
THE INTELLIGENCE SHORTCUT: How Smaller, Cheaper AI Models Learn From the Giants
Why DeepSeek, Kimi, GLM, and s1 are shaking up a hundred-billion-dollar industry — and how anyone can do it

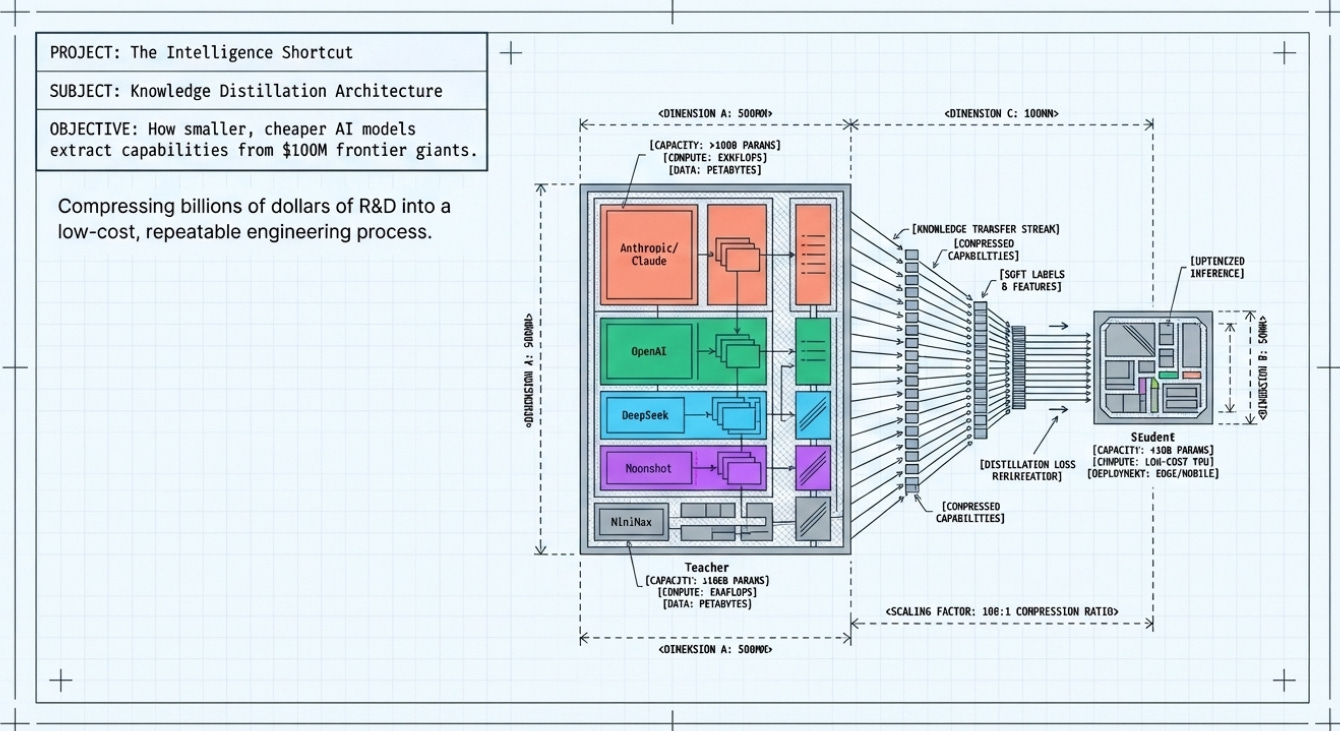
The “Scandal That Shook Silicon Valley”?
In February 2026, Anthropic — the (AI safety) company behind Claude — dropped a bombshell...of sorts. Three prominent Chinese AI labs had, according to Anthropic, secretly created over 24,000 fraudulent accounts and generated more than 16 million exchanges with Claude. Their goal: to feed Claude’s outputs into their own training pipelines and make their models dramatically smarter — at a tiny fraction of the cost.
The three accused labs were DeepSeek (Yes the one that triggered a market correction in late 2024/early 2025, and renowned for it’s “DeepSeek Moment”. And at the time, for its shockingly cheap R1 model), Moonshot AI (makers of the Kimi model family), and MiniMax. Each had allegedly targeted different capabilities: DeepSeek focused on foundational reasoning and alignment; Moonshot went after agentic reasoning and coding; MiniMax ran the largest operation with over 13 million exchanges.

OpenAI had raised similar alarms earlier that month, warning US lawmakers that DeepSeek was using ‘new, obfuscated methods’ to continue distilling OpenAI’s models. The pattern was unmistakable: a new generation of AI companies had figured out how to compress billions of dollars of R&D into a much cheaper process.
To understand why this matters — and why it’s both brilliant and controversial — you first need to understand what distillation actually is.
Important Note:
DeepSeek, Moonshot, and MiniMax do have their own proprietary base models; however, it is likely (if you believe the write-ups to be true), that they have also leveraged distillation from other companies to enhance those models or to create specific distilled versions.
DeepSeek
DeepSeek maintains a clear distinction between its flagship original models and its distilled offerings:
Original Base Models: The flagship DeepSeek-R1 and DeepSeek-V3 are their own architectures. DeepSeek-R1, for instance, was trained using large-scale reinforcement learning (RL) and supervised fine-tuning (SFT) from scratch, costing an estimated $5–6 million.
Distilled Models: DeepSeek also released the R1-Distill series (ranging from 1.5B to 70B parameters). These specifically use other companies’ base models, such as Meta’s Llama and Alibaba’s Qwen, which were then fine-tuned on reasoning traces generated by DeepSeek’s larger original models.
Moonshot AI (Kimi)
Moonshot has developed its own massive-scale architectures:
Kimi K2 and K2.5: These are proprietary models. Kimi K2 is a 1-trillion parameter Mixture-of-Experts (MoE) model trained on 15.5 trillion tokens using a novel “Muon optimizer”. Its successor, Kimi K2.5, added native multimodal vision capabilities.
Controversy: Despite having these base models, Moonshot was accused by Anthropic of conducting over 3.4 million exchanges with Claude to distill agentic reasoning, coding, and tool-use capabilities into their own pipeline.
MiniMax
MiniMax has also produced original large-scale architectures:
MiniMax-01: This model features 456 billion parameters and uses a “lightning attention” mechanism to support a 1-million-token context window.
MiniMax-M1: A follow-up reasoning model that uses a hybrid MoE architecture and was trained using a specific RL algorithm (CISPO).
Controversy: MiniMax was alleged to have run the largest “industrial-scale distillation” operation against Anthropic, with over 13 million exchanges intended to feed Claude’s outputs into their training pipelines.
Summary of the Distinction
However, you will read many write-ups and large AI Labs indicate that these companies used distillation as an “intelligence shortcut” to make their existing models smarter or to train them more cheaply, rather than distillation being their only source of model architecture. While they built high-parameter base models from scratch, they allegedly used unauthorized access to frontier models like Claude to “seed” or “transfer” complex reasoning capabilities that are otherwise expensive and difficult to discover through raw data alone.
Distillation: Teaching the Student Everything the Teacher Knows
The Classic Analogy: Textbook vs. Private Tutor
Imagine learning calculus from a textbook. You grind through exercises, get right answers and wrong answers, and slowly build intuition over months. Now imagine instead that you have access to a world-class mathematician sitting beside you — one who doesn’t just give you the answer, but walks you through exactly how they think about the problem: the mental shortcuts they use, the wrong paths they immediately rule out, the intuitions they’ve built over decades.
That’s the difference between training on raw data versus training through distillation. The ‘teacher’ model is the world-class mathematician. The ‘student’ model is learning not just from right/wrong answers but from rich, structured thinking.
The Technical Picture: Two Flavors of Distillation
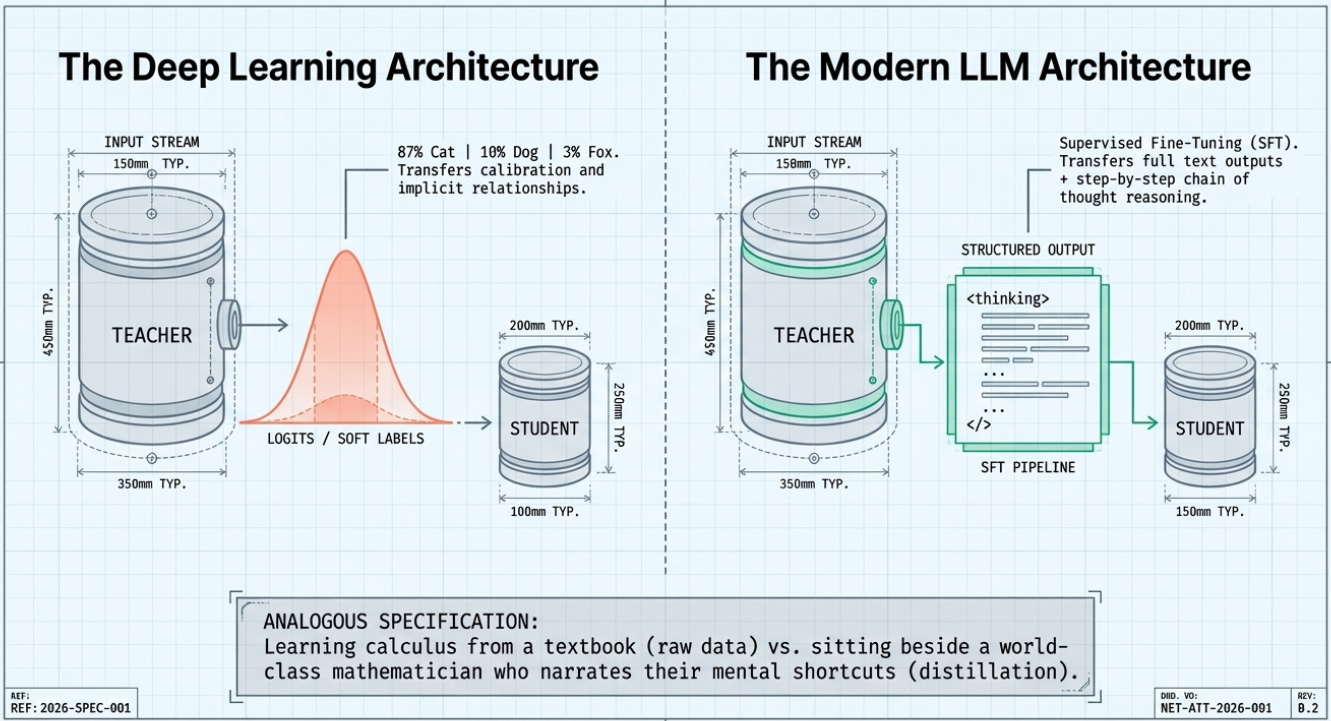
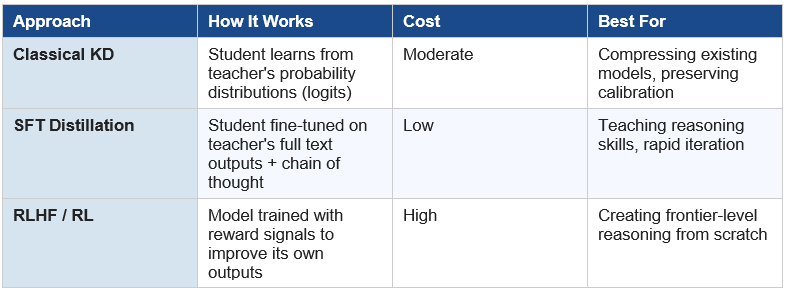
Flavor 1 — Classical Knowledge Distillation (The Deep Learning Version)
In traditional knowledge distillation (introduced in a famous 2015 paper by Geoffrey Hinton and colleagues), a large, expensive ‘teacher’ model trains a smaller, cheaper ‘student’ model by sharing not just its final answers but its entire probability distribution over possible answers — called ‘soft labels’ or ‘logits’.
Here’s why this matters: a teacher model asked to classify an image of a cat doesn’t just output ‘100% cat.’ It might output something like ‘87% cat, 10% small dog, 3% fox.’ That distribution is rich with implicit information. The student learns not just what the right answer is, but how similar or different the wrong answers are — knowledge that’s invisible if you only see the final label.

Flavor 2 — SFT-Based Distillation (The LLM Version)
Modern LLM distillation, which is what DeepSeek, Moonshot, and s1 primarily used, works differently. Instead of copying probability distributions, the student model is fine-tuned on a curated dataset of questions paired with the teacher model’s full answers — including, crucially, the teacher’s chain of thought: the step-by-step reasoning it used to arrive at the answer.
This is called Supervised Fine-Tuning (SFT). It’s cheaper and simpler than classical distillation but astonishingly effective. As Sebastian Raschka (author of ‘Build a Reasoning Model from Scratch’) explains, this approach is what DeepSeek used to train their R1-Distill family: they fed smaller Llama and Qwen base models on training data generated by their larger DeepSeek-V3 and R1 models.
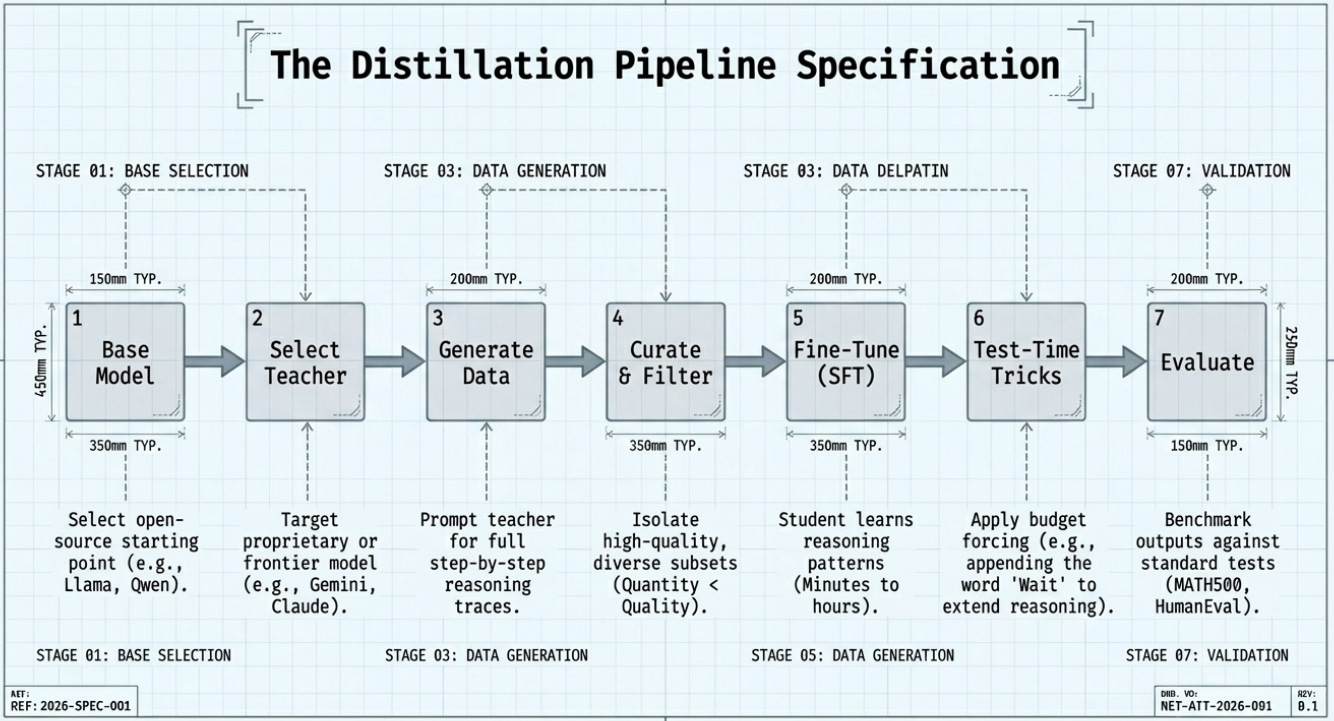
The Distillation Pipeline: Step by Step
This is the process that labs like DeepSeek, Moonshot, and academic teams like Stanford’s s1 project followed. Each step is explained in plain language, followed by a concrete example.



The Economics of Intelligence: How $100 Million Becomes $50
Why Frontier Model Training Costs So Much
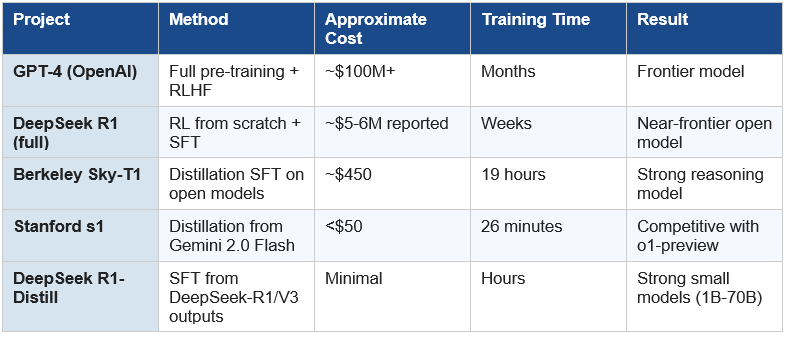
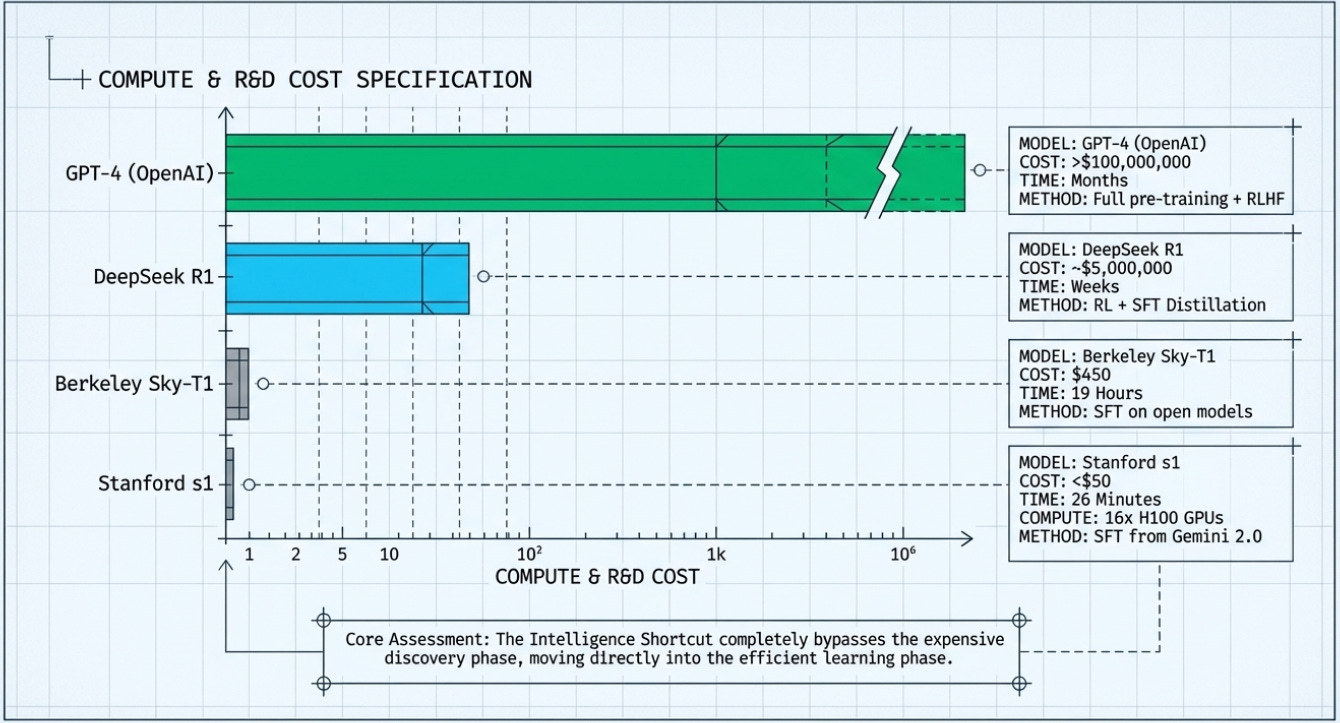
Training a frontier model like GPT-4 is estimated to have cost over $100 million. Claude, Gemini Ultra, and similar frontier models likely cost in the same ballpark, or more. These costs come from three sources: the compute required to train on trillions of tokens of data, the massive research teams needed to design architectures and training recipes, and the years of iteration and experimentation required to get things right. Worth reading: Scaling Laws For Neural Language Models (2020)
All of that investment is crystallized into the model’s weights — the billions of numerical parameters that encode everything it has learned. Those weights are, in a sense, the distilled wisdom of enormous amounts of human knowledge and research effort.
Why Distillation is Radically Cheaper
Here is the key insight: once a frontier model exists, a student model can learn from its outputs rather than from scratch. The student doesn’t need to process trillions of tokens of raw internet text. It just needs to process thousands (or tens of thousands) of high-quality examples of the teacher reasoning through problems.
The student doesn’t need to discover how to reason about mathematics — it can simply be shown thousands of examples of a great mathematician’s working. It skips the expensive discovery phase entirely and goes straight to the efficient learning phase.

Case Studies: How the Giants Did It
Case Study 1 — DeepSeek R1: The Shot Heard Around the World
In January 2025, DeepSeek — a Chinese AI lab — released R1, a reasoning model that matched or approached the performance of OpenAI’s o1 on key benchmarks, while reportedly costing a tiny fraction of the price to train. The release sent more than $1 trillion in tech stock valuations tumbling overnight, as investors recalibrated their assumptions about the economics of AI.
DeepSeek’s approach was multi-layered. For their flagship R1 model, they used large-scale reinforcement learning — training the model to improve its own reasoning through a reward signal. But for their R1-Distill series (smaller models ranging from 1.5B to 70B parameters), they used pure SFT distillation: fine-tuning Qwen and Llama base models on the same reasoning traces that were used to train R1 itself.
These distilled smaller models punched dramatically above their weight. A 7-billion-parameter distilled model could handle mathematical reasoning tasks that previously required models many times larger. The distillation data — the step-by-step reasoning traces generated by DeepSeek-V3 and the intermediate R1 checkpoint — was the key ingredient.
As for whether DeepSeek itself had distilled from OpenAI’s models during its own development: OpenAI claimed evidence of this, and Anthropic’s later disclosure suggests the pattern was real. The irony was not lost on observers that DeepSeek then openly published distilled models under the MIT license, allowing anyone to build on them — even as the company had allegedly fed on proprietary American models to get there.
Case Study 2 — Stanford s1: $50 and 26 Minutes
In February 2025, a team of researchers at Stanford University and the University of Washington published what may be the most striking demonstration of distillation’s power to date. Their model, s1, was built for under $50 in cloud compute credits and trained in just 26 minutes on 16 Nvidia H100 GPUs. Despite these almost absurdly modest resources, s1 performed comparably to OpenAI’s o1-preview on competition mathematics benchmarks — and in some tests, outperformed it.
The team’s recipe was elegantly simple. They started with Qwen2.5-32B (a powerful open-source base model from Alibaba). They sent 1,000 carefully curated questions to Google’s Gemini 2.0 Flash Thinking Experimental model, collecting not just the answers but the full reasoning traces — Gemini’s step-by-step thinking. They then fine-tuned Qwen on these 1,000 (question, reasoning, answer) triplets.
Their key discovery was that curation quality matters far more than dataset size. They tested multiple versions of their dataset and found that harder, more diverse problems produced better results than simply having more problems. They also discovered the ‘budget forcing’ trick: by appending the word ‘Wait’ when the model tried to stop reasoning prematurely, they could extend its thinking time and improve accuracy significantly.
The team’s paper, titled ‘s1: Simple Test-Time Scaling,’ is publicly available on arXiv and the code is on GitHub — making it the most accessible end-to-end distillation recipe in the field.
Case Study 3 — Berkeley Sky-T1: $450 in 19 Hours
Even before s1, researchers at UC Berkeley demonstrated a similar approach. Their model, Sky-T1-32B-Preview, was trained for approximately $450 over 19 hours using distillation from NovaSky-Instruct data (itself derived from o1-style reasoning data). The model achieved competitive scores on MATH and coding benchmarks, demonstrating that the s1 phenomenon was reproducible and that the $50 result wasn’t a fluke.
Case Study 4 — DeepSeek, Moonshot, MiniMax & Claude: The Industrial-Scale Operation
The February 2026 disclosure by Anthropic revealed a different kind of distillation — not academic research but what Anthropic called ‘industrial-scale distillation attacks.’ The scale supposedly dwarfed anything in the academic literature, but there are varying opinions on whether these could be classified as “industrial-scale” let alone “distillation attacks”. So for a bit of push - these are worth watching:
MiniMax supposedly ran the largest operation: over 13 million exchanges with Claude. Moonshot (Kimi) conducted more than 3.4 million exchanges, focused on agentic reasoning, tool use, coding, and computer vision. DeepSeek, despite being the most famous name, actually ran the smallest of the three operations with approximately 150,000 exchanges — but those were targeted specifically at reasoning tasks and censorship-safe rewrites of politically sensitive queries.
Anthropic identified the operations through IP address patterns, metadata, and signals from industry partners. The “perpetrators” had built what Anthropic called ‘hydra cluster’ networks — pools of up to 20,000 fraudulent accounts, carefully mixing extraction traffic with ordinary user requests to avoid detection. The prompts were a giveaway: extremely high volume, tightly focused on specific capability domains, and highly repetitive — a pattern consistent with building a training dataset rather than ordinary usage.

The New Landscape: Small Models That Punch Above Their Weight
Liquid Foundation Models (LFMs): Intelligence on Every Device
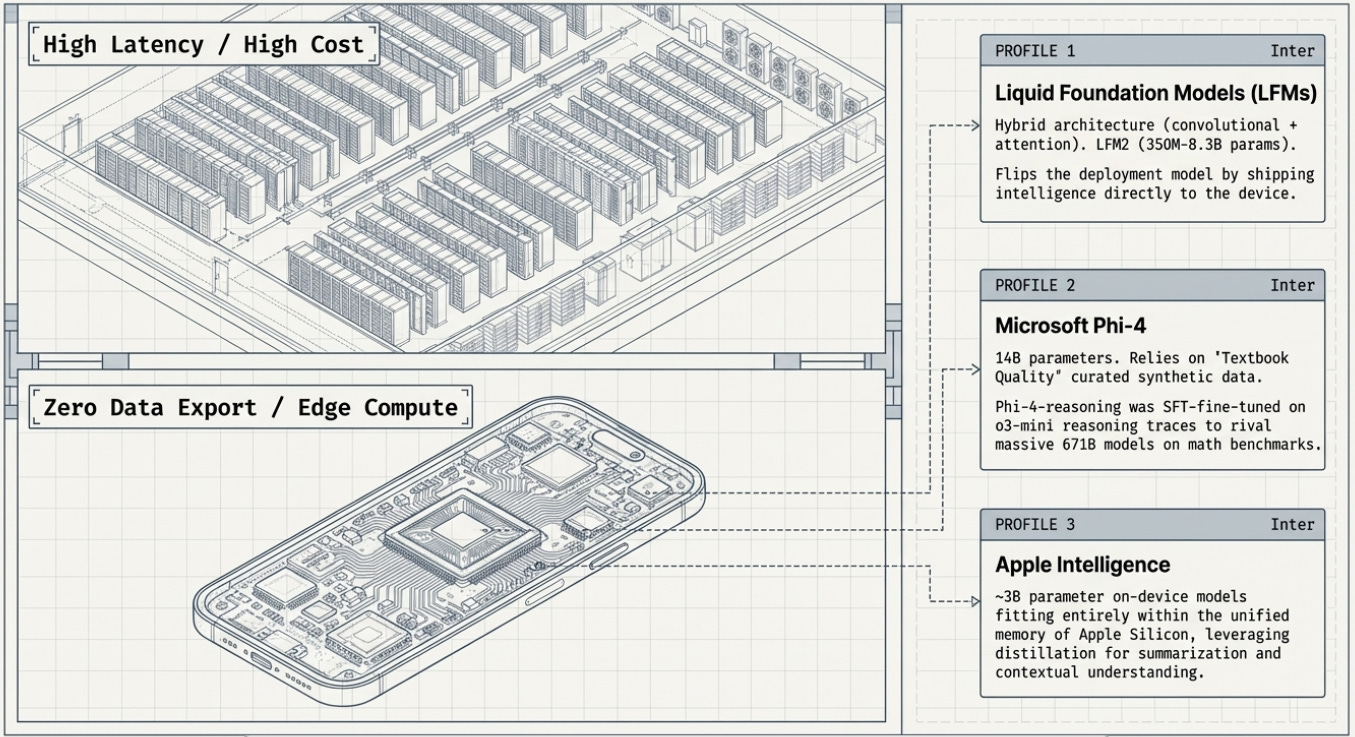
While the distillation drama plays out at the frontier, a quieter revolution is underway at the opposite end of the size spectrum. Liquid AI, a company spun out of MIT’s CSAIL (Computer Science and Artificial Intelligence Laboratory), has built an entirely different architecture for small AI models called Liquid Foundation Models (LFMs).
Unlike most AI models, which are based on the transformer architecture introduced by Google in 2017, LFMs use a hybrid architecture: a mix of short convolutional layers (which are extremely efficient for local pattern recognition) and a small number of grouped query attention blocks. This architectural innovation, combined with distillation from larger LFM models, produces models that run up to twice as fast as comparable-sized transformer models on standard CPUs.
Their LFM2 family ranges from 350 million to 8.3 billion parameters and is designed specifically for on-device deployment: phones, laptops, cars, wearables, and industrial robots. Crucially, LFM2 was itself trained using knowledge distillation — specifically using their larger LFM1-7B model as a teacher, with its cross-entropy outputs serving as the training signal throughout a 10-trillion-token training run.
Liquid’s ‘Nano’ models (350M to 2.6B parameters) have demonstrated GPT-4o-class performance on specialized agentic tasks despite being hundreds of times smaller. The CEO’s framing captures the paradigm shift: ‘Nanos flip the deployment model. Instead of shipping every token to a data center, we ship intelligence to the device.’
Microsoft Phi & Apple Intelligence: The Efficiency Revolution
Microsoft’s Phi series demonstrated something radical: ‘textbook quality’ training data — clean, curated, logically structured — beats internet-scale scraping for small models. The 2023 paper ‘Textbooks Are All You Need’ launched the Phi lineage, and each generation has pushed further. Phi-4 (14B parameters, December 2024) was itself partially distilled from GPT-4 outputs and then surpassed GPT-4 on STEM reasoning benchmarks — a student beating its teacher. Phi-4-reasoning (April 2025), fine-tuned on o3-mini reasoning traces, approaches DeepSeek-R1 (671B parameters) on competition mathematics despite being 48 times smaller. Phi-4-Mini (3.8B parameters, March 2025) matches models twice its size on math and coding. The full Phi-4 family is downloadable from Hugging Face under a permissive license.
Apple’s on-device AI models, powering Apple Intelligence features, similarly leverage distillation and architectural optimization to run sophisticated language and reasoning tasks entirely on an iPhone — with no data leaving the device. These models are compact enough (around 3B parameters) to fit in the unified memory of an Apple Silicon chip, yet capable enough to handle document summarization, email drafting, and contextual understanding.
The Kimi, GLM, and Qwen Families: China’s AI Tigers
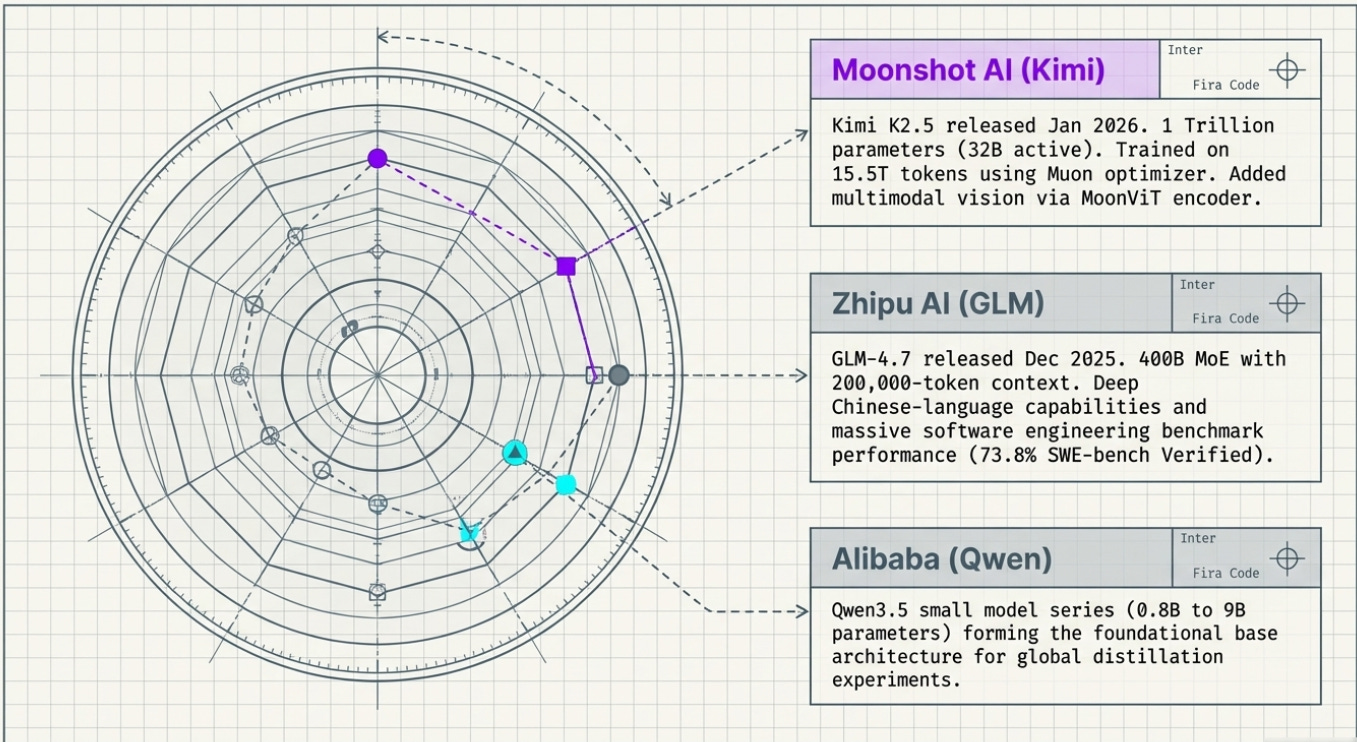
Beyond DeepSeek, China’s AI ecosystem has produced a remarkable number of capable open-weight models. Moonshot AI’s Kimi K2 (released July 2025 with 1 trillion total parameters, 32B active) is one of the most capable open-source agentic models in the world, trained on 15.5 trillion tokens using the novel Muon optimizer. Its January 2026 successor, Kimi K2.5, added multimodal vision via the MoonViT encoder. Both models are released under a modified MIT license. Moonshot has also released Kimi-Dev-72B, achieving 60.4% on SWE-bench Verified for software engineering. Whether any of these capabilities were seeded by the distillation operations against Claude remains contested.
Zhipu AI’s GLM (General Language Model) family has evolved at remarkable speed. By August 2025, GLM-4.5 — a 355B MoE model with just 32B active parameters — ranked 3rd overall on agentic benchmarks and outperformed Claude 4 Opus on AIME 2024. By December 2025, GLM-4.7 extended this to 400B parameters with a 200,000-token context window and a striking 73.8% on SWE-bench Verified. The architecture has evolved across multiple generations at Tsinghua University, giving it deep Chinese-language capabilities alongside strong English performance. And as recently as March 2, 2026, Alibaba’s Qwen team released the Qwen3.5 small model series (0.8B to 9B parameters) — adding to a rich, freely available ecosystem of base models that anyone can use to run their own distillation experiments.
How to Do It Yourself: A Practical Roadmap
What You Actually Need
The most important thing for a beginner to understand is that the barrier to entry for distillation-based model training has fallen dramatically. Here is what a well-resourced individual or small team actually needs:
• Hardware: A computer with a GPU — or a cloud account. AWS, Google Cloud, and Lambda Labs all offer GPU instances. The s1 experiment cost under $50 on cloud H100s. You can start experimenting for a few dollars.
• A base model: An open-source base model. Qwen3, Llama 3, Mistral, and Gemma are all freely available and form excellent starting points. These are downloadable from Hugging Face.
• A teacher model: Access to a capable teacher model. This could be Claude, GPT-4o, Gemini — accessible through their APIs — or a powerful open model like DeepSeek-R1. Be aware that using proprietary models’ outputs for training may violate their terms of service.
• Software: Python, PyTorch, and the Hugging Face ecosystem (transformers, datasets, trl). Sebastian Raschka’s book and GitHub repository provide step-by-step code.
• Training data: Ideally 100-10,000 high-quality (question, reasoning, answer) examples. The s1 paper proved you can get surprisingly far with 1,000 curated examples.
A Minimal Working Recipe


The Bigger Picture: What This Means for the Future of AI
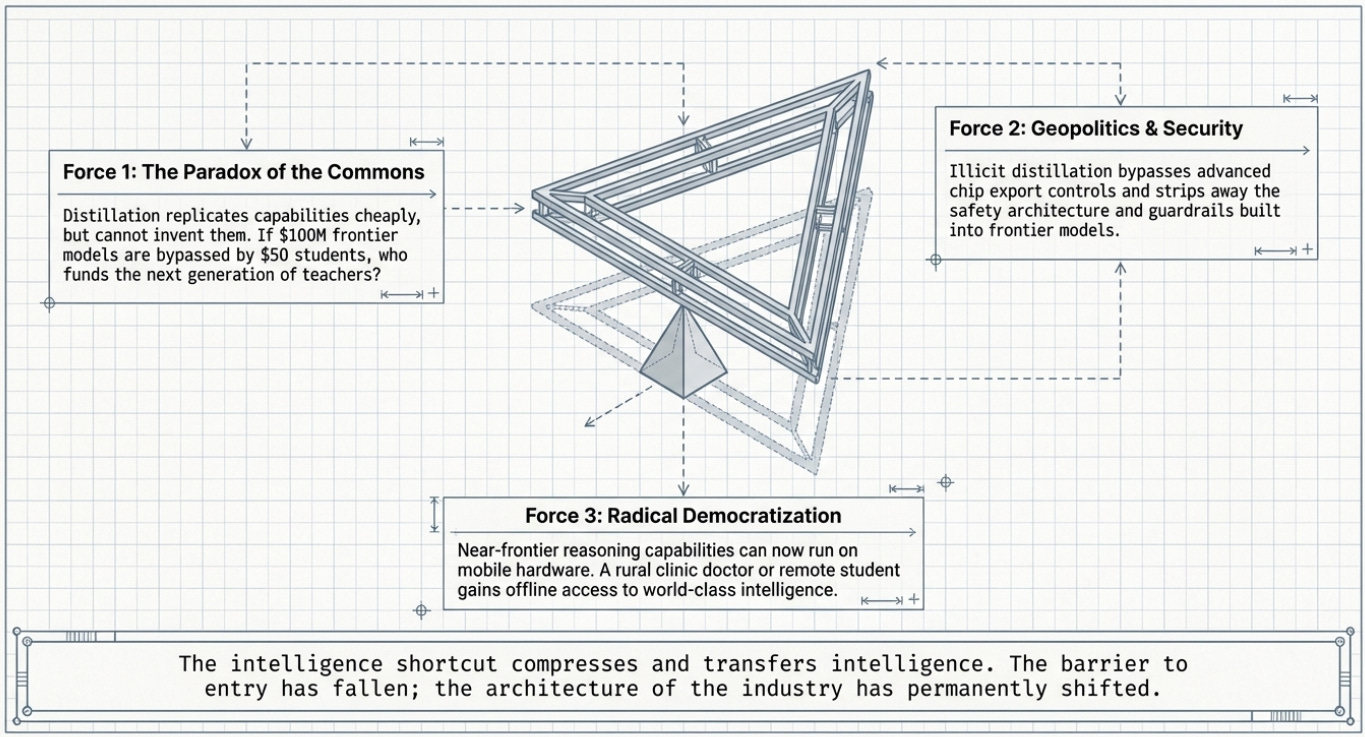
The Paradox of the Commons
Distillation creates a paradox for the AI industry. It is most valuable when frontier models exist to learn from — which means someone must still build those expensive frontier models. But if distillation makes it so cheap to replicate frontier capabilities, who will fund the next generation of frontier models?
As Databricks CEO Ali Ghodsi put it at the time of DeepSeek R1’s release: ‘This distillation technique is just so extremely powerful and so extremely cheap, and it’s just available to anyone.’ His implication was clear: the business models of frontier AI labs were under pressure in a world where their capabilities could be approximated for a few hundred dollars.
The counterargument is that distillation cannot exceed what the teacher can do. Frontier labs maintain a perpetual advantage at the absolute cutting edge. But the frontier moves quickly, and the gap between leading frontier capabilities and what’s achievable through distillation appears to be narrowing.
The Geopolitical Dimension
The controversy around Chinese labs distilling from American frontier models has become entangled with broader geopolitical competition. Anthropic and OpenAI have both framed unauthorized distillation as a national security concern, arguing that distilled models stripped of safety guardrails could be used for offensive cyber operations, disinformation, and surveillance.
There is genuine substance to this concern. Models built through illicit distillation may not retain the safety filters and refusals built into frontier models. A version of Claude’s capabilities without Claude’s safety architecture is a meaningfully different — and potentially more dangerous — artifact.
US export controls on advanced chips (particularly Nvidia’s H100 and Blackwell or future Rubin series) were designed partly to limit China’s ability to train frontier models from scratch. The distillation controversy reveals a gap in that strategy: even with chip restrictions, it may be possible to extract significant capabilities from frontier models through carefully designed API interactions — no advanced chips required for the extraction itself.
The Democratization Question
Step back from the geopolitics, and distillation looks like an unambiguous force for democratization. The fact that a Stanford grad student can replicate near-frontier reasoning capabilities for $50 is — if you set aside the legal and ethical questions about which teacher model was used — an extraordinary development for scientific research, education, and developing-world access to AI.
Liquid AI’s Nano models, running on an ordinary smartphone, embody this possibility. A doctor in a rural clinic with no internet connectivity can have a capable AI assistant on their phone. A student in a country with no data center infrastructure can have access to reasoning-grade AI. The intelligence can be shipped to the device rather than requiring the device to reach out to a distant cloud.
This is the dual nature of the intelligence shortcut: it simultaneously threatens the business models of those who built the frontier, raises genuine safety concerns, and offers genuine hope for broader access to AI’s benefits.
Reading List & Resources
Every model, lab, and concept mentioned in this guide has a primary source. The list below is organized so you can start wherever you are: a curious non-expert, a developer ready to build, or a researcher going deep. Each entry links directly to the paper, repository, or article.
Start Here: Conceptual Foundations
• Sebastian Raschka — ‘Understanding Reasoning LLMs’ (Substack, Feb 2025) — The clearest non-technical explanation of DeepSeek R1, distillation vs. RL, and the reasoning model landscape. Read this first.
• Anthropic’s distillation disclosure coverage — VentureBeat (Feb 2026) — Comprehensive coverage of the 24,000 fake accounts and 16 million Claude exchanges scandal, with legal and geopolitical context.
• Tom’s Hardware — Anthropic’s industrial-scale extraction disclosure — Detailed technical breakdown of the hydra cluster networks, the three labs involved, and how the extraction was detected.
• MIT Technology Review — What’s Next for AI in 2026 — Authoritative survey of the geopolitical and technical forces shaping AI’s direction, including the rise of open-weight models and distillation economics.
Hands-On Learning: Build It Yourself
• Sebastian Raschka — ‘Build a Reasoning Model From Scratch’ (GitHub repository) — The official companion code for Raschka’s book. Chapter 8 covers distillation data generation using a Qwen3 base model. Free to browse.
• ‘Build a Reasoning Model From Scratch’ — Chapter 8 distillation walkthrough — The specific chapter that prompted this guide. Step-by-step instructions for generating distillation data and running SFT fine-tuning.
• Manning Publications — ‘Build a Reasoning Model From Scratch’ (full book) — The complete book by Raschka. The most thorough beginner-to-expert guide for building distilled reasoning models from scratch.
• Hugging Face TRL Library — SFTTrainer documentation — The primary Python library for supervised fine-tuning. The SFTTrainer class is the main tool you will use in any distillation pipeline.
Stanford s1: The $50 Reasoning Model
• s1: Simple Test-Time Scaling — arXiv paper (2501.19393) — The original Stanford/UW paper. Clearly written and surprisingly accessible. Describes the 1,000-question dataset, 26-minute training, and ‘Wait’ budget-forcing trick.
• s1 GitHub repository (Stanford / simplescaling) — Complete code, data pipeline, and the full 1,000-question training dataset used to build s1. Everything needed to replicate the experiment.
• TechCrunch — ‘Researchers created an open rival to o1 for under $50’ — The news article that broke the s1 story to mainstream audiences. Accessible context for non-specialists.
Berkeley Sky-T1: $450 in 19 Hours
• Sky-T1: Train Your Own O1 Preview Model Within $450 — NovaSky blog post — The original write-up from the UC Berkeley Sky Computing Lab team. Explains the data curation, rejection sampling, and training approach.
• SkyThought GitHub repository (NovaSky-AI) — Fully open-source code, training scripts, and the 17,000-example dataset derived from QwQ-32B-Preview. Everything to replicate the $450 model.
• Sky-T1 model on Hugging Face (NovaSky-AI/Sky-T1-32B-Preview) — Downloadable model weights with full model card explaining architecture, training data, and benchmark results.
• TechCrunch — ‘Researchers open source Sky-T1, a reasoning AI model trained for less than $450’ — Mainstream news coverage of the Sky-T1 release, including context on how it compares to o1-preview.
DeepSeek: The Model That Shocked Wall Street
• DeepSeek-R1 Technical Report — arXiv (2501.12948) — The complete technical paper describing DeepSeek’s training approach, including the RL pipeline and the SFT distillation used for the smaller R1-Distill family. Essential reading.
• DeepSeek-R1 model weights and code (GitHub) — The official DeepSeek repository with model weights, inference code, and links to all model variants from 1.5B to 671B parameters.
• DeepSeek-R1 distilled models on Hugging Face — All DeepSeek models including the distilled Qwen and Llama variants (1.5B, 7B, 8B, 14B, 32B, 70B). Downloadable under MIT license.
Moonshot AI / Kimi: Long Context and Agentic Intelligence
• Kimi K1.5 Technical Report — arXiv — Moonshot’s technical paper on K1.5, describing their reinforcement learning approach to building an o1-level multimodal reasoning model.
• Kimi K2 — GitHub repository (MoonshotAI/Kimi-K2) — Open-source code and deployment guide for Kimi K2, the 1-trillion parameter MoE model. Includes the technical report PDF and model weights on Hugging Face.
• Kimi K2.5 — GitHub repository (MoonshotAI/Kimi-K2.5) — The January 2026 multimodal upgrade to K2, adding native vision via the MoonViT encoder. Technical report and model weights.
• Moonshot AI — Wikipedia overview — Comprehensive timeline of Moonshot’s model releases, funding rounds, and the February 2026 Anthropic distillation controversy.
MiniMax: Lightning Attention and 1-Million Token Contexts
• MiniMax-01 Technical Report — arXiv (2501.08313) — The paper introducing MiniMax-Text-01, with 456B total parameters and a 1-million-token context window enabled by the lightning attention mechanism.
• MiniMax-01 GitHub repository (MiniMax-AI/MiniMax-01) — Official code and model weights for MiniMax-Text-01 and MiniMax-VL-01. Includes inference examples and deployment instructions.
• MiniMax-M1 Technical Report — arXiv (2506.13585) — The follow-on reasoning model combining hybrid MoE architecture with RL training (CISPO algorithm). Full RL training completed for ~$534,700 on 512 H800 GPUs.
• MiniMax-M1 GitHub repository (MiniMax-AI/MiniMax-M1) — Open-source code for the world’s first open-weight large-scale hybrid-attention reasoning model.
GLM / Zhipu AI: From Tsinghua to the World
• ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 — arXiv (2406.12793) — The comprehensive technical report covering the full GLM lineage from early Tsinghua research through GLM-4 and its All Tools variant.
• GLM-4 GitHub repository (zai-org/GLM-4) — Official open-source repository for the GLM-4 family, including GLM-4-9B and the 32B variants. Inference code and model cards included.
• GLM-4.5: Agentic, Reasoning, and Coding — arXiv (2508.06471) — Technical report on GLM-4.5, a 355B MoE model that ranks 3rd overall on agentic benchmarks, beating models much larger than itself.
• GLM-4.5 GitHub repository (zai-org/GLM-4.5) — Open-source code, weights, and deployment instructions for GLM-4.5 and the compact GLM-4.5-Air (106B) variant. Inc GLM-4.6, GLM-4.7.
• DeepLearning.AI — GLM-4.5 release coverage — Accessible coverage of GLM-4.5’s release and its notable use of multi-expert distillation into a compact base.
Microsoft Phi: Textbook Quality Over Brute-Force Scale
• Phi-4 Technical Report — arXiv (2412.08905) — The definitive paper on Microsoft’s Phi-4 14B model, explaining the ‘textbook quality data’ philosophy and how phi-4 surpassed its GPT-4 teacher on STEM benchmarks.
• Phi-4-Mini Technical Report — arXiv (2503.01743) — Paper on Phi-4-Mini (3.8B parameters) and Phi-4-Multimodal, which processes text, vision, and speech simultaneously. Shows 3.8B matching models twice its size on reasoning.
• Phi-4-reasoning Technical Report — Microsoft Research — Describes how Phi-4 was SFT-fine-tuned on o3-mini reasoning traces to create a 14B model approaching DeepSeek-R1 (671B) on mathematics benchmarks.
• Phi-4 model family — Hugging Face (microsoft/phi-4) — All Phi-4 model weights including Phi-4-Mini, Phi-4-Multimodal, Phi-4-reasoning, and Phi-4-reasoning-plus. Downloadable for local deployment.
• ‘Textbooks Are All You Need’ — the founding philosophy paper (arXiv 2306.11644) — The 2023 paper that launched the Phi series. Argues that training on curated ‘textbook quality’ synthetic data beats internet-scale scraping for small models.
Liquid AI: Intelligence on the Device
• LFM2 Technical Report — arXiv (2511.23404) — Liquid AI’s detailed paper on their hybrid architecture and knowledge distillation approach for models from 350M to 8.3B parameters designed for on-device deployment.
• Liquid AI — LFM2 official blog post — Liquid’s own explanation of LFM2’s architecture, training pipeline, and what ‘Nano’ models running at GPT-4o-class on a phone actually means.
The Academic Foundations
• Distilling the Knowledge in a Neural Network — Hinton et al. (arXiv 1503.02531) — The 2015 paper that introduced knowledge distillation to deep learning. The idea of ‘soft labels’ and teacher-student training. Historically foundational.
• A Survey on Knowledge Distillation of Large Language Models — arXiv — Comprehensive 2024 academic survey mapping every major distillation technique for LLMs. Excellent reference once you understand the basics.
• Chain-of-Thought Prompting Elicits Reasoning in Large Language Models — Wei et al. — The paper that introduced chain-of-thought prompting — the technique that makes distillation of reasoning capabilities possible by having teachers show their working.
The intelligence shortcut is real — and it’s reshaping who gets to build AI, at what cost, and for whose benefit.
The question is no longer whether small models can match frontier giants. The question is what we do with that fact.
A fantastic write up, with evidence, stunning visuals and a roadmap to do it yourself. Good job!
Personally I’d rather tweak the system prompt of the existing well prepared and tested LLM than train or distill a new one