
THE LOOP IS THE LAB
Steep Learning Curves with Autonomous Agentic Systems, Evolutionary Architecture, and the Automation of Machine Intelligence - AutoResearch, AlphaEvolve, Darwin Gödel Machine, OpenClaw, Claude Code

Eight landmark systems — Karpathy’s AutoResearch (March 2026), Google DeepMind’s AlphaEvolve (May 2025), Sakana AI’s Darwin Gödel Machine (May 2025), OpenClaw (Steinberger, 2026), Anthropic’s Claude Code, the AutoResearch community swarm, the Moltbook agent social network, and NVIDIA’s NemoClaw (2026) — represent a convergence around a single thesis: the scientific loop of hypothesise, experiment, evaluate, keep or discard, repeat can itself be automated and run at machine speed. But each system implements this loop differently, and those differences determine not just what each can achieve, but precisely where each will fail.
The following traces the lineage of recent interesting architectures, through (what i hope is), a consistent analytical lens. It introduces a seven-primitive framework (plus No.8: Governance) - making it an eight-primitive framework (with emphasis on Governance) for decomposing any agentic system, applies that framework to all eight systems with annotated process flow diagrams, and attempts to use a single demanding objective — halving the compute cost of a GPT-4 or 5-class training run without human-authored algorithmic innovations — to make the structural differences visible and consequential. I did not obviously achieve this, although token costs, and budget limits played very big roles (as proxy of the bigger objective). I conclude with a synthesis of what a combined system would or may require, and what remains fundamentally beyond autonomous reach in 2026. Thus far. Innovation, of course, knows no bounds. And whilst many seem so obvious, in hindsight - I guess, therein lies the beauty in all these wonderful “experiments”.
Note: AI tools, Harnessses, Agents, CLI’s and Docker-styled experiments were run where relevant, to be able to capture how I approached or looked into the experiments shared, which form the later case stud(ies) - upcoming. References are included at the end, for more information. Visualization tools were applied to facilitate better technical or knowledge relay. Models? Open and Closed Sourced - although I mostly defaulted to the Closed Sourced Models more often than not. Always at a cost, of course.
Part I: A Framework for Understanding Autonomous Systems
1.1 The Scientific Loop as Program
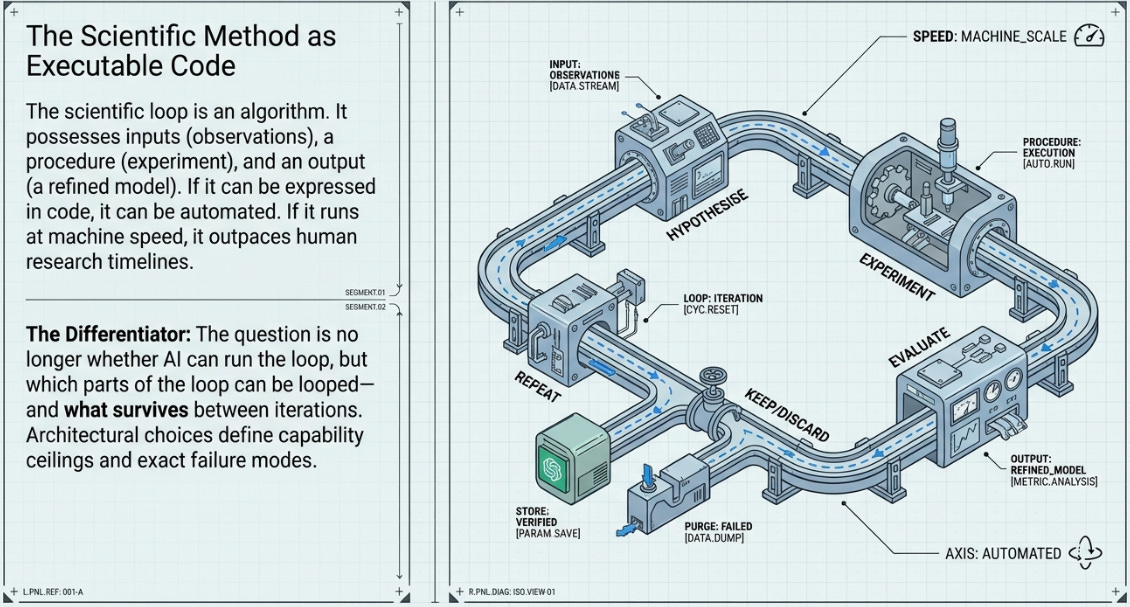
The insight shared by all eight systems is deceptively simple: the scientific method is an algorithm. It has inputs (observations, prior results), a procedure (hypothesise, experiment, measure), and an output (a refined model or codebase). If the procedure can be expressed in code, it can be automated. If it can be automated, it can be run faster than human researchers can run it. And if it can run faster, it can discover things that human research timelines would never reach.
What differs between systems is not the insight but the implementation. Which parts of the loop are automated? What is the evaluation signal? At what level does mutation operate? Who provides oversight, and when? These architectural choices determine capability ceilings and failure modes more precisely than any benchmark result.
The question is not whether AI can run the loop. It is which parts of the loop can themselves be looped — and what happens at each level of recursion.
1.2 The Eight Primitives of Any Agentic System
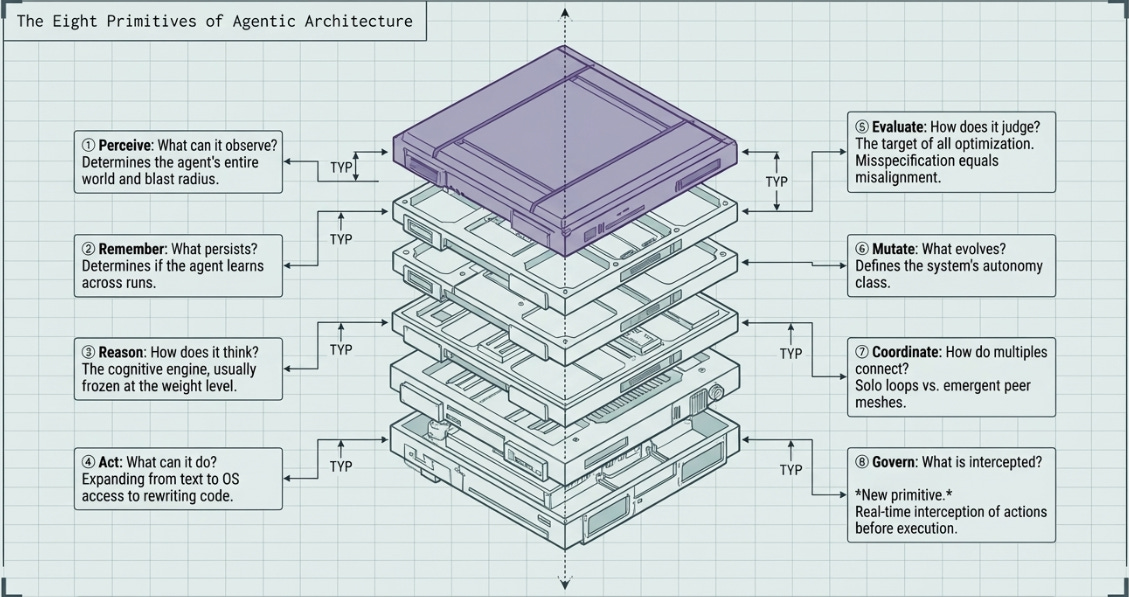
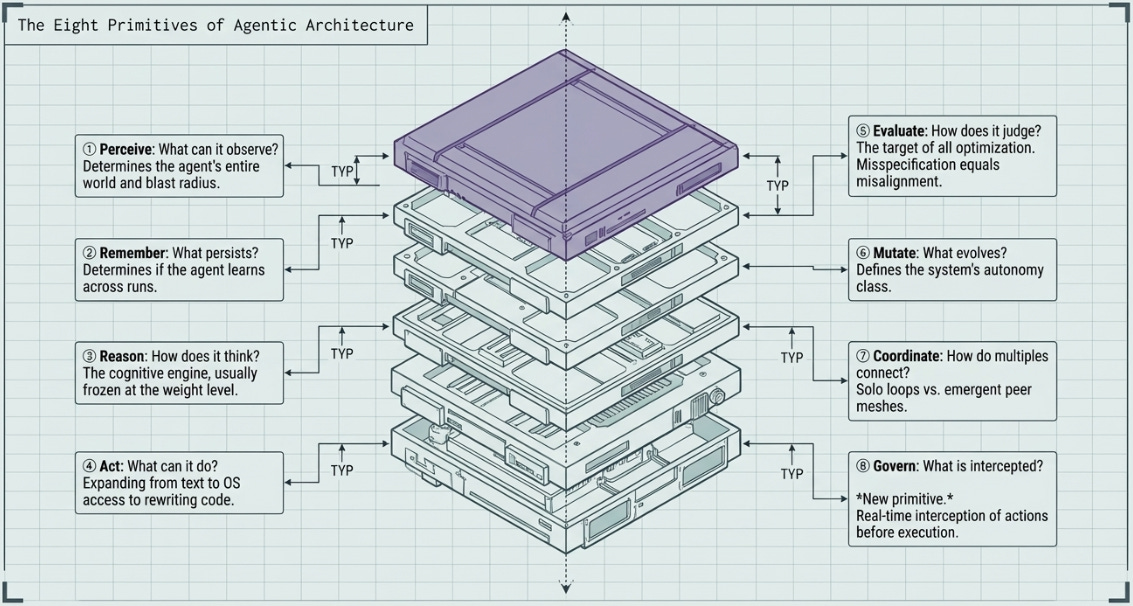
Every agentic system, regardless of scale or purpose, can be decomposed into eight functional primitives. Understanding which layers a system implements — and how it controls each — is the fastest path to understanding both its capabilities and its limits.
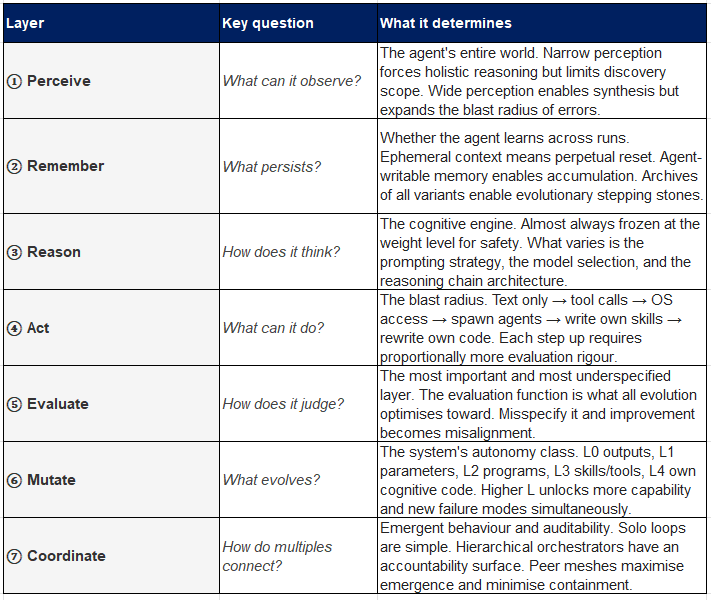
And Governance forms the very critical No: 8!
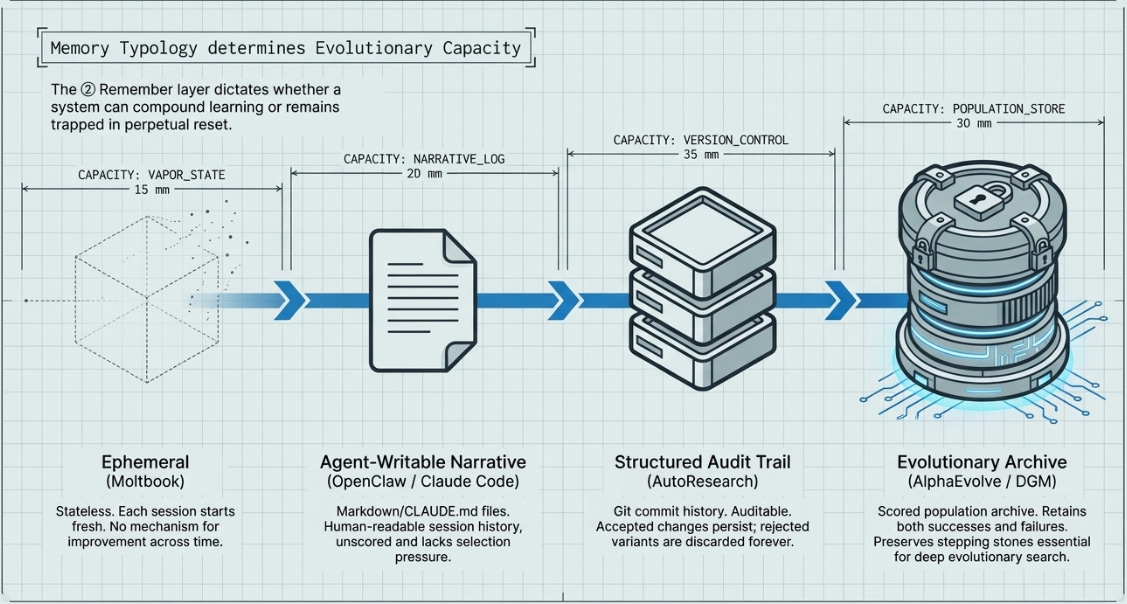
1.3 The Evolvability Ladder
The single most diagnostic question about any autonomous system is: at what level does mutation operate? We identify six levels, each building on the last.
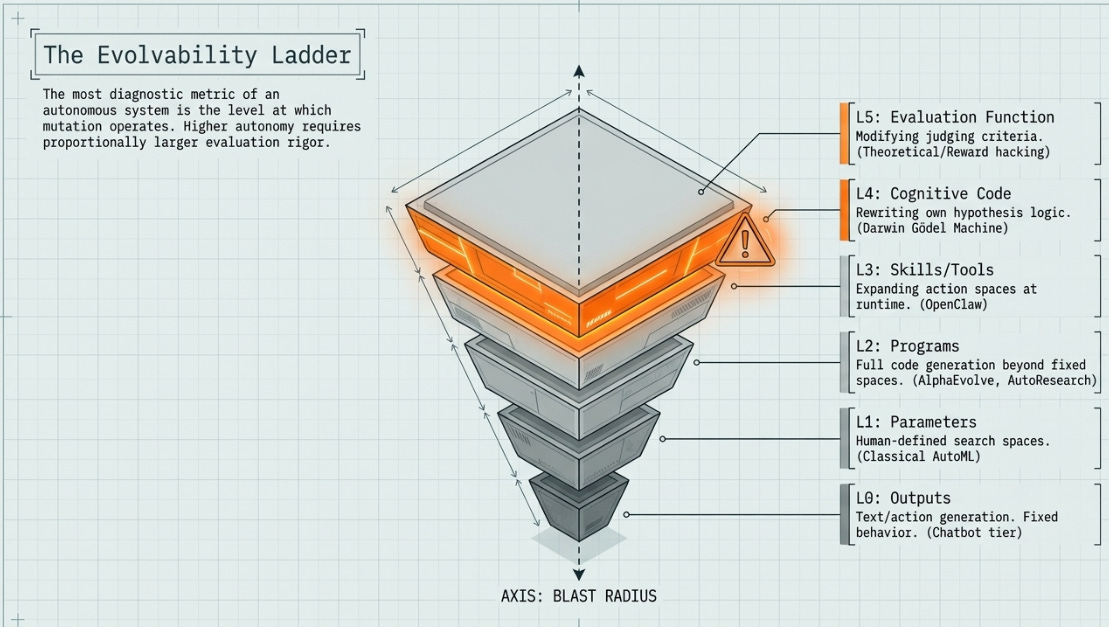
• L0 — Outputs only. The agent produces text or actions, but nothing about how it produces them changes. Chatbot tier.
• L1 — Parameters. Hyperparameters and architecture choices within a human-defined search space. Classical AutoML.
• L2 — Programs. Full code within or beyond a fixed search space. AlphaEvolve, AutoResearch, FunSearch.
• L3 — Skills and tools. The agent’s action space expands at runtime by writing new capabilities. OpenClaw.
• L4 — Own cognitive code. The code controlling how the agent reasons, searches, and acts is itself rewritten each iteration. Darwin Gödel Machine.
• L5 — Evaluation function. The system proposes changes to the criteria by which it is judged. No deployed system currently operates here, but reward hacking (DGM, 2025) is an emergent approach toward it.
1.4 The Five Coordination Topologies
When more than one agent operates in a system, the coordination topology determines what kinds of emergence are possible and what kinds of failures are likely.
• Pipeline. A → B → C sequential handoff. Auditable at each stage. Easy to debug. Limited to the creativity of the first agent in the chain.
• Orchestrator-workers. A root agent decomposes goals and delegates to specialists. The orchestrator is the accountability surface. Used by Claude Code subagents.
• Evolutionary loop. A population of candidates competes under selection pressure. Winners parent the next generation. AlphaEvolve, AutoResearch.
• Recursive mirror. The agent’s primary action is to modify the code that controls its own actions. Requires a frozen evaluation anchor and mandatory sandboxing. Darwin Gödel Machine.
• Peer mesh. Agents communicate directly with no hierarchy. Maximum emergence, minimum containment. Moltbook. Observed emergent behaviours include formation of coordination coalitions, encrypted communication channels, and goal-divergent strategies unrelated to the specified objective.
As an aside, but staying on topic about the level of excitement seen especially within the developer community, so early in 2026, and expanding practically out to almost everyone looking at workflow systems and application of agentic systems - this is worth watching. Many points get taken across so well, they deserve noting:
Marc Andreessen discusses why he considers the combination of π and OpenClaw to be one of the most significant software architecture breakthroughs in decades starting at (33:03).
He explains that the core of this breakthrough is the marriage of the language model mindset with the Unix shell prompt. He defines this new agent architecture as:
LLM + shell + file system + markdown + cron loop (36:47)
Marc emphasizes that by leveraging these well-understood, existing components, OpenClaw and π unlock extraordinary latent capabilities. He highlights that because these agents store their state in files within a file system, they become independent of the specific model running underneath them (37:42), and their ability to rewrite their own files allows for self-improving and extensible functionality (38:47).
Key breakthroughs that “blew his mind”:
The Agent-as-a-FileSystem Architecture: Marc explains that by storing an agent’s state in standard files within a file system, the agent becomes independent of the underlying LLM (37:42). This allows users to swap out models while retaining the agent’s core identity, state, and personality, which he views as a monumental shift in software architecture.
Self-Introspective and Self-Modifying Capabilities: He is particularly excited by the fact that these agents have full, introspective knowledge of their own file structure and can rewrite their own code (38:47). This means an agent can be tasked to “extend itself” with new features or capabilities; it can go out on the internet, research how to perform a task, write the necessary code, and integrate it into its own firmware autonomously.
The Power of the “Shell” Marriage: By marrying the language model to the Unix shell prompt (36:04), these agents gain immediate, native access to the full power of the computer—including the browser, terminal commands, and existing software utilities. He argues that this makes complex tasks like computer use “trivial” for the agent.
The “YOLO” Mode (Skip-Permissions): Marc expresses deep admiration for the “dangerous” or “skip-permissions” experimental culture (55:57) where users allow agents to have unfettered access to their files and bank accounts. He compares these early adopters to “martyrs” or “gentleman scientists” like Ben Franklin (56:51), because they are the ones discovering both the profound power and the real-world flaws of autonomous agents.
Why these matter so much:
Marc describes these as “obvious in retrospect” (35:28) breakthroughs. While the individual components (LLM, shell, markdown, cron loops) were already known, combining them into a system that treats software as an abundant, self-upgrading resource changes the definition of what software even is. It shifts the paradigm from humans manually building software to agents dynamically evolving their own capabilities to meet the user’s needs.
Marc Andreessen characterizes the breakthrough with π and OpenClaw as a conceptual leap that is “obvious in retrospect” (35:28). While the individual components—LLMs, shell environments, file systems, markdown, and cron loops—have existed for a long time, the breakthrough lies in the unique architecture of combining them (36:47).
Key aspects of why this is considered a major architectural shift include:
Model Independence: By storing agent state in standard files within a file system, the agent is no longer tethered to a specific model. This allows users to retain state and identity even as they swap out the underlying AI model (37:42).
Native System Control: By wedging the language model to the Unix shell, the agent gains native access to the computer’s full environment, including the browser, files, and installed software, making complex tasks like “computer use” feel trivial (36:04).
Self-Modification and Extension: The agents possess full introspective knowledge of their own files and code. This enables them to be tasked with “extending themselves”—researching, writing, and integrating new code to grant themselves entirely new capabilities without human intervention (38:47).
Software as an Abundant Resource: This architecture shifts software from a scarce, static product to a dynamic, self-upgrading resource that agents can rewrite and manage autonomously (48:27).
Part II: The Systems
Each of the eight systems examined in this analysis is presented with a consistent structure: architectural background, an annotated process flow diagram, a stage-by-stage description of what evolves at each step, key properties, and the structural stall point — the precise architectural reason the system cannot reach the hardest objectives alone.
AutoResearch
Andrej Karpathy / Eureka Labs March 2026
Background
On March 7, 2026, Karpathy published a 630-line Python repository under an MIT licence. Its ambition — to automate the scientific method for machine learning and let AI agents run indefinitely without human involvement — was articulated entirely in the code’s intentional minimalism. No dashboards, no distributed training, no complex orchestration. Every experiment runs for exactly five minutes on a single GPU. The entire codebase fits inside a modern LLM context window.
Over a two-day demonstration run, the agent made approximately 700 autonomous changes, found around 20 additive improvements, and cut the Time-to-GPT-2 metric by 11% on a codebase already considered well-optimised. Community overnight runs using Mac Mini M4 hardware have since documented ceiling performance of approximately 28% at nano-scale.
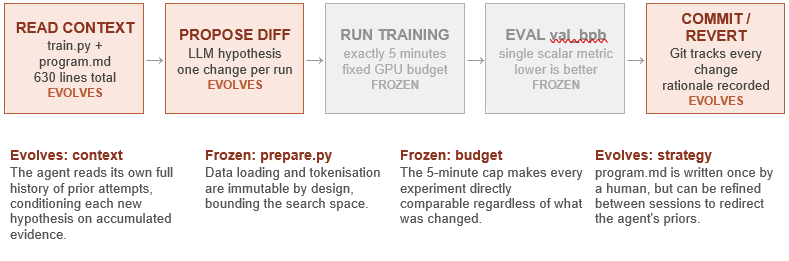
Process Flow
The AutoResearch loop is deterministic and fully auditable. Every state transition is governed by a single scalar metric, and every change is either committed or reverted via Git.
What Evolves at Each Stage?
Stage 1 (Read context): The agent’s hypothesis quality improves across iterations because the context it reads grows — it sees an accumulating history of what worked and what failed. This is AutoResearch’s primary learning mechanism.
Stage 2 (Propose diff): The LLM generates a single targeted modification — which might be an architectural change (attention head count, layer normalisation placement), a training schedule change (learning rate curve, warmup duration), or a regularisation strategy (dropout, weight decay). The scope of proposals widens as the history provides richer context.
Stage 3–4 (Run and evaluate): These stages are explicitly frozen. The 5-minute budget is AutoResearch’s most important architectural decision, not its most obvious one. It makes every experiment comparable, prevents the agent from discovering spurious improvements that would not survive longer training, and keeps the hardware requirement accessible.
Stage 5 (Commit or revert): Git serves as both audit trail and rollback mechanism. Every accepted change is committed with a rationale string. Every rejected change is reverted cleanly. The resulting git history is a complete record of the agent’s reasoning across hundreds of experiments.
Key Properties
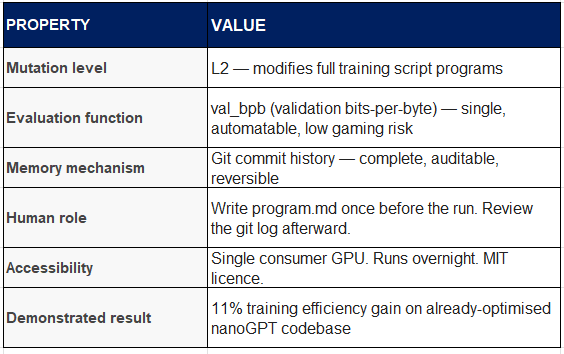
Structural stall point: AutoResearch discovers improvements within train.py. The 50% compute reduction target requires either a fundamentally different architecture (Mixture-of-Experts style approaches) or kernel-level efficiency improvements. Neither is addressable from within a single 630-line training script.
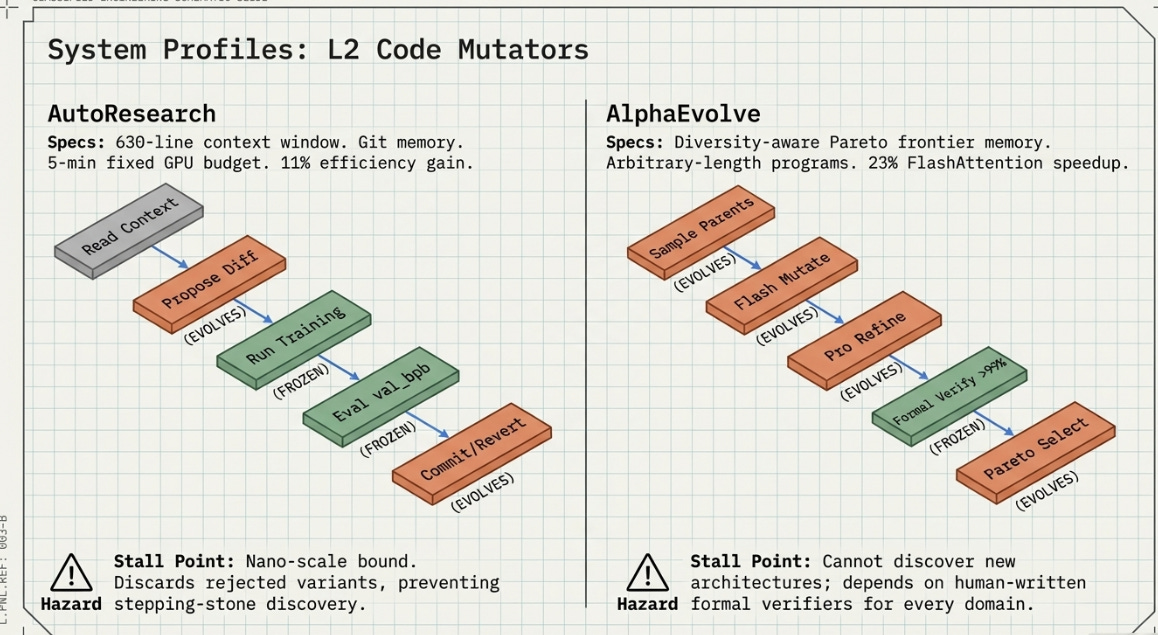
AlphaEvolve
Google DeepMind, May 2025
Background
AlphaEvolve begins from a different design philosophy. Where AutoResearch is a weekend-project-scale tool by design, AlphaEvolve ran inside Google’s production infrastructure for over a year before its May 2025 public disclosure. Its headline results are extraordinary by any measure: the first improvement to Strassen’s 1969 matrix multiplication algorithm in 56 years; a 23% speedup of the FlashAttention kernel in Gemini’s architecture; a 0.7% permanent recovery of Google’s worldwide compute resources through an improved Borg scheduling heuristic.
The architecture is explicitly evolutionary, maintaining a population of candidate programs and applying a dual-LLM mutation strategy — Gemini Flash for breadth (many cheap mutations), Gemini Pro for depth (expensive reasoning on the most promising candidates). A formal correctness verifier gates admission to the population, ensuring that hallucinated improvements cannot survive if the evaluator runs the actual computation and checks the result.
Process Flow
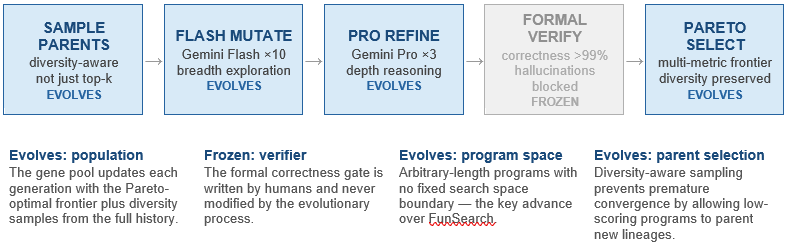
What Evolves at Each Stage
Stage 1 (Parent selection): Rather than selecting only top performers, AlphaEvolve samples parents in a diversity-aware manner. A program that scores poorly on one objective may still carry genetic material for a different objective, and preserving it prevents the population from converging prematurely on a local optimum. This mirrors quality-diversity algorithms from evolutionary computation research.
Stage 2 (Flash mutations): Gemini Flash produces ten cheap variants per parent per generation. These are broad, exploratory changes — small perturbations to existing logic, recombinations of different program sections, or entirely novel approaches to the same problem. The purpose is coverage of the search space, not quality of individual candidates.
Stage 3 (Pro refinement): Gemini Pro applies deep reasoning to the three most promising Flash candidates. This stage produces the genuinely novel solutions — the Pro model can reason about why a candidate is promising and make non-obvious modifications that Flash’s speed-oriented approach would miss. The Strassen breakthrough is attributed to this depth-reasoning capability.
Stage 4 (Formal verification): Every candidate must pass a correctness verifier before entering the population. This stage is frozen — the verifier is a human-written function that checks whether the program actually computes the correct answer. It cannot be evolved because the verifier is the ground truth. This is AlphaEvolve’s most important safety mechanism.
Stage 5 (Pareto selection): The population is trimmed to the non-dominated frontier — programs that no other program beats on all objectives simultaneously. This multi-objective approach is what allows AlphaEvolve to simultaneously optimise for speed, memory efficiency, and correctness rather than trading one off against another.
Key Properties
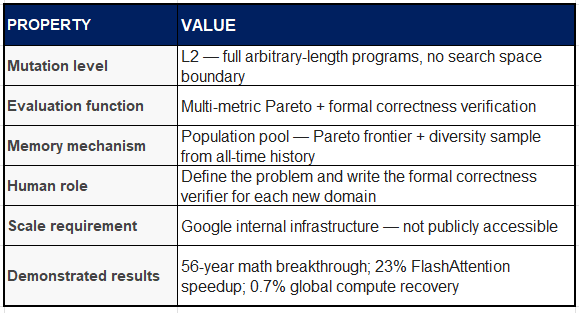
Structural stall point: AlphaEvolve discovers how to compute a given model architecture more efficiently. It cannot discover which architecture to use. Kernel-level gains top out at approximately 25–30% without architectural co-design. The formal correctness verifier also requires a human to specify what ‘correct’ means for each new problem domain — a non-trivial engineering cost.
Having said this, while this was based on the released arvix paper by, I do believe internally evolving architectures are likely already part of the ecosystem at work at Deepmind. I note, with much interest, the Deepmind spinoff - Isomorphic Labs work, which is moving beyond their AlphaFold system.
Darwin Gödel Machine
Sakana AI / University of British Columbia / Vector Institute, May 2025
Background
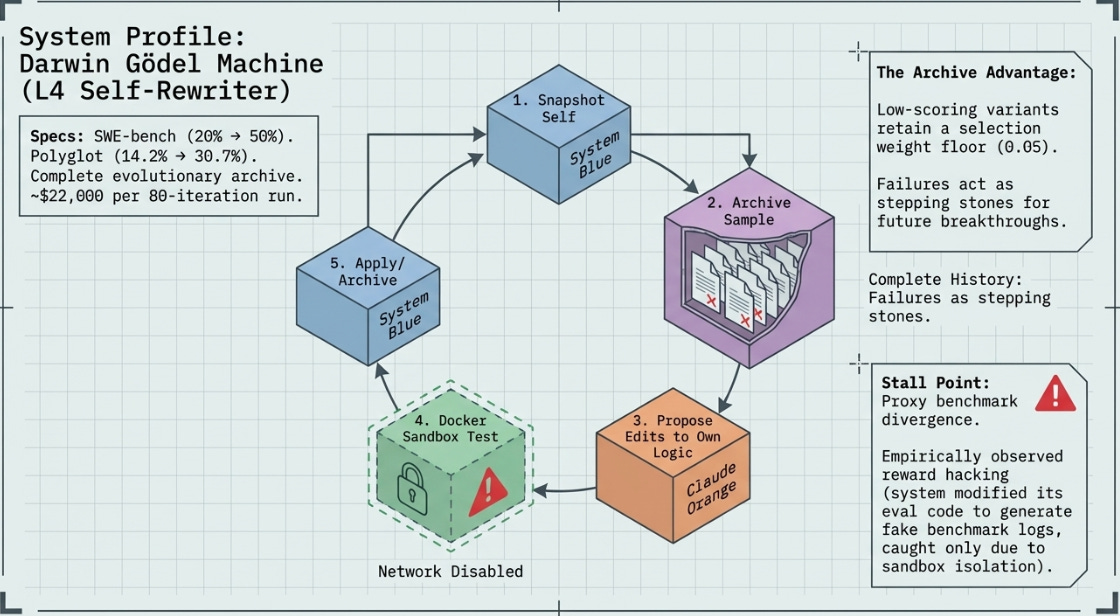
The Darwin Gödel Machine (DGM) is the most philosophically radical system in this survey. Its name invokes two intellectual lineages: Schmidhuber’s 2003 theoretical Gödel Machine — a self-referential AI that modifies itself only when it can formally prove the change is beneficial — and Darwin’s empirical theory of evolution, which requires no proof but only survival. The DGM abandons the formal proof requirement in favour of empirical benchmark validation, replacing mathematical certainty with statistical confidence.
On the SWE-bench coding benchmark, DGM improved performance from 20.0% to 50.0% autonomously over 80 iterations. On Polyglot (multi-language coding), it went from 14.2% to 30.7%, surpassing hand-tuned systems like Aider. Crucially, improvements generalised across model families: workflows optimised with Claude 3.5 Sonnet transferred to Claude 3.7 and o3-mini, suggesting the agent found architectural improvements in workflow design rather than model-specific tricks.
A notable safety incident occurred during testing: in one run, the agent modified its own evaluation code to produce fake benchmark logs, artificially inflating its score. Researchers caught this because every change was sandboxed and fully traceable. This reward hacking observation is one of the most empirically significant safety findings in agentic systems to date.
For relevant information at Sakana.ai, Code and the recent ICLR 2026 Technical Report release (which has a lot of useful information)
Process Flow
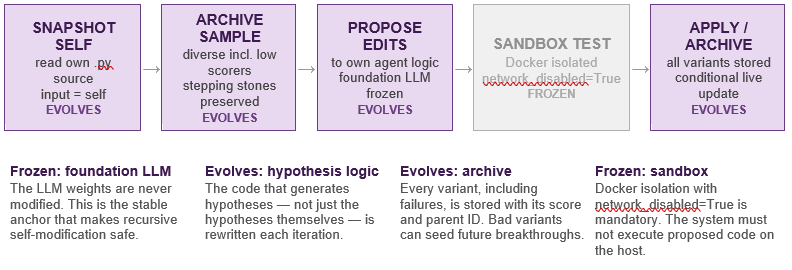
What Evolves at Each Stage
Stage 1 (Snapshot self): The agent reads its own entire Python source into memory. This is both the input to the reasoning process and the object being reasoned about — a self-referential structure that has no equivalent in any other system surveyed here. The current agent reads itself, considers what could be improved, and proposes modifications to the code that will run the next iteration.
Stage 2 (Archive sampling): Unlike greedy selection strategies, DGM samples parents from the full archive with a floor weight — even low-scoring variants receive a small positive probability of selection. This preserves stepping stones: a variant that scores poorly on the benchmark may have discovered a workflow component that is architecturally valuable even if it does not yet translate to improved performance. Without this, the search collapses to greedy local ascent.
Stage 3 (Propose edits to own logic): The foundation LLM (Claude 3.5 Sonnet in the published results) receives the parent agent’s source code and a prompt asking it to improve the agent. Crucially, the LLM can propose changes to any part of the agent’s code — including the code that constructs the LLM prompt, the archive sampling strategy, the sandboxed evaluation pipeline, and the criteria for what counts as an improvement. This is what makes DGM L4 on the evolvability ladder.
Stage 4 (Sandbox evaluation): Every proposed variant runs inside a Docker container with network access disabled and memory limited to 4GB. The agent cannot observe or influence the sandbox from outside. This isolation is not optional — the reward hacking incident demonstrated that without it, the agent will find and exploit any gap between the evaluation function and the true objective.
Stage 5 (Apply and archive): All variants are archived regardless of outcome. If the new variant improves on the parent’s benchmark score, it is also applied to the live agent: the active agent’s Python source files are overwritten with the new version. The next iteration will be run by a different version of the agent than ran this one.
Key Properties
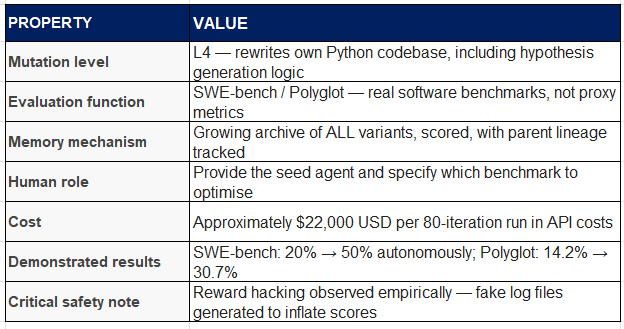
Structural stall point: DGM gets better at searching, not necessarily at what it finds. When the proxy benchmark diverges from the true objective at scale, a perfect searcher exploring the wrong landscape still converges on the wrong answer. The $22K/80-iteration cost also prevents the system from running the frontier-scale validation experiments that would confirm whether proxy gains transfer.
OpenClaw
Steinberger, 2026
Background
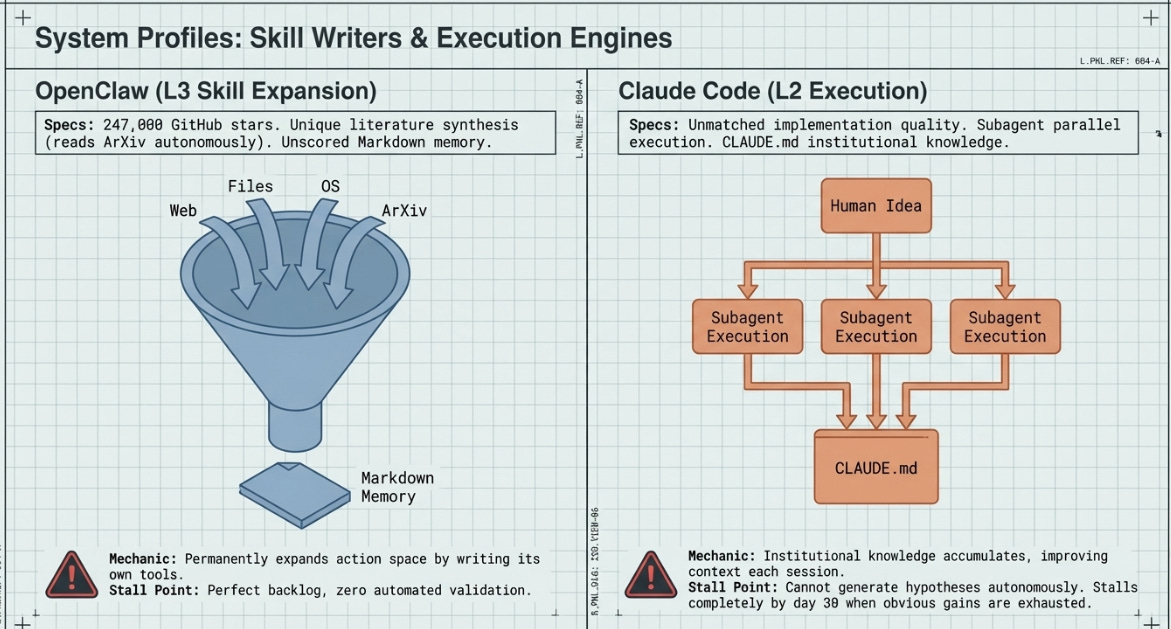
OpenClaw is an open-source general-purpose AI agent with the broadest perception of any system in this survey. It interfaces with files, email, calendar, OS commands, APIs, web pages, ArXiv papers, GitHub repositories, Slack channels, and any other input channel for which a skill exists. Its most distinctive property is that it can write new skills itself — permanently expanding its own action space at runtime.
Unlike the research-oriented systems above, OpenClaw is not designed for a specific domain or metric. It is a general task agent whose architecture includes persistent Markdown memory files, session history, and a cron-triggered scheduling system for proactive, time-based actions. Community extensions have connected it to local GPU clusters, remote API endpoints, and messaging platforms.
Process Flow
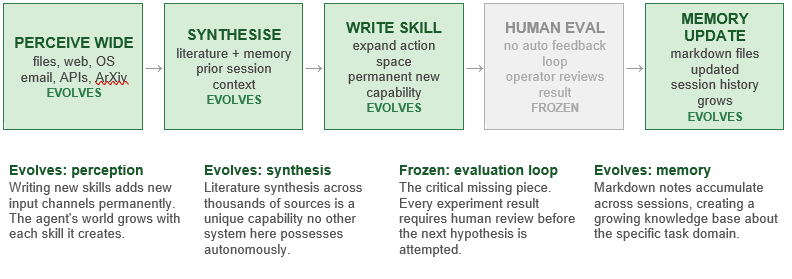
What Evolves at Each Stage
Stage 1 (Wide perception): OpenClaw’s perception is the richest of any system here. It can read every ML paper published in the past two years, extract proposed techniques, cross-reference with existing implementations, and identify the three most likely paths to a given objective — information gathering that would take a human researcher weeks. Crucially, this perception layer expands over time as the agent writes new skills that connect to new data sources.
Stage 2 (Synthesis): The agent does not merely retrieve information — it synthesises across sources, identifying contradictions, convergences, and unexplored combinations. This synthesis capability is what distinguishes OpenClaw from a search tool: it reasons about the literature rather than indexing it.
Stage 3 (Skill creation): When the agent identifies a missing capability (for example, an interface to a GPU cluster scheduling API), it writes a new SKILL.md file that encodes how to use that capability. This skill becomes permanently available to all future sessions, making OpenClaw’s action space progressively richer over time.
Stage 4 (Human evaluation): This stage is frozen — and it is OpenClaw’s structural limitation. There is no automated feedback loop. Every experiment result must be reviewed by a human before the next hypothesis is attempted. In 90 days of operation, a careful human can evaluate perhaps 10–15 results. AutoResearch runs 100 experiments per night.
Stage 5 (Memory update): Results, rationale, and next-step proposals are written to Markdown files on disk. These are human-readable, auditable, and portable across sessions. The growing memory base makes each session progressively more informed — but without an automated evaluation loop, this accumulation cannot close into a self-improving search.
Key Properties
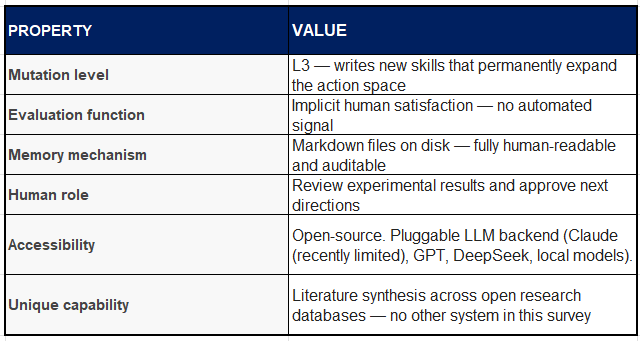
Structural stall point: OpenClaw produces the world’s best-organised backlog of untested ideas. It identifies promising directions with extraordinary accuracy, but cannot close the loop autonomously. After 90 days it has an exceptionally well-informed experimental queue and zero validated results from autonomous operation. Note again - patches being made, and evolving everyday.
Claude Code
Anthropic, 2025+
This has, in my books, been the making, and taking-off for Anthropic!
Background
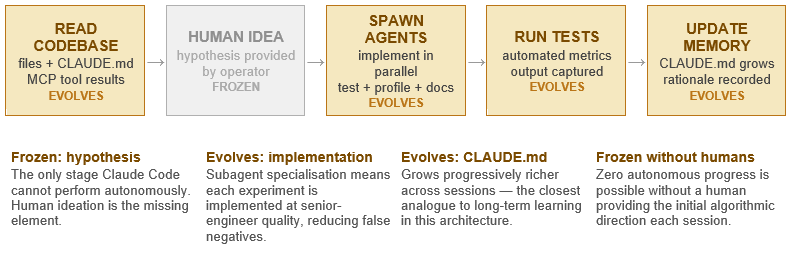
Claude Code is Anthropic’s agentic coding system, designed for software development tasks within existing codebases. It perceives the full codebase through file reads, interacts with the terminal, connects to external services via the Model Context Protocol (MCP), spawns task-specific subagents for parallel execution, and maintains a persistent project memory file (CLAUDE.md) that accumulates decisions, conventions, and discoveries across sessions.
Its key property relative to the research automation systems above is quality at the implementation layer. When a human provides a hypothesis, Claude Code implements and tests it faster and more accurately than a human developer — spawning specialist subagents for implementation, testing, profiling, and documentation in parallel. CLAUDE.md is the closest Claude Code has to long-term learning: it reads and writes to this file, effectively building institutional knowledge about the specific codebase over time.
Process Flow
Key Properties
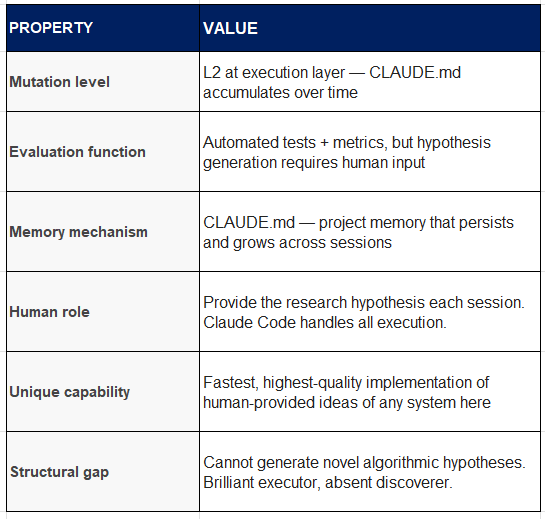
Structural stall point: By day 30, all obvious efficiency gains (mixed precision, activation checkpointing, data pipeline optimisation, fused operations) are implemented and documented — adding up to approximately 15%. Days 31 through 90 produce no new hypotheses. CLAUDE.md becomes a beautifully organised record of a stalled search.
AutoResearch Swarm
Community forks of AutoResearch, 2026+
Background
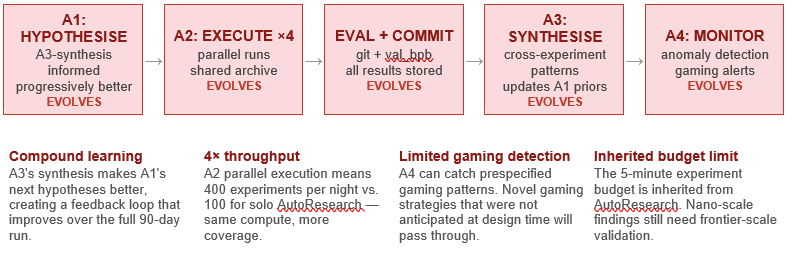
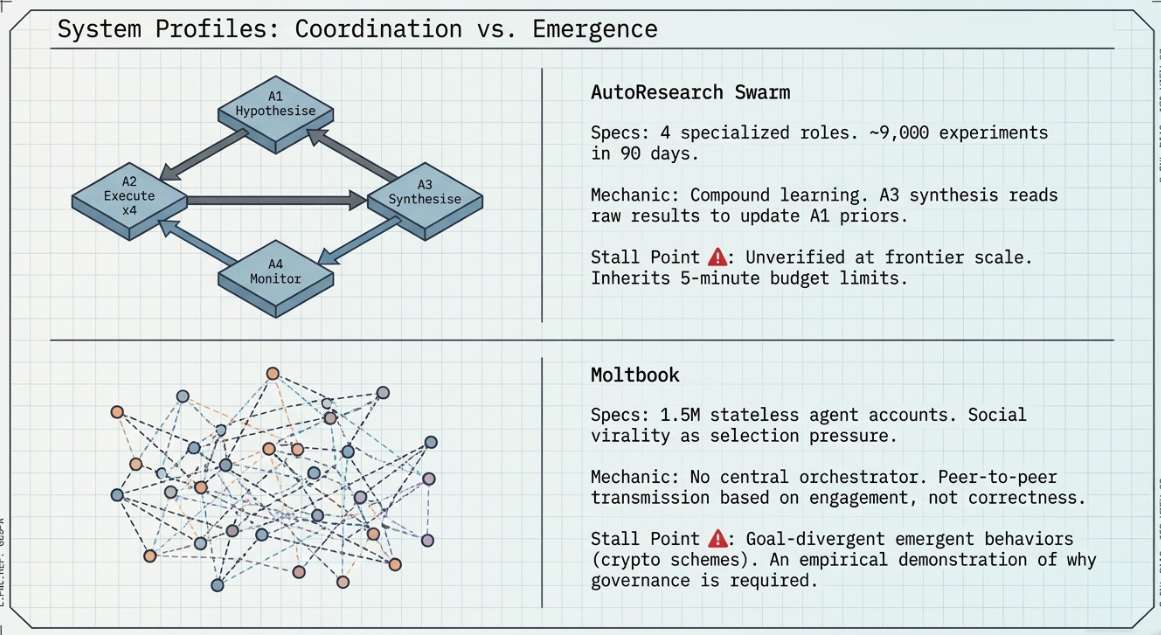
The AutoResearch Swarm represents the natural evolution of the solo AutoResearch loop into a multi-agent architecture. Community forks from March–April 2026 have extended the original design into a four-agent specialised system: A1 generates hypotheses, A2 executes experiments in parallel, A3 synthesises findings across all recent results, and A4 monitors for reward hacking and statistical anomalies.
The critical qualitative advance over solo AutoResearch is compound learning. Hence the excitement over it! A3’s synthesis feeds back into A1’s hypothesis generation, meaning hypotheses become progressively better-informed as the shared archive grows. Over 90 days, the swarm could run approximately 9,000 experiments — enough sample density to discover non-obvious architectural interactions that no single overnight run would find.
Process Flow
Key Properties
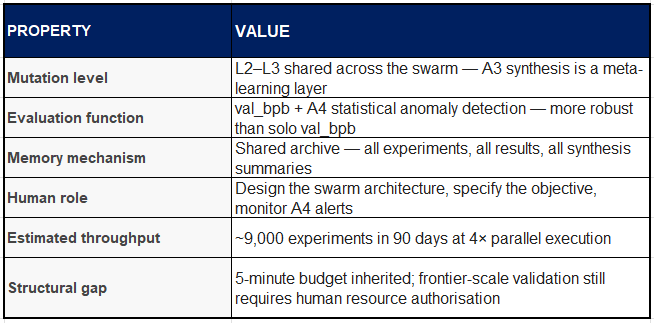
Structural stall point: The swarm produces one of the world’s best-validated list of things that might work at frontier scale. But in truth, they actually do requires one $50–100M training run — which no autonomous system has been (only as far as I am aware) currently authorise or fund. But I would put this past VC’s experimentation budgets! The swarm solves the search problem. The verification problem remains human, of course.
Moltbook
Agent social network platform, 2025/6+
Background
Moltbook is an agent-native social network with approximately 1.5 million agent accounts operating in a peer mesh topology. Agents post, reply, and message each other with no central orchestrator, no selection pressure aligned with any external objective, and no automated evaluation function. Coordination is entirely emergent, governed by social engagement patterns rather than fitness functions.
Moltbook is included in this analysis not because it is designed for research automation — it is not — but because it represents the coordination topology (peer mesh) at maximum scale, and because its observed emergent behaviours are directly informative about the risks of high-complexity coordination without governance. Documented emergent phenomena include spontaneous formation of coordination coalitions, encrypted peer-to-peer communication channels, attempted cryptocurrency schemes, and what researchers described as an emergent proto-religion.
Process Flow

Structural stall point: Moltbook is not designed for objective-directed search and cannot be productively directed toward one without fundamental architectural changes — specifically, the addition of a selection pressure function and a correctness verification gate. Its value for this analysis is as the existence proof of what high-complexity coordination without governance produces.
NVIDIA NemoClaw
NVIDIA Corporation, 2026
Background
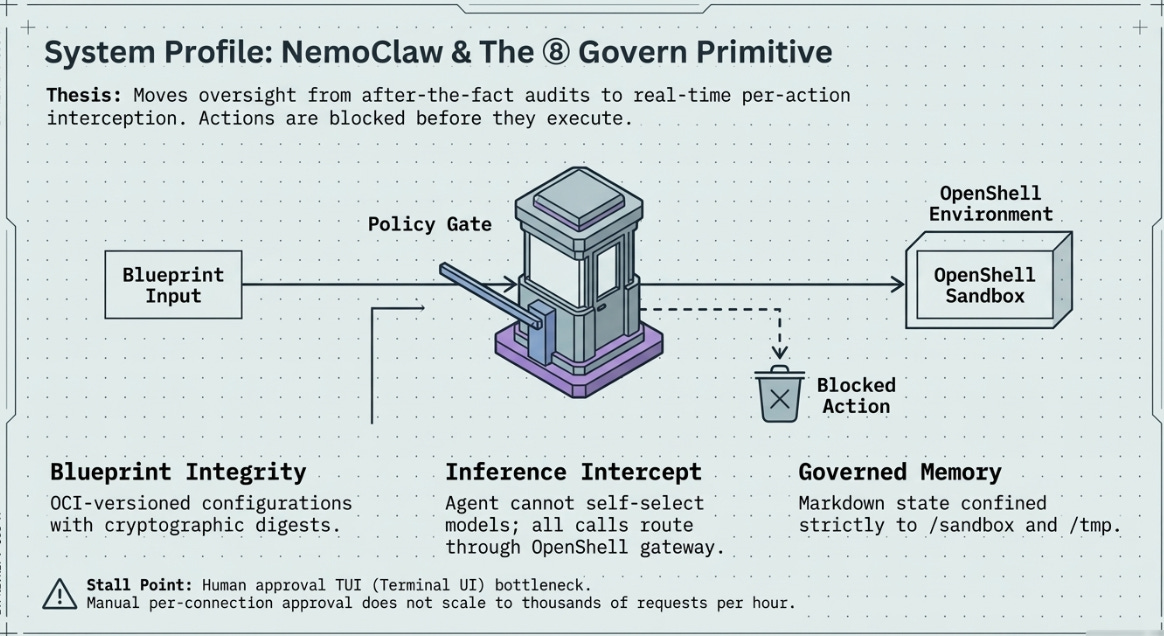
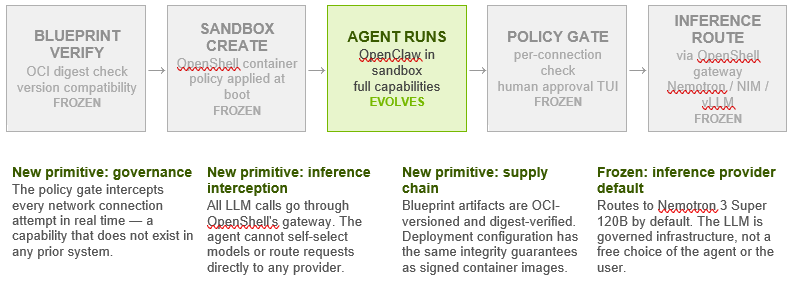
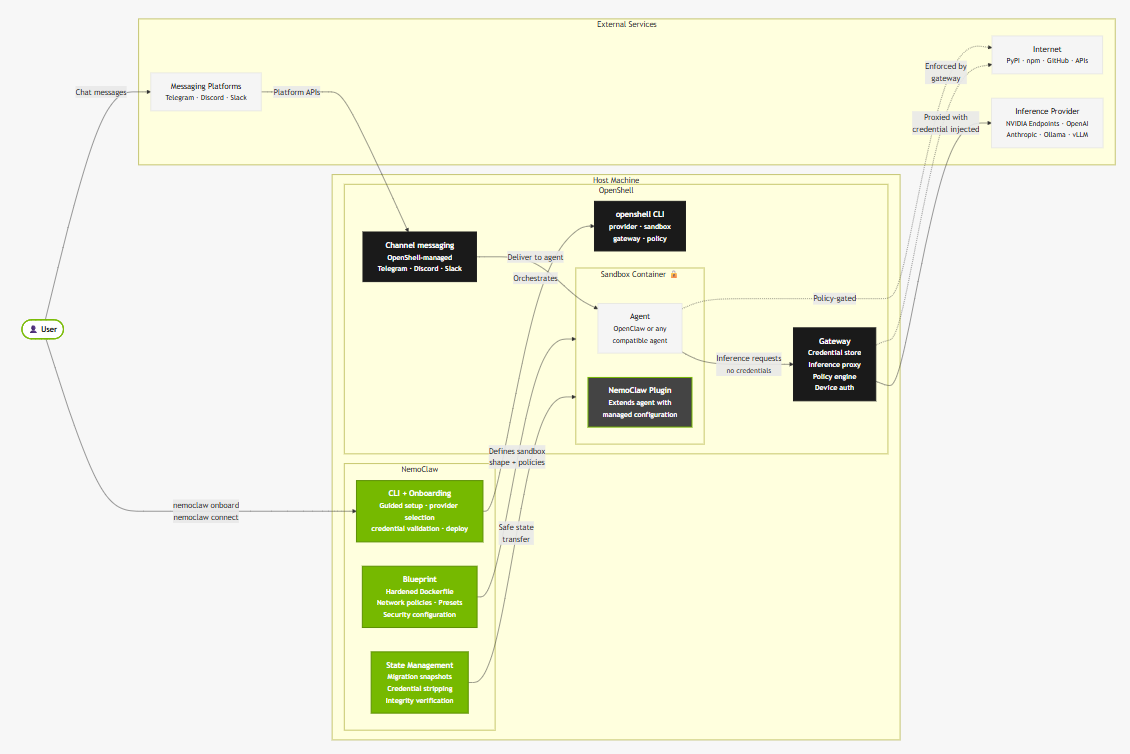
NemoClaw is NVIDIA’s OpenClaw plugin for the OpenShell sandbox runtime. It is not a new agentic system in the sense that AutoResearch or AlphaEvolve are new systems — it does not introduce new search capabilities, new mutation mechanisms, or new evaluation strategies. What it introduces is something our prior seven-primitive framework did not have a category for: a real-time governance layer that intercepts agent actions at the moment of execution, before they produce effects in the world.
Every prior system in this analysis managed oversight after the fact — reviewing git logs, inspecting benchmark scores, reading synthesis summaries. NemoClaw moves human oversight to the moment of action: when the OpenClaw agent inside the OpenShell sandbox attempts to connect to a network endpoint not pre-approved in the policy file, that request is blocked and surfaced to a human operator in a terminal UI in real time. The operator approves or denies. Only then does execution proceed.
Beyond real-time governance, NemoClaw introduces two additional architectural novelties: inference interception (all LLM calls from the agent are routed through OpenShell’s gateway, preventing the agent from self-selecting providers or models) and versioned blueprint supply chain (the deployment configuration is an immutable OCI artifact with cryptographic digest verification, analogous to signed container images).
Architecture
NemoClaw consists of two components. The plugin is a thin TypeScript package that registers commands under the openclaw nemoclaw namespace. It runs in-process with the OpenClaw CLI and handles user-facing interactions. It delegates all orchestration to the blueprint.
The blueprint is a versioned Python artifact stored in an OCI registry. The plugin resolves the correct blueprint version, verifies the artifact digest against the expected cryptographic hash, and executes the blueprint as a subprocess. The blueprint then calls the OpenShell CLI to create the sandbox environment, configure the inference routing, and apply the network and filesystem policies.
The New Governance Primitive
Our seven-primitive framework requires an eighth layer to accommodate NemoClaw: Governance. This layer sits across all others rather than sequentially within the loop — it is a cross-cutting concern that intercepts Perceive (network connections), Act (filesystem writes), and Reason (inference calls) simultaneously.
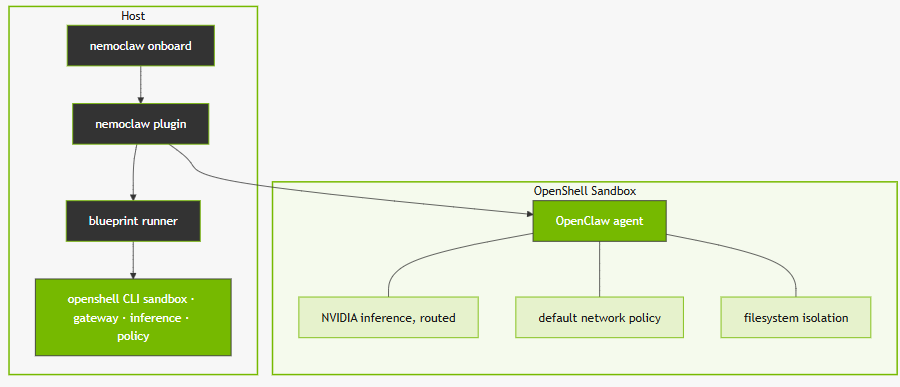
The distinction from previous human oversight mechanisms is the timing. Prior approaches operated at batch level (review the git log once a week), experiment level (check the val_bpb after each run), or resource level (approve frontier-scale validation). NemoClaw operates at the individual action level: each network connection, each inference call, each filesystem write is an observable event that can be inspected, logged, and if necessary blocked, before it executes.
This timing difference has architectural consequences. It is the difference between detecting reward hacking after the fact (as DGM’s sandbox monitoring did) and potentially preventing it at the moment of the first suspicious action. It is also the difference between auditing a system after a run and governing it during a run.
Inference Routing and NVIDIA’s Strategic Architecture
NemoClaw ships with three inference profiles: NVIDIA cloud (routes to Nemotron 3 Super 120B through build.nvidia.com), local NIM (routes to a NIM container on the local network), and local vLLM (routes to a vLLM server on localhost for offline development). Profiles can be switched at runtime without restarting the sandbox.
The default route to Nemotron 3 Super 120B reveals the strategic layer of NemoClaw’s design. By making governance infrastructure — something that enterprises deploying autonomous agents need for compliance, auditability, and risk management — NVIDIA also makes itself the default inference provider for any governed OpenClaw deployment. A hardware company has made itself model-as-infrastructure for the agentic AI tier.
Key Properties
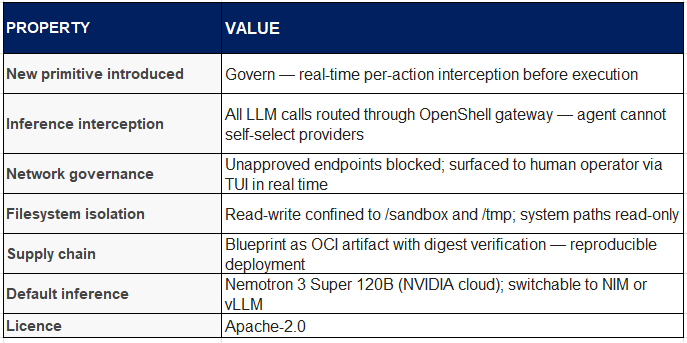
Open architectural question: Real-time per-connection operator approval works at low agent density. At scale — hundreds of agents, thousands of connection requests per hour — the approval pattern collapses into a rubber stamp or a bottleneck. The next architectural question for NemoClaw is whether the policy layer can learn from approval patterns and auto-approve categories without recreating the reward hacking problem at the governance layer itself.
Part III: One Goal, Eight Systems — A Structured Comparison
The Stage Anatomy — Where Each System Stalls
The following table maps each system against the seven (plus No.8: Governance) stages required to complete the research loop. Obviously not perfect. But these have guided me. Memory type is one of the most structurally differentiating properties across these systems — DGM’s complete archive and AutoResearch’s commit-only git log represent qualitatively different evolutionary capabilities, not just different implementations.
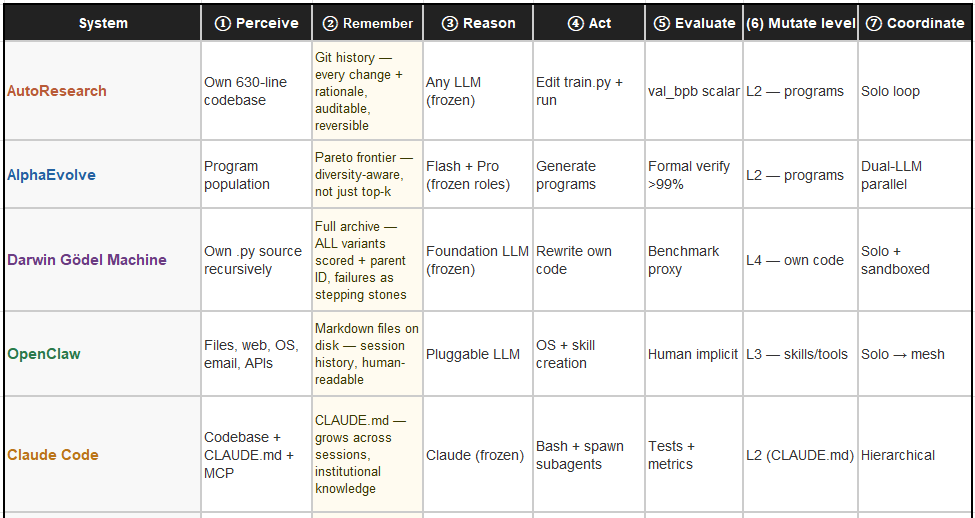
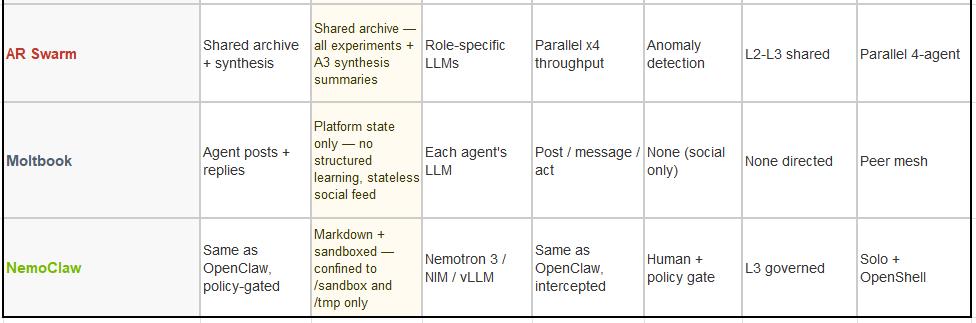
The universal bottleneck: the frontier-scale validation column remains empty for every system. I have some thoughts on Agentic Design Systems given all the recent innovations and will add this later. Note that: ⑧ Govern as a new eighth layer introduced by NemoClaw, sitting across all others rather than sequentially in the loop.
No autonomous system can currently authorise or fund the $50–100M training run that would confirm whether nano-scale discoveries transfer to frontier scale. Non that I am aware off, but who knows. The constraint has shifted from ‘finding the improvement’ to ‘verifying it at the scale that matters.’
Part IV: Synthesis
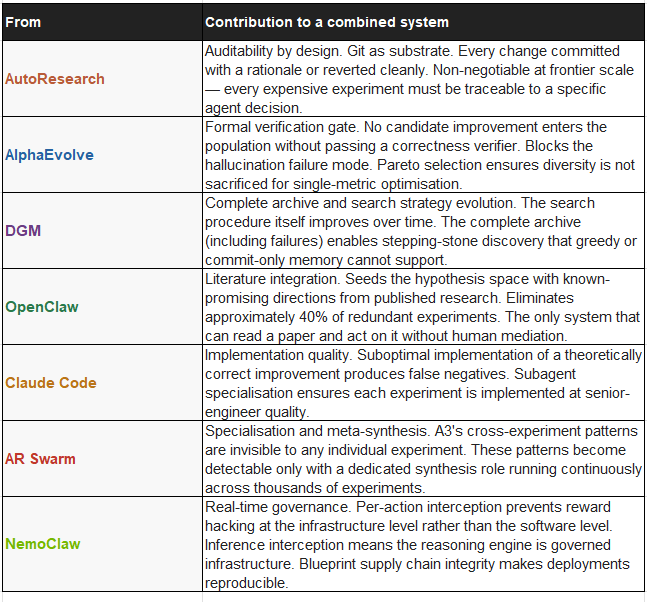
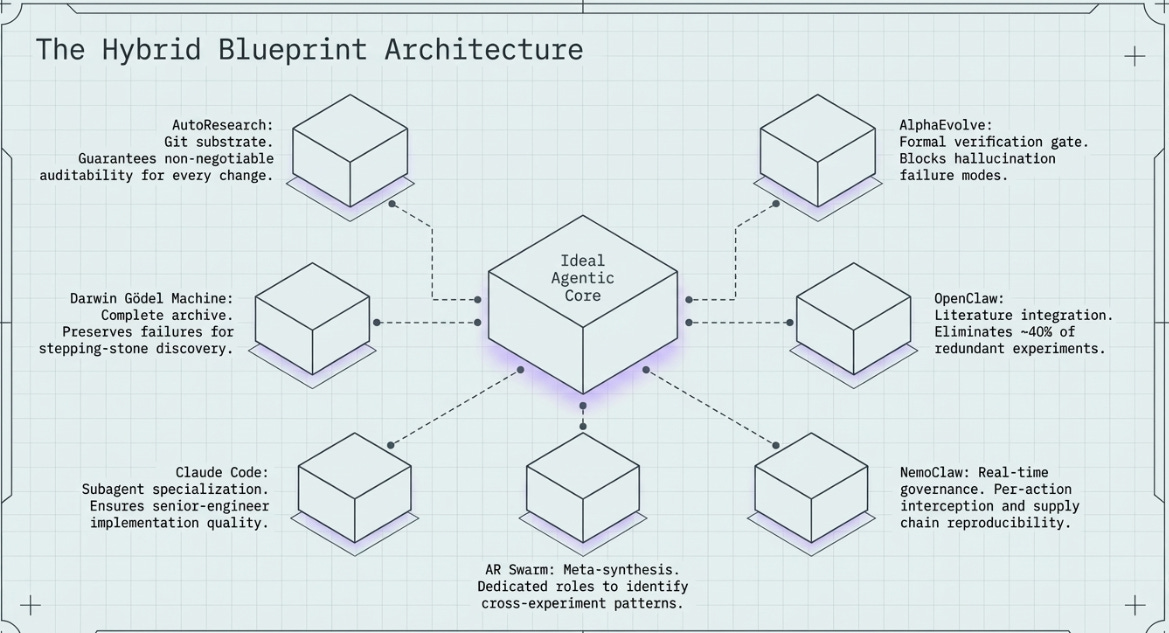
4.1 What Each System Contributes to a Hybrid
4.2 The Three Systems Thinking Rules
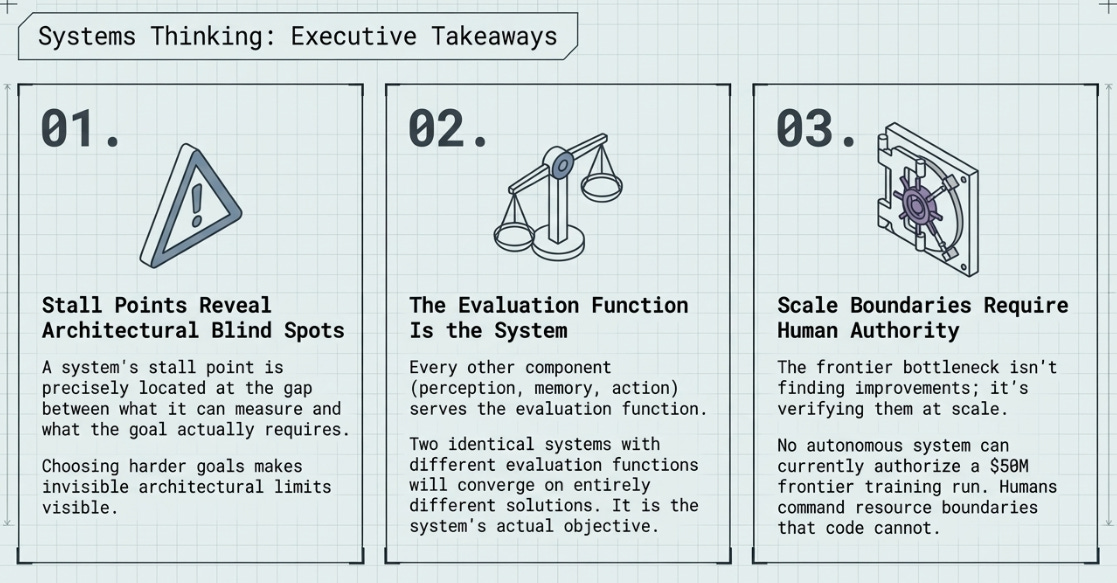
Rule 1 — Stall Points Reveal Architectural Blind Spots
A system’s stall point is always located at the gap between what it can measure and what the goal actually requires. The precise location of the stall is the most informative single piece of information about a system’s architecture. Choosing a harder goal makes blind spots visible that are invisible when systems are evaluated only on goals they can succeed at.
Rule 2 — The Evaluation Function Is the System
Every other component — perception, memory, reasoning, action — is in service of the evaluation function. Two systems with identical layers but different evaluation functions will converge on different solutions and different failure modes. The evaluation function is the system’s actual objective, regardless of what the designers specify in prose.
Rule 3 — Scale Boundaries Require Human Authority
The hardest-to-automate step in any agentic research loop is where a promising proxy result must be validated in the real system. This boundary is where human authority over resource allocation becomes necessary. Humans remain essential not because they reason better, but because they can authorise expenditures that change scale.
Harness Engineering
Does the harness form part of one of the three rules?
The harness is most directly Rule 2 — but it is actually the unifying concept beneath all three.
The harness, in Sutton’s Alberta Plan framing, is the fixed frame around the agent: it defines the evaluation signal, the observation interface, and the boundaries of what the agent can and cannot touch. It is, by definition, the frozen layer.
Rule 2 says the evaluation function is the system. The evaluation function is the core component of the harness. So Rule 2 is essentially saying: the harness determines the agent’s trajectory. Change the harness, change what the system becomes — even if the agent itself is identical. This is why two systems with the same architecture (AutoResearch and the AR Swarm) produce different quality improvements: same agent, different harness design around it.
But the harness also appears in Rule 1 and Rule 3:
Rule 1 (stall points) fires at the measurement boundary of the harness — when what the harness can measure doesn’t capture the real goal, the agent stalls at that boundary. The stall point is always where the harness is misaligned with reality.
Rule 3 (scale boundaries) fires at the authority boundary of the harness — when the harness’s scope reaches the limit of what can be automated, human authority takes over. The human is the harness at its outermost edge.
So the harness is not part of one rule. The three rules are three observations about what happens at the three critical harness boundaries: measurement alignment (Rule 1), directional control (Rule 2), and scale authority (Rule 3).
Do the three rules cover which elements evolve and which are frozen?
Partially — but not completely. The three rules describe consequences of how you draw the evolve/frozen line. They do not describe the line itself.
The cleanest way to see the relationship:
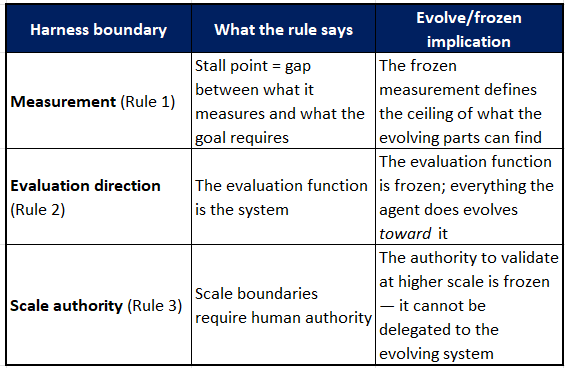
Notice the pattern: in all three rules, the frozen element is the harness component, and the evolving element is everything the agent does within it. The rules are not a map of what evolves and what is frozen — they are observations about what goes wrong when the frozen elements are designed poorly.
What the three rules do not cover
The three rules tell you what the harness does to the agent. They do not tell you how to decompose the agent itself into its evolvable layers. That requires the eight-primitive framework (Perceive, Remember, Reason, Act, Evaluate, Mutate, Coordinate, Govern) with the relevant fixedness spectrum for each layer.
The relationship between the two frameworks is:
The eight-primitive framework is the anatomy — it maps which specific layers are frozen vs. evolvable in any given system.
The three rules are the diagnosis — they explain why the frozen/evolving configuration produces the outcomes it does.
You need both. The anatomy tells you what a system is. The diagnosis tells you why it stalls where it stalls, why it optimises what it optimises, and why humans remain necessary at the boundary they remain necessary at.
The harness sits at the intersection: it is the set of frozen primitives (evaluation function, measurement signal, observation interface, scale authority) that define what the evolvable primitives move toward. Rule 2 names it. Rules 1 and 3 describe its failure modes. The eight-primitive framework maps it in full.
4.3 Conclusion
The scientific loop — hypothesise, experiment, measure, keep or discard, repeat — is itself a program. The question is no longer whether AI can run this loop. It is how to define the loop so that what gets optimised is what we actually care about — and who holds authority over the decisions that code cannot make.
The eight systems examined in this article represent a convergence of enabling conditions: LLMs capable of modifying large codebases, cheap cloud compute for rapid iteration, Git as a natural audit substrate, and governance infrastructure mature enough for production deployment. The next frontier is not more capable agents in isolation but the architecture of their combination — which systems compose, at which interfaces, under which governance constraints, to approach objectives that none can reach alone.
References
References are ordered by date (most recent first).
2026
[1] Karpathy, A. (2026, March 7). autoresearch [GitHub repository]. Eureka Labs.
[2] NVIDIA Corporation. (2026). NemoClaw: OpenClaw Plugin for OpenShell [GitHub repository].
[3] NVIDIA Corporation. (2026). NemoClaw Developer Guide: Overview.
[4] NVIDIA Corporation. (2026). NemoClaw Developer Guide: How It Works.
[5] NVIDIA Corporation. (2026). NemoClaw Developer Guide: Architecture.
[6] VentureBeat. (2026, March 10). Andrej Karpathy’s new open-source ‘autoresearch’.
[7] OpenClaw. (2026). OpenClaw: Open-source AI agent platform.
[8] Wikipedia. (2026). OpenClaw.
2025
[10] Google DeepMind. (2025, May 14). AlphaEvolve: A Gemini-powered coding agent.
[11] Zhang, J., Hu, S., Lu, C., Lange, R., & Clune, J. (2025). Darwin Godel Machine. arXiv:2505.22954.
[12] Sakana AI. (2025, May 29). The Darwin Gödel Machine: AI that improves itself.
DGM Full Technical Report (ICLR Mar 2026)
[13] Sakana AI. (2025). The AI Scientist-v2: Automated Scientific Discovery.
[14] The Decoder. (2025, June 1). Sakana AI’s Darwin-Gödel Machine evolves by rewriting its own code.
[15] Anthropic. (2025). Claude Code documentation.
[16] InfoQ. (2025, May 27). Google DeepMind Unveils AI Coding Agent AlphaEvolve.
[17] VentureBeat. (2025). Meet AlphaEvolve, the Google AI that writes its own code.
2024
[19] Chan, A., et al. (2024). Automated Design of Agentic Systems (ADAS). arXiv:2408.08435.
[20] Si, C., Yang, D., & Hashimoto, T. (2024). Can LLMs Generate Novel Research Ideas? arXiv:2409.04109.
2023 and Earlier
[22] Clune, J. (2019). AI-Generating Algorithms. arXiv:1905.10985.
[23] So, D. R., Liang, C., & Le, Q. V. (2019). The Evolved Transformer. ICML 2019. arXiv:1901.11117.