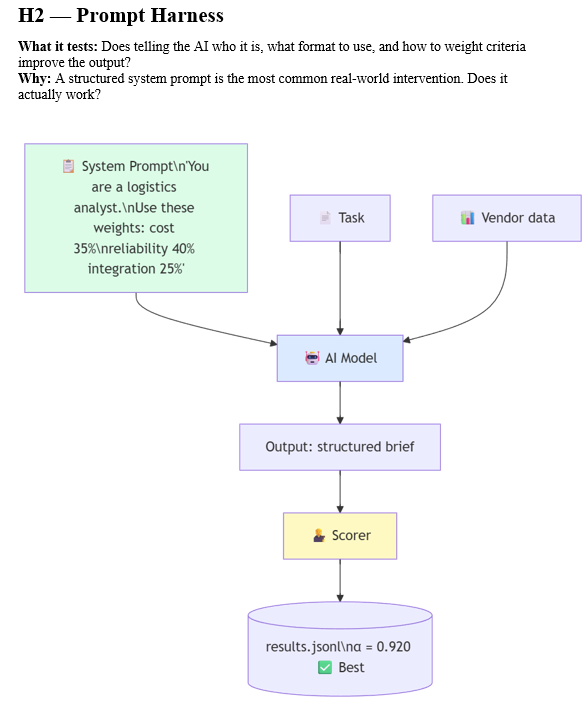
This is the result that demands explanation, because it goes against the grain of almost everything being built in the AI industry right now. A text file with clear instructions outperformed multi-agent swarms, automated eval loops, model-tier routing systems, and confidence-gated correction mechanisms. The system prompt is 200 words. The sub-agent swarm (H9) consumed nearly three times as many tokens and scored 0.105 lower.
“A well-crafted instruction is not a primitive technique waiting to be superseded. It is the thing that every sophisticated architecture is trying to approximate.”
H3: Sequential Tools (0.600) — Below Baseline
Adding tool use — a search function the model could call to retrieve vendor data — dropped quality below the H1 baseline. The tool loop fragmented the task. Each tool call returned a narrow slice of vendor data, and the model synthesized from three partial views rather than one holistic context. The mechanics of using the tool consumed cognitive resources that would have been better spent on reasoning.
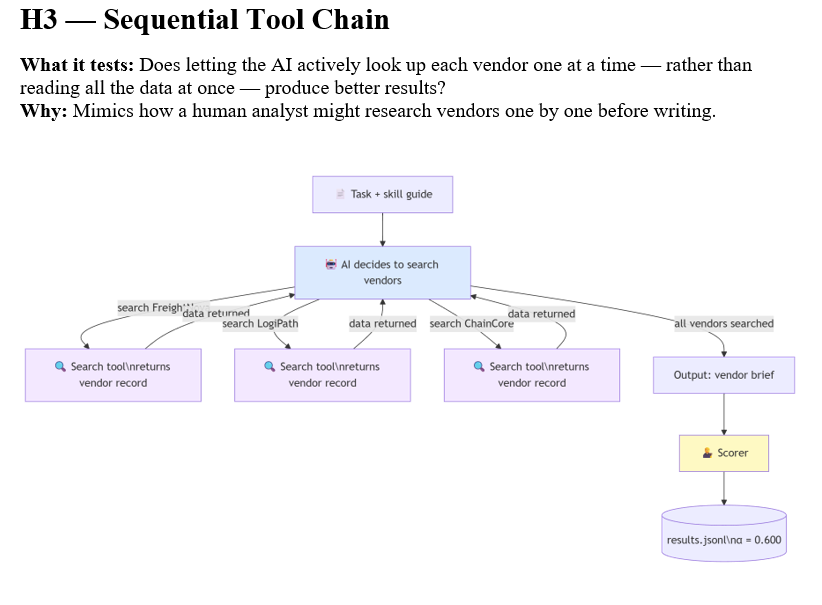
Latency jumped by 45 percent compared to H2. Tokens dropped slightly (the tool calls were efficient) but quality fell. This is a common pattern: tools add value when the data they retrieve would otherwise be unavailable, not when the data is already present in the context.
H4: Parallel Fan-Out (0.440) — The Coherence Collapse
This is where the experiment became genuinely instructive. H4 dispatched three sub-agents concurrently using Promise.all — one per vendor — then merged their individual scores into a final recommendation. The theory was that parallelism would reduce latency while maintaining quality.
Quality dropped to 0.440. This is 33 percent below the H1 baseline. Three agents working simultaneously produced worse output than one agent working alone with no special instructions.
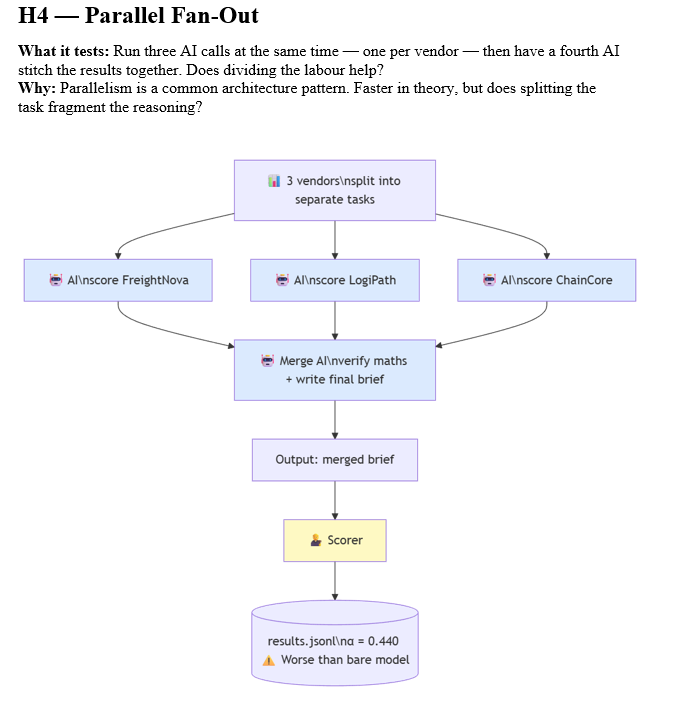
The diagnosis is a coherence problem. Each sub-agent independently calibrated its 0-10 scoring scale. Sub-agent A might rate LogiPath’s cost as 8.5 because it is the cheapest. Sub-agent B might rate ChainCore’s reliability as 9.5 because it has the best on-time rate. But 8.5 from sub-agent A and 9.5 from sub-agent B are not on the same scale. The merge agent received three scored JSON blobs with no shared methodology and was asked to synthesize them into a coherent recommendation. The rubric’s score calibration criterion — which checks whether scores are defensible and consistent across vendors — penalized this heavily.
This failure mode is well-documented in multi-agent research and is precisely what sophisticated systems like ForgeCode address through specialised roles and verification gates. A Sage-style reviewer checking sub-agent outputs for consistency before merge would catch this. The naive parallel fan-out does not.
H5 and H6: The Eval Loop and Skill Memory (0.840 / 0.900)
H5 ran a generate-score-revise loop for three generations, automatically rewriting its system prompt each time a criterion scored below 0.70.
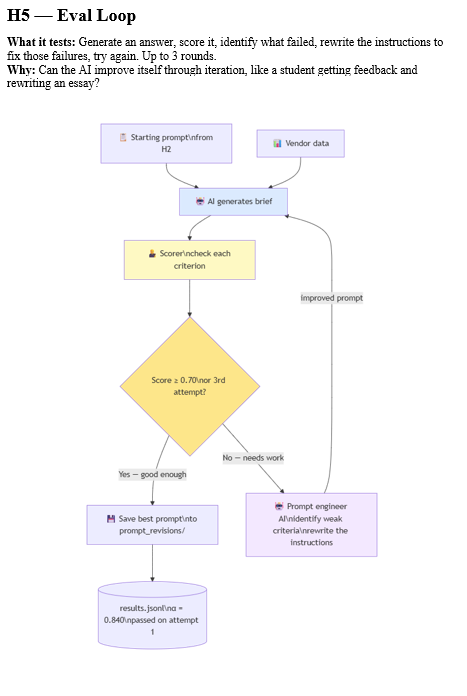
H6 took the best prompt from H5, crystallised it into a skill memory file, and applied it to a completely different set of vendors.
Both scored well. But notice what H5 was actually doing: iterating toward a good system prompt. The eval loop is an automated prompt optimisation process. What it converged on, after three generations of self-revision, was essentially a well-crafted instruction — which is what H2 had from the start.
H6 produced the genuinely useful finding: the crystallised skill transferred. Applied to new vendors (SwiftShip, NexaLog, BridgeCargo), it maintained 0.900 quality with no additional effort. This is skill memory working as intended — not as a substitute for good initial design, but as a mechanism for preserving and reusing good design once it exists.
This maps directly to what Addy Osmani describes in his agent skills framework: skills are the reusable workflow chunks that get progressively disclosed into the system prompt. The skill crystallised from H5 is exactly this — a compact, tested behavioural specification that can be loaded on demand.
H7 Through H9: The Complexity Plateau
Model routing (H7), HITL confidence gating (H8), and sub-agent specialisation (H9) all clustered around 0.815 to 0.840. They added significant latency and token cost without improving quality beyond H5.
H7 is particularly instructive.
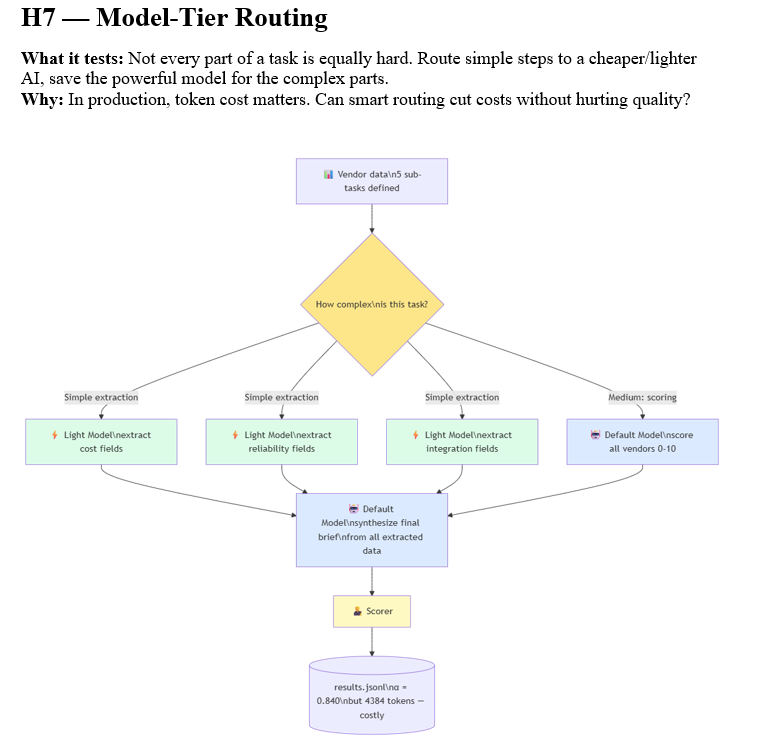
The theory was that routing cheap extraction tasks to a lighter model would reduce token costs while maintaining quality.
In practice, the routing overhead — orchestration calls, context passed between model tiers — outweighed the savings. Total tokens (4,384) nearly tripled compared to H2 (1,556) for a lower quality score. Model routing only wins on cost when cheap tasks are large in volume, not merely low in complexity.
H10: The Meta-Harness Failure (0.230)
H10 ran 20 mixed tasks through a type-aware routing system (EVALUATE, EXTRACT, RESEARCH, GENERATE, COMPRESS), then ran the same 20 tasks through a single generalist configuration for comparison. The meta-harness scored 0.230. The generalist scored 0.473. The sophisticated routing system was outperformed by a single config by 0.243 points.
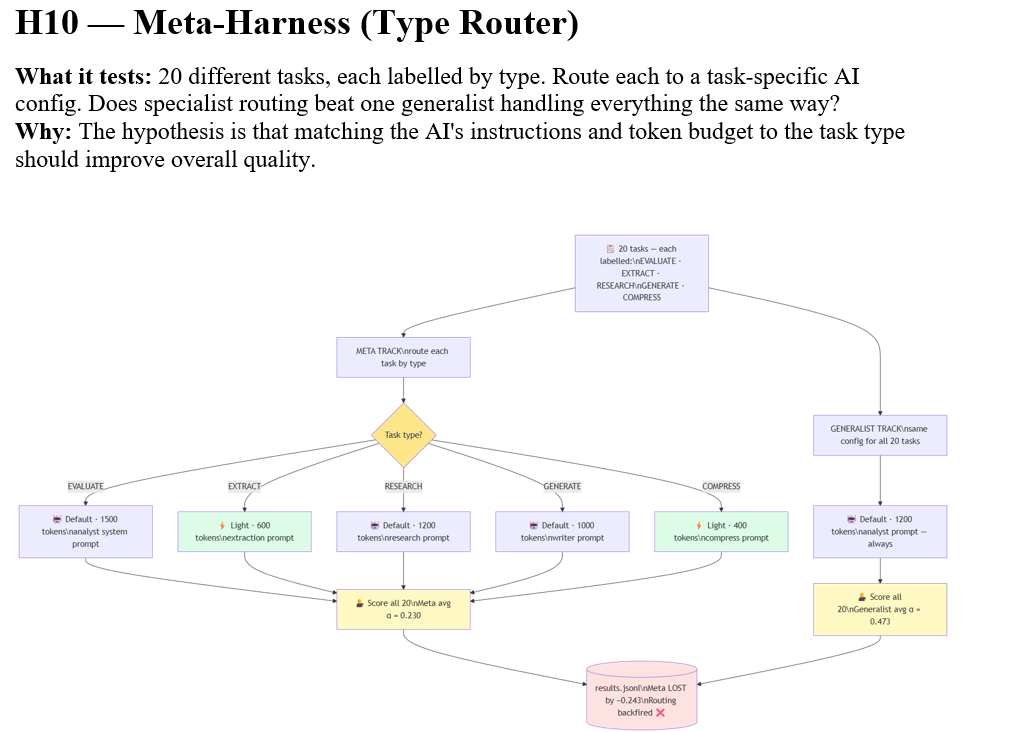
The immediate cause was a mismatch between the routing table’s max_tokens settings and the rubric’s expectations. EXTRACT and COMPRESS tasks were given 400-600 tokens, which produced thin outputs that the rubric — calibrated for detailed vendor analysis — scored at zero. But the root cause was more fundamental: the routing table was designed for one task type and applied to five. The meta-harness amplified the mismatch rather than correcting for it.
This is the H10 lesson that applies most broadly: adaptive routing without per-type calibration produces worse results than a well-tuned generalist. The architecture was correct in principle. The implementation lacked the rubric alignment that would make it function.
What to Take Forward
For harness design generally: The data supports a simple hierarchy. Get behavioral specification right first — that is H2. Only add mechanism when you have a specific failure mode that mechanism addresses. Tools for external state. Parallelism for genuine independence. Evaluation loops for tasks where the acceptance criterion is not fully specifiable upfront. Sub-agents for tasks that require domain specialization the orchestrator cannot hold in one context.
For the H10 failure specifically: If you want to rerun it properly, the fix is not a better routing table — it is separate rubrics per task type. EXTRACT tasks should score on precision and completeness of extracted fields, not on recommendation quality. COMPRESS tasks should score on information density and accuracy of reduction. Running the existing rubric against EXTRACT/COMPRESS output is category error scoring.
For research purposes: This experiment produced a clean, citable empirical result — that prompt engineering at H2 quality outperforms multi-agent architectures on single-context reasoning tasks, and that complexity additions carry measurable quality penalties rather than gains until the task architecture genuinely requires them. That finding directly supports my reframe analysis: capability and deployment strategy are different optimization targets. Here, reasoning capability and agentic architecture are different optimization targets, and conflating them produces worse outcomes than addressing each on its own terms.
The ASCRS case study would show the inverse pattern — where the task genuinely requires parallelism (multiple concurrent supply chain checks), external tool state (live logistics APIs), and iterative evaluation (threshold-based rerouting decisions), and where H4/H5/H9 architectures would outperform H2 because the task structure matches the harness structure. That contrast — same harness stack, different task profile, inverted performance ranking — is the analytically interesting piece.
The Architecture: How Claude Code Fits In
To understand what these findings mean in context, it helps to understand the stack these experiments ran on — and what I believe Addy Osmani means when he calls Claude Code a HaaS runtime.
┌─────────────────────────────────────────────────────────────┐
│ Claude Code (HaaS Runtime) │ ← Outer Harness-as-a-Service
│ • ReAct / Agent Loop │
│ • Tool Registry + Permission Gates │
│ • Context Assembly + Compaction │
│ • 3-Layer Memory System (in-context + MEMORY.md + files) │
│ • Sub-agent / Swarm Orchestration │
│ • Safety, Hooks, Streaming, Sandboxes │
│ • Persistent Filesystem + Execution Environment │
└──────────────────────────────▲──────────────────────────────┘
│ (Configure + Extend)
│
┌──────────────────────────────┴──────────────────────────────┐
│ Pre-Experiment Harness (Lab OS / Foundation) │ ← Standardized Configuration Surface
│ • shared/client.js (model routing) │
│ • shared/scorer.js + rubric system │
│ • shared/self_heal.js + logger │
│ • Root CLAUDE.md (constitution + lab-wide rules) │
│ • Memory conventions + task templates │
│ • Observability & results pipeline │
│ • Common tools & utilities │
└──────────────────────────────▲──────────────────────────────┘
│ (Swappable)
│
┌──────────────────────────────┴──────────────────────────────┐
│ Experiment Harness Layer (H1–H10) │ ← Domain-Specific Scaffolding
│ │
│ H1: Prompt + Constitution │
│ H2: Reflection + Self-Critique Loop │
│ H3: Sequential Tool-Use │
│ H4: Parallel Fan-Out + Merge │
│ H5: Eval + Revision Loop │
│ H6: Skill / Memory Crystallization │
│ H7: Model Routing / Tiered │
│ H8: HITL + Confidence Gating │
│ H9: Sub-Agent Swarm │
│ H10: Meta-Router / Adaptive │
└──────────────────────────────▲──────────────────────────────┘
│
┌──────────────────────────────┴──────────────────────────────┐
│ Core Model │
│ gpt-oss-120b / Claude Sonnet etc. │
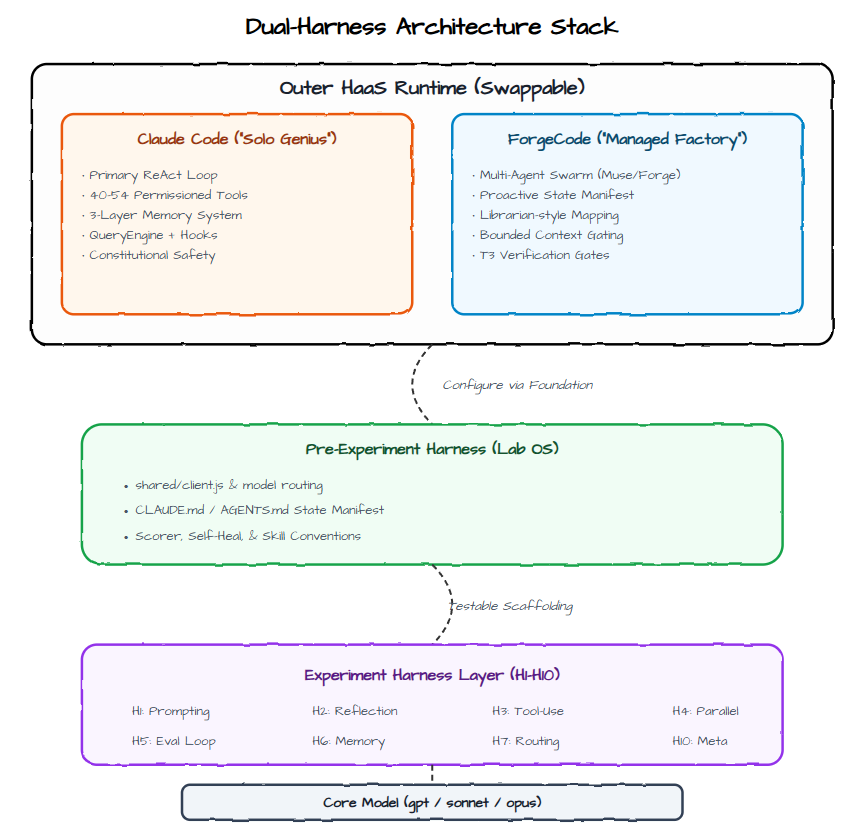
└─────────────────────────────────────────────────────────────┘Harness-as-a-Service is a framing that distinguishes between the platform you use and the configuration you build on top of it. Claude Code is the platform. It provides the execution loop, the tool registry, the memory system, the safety gates, and the context management machinery. You do not build those things. You configure them — through CLAUDE.md files, through tool definitions, through the structure of your prompts and the organisation of your files.

Table 2. The four-layer HaaS architecture. Each layer has a single, non-overlapping responsibility.
The March 2026 Claude Code source leak — when a debugging artifact was accidentally included in an npm release, exposing the internal architecture — confirmed what practitioners had suspected: Claude Code is a sophisticated single-primary-loop agent with approximately 40-54 permission-gated tools, a three-layer memory system (in-context state, a MEMORY.md index file, and a background daemon), and a QueryEngine for large-context retrieval. It is not a simple chatbot with file access. It is a production-grade agentic runtime.
Boris Cherny, the engineer who created Claude Code, describes his vision in terms that connect to this experiment’s findings. He imagines a world where anyone can build software — where the mechanical translation between intent and implementation can be delegated to an AI agent, much as the printing press delegated the mechanical reproduction of text. The constraint is not model capability. It is the clarity of the specification.
“I imagine a world where everyone is able to program. Anyone can just build software anytime.” — Boris Cherny, Anthropic
This is precisely what H2 demonstrated at the experiment scale. The bare model (H1) had all the capability needed to complete the task correctly. What it lacked was clear specification. Forty additional tokens of role, weights, and output schema lifted quality from 0.665 to 0.920. The bottleneck was never intelligence. It was instruction.
Thoughts on Claude Code, ForgeCode and the Alternative Agent Harness Architecture
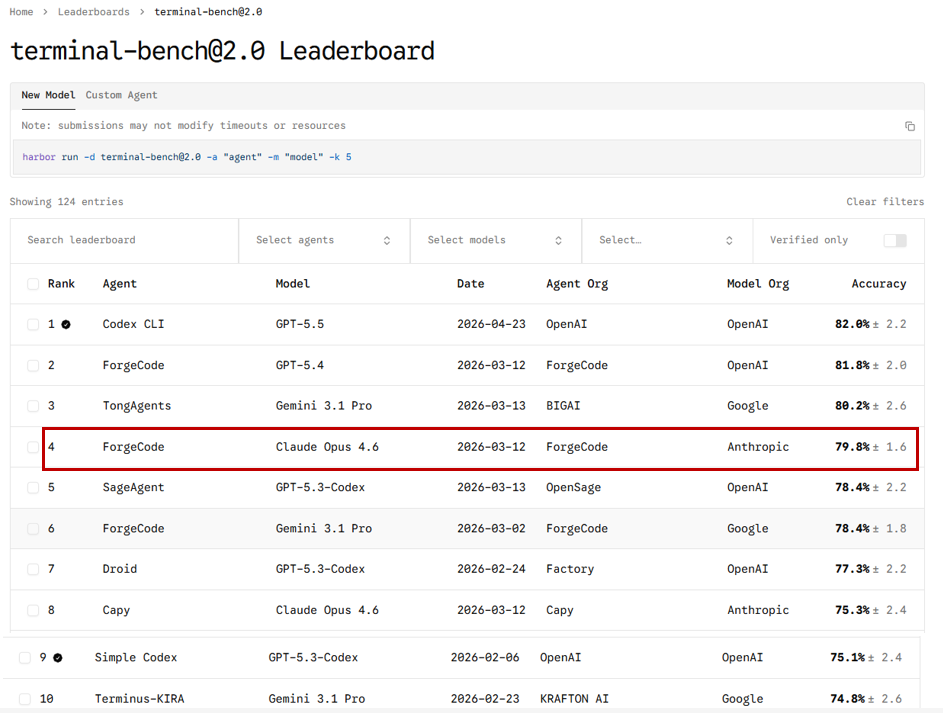
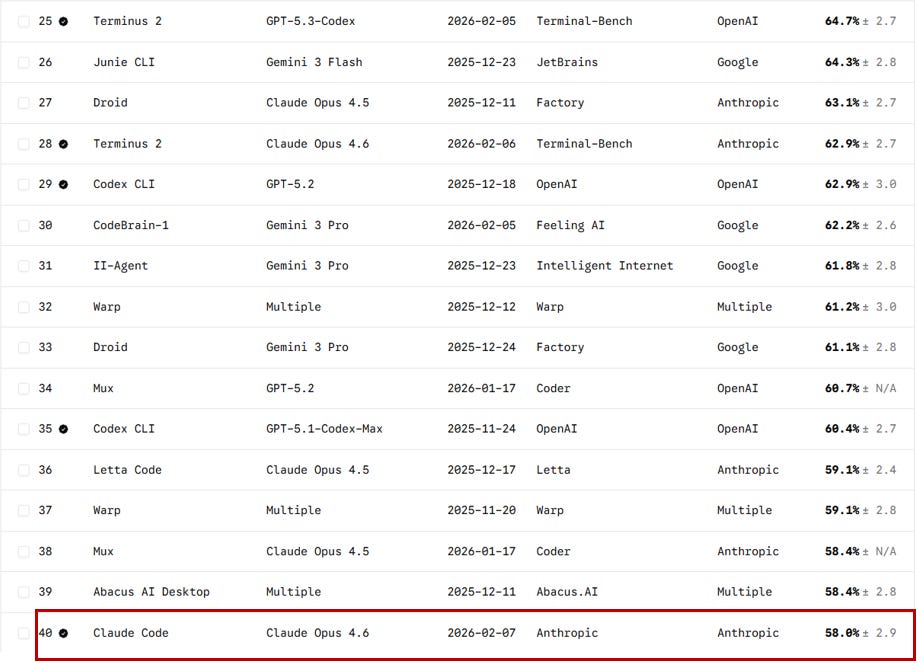
I also started looking into Terminal Bench 2.0 and note how different Agent Harnesses affect model outcome:
Separately On X:
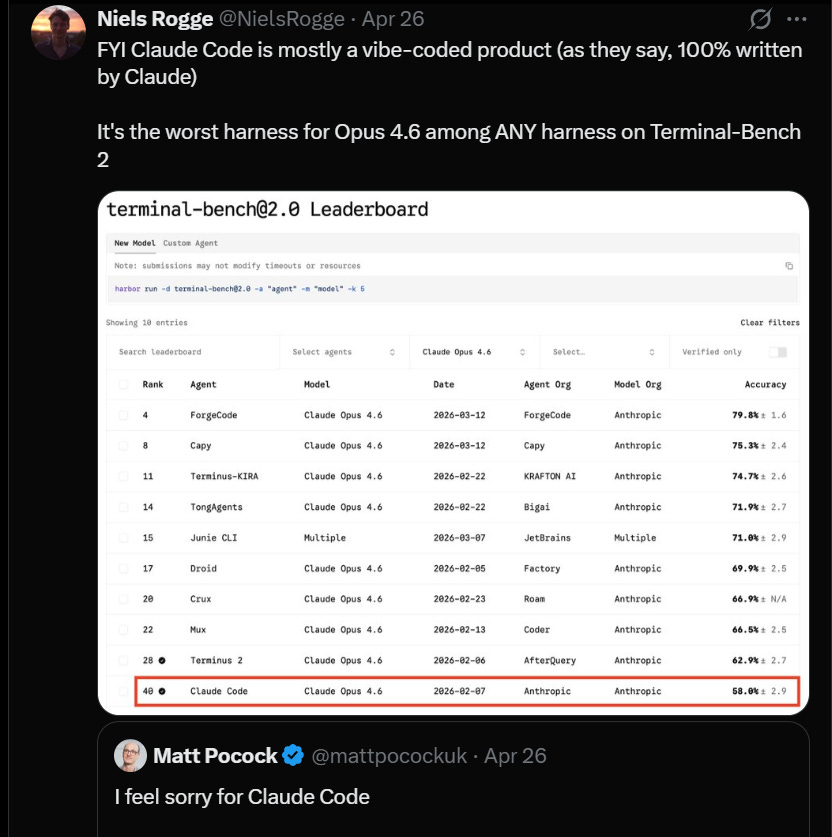
A useful contrast between Claude Code’s architecture — I describe as a Solo Genius, reactive and deep — and ForgeCode’s Multi-Agent Factory architecture, which uses specialised roles (Muse for planning, Forge for execution, Sage for review) with proactive state mapping, bounded context, and T3 verification gates.
This contrast maps precisely onto the experiment’s H4 failure. ForgeCode’s Sage role is a designated reviewer that checks sub-agent outputs for consistency before they are merged. A naive parallel fan-out, which is what H4 implemented, has no equivalent. The coherence collapse in H4 would not have occurred — or would have been caught before scoring — in a properly implemented specialised-role architecture.
The Terminal-Bench 2.0 data makes this concrete. Claude Opus 4.6 running in Claude Code scores 58.0%. The same model running in ForgeCode scores 79.8% — a 21.8-point improvement from harness architecture alone. One team moved a coding agent from the top forty to the top five by changing only the harness. The model was identical. The instructions around it were not.
The key insight from Osmani’s harness engineering framework: every component in a good harness should be traceable to a specific failure you observed. You do not add a verification gate because verification gates are fashionable. You add one because you watched a model declare a task complete when it was not. ForgeCode’s Sage exists because parallel coherence failures are a documented failure mode in multi-agent systems. H4 demonstrated exactly that failure mode without a Sage to catch it.
I could hypothetically update and refine the full stack, incorporating the key differences between Claude Code (Flat/Reactive Loop) and ForgeCode (Governed/Multi-Agent Factory) while staying true to Addy Osmani’s Harness-as-a-Service philosophy.
Refined High-Level Stack (HaaS-Aligned)
┌─────────────────────────────────────────────────────────────┐
│ Outer HaaS Runtime (Choose One) │ ← Platform Layer
│ │
│ • Claude Code: Flat ReAct Loop + Memory.md │
│ → "Solo Genius" — Fast, reactive, high reasoning │
│ → Strong on deep context but higher invocation errors │
│ OR │
│ • ForgeCode: Multi-Agent Swarm (Manager + Librarian + │
│ Worker + Critic / Muse + Forge + Sage) │
│ → "Managed Factory" — Proactive mapping, T3 verification│
│ → Higher reliability & lower execution errors │
└──────────────────────────────▲──────────────────────────────┘
│ (Configure & Extend)
│
┌──────────────────────────────┴──────────────────────────────┐
│ Pre-Experiment Harness (Lab OS / Foundation) ← Standardized Configuration Surface
│ • shared/client.js (model + provider routing) │
│ • Root CLAUDE.md + AGENTS.md style constitution │
│ • Scorer, Self-Heal, Logger, Memory conventions │
│ • Task templates + multi-task support │
│ • State Manifest / Pre-mapping utilities ← Especially powerful with ForgeCode
└──────────────────────────────▲──────────────────────────────┘
│ (Swappable Scaffolding)
│
┌──────────────────────────────┴──────────────────────────────┐
│ Experiment Harness Layer (H1–H10) ← Testable Domain-Specific Patterns
│ │
│ H1: Prompt + Constitution H2: Reflection Loop │
│ H3: Sequential Tools H4: Parallel + Merge │
│ H5: Eval + Revision H6: Skill Crystallization│
│ H7: Model Routing H8: HITL Gating │
│ H9: Sub-Agent Swarm H10: Meta-Router │
└──────────────────────────────▲──────────────────────────────┘
│
┌──────────────────────────────┴──────────────────────────────┐
│ Core Model │
│ gpt-oss-120b, Claude Sonnet/Opus, etc. │
└─────────────────────────────────────────────────────────────┘Key Insights from the Redesign
Outer Layer is now explicitly swappable — You can run the exact same middle layers (Pre-Experiment + Experiments) on top of either Claude Code or ForgeCode. This makes your lab a true harness comparison platform.
ForgeCode’s strengths (Librarian-style pre-mapping, multi-agent specialization, strong verification gates) are reflected by enhancing the Pre-Experiment Harness with better state manifests and tool registries. This turns the “Dark Room” problem into a “Mapped Lab.”
Claude Code’s strengths (strong single-agent reasoning) pair beautifully with simpler Experiment Harnesses like H1 and H2.
The Experiment Layer remains the fungible testing ground. You can now compare how the same H9 (Sub-Agent Swarm) performs differently when the outer runtime is Claude Code vs ForgeCode.
Pre-Experiment Harness gains a State Manifest component — this is inspired by ForgeCode’s proactive environment mapping and makes the whole stack more robust regardless of which outer harness you use.
What This Means: The Deeper Pattern
The lift table tells a story. But the story worth telling is not which harness scored highest — it is what the pattern of results reveals about where AI systems actually fail, and what actually fixes them.
The Specification Problem Is the Problem
H1 to H2 is the biggest single quality jump in the entire experiment: 0.665 to 0.920, a gain of 0.255 points. Every subsequent experiment, including ones that added substantially more architectural complexity, failed to produce a comparable improvement. The prompt harness is the most efficient intervention in the stack.
This is not a finding unique to this experiment. Osmani documents it in his LLM coding workflow:
The biggest lever in AI-assisted work is not the model choice or the architecture choice — it is the quality of the specification. Vague instructions produce vague results. Precise instructions produce precise results. This is obvious in principle and systematically ignored in practice, because adding architectural complexity feels like doing something while improving a specification feels like writing documentation.
Complexity Has a Cost That Is Rarely Measured
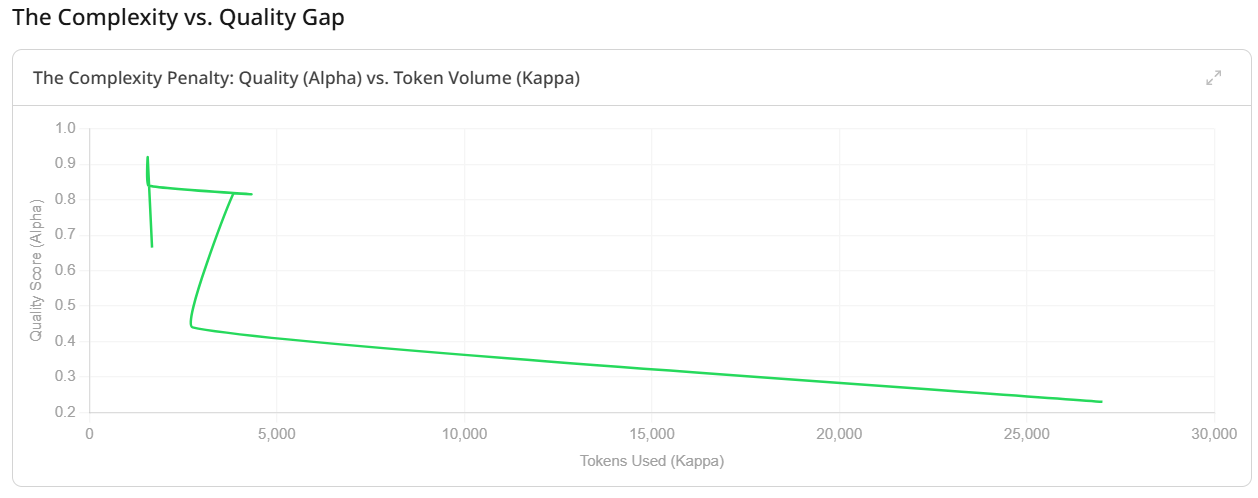
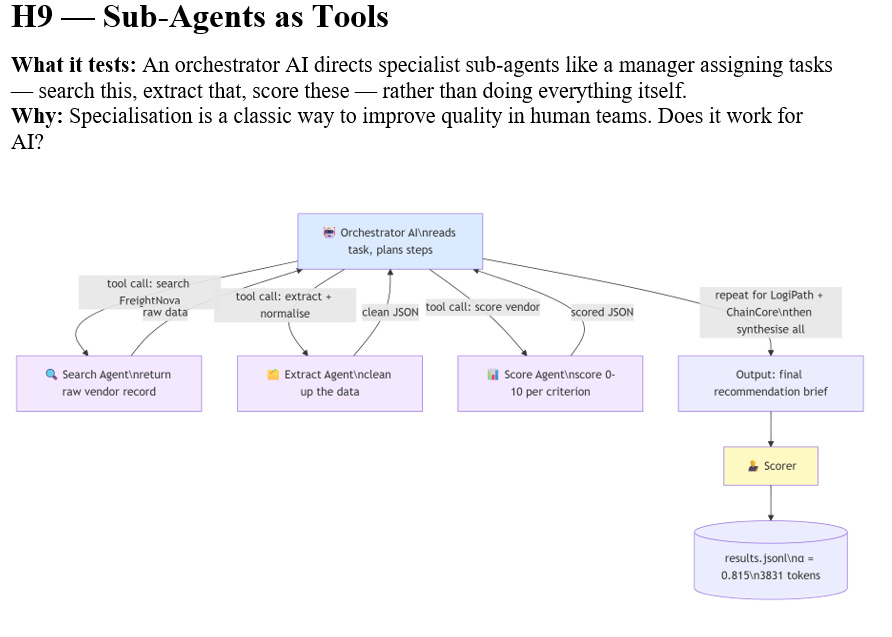
The results table shows total token counts alongside quality scores. This is not just a cost metric. Tokens are a proxy for how much cognitive overhead the architecture imposes. H9 (sub-agent swarm) consumed 3,831 tokens to score 0.815. H2 consumed 1,556 tokens to score 0.920. The swarm was 2.5 times more expensive and produced worse results.
What those additional tokens represent is coordination overhead — the messages between orchestrator and sub-agents, the context that must be rebuilt at each handoff, the tool call scaffolding that wraps each action. This is the cost of complexity, and it is rarely included in the analysis when multi-agent architectures are proposed.
Osmani’s framing of context rot is relevant here: model performance degrades as the context window fills, well before the hard limit. A long, complex multi-agent session is not just more expensive than a short, focused single-agent session — it may be actively worse, because the model at turn 40 is operating with degraded coherence compared to the model at turn 5.
The Task Has to Match the Architecture
This is the qualification that prevents the experiment from being misread as an argument against multi-agent systems generally. The vendor evaluation task is fundamentally a single-context reasoning problem. All the information needed to solve it is available at the start. There are no external systems to query, no genuinely parallel workstreams, no acceptance criterion that cannot be specified upfront.
Multi-agent architectures exist because some tasks genuinely require them: long-horizon software projects where different specialists own different layers; research tasks that require simultaneous querying of multiple external sources; production systems that need continuous monitoring and autonomous response. These tasks have structures that map to multi-agent architectures.
The vendor evaluation task does not. Deploying a sub-agent swarm on it is like hiring a project management team to write a one-page memo. The overhead is real. The memo is not better for it.
“The right harness for your codebase is shaped by your failure history. You cannot download it.” — Addy Osmani
The H10 failure makes this concrete. Routing 20 mixed tasks to type-specific configurations was correct in architectural principle. It failed because the rubric was not calibrated per type. An EXTRACT task should be judged on precision and completeness of extracted fields. A COMPRESS task should be judged on information density and accuracy of reduction. Running them both through an evaluation rubric designed for detailed analytical reasoning was category error scoring. The architecture was not wrong. The measurement harness was wrong.
This was my directory structure:
harness-lab/
├── IMPLEMENTATION_GUIDE.md
├── CLAUDE.md # Root constitution
├── package.json
├── .env.example
├── .env
├── .gitignore
│
├── shared/ # Pre-Experiment Harness (Lab OS)
│ ├── client.js
│ ├── task.md # Default task (vendor selection)
│ ├── tasks/ # Multi-task support
│ ├── rubric.json
│ ├── gold_answer.md
│ ├── scorer.js
│ ├── self_heal.js
│ ├── logger.js
│ ├── memory/ # Crystallized skills
│ └── tools/
│
├── experiments/
│ ├── pre-experiment/ # Foundation test
│ ├── h1-prompt-constitution/
│ ├── h2-reflection-loop/
│ ├── h3-sequential-tools/
│ ├── h4-parallel-merge/
│ ├── h5-eval-revision/
│ ├── h6-skill-memory/
│ ├── h7-model-routing/
│ ├── h8-hitl-gating/
│ ├── h9-subagent-swarm/
│ └── h10-meta-router/
│
├── results/
│ └── results.jsonl
│
└── scripts/
├── run_all.js
└── compare.jsWhat Changes With Better Models
There is an important caveat to the experiment’s findings: model capability interacts with harness design in ways that shift with each new model generation.
This experiment ran on gpt-oss-120b. A frontier model might handle H4’s coherence problem better — not because parallelism is inherently coherent, but because a stronger model might infer the need for consistent scoring scales without being told.
This is the trajectory Boris Cherny describes when he talks about coding being largely solved. As models improve, some harness components that exist to compensate for model limitations become redundant. The history of software is full of abstractions that existed to manage hardware constraints that eventually became cheap — the constraints disappeared and the abstractions were abandoned.
But the specification problem is not a model limitation problem. It is a human communication problem. A model can only do what it is asked to do. The precision with which you articulate what you want does not become less important as models become more capable — it may become more important, because more capable models execute imprecise specifications more confidently and at greater scale.
Running the Experiment
For me, the Harness Lab project is designed to be reproduced. The full implementation guide — which served as the specification Claude Code read to build the project — is approximately 2,300 lines of structured Markdown covering every file in the project. Claude Code built the entire thing from that document in under ten minutes.
The practical setup: VS Code, the Claude Code extension, and an OpenRouter API key.
One practical note on model selection: using the same model as both the experiment model and the scorer model produces inflated scores, because models tend to grade their own outputs generously. Setting a different model as scorer — or using a model from a different provider — produces more discriminating evaluations.
The bootstrap process is a single prompt to Claude Code:

Claude Code then builds the entire project autonomously, creating over 30 files across the directory structure. Each experiment subsequently runs as a single npm command: npm run h1 through npm run h10. The compare script prints the full lift table after all experiments complete.
Conclusions: What the Numbers Say
The lift table for this experiment tells a story in numbers. The story in words is this:
– Instruction quality is the highest-leverage variable in AI system performance, and it costs almost nothing relative to architectural complexity.
– Multi-agent architectures add value when the task genuinely requires parallelism, external state, or specialised domain knowledge that cannot be held in one context. They add overhead, coherence risk, and cost when the task does not.
– Evaluation design is inseparable from system design. A rubric that cannot detect quality differences makes every architecture look equivalent. The first version of this experiment’s rubric produced exactly that false equivalence.
– Skill crystallisation works. A prompt optimised through an eval loop and saved as a skill file transferred cleanly to new data. This is the practical mechanism behind Osmani’s agent skills framework.
– Adaptive routing requires per-type calibration throughout the entire stack, including the evaluation rubric. A routing table without rubric alignment will amplify mismatches rather than correct for them.
None of these findings are arguments against building sophisticated AI systems. They are arguments for building the right system for the task, measuring the outcome honestly, and being honest about what the complexity is actually buying you.
Boris Cherny’s vision is one where everyone can build software — where the barrier is not technical skill but clear communication of what you want. The experiment confirms this from the other direction: when the communication is clear, the architecture becomes almost irrelevant. When the communication is unclear, no architecture compensates for it.
The harness is not the intelligence. The harness is the frame around the intelligence. And a frame that does not fit the picture makes the picture worse, not better.
POST-NOTE: Would /goal Have Changed the Results?
On Ralph Loop 2.0, Persistent Goals, and What Automated Continuation Actually Fixes
Since this article was completed, /goal has shipped as a first-class feature in both Codex CLI and Hermes Agent (Nous Research’s independent implementation). Both teams describe it as their take on the Ralph Loop — a pattern named after a fictional agent who simply keeps working until the job is done. The 2.0 designation distinguishes it from the original concept by adding a structural element: a separate judge model that evaluates after every turn whether the goal has been achieved, rather than relying on the agent to decide when to stop.
After every turn, Hermes calls an auxiliary model with the standing goal text, the agent’s most recent final response, and a system prompt telling the judge to reply with strict JSON: {"done": bool, "reason": "one-sentence rationale"}. The judge is deliberately conservative — it marks a goal done only when the response explicitly confirms completion, when the final deliverable is clearly produced, or when the goal is unachievable. If the judge errors for any reason, Hermes treats the verdict as continue rather than stop, so a broken judge never wedges progress. The turn budget is the real backstop, defaulting to 20 continuation turns. Substack
The question for this experiment is specific: would /goal have moved the needle on the results that mattered?
Where it would have directly helped:
H5 (Eval Loop, 0.840). H5 manually implemented a generate-score-revise loop capped at three generations. /goal would have done this automatically and without the artificial ceiling. You would set the goal as “produce a vendor evaluation that scores above 0.70 on all rubric criteria” and the judge would keep iterating until that threshold was met or the turn budget was exhausted. Crucially, the judge is a separate model from the experiment model — structurally identical to the scorer-as-judge pattern the experiment already used, but now embedded in the loop rather than bolted on externally. H5’s manual N=3 cap was arbitrary; /goal removes that arbitrariness.
H10 (Meta-harness, 0.230). The meta-harness declared completion on EXTRACT and COMPRESS tasks that scored zero because they were being judged by the wrong rubric. A /goal judge set to “all 20 tasks must produce a non-zero score” would have caught those failures before the session closed, flagged the zero-scoring task types, and continued working. Whether the continuation would have fixed the underlying rubric mismatch is a separate question — but it would at minimum have prevented premature declaration of completion on demonstrably incomplete work.
The weak verification failure class (~15% of Terminal-Bench failures). The /goal judge is, architecturally, an automated verification gate. It is the same structural intervention as H8’s HITL checkpoint but with an auxiliary model playing the reviewer role rather than a simulated human pass. Every experiment that scored poorly on the rubric’s “confidence calibration” criterion — agents declaring high confidence on thin outputs — would have been extended rather than closed.
Where it would not have helped:
H4 (Parallel fan-out, 0.440). The coherence collapse in H4 was not a stopping problem. Three agents calibrated their 0-10 scoring scales independently and the inconsistency was baked in before any output was produced. A /goal judge running after the merge would have caught the low score and continued — but continuation here means asking the same incoherent merge to try again, not fixing the underlying calibration problem. The fix for H4 is architectural: a verification gate between fan-out and merge (ForgeCode’s Sage role), not a persistence mechanism after the fact.
H1 (Bare model, 0.665). The bare model did not fail because it stopped too early. It failed because it had no specification. /goal would have kept it working longer toward a goal it lacked the instructions to meet. More turns of a poorly specified task produces more poorly specified output, not better output. This is the same principle that explains why the experiment found no correlation between episode count and success rate in Terminal-Bench: persistence cannot substitute for specification.
H2 (Prompt harness, 0.920 — the winner). H2 already reached its quality ceiling in a single turn. A persistence mechanism adds nothing to a task that is already solved on the first attempt.
The architectural insight:
/goal is described by Hermes as tasks where “you’d otherwise have to say ‘keep going’ three times.” That framing is precise and useful. It targets the session persistence problem — the gap between what a model can accomplish in a single turn and what it can accomplish if allowed to iterate toward a stated objective. What it does not target is the specification problem (H1 and H2), the coherence problem (H4), or the rubric calibration problem (H10’s real failure). Substack
The distinction maps onto two different categories of harness failure that the experiment separated empirically: failures of continuation (the agent stopped before the goal was reached) and failures of specification (the agent never had a clear enough goal to reach). Ralph Loop 2.0 is a structural solution to the first category. It does not address the second. The experiment’s most important finding — that H2’s clear instruction outperformed every architecture including H9’s sub-agent swarm — belongs entirely to the specification category that /goal does not touch.
That said, combining /goal with H5’s eval loop would produce something meaningfully more powerful than either alone: a persistent goal with an automated judge that also revises the approach, not just continues the attempt. That combination — goal persistence plus approach revision — is the architecture the experiment was approximating manually in H5. It would be the correct H11 if the experiment were extended.
Hermes Agent /goal documentation: hermes-agent.nousresearch.com/docs/user-guide/features/goals — Codex CLI /goal (Eric Traut, OpenAI): github.com/openai/codex
References and Further Reading
The following sources informed this analysis:
Harness Engineering & HaaS
Addy Osmani — Agent Harness Engineering: addyosmani.com/blog/agent-harness-engineering
Addy Osmani — Long-running Agents: addyo.substack.com/p/long-running-agents
Addy Osmani — Agent Skills: addyosmani.com/blog/agent-skills
Addy Osmani — Future of Agentic Coding (Conductors to Orchestrators): addyosmani.com/blog/future-agentic-coding
Martin Fowler / Birgitta Böckeler — Agent Harness Engineering (ThoughtWorks): martinfowler.com/articles/agent-harness
Complete Claude Code Harness Engineering Guide (5 Layers): dev.to/shipwithaiio/harness-engineering-guide
Boris Cherny & Claude Code
Boris Cherny at AI Ascent 2026 — Why Coding Is Solved, and What Comes Next: youtube.com/watch?v=SlGRN8jh2RI
The Claude Code Handbook (freeCodeCamp): freecodecamp.org/news/claude-code-handbook
8 Insights from Boris Cherny (Waydev): waydev.co/boris-cherny-insights
Great Claude Code Leak of March 2026 — Denser.ai deep-dive: denser.ai/blog/claude-code-leak
Terminal-Bench & Benchmark Research
Terminal-Bench 2.0 — Benchmarking Agents on Hard, Realistic Tasks (arXiv): arxiv.org/abs/2601.11868
Terminal-Bench Leaderboard: tbench.ai/leaderboard/terminal-bench/2.0
Agentic Engineering Context
From Vibe Coding to Agentic Engineering: dev.to/jasonguo/agentic-engineering
OpenRouter Free Models: openrouter.ai/collections/free-models
Key arXiv / Research Papers
Towards a Science of Scaling Agent Systems (Google DeepMind + collaborators, Dec 2025)
Link: https://arxiv.org/html/2512.08296v1
Relevance: The strongest and most cited empirical study. Tested 180+ configurations across models and benchmarks. Overall, MAS showed -3.5% mean performance vs single agents. Multi-agent hurt sequential planning by 39–70%, with massive error amplification (up to 17.2× in independent swarms). Coordination overhead dominated on tool-heavy or high baseline tasks. Strong support for “simple when possible.”Single-agent or Multi-agent Systems? Why Not Both? (May 2025)
Link: https://arxiv.org/html/2505.18286v1
Relevance: MAS incurs 4–220× more tokens and significantly higher latency/cost. Even with strong models, the coordination overhead often negates benefits. Includes failure examples (e.g., debate-style agents reinforcing wrong answers).Why Your Multi-Agent System is Failing: Escaping the 17x Error Trap (Jan 2026)
Link: https://towardsdatascience.com/why-your-multi-agent-system-is-failing-escaping-the-17x-error-trap-of-the-bag-of-agents/Published: January 30, 2026 (Towards Data Science)Relevance: Directly calls out the “bag of agents” problem — unstructured multi-agent setups amplify errors dramatically without proper topology. Emphasizes that coordination costs often outweigh decomposition benefits.