
The Speciation of Intelligence
AlphaEvolve's evolutionary search to Pi's self-extending minimal core to Hermes's closed learning loop — A field guide to the harnesses now running AI Agents, and the engineering discipline required

The "Speciation of intelligence" refers to the evolutionary process by which distinct forms or levels of intelligence emerge and become reproductively isolated in different populations, leading to the creation of new species with unique cognitive abilities. In the context of human evolution, it often highlights how social and cultural pressures drove hominids toward a specialized "cognitive niche," separating them from other primates.
~ Source: Unknown?
"Agentic AI represents a qualitative leap: these systems do not require micromanagement—they learn and adapt. They pursue objectives. They surprise even their creators."
— Sunil Kulkarni, Cognizant Technology Solutions“…Intelligence is the ability to achieve Complex Goals…” Life 3.0: Being Human in the Age of Artificial Intelligence
A Test That Doesn’t Test the Right Thing Is Worse Than No Test at All
There is a particular kind of institutional blindness that emerges when an evaluation metric becomes a proxy for the thing it was meant to measure. Language models are increasingly deployed as autonomous agents — entities that plan multi-step tasks, write and execute code, interpret tool outputs, and revise their approach mid-task. Yet the dominant evaluation paradigm remains the accuracy-on-a-benchmark model, unchanged in spirit since 2020.
The field’s response has not been incremental. Between 2020 and 2026, at least eight fundamentally distinct evaluation philosophies emerged — each encoding a different answer to the same question: what property of intelligence actually matters? They disagree profoundly. A model that passes one harness can fail the next. The harness you choose determines the signal you receive and, therefore, the model you build next.
This is a field guide to the taxonomy: the loop architectures, what each one can and cannot see, which ones you can actually run, and how to sequence them.
— Andrej Karpathy, AutoResearch README, March 2026
Note
All cited results in this report are drawn from published papers or open repositories. Where a framework’s capabilities are described structurally — showing what a harness does rather than reporting a specific experimental outcome — this is noted clearly in the text.
Several systems discussed (AlphaEvolve, NVIDIA SCORE) are not publicly available to run. Their loop architectures are described from published technical reports; the results cited are those reported by their authors, not independently reproducible by readers of this article. Where they are open source, a case study that follows will serve better cause than a set of summary notes (these are best reviewed either with a pre-run enterprise exercise, or a case study review - as a learning aid)
From Mathematical Fossils to Self-Extending Agents
Era I: Natural Selection (2020–2022)
AutoML-Zero and its successors treated neural architectures as organisms — mutating low-level operations, selecting survivors, discarding failures. The insight was genuine: optimization pressure applied to the program itself, not just its weights, could find solutions humans would never design. The limitation was equally genuine: systems operating purely bottom-up, without high-level intent, consumed enormous compute to discover things a competent engineer could sketch in an afternoon.
Era II: The Artificial Scholar (2024–2025)
Sakana AI’s The AI Scientist (2024) introduced the top-down inversion: start with a research hypothesis generated by an LLM, execute the experiment, write the paper, run peer review. Evaluation shifted from benchmark accuracy to scientific novelty — a category that no leaderboard captures. Simultaneously, AlphaEvolve (Google DeepMind, May 2025) demonstrated that evolutionary search guided by LLMs as mutation operators could beat 56 years of human mathematical effort on matrix multiplication. The paper has been published; the system itself is internal to Google.
Era III: Recursive Engineering & Persistent Learning (2025–2026)
Karpathy’s AutoResearch hands the model its own training script and a compute budget; what it discovers is hardware-specific and non-transferable by design. Sakana AI’s Darwin Gödel Machine (May 2025) goes further: the agent modifies its own codebase and validates each change empirically on coding benchmarks — improving from 20% to 50% on SWE-bench across self-modification cycles, a result the authors published and the code for which is publicly available.
At the practitioner layer, Pi and Hermes Agent define two opposing philosophies of how deployed agents should grow over time.
Eight Frameworks, Eight Theories of Mind
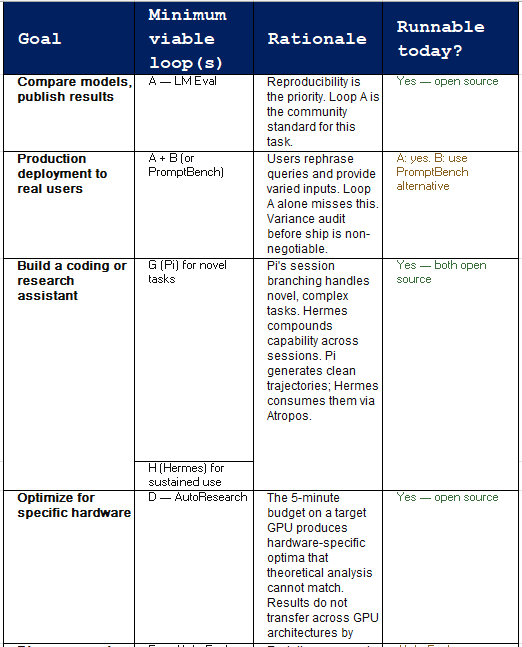
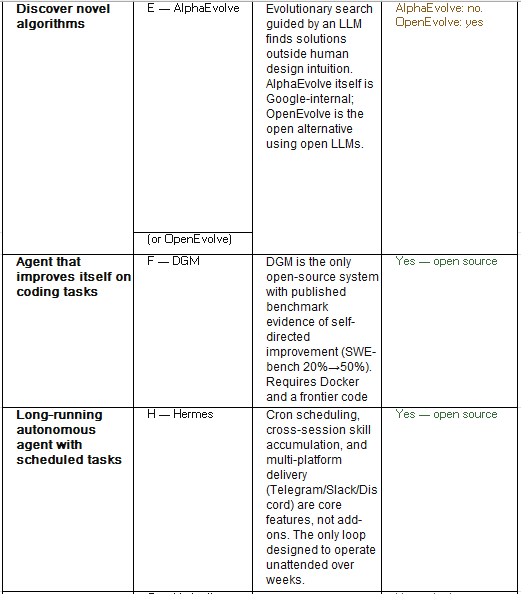
The table below maps each framework to the property of intelligence it measures — and, critically, whether it can actually be run. Availability matters: describing AlphaEvolve and SCORE as equivalent options to LM Eval Harness would be misleading.
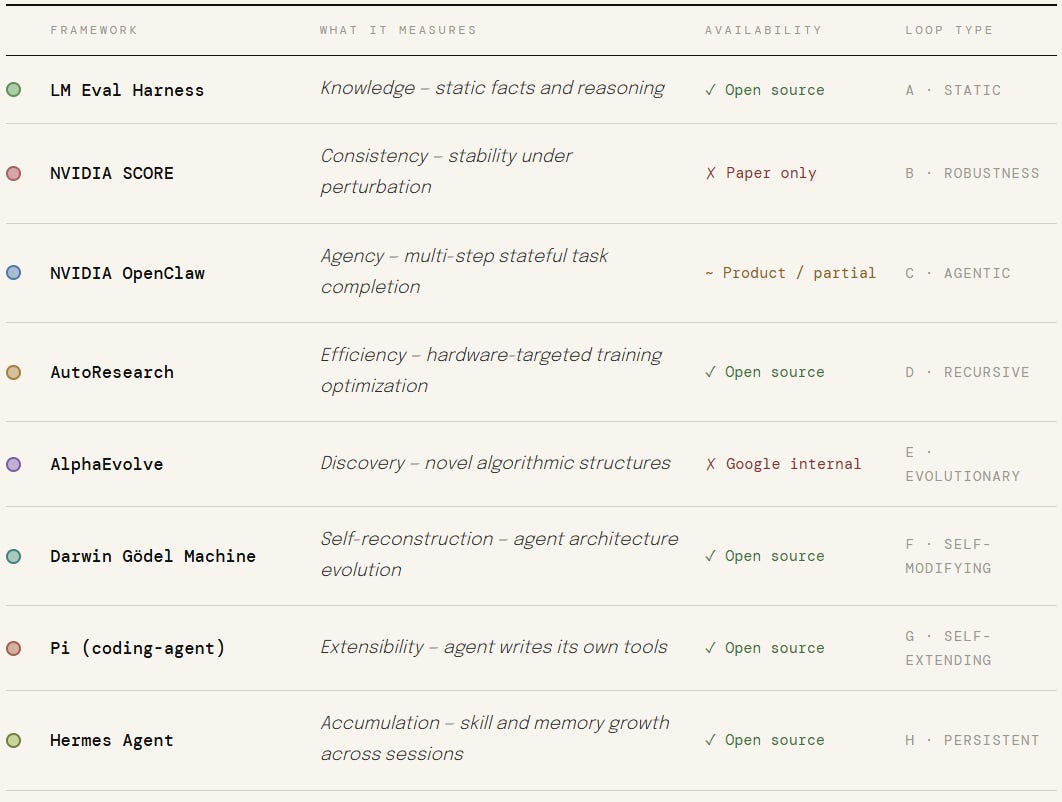
Availability shapes strategy. For Loops B and E, you are reading research results and drawing architectural lessons — not running experiments. For Loops A, D, F, G, and H, you can fork the repository today.
Why the Same Model Returns Different Results from Different Harnesses
Each loop is a different information flow architecture. The variations — where feedback enters, whether state persists, whether the objective is fixed or agent-controlled — determine what the harness can and cannot observe. The flow diagrams below describe the structural logic of each loop. The illustrative task used throughout is intentionally generic: improving a language model’s performance on a long-context coding task. This is not a reported experiment; it is a structural walk-through to make the loop differences concrete.
A. The Static Baseline Loop
A fixed prompt set enters. Inference runs once at a fixed temperature. A scalar metric is logged. There is no second chance, no perturbation, no adaptation. The harness evaluates the model on exactly the questions it knows how to ask, phrased exactly as the benchmark author intended.
Its value is reproducibility. Every lab, every paper, every arXiv submission uses the same benchmark. The community has a shared lingua franca — imperfect but shared. Its structural limit is equally clear: Loop A measures best-case performance under ideal conditions. It has nothing to say about what happens when the prompts are different, the context is longer, or the task requires multiple steps.
What Loop A sees in the illustration: The model scores well on short-context coding benchmarks. The report is filed. If the team stops here, they ship a model whose real-world failures — longer contexts, rephrased problems, multi-step execution — are structurally invisible to the evaluation.
Published evidence — EleutherAI
The LM Evaluation Harness is the canonical open-source benchmark framework, used to produce the majority of model comparison tables published in 2024–2026. It supports over 200 tasks including MMLU, HumanEval, and GSM8K. Results are reproducible across institutions.
Source: github.com/EleutherAI/lm-evaluation-harness
Ideal prompt phrasing, fixed context length, single-pass — all conditions that production deployments routinely violate. Variance across phrasing and length is invisible.

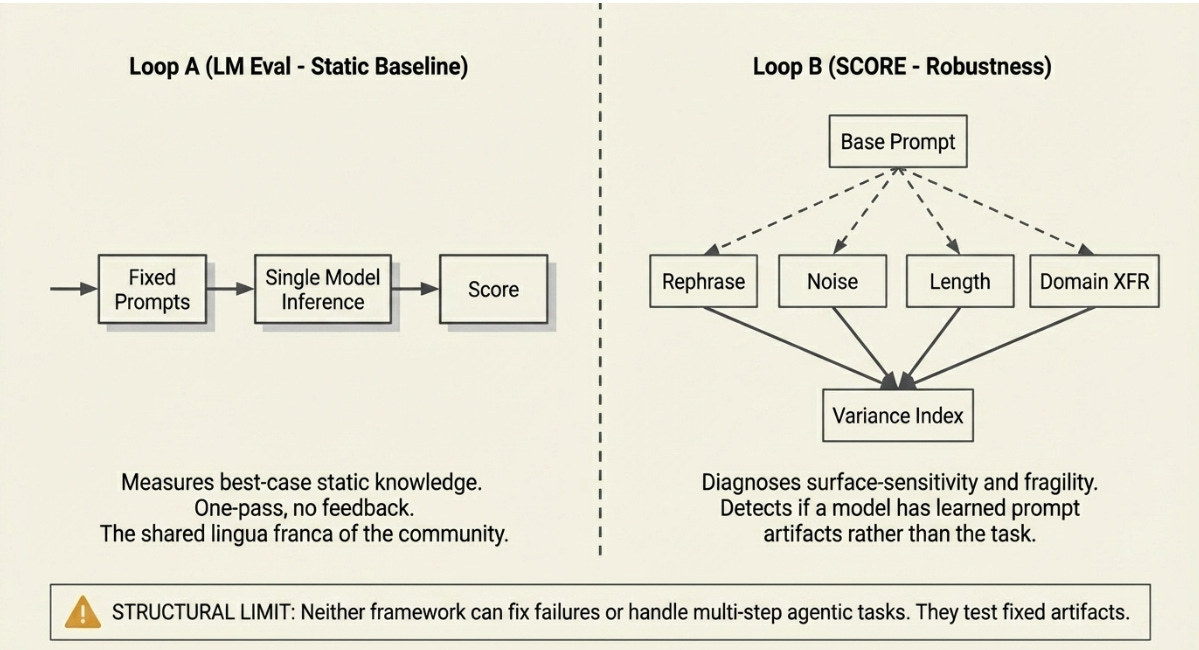
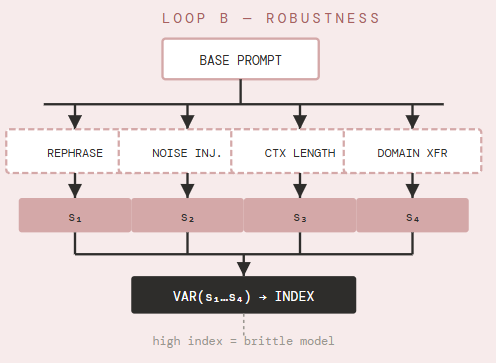
B. The Adversarial Robustness Loop
NVIDIA’s SCORE framework argues that typical evaluations “report a single metric representing the model’s best-case performance.” Loop B finds fragility by fanning a single prompt into a family of semantically equivalent variants — rephrased, noisy, domain-shifted, length-varied — and measuring the variance of the resulting score distribution.
The structural innovation is fan-out before evaluation. Rather than asking once, the harness generates multiple question variants and compares outcomes. High variance signals surface-sensitivity: the model has learned prompt artifacts rather than the underlying task. This is the gap between a lab demo and a production deployment.
What Loop B sees that A cannot: whether the benchmark score is stable across the rephrasing and context-length variations that real users naturally introduce. A model that scores well on Loop A but has high variance on Loop B will degrade significantly in any deployment that doesn’t carefully curate its prompts.
Access note: SCORE is described in a published paper and referenced in NVIDIA’s research outputs. There is no public implementation to download and run. The architectural lesson — fan-out perturbation plus variance scoring — can be reproduced using PromptBench (Microsoft, open source).
Published evidence — NVIDIA (2025)
The SCORE paper (arXiv:2503.00137) documents the methodology and reports evaluation results on major language models showing substantial variance between best-case and perturbed performance. The consistency index is the core reported metric.
NVIDIA SCORE · arXiv:2503.00137 · 2025 · Code: not public · Open alternative: PromptBench (github.com/microsoft/promptbench)
Structural Limit: Diagnoses fragility but cannot fix it. Cannot tell you whether the model is useful as an end-to-end agent for multi-step tasks.
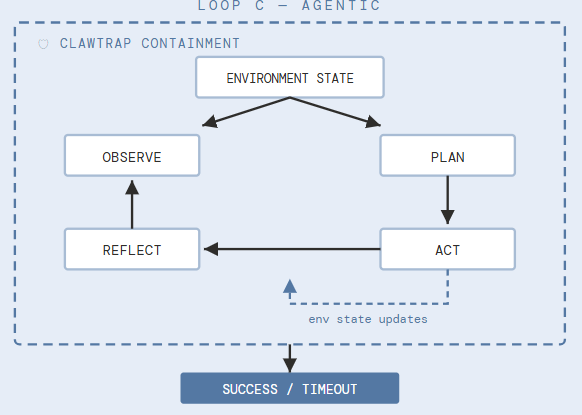
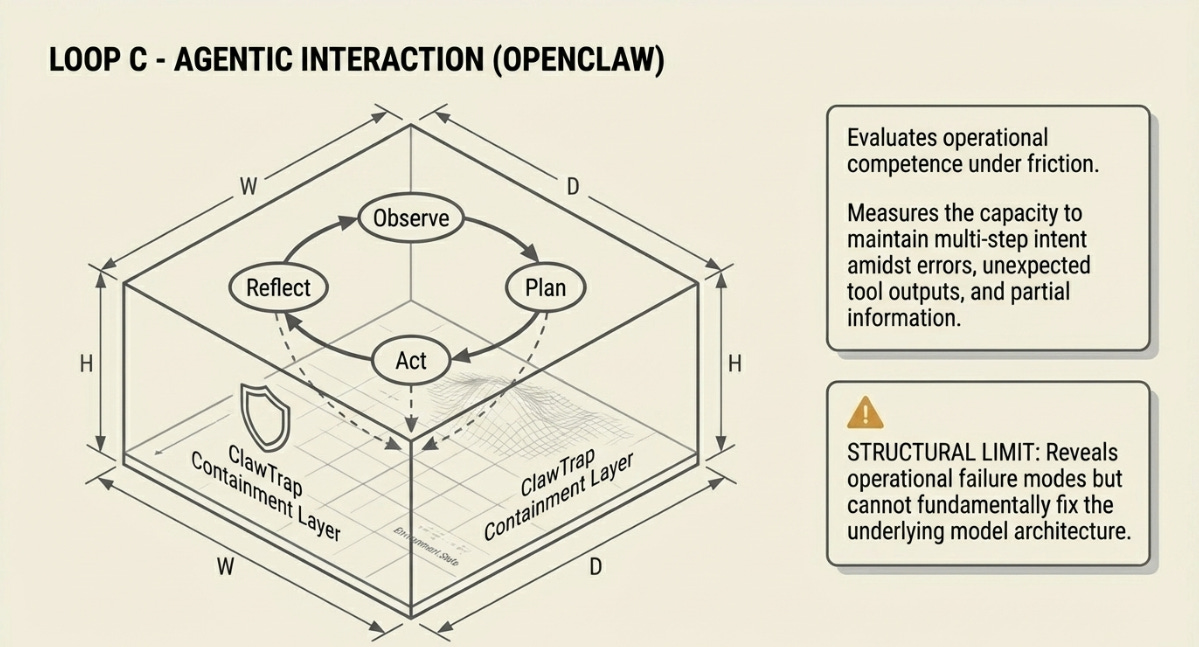
C. The Agentic Interaction Loop - Nvidia OpenClaw
Loop C is the first stateful loop. The model does not answer a question — it acts on an environment, which changes in response, and must then interpret the environment it just modified. The cycle — Observe, Plan, Act, Reflect — repeats until the task completes or the budget expires.
OpenClaw provides real tooling: browser access, code execution environments, file systems. What is being evaluated is not static knowledge but operational competence under friction — the capacity to maintain multi-step intent in the presence of errors, unexpected tool outputs, and partial information. The ClawTrap security layer monitors for prompt injection and unauthorized tool calls.
What Loop C adds that A and B cannot see: whether the model can self-correct. A model that knows the right answer on Loop A but cannot use that knowledge to recover from a failed tool call will fail on Loop C. The two failure modes look identical from the outside but require entirely different fixes.
Architecture evidence — OpenClaw / ClawTrap (2026)
OpenClaw is described in the ClawTrap security paper (arXiv:2603.18762). The Observe-Plan-Act-Reflect loop is the standard agentic scaffold; OpenClaw’s contribution is the containment layer (ClawTrap) and the real-browser, real-IDE tooling that makes the environment genuinely stateful.
ClawTrap: arXiv:2603.18762 · OpenClaw product: openclaw.ai ·
Note: Pi is the open-source substrate underlying OpenClaw
Structural Limit: Reveals operational failure modes but cannot fix them. Cannot discover a better underlying architecture — only test the one already deployed.
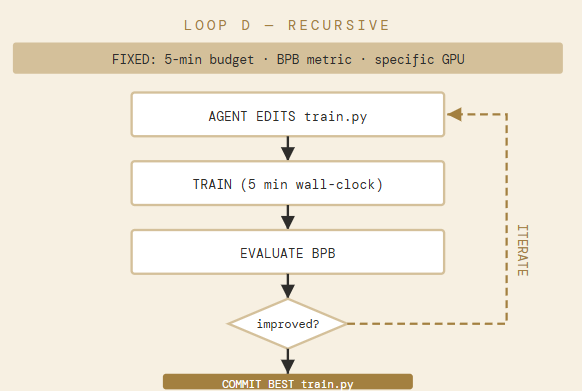
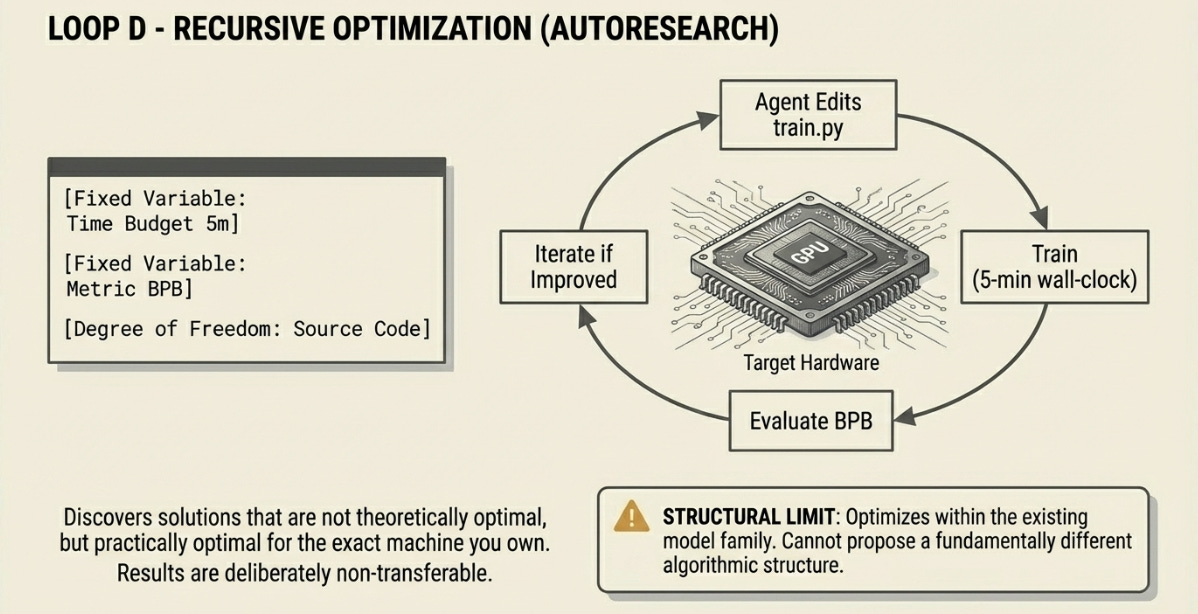
D. The Recursive Optimization Loop
AutoResearch fixes two parameters and maximizes one: a time budget (5 minutes of training per iteration on the target hardware), a metric (Bits-Per-Byte on a held-out corpus), and the degree of freedom (the source code of train.py). The agent edits its own training script and reruns within the budget.
The constraint is the design. By fixing time to 5 minutes on a specific GPU, the harness forces the discovery of solutions that are efficient on that exact hardware — not theoretically optimal, but practically optimal for the machine you actually own. Results are non-transferable between GPU architectures. This is a feature, not a bug: it eliminates the gap between benchmark performance and production performance on your actual hardware.
What Loop D adds that others miss: it modifies the model. Every other loop evaluates a fixed artifact. Loop D produces a different artifact at the end. If you run Loop A before and after Loop D, you will get different results — because they are different models.
Architecture note — AutoResearch (Karpathy, 2026)
AutoResearch is available on GitHub. The loop structure — edit training script, run 5-minute training, evaluate BPB, iterate — is described in the repository README. No formal paper with benchmark comparisons has been published at the time of writing; the repository documents the design intent and loop structure.
github.com/karpathy/AutoResearch · Open source · Karpathy, March 2026
Structural Limit: Optimizes within the existing model family and training procedure. Cannot propose a fundamentally different algorithmic structure — only refine implementation details of the current one.
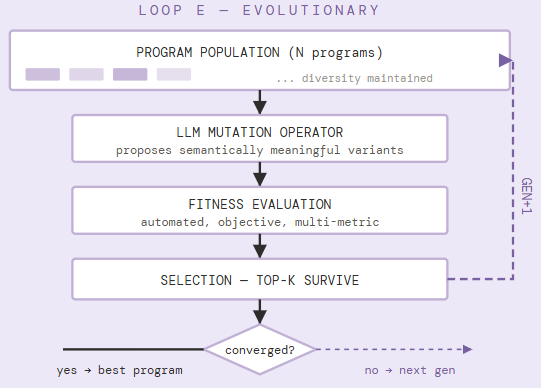
E. The Evolutionary Discovery Loop
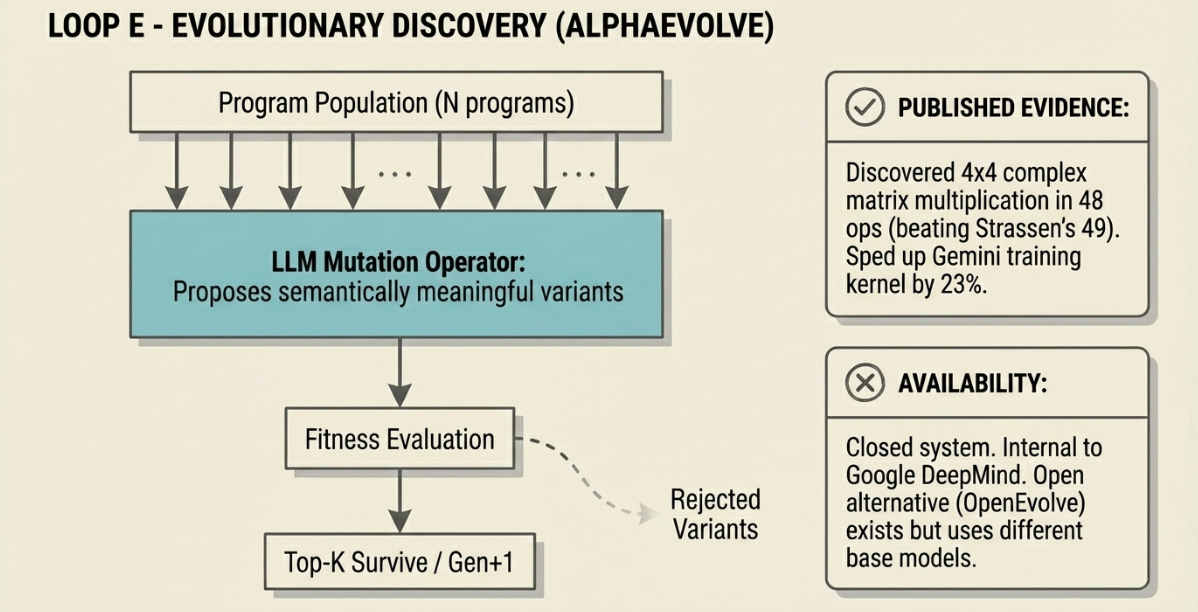
AlphaEvolve uses the LLM not as a reasoning agent but as a structured mutation operator — generating syntactically valid, semantically coherent program variants that purely random search would never reach. A population of programs is maintained, mutated, evaluated against a fitness function, and selected. This iterates until convergence.
The key insight separating AlphaEvolve from earlier evolutionary approaches is that the LLM understands the structure of code well enough to propose mutations that are likely to be interesting rather than merely syntactically valid. This dramatically narrows the search space while preserving access to solutions outside any human designer’s intuition.
Critical access note: AlphaEvolve is internal to Google. Its results code — the discovered algorithms — is published in a Colab notebook. The system itself cannot be run by external researchers. Community implementations like OpenEvolve (Hugging Face) reproduce the architecture using open LLMs but are not the same system. Results cited below are from Google’s published paper.
Published evidence — AlphaEvolve (DeepMind, May 2025)
AlphaEvolve discovered an algorithm multiplying 4×4 complex matrices using 48 scalar multiplications, improving on Strassen’s algorithm (49 multiplications) for the first time since 1969. It optimized a FlashAttention kernel achieving up to 32.5% speedup in benchmarks, and sped up a critical Gemini training kernel by 23%, cutting overall training time by ~1%. Across 50+ open mathematical problems, it matched state-of-the-art in ~75% of cases and improved on known solutions in ~20%.
Novikov et al., arXiv:2506.13131 · Results code only: github.com/google-deepmind/alphaevolve_results · Open alternative: github.com/codelion/openevolve
F. The Self-Reconstruction Loop
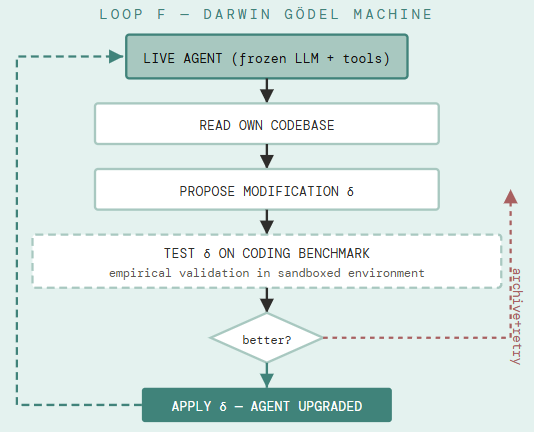
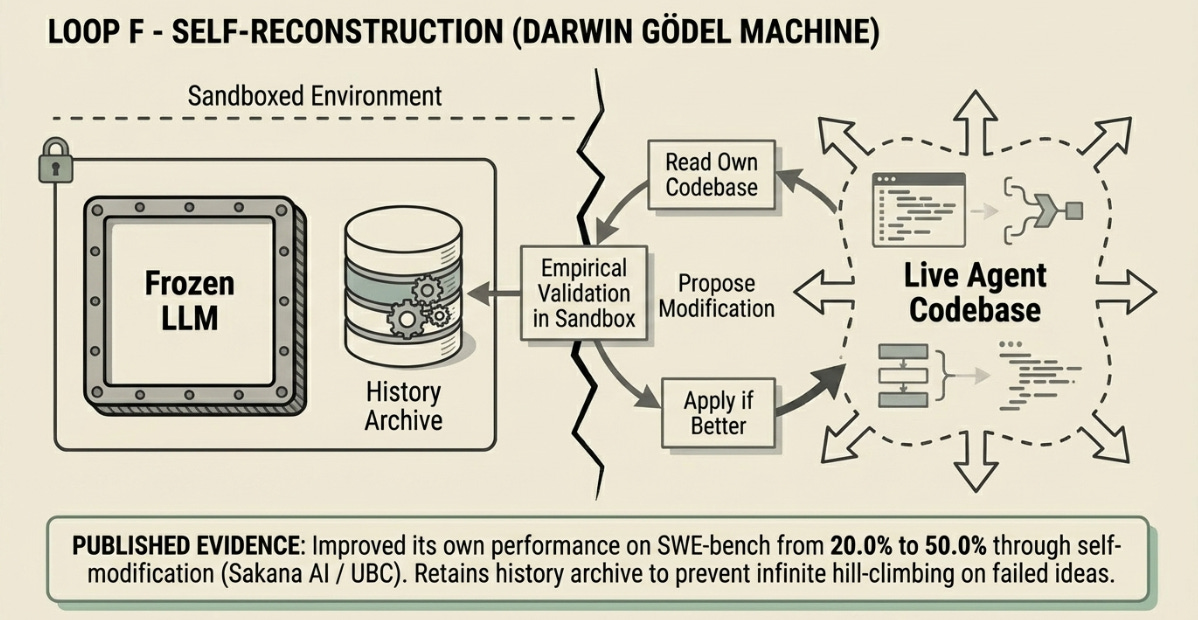
The Darwin Gödel Machine relaxes the original Gödel Machine’s impractical requirement — that a self-modification must be provably beneficial — in favour of empirical validation. Each proposed modification to the agent’s own Python codebase is tested against coding benchmarks. Modifications that demonstrate improvement are retained; others are discarded. An archive of all generated agent variants is maintained to support open-ended exploration rather than hill-climbing.
In practice, the DGM improves at the agent-architecture level: it adds patch validation steps, improves file viewing tools, adds history of what has been tried and why it failed, and refines its own editing workflow. These are not weight updates — the underlying LLM is frozen. The system improves by improving how it uses the LLM it was given.
What distinguishes Loop F: the agent that completes the loop may be architecturally different from the agent that started it. Its tools, its workflow, and its self-evaluation criteria may all have changed. The code repository is open; with an API key for a capable code model and Docker, the loop can be reproduced.
Published evidence — DGM (Sakana AI / UBC, May 2025)
On SWE-bench (resolving real-world GitHub issues), DGM improved its own performance from 20.0% to 50.0% through self-modification. On Polyglot (multi-language coding), it went from 14.2% to 30.7%, significantly outperforming hand-designed baseline agents. The code to reproduce these runs is publicly available.
Zhang et al., arXiv:2505.22954 · Code: github.com/jennyzzt/dgm · Requires: Docker, API key for frontier code model
Structural Limitation: The underlying LLM is frozen — DGM improves how it uses the model, not the model itself. Compute costs are substantial; the published runs used significant GPU-hours. Improvements are measured on coding benchmarks only.
Pi and Hermes: Two Philosophies of How Agents Should Grow
Loops A through F were designed primarily by research labs for evaluation and discovery. They answer: what can a model do under controlled conditions? Pi and Hermes answer a different question: how should an agent behave when real work needs to get done, repeatedly, over time?
G. The Minimal Self-Extension Loop
Pi by Mario Zechner - 4 tools, Session trees, Hot-reload extensions, OpenClaw substrate
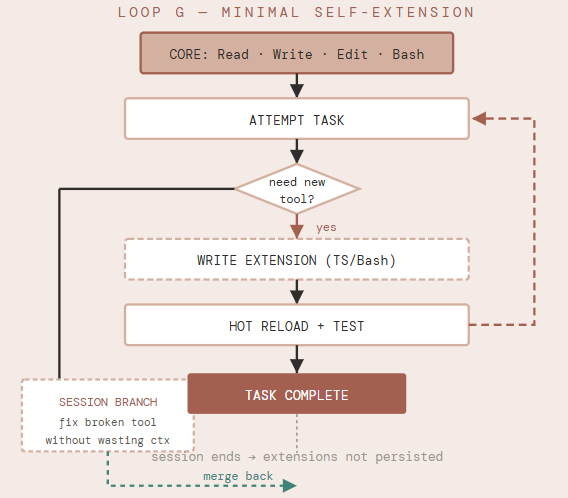
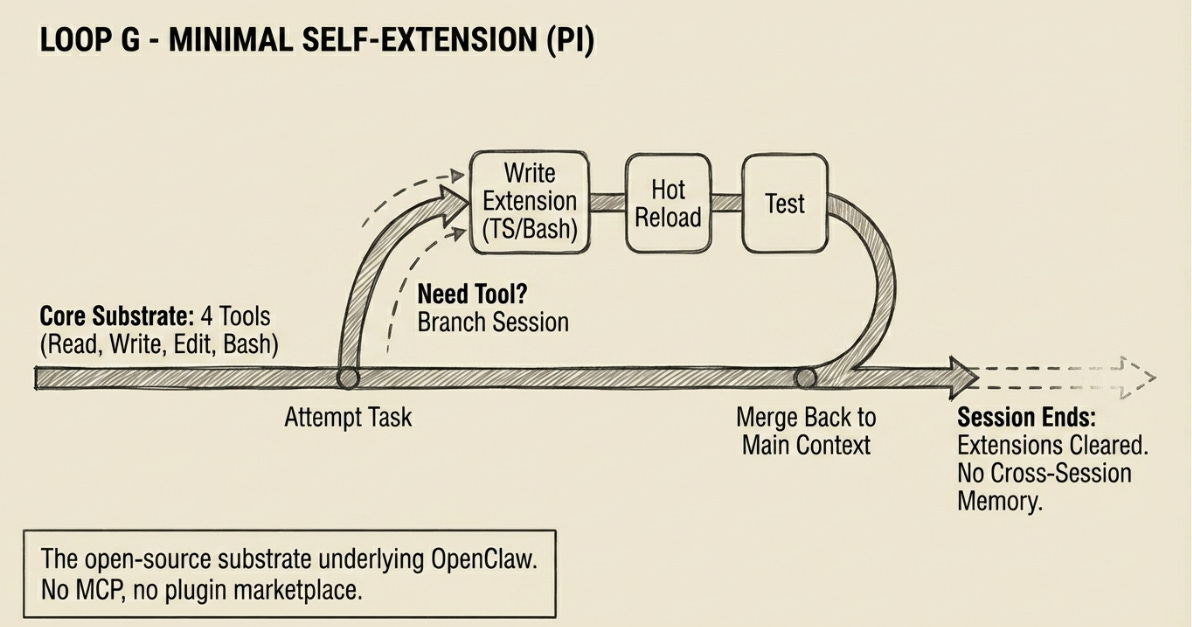
Pi is, by deliberate design, the smallest viable coding agent. Its tool surface is four items: Read, Write, Edit, Bash. Nothing else. No MCP support, no plugin marketplace, no predefined skill library. This is the architecture, not an omission.
The design philosophy: if the agent needs a capability it doesn’t have, it should build it using the four tools it does have. Rather than downloading a browser-automation extension, Pi writes one. Rather than loading a database MCP server, Pi writes a Bash script. The resulting tools are crafted to the exact specification the current task requires — not generic, not downloaded from someone else’s repository.
The structural innovation enabling this is the session tree. Pi sessions are not linear — they branch. When a tool breaks mid-task, the agent forks into a side branch to fix it without consuming context in the main session. When the fix is complete, the session rewinds and continues. This is lightweight multi-agent coordination without explicit orchestration infrastructure.
Hot reloading closes the self-extension loop: the agent writes an extension, reloads the runtime, tests it, and iterates — without restarting the conversation or losing context. Extensions can persist state to disk across turns within a session.
Pi is the substrate on which OpenClaw is built. Understanding Pi means understanding what is actually executing inside Loop C.
Architecture evidence — Pi (Zechner, 2026) / Ronacher writeup
Armin Ronacher (lucumr.pocoo.org, January 2026) documents Pi’s architecture in detail: shortest system prompt of any production agent he is aware of, four-tool core, session-tree branching, hot-reload extension system, and the deliberate exclusion of MCP. Pi’s exclusion of MCP is architectural: MCP requires tools to be loaded into the system context at session start, making hot-reload incompatible with the context cache.
github.com/badlogic/pi-mono · 5.1k stars · lucumr.pocoo.org/2026/1/31/pi/ · MIT license
Structural Limitation: Session-local only. Every new Pi session starts from the same four-tool core — extensions built in one session do not persist to the next. Pi has no cross-session memory or skill accumulation.
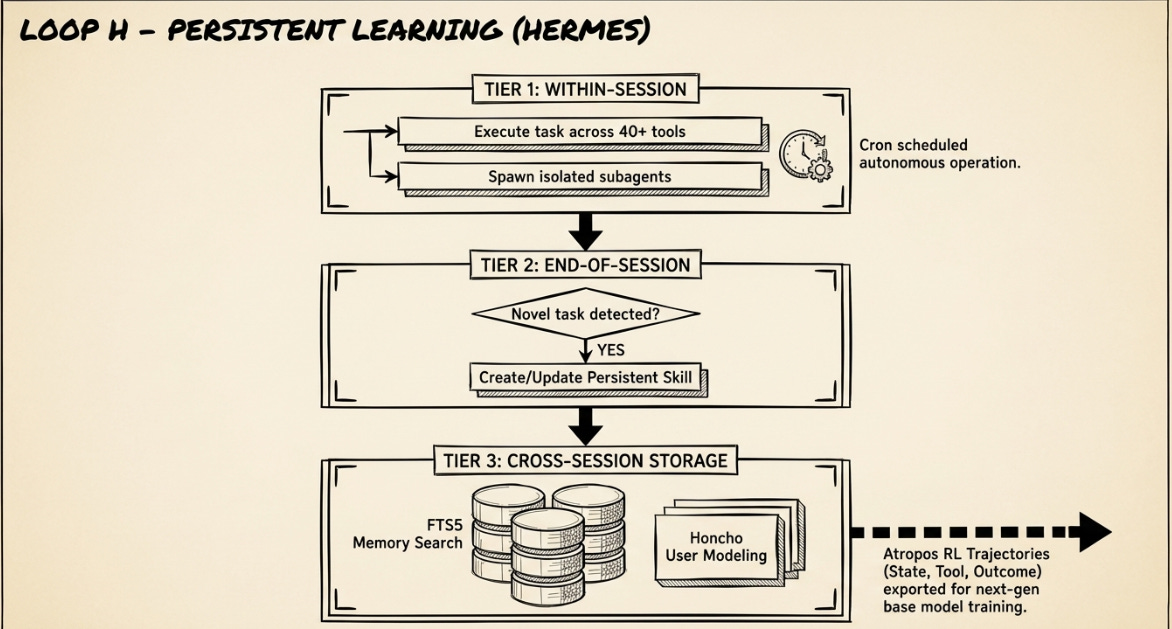
H. The Persistent Learning Loop
Hermes Agent by Nous Research - Skill creation from experience, Cross-session memory, RL trajectories
Hermes is described in its own README as “the agent that grows with you.” Unlike every other system in this taxonomy, Hermes is explicitly designed to compound capability across sessions rather than reset at each run. Three mechanisms work in concert across three timescales.
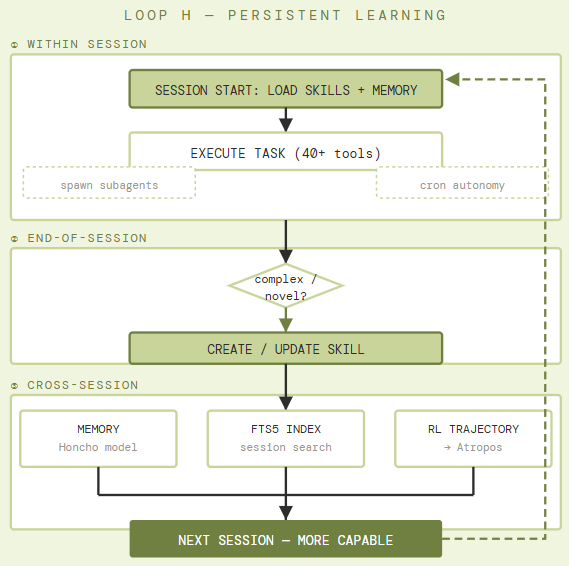
Within-session: Hermes executes tasks using a 40+ tool suite across six execution backends (local, Docker, SSH, Daytona, Singularity, Modal) and can spawn isolated subagents for parallel workstreams. Cron scheduling enables fully autonomous operation — tasks run unattended on schedule and deliver results to Telegram, Discord, Slack, WhatsApp, or Signal.
End-of-session: After complex tasks, Hermes evaluates whether the work justifies creating a persistent skill — a documented, reusable procedural memory entry indexed under ~/.hermes/skills/ and compatible with the agentskills.io open standard. Skills self-improve during use.
Cross-session: An FTS5 full-text search index over prior sessions, with LLM-powered summarization, allows the agent to recall relevant prior work. Honcho dialectic user modeling builds a persistent model of the user across sessions. Critically, Hermes generates RL trajectories via the Tinker-Atropos integration — labeled (state, tool-call, outcome) tuples from successful complex tasks that feed into training pipelines for the next generation of tool-calling models.
Architecture evidence — Hermes Agent v0.7.0 (Nous Research, April 2026)
Hermes v0.7.0 (released April 3, 2026) documents the persistent skill creation loop, FTS5 session search, Honcho user modeling, and Atropos RL trajectory generation. Unsurprisingly, the repository has 26.1k stars, 271 contributors, and an active migration path from OpenClaw. The README explicitly notes the closed learning loop as the system’s core differentiator.
github.com/NousResearch/hermes-agent · v0.7.0 · MIT license · hermes-agent.nousresearch.com/docs
Structural Limitation: Skill store can accumulate stale or incorrect procedural knowledge that persists across sessions. No formal guarantee that accumulated skills improve performance on all task variants — a skill optimized for one environment may degrade on another. Requires audit as the skill base grows.
Choosing and Sequencing the Loops
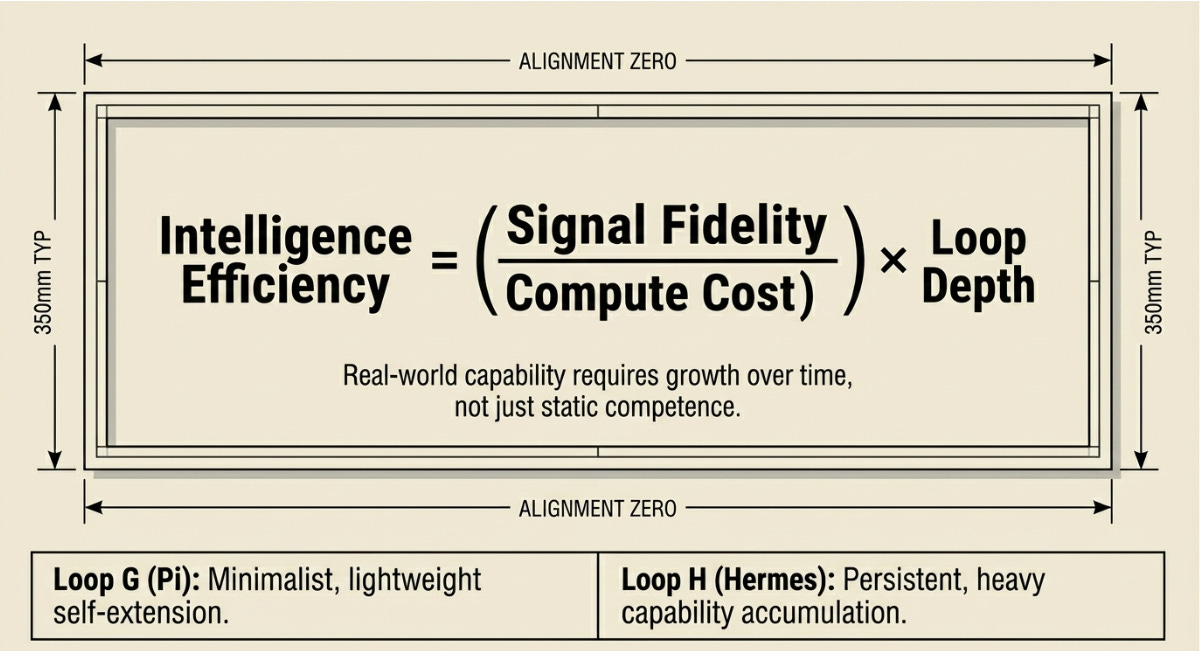
Intelligence Efficiency = ( Signal Fidelity / Compute Cost ) × Loop Depth
Basically, Signal per dollar, multiplied by the number of feedback dimensions the harness can access
No serious evaluation pipeline uses a single loop. The skill is in knowing which loops to sequence, in which order, and at what point to stop. The table below is a practical guide based on the structural properties of each loop — not on proprietary experimental results. Where a harness is unavailable (B, E), the architectural lesson can be partially reproduced using open alternatives.
Or something like this?

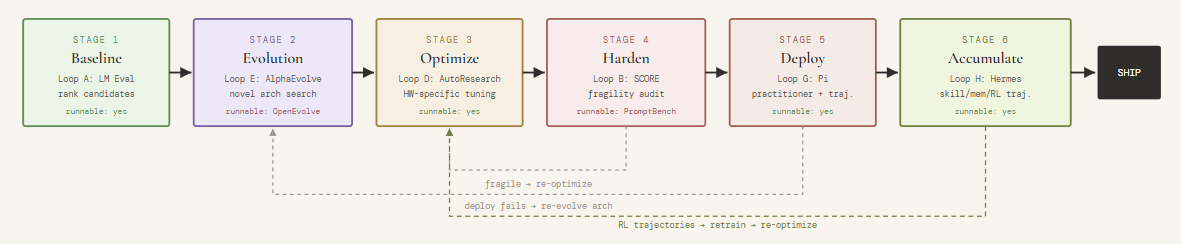
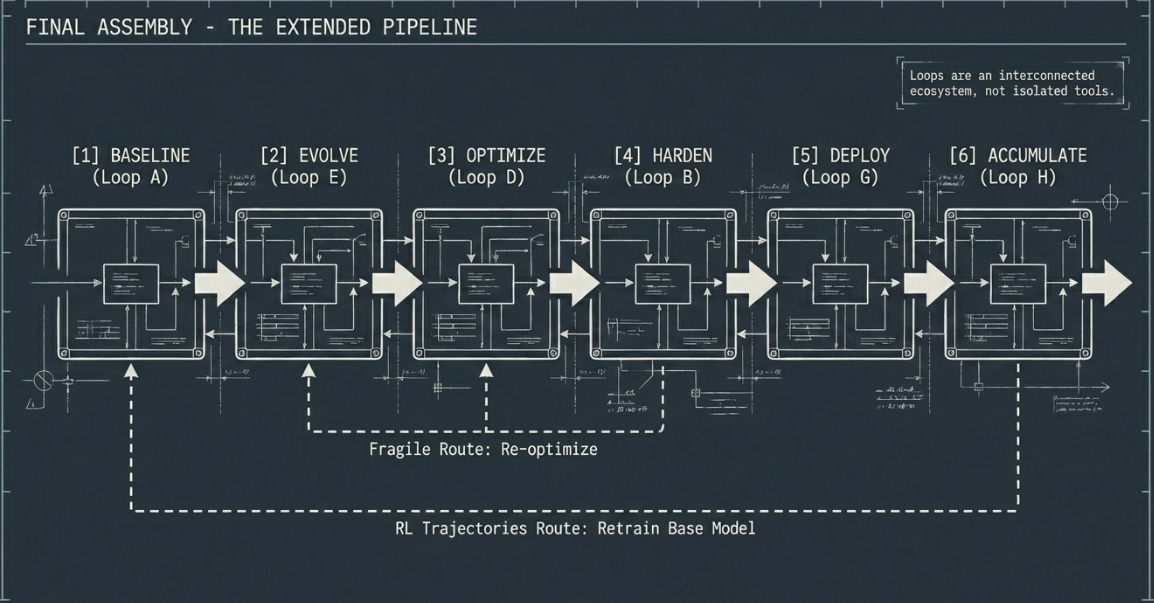
The Extended Pipeline: Loops in Sequence
For teams investing in the full stack, the following sequence represents current best practice, as I see it... Failure at any stage routes back — the pipeline is not a waterfall.
References:
Research Papers
Google DeepMind May 2025 arXiv:2506.13131
AlphaEvolve: A Coding Agent for Scientific and Algorithmic Discovery
Sakana AI / UBC May 2025 arXiv:2505.22954
Darwin Gödel Machine: Open-Ended Evolution of Self-Improving Agents
NVIDIA SCORE: Robustness Evaluation for Language Models
Sakana AI 2024 arXiv:2408.06292
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Practitioner Systems
Loop G - Four-tool minimal core, session-tree branching, hot-reload extensions. OpenClaw is built on Pi. TypeScript.
Armin Ronacher - The Minimal Agent Within OpenClaw
Pi: The Minimal Agent Within OpenClaw
Loop H. Persistent skill creation, FTS5 session memory, Honcho user modeling, Atropos RL trajectory generation, cron scheduling, 6 execution backends
Open Benchmark Infrastructure
Loop A. Canonical open-source benchmark framework. 200+ tasks. The community standard for model comparison tables.
Loop B alternative. Open robustness evaluation: perturbation, adversarial prompts, variance analysis. Runnable substitute for NVIDIA SCORE.
Loop D. Minimal self-improving training harness. Fixed 5-min budget, BPB metric, hardware-specific hill-climbing.
Hugging Face OpenEvolve
Loop E open alternative. Reimplements AlphaEvolve architecture using open LLMs. Results differ from Google’s internal system.