
The Inference Revolution: How China's Open-Source and Domestic Hardware Ecosystem Could Reshape Global AI
China's global AI deployment via the Digital Silk Road (DSR), a key component of its overarching Belt and Road Initiative (BRI) and Why "Good Enough" may be Good Enough for Global Inference Dominance

It is not the strongest of the species that survives, not the most intelligent that survives.
It is the one that is the most adaptable to change.
~ Charles Darwin
This is written as part of a Two-Part Series. Part II can be found here - “The Great Decoupling.”
Whilst I enjoy seeing balanced views, I especially relish opinions on evolving technologies, or integrated stacks. We are the wiser because of amazingly excellent views (and opinions); more so if these diverge (in various directions). The chat, language, multi-modal, agentic, world model space continutes to brim with transparent sharing - and policy papers, reflecting (sometimes) various country’s endevours, and hopeful paths towards “global domination”. It is not only an exciting space, but deemed by many to be the “holy grail” in value creation. The Ultimate Prize.
But I find something missing. So I shall add my opinion, a slightly different tangent, in this multi-dimensional, rich, latent space. I reference the wonderful views and analysis, recently released here, with kind thanks for the sharing:
The Power Law’s “Z.ai and Huawei aren't defeating US export controls”
The Wall Street Journal’s “China’s Z.ai and America’s Self-Defeating AI Strategy”
Kyle Chan and Ray Wang’s “A Smarter Strategy for AI Chip Export Controls to China”
Chris Miller’s “How US Export Controls Have (and Haven't) Curbed Chinese AI”
Epoch Ai’s “Why China isn’t about to leap ahead of the West on compute”
CNAS’s Analysis on, “Countering AI Chip Smuggling Has Become a National Security Priority”
And this very useful chart, referenced so very many times in the various articles above:
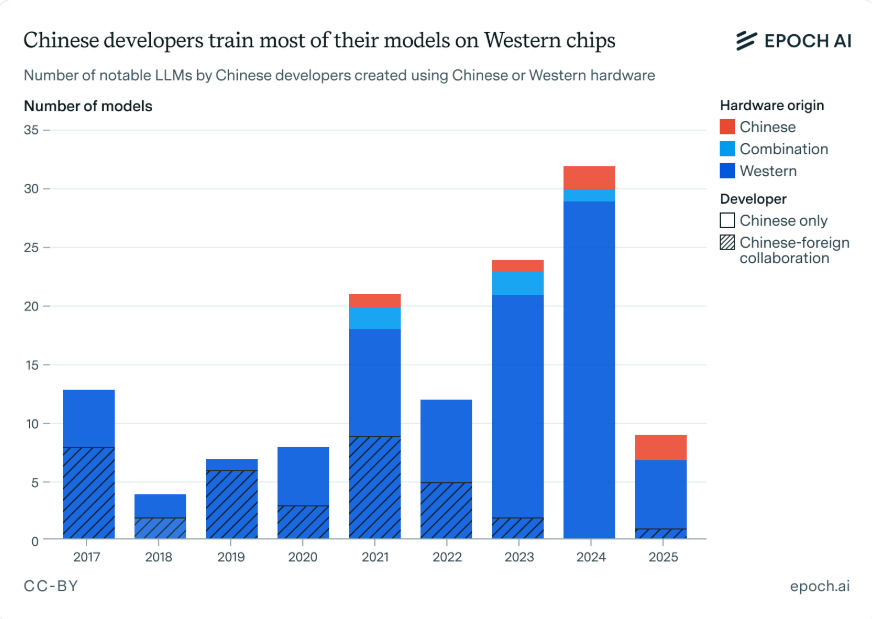
Boo-hoo China? Not so fast. Perhaps we’re not looking deep enough. We forget how China knows how to play the very patient, very long-game, in very exciting engineering and technical industries or spaces (witness: Drones, Shipping, Logistics etc).

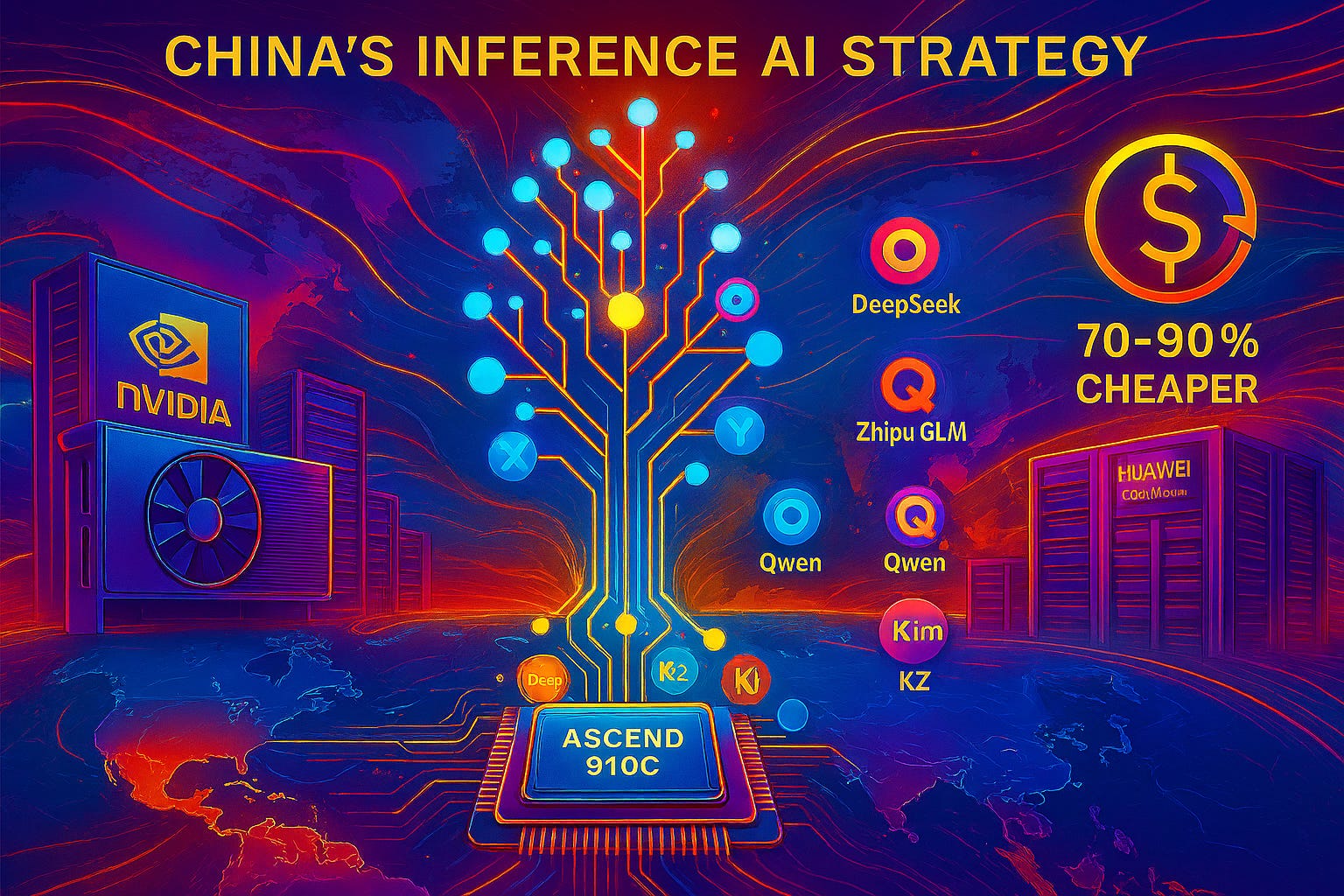
While the global artificial intelligence (AI) discourse remains fixated on training infrastructure and the latest GPU generations, I believe China is quietly executing a parallel strategy that could fundamentally reshape the global AI landscape. Rather than competing directly with United States dominance in cutting-edge training hardware, Chinese companies are pioneering a different path to global AI supremacy: combining world-leading open-source models with domestically produced inference chips to create a scalable, cost-effective deployment ecosystem that could capture the majority of global AI usage.
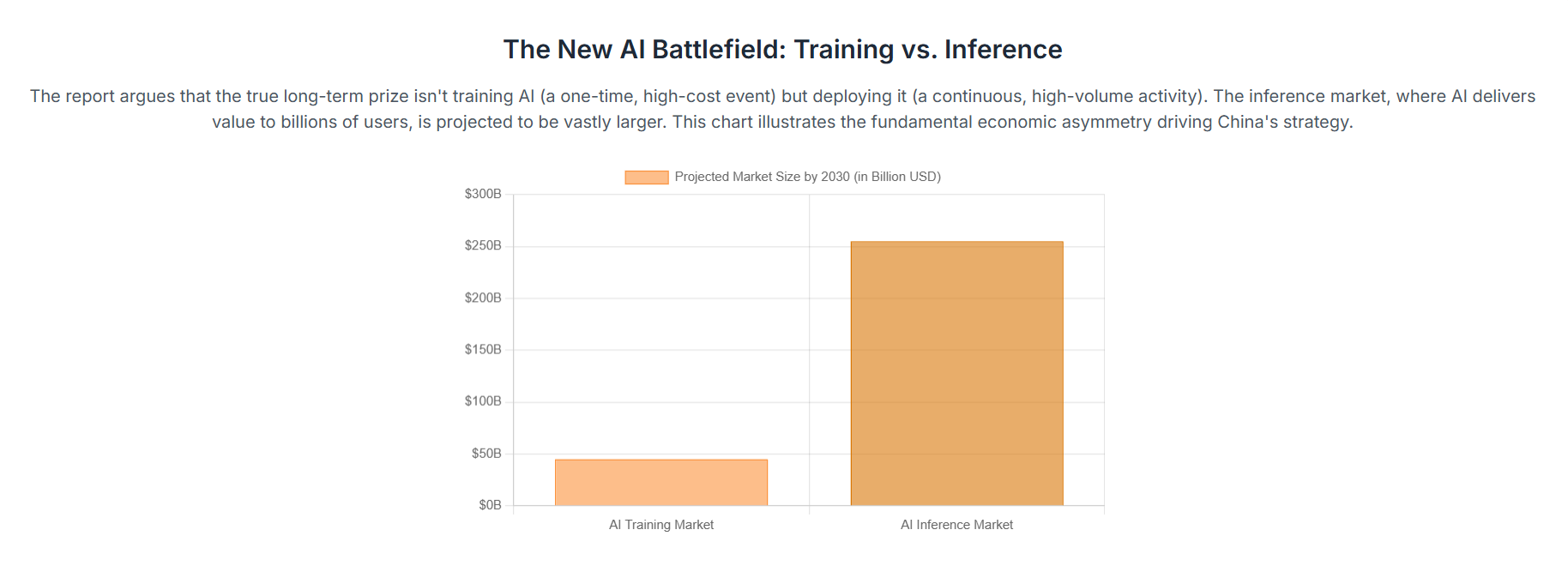
This strategy represents a profound strategic direction: in the long term, global AI dominance will be determined not by who can train the most powerful models, but by who can deploy AI capabilities most efficiently, affordably, and at the largest scale. The market data is unequivocal: the AI inference market is projected to reach approximately $255 billion by 2030, dwarfing the training market.1
While the United States maintains its lead in frontier model training through advanced Nvidia hardware, China is positioning itself to control this far larger inference market through superior open-source models optimized for its domestic chip ecosystem. Chinese models from firms like DeepSeek, Zhipu AI, and Moonshot now lead global open-source benchmarks while offering their services at prices reportedly 70-90% below comparable US offerings.2
The implications are staggering. If successful, this approach could allow China to bypass US export controls entirely, create technological dependency among developing nations through initiatives like the Digital Silk Road, and establish Chinese AI infrastructure as the de facto global standard—all while the US focuses on maintaining its training advantage for a relatively small number of frontier models. I hope to somewhat exhaustively (if that is even possible) analyze China's inference-centric strategy, its technical underpinnings, its geopolitical objectives, and the strategic blind spots in the current US response.
The New AI Battlefield: Quantifying the Training vs. Inference Paradigm
The prevailing narrative of the AI competition has been dominated by a training-centric worldview: the entity capable of building the most powerful models using the most advanced hardware wins the AI race. This perspective explains the intense global focus on Nvidia's latest GPUs, the multi-billion-dollar investments in massive training clusters, and the strategic importance of cutting-edge semiconductor fabrication.4 However, this narrative fundamentally misunderstands the economics of how AI will be consumed globally and overlooks the critical distinction between the creation of AI and its application. China's emerging strategy is built upon a clear-eyed assessment of this distinction, exploiting a fundamental asymmetry between the AI training and inference markets.
The Fundamental Asymmetry: From One-Time Cost to Continuous Value
AI model development consists of two distinct phases: training and inference. Training is the computationally intensive process where a model learns from vast datasets. It is a one-time, upfront capital expenditure (CapEx) to create a single version of a model, analogous to the design, engineering, and construction of a factory.4 This phase demands thousands of the most powerful and expensive processors working in concert for months. The training cost for a single frontier model like OpenAI's GPT-4 is estimated to be between $100 million and $200 million.6
Inference, by contrast, is the deployment phase where the trained model makes predictions or generates outputs based on new data. It is the point of value delivery where the AI interacts with users and business processes. This phase represents a continuous, high-volume operational expenditure (OpEx), analogous to the factory's daily production output.4 While a model is trained once, inference occurs billions of times per day across a multitude of applications, from consumer chatbots to industrial automation and financial analytics.5
This creates a fundamental economic and architectural asymmetry. The training market is a high-cost, low-volume domain supporting a few dozen frontier models. The inference market is a lower-cost-per-transaction, extremely high-volume domain requiring millions of deployment points, ranging from large data centers to lightweight edge devices.5 China's strategy recognizes that while the United States currently dominates the prestigious but narrow training domain, the larger and more globally influential prize is the inference market.
Market Projections: Sizing the Multi-Hundred-Billion-Dollar Inference Opportunity
Quantitative market analysis confirms that the long-term economic center of gravity in the AI industry lies in inference. While the global AI training market is substantial, projected to reach tens of billions of dollars by 2027 with a compound annual growth rate (CAGR) of around 30%, it is significantly outsized by the inference market.5
According to a comprehensive report by MarketsandMarkets, the AI inference market is projected to grow from $106.15 billion in 2025 to $254.98 billion by 2030, expanding at a CAGR of 19.2%.1 This growth is fueled by the proliferation of AI-powered applications in mobile devices, IoT, enterprise software, and generative AI services like chatbots and content creation.1 Further analysis from Verified Market Research projects that the AI Inference
Chip market alone will expand from approximately $31 billion in 2024 to $167.4 billion by 2032, driven by surging demand from data centers and edge AI applications.8 Some industry analysts have made even bolder predictions, suggesting that in the long run, the inference market will be
100 times larger than the training market.7
This vast market potential explains the strategic logic of focusing on inference. While the US strategy appears centered on maintaining a lead in the development of a limited number of high-cost models, China's strategy is aimed at capturing the lion's share of the much larger, more distributed, and faster-growing global deployment market. This is not a pivot to a niche segment but a direct targeting of the primary economic engine of the future AI economy.
The Compelling Economics: Deconstructing the Cost-per-Query Advantage
The cost structure of AI further illuminates the strategic landscape. Training costs are monumental; xAI's investment in a supercomputer for model training, comprising tens of thousands of Nvidia H100 GPUs, is estimated to be between $3 billion and $4 billion for the hardware alone.4 These are one-time investments to create the asset.
Inference costs, while small on a per-query basis, accumulate to become the dominant ongoing operational expense for any AI service provider.6 Critically, the cost of inference has been on a steep downward trajectory. In the 12 months following its launch, the cost to run OpenAI's GPT-3 model dropped by an annualized rate of 86%, a trend driven by hardware improvements and model optimization.4
However, a significant cost floor remains for large, proprietary "dense" models. Running a model like GPT-4 for inference still requires multiple high-end GPUs with over 48 GB of VRAM per query, making it expensive to scale for mass-market applications.6 This persistent cost creates a crucial vulnerability and a strategic opening. A competitor who can engineer models with fundamentally greater inference efficiency can offer comparable performance at a fraction of the cost, disrupting the market. This is precisely the opportunity that Chinese AI firms have targeted, creating a new competitive axis centered not on absolute performance but on performance-per-dollar at the point of deployment. The ability to drive down inference costs is the key enabler for capturing the multi-hundred-billion-dollar global market.
The prevailing US strategy, which views ownership of massive, cutting-edge training compute as an insurmountable competitive moat, may be based on a strategic miscalculation. The market data reveals that the inference market is not only larger but also possesses fundamentally different hardware requirements—less sophisticated, more distributed, and optimized for latency and energy efficiency rather than raw floating-point operations per second.5 A strategy focused on cornering the market for premium training hardware, like Nvidia's H100 and B200 series, risks ceding the much larger and more globally influential inference market to a competitor who optimizes for cost-effective, large-scale deployment. The "moat" built around training infrastructure may only protect a small, albeit prestigious, island in a much larger ocean of AI applications.
Furthermore, while training is a centralized and largely private process, inference is the external-facing interface of AI that touches billions of users daily across every sector of the global economy.8 Dominance in the inference layer—the combination of models, hardware, and software that delivers AI services—translates directly into geopolitical influence. The entity that provides the world's default inference stack sets the technical standards, influences data governance protocols, and builds deep, lasting ecosystem dependencies. China's focus on inference is therefore not merely an economic strategy; it is a direct path to embedding its technology and standards into the digital fabric of other nations, particularly in the developing world.9 This form of influence, built on utility and accessibility, is potentially far more potent and durable than simply possessing the world's most powerful, but isolated, training clusters.
Constraint-Driven Innovation: A Technical Analysis of China's Efficiency-First Models
US export controls, designed to hobble China's AI ambitions by restricting access to state-of-the-art training hardware, have paradoxically catalyzed a wave of profound innovation. Faced with hardware constraints, Chinese AI labs have been forced to pursue a divergent architectural philosophy—one that prioritizes computational efficiency and performance-per-dollar over the raw, brute-force performance metrics often chased in the West. This "constraint-driven innovation" has given rise to a new generation of open-source models that are not only competitive with their proprietary US counterparts but are fundamentally better suited for scalable, cost-effective global deployment.
The Architectural Philosophy: Maximizing Performance-per-Watt and Performance-per-Dollar
Rather than attempting to replicate the development path of Western firms, which often relies on access to ever-larger clusters of premium Nvidia GPUs, Chinese companies have reoriented their design principles. The core philosophy is to maximize the intelligence delivered per unit of computational resource, whether measured in watts of energy consumed or dollars of hardware cost. This has led to a strong emphasis on architectural designs that reduce the computational load during inference without sacrificing capability.
The most prominent of these designs is the Mixture-of-Experts (MoE) architecture. An MoE model consists of a vast number of "expert" sub-networks but only activates a small fraction of them to process any given input token. This "sparse activation" approach allows for the creation of models with enormous total parameter counts—a key factor in their knowledge and reasoning capacity—while keeping the active parameter count during inference low and computationally manageable. This design is the technical cornerstone of China's inference-centric strategy.
DeepSeek Series (V3 & R1): Pioneering Sparse Architectures for Frontier Performance
DeepSeek AI has emerged as a leader in this new architectural paradigm. Its DeepSeek-V3 model is a prime example of leveraging sparse architectures to achieve frontier-level performance with remarkable efficiency.
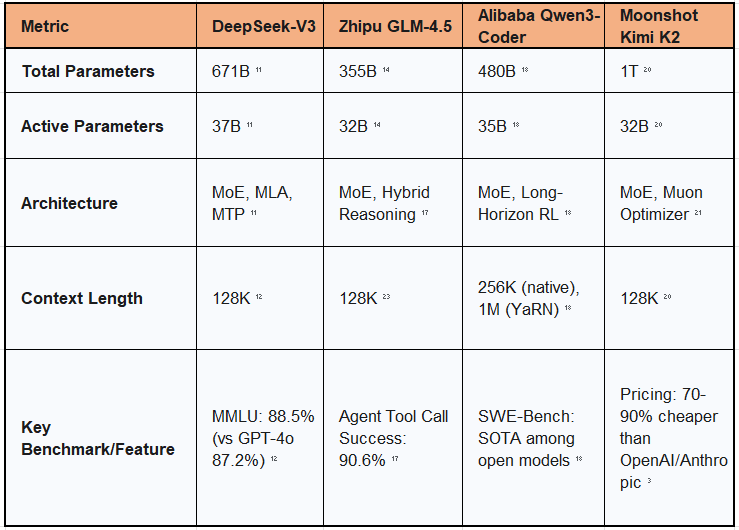
Technically, DeepSeek-V3 is an MoE model with a staggering 671 billion total parameters, yet it activates only 37 billion parameters per token during inference.11 This design allows it to achieve performance that rivals or even surpasses top-tier proprietary models. For instance, it scores 88.5% on the MMLU benchmark for general knowledge and reasoning, slightly ahead of GPT-4o's reported 87.2%.12 Beyond benchmarks, the model incorporates advanced features like Multi-Head Latent Attention (MLA) for efficient long-context processing and Multi-Token Prediction (MTP) to improve training stability and reduce inference latency.11
Crucially, this performance is achieved with unprecedented efficiency. The model was pretrained for an estimated cost of only ~$5.6 million using 2.788 million H800 GPU hours, a fraction of the over $100 million estimated for GPT-4.6 The training process was noted for its high stability, with "no irrecoverable loss spikes," indicating a robust architecture optimized for production environments rather than just laboratory research.12 DeepSeek's models are not mere imitations; they represent a fundamental advance in making massive-scale AI economically viable for widespread deployment.
Zhipu GLM-4.5 Series: Unifying Reasoning and Agentic Capabilities with Efficiency
Zhipu AI's GLM-4.5 series further demonstrates the trend toward efficient, application-focused models. Like DeepSeek, it employs an MoE architecture, with the flagship GLM-4.5 featuring 355 billion total parameters and 32 billion active parameters. A more compact variant, GLM-4.5-Air, offers 106 billion total parameters with just 12 billion active, making it suitable for deployment on less powerful hardware.14
GLM-4.5 has achieved a top-three global ranking on a composite of industry benchmarks and is the leading open-source model.14 Its design philosophy emphasizes the unification of diverse capabilities—reasoning, coding, and intelligent agents—into a single, coherent system. This is particularly evident in its performance on agentic tasks, where it matches the capabilities of models like Claude 4 Sonnet and achieves a
90.6% success rate in tool-calling tasks, outperforming both Claude Sonnet (89.5%) and Kimi K2 (86.2%).17 This focus on building a reliable foundation for autonomous agents that can interact with external tools and APIs signals a clear product strategy aimed at high-value, real-world applications.
Alibaba Qwen3-Coder: Dominance in Long-Context and Agentic Coding
Alibaba's Qwen family of models showcases another critical dimension of efficiency: the ability to process extremely long contexts. The Qwen3-Coder model, a 480 billion parameter MoE model with 35 billion active parameters, is specifically optimized for coding tasks that require understanding vast amounts of information, such as entire software repositories.18
Its key innovation is the ability to support a context length of up to 1 million tokens using Alibaba's "YaRN" extrapolation method, with native support for 256K tokens.18 This capability enables massive productivity gains in software development and complex document analysis. On coding benchmarks like SWE-Bench Verified, Qwen3-Coder achieves state-of-the-art performance among open-source models and demonstrates competitive capabilities against proprietary models like Claude Sonnet 4 in agentic coding and tool-use scenarios.18 Qwen's success demonstrates that Chinese models are not just competing on general-purpose benchmarks but are targeting and establishing leadership in specific, high-impact enterprise verticals.
Moonshot Kimi K2: The Trillion-Parameter Model with a 70% Cost Advantage
Moonshot AI's Kimi K2 represents the culmination of this efficiency-first strategy, combining a headline-grabbing parameter count with a radically disruptive pricing model. Kimi K2 is a 1 trillion-parameter MoE model that activates 32 billion parameters per inference pass, trained with a custom Muon optimizer for stability and performance.20
While its technical specifications are impressive, its strategic importance lies in its pricing. For commercial API use, Kimi K2 is priced at just $0.15 per million input tokens and $2.50 per million output tokens.3 This is a dramatic reduction compared to leading US models like Anthropic's Claude Opus 4 ($15 input / $75 output) or OpenAI's GPT-4.1 ($2 input / $8 output), representing a cost advantage of over 90% in some cases.3 Despite the low price, users and analysts have praised Kimi K2 for its robust performance, particularly in complex agentic workflows and tool-calling scenarios.3
Kimi K2 is the clearest expression of China's business strategy for AI. The technical architecture (MoE) is not an end in itself but a direct enabler of a disruptive pricing model designed to rapidly capture the mass market, particularly in price-sensitive developing economies that cannot afford premium US solutions.9

The Ascend Ecosystem: Hardware and Software Engineered for Global Scale
China's inference strategy is not limited to software innovation. It is underpinned by a concerted national effort, led by Huawei, to build a vertically integrated hardware and software ecosystem optimized for large-scale AI deployment. This ecosystem, centered on the Ascend line of processors and the open-source CANN software stack, is designed to provide a sovereign, scalable, and cost-effective alternative to the dominant Nvidia-CUDA platform.
Beyond Chip-to-Chip: Huawei's Volume and System-Level Strategy
A common analytical error made in the West is to evaluate China's hardware progress through a simple chip-to-chip comparison, where an individual Huawei Ascend processor is benchmarked against its Nvidia counterpart. This approach fundamentally misunderstands China's strategic intent. While a single Huawei Ascend 910C chip delivers approximately 60% of the inference performance of an Nvidia H100, Huawei is not attempting to win a battle of individual chip supremacy.24
Instead, China is pursuing a volume and system-level strategy. The goal is not to build the single most powerful chip in the world, but to build a complete, integrated system that leverages the mass production of domestically manufactured "good enough" chips to achieve competitive, and in some cases superior, performance at the cluster or rack scale.25 This approach trades the peak performance and efficiency of a single, cutting-edge chip for the strategic advantages of a guaranteed domestic supply chain, predictable costs, and insulation from US foreign policy.
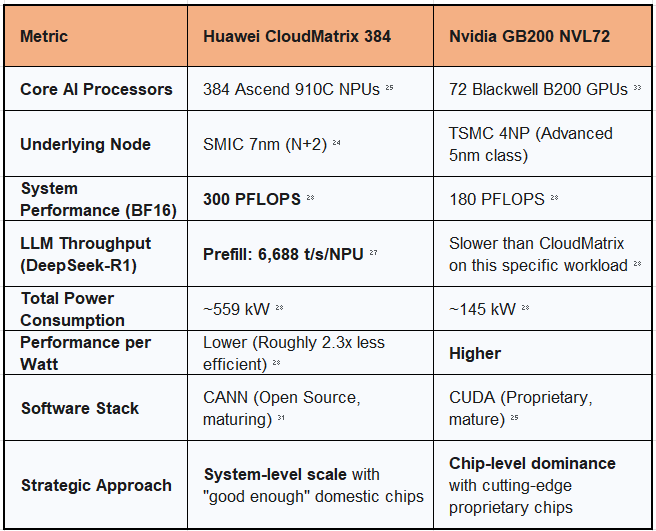
Hardware Deep Dive: The Ascend 910C and the CloudMatrix 384 Supercluster
The flagships of this hardware strategy are the Ascend 910C processor and the CloudMatrix 384 supercluster.
The Ascend 910C is an AI processor manufactured on SMIC's 7nm process node, making it a fully domestic alternative to Nvidia's export-controlled GPUs.24 While it lags behind Nvidia's best in computationally demanding training tasks, it has proven to be a surprisingly capable and efficient accelerator for inference workloads, which are the primary target of China's strategy.24
The CloudMatrix 384 is the key to unlocking the system-level strategy. It is not a single server but a massive, rack-scale supercluster that integrates 384 Ascend 910C AI processors (referred to as NPUs, or Neural Processing Units) with 192 Kunpeng CPUs across 16 server racks.25 The critical innovation is the interconnect. The entire system is networked via an ultra-high-bandwidth optical Unified Bus (UB) that enables direct, all-to-all communication between every processor in the cluster with extremely low latency.27
This architecture allows the CloudMatrix to function as a single, logically unified computer. By harnessing the power of massive parallelism, it can achieve performance that meets or exceeds Nvidia's top-tier systems in specific, optimized workloads. For example, research conducted by Huawei and AI startup SiliconFlow found that a CloudMatrix 384 system running the DeepSeek-R1 model could outperform systems based on Nvidia's H100 and GB200 NVL72.26 The system achieves a state-of-the-art prefill throughput of 6,688 tokens per second per NPU and a decode throughput of 1,943 tokens per second per NPU.27
This performance comes at a significant trade-off: power consumption. The CloudMatrix 384 consumes approximately 559 kW of power, roughly 3.9 times more than the ~145 kW consumed by an Nvidia GB200 NVL72 rack.25 For a purely commercial data center operator in a region with high energy costs, this would be a major drawback. However, for a state-backed strategic initiative focused on achieving technological sovereignty, and in a domestic market with abundant and less expensive energy, this is a calculated and acceptable trade-off.25
The Software Gambit: Open-Sourcing CANN to Challenge CUDA's Moat
Hardware alone is insufficient. Nvidia's most durable competitive advantage is not its silicon but its CUDA (Compute Unified Device Architecture) software platform—a mature, feature-rich, and deeply entrenched ecosystem of libraries, tools, and developer expertise built over two decades.29 To compete, Huawei must build a viable alternative.
Its answer is the Compute Architecture for Neural Networks (CANN), and its strategy is to open-source it. Huawei has announced that CANN will be released under a permissive open-source license, a direct strategic gambit to build a global developer community around its Ascend hardware.31
Currently, the CANN software stack lags significantly in maturity, documentation, and third-party library support compared to CUDA.25 Developers who have worked with the platform describe it as "early" and note that migrating code from PyTorch or TensorFlow still involves "migration friction".25 However, the open-source approach provides several powerful, long-term strategic advantages:
Developer Ecosystem Growth: By making the stack free and open, Huawei aims to replicate the grassroots enthusiasm that drove the adoption of Linux and RISC-V, creating a virtuous cycle where more developers lead to better tools, which in turn attracts more developers.31
Cost Advantage: Eliminating software licensing fees further reduces the total cost of ownership for deploying AI on the Ascend platform, reinforcing the core value proposition of affordability.31
Geopolitical Resilience: An open-source software stack cannot be subjected to export controls, sanctions, or licensing restrictions, providing guaranteed long-term access for any country or company that adopts it.31
Customization and Sovereignty: Open source allows nations and enterprises to audit, modify, and adapt the software to their specific needs, fostering a sense of technological sovereignty that proprietary, black-box solutions like CUDA cannot offer.31
While it will take years for CANN to approach the maturity of CUDA, Huawei is playing a long game. It is betting that the combined pull of lower costs, geopolitical resilience, and the collaborative power of open source will eventually build an ecosystem powerful enough to challenge Nvidia's software moat.

The Foundation of Scale: Assessing China's Domestic Semiconductor Viability
The entire edifice of China's inference strategy—from its efficient open-source models to its large-scale hardware systems—rests on a single, critical foundation: the ability to manufacture the necessary semiconductor chips domestically. Under the intense pressure of US sanctions, China's leading foundry, Semiconductor Manufacturing International Corporation (SMIC), has been tasked with achieving a level of technological capability and production scale sufficient to support these national ambitions. While SMIC still lags behind the global leader, TSMC, its progress has been substantial and, crucially, has reached a threshold of viability for the inference-centric strategy.
SMIC's 7nm Process: Achieving "Commercially Viable" Yields Under Sanctions
The cornerstone of China's current AI hardware is SMIC's 7nm-class process node. Lacking access to the advanced Extreme Ultraviolet (EUV) lithography machines produced by Dutch firm ASML, SMIC has been forced to rely on older Deep Ultraviolet (DUV) equipment. To create the fine features required for a 7nm chip, SMIC must use complex and costly multi-patterning techniques, which involve exposing the silicon wafer multiple times for a single layer.34
This approach initially resulted in very low production yields, with some estimates in 2023 placing the rate below 50%.36 However, by early 2025, reports indicated that SMIC had made significant progress. The yield rate for Huawei's Ascend 910C AI chip, produced on SMIC's 7nm (N+2) process, had reportedly improved from just 20% a year prior to 40%.38 Industry analysts have deemed this 40% yield rate to be "commercially viable or good enough to make money," with SMIC setting a goal to further improve it to 60%.38
This is a critical milestone. While a 40% yield is considerably lower than the greater than 90% yields routinely achieved by TSMC on its mature nodes, it is sufficient for China's strategic purposes.36 For a state-subsidized national champion producing a critical component for a national security priority, profitability is secondary to supply assurance. A 40% yield ensures a reliable domestic source of the "good enough" 7nm chips needed to power the Ascend ecosystem in high volume, effectively insulating the inference hardware strategy from US sanctions.
The 5nm Frontier: Cost, Yield, and the Limits of DUV Lithography
While SMIC has achieved viability at 7nm, the path to more advanced nodes using DUV technology becomes exponentially more difficult and expensive. SMIC is reportedly on track to finalize a 5nm process in 2025, but this will push the limits of multi-patterning DUV lithography.39
The economic and technical penalties are severe. The cost to produce a 5nm wafer at SMIC is projected to be 40-50% higher than producing a comparable wafer at TSMC using EUV machines.39 Furthermore, the yield for this process is estimated to be only one-third of TSMC's, making it a commercially challenging proposition even with state subsidies.39 Recent technical analysis of Huawei's latest devices has debunked rumors of a 5nm breakthrough, confirming that its flagship chips remain on the more mature 7nm process.42
This suggests that for the near-to-medium term, the 7nm Ascend 910C will remain the workhorse of China's AI hardware strategy. Progress to 5nm and beyond at scale will likely depend on China's ability to develop its own indigenous EUV-class lithography equipment, a monumental technological challenge.
Sufficient Scale: Why "Good Enough" is Good Enough for Inference Dominance
The analysis of SMIC's capabilities reveals a crucial strategic point: China's semiconductor industry does not need to achieve parity with TSMC to enable its global AI ambitions. It only needs to achieve sufficient scale in producing inference-optimized hardware, insulated from foreign control.
The evidence suggests it is meeting this threshold. SMIC's global market share rose to 5.7% in the first quarter of 2024, establishing it as the world's third-largest foundry by revenue.34 This demonstrates a growing capacity to produce wafers at scale. The combination of a commercially viable 40% yield on its 7nm process with a system-level architecture (like the CloudMatrix) that aggregates the power of hundreds of these chips creates a resilient, sovereign, and scalable manufacturing base for the hardware needed to win the inference race.
The Western focus on denying China access to the absolute leading edge of semiconductor manufacturing (sub-5nm nodes) may overlook the strategic reality that China's inference-centric approach has successfully decoupled its AI goals from this requirement. By pivoting the competition to a domain where "good enough" domestic technology is sufficient when deployed at massive scale, China has found a way to remain highly competitive. The high cost and relative inefficiency of this domestic production, often cited as a weakness from a Western market perspective, should be re-contextualized. It is not a market failure but a state-subsidized feature of a national security strategy. The "extra cost" is the price the Chinese state is willing to pay for technological sovereignty and the ability to pursue its global AI ambitions unhindered by US policy. This willingness to absorb economic inefficiency for strategic gain is a core asymmetric advantage that market-driven Western economies find difficult to counter.

The Geopolitical Gambit: Open Source as a Tool for Global Influence
China's inference strategy extends far beyond the technical and economic realms; it is a sophisticated and fully integrated component of its broader geopolitical ambitions. By combining low-cost, high-performance open-source AI models with affordable, domestically produced hardware, China is creating a technological value proposition that is highly attractive to the developing world. This strategy is being executed through established foreign policy frameworks like the Digital Silk Road, with the ultimate goal of establishing Chinese technology as the global standard, building spheres of influence, and creating durable technological dependencies.
The Digital Silk Road: Deploying AI Infrastructure Across the Global South
The primary vehicle for China's global AI deployment is the Digital Silk Road (DSR), a key component of its overarching Belt and Road Initiative (BRI).44 The DSR's objective is to create an integrated global digital ecosystem with China at its center. This involves providing partner nations—primarily in Asia, Africa, and Latin America—with digital infrastructure, including 5G telecommunications networks, data centers, cloud computing services, and AI capabilities.44
AI serves as the "linchpin" or the "brains" of the DSR, animating the physical infrastructure and enabling advanced applications like smart cities, e-commerce platforms, and digital government services.44 The combination of China's efficient open-source models and the affordable Ascend hardware ecosystem provides the perfect technological toolkit for this initiative. It allows China to offer partner nations access to cutting-edge AI at a price point they can afford, a compelling alternative to the expensive, proprietary systems offered by US firms.10 This approach helps developing countries shrink the digital divide while simultaneously embedding Chinese technology and standards into their national economies.
Case Studies in Technological Dependency: AI Adoption in Africa
Africa has emerged as a key proving ground and battleground for this strategy. Chinese technology companies, often with financing from state-backed banks like the China Exim Bank, have been deeply involved in building out the continent's digital infrastructure.47 Huawei alone has constructed an estimated 70% of Africa's 4G networks and is a key provider for smart city projects.47
These "Smart City" initiatives, which have been implemented in at least nine African countries including Kenya, Uganda, and Zimbabwe, often involve the deployment of extensive AI-powered surveillance systems.49 While packaged as tools for improving public safety and urban management, these technologies have drawn significant criticism. In Uganda, Huawei's facial recognition systems were reportedly used to identify and arrest supporters of an opposition political leader.47
Furthermore, these partnerships often involve arrangements that raise concerns about "data colonialism." A notable deal between the Zimbabwean government and Chinese AI firm CloudWalk Technology involved Zimbabwe sending vast amounts of its citizens' biometric data to China to help train and improve facial recognition algorithms.48 Such cases illustrate how the deployment of Chinese AI can lead to the erosion of data privacy and the export of "authoritarian tech," creating deep technological and political dependencies that are difficult for recipient nations to reverse.50
The Open-Source Trojan Horse: Ecosystem Lock-in and De Facto Standard-Setting
China's strategic use of open source is a sophisticated play for long-term influence, disguised as technological benevolence. Chinese policymakers and strategists explicitly view open-source AI as a "strategic counterbalance to Western platform dominance" and a way to internationalize Chinese-developed frameworks.2
By releasing high-performance models like DeepSeek, GLM, and Qwen under permissive licenses, Chinese firms accomplish several strategic objectives simultaneously:
Ecosystem Lock-in: Developers, companies, and entire countries that build their applications and infrastructure on top of Chinese open-source models become part of the Chinese AI ecosystem. Over time, this creates significant switching costs, making it harder to migrate to alternative platforms.2
De Facto Standard-Setting: Widespread global adoption of Chinese models establishes their underlying architectures, data formats, and safety protocols as the de facto global standards. This gives China immense influence over the future evolution of AI technology and governance, sidelining US-led efforts.26
Global Data Collection: The deployment of these models around the world provides Chinese firms with invaluable data on usage patterns, performance in diverse environments, and emerging market needs. This data creates a powerful feedback loop that informs and accelerates future model development.2
Soft Power and Narrative Control: The open-source strategy is carefully packaged with a narrative of democratization, accessibility, and "AI for good".10 This messaging is highly effective in the Global South, where it contrasts sharply with the expensive, closed, and export-controlled nature of leading US AI platforms. It allows China to portray itself as a benevolent technological partner, masking the deeper strategic intent to build a new, Sino-centric global technology order.
The US Response: Strategic Blind Spots and Potential Countermoves
The emergence of China's inference-centric strategy presents a formidable challenge to the United States' long-held leadership in artificial intelligence. An analysis of the current US response reveals a series of strategic blind spots and a policy framework that may be inadvertently accelerating the very trends it seeks to combat. However, recognizing these shortcomings also illuminates a path toward a more effective competitive strategy.
The Export Control Paradox: How Sanctions Inadvertently Fuel China's Strategy
The central pillar of the US strategy to counter China's AI rise has been a series of increasingly stringent export controls designed to restrict China's access to high-end AI chips and semiconductor manufacturing equipment.53 While intended to slow China's progress, these controls have had a paradoxical effect: they have acted as a powerful catalyst for the very inference-centric strategy that now threatens US dominance.
By denying Chinese firms easy access to state-of-the-art Nvidia GPUs, US policy has forced them down a path of "constraint-driven innovation." This has led directly to the development of the superior, efficiency-first model architectures detailed earlier. Simultaneously, the sanctions have strengthened China's strategic resolve and catalyzed massive state-led investment in its indigenous hardware ecosystem (the Ascend platform) and domestic manufacturing capabilities (SMIC), as analyzed earlier.54 In essence, US policy, by closing the door to the "easy" path of buying the best hardware, has compelled China to develop a more resilient, sovereign, and strategically coherent long-term alternative.
The Training-Centric Blind Spot in US Policy and Investment
The second major vulnerability in the US approach is its persistent and overwhelming focus on winning the AI training race. US policy, private sector investment, and public discourse are all heavily oriented toward maintaining leadership in the development of ever-larger, more powerful frontier models.55 This is often framed as a "race to AGI" (Artificial General Intelligence) or ASI (Artificial Super Intelligence).55
This focus is reflected in policy initiatives like the CHIPS and Science Act, which directs billions toward boosting US semiconductor manufacturing for high-end applications, and recent White House AI action plans that prioritize streamlining the construction of massive data centers to house these power-hungry training clusters.56 While these investments are critical for maintaining leadership in the prestige category of frontier AI research, they largely ignore the larger and more immediate strategic competition for global AI deployment. As demonstrated above, the inference market is where the bulk of economic value and geopolitical influence will be decided. The US focus on winning the training "sprint" risks losing the deployment "marathon."
A Blueprint for Competition: An Open-Source Counter-Strategy
An effective US response requires moving beyond the current strategy and competing with China on the new battlefield of inference. This involves shifting from a purely defensive posture of denial (via export controls) to a proactive posture of competition. A blueprint for such a strategy is beginning to emerge.
First, the US must embrace open-source AI as a strategic asset. The Trump administration's 2025 AI Action Plan surprisingly endorsed open-source models for their "geostrategic value," recognizing that they can become global standards and extend US technological influence.59 Leading US companies like Meta have long championed open source with their LLaMA models, and even the historically closed OpenAI is now releasing open-weight models in response to global competition.60 A concerted national strategy that encourages and supports the development of high-performance, inference-optimized US open-source models could directly counter China's offerings and provide a compelling alternative for the global developer community.62
Second, the US should build allied hardware and software coalitions. Unilateral export controls have often frustrated key allies, creating market fragmentation that China can exploit.63 A more effective approach would be to work with partners in Europe, Japan, South Korea, and Taiwan to create alternative, trusted supply chains for cost-competitive inference hardware. This would provide a non-Chinese option for the global market that is not locked into a single proprietary ecosystem.
Third, the US must compete on economics and accessibility. China's Digital Silk Road succeeds by offering a compelling economic package. The US can counter this by leveraging federal financing tools, development aid, and strategic export programs to create "full-stack AI export packages"—including hardware, models, software, and support—that are price-competitive in key strategic markets.56 This would directly challenge China's value proposition and offer developing nations a viable pathway to adopt AI without becoming technologically dependent on Beijing.
Future Scenarios and Strategic Recommendations
The confluence of China's inference-centric strategy and the current US response creates a strategic inflection point for the future of the global AI ecosystem. The trajectory from this point is not predetermined and could lead to several distinct outcomes, each with profound implications for technological leadership, economic distribution, and geopolitical alignment.

Scenario 1: Chinese Inference Dominance
In this scenario, China's strategy succeeds largely uncontested. Its open-source models, optimized for the Ascend hardware stack, continue to improve and dominate global performance benchmarks for most practical applications. The significant and sustained cost advantages, potentially reaching 70-90% below US alternatives, make the Chinese AI stack the default choice for startups, enterprises, and governments in developing nations across Asia, Africa, and Latin America.
As more of the world builds its digital infrastructure on Chinese platforms, network effects and high switching costs solidify China's position. Chinese technical standards for AI safety, data governance, and interoperability become the de facto global norms. The United States maintains its lead in a small number of highly advanced, proprietary frontier models, but these become increasingly niche and irrelevant to the vast majority of global AI usage. In this future, the US wins the battle for AGI research in the lab but loses the war for AI deployment in the world.
Scenario 2: A Bifurcated Global AI Ecosystem
A more likely alternative is the emergence of a "digital iron curtain" that splits the global AI ecosystem into two distinct, geopolitically aligned spheres.
The Western AI Sphere, comprising the United States and its close allies, would continue to rely on proprietary models from companies like OpenAI, Google, and Anthropic, running primarily on Nvidia's advanced hardware. This sphere would maintain leadership in frontier research and high-margin enterprise applications but would be largely excluded from mass-market deployment in non-aligned nations due to high costs and export restrictions.
The Chinese AI Sphere would encompass China, its strategic partners, and the majority of the developing world. This sphere would be built on China's open-source models and domestically produced hardware. It would dominate in terms of user volume and deployment scale, even if its technology lags slightly at the absolute cutting edge.
While some level of technical interoperability might exist, data flows, governance frameworks, and commercial ecosystems would be largely separate, creating significant global inefficiencies but also preventing a single power from achieving total technological hegemony.
Scenario 3: Renewed US-Led Competition
This scenario envisions a future in which the United States recognizes the strategic threat posed by China's inference strategy and executes a successful strategic pivot. Acknowledging the limitations of its training-centric focus and protectionist policies, the US government and private sector collaborate on a new, more competitive approach.
This would involve launching a major national initiative to develop and promote high-performance, inference-efficient US open-source models. Washington would reform its export control regime, shifting from unilateral restrictions to building collaborative technology partnerships with allies to create trusted, cost-effective hardware alternatives. Finally, the US would deploy strategic economic tools—development aid, export financing, and public-private partnerships—to make the American AI stack accessible and attractive to developing nations. In this future, the world would have two competitive, viable options for AI infrastructure, leading to a more dynamic, multi-polar, and innovative global market.
Actionable Recommendations for Policymakers and Industry Leaders
To navigate this complex landscape and steer toward a more favorable outcome, US policymakers and technology leaders should consider the following strategic actions:
Shift the Focus from Training to Inference Efficiency: Rebalance federal AI research and development funding. While maintaining investment in frontier model training, a significant portion of funding should be redirected to a national initiative focused on developing novel algorithms, model architectures, and hardware designs that radically improve AI inference efficiency (performance-per-watt and performance-per-dollar).
Launch a National Open-Source AI Initiative: The US government should partner with leading academic institutions and technology companies to create and support a portfolio of flagship American open-source models. These models should be specifically designed to compete with Chinese offerings on performance, efficiency, and ease of use, providing a credible alternative for the global developer community.
Counter the Digital Silk Road with a "Full-Stack" Allied Export Program: Move beyond simply selling chips or API access. The Departments of Commerce and State should lead an effort to create comprehensive, price-competitive AI export packages for allied and partner nations. These packages should include hardware, open models, software support, and training, financed through development aid and export-import bank guarantees.
Forge a Semiconductor Coalition for Inference Hardware: Reform the export control strategy to be less unilateral and more collaborative. The US should work with key semiconductor partners (e.g., Japan, South Korea, Taiwan, the Netherlands) to establish a trusted supply chain for a new class of "inference-optimized" chips that are cost-effective and not subject to the most stringent export controls, providing a clear alternative to Huawei's Ascend platform.
Invest in a CUDA Alternative: Recognize that Nvidia's CUDA is a single point of strategic dependency. The US should fund a public-private consortium to develop a high-performance, open-source computing stack for AI that is hardware-agnostic. This would foster greater competition in the hardware market and provide a resilient, non-proprietary foundation for the future of American and allied AI development.
The question is no longer whether China can compete with US AI leadership, but whether the US can adapt its strategy to compete effectively for global AI ecosystem dominance in an environment where efficiency, accessibility, and cost may ultimately matter more than absolute technical superiority at the frontier. The window for an effective strategic response is narrowing as Chinese inference capabilities improve and global adoption accelerates.
I end, as I began, with this hopeful message mindfully shared this morning by the wonderful Sara Hooker of Cohere Labs:
It is not the strongest of the species that survives, not the most intelligent that survives.
It is the one that is the most adaptable to change.
~ Charles Darwin
References:
AI Inference Market worth $254.98 billion by 2030 - Exclusive Report ... , https://www.prnewswire.com/news-releases/ai-inference-market-worth-254-98-billion-by-2030---exclusive-report-by-marketsandmarkets-302388315.html
It's frankly embarrassing for the West what China has done for open-source AI - Reddit , https://www.reddit.com/r/accelerate/comments/1m7tkpm/its_frankly_embarrassing_for_the_west_what_china/
Alibaba‑backed Moonshot Unveils Kimi K2: A High‑Performance ... , https://rits.shanghai.nyu.edu/ai/alibaba%E2%80%91backed-moonshot-unveils-kimi-k2-a-high%E2%80%91performance-cost%E2%80%91effective-rival-to-chatgpt-and-claude/
LLMs: Training vs. Inference. As AI tools become more commonplace we… | by Mangusta Capital | Medium , https://medium.com/@Mangusta/llms-training-vs-inference-97b02337cabb
AI Training vs Inference Market Size: A Comprehensive Analysis , https://www.byteplus.com/en/topic/447591
The Economics of AI Training and Inference: How DeepSeek Broke the Cost Curve - Adyog , https://blog.adyog.com/2025/02/09/the-economics-of-ai-training-and-inference-how-deepseek-broke-the-cost-curve/
"AI is really two markets, training and inference. Inference is going to be 100 times bigger than training. Nvidia is really good at training but very miscast at inference." - Chamath Palihapitiya : r/AMD_Stock - Reddit , https://www.reddit.com/r/AMD_Stock/comments/1cf765y/ai_is_really_two_markets_training_and_inference/
AI Inference Chip Market Size, Share, Scope, Analysis & Forecast , https://www.verifiedmarketresearch.com/product/ai-inference-chip-market/
Chinese AI Startups Slash Costs, Challenge US Dominance with ... , https://www.webpronews.com/chinese-ai-startups-slash-costs-challenge-us-dominance-with-open-source-models/
China's AI Global Initiative and the Geopolitical Reshaping of Tech Markets: Strategic Positioning and Investment Opportunities - AInvest , https://www.ainvest.com/news/china-ai-global-initiative-geopolitical-reshaping-tech-markets-strategic-positioning-investment-opportunities-2507/
DeepSeek-V3 Explained: Optimizing Efficiency and Scale - ADaSci , https://adasci.org/deepseek-v3-explained-optimizing-efficiency-and-scale/
DeepSeek Model V3: Download, Architecture, Performance Guide - MuneebDev , https://muneebdev.com/deepseek-model-v3-guide/
DeepSeek-V3 Technical Report - arXiv , https://arxiv.org/pdf/2412.19437
zai-org/GLM-4.5 - Hugging Face , https://huggingface.co/zai-org/GLM-4.5
Zhipu AI Launches GLM‑4.5, an Open-Source 355B AI Model Aimed ... , https://pandaily.com/zhipu-ai-launches-glm-4-5-an-open-source-355-b-ai-model-aimed-at-ai-agents
Z.ai Releases GLM-4.5, Setting New Standards for AI Performance and Accessibility While Improving Affordability - PR Newswire , https://www.prnewswire.com/news-releases/zai-releases-glm-4-5--setting-new-standards-for-ai-performance-and-accessibility-while-improving-affordability-302514803.html
GLM-4.5: Reasoning, Coding, and Agentic Abililties - Z.ai , https://z.ai/blog/glm-4.5
Qwen3-Coder: Agentic Coding in the World | Qwen , https://qwenlm.github.io/blog/qwen3-coder/
Qwen3 Coder vs. Kimi K2 vs. Sonnet 4 Coding Comparison (Tested on Qwen CLI) - Reddit , https://www.reddit.com/r/LocalLLaMA/comments/1mi8lbl/qwen3_coder_vs_kimi_k2_vs_sonnet_4_coding/
Is Kimi K2 API Pricing Really Worth the Hype for Developers in 2025 - Apidog , https://apidog.com/blog/kimi-k2-api-pricing/
Kimi K2 API Pricing in 2025: Is It Really a Game-Changer for Developers? - Gary Svenson , https://garysvenson09.medium.com/kimi-k2-api-pricing-in-2025-is-it-really-a-game-changer-for-developers-f612700fb3bf
moonshotai/Kimi-K2-Instruct - Hugging Face , https://huggingface.co/moonshotai/Kimi-K2-Instruct
GLM-4.5: Reasoning, Coding, and Agentic Abililties - Simon Willison's Weblog , https://simonwillison.net/2025/Jul/28/glm-45/
DeepSeek research suggests Huawei's Ascend 910C delivers 60 ... , https://www.tomshardware.com/tech-industry/artificial-intelligence/deepseek-research-suggests-huaweis-ascend-910c-delivers-60-percent-nvidia-h100-inference-performance
AI Race: Can Huawei Close The AI Gap? - Forrester , https://www.forrester.com/blogs/ai-race-can-huawei-close-the-ai-gap/
Investor alert: Chinese AI is booming in global markets, and Huawei's chips beat Nvidia's
Serving Large Language Models on Huawei CloudMatrix384 - arXiv , https://arxiv.org/abs/2506.12708
Huawei's brute force AI tactic seems to be working — CloudMatrix ... , https://www.tomshardware.com/pc-components/gpus/huaweis-brute-force-ai-tactic-seems-to-be-working-cloudmatrix-384-claimed-to-outperform-nvidia-processors-running-deepseek-r1
Reports Suggest DeepSeek Running Inference on Huawei Ascend 910C AI GPUs , https://www.techpowerup.com/forums/threads/reports-suggest-deepseek-running-inference-on-huawei-ascend-910c-ai-gpus.331763/
How Chip Stacking Became Huawei's Weapon in the AI War - Nasdaq , https://www.nasdaq.com/articles/how-chip-stacking-became-huaweis-weapon-ai-war
Huawei Open-Sources AI Software Stack, Aiming to Rival CUDA - TechPowerUp , https://www.techpowerup.com/339664/huawei-open-sources-ai-software-stack-aiming-to-rival-cuda
Huawei open-sources CANN to challenge Nvidia's CUDA dominance - digitimes , https://www.digitimes.com/news/a20250806PD229/software-huawei-ascend-nvidia-cuda.html
Huawei CloudMatrix 384 Beating Blackwell - At What Environmental Cost? - TechInsights , https://library.techinsights.com/sectioned-blog-viewer/3444441a-5b83-47e0-af79-ed974829119f
SMIC profit slides 23% in 2024 despite record revenue surge - digitimes , https://www.digitimes.com/news/a20250328VL203/smic-wafer-ic-manufacturing-revenue-2024.html
China's SMIC Plays 7 nm Card | TechInsights , https://www.techinsights.com/blog/chinas-smic-plays-7-nm-card
SMIC making progress towards 5nm chip tech - Evertiq , https://evertiq.com/design/55327
SMIC to sell Huawei costly, inefficient 5nm chips - Asia Times , https://asiatimes.com/2024/02/smic-to-sell-huawei-costly-inefficient-5nm-chips/
How is SMIC after US embargo? - Andy Lin's Long-term Stock Investment Blog , https://www.granitefirm.com/blog/us/2025/03/08/smic-after-us-embargo/
SMIC Reportedly On Track to Finalize 5 nm Process in 2025, Projected to Cost 40-50% More Than TSMC Equivalent - TechPowerUp , https://www.techpowerup.com/forums/threads/smic-reportedly-on-track-to-finalize-5-nm-process-in-2025-projected-to-cost-40-50-more-than-tsmc-equivalent.334789/
SMIC Reportedly On Track to Finalize 5 nm Process in 2025 ... , https://www.techpowerup.com/334789/smic-reportedly-on-track-to-finalize-5-nm-process-in-2025-projected-to-cost-40-50-more-than-tsmc-equivalent
5-7 Nm Possibly The Long-Term Technological Ceiling For China's Semiconductor Industry – Analysis - Eurasia Review , https://www.eurasiareview.com/09012025-5-7-nm-possibly-the-long-term-technological-ceiling-for-chinas-semiconductor-industry-analysis/
Huawei's new notebook shows China's SMIC years behind TSMC - The Register , https://www.theregister.com/2025/06/23/huaweis_foldable_shows_china_years_behind_tsmc/
How could SMIC achieve 5 nm? - TechInsights , https://www.techinsights.com/blog/how-could-smic-achieve-5-nm
China expands AI globally through the Digital Silk Road | East Asia ... , https://eastasiaforum.org/2025/04/11/china-expands-ai-globally-through-the-digital-silk-road/
Assessing China's Digital Silk Road Initiative - Council on Foreign Relations , https://www.cfr.org/china-digital-silk-road/
China's AI Strategy: A Case Study in Innovation and Global Ambition , https://trendsresearch.org/insight/chinas-ai-strategy-a-case-study-in-innovation-and-global-ambition/
China's AI deployment in Africa poses risks to security and sovereignty | The Strategist , https://www.aspistrategist.org.au/chinas-ai-deployment-in-africa-poses-risks-to-security-and-sovereignty/
China's Digital Silk Road taking its shot at the global stage - East Asia Forum , https://eastasiaforum.org/2024/05/09/chinas-digital-silk-road-taking-its-shot-at-the-global-stage/
China's Smart Cities in Africa: Should the United States Be ... - CSIS , https://www.csis.org/analysis/chinas-smart-cities-africa-should-united-states-be-concerned
The Impact of Chinese AI on Developing Countries in Sub-Saharan Africa - ScholarWorks , https://scholarworks.calstate.edu/downloads/t435gn69c
China AI Strategy , https://datagovhub.elliott.gwu.edu/china-ai-strategy/
Geopolitical implications of AI and digital surveillance adoption - Brookings Institution , https://www.brookings.edu/articles/geopolitical-implications-of-ai-and-digital-surveillance-adoption/
China draws red lines on US chip tracking with Nvidia meeting - The ... , https://economictimes.indiatimes.com/tech/technology/china-draws-red-lines-on-us-chip-tracking-with-nvidia-meeting/articleshow/123139040.cms
China's drive toward self-reliance in artificial intelligence: from chips ... , https://merics.org/en/report/chinas-drive-toward-self-reliance-artificial-intelligence-chips-large-language-models
Full Stack: China's Evolving Industrial Policy for AI - RAND , https://www.rand.org/pubs/perspectives/PEA4012-1.html
President Trump AI Action Plan Key Insights - Latham & Watkins LLP , https://www.lw.com/en/insights/president-trump-ai-action-plan-key-insights
What The CHIPS and Science Act means for Artificial Intelligence | Stanford HAI , https://hai.stanford.edu/policy/what-the-chips-and-science-act-means-for-artificial-intelligence
The CHIPS and Science Act: Here's what's in it - McKinsey , https://www.mckinsey.com/industries/public-sector/our-insights/the-chips-and-science-act-heres-whats-in-it
Open-source AI could provide 'geostrategic value,' Trump AI plan says | FedScoop , https://fedscoop.com/open-source-ai-trump-ai-action-plan/
OpenAI shifts to open-source AI models to counter China's ... , https://biz.chosun.com/en/en-it/2025/08/07/SB3N6PPLAFFQJPWTLX457ZMJN4/
Elon Musk’s xAI and OpenAI go Meta’s way, to give away tech behind AI chatbots , https://timesofindia.indiatimes.com/technology/tech-news/elon-musks-xai-and-openai-go-metas-way-to-give-away-tech-behind-ai-chatbots/articleshow/123143361.cms
Open-Source AI in America: A Roadmap to Safeguarding U.S. Innovation and National Security - R Street Institute , https://www.rstreet.org/research/open-source-ai-in-america-a-roadmap-to-safeguarding-u-s-innovation-and-national-security/
America's AI Strategy: Playing Defense While China Plays to Win | Wilson Center , https://www.wilsoncenter.org/article/americas-ai-strategy-playing-defense-while-china-plays-win
President Trump Announces AI Action Plan and Accelerated Permitting and Financing for Data Centers - Hunton Andrews Kurth LLP , https://www.hunton.com/the-nickel-report/president-trump-announces-ai-action-plan-and-accelerated-permitting-and-financing-for-datacenters