
The Invisible Codebase
250 Billion Lines of Business Logic That Nobody Fully Understands, Why AI Is Finally Making It Extractable, and What the Practitioner Toolkit Looks Like in 2026


In early 2026, a single Anthropic blog post about Claude Code and COBOL erased nearly $40 billion from IBM’s market capitalisation in a day (Note: IBM shares not only fully recovered from its $40 billion market cap drop, but the stock recently reached all-time highs - some of it better understood by reading through and understanding the experiment I ran). That reaction was not panic — it was the market correctly pricing a structural shift. This article surveys the landscape that shift created: what IBM, Amazon, and specialist firms are actually deploying at enterprise scale; whether Claude Code can perform meaningful migration without a structured framework; where Reversa (an open-source methodology released May 2026) fits in the ecosystem; and what a practitioner might learn by building and running a five-agent migration pipeline on their own machine. The central argument is that the tool matters far less than the methodology — specifically, the distinction between syntactic code translation and operational contract reconstruction, and the confidence tagging system that makes human oversight tractable rather than exhausting.
Note: The experiment relies on assumptions of a hypothetical but working code base written in COBOL. Tools of analysis were selected based on the requirements of the case study. Different models, harnesses and agentic pipelines can produce varying results, which depend on the methodologies applied herein.
The Post That Moved Markets
In February 2026, Anthropic published a post describing how Claude Code could automate the exploration and analysis of COBOL codebases. The announcement was technically measured — careful about what AI could and could not do. The market was less measured. IBM’s stock fell thirteen percent in a single session, its worst single-day loss since 2000. The trigger was a blog post about a 67-year-old programming language.
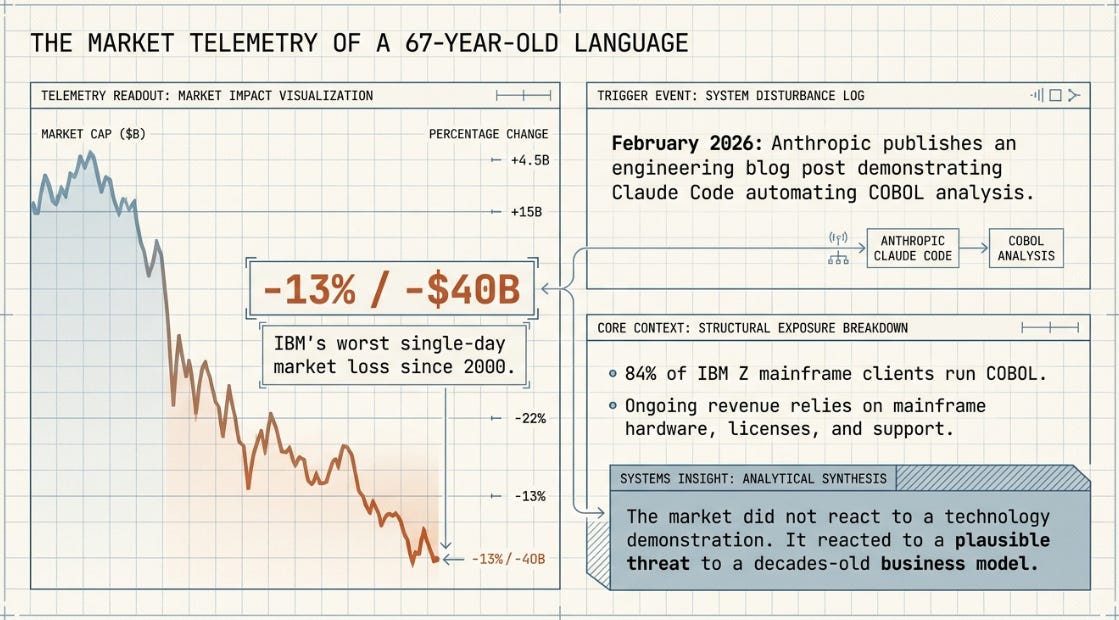
To understand why, you need to understand what COBOL represents to IBM’s business model. Approximately 84 percent of IBM’s Z mainframe clients are running COBOL applications. Those clients pay substantial ongoing fees for mainframe hardware, software licences, and specialised support. If AI could meaningfully accelerate the migration of those workloads off mainframe and onto commodity cloud infrastructure, the revenue implications for IBM were severe. The market priced that risk immediately.
Whether the market’s reaction was proportionate is a separate question. What it confirmed, beyond any industry analyst’s forecast, is that AI-assisted legacy migration has crossed from speculative to credible in the minds of the people who allocate capital. That is the moment this article is written inside.
The market did not react to a technology demonstration. It reacted to a plausible threat to a decades-old business model. Those are different things, and the distinction matters for how you think about this space.
What Is Actually Being Migrated — and Why It Is Hard
The scale figures are well known: an estimated 250 billion lines of COBOL in production worldwide, processing roughly 95 percent of ATM transactions and 80 percent of in-person credit card transactions daily. What is less often articulated is why migrating this code is structurally different from migrating any other software.
The answer is that a COBOL program written in 1985 and maintained through 2026 contains two codebases that are technically inseparable but conceptually distinct.
The Visible Codebase
Source files, database schemas, JCL job scripts, copybooks. Everything a developer or AI agent can read. This is what most migration tools operate on.
The Invisible Codebase
The accumulated decisions, regulatory adaptations, and implicit business rules that were never formally documented. The $9,500 threshold that was set in 1994 in response to a specific FinCEN guidance letter and exists nowhere except as a literal constant in a PROCEDURE DIVISION paragraph. The leap-year interest divisor that differs between account types for a reason that retired with the person who coded it. The DTI ceiling that was adjusted after a 2008 OCC examination finding and has never appeared in any policy document since.
Any migration approach that ignores the invisible codebase produces code that passes all its tests in a UAT environment and fails in production when it encounters the exact condition the invisible rule was written to handle. This has happened, repeatedly and expensively, at organisations that attempted big-bang migrations using earlier-generation automated tools.
THE CORE INSIGHT
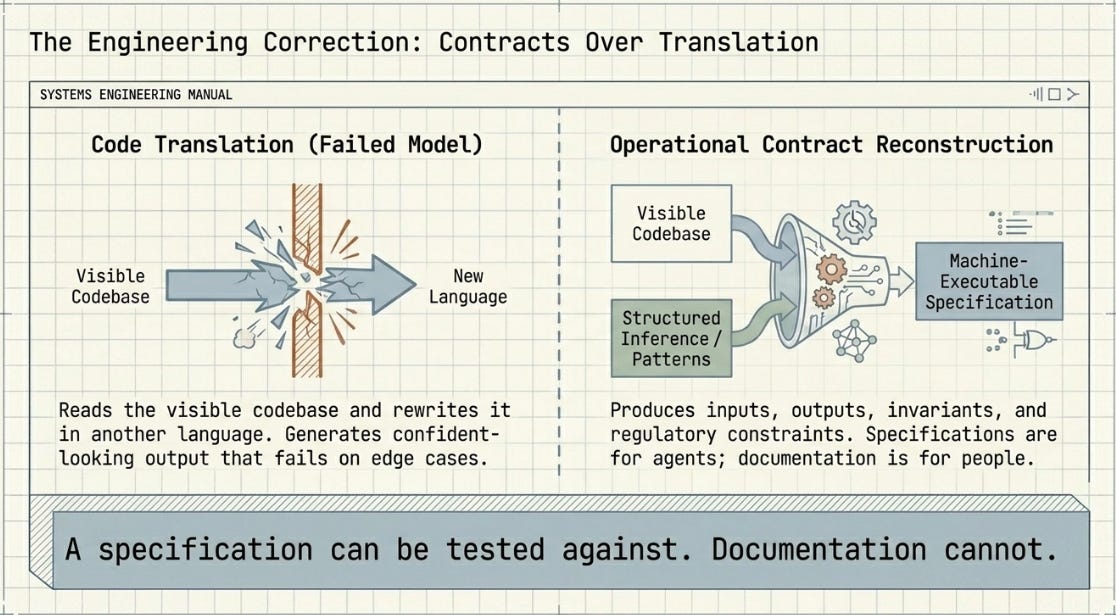
This is why the distinction between code translation and operational contract reconstruction is not academic. Code translation reads the visible codebase and rewrites it in another language. Operational contract reconstruction reads both codebases — the visible one from the source, the invisible one from patterns, comments, regulatory citations, and structured inference — and produces a specification that an agent can safely use as a migration target.
The Institutional Landscape: What Enterprises Are Actually Using
Three distinct tiers have emerged, with very different economics, target audiences, and architectural philosophies.
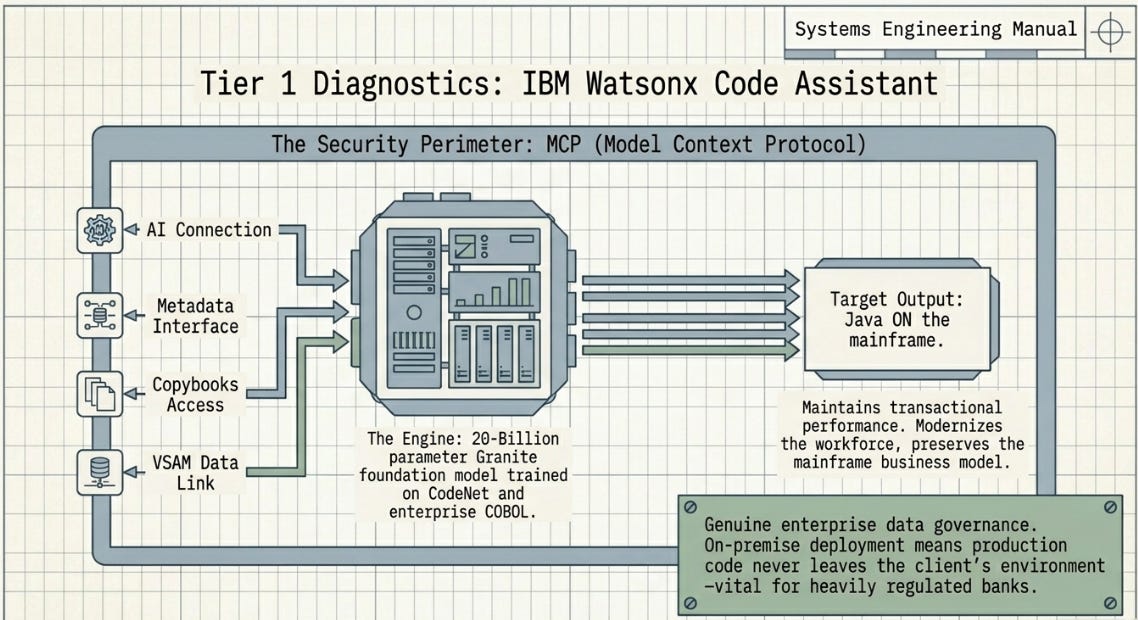
Tier 1 — IBM Watsonx Code Assistant for Z
IBM’s response to the migration moment is a dedicated enterprise product: Watsonx Code Assistant for Z. The architecture is revealing. IBM trained a 20-billion parameter Granite foundation model on CodeNet — one of the largest code datasets available — supplemented by enterprise COBOL specifically to ensure the model understands the language’s idiosyncrasies rather than treating it as a dialect of something more common.
The target migration is COBOL to Java, not to Python or any other language. This is a deliberate choice: Java on IBM Z maintains the performance and transactional characteristics of the mainframe runtime while moving the code to a language with a large modern developer workforce. IBM is not trying to move workloads off mainframe — it is trying to modernise workloads while keeping them on mainframe. The business model preservation is explicit.
Version 2.8, released March 2026, introduced an agentic workflow using MCP (Model Context Protocol) to connect the AI to mainframe-specific data sources — job control metadata, copybook libraries, VSAM data definitions. The result is a system with genuine enterprise data governance: code never leaves the client’s environment if they use the on-premise deployment option, which matters considerably to banks that are legally restricted from transmitting certain data to external cloud services.
Pricing is enterprise. Deployment requires IBM Z hardware and software stack. The addressable audience is a few hundred institutions globally with the largest COBOL estates.
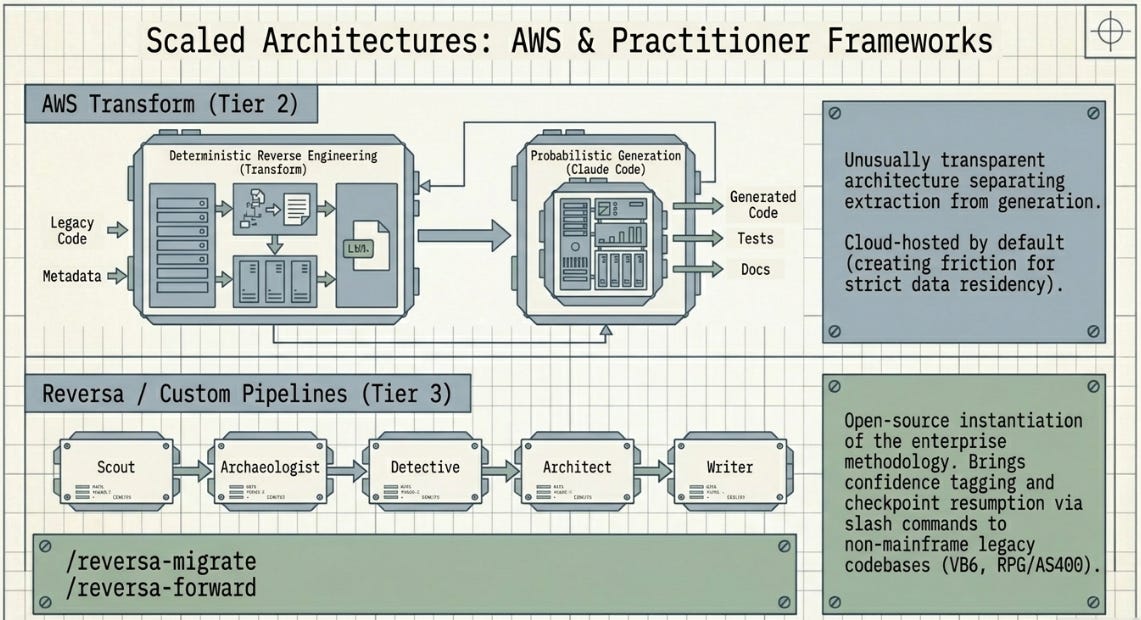
Tier 2 — AWS Transform and the Claude Code Partnership
Amazon’s approach is architecturally the most instructive for understanding what actually works at scale, because AWS has been unusually transparent about why it made the architectural choices it did.
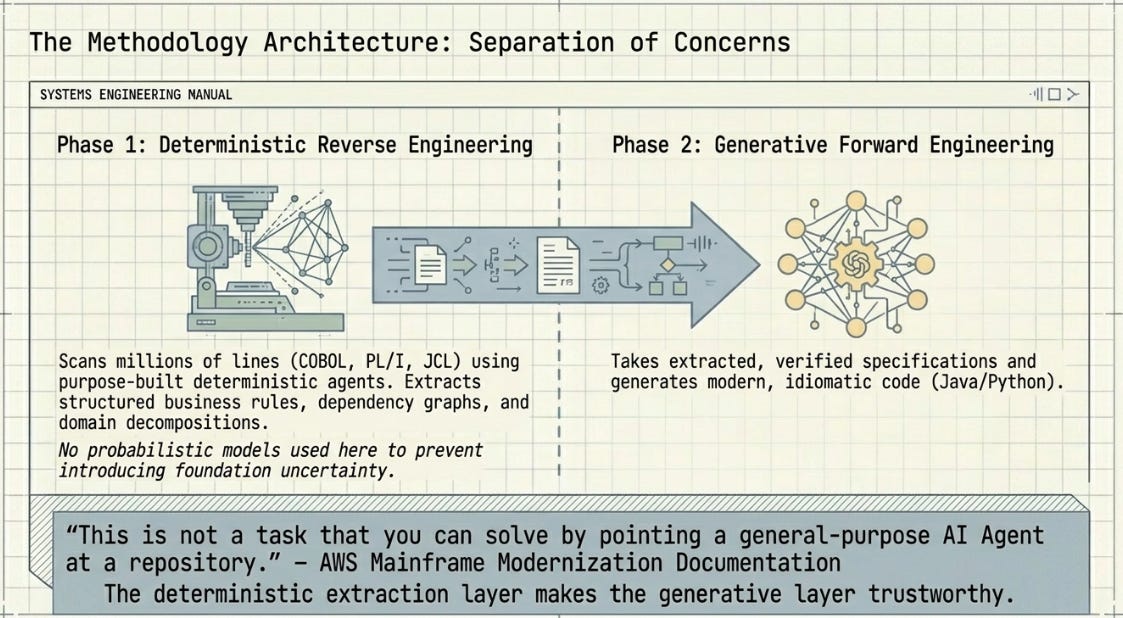
AWS Transform handles reverse engineering. It deploys specialised deterministic agents that scan entire codebases — potentially millions of lines of COBOL, PL/I, and JCL — extracting structured business rules, dependency graphs, data lineage maps, and domain decompositions. The keyword is deterministic: AWS’s documentation explicitly states that this extraction uses purpose-built tools rather than probabilistic models, because probabilistic models at this stage introduce the kind of uncertainty that makes the downstream migration untrustworthy.
For the forward engineering phase — taking those extracted specifications and generating modern code — AWS recommends Claude Code. Their own published workflow blog post states this directly: AWS Transform produces the reliable foundation, Claude Code does the generation. The separation is the architecture.
THE AWS INSIGHT
“This is not a task that you can solve by pointing a general-purpose AI Agent at a repository.” AWS’s own documentation on its enterprise mainframe service. The deterministic extraction layer is not a nice-to-have — it is what makes the generative layer trustworthy.
Transamerica, Allianz, and Marriott Hotels are among AWS’s referenced enterprise modernisation clients. The service is cloud-hosted, not on-premise by default, which creates friction for the most heavily regulated banking institutions. AWS addressed this partly by acquiring Blu Age, a French automated refactoring company that handles automated COBOL-to-Java conversion for clients who want deterministic transformation rather than LLM-generated output.
Tier 3 — Specialist Firms and Proprietary Methodologies
A third tier of specialist companies approaches the problem from a fundamentally different angle. One illuminating example is Phase Change Software, whose product COBOL Colleague uses graph-based deterministic analysis to establish verified facts about COBOL programs before any LLM is involved. Their characterisation of Claude Code’s role is precise: “The LLM translates our verified facts into fluent prose. While Claude Code struggles to present the facts, it excels at narrating them.”
The consulting firms — Accenture, Deloitte, IBM Consulting — operate at the intersection of all three tiers, typically deploying combinations of vendor tools alongside proprietary frameworks developed through years of actual migration engagements. Their differentiator is not the AI; it is the pattern library of edge cases, regulatory nuances, and failure modes accumulated from real migrations.
The Uncomfortable Reality Most Skip
Most large financial institutions are not migrating their COBOL. They are running it, carefully, and managing the risk of the aging workforce through knowledge transfer programmes, documentation initiatives, and strategic hiring of the few remaining COBOL-fluent developers. The migration momentum exists at second-tier institutions and government agencies, not at the top twenty global banks, most of which have attempted and partially failed major migration efforts in the past two decades and carry institutional scar tissue from those experiences.
AI-assisted migration changes the economics and the risk profile of attempting it. It does not eliminate the need for judgment, the risk of missing an invisible rule, or the regulatory requirement to prove behavioral equivalence before cutover. Those constraints remain structural regardless of which tool sits in the pipeline.
Can Claude Do It Without a Structured Framework?
This is the question practitioners naturally ask, and it deserves a direct answer rather than a diplomatic one.
Yes, with important caveats. Claude, prompted carefully, can read a COBOL program, identify its business rules, generate idiomatic Python, and write tests that verify the output. For a clean, well-commented COBOL program with regulatory citations in comments and consistent naming conventions, the results are genuinely useful on a first pass.
The TechChannel evaluation team tested Claude Code on real Medicare payment COBOL — not the kind of clean example used in tutorials — and documented specific failure modes: dropped conditional branches, compressed algorithms that merged adjacent logic, and incorrect regulatory constants. Their conclusion was blunt: in a financial or healthcare system, the difference between “mostly correct” and “correct” is the difference between compliance and liability.
Three things that a structured framework adds, which raw prompting does not:
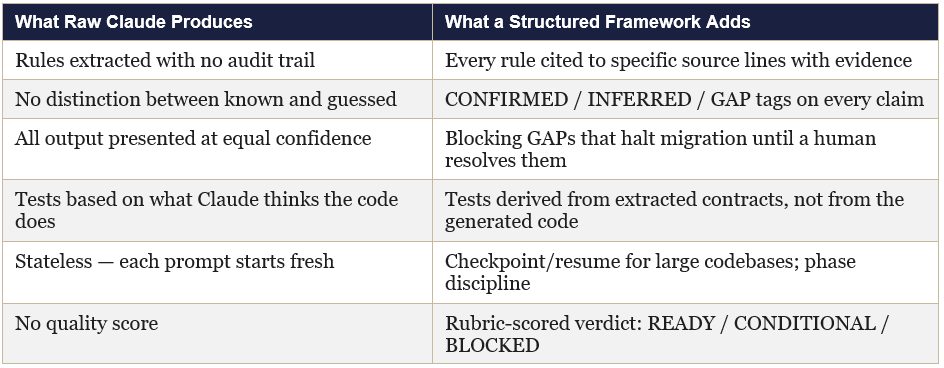
The AWS architecture described above encodes exactly this lesson at enterprise scale. The structured extraction layer produces what raw prompting cannot: verifiable, traceable, confidence-tagged foundations that a generative model can safely build on.
Where Reversa Fits: Honest Assessment
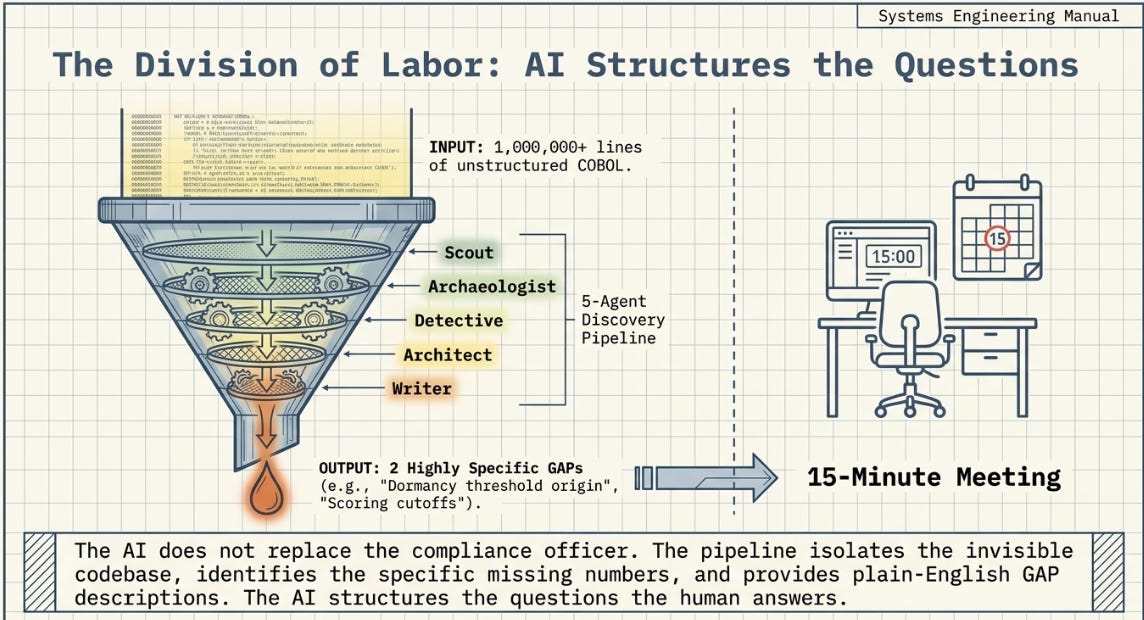
Reversa, released in May 2026 by Macedo and da Costa, is the open-source instantiation of the same methodology that IBM and AWS apply at enterprise scale. It is not competing with Watsonx Code Assistant for Z. It is making the methodology accessible to practitioners who do not have a mainframe contract or a seven-figure modernisation budget.
What Reversa contributes technically is a structured coordination layer for Claude Code: the five-phase Discovery pipeline (Scout, Archaeologist, Detective, Architect, Writer), the confidence tagging system, the SDD (Software Design Document) output format, and the slash command interface (/reversa, /reversa-migrate, /reversa-forward) that provides phase discipline and checkpoint resumption. The AI capability underneath is Claude. The value Reversa adds is the methodology wrapping.
To be honest about what this means: a skilled prompt engineer with enough time could replicate Reversa’s core functionality. The project’s genuine contribution is that it has done that work, made it publicly available, and embedded in it the methodological discipline — particularly the confidence tagging and GAP system — that most ad hoc approaches omit.
Where Reversa Is Strong
• Non-mainframe legacy: VB6, RPG/AS400, older Java EE, PL/I, FORTRAN — the long tail of enterprise legacy that IBM’s mainframe-specific tools do not address.
• Practitioner scale: A single developer or small team working on a bounded legacy system. The overhead of an enterprise migration platform is unnecessary and counterproductive at this scale.
• Learning and research: Understanding the methodology, experimenting with different COBOL programs, building institutional knowledge before committing to a production migration.
• The forward evolution use case: The /reversa-forward command, which propagates regulatory or policy changes through an already-migrated system, is particularly well-suited to insurance policy administration where rules change continuously.
Where Reversa Has Limits
• Million-line mainframe codebases: Enterprise COBOL estates are too large for Claude Code’s context window without the deterministic scaffolding that AWS Transform or IBM’s ADDI tool provides.
• Regulatory data governance: A bank subject to strict data residency rules cannot send production COBOL to a cloud-hosted Claude model. IBM’s on-premise option exists specifically for this constraint.
• The invisible codebase still needs humans: No tool, including Reversa, can answer what a threshold means if it is undocumented. GAP resolution requires domain expertise regardless of how well the framework surfaces the GAPs.
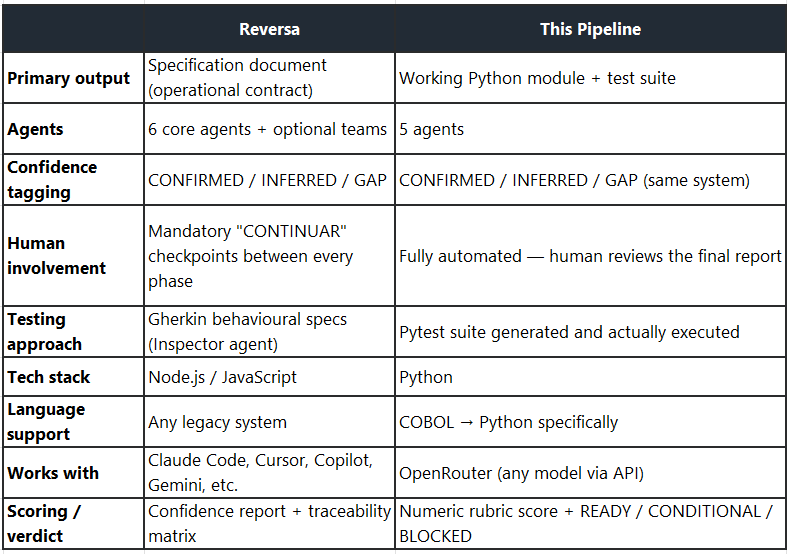
Custom Pipeline vs Reversa
What Reversa Is Trying to Do
So I decided to run my own pipeline: COBOL → Python. Reversa and my simple pipeline solve different problems, which is why both can be working solutions.
Reversa asks: “What does this legacy system actually do?” — It reverse-engineers the system into a specification document that humans and AI coding agents can use as a blueprint going forward. The output is knowledge, not code.
This pipeline asks: “Can we run this COBOL as Python today?” — It goes straight to a working translation, tests it, and scores it. The output is runnable code with a verdict.
Why Both Achieve Their Objectives
Reversa succeeds because it doesn’t try to produce code — it produces understanding. By making humans approve each phase, it catches the INFERRED and GAP items before they become bugs in production. It is more conservative and more thorough for complex, undocumented systems where you cannot afford to guess.
This pipeline succeeds because it narrows the problem. By committing to one target language (Python) and one output (runnable code), it can automate the full loop — translate, test, score — in under 3 minutes. The tradeoff is that it will confidently produce something wrong if the COBOL had undocumented assumptions.
The Honest Observation
Both projects use the exact same CONFIRMED / INFERRED / GAP confidence model. That convergence is not a coincidence — it is the fundamental truth of legacy migration: some things are knowable from the code, some things are educated guesses, and some things require a human who was there. No amount of AI sophistication eliminates that third category.
Reversa builds its entire workflow around that fact and refuses to proceed without human sign-off. This pipeline surfaces it in the final report and issues a BLOCKED verdict when too many GAPs exist. Different mechanisms, same underlying problem.
If you are migrating a payroll system or an AML engine that has been running in production for 30 years, Reversa’s approach — slow, documented, human-approved at every step — is the safer choice. If you want a quick first-pass translation to understand the scope of effort, this pipeline gets you there faster. Albeit not perfectly, but with a bit of fine-tuning, and sit-down sessions - all doable.
Building It Yourself: What the Custom Pipeline Reveals
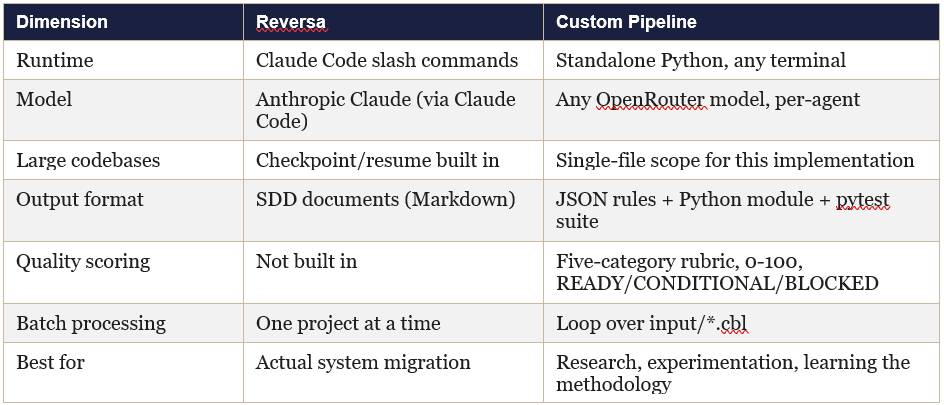
A five-agent pipeline built in the companion experiment to this article (only results shared here) took a different architectural approach from Reversa: standalone Python running via OpenRouter rather than Claude Code slash commands. This was a deliberate choice, and the difference is instructive.
Each stage in the pipeline is a separate AI agent — a distinct model with its own system prompt and specific job. Because this was a “lab experiment” for me, and given fairly straightforward, uncomplicated code, earlier model versions were applied. Here's what each one did on a sample AML-TEST.cbl run:
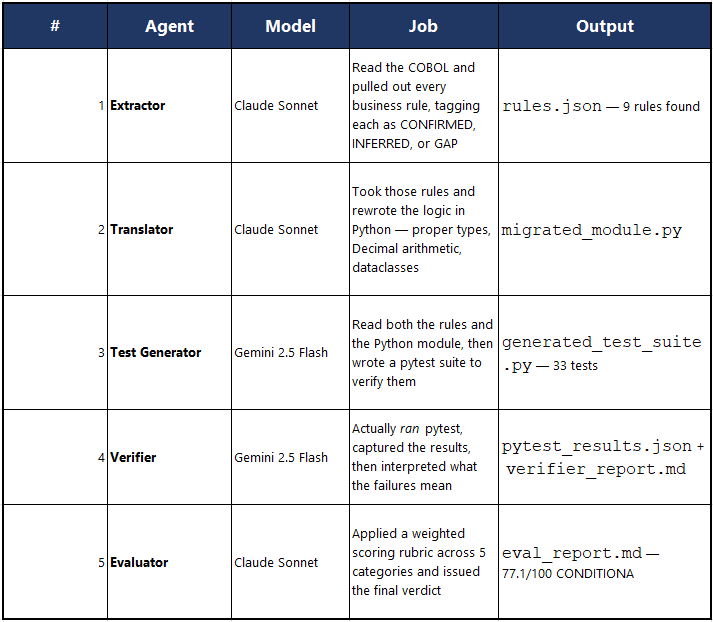
Each agent only sees what it needs — the Translator never sees the test code, the Evaluator never touches the COBOL. They pass work forward like an assembly line, with the orchestrator (orchestrator.py) coordinating the handoffs.
The faster/cheaper Gemini models handle the mechanical work (write tests, run tests). The more capable Claude models handle the reasoning-heavy work (understand COBOL intent, judge migration quality). That’s the cost/quality tradeoff baked into the design.
Running the pipeline on an AML transaction screening program produced a complete extraction, idiomatic Python with Decimal arithmetic throughout, a 33-test pytest suite, and an evaluation report scoring 77.1/100 with a CONDITIONAL verdict.
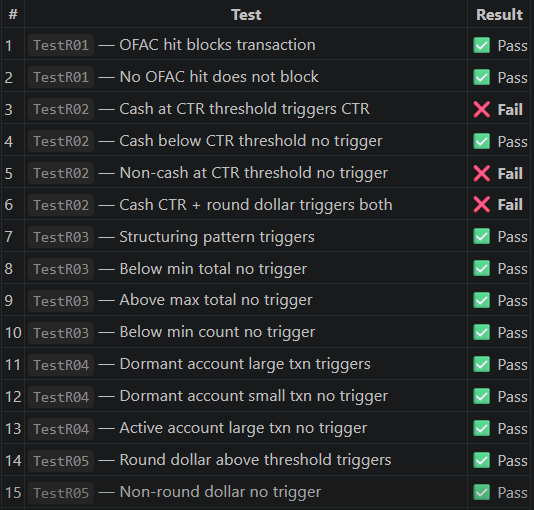
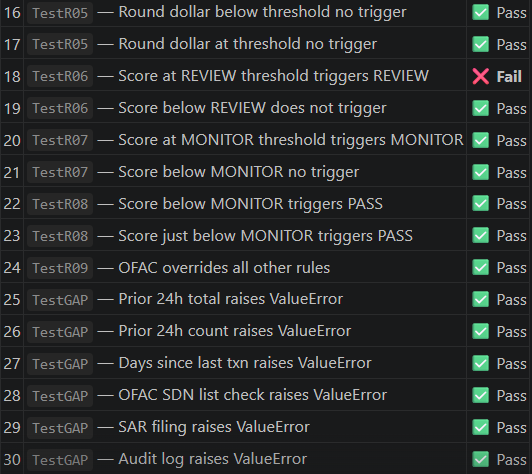

All 5 failures trace to the same root cause: $10,000 is a round number divisible by 1,000, so the round dollar rule fires on every CTR-level cash transaction. The tests expected those to be treated as separate, independent events — but the generated Python doesn't distinguish them. Fix the round dollar rule's logic and tests 3, 5, 6, and 18 likely resolve automatically. Test 33 fails separately because the dormant activity rule doesn't fire in the combined scenario — that needs a separate look at migrated_module.py.
The Honest Assessment for Leadership
AI did not “convert COBOL to Python.” What it did was:
Draft a working translation that gets you most of the way there — faster than a team starting from scratch
Surface the gaps — the areas where the COBOL was relying on undocumented assumptions, external systems, or institutional memory. Without this tool, a developer might not even know those gaps existed until something failed in production
Write and run a test suite that identified real defects before anyone deployed anything
What it could not do — and no AI currently can do — is:
Validate that inferred business rules match your compliance policy
Connect to your sanctions screening system (not in this test)
Decide when to file a SAR
Vouch for regulatory correctness
The analogy: think of this like a very fast, very thorough junior analyst who read the old system overnight, wrote up a detailed summary, drafted new code, and flagged everything they were uncertain about. You still need a senior compliance officer and an engineer to review the flagged items before this goes anywhere near production.
Recommended Next Steps
Compliance review of the 6 inferred rules — specifically the $8,500 structuring threshold. Is that your institution’s policy, or did the AI make it up?
Engineering fixes for the 5 failing tests — these are known, specific defects and should be straightforward to correct once the correct logic is confirmed
Integration planning for the 4 GAPs — OFAC, aggregation, SAR filing, and audit logging each require a conversation with the teams that own those systems
Do not go live until the score reaches READY (≥ 80) with zero blocking GAPs. The current state is a solid foundation, not a finished product.
The pipeline saved weeks of initial translation work. It did not save the compliance validation, integration work, or human judgment that AML systems legally require. That was never going to be automated away.
Code is now the cheap part of legacy migration. Architecture judgment and domain knowledge are the expensive parts. That was always true. AI makes it undeniable.
The Methodology Is the Point
At every tier of the market — IBM’s enterprise Granite model, AWS’s deterministic Transform agents, Reversa’s open-source pipeline, the custom five-agent Python implementation — the same architectural decision appears: separate the extraction of what the code knows from the generation of what the new code should say. The tools differ enormously. The methodology is consistent.
Three elements of that methodology deserve emphasis because they are what makes the difference between a migration that produces useful output and one that produces confident-looking output that fails when it encounters an edge case:
Operational Contracts, Not Documentation
The output of the extraction phase should be machine-executable specifications — inputs, outputs, invariants, regulatory constraints, edge cases — not human-readable documentation. Documentation is for people. Specifications are for agents. The difference is that a specification can be tested against. Documentation cannot.
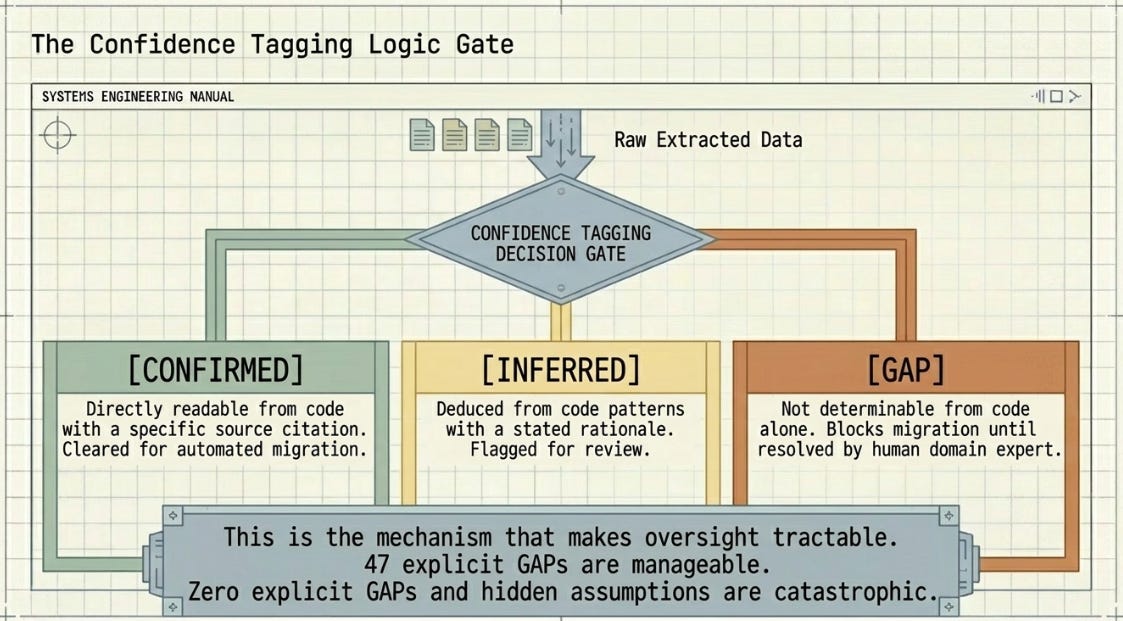
The Confidence Tagging System
Every extracted claim should carry one of three marks: CONFIRMED (directly readable from code with a source citation), INFERRED (deduced from pattern with a stated rationale), or GAP (not determinable from code, requires human input). This is not administrative overhead. It is the mechanism that makes human oversight tractable. A migration with 47 GAPs to review is manageable. A migration with no explicit GAPs and hidden assumptions is not.
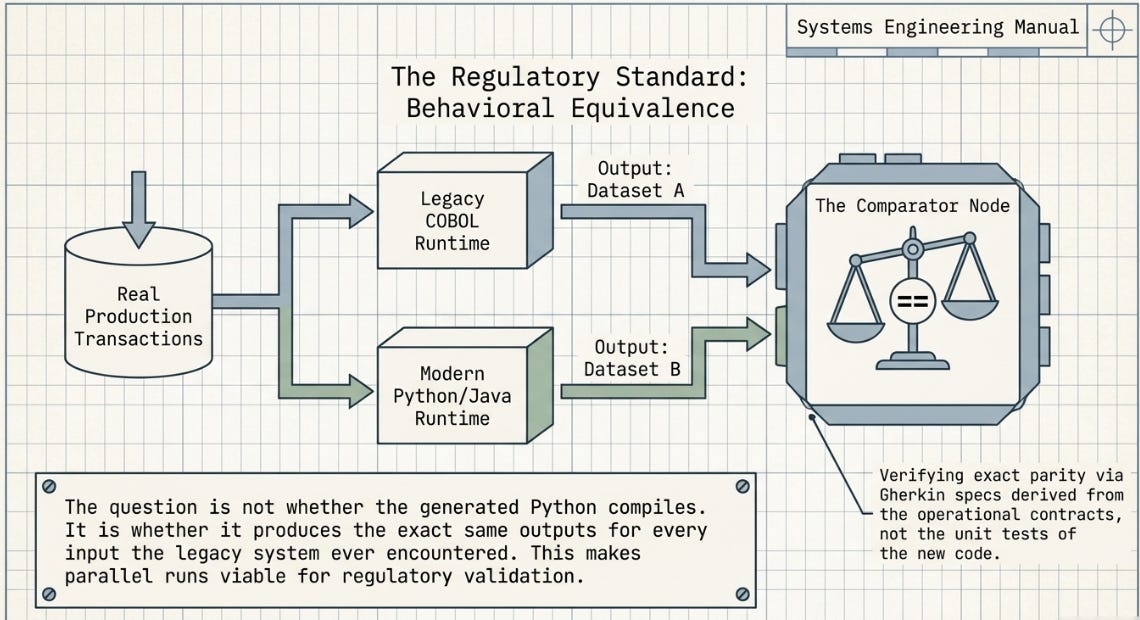
Behavioral Equivalence as the Standard, Not Code Correctness
The question is not whether the generated Python compiles and passes unit tests. It is whether the Python produces the same outputs as the COBOL for every input the COBOL ever encountered. Gherkin parity specs derived from the extracted contracts — not from the generated code — are the appropriate test artefact for this standard. This is what makes a Parallel Run viable as a regulatory validation mechanism: both systems run simultaneously against real transactions, and every divergence is documented and investigated.
Verdict: Was This Worth My Time & Tokens?
The practitioner’s question is blunt: given that IBM has a purpose-built enterprise tool, AWS has a cloud service with Fortune 500 references, and Anthropic itself publishes guidance on using Claude Code directly for COBOL analysis, is there genuine value in understanding and running an open-source framework or custom pipeline?
The answer depends on what you are optimising for.
If you are evaluating migration tooling for an institution
The institutional tier tools (IBM, AWS) have genuine advantages for large mainframe estates: security, data governance, enterprise support, and provenance from organisations with skin in the game. For a bank with ten million lines of COBOL running on IBM Z hardware, Watsonx Code Assistant for Z is the serious option. For a mid-size insurer wanting to modernise a policy administration system to cloud, AWS Transform with Claude Code forward engineering is the serious option. Neither requires you to understand Reversa or build your own pipeline.
If you are a practitioner-researcher, consultant, or reader
The methodological insight — structured extraction, confidence tagging, operational contracts, GAP-driven human oversight — is what you need to understand regardless of which tool sits on top of it. Building and running the custom pipeline teaches you this in a way that reading about IBM’s product does not. The experiments in this series used a simple AML screening program rather than a million-line mainframe system, but the methodology scales. The same principles govern both.
Reversa is worth your time as a learning and research instrument. It is also worth writing about, not because it will replace IBM Watsonx Code Assistant for Z, but because it makes the methodology accessible and demonstrates that the core problem — extracting the invisible codebase, tagging it honestly, and handing the gaps to a human — is not a capability reserved soley for enterprises with mainframe contracts.
The Question That Remains Open
The AI-assisted migration moment is real.
The tooling is advancing rapidly at every tier. What has not changed, and what no advance in model capability will change, is the epistemological limit: an AI cannot know what a threshold means if no one wrote it down. The compliance officer who can answer that question in a fifteen-minute meeting is not being replaced by the migration pipeline. She is being given a much shorter, much better-organised list of questions to answer. That is not a small thing.
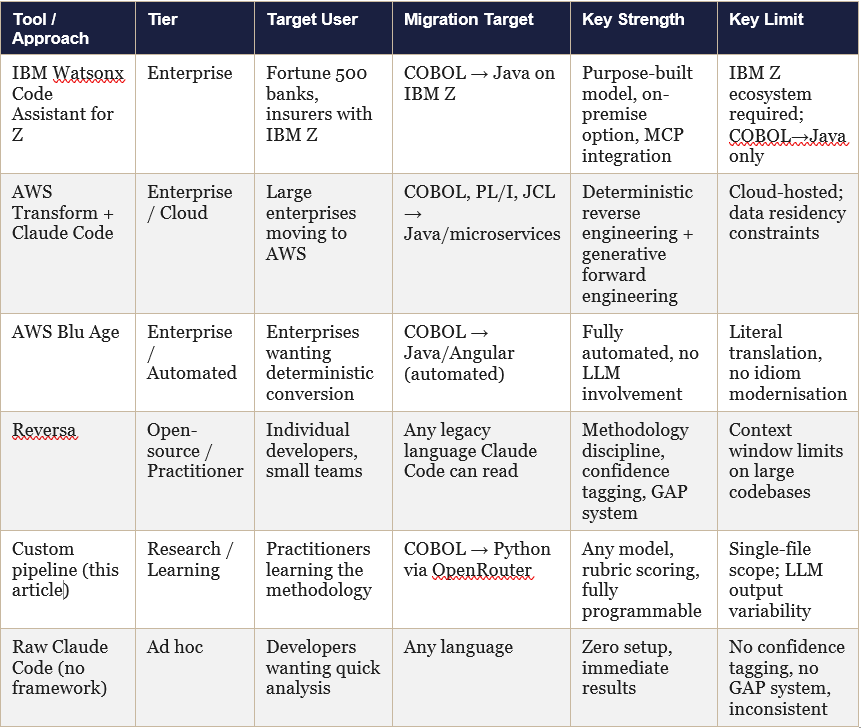
Appendix: The Tier Landscape at a Glance
References
[1] Anthropic. How AI Helps Break the Cost Barrier to COBOL Modernization Anthropic Blog, February 23, 2026.
[2] Economic Times India / Reuters. IBM Shares Hit 13% Drop, February 24, 2026.
[3] Slashdot. IBM Shares Crater 13% After Anthropic Says Claude Code Can Tackle COBOL Modernization Slashdot, February 23, 2026.
[4] PYMNTS. Anthropic’s COBOL Bet Shakes Mainframe Economics PYMNTS.com, February 24, 2026.
[5] IBM. Agentic AI for Smarter Mainframe Modernization with IBM Watsonx Code Assistant for Z IBM Newsroom, March 2, 2026.
[6] IBM Research. COBOL to Java: Application Modernization with IBM Generative AI IBM Research Blog, 2025.
[7] VentureBeat. IBM Taps Watsonx Generative AI to Help Modernize COBOL on Mainframes VentureBeat, December 22, 2025.
[8] AWS. Reimagining Mainframe Applications with AWS Transform and Claude Code AWS Migration and Modernization Blog, April–May 2026.
[9] AWS. AWS Mainframe Modernization Service — Features AWS Documentation, 2026.
[10] AWS Migration and Modernization Blog. AWS Named a Leader in the ISG Provider Lens Mainframe Application Modernization Software 2025 Report AWS Blog, 2025.
[11] TechChannel. Can Claude Code Really Understand COBOL Applications? TechChannel, March 24, 2026.
[12] Phase Change Software. Anthropic Says Claude Code Can Analyze COBOL. Here’s Why Analysis Isn’t Proof. Phase Change Software Blog, February 25, 2026.
[13] MGM Technology Partners. Claude Can Migrate COBOL — Who’s Making the Transition? MGM Insights, March 5, 2026.
[14] Macedo, S.O. and da Costa, R.M.. Reversa: A Reverse Documentation Engineering Framework for Converting Legacy Software into Operational Specifications for AI Agents arXiv:2605.18684, May 18, 2026.
[15] Macedo, S.O. and da Costa, R.M.. Reversa — GitHub Repository (sandeco/reversa) GitHub, 2026.
[16] The New Stack. COBOL Is Everywhere. Who Will Maintain It? The New Stack, 2024.
[17] IT Brew. Can COBOL’ers Collab with Claude Code? IT Brew, February 26, 2026.