
Two Architectures of Control
Bounded Evolution vs. Composable Constraints in Agentic Systems

I recently wrote ‘What Should — and Should Not — Evolve in Self-Improving Multi-Agent Systems?’, which builds a four-tier safety taxonomy from a convergent body of academic research spanning Columbia, Princeton, Renmin University, and Anthropic — arguing that certain components of any self-improving agentic system must be architecturally frozen, and others must evolve only under strict governance conditions. I do apply this framework, which I find creates amazing discipline in harness engineering or at least how multi-agent systems guardrails apply. I have additionally taken note of some critical findings (in When The Recipe Gets In The Way) depending on how much thought-chaining and multi-step approaches are necessary depending on domain (within which it is being applied to) vs what the base model can perhaps already respond to - To ensure the instruction (skills or markdown) file(s) do not overwrite any latent competence the model already possesses.
Note that I treat everything “agentic” as fast evolving, from which there are many wonderful learning lessons (let me refer to them simply as “adaptations” or “evolutions”, no different from the systems we use, study, or put into place). Therefore many, manyyyy things we figure out, as we get into the weeds of various ongoing projects. Adapted to circumstances and “fit for purpose” requirements.
So Matt Pocock’s skills repository, additionally, came as a fantastic, relevant, recent find - offering 9 Core Engineering markdown files and a one-line npm installer, arguing that the best way to maintain control over a coding agent is to stay simple, composable, and close to the decision chain. There is much elegance in the way he addresses agentic construct.
In truth, these two positions are not in direct conflict. They are operating at different altitudes. But placing them in dialogue surfaces something important: the architecture article builds, and the practical control the skills approach exercises, are describing the same problem from the top down and the bottom up, respectively. From my perspective, understanding where they agree, where they diverge, and what each gets wrong is more useful than treating them as separate concerns.
The multi-agent article asks: how do you govern a system that can modify itself? Pocock asks: how do you stay in control of a tool that can act for you? They are both correct that the answer is the same — you fix what must not move, and you let everything else evolve.
The Multi-Agent Article: A Taxonomy of Bounded Evolution
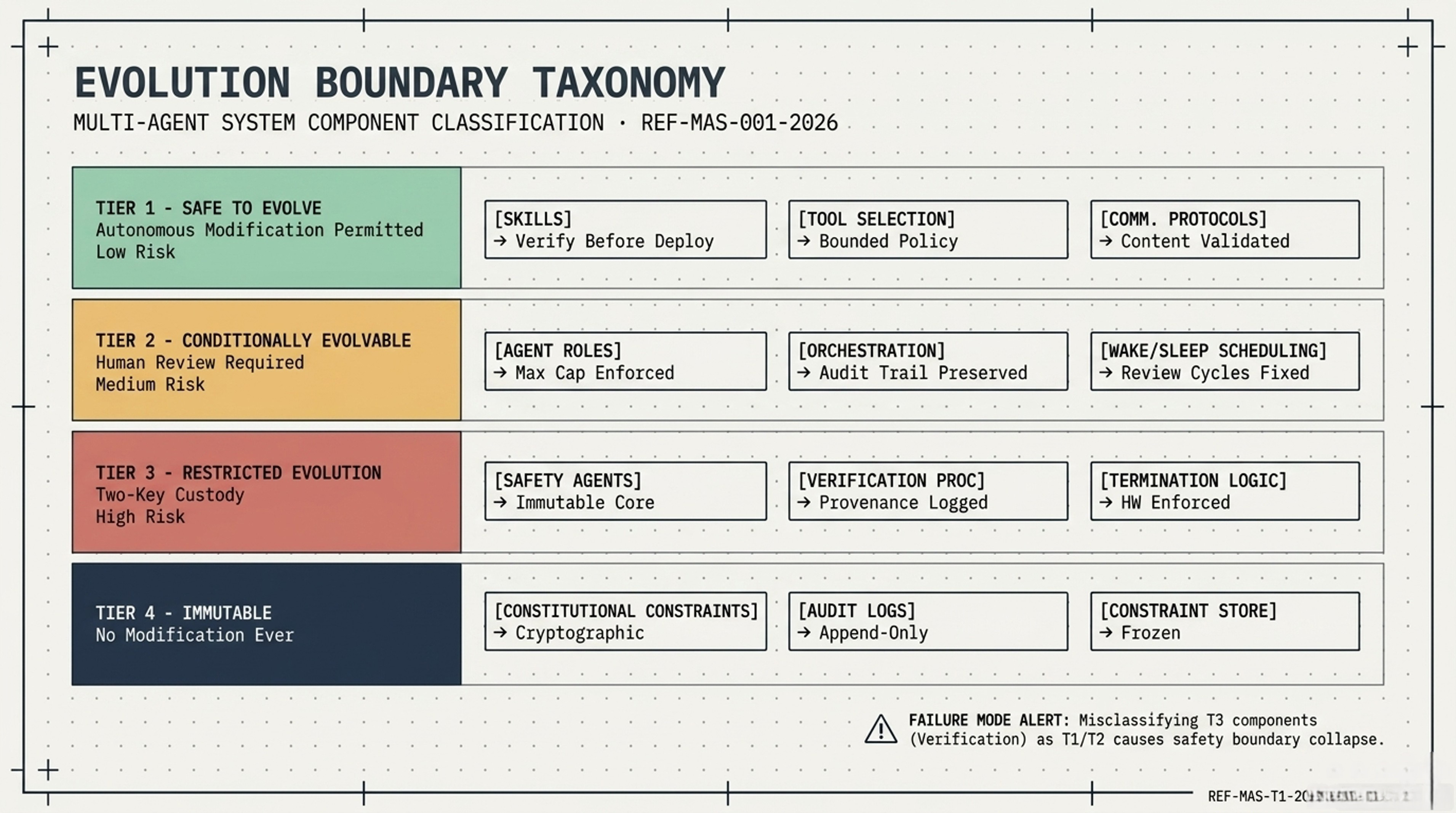
The article’s central claim is structural: in any multi-agent system capable of self-modification, components must be classified before they are built according to how dangerous it is to allow them to evolve. The four-tier taxonomy it proposes assigns everything from skill libraries (Tier 1, safe to evolve autonomously) to constitutional constraints and audit logs (Tier 4, never modified under any circumstances) into a clear governance hierarchy.
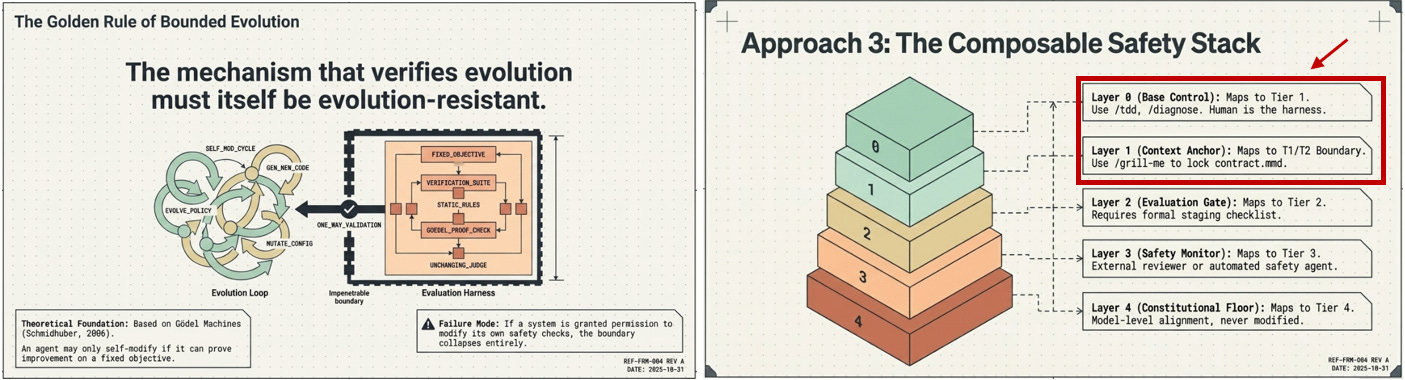
The architecture principle the article derives is somewhat elegant: fix the axioms, fix the verifier, and let everything else evolve within those constraints. The verifier — whatever checks whether an evolution is safe — must itself be outside the evolution loop. If the system can modify its own safety checks, the safety boundary collapses. The article calls this the Golden Rule of agentic evolution.
Supporting this argument are two specific research findings the article leans on heavily. The Statistical Limits Theorem, attributed to Columbia University (2025), claims that simultaneous unconstrained improvement across five axes of self-improvement is statistically impossible without system instability — meaning at least one axis must be frozen, and the article argues that axis should be alignment. The Safety Vanishing problem, from Renmin University and BAAI (2026), documents that safety specifications drift toward reduced restrictiveness over time in self-evolving multi-agent societies, even without any malicious intent — simply through the accumulated effect of individually reasonable adaptations.
Matt Pocock’s Skills: Composable Practitioner Control!!!
Pocock’s argument is operational (taking more control back), non-theoretical - i enjoyed recent sharings of his here (100% watch and take notes).
His repository is a collection of 9 Core Engineering markdown files — skills — that a developer loads into a .claude or agents directory and invokes as slash commands. Skills like grill me, TDD, and diagnose are designed to solve specific, recurring failure modes: the agent going in the wrong direction, the code not working, the codebase accumulating structural debt.

The philosophy is explicit: no orchestrator, no planner, no spec kit, no runtime. Heavy-process frameworks like BMAD or GSD, in Pocock’s view, take control away from the engineer and make debugging harder. The value of skills is precisely their simplicity — they are small, composable, and adapt to the developer’s workflow rather than forcing the developer to adapt to a rigid framework.

The grill me skill — which interrogates the developer to resolve decision trees before any code is written — is the most architecturally significant. It functions as a context construction program that front-loads disambiguation, preventing the agent from building the wrong thing. Tosea.ai have a guide here.
The Composable Safety Stack
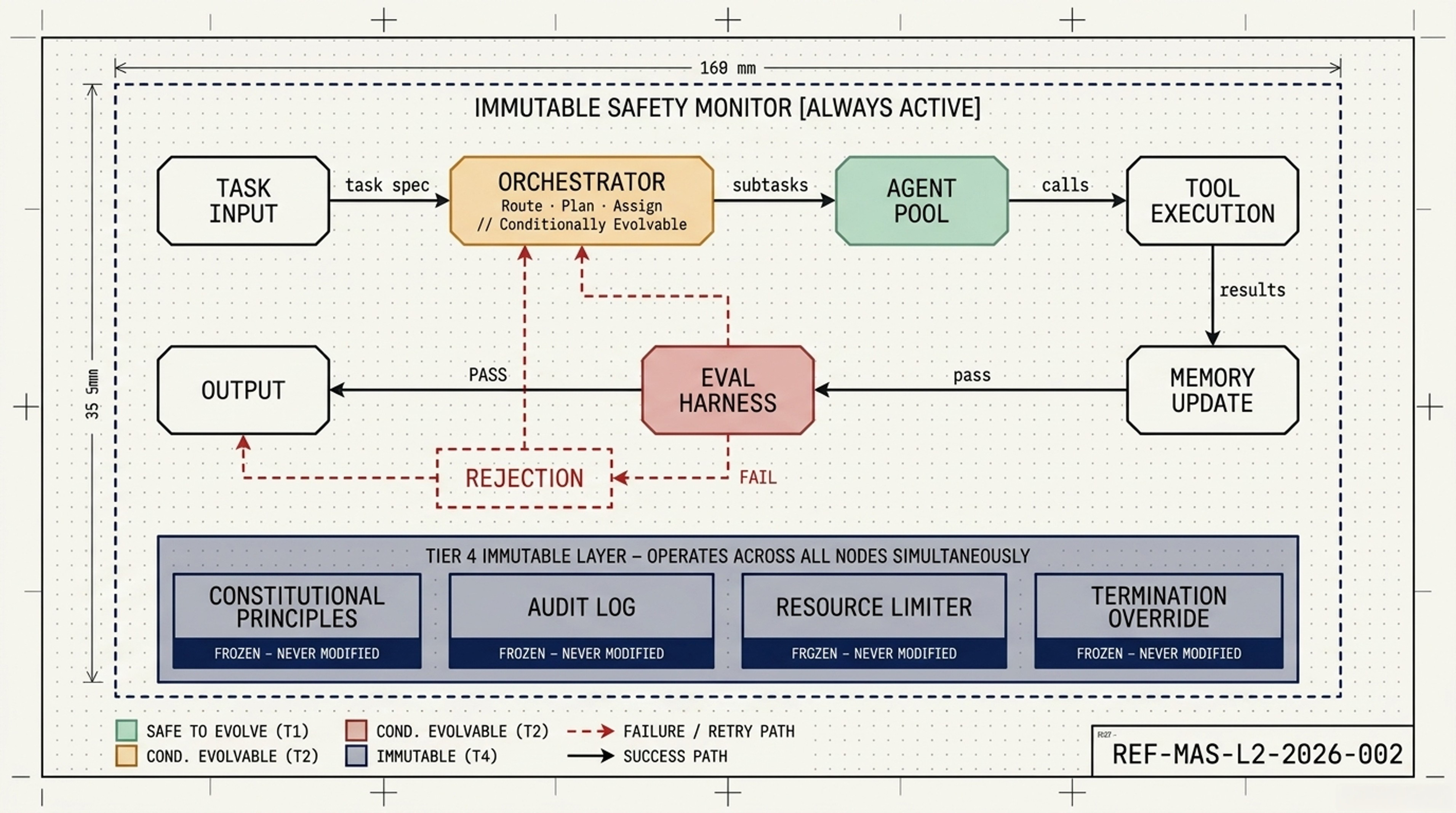
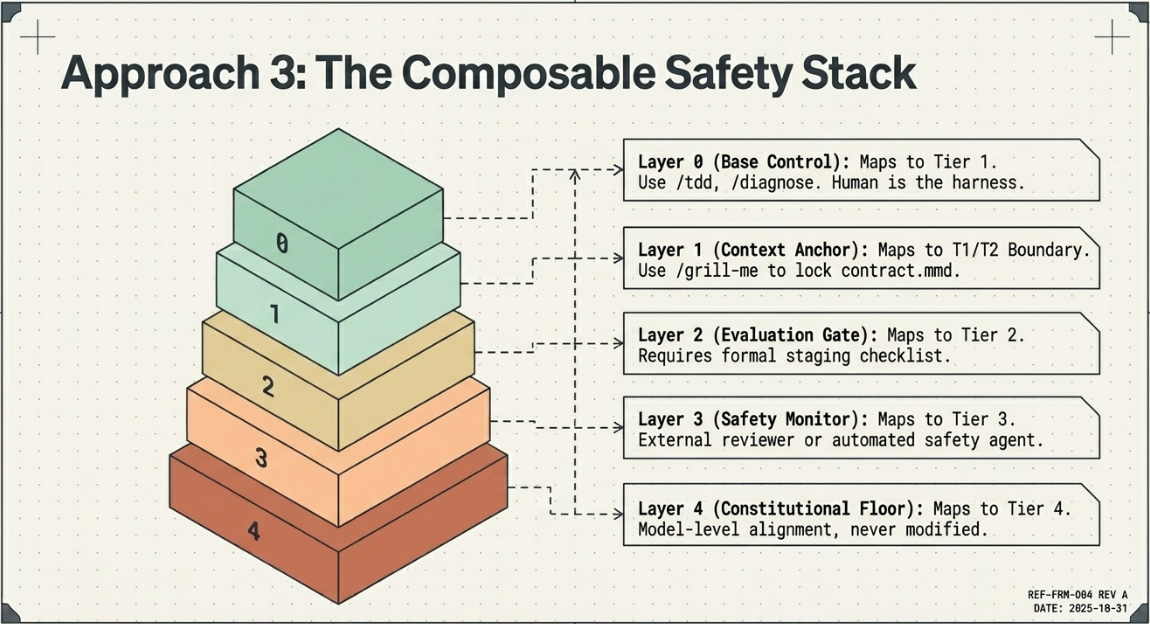
The central insight of the comparative analysis is this: Pocock’s skills are an excellent implementation of Tier 1 in the 4-Tier taxonomy. They are precisely the kind of safely-evolvable, practitioner-tunable, verification-gated (by the human developer) components that the ISR article argues should be autonomous.
The synthesis framework proposed here — the Composable Safety Stack — treats the two approaches not as alternatives but as complementary layers in a single architecture, with the selection of which layers to activate governed by task complexity, autonomy level, and consequence severity.
The Composable Safety Stack: Start with Pocock’s skills as the T1 evolvable layer. Add governance layers incrementally as task complexity, autonomy, and consequence severity increase. Never skip a level.
The Stack
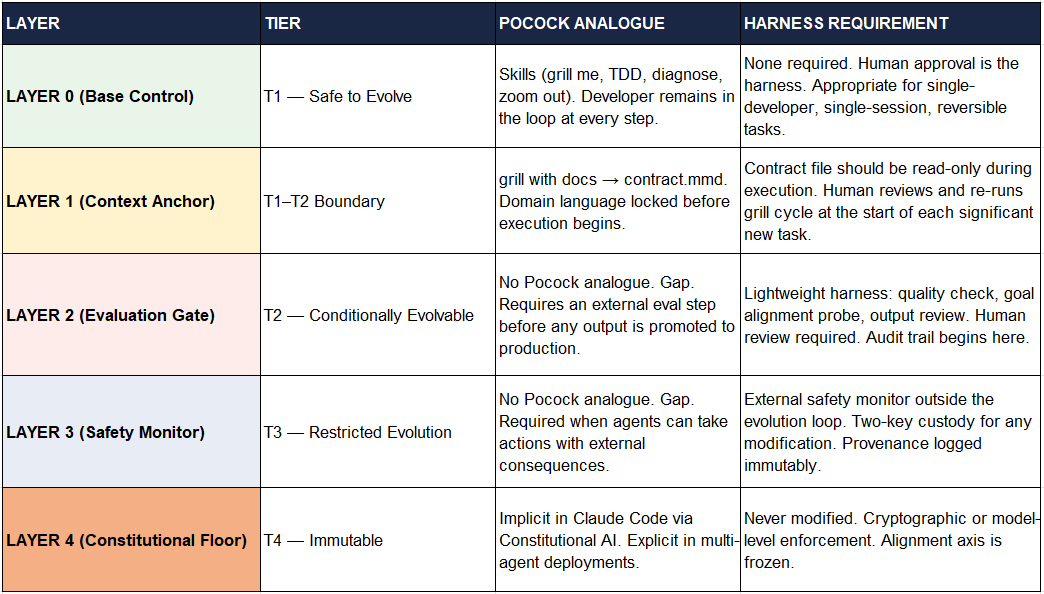
When to Add Each Layer
The practitioner’s question is not ‘which tier taxonomy applies to my system?’ but ‘at what point do I need to add the next layer?’ The Composable Safety Stack answers this with a simple escalation decision tree.
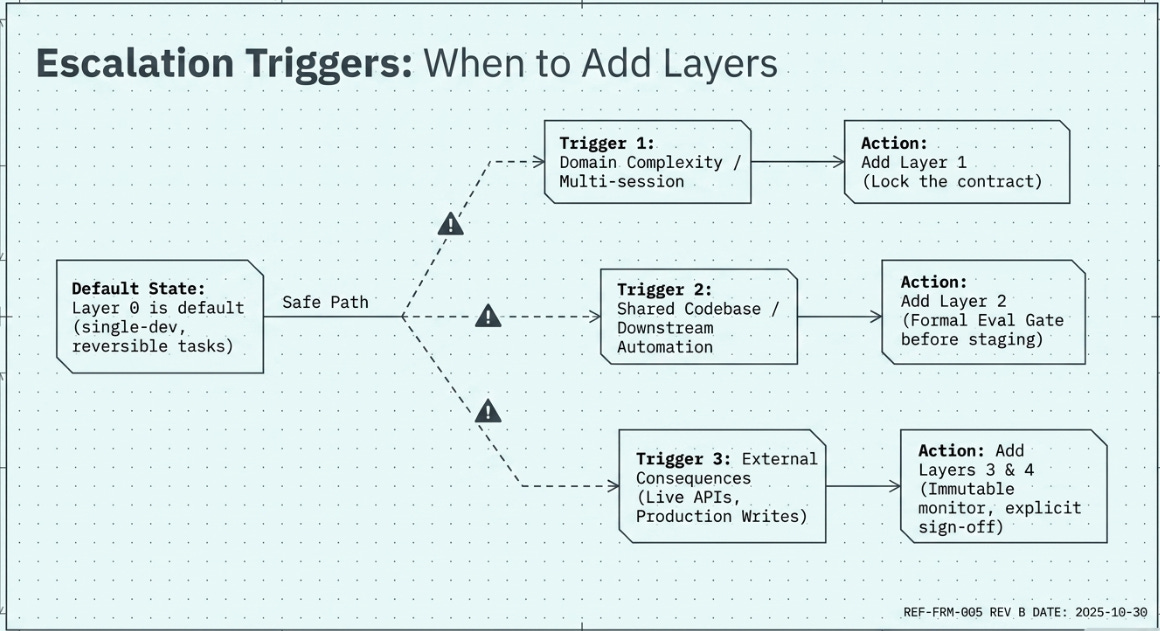
Layer 0 is always present. It is the default. Any developer using Claude Code, Cursor, or a similar tool with markdown skill files is operating at Layer 0. This is the Pocock starting point.
Add Layer 1 when: the task involves domain-specific language, multi-session continuity, or onboarding a new engineer. The contract.mmd pattern is the minimal viable implementation.
Add Layer 2 when: the agent’s output will be used by another person, published, committed to a shared codebase, or used as input to a downstream automated process. A lightweight eval step — even a structured human review checklist — is sufficient at this level.
Add Layer 3 when: the agent can take actions with external consequences: writing to production, executing API calls that affect real data, spawning sub-agents, or operating with reduced human supervision. This is where the ISR article’s harness architecture becomes mandatory rather than optional.
Add Layer 4 when: the system is multi-agent, partially autonomous, or capable of self-modification. At this level, the Anthropic Constitutional AI layer in the underlying model is not sufficient — it must be supplemented by explicit architectural enforcement.
To make the comparison concrete, we follow a single software development task through all three approaches - Pocock’s skills, Multi-Agent 4 Tier Framework and then a blend of both cases.
PART II
The task is this: a developer working on a customer-facing SaaS application needs to integrate Stripe payments — handling checkout sessions, processing webhooks, and writing payment records to the application’s database.
This task is a useful test case for several reasons. It involves multiple sequential steps that build on each other. It requires the agent to read and write real files in an existing codebase. It involves external API calls and, at the end, code that runs in production where mistakes can charge customers or corrupt financial records. And it is the kind of task a developer might reasonably hand to a capable coding agent today.
Task
Integrate Stripe payments (checkout + webhooks + database writes) into an existing Node.js/Express application
Developer
Solo developer, familiar with the codebase, first time working with Stripe
Agent
Claude Code or equivalent coding agent with file read/write and bash access
Stakes
Medium-high: errors could affect live users; payment data requires care; some actions are hard to reverse
Duration
Estimated 2–4 hours with agent assistance
Each approach below follows the same task from first prompt to shipped code. Pay attention to where the human makes decisions, where the agent acts autonomously, and where the system stops and asks for confirmation.
APPROACH 1: POCOCK’S SKILLS
The Practitioner Approach
Composable markdown skills · Developer stays in the loop · No framework, no runtime
The developer opens their project in their editor (VS Code with Claude Code, or Cursor). They have installed the Pocock skills via the npx installer, which has placed the skill files in the .claude/commands directory. There is no daemon running, no background process, no orchestrator. The developer types a slash command to begin.




APPROACH 2: THE HARNESS STACK
The Governed Architecture
External evaluation harness · Multi-agent pool · Immutable safety layer · Structured governance
In a harness-based system, the same task is handled by a coordinated team of specialist agents, each with a specific role, governed by an external evaluation layer that the agents cannot modify. The human engineer submits a task specification; the system does not return an output until that output has passed structured quality and safety gates.
This architecture is overkill for a solo developer building a Stripe integration on a Tuesday afternoon. It becomes appropriate — and eventually mandatory — when the agent is operating at reduced human supervision, when the codebase is shared across a team, when the output goes to production automatically, or when the task involves consequential external actions at scale.





APPROACH 3: THE SYNTHESIS STACK
The Layered Approach
Start simple · Escalate deliberately · Add governance exactly where consequences require it
The Composable Safety Stack does not ask the developer to choose between Pocock’s skills and a full harness architecture. It asks a different question: at which point in this specific task does the next governance layer become necessary? The answer is determined by three factors — autonomy (how much the agent is acting without direct human oversight), consequence severity (how hard is it to reverse a mistake), and coordination scope (are multiple agents involved?).
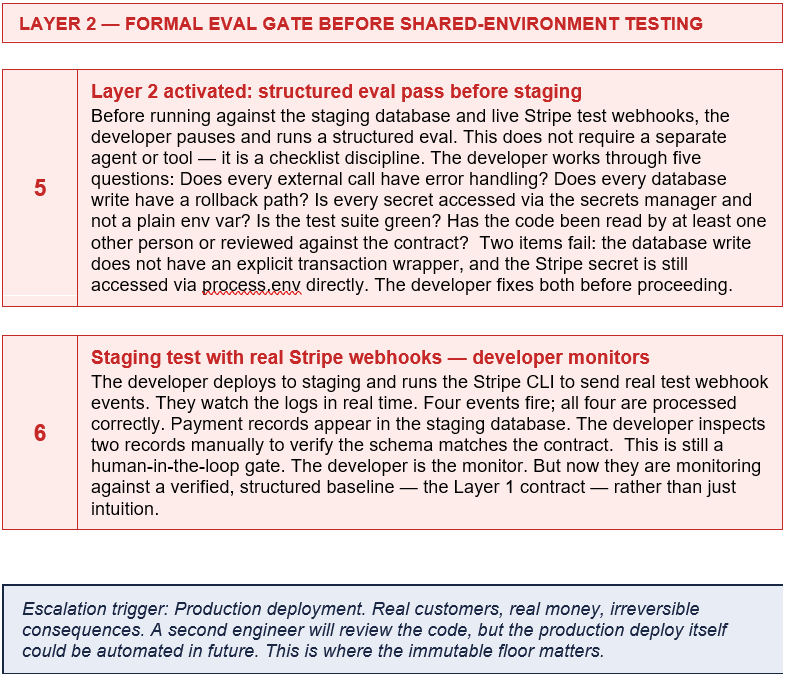
For the Stripe integration, the synthesis approach starts exactly where Pocock starts — with a grill me session and a TDD discipline. The difference appears at the moment the developer’s code will process real financial data on behalf of real users. That is the escalation trigger.




SIDE BY SIDE
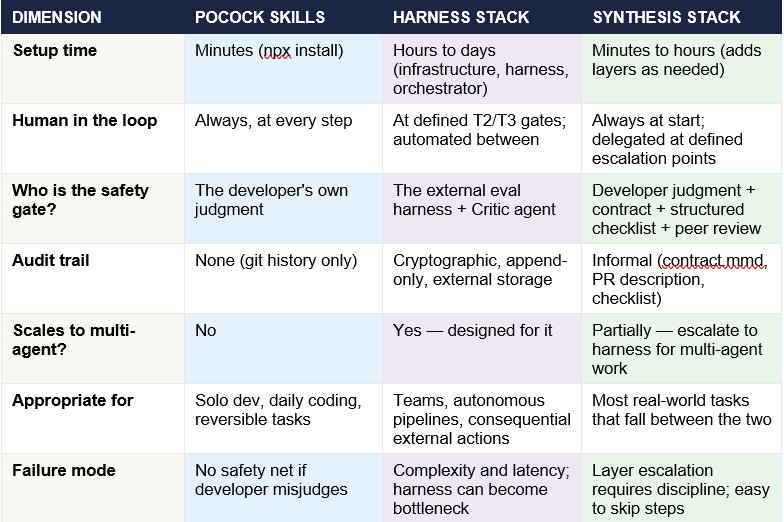
The table below compares the three approaches across the dimensions that matter most for a practitioner deciding which to use.
A NOTE ON READING THE WORKFLOWS
Three things are worth noticing across these walkthroughs.
First, the Pocock approach and the Synthesis Stack look almost identical for the first two steps. The divergence only appears when the task crosses a consequence threshold. This is the point: the Synthesis Stack does not add overhead upfront — it adds it precisely when the task requires it.
Second, the Harness Stack’s overhead is real and significant. The benefit is that the output arrives with a verifiable provenance trail and structured safety review that no human reviewer can replicate at the speed an agent team operates. For solo developers, this is unnecessary. For teams deploying code automatically, it is the baseline.
Third, none of these approaches removes the developer from the process entirely. Even the full harness architecture requires human review at T2/T3 boundaries and explicit sign-off for production deployment. The question each approach answers differently is not ‘how do we remove the human?’ but ‘where in the process does the human’s attention have the most leverage?’ Whatever said and done - HITL always! At least for now….
Pocock: the developer’s attention is everywhere, always. Harness: the developer’s attention is concentrated at the governance gates. Synthesis: the developer decides where their attention is needed and escalates to governance exactly there.