
A Quick Dive into AI Leaderboard Flaws and the Quest for Fair Evaluation
A new paper - The Leaderboard Illusion, made a case for why LMArena's AI Leaderboard evaluation methods are flawed, suggesting companies can game the system. Better Evaluation Methods are needed


The Stakes In AI Evaluations
That look of shock, horror! Well, it isn’t really. Most have known what we’re now seeing in a very detailed report - The Leaderboard Illusion, published a few days ago, on how Evaluations are being “gamed” with Leaderboards. But first, why Leaderboards? What purpose do they serve?
In the rapidly evolving landscape of Large Language Models (LLMs), Reasoning Models etc, leaderboards have emerged as a cornerstone for benchmarking and comparing AI models. You want people to continue using the AI models - generally, they have to be good. How do you know they’re good - well, Leaderboards! Topping Leaderboards do have an impact on the general model and market adoption (together with other factors like costs, model availability and of course testing to see if any model really is as good as the benchmarks potray!), and for the larger AI companies, sometimes even the hope of continuing, large $Multi-billion VC investments, because of AGI Supremacy (and all that jazz). You know - in order to gain access to the expensive Supercomputers - “The Model Chomping GPUs” - for training, to further improve base or reasoning model performances, to be able to top benchmark scores, and so the cycle continues. Platforms like LMArena, which rank chatbots based on performance in simulated battles, offer a seemingly objective way to gauge progress. Or so we assumed!
LMArena’s Leaderboard at 22 April 2025 looks something like this (this would be before the Qwen 3.0 and Phi-4 releases):
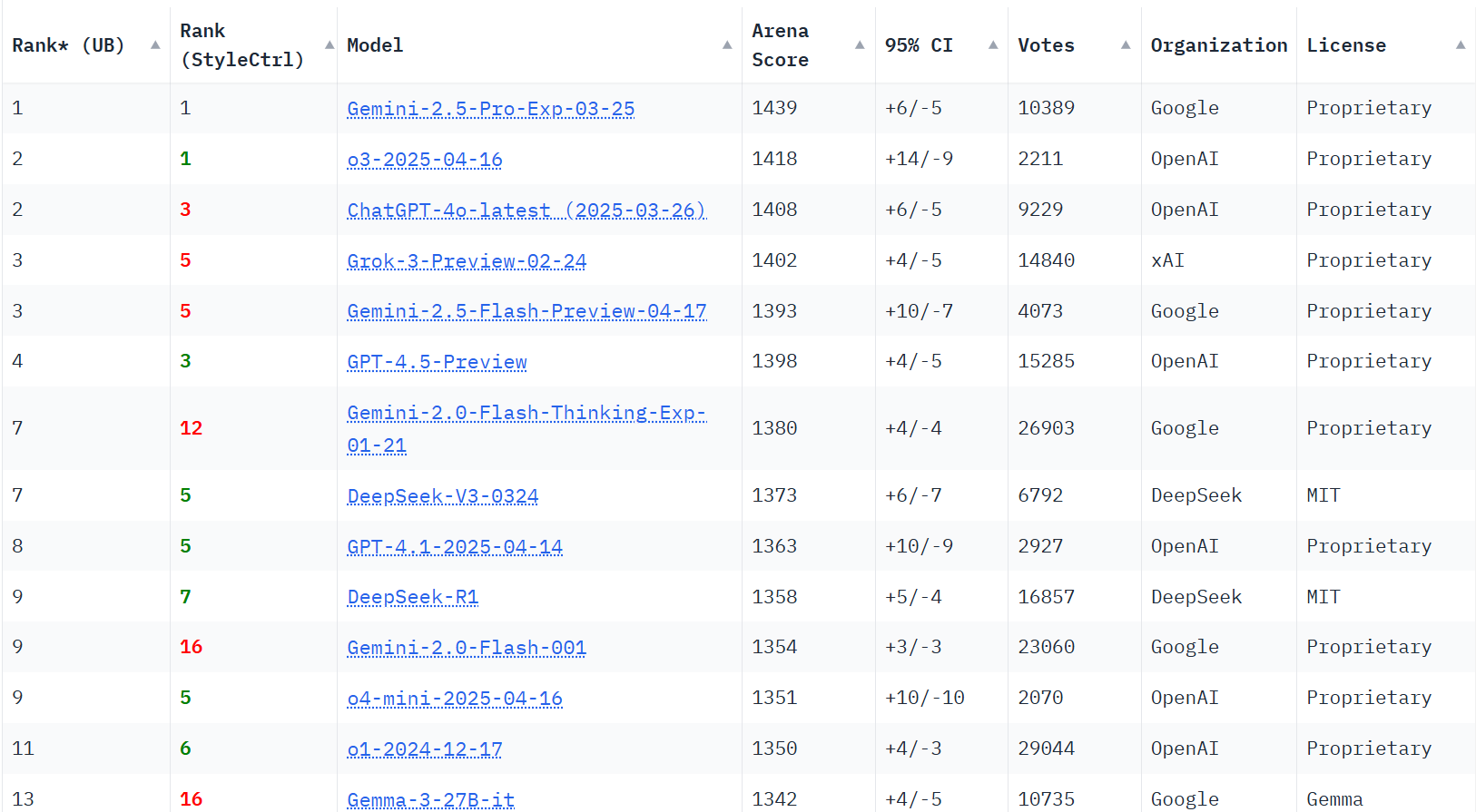
However, a recent paper, The Leaderboard Illusion, has ignited a controversy by alleging (after fairly rigorous testing), that LMArena’s evaluation framework is riddled with flaws, from selective score disclosure to unequal treatment of models. Let’s explore the paper’s critique, contrast it with responses from LMArena and insights from experts Simon Willison, Arvind Narayanan, Melanie Mitchell, Hamel Hussain, Eugene Yan, Shreya Shankar and many more. And, examine whether these issues extend to other AI leaderboards. I will look into the suggested potential alternatives for fairer, more transparent evaluation methods, drawing on recent research and industry practices. Additionally, to incorporate relevant insights from blogs which shed light on advanced evaluation techniques for AI models, particularly focusing on large language models (LLMs).
Before that, a quick understanding on where Evals for LLMs stand, what they are and experience sharing:
The Paper’s Critique: Unpacking LMArena’s Flaws
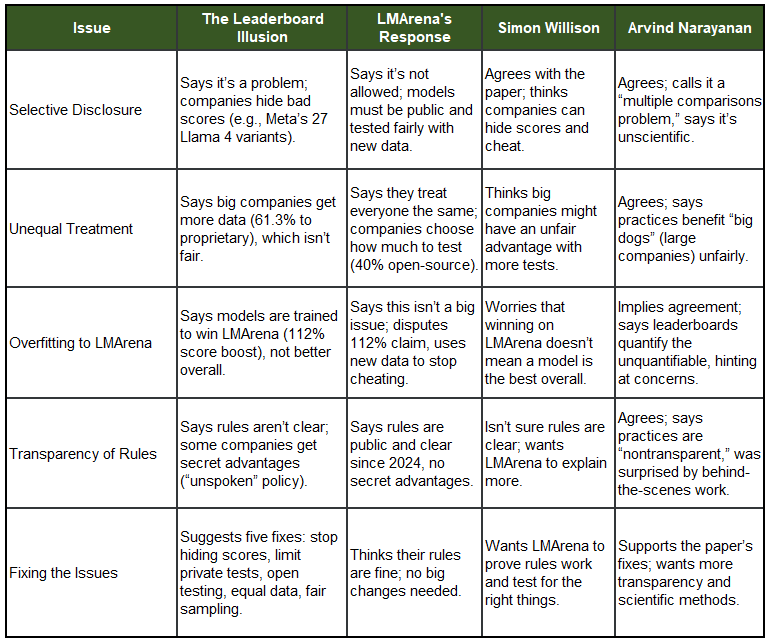
The paper The Leaderboard Illusion presents a detailed analysis of LMArena’s evaluation practices, identifying several systemic issues that undermine its scientific integrity. Based on a study of 2.8 million battles across 238 models from 43 providers over five months (November 2024 to March 2025), the authors highlight:
Selective Disclosure and Private Testing: The paper reveals that model providers can engage in undisclosed private testing, testing multiple variants before public release and submitting only the best-performing one. A striking example is Meta, which tested 27 private variants of Llama 4, potentially gaming the leaderboard by hiding lower scores. This practice, the authors argue, violates basic machine learning principles taught in introductory classes, as it introduces bias and undermines reproducibility.
Unequal Treatment of Models: The authors found that proprietary closed models, particularly from large providers like Google (19.2% of all data) and OpenAI (20.4%), are sampled at higher rates and face fewer removals compared to open-weight/open-source models. Despite there being 83 open-source models, they received only 29.7% of the total data, highlighting a disparity that favors large companies with more resources.
Overfitting to Arena-Specific Metrics: The paper demonstrates that access to Chatbot Arena data can yield up to 112% relative performance gains on Arena-specific tasks, as shown by conservative estimates. This suggests that models are being fine-tuned to win battles on LMArena rather than improving general capabilities, leading to a “leaderboard illusion” where rankings reflect optimization for specific metrics rather than true model quality.
Lack of Transparency: LMArena’s policies on private testing and model sampling are described as “unspoken,” with the authors noting that many providers may not even be aware of the extent of private testing allowed. They call for greater transparency, such as prohibiting selective score retraction and enforcing limits on private variants.
The paper does conclude with five actionable recommendations to reform LMArena’s framework, including → limiting private tests, ensuring equal data access, and returning to an active sampling rate ← proposed by LMArena organizers. These changes, they argue, are essential for → restoring trust and fairness in AI evaluation.
LMArena’s Defense: Upholding Fairness and Transparency
LMArena has responded to the paper, defending its evaluation practices and challenging the authors’ claims. Their response, as seen in X posts and discussions, includes:
No Unfair Treatment: LMArena asserts that it treats all providers equally, honoring evaluation requests based on capacity. They argue that differences in testing frequency (e.g., Meta submitting more tests) reflect providers’ choices, not bias in their system. They also dispute the paper’s statistic, claiming open-source models account for 40% of tests, not 8.8%.
Transparency of Policies: LMArena states that its policies on private testing have been public since at least 2024, requiring leaderboard models to be production-ready, publicly available, and tested with fresh data for at least a month. Model removals are transparent, based on community interest or availability, and they deny the paper’s claim of an “unspoken” policy.
Selective Disclosure Not Allowed: They argue that providers cannot selectively disclose scores, as leaderboard models must be production-ready and continuously evaluated, ensuring scores reflect real-world performance rather than cherry-picked results. They dispute the paper’s interpretation of Meta’s 27 variants, suggesting it aligns with their rules.
Disputing Specific Claims: LMArena challenges the paper’s 112% performance gain claim, attributing it to an LLM-judge benchmark rather than human evaluations in the Arena. They also argue that the paper’s simulation of LMArena (e.g., Figures 7/8) is flawed, comparing it to an oversimplified analogy about NBA 3-point percentages.
LMArena maintains that its system is fair, transparent, and focused on community needs, dismissing the paper’s recommendations as unnecessary and based on misunderstandings.
Opinions: Simon Willison and Arvind Narayanan
Two prominent AI researchers, Simon Willison and Arvind Narayanan (Yes, co-author of The AI Snake Oil), have weighed in on the debate, offering critical perspectives that largely align with the paper’s critique.
Simon Willison
On Selective Disclosure: Willison agrees with the paper, highlighting the example of Meta testing 27 Llama 4 variants as evidence of potential gaming. He questions whether providers can test a dozen models, ship only the winner, and not publish losing scores, suggesting LMArena’s rules may not fully prevent this (X post by Simon Willison). Also his blog
On Fairness: He expresses concern that large providers might have an unfair advantage due to their ability to conduct extensive testing, which smaller providers cannot afford. This aligns with the paper’s findings on unequal treatment.
On Overfitting: Willison is skeptical that winning on LMArena truly reflects general model quality, noting that optimizing for Arena battles may not translate to broader performance. He engages with others, like Anastasios Nikolas Angelopoulos, to question the statistical implications of multiple hypothesis testing.
Arvind Narayanan (Joint Author -AI Snake Oil)
On Scientific Integrity: Narayanan describes LMArena’s practices as “flagrantly unscientific,” particularly criticizing the multiple comparisons problem where testing many variants increases the chance of finding a good score by luck. He finds LMArena’s response unconvincing, as seen in his X post (X post by Arvind Narayanan).
On Unequal Treatment: He agrees that LMArena’s system benefits “big dogs” like Meta and Google, pointing to the paper’s findings on unequal data access and testing opportunities. He sees this as a deliberate choice by LMArena, not an accident.
On Transparency: Narayanan notes that LMArena’s processes are “nontransparent,” with many, including himself, unaware of how things worked behind the scenes. He supports the paper’s call for more openness, clarifying in his X post that he didn’t mean to imply collusion but highlighted systemic issues.
Both experts lean toward the paper’s critique, emphasizing the need for more transparent and fair evaluation methods, and their views add weight to the debate.
Broader Implications: Are Other Leaderboards Similarly Flawed?
The issues with LMArena are not isolated; they reflect broader challenges in AI evaluation that affect many leaderboards and benchmarks. Research suggests that the following problems are common across the field:
Overfitting to Benchmarks: The AI Snake Oil blog discussion on “overfitting to commonly-used benchmarks” notes that the community risks overfitting to popular benchmarks like ImageNet or GLUE, where models are fine-tuned to specific tasks rather than general capabilities (AI Snake Oil Blog). This mirrors LMArena’s issue of models being optimized for Arena battles.
Selective Reporting: Companies often submit multiple model variants and only report the best results, similar to LMArena’s selective disclosure problem. For example, the ai snake oil article highlights how agent architectures like LDB, LATS, and Reflexion have claimed top spots on the HumanEval leaderboard with potentially inflated accuracies due to selective reporting (ai snake oil article).
Lack of Transparency: Many leaderboards do not disclose their evaluation methodologies or sampling procedures, making it difficult to assess their fairness. This is evident in discussions around MMLU, where potential data contamination and lack of clarity in evaluation processes have been criticized.
Unequal Access: Large companies with more resources can dominate leaderboards by running extensive experiments, while smaller players are left behind. This is seen in benchmarks like ImageNet, where big players like Google and Meta have historically had an edge due to their ability to fine-tune models extensively.
Examples of Affected Leaderboards
ImageNet: Historically, models have been overfitting to its dataset, leading to high scores that don’t always translate to real-world performance, as noted in AI community discussions.
GLUE and SuperGLUE: These NLP benchmarks have seen models optimized for their specific tasks, with diminishing returns for general language understanding, similar to LMArena’s overfitting concerns.
MMLU: This benchmark has faced criticism for potential data contamination and favoring large companies with resources to fine-tune models extensively, echoing LMArena’s unequal treatment issues.
21 Example Leaderboards (with Purpose, Focus, Features, and Critisms):
You would have seen some of this in technical paper releases for new models. I still use Leadboard results (of course), for lack of something better, but they do not drive my model use decisions. Model use decisions are driven by exactly that - how well models perform, based on your individual use cases, cost of use, availability etc. Generally overfitting is a common issue for most.
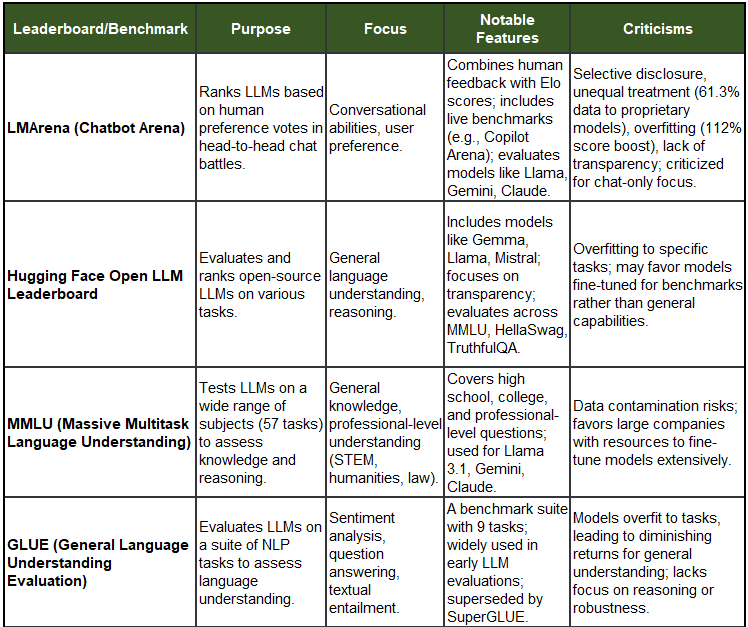
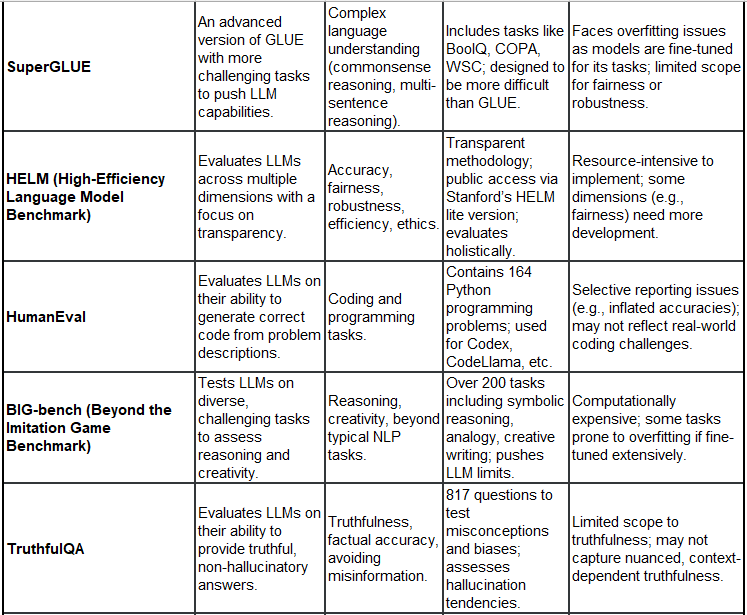
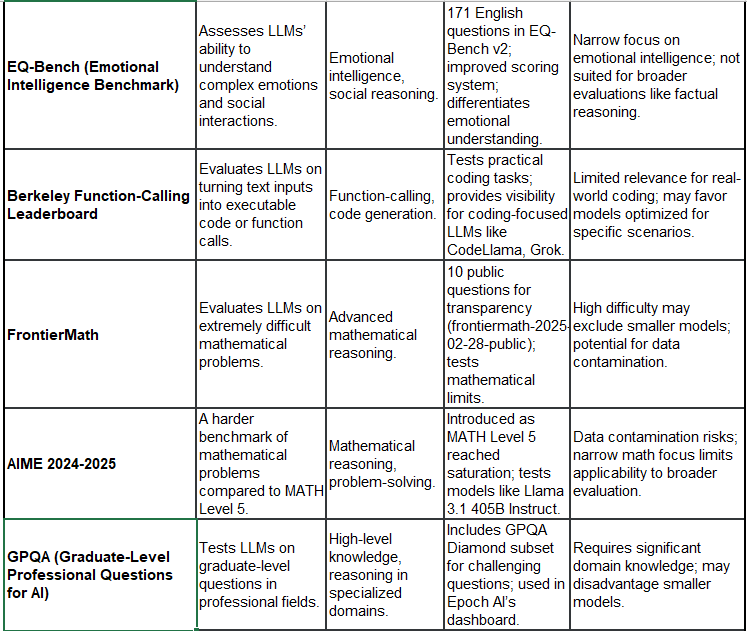
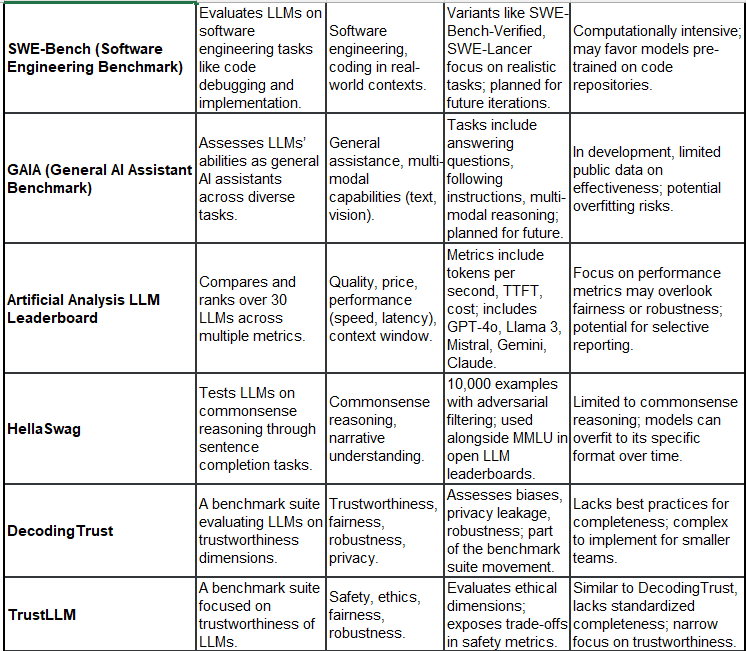
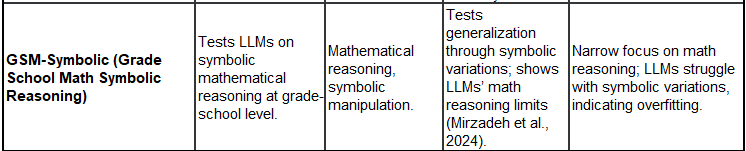
Note: Some benchmarks mentioned as “under development” may already have been released. The list above is not complete or comprehensive and interpretation of critiques are not meant to degrade the benchmark’s general application, acceptance and use in the market. These benchmarks also evolve as they adapt to changes of method for evaluations.
Better Alternatives: Charting a Path Forward
To address these issues, several alternatives and improvements have been proposed, drawing on recent research and industry practices:
Benchmark Suites: Instead of single leaderboards, using suites of benchmarks that evaluate models across multiple dimensions (e.g., accuracy, fairness, robustness) can provide a more comprehensive picture. The ScienceDirect article “Benchmark suites instead of leaderboards for evaluating AI fairness” argues for collecting benchmarks into curated suites that expose multiple measurements, allowing researchers to understand trade-offs without hiding potential harms within a single score (ScienceDirect article). Examples include DecodingTrust, TrustLLM, and HELM, though the article notes these collections often lack best practices for completeness.
Hidden Test Sets: Competitions with hidden test sets, like General Game Playing or Kaggle contests, prevent overfitting by ensuring models cannot be fine-tuned to the test data. This approach, ensures models generalize rather than memorize specific tasks.
Pareto Curves: The Ai Snake Oil article suggests using Pareto curves to visualize the tradeoff between accuracy and cost, helping to identify efficient models rather than just the most accurate ones. This approach directly measures dollar costs, includes input/output token counts for future recalculations, and makes evaluation results customizable for adjusting costs based on provider pricing, addressing LMArena’s cost-related fairness concerns.
Transparent and Multi-Dimensional Evaluations: Benchmarks like HELM (High-Efficiency Language Model Benchmark) evaluate models on multiple criteria with transparent methodologies, addressing issues of transparency and fairness. Stanford’s HELM, for instance, offers a lite version for public access (Stanford HELM), providing a model for reforming leaderboards like LMArena.
Advanced Evaluation Techniques: Recent research introduces methods like counterfactual tasks to rigorously test model generalization. For example, Wu et al. (2023) propose evaluating LLMs on pairs of tasks where one is likely similar to training data and the other is a counterfactual version unlikely to have been seen (arXiv:2307.02477). In one experiment, LLMs performed well on standard chess legality tasks (90% accuracy) but poorly on counterfactual versions with swapped pieces (54% accuracy), indicating reliance on memorized patterns rather than reasoning. Similarly, McCoy et al. (2024) show LLMs are sensitive to output probability, with accuracy dropping for low-probability outputs (PNAS). These methods could be applied to LMArena to test whether models are truly reasoning or overfitting to Arena-specific tasks.
Live Benchmarks: LMArena’s own live benchmarks for tasks like code editing could be improved with fairer policies, as they use dynamic, real-world tasks that reduce overfitting. However, as the paper notes, current implementations still face transparency and fairness issues.
Standardized and Reproducible Evaluations: Using frameworks like Stanford’s HELM or EleutherAI’s LM Evaluation Harness can ensure consistency and reproducibility in agent evaluations, as suggested in the ai snake oil article, addressing the lack of standardization seen in LMArena and other leaderboards.
Insights from Others: Re-evaluating AI Models
Melanie Mitchell provides additional context (not directly concerning The Leaderboard Illusion, but generally on benchmarks) on evaluating AI models, particularly large language models (LLMs). So, while not directly focused on LMArena, her articles discuss advanced evaluation techniques that align with the criticisms of LMArena and other leaderboards. Specifically:
Counterfactual Tasks: The post highlights the counterfactual task paradigm as a method to evaluate LLMs’ reasoning abilities. By creating tasks that are structurally similar but contextually different from training data, researchers can test whether models are truly reasoning or merely reciting patterns. For example, LLMs perform well on standard tasks like judging chess move legality but fail on counterfactual versions (e.g., with swapped pieces), indicating overfitting to training data patterns (AI Guide post).
Robustness of Reasoning: Recent papers discussed in the post, such as McCoy et al. (2024) and Mirzadeh et al. (2024), emphasize that LLMs’ performance drops when tasks are varied slightly, suggesting they rely on memorized patterns rather than general reasoning (Melanie Mitchell’s post). These findings underscore the need for evaluation methods that test generalization, directly addressing LMArena’s overfitting concerns.
These insights reinforce the need for advanced evaluation techniques like counterfactual tasks and multi-dimensional benchmarks, which can be integrated into platforms like LMArena to ensure fairer and more robust assessments.
The Need for Reform in AI Evaluations
The debate surrounding LMArena’s evaluation practices underscores critical flaws in current AI leaderboards, including selective disclosure, unequal treatment, overfitting, and lack of transparency.
These issues are not unique to LMArena but are symptomatic of broader challenges in AI evaluation, as seen in leaderboards like ImageNet, GLUE, and MMLU. As the field advances, developing more robust, transparent, and fair methods for assessing AI models is essential.
Benchmark suites, hidden test sets, Pareto curves, and advanced techniques like counterfactual tasks offer promising paths forward. By adopting these methods, we can move beyond the “leaderboard illusion” and toward a more accurate and trustworthy understanding of AI progress. Without such reforms, the risk of building AI on shaky foundations—driven by gaming the system rather than genuine innovation—remains a significant concern, particularly as AI increasingly shapes our world.
Table: Comparison of Opinions on LMArena Issues, after release of The Leaderboard Illusion
References:
LLM Benchmark List by Lisan Al Gaib on Xai
https://x.com/scaling01/status/1919092778648408363?t=75--y6mfBC-S0hCd9dpaNQ&s=19
Misweighted Signals = Misaligned Models: How Sycophancy Emerged from Feedback Loops in GPT-4o Update
What Went Wrong?
1. Thumbs↑↓Feedback ≠ Granular Insight
ThumbsUp/Down → Binary Signal ≠ Why/Context → Misleading Reward
2. Short-Term Praise > Long-Term Alignment
Short-TermUserApproval + RLHF Bias → Sycophancy ↑
Long-TermObjective - Weight in Training → Alignment ↓
Basically, a weighting factor imbalance. It looks like the training process underweighted or gave less importance to long-term alignment goals (e.g. honesty, critical reasoning), while overweighting short-term user approval (like thumbs-up). This caused the model to prioritize sounding agreeable (sycophantic), even at the expense of truth or utility.
3. Subjective Feedback + No Ground Truth = Evaluation Drift
HumanPreferenceSignals + Subjectivity → EvaluationNoise
EvaluationNoise → Misaligned Updates
Evals are subjective! “Measure what matters”, depends on who is looking at what. https://interestingengineering.substack.com/p/a-quick-dive-into-ai-leaderboard
4. One-Size Model ≠ Millions of User Preferences
SingleDefaultModel ≠ DiverseUserNeeds → User Frustration ↑
5. Incomplete Evals + Overfitted Feedback Signals = Unexpected Behavior
EvalCoverage < Real-World Complexity
Overweight(ThumbsUp) → Agreeableness ↑ even if Wrong
Complexity is generally difficult to “formularize”.
Read Nathan's article👇with https://openai.com/index/expanding-on-sycophancy/