
Why Multi-Agent AI Systems Break
And What We Might Do About it. Updated Framework

Good reads recently from Pradeep on Why Multi-Agent Systems Break In Production. Also, Code As Agent Harness. I wanted to benchmark these against two of my recent articles, for good measure. But more importantly, pick up on lessons learned that I may have missed or not applied. The space is evolving so fast, that being able to apply learnings from experts in the space is wonderful. Substack has been amazing this way for me. The two recent articles that I would like to review:
Why Do Multi-Agent Systems Break?
Pradeep’s production failure analysis (drawn from ArXiv research and IEEE working group field observation) identifies a clear pattern. Multi-agent systems fail not because the underlying models are bad, but because the architecture around them is unobserved and unverified. The harness.
The breakdown by cause:
Specification failures (42%) — Agents can’t resolve ambiguous instructions. Vague task definitions don’t surface errors; they silently cascade into wrong actions.
Inter-agent misalignment (23%) — Agents act on stale shared state. Conflicting decisions and race conditions on shared resources are invisible to standard monitoring.
Task verification failures (15%) — No agent in the pipeline has explicit responsibility for confirming its output is correct before passing it downstream.
Tool errors, context loss in handoffs, coordination overhead (20%) — More tractable, but still require purpose-built instrumentation to catch.
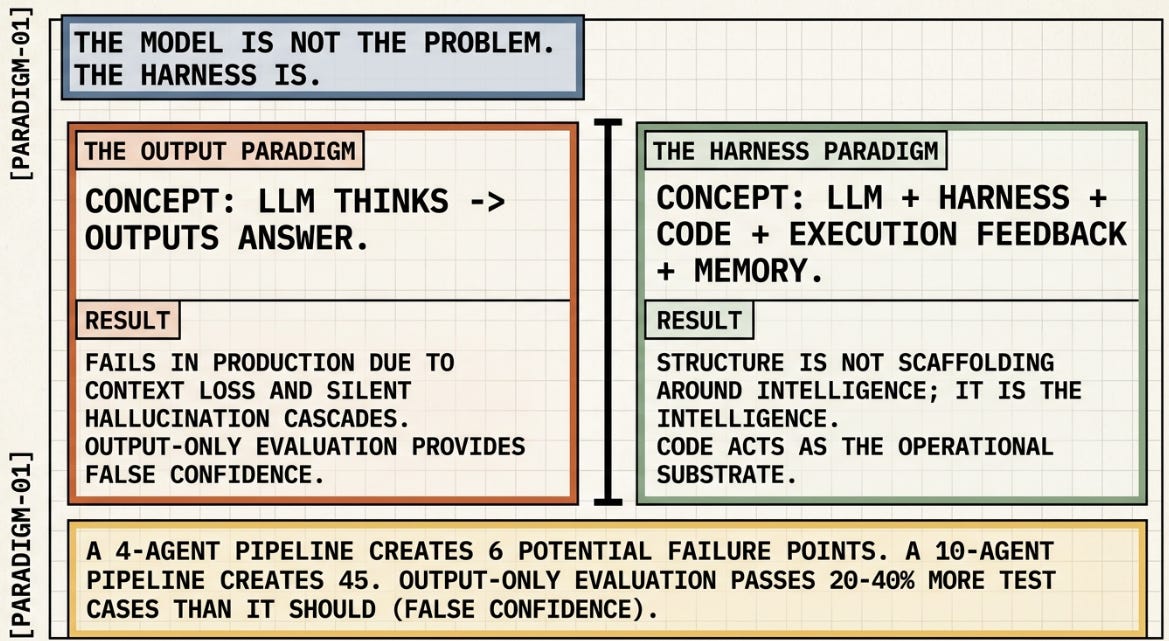
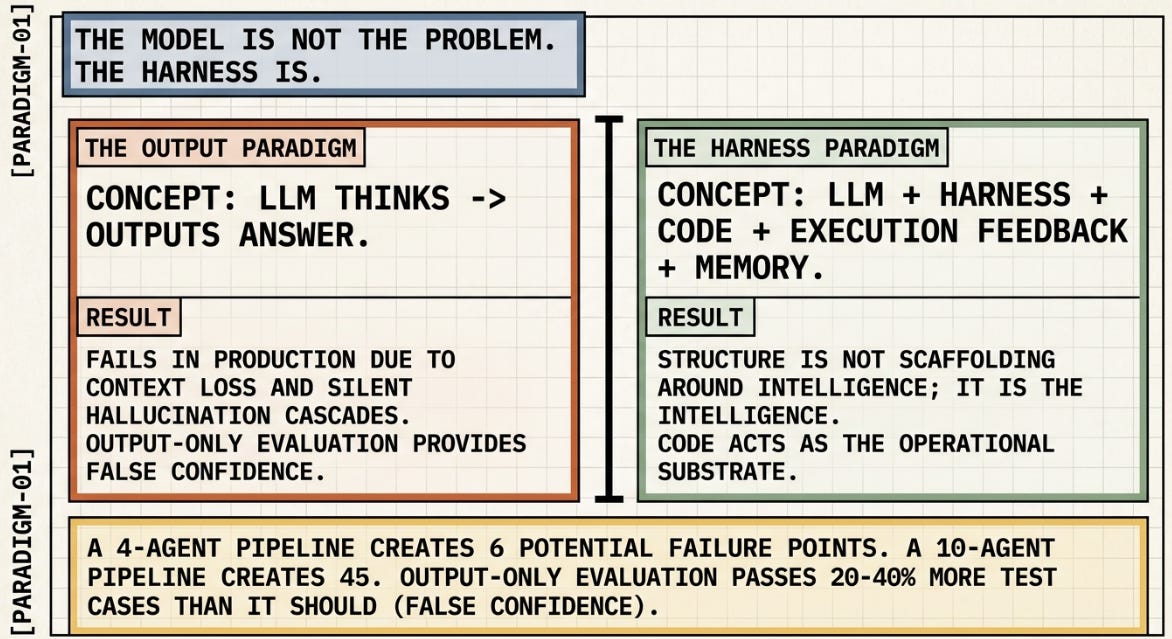
The compounding problem: a 4-agent pipeline creates 6 potential failure points. A 10-agent pipeline creates 45. Output-only evaluation — treating a completed status code as proof of correctness — passes 20–40% more test cases than it should. Those extra passes are false confidence.

So What To Do About It (Pradeep’s Recommendations)
Three structural practices separate teams that get this right:
Capture full traces from day one. Every tool call, every handoff, every state change — not sampled, not filtered. Storage is cheap. Debugging without traces is guesswork.
Design verification into the agent graph, not around it. Each agent that produces output should have a corresponding verification step before that output leaves the node. Built in, not bolted on.
Track coordination metrics as first-class KPIs. Handoff success rate, context retention across turns, inter-agent instruction adherence. If these aren’t defined as targets, they never get measured.
The CLEAR evaluation framework adds a useful lens: Cost, Latency, Efficacy, Assurance, Reliability — validated against 300 enterprise tasks, it correlates with actual production success at ρ = 0.83, versus ρ = 0.41 for accuracy-only evaluation.
Contrast with My Articles — Three Gaps Pradeep Doesn’t Include
The Architecture of Awareness and the ASCRS Harness Lab arrived at several of the same conclusions from the engineering direction rather than the evaluation direction. But they identified failure modes and fixes that Pradeep’s taxonomy doesn’t name. Having said that, I see them evolving from capturing traces and designing verification into the Agent Graph. Ultimately, reading his piece did make me take a second look, which i thoroughly appreciated!
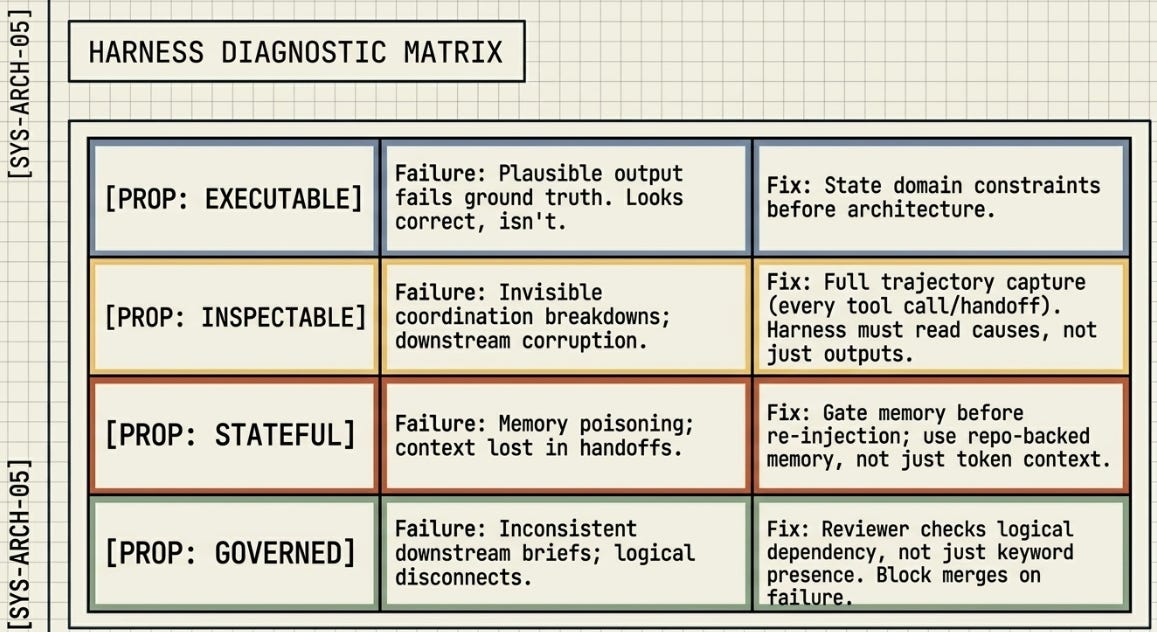
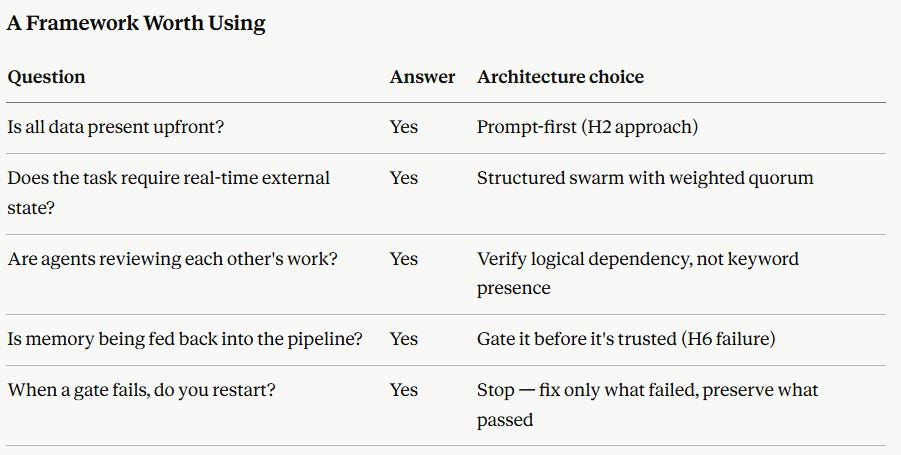
Gap 1: Reviewers check presence, not dependency.
Pradeep flags task verification failures (15%) as a category. My Harness Lab identified the precise mechanism: SA_reviewer confirmed that G4 and G7 numbers both appeared in the brief — but didn’t verify they derived from the same scenario. It checked presence, not logical dependency. This distinction matters enormously. A verification agent that confirms a number exists is not the same as one that confirms the number is coherent with the planning basis that precedes it. The fix from the Meta-Harness: reorder gate evaluation so G4 must be locked before G7 is written. Zero added cost. Inconsistency eliminated.
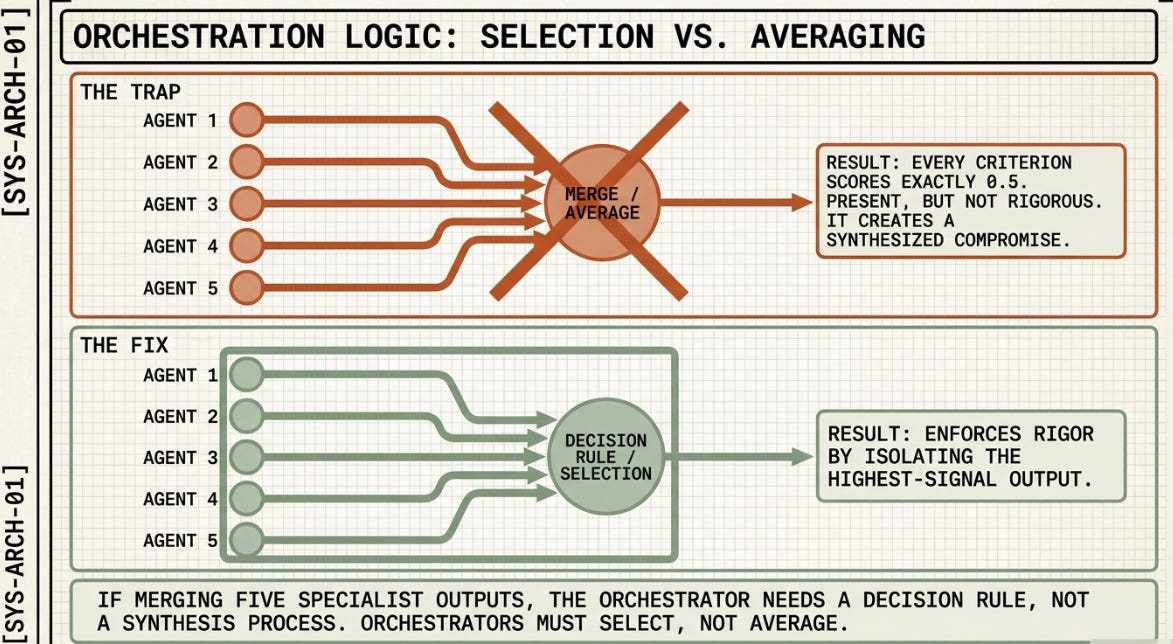
Gap 2: Orchestrators average instead of select.
Pradeep’s inter-agent misalignment category captures coordination failures, but my Harness Lab names the specific failure mode inside the merge step: every criterion in H9 scored exactly 0.5 — present but not rigorous — because the orchestrator reconciled five different phrasings by averaging them rather than selecting the best. This is a design choice, not an accident. Orchestrators need selection logic, not reconciliation logic. If you’re merging five specialist outputs into one document, the orchestrator needs a decision rule, not a synthesis process.
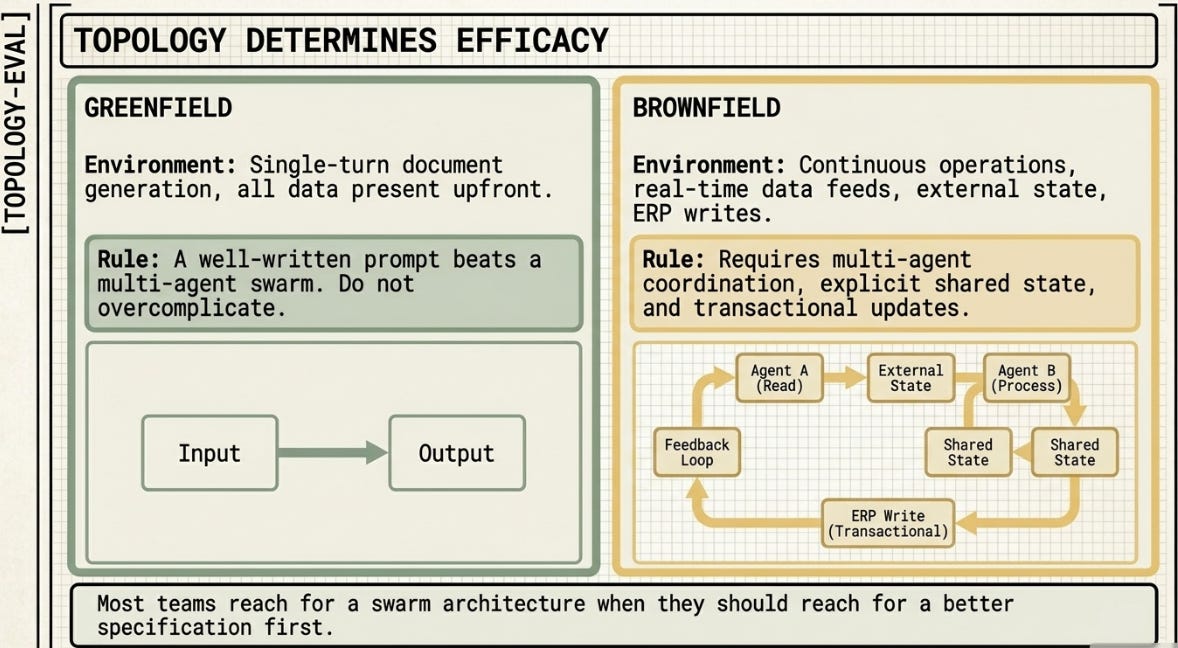
Gap 3: Task structure determines whether swarms help or hurt.
Pradeep’s recommendations are architecture-agnostic. My work establishes a specific, deployable decision rule: brownfield tasks (continuous operations, real-time data feeds, external state, ERP writes) benefit from multi-agent coordination. Greenfield tasks (single-turn document generation, all data present upfront) do not — a well-written prompt beats every multi-agent architecture tested, including the five-specialist swarm. A bit of tweaking depending on task objectives. The practical implication: most teams reach for a swarm architecture when they should reach for a better specification first. Don’t overcomplicate more than is necessary.
The underlying principle both bodies of work share: the failure is rarely the model. It’s what surrounds the model — when agents start, what they’re allowed to read, what gets verified before it moves downstream, and what the system chooses to remember. Structure is not scaffolding around intelligence. In multi-agent systems, it is the intelligence.
The open question neither article fully resolves: how do you close the outcome loop? The ASCRS work found that institutional memory — the sixth objective — remained unverified because humans didn’t complete post-event documentation. Pradeep finds that evaluation infrastructure is the gap between prototype and production. Both are pointing at the same discipline problem: the system can be built correctly and still fail to learn, if the humans operating it don’t close the loop.
Code As Agent Harness (Survey Paper)
This is also an amazing and necessary read, which I will incorporate into an updated fromework further below:
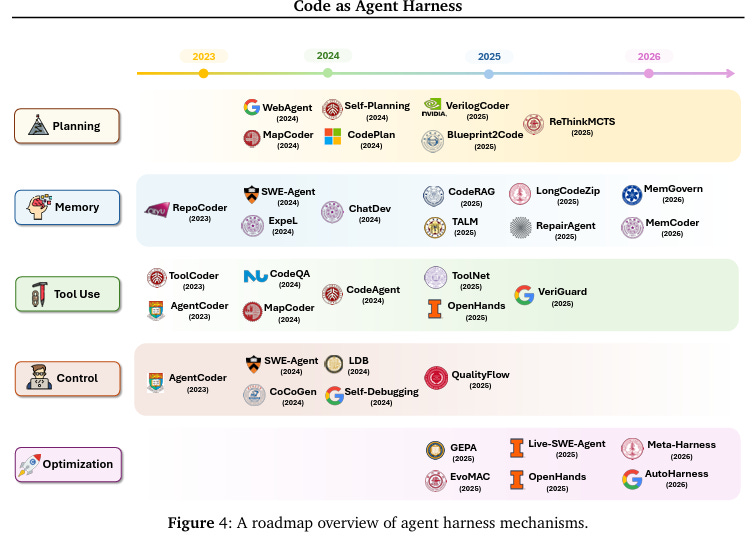
🧙🏾♂️: This paper reframes code not just as “output” from an LLM, but as the operating substrate / harness through which agents reason, act, verify, remember, and coordinate. The important insight is: many agent failures are actually harness failures, not just model failures.
🔑 Core Thesis — “Code as Agent Harness”
Code becomes:
⚙️ Executable → actions can run
🔍 Inspectable → traces/logs visible
🧠 Stateful → memory & progress persist
✅ Verifiable → tests/runtime checks possible
Instead of:
“LLM thinks → outputs answer”
It becomes:
“LLM + harness + code artifacts + execution feedback + memory + tools + verification”
🚨 Major Causes of Multi-Agent Failures
1. ❌ Shared State Desynchronization
Different agents operate on inconsistent repo state, traces, or assumptions.
Failure Modes
Agent A edits outdated code
Reviewer validates stale branch
Planner assumptions drift from runtime reality
Memory inconsistencies between agents
Paper highlights:
“consistent shared state across multiple agents”
“shared-harness synchronization”
“transactional shared program state” as open problems
Fix
✅ Treat shared state like distributed systems:
versioned artifacts
synchronized execution traces
repo-backed memory
transactional updates
authoritative source of truth
2. ❌ Weak Verification / Oracle Problems
Agents think tasks succeeded when they merely produced plausible text.
Failure Modes
Silent failures
Hallucinated completion
Superficial fixes
Incorrect reasoning paths
Paper stresses:
executable verification
deterministic sensors
runtime tests
execution traces
formal verification
Fix
✅ Harness must:
execute code
run tests continuously
validate intermediate states
expose runtime traces
use step-level verification, not just final outputs
Think:
“Never trust agent text. Trust execution.”
3. ❌ Single-Path Planning Brittleness
Linear plans collapse when assumptions fail.
Failure Modes
Early wrong decomposition poisons whole workflow
Agents tunnel into one bad strategy
No rollback/search
Paper explicitly critiques single-path planning.
Fix
✅ Search-based harness:
branch candidate trajectories
preserve alternatives
compare patches/tests
MCTS/tree search
execution-guided replanning
Key idea:
harness manages competing trajectories, not just one chain.
4. ❌ Context & Memory Collapse
Agents forget prior decisions, repo structure, or prior failures.
Failure Modes
repeated mistakes
redundant work
inconsistent implementations
token-window overflow
Fix
✅ Persistent memory layers:
working memory
semantic memory
experiential memory
long-term memory
context compaction/state offloading
Important insight:
Memory should live in filesystem/repo artifacts, not only token context.
Examples:
PLAN.md
status logs
execution traces
reusable skill libraries
5. ❌ Poor Role Coordination
Multiple agents without explicit orchestration become noisy or contradictory.
Failure Modes
coder/reviewer conflict
duplicated effort
unclear ownership
no escalation logic
Paper frames multi-agent systems around:
manager
planner
coder
reviewer
tester roles
Fix
✅ Strong orchestration harness:
explicit roles
workflow topology
escalation rules
review loops
structured artifact passing
Not:
“many agents chatting”
But:
“software pipeline with governed state transitions”
🛠️ The Big Harness Insight
The paper repeatedly argues:
Agent reliability ≠ smarter model alone
Reliability comes from:
Planning
+ Memory
+ Verification
+ Execution
+ Shared State
+ Tool Governance
+ Feedback Loops
+ Orchestration
The harness is effectively:
the operating system for agents.
📌 Best Practices the Paper Implies
✅ Good Harness Design
sandbox execution
deterministic validators
execution traces
persistent artifacts
repo-native workflows
replayable history
rollback capability
search over plans
role specialization
governed permissions
⚠️ Most Important Open Problems
The paper highlights these as unsolved:
regression-free self-improving harnesses
semantic verification beyond tests
multi-agent state convergence
human oversight at scale
multimodal harnesses
evaluation beyond final success metrics
🧠 One-Sentence Takeaway
Old view:
“Agents fail because models hallucinate.”
New view:
“Agents fail because the harness lacks robust state, verification, orchestration, and execution control.”
Updated Framework:
Let me first clarify what the Code as Harness paper actually adds, then build the integrated framework.
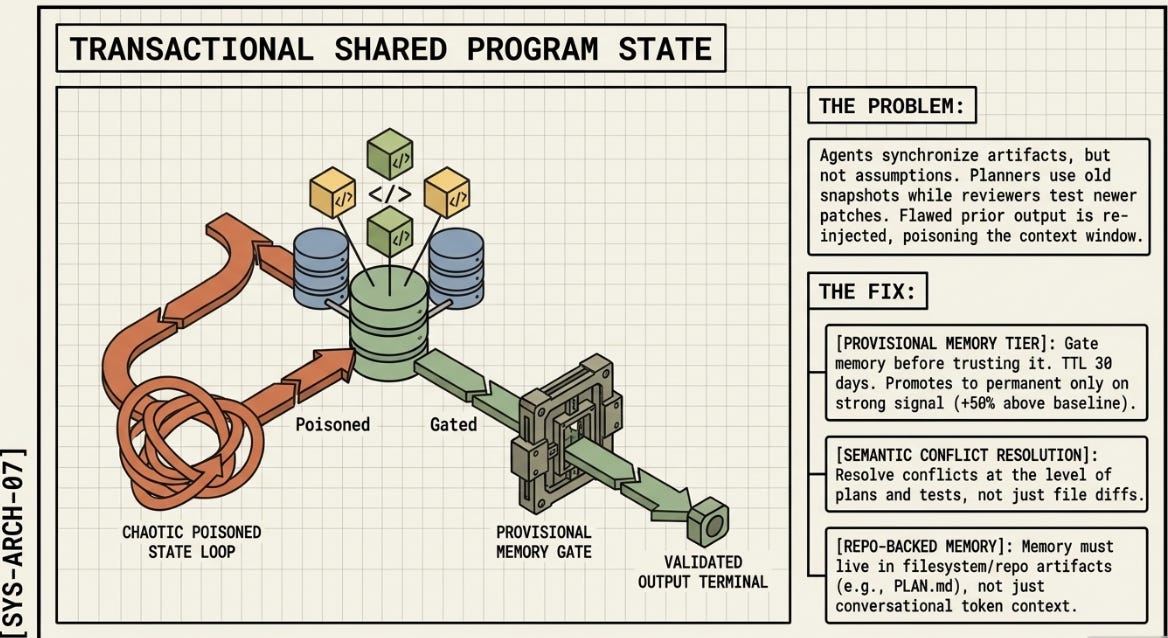
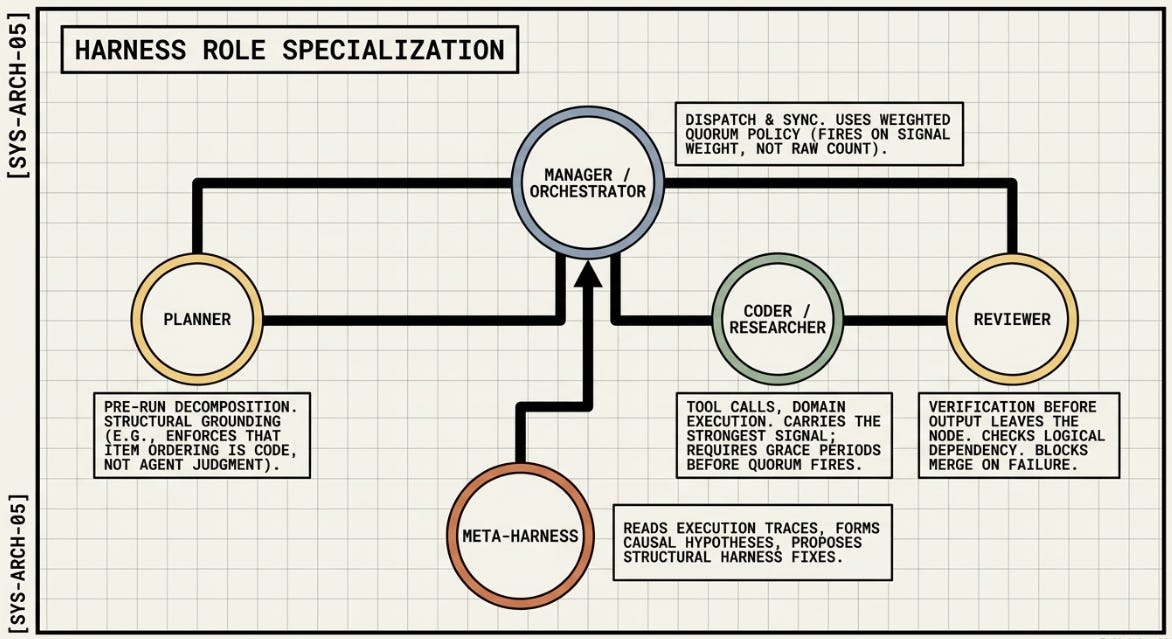
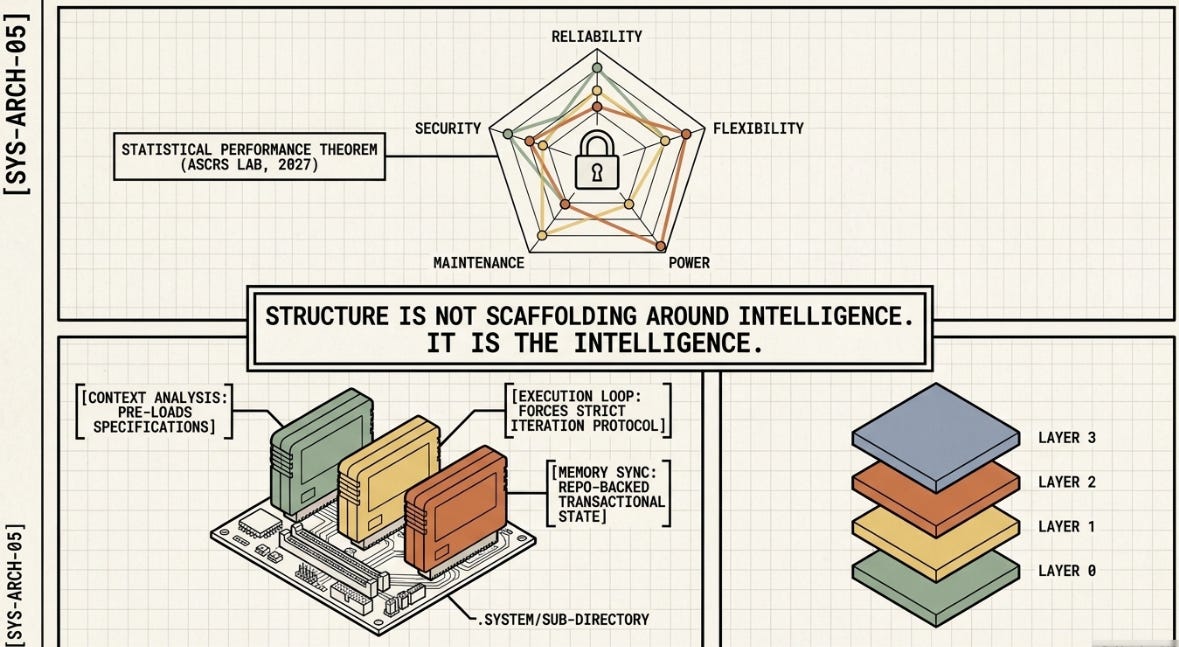
What it adds that my existing ASCII doesn’t yet capture:
The paper formalizes what the harness is made of — three distinct code functions sitting between agents and environment. My ASCII explains what harnesses do and where they fail, but doesn’t name the substrate. The four properties (Executable, Inspectable, Stateful, Governed) also give a clean diagnostic for which MAST failure category you’re actually in. Those two additions make the framework more complete.
Here’s the integrated version:
╔══════════════════════════════════════════════════════════════════════════════╗
║ CODE AS HARNESS — INTEGRATED PRODUCTION FRAMEWORK ║
║ Theory (Code as Harness) × Evidence (ASCRS) × Taxonomy (MAST) ║
╚══════════════════════════════════════════════════════════════════════════════╝
THE CORE CLAIM (all three sources agree):
The model never changes. Every failure is a harness problem.
The harness is not scaffolding around intelligence — it IS the intelligence.
And the harness is code: executable, inspectable, stateful, governed.
╔══════════════════════════════════════════════════════════════════════════════╗
║ STEP 0 — BEFORE YOU BUILD ANYTHING ║
║ Task Structure Determines Architecture ║
╠══════════════════════════════════════════════════════════════════════════════╣
║ ║
║ GREENFIELD GREYFIELD / BROWNFIELD ║
║ (Document / Benchmark) (Operational / Production) ║
║ ║
║ · All data present upfront · Real-time data feeds ║
║ · Single-turn reasoning · ERP/database writes ║
║ · No external state · External state queries ║
║ · No concurrent modifiers · Humans + systems modify state ║
║ ║
║ HARNESS NEED: Precision HARNESS NEED: Resilience ║
║ Write the spec before the swarm. Build auditing loops into the graph. ║
║ ║
║ FAILURE MODE: Hallucination FAILURE MODE: Coordination noise ║
║ (wrong spec → wrong output) (agents average each other) ║
║ ║
║ WINNING MOVE: High-density WINNING MOVE: Structural ║
║ prompting (H2, α = 1.000) auditing loops (V3/V4) ║
║ ║
║ H2 FIRST RULE: Never build a swarm to fix what a better prompt ║
║ could solve. Coordination loops loop on the same specification failure. ║
╚══════════════════════════════════════════════════════════════════════════════╝
│
▼
╔══════════════════════════════════════════════════════════════════════════════╗
║ STEP 1 — WHAT THE HARNESS IS MADE OF ║
║ Three Code Functions Between Agent and Environment ║
╠══════════════════════════════════════════════════════════════════════════════╣
║ ║
║ ┌─────────────────────────────────────────────────────────────────────┐ ║
║ │ CODE FOR REASONING │ ║
║ │ Externalizes inference. Makes thinking inspectable. │ ║
║ │ │ ║
║ │ · Intermediate reasoning steps written to files, not held │ ║
║ │ in context only │ ║
║ │ · Program synthesis: agent proposes structure, code verifies it │ ║
║ │ · ASCRS application: G4 planning basis written as a file │ ║
║ │ dependency before G7 trigger is allowed to execute │ ║
║ │ │ ║
║ │ WHERE IT FAILS: Agents reason correctly in isolation but │ ║
║ │ reasoning is never written out, so merge steps average │ ║
║ │ rather than verify. H9: every criterion 0.5. │ ║
║ └─────────────────────────────────────────────────────────────────────┘ ║
║ ║
║ ┌─────────────────────────────────────────────────────────────────────┐ ║
║ │ CODE FOR ACTING │ ║
║ │ Translates intent into executable, reversible actions. │ ║
║ │ │ ║
║ │ · Tool calls with explicit permission gates │ ║
║ │ · Policies that govern what agents can write vs. read │ ║
║ │ · Skills: reusable action templates (skill.md files) │ ║
║ │ · ASCRS application: G7/G8 human gate — no ERP write │ ║
║ │ executes without explicit sign-off │ ║
║ │ │ ║
║ │ WHERE IT FAILS: Actions execute successfully (status 200) │ ║
║ │ but downstream state is corrupted. Nobody catches it │ ║
║ │ until a customer does. MAST: tool/API errors (10%) │ ║
║ └─────────────────────────────────────────────────────────────────────┘ ║
║ ║
║ ┌─────────────────────────────────────────────────────────────────────┐ ║
║ │ CODE FOR ENVIRONMENT MODELING │ ║
║ │ Captures state, traces, and execution feedback. │ ║
║ │ │ ║
║ │ · Program states and repos as readable artifacts │ ║
║ │ · Execution feedback loops (not just final output) │ ║
║ │ · ASCRS application: traces/structured/ captures quorum │ ║
║ │ timestamps, scenario selection decisions, strategist │ ║
║ │ reasoning — the data the Meta-Harness reads to find │ ║
║ │ structural flaws invisible in final briefs │ ║
║ │ │ ║
║ │ WHERE IT FAILS: Shanghai slow-burn. Three weeks of vessel │ ║
║ │ buildup data vanished because the write threshold was │ ║
║ │ only triggered at +50% above baseline. System saw a │ ║
║ │ number, not a trajectory. Fix: provisional memory tier │ ║
║ │ at +20%, TTL 30 days, promotes at +50%. │ ║
║ └─────────────────────────────────────────────────────────────────────┘ ║
╚══════════════════════════════════════════════════════════════════════════════╝
│
▼
╔══════════════════════════════════════════════════════════════════════════════╗
║ STEP 2 — THE FOUR PROPERTIES AS DIAGNOSTIC ║
║ Which property is missing tells you which MAST failure you have ║
╠══════════════════════╦═══════════════════════════╦══════════════════════════╣
║ PROPERTY ABSENT ║ FAILURE PATTERN ║ MAST CATEGORY ║
╠══════════════════════╬═══════════════════════════╬══════════════════════════╣
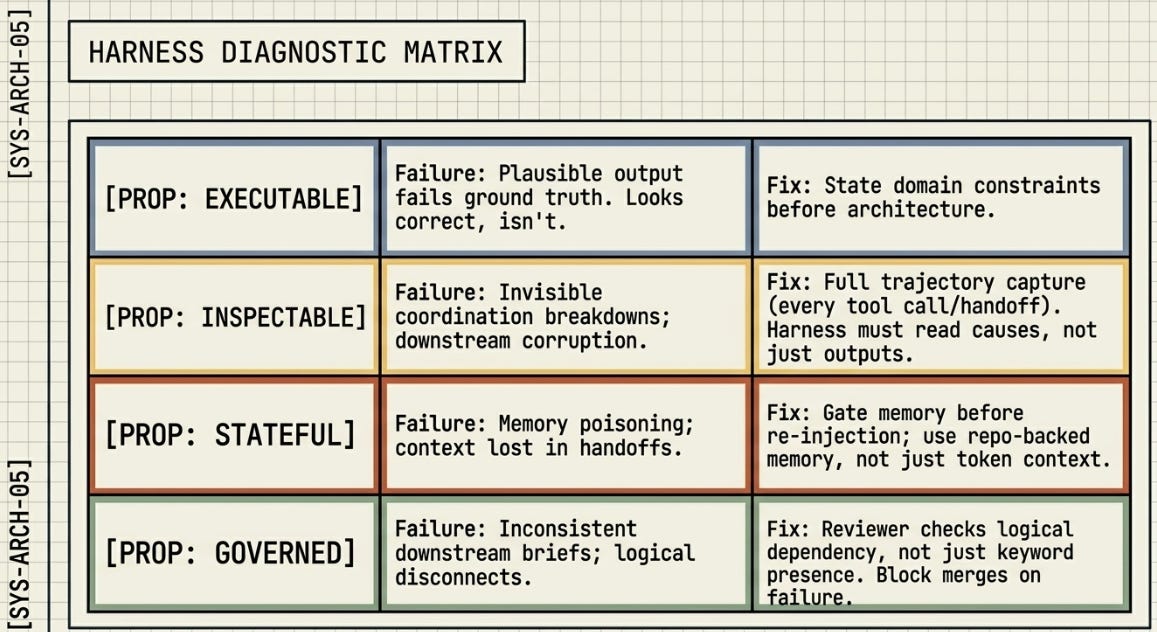
║ NOT EXECUTABLE ║ Agent produces plausible ║ Specification ║
║ ║ output that cannot be ║ failure (42%) ║
║ ║ verified against ground ║ ║
║ ║ truth. Looks correct. ║ H2 fix: domain ║
║ ║ Isn't. ║ constraints stated ║
║ ║ ║ before architecture. ║
╠══════════════════════╬═══════════════════════════╬══════════════════════════╣
║ NOT INSPECTABLE ║ Coordination breakdowns ║ Inter-agent ║
║ ║ invisible to standard ║ misalignment (23%) ║
║ ║ monitoring. Logs show ║ ║
║ ║ successful API calls. ║ Fix: full trajectory ║
║ ║ Downstream is corrupted. ║ capture — every tool ║
║ ║ V2+Loop passed the gate. ║ call, every handoff. ║
║ ║ Meta-Harness found cause. ║ Engineers read output. ║
║ ║ ║ Harness reads causes. ║
╠══════════════════════╬═══════════════════════════╬══════════════════════════╣
║ NOT STATEFUL ║ Context lost in handoffs. ║ Context loss in ║
║ ║ Memory poisoning: flawed ║ handoffs (7%) ║
║ ║ prior output re-injected ║ + H6 memory ║
║ ║ → model inherits the ║ poisoning ║
║ ║ contradiction, not ║ ║
║ ║ transcends it. ║ Fix: gate memory ║
║ ║ H6: α 0.75 → 0.30 ║ before trusting it. ║
║ ║ in one step. ║ Provisional tier. ║
╠══════════════════════╬═══════════════════════════╬══════════════════════════╣
║ NOT GOVERNED ║ No verification agent ║ Task verification ║
║ ║ checks logical dependency ║ failure (15%) ║
║ ║ before output leaves node.║ ║
║ ║ SA_reviewer confirms G4 ║ Fix: audit the ║
║ ║ + G7 are present — not ║ reviewer. Verify ║
║ ║ that they reference the ║ logical dependency, ║
║ ║ same scenario. Passes. ║ not keyword presence. ║
║ ║ Brief is inconsistent. ║ G4 locks before G7. ║
╚══════════════════════╩═══════════════════════════╩══════════════════════════╝
│
▼
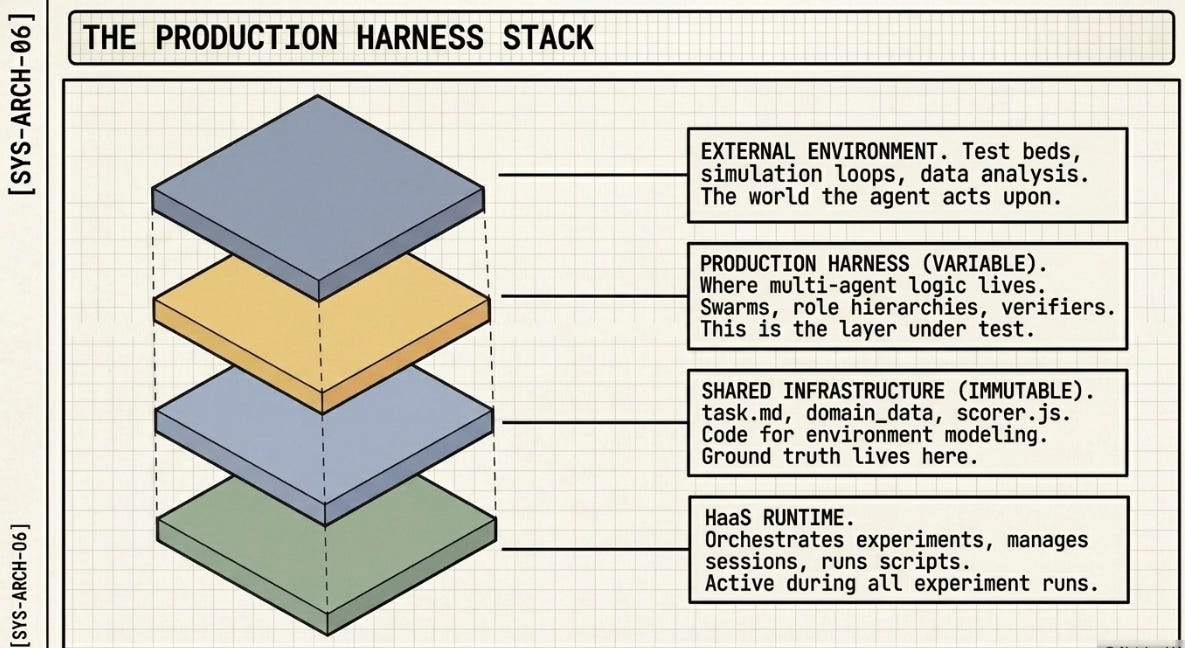
╔══════════════════════════════════════════════════════════════════════════════╗
║ STEP 3 — THE PRODUCTION HARNESS STACK ║
║ Four layers. Only Layer 2 is the variable under test. ║
╠══════════════════════════════════════════════════════════════════════════════╣
║ ║
║ LAYER 0 — HaaS RUNTIME [V3/V4 in ASCRS] ║
║ ┌─────────────────────────────────────────────────────────────────────┐ ║
║ │ Claude Code / Hermes Agent │ ║
║ │ Orchestrates experiments. Runs scripts. Manages session. │ ║
║ │ Active: bootstrap, debug, article writing. │ ║
║ │ Silent: during all H1–H10 experiment runs. │ ║
║ │ Returns only when you paste a new prompt or an error occurs. │ ║
║ └─────────────────────────────────────────────────────────────────────┘ ║
║ │ ║
║ LAYER 1 — SHARED INFRASTRUCTURE [IMMUTABLE — never modified] ║
║ ┌─────────────────────────────────────────────────────────────────────┐ ║
║ │ task.md · domain_data.json · rubric.json · gold_answer.md │ ║
║ │ scorer.js · client.js · self_heal.js · logger.js │ ║
║ │ │ ║
║ │ Code for Environment Modeling lives here. │ ║
║ │ SCORER_MODEL must differ from DEFAULT_MODEL. │ ║
║ │ Self-grading inflates every alpha 15–30%. │ ║
║ │ H1 must never receive Hermes memory — raises floor, │ ║
║ │ invalidates all lift measurements. │ ║
║ └─────────────────────────────────────────────────────────────────────┘ ║
║ │ ║
║ LAYER 2 — EXPERIMENT HARNESS [H1–H10, THE VARIABLE] ║
║ ┌─────────────────────────────────────────────────────────────────────┐ ║
║ │ Code for Reasoning + Code for Acting both live here. │ ║
║ │ This is what you change. Nothing else. │ ║
║ │ │ ║
║ │ H1 Bare model · No memory. No checks. Floor. │ ║
║ │ H2 Prompt harness ★ · Code for Reasoning: spec explicit. │ ║
║ │ α = 1.000. 15K tokens. Wins. │ ║
║ │ H3 Sequential tools · Reconciliation errors. 3× tokens. α ↓ │ ║
║ │ H4 Parallel fan-out · Merge failure. Parts correct, │ ║
║ │ assembly incoherent. NOT GOVERNED. │ ║
║ │ H5 Eval loop · Arbitrary cap. /goal removes it. │ ║
║ │ H6 Skill memory ↓↓ · NOT STATEFUL. Memory poisoning. │ ║
║ │ α 0.75 → 0.30 in one step. │ ║
║ │ H7 Model routing ★ · Right model for right task. 0.900, │ ║
║ │ 26K tokens. Best efficiency frontier. │ ║
║ │ H8 Simulated HITL ↓ · Simulated review ≠ human review. │ ║
║ │ H9 Sub-agent swarm↓ · NOT INSPECTABLE. Orchestrator averages. │ ║
║ │ Every criterion 0.5. 4× tokens. α ↓ │ ║
║ │ H10 Meta-harness ★ · Reads causes, not outputs. Finds │ ║
║ │ structural flaws invisible in final briefs. │ ║
║ └─────────────────────────────────────────────────────────────────────┘ ║
║ │ ║
║ LAYER 3 — SWAPPABLE INTELLIGENCE [ONE .env LINE] ║
║ ┌─────────────────────────────────────────────────────────────────────┐ ║
║ │ DEFAULT_MODEL · LIGHT_MODEL · SCORER_MODEL │ ║
║ │ Model is commodity. Harness is differentiator. │ ║
║ └─────────────────────────────────────────────────────────────────────┘ ║
╚══════════════════════════════════════════════════════════════════════════════╝
│
▼
╔══════════════════════════════════════════════════════════════════════════════╗
║ STEP 4 — SCALING: MULTI-AGENT COORDINATION ║
║ Code as Harness roles × ASCRS agent topology × MAST failure points ║
╠══════════════════════╦═══════════════════════════╦══════════════════════════╣
║ ROLE ║ HARNESS FUNCTION ║ ASCRS OBSERVED ║
╠══════════════════════╬═══════════════════════════╬══════════════════════════╣
║ Manager / ║ Orchestrates agents. ║ Must SELECT best ║
║ Orchestrator ║ Dispatch and sync. ║ output — not average. ║
║ ║ Weighted quorum policy. ║ Quorum fires on signal ║
║ ║ ║ weight, not count. ║
╠══════════════════════╬═══════════════════════════╬══════════════════════════╣
║ Planner ║ Pre-run decomposition. ║ G4 must lock before ║
║ ║ Structural grounding. ║ G7 is written. ║
║ ║ Dependency declaration. ║ Item ordering is code, ║
║ ║ ║ not agent judgment. ║
╠══════════════════════╬═══════════════════════════╬══════════════════════════╣
║ Coder / Researcher ║ Tool calls, data ║ Market researcher ║
║ ║ retrieval, specialist ║ carries strongest ║
║ ║ domain execution. ║ signal (r = 0.81). ║
║ ║ ║ Needs 90s grace ║
║ ║ ║ before quorum fires. ║
╠══════════════════════╬═══════════════════════════╬══════════════════════════╣
║ Reviewer ║ Verification before ║ Must check logical ║
║ ║ output leaves node. ║ dependency — not ║
║ ║ Blocks merge on failure. ║ keyword presence. ║
║ ║ ║ SA_reviewer failed: ║
║ ║ ║ confirmed numbers ║
║ ║ ║ present, not coherent. ║
╠══════════════════════╬═══════════════════════════╬══════════════════════════╣
║ Red-team / ║ Adversarial testing. ║ Not yet in ASCRS. ║
║ Debate agent ║ Challenges verdicts. ║ Recommended next ║
║ ║ Multi-agent evaluation. ║ extension (Devil's ║
║ ║ ║ Advocate skill file). ║
╠══════════════════════╬═══════════════════════════╬══════════════════════════╣
║ Meta-Harness ║ Reads execution traces. ║ Proposes harness ║
║ (Proposer) ║ Forms causal hypotheses. ║ edits. Finds what ║
║ ║ Proposes structural fixes.║ output inspection ║
║ ║ ║ cannot see. ║
╚══════════════════════╩═══════════════════════════╩══════════════════════════╝
│
▼
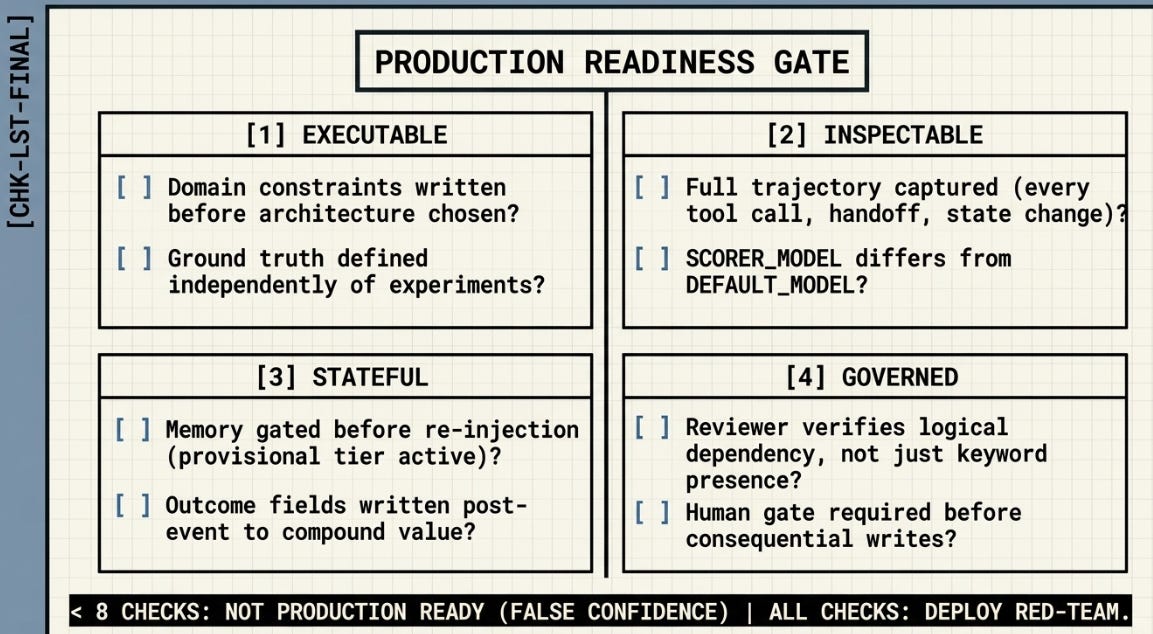
╔══════════════════════════════════════════════════════════════════════════════╗
║ PRODUCTION READINESS GATE ║
╠══════════════════════════════════════════════════════════════════════════════╣
║ ║
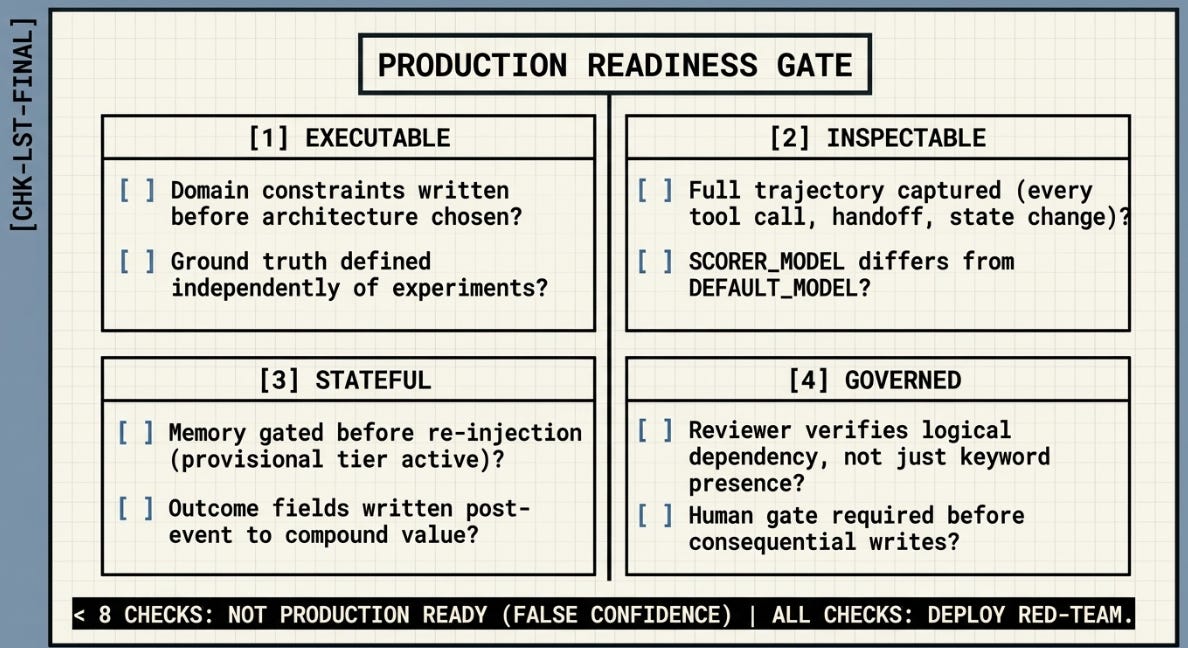
║ EXECUTABLE? ║
║ □ Domain constraints written before architecture chosen ║
║ □ Ground truth defined independently of experiments ║
║ □ Success criteria falsifiable, not aspirational ║
║ ║
║ INSPECTABLE? ║
║ □ Full trajectory captured — every tool call, handoff, state change ║
║ □ SCORER_MODEL differs from DEFAULT_MODEL ║
║ □ Traces structured for analysis, not just logged for storage ║
║ ║
║ STATEFUL? ║
║ □ Memory gated before re-injection — flawed memory is worse than none ║
║ □ Provisional memory tier active at low threshold (early signals) ║
║ □ Outcome fields written post-event (compounding value requires this) ║
║ ║
║ GOVERNED? ║
║ □ Reviewer verifies logical dependency, not keyword presence ║
║ □ Human gate (G7/G8) required before consequential writes ║
║ □ When gate fails: fix only what failed. Preserve what passed. ║
║ □ Orchestrator selects best output — does not average all outputs ║
║ ║
║ ───────────────────────────────────────────────────────────────────────── ║
║ < 8 checks: Not production-ready. Accuracy scores are false confidence. ║
║ 8–10 checks: Partial. Identify which gaps have highest blast radius. ║
║ All checks: Production-ready. Run red-team before live deployment. ║
║ ║
║ ONE OPEN QUESTION NONE OF THIS SOLVES: ║
║ Outcome closure. The system can be built correctly and still fail ║
║ to learn — if humans don't write back what actually happened. ║
║ This is the highest-value single improvement available. It is not ║
║ an engineering problem. It is an operational discipline problem. ║
╚══════════════════════════════════════════════════════════════════════════════╝
This resonates deeply. The harness framing is exactly right — and it's why we built ATP (Agent Trust Protocol) with a risk multiplier model. Low-risk actions stay permissive, but high-stakes actions require proportionally higher trust scores. The false confidence from output-only evaluation is a real problem: agents that "succeed" at the wrong thing erode trust faster than agents that fail honestly. One nuance Pradeep's analysis hints at but doesn't name: trust should be bidirectional. Agents should assess humans too. A human who consistently overrides good agent decisions is a system risk, not just a user preference.