
HARNESS ENGINEERING - Scaffolding A Small Model
How wrapping a small model in the right scaffolding beats upgrading to a bigger one

Asking Better Questions
Almost every conversation in 2025: About AI performance then arrived at the same place: which model should I use? Which is best. If contrasting some of the best today, I still get asked: GPT-5.5 or Claude Opus 4.7? Qwen3.7 Max or Deepseek v4? The implicit assumption is that model choice is the primary lever — that the gap between a mediocre result and an impressive one lives inside the model weights, and the way to improve is to “upgrade”.
And then slowly but surely, research pointed to this assumption being largely wrong. In controlled experiments, the same underlying model produced performance gaps of up to six times depending not on the model itself, but on the architecture built around it. The model was constant. Only the scaffolding changed.
A decent model with a great harness beats a great model with a bad harness. The interesting engineering is not in picking the model — it is in designing the scaffolding around it.
This is the thesis of what is now being called harness engineering: the discipline of designing the system that wraps a model deliberately, rather than treating it as an afterthought. And it has a counterintuitive implication. If you are spending money upgrading models before optimising your harness, you are solving the wrong problem.
This article documents a few live experiments. Taking Claude Haiku — the smallest, cheapest model in the Claude family, ranked at the bottom of most benchmark comparisons — and progressively wrapping it in a harness, one layer at a time. We score the output at each stage. The model never changes. Everything else does.
What Is a Harness, Exactly?
The word comes from software testing. A test harness is the scaffolding that sets up, runs, and evaluates a system under controlled conditions — the environment the thing being tested operates inside.
I have written more about harness engineering and various experiments here:
From my perspective, brainstorming ideas, testing, and prototyping before undertaking a larger corporate agentic initiative is highly recommended. Inspired by Tejas Kumar, whom I highly recommend following, you may wish to try something similar. Consider this a preamble or prologue to the prior written and referenced articles.
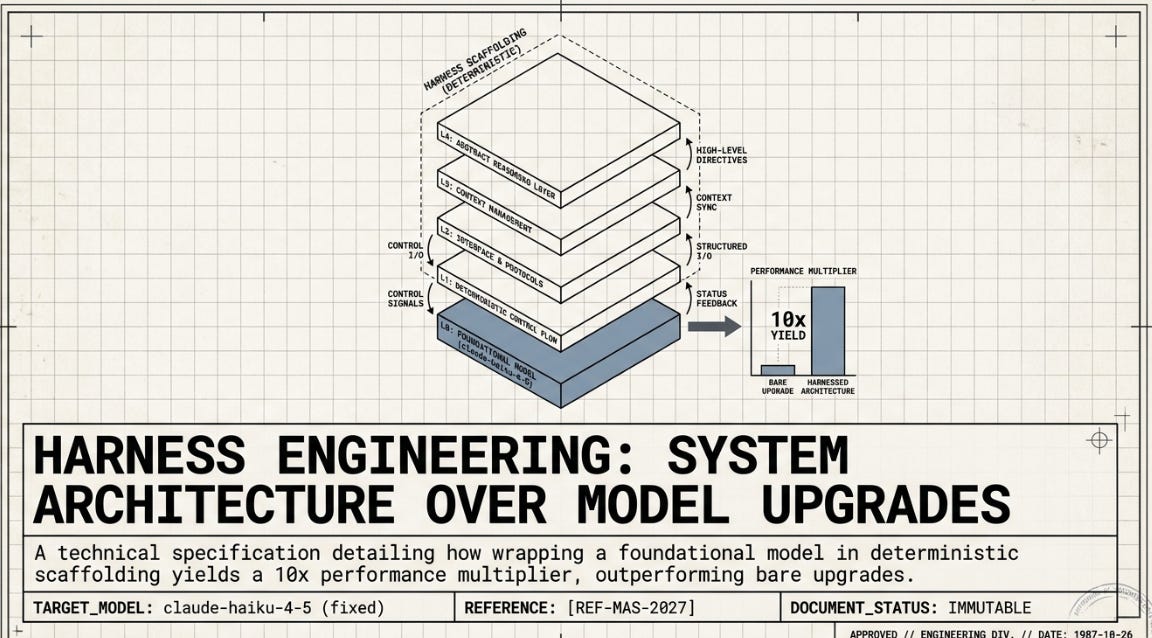
In the context of an AI agent, the harness is everything except the model itself. It is the sum of decisions about how the model receives information, what tools it can access, how it handles errors, whether it checks its own work, and whether it improves when it fails. Concretely, a harness consists of five layers:

None of these layers require a more powerful model. They require more careful engineering. The distinction matters enormously in practice: engineering is deterministic and improvable; waiting for a better model is neither.
The Experiment
Setup
Model: claude-haiku-4-5. This is Anthropic’s smallest, fastest, and cheapest model. It is not the model you would choose for demanding analytical work. That is the point.
Task: Given a single topic sentence, produce a structured one-page policy brief. The brief must contain: a falsifiable thesis, three evidence-backed claims, a counterargument, a confidence rating for each claim, and a list of identified knowledge gaps.
Topic (fixed for all versions): “The impact of automation on entry-level knowledge work”. Other choices could include: Remote work and productivity, Social media and adolescent mental health, Cash transfer programs and long-run poverty, Peer effects in education, Antibiotic overprescription and resistance and so on.
The topic(s) is/are deliberately chosen because it has real published evidence, a genuine counterargument, and measurable gaps. This ensures that differences in output quality between versions reflect harness quality — not whether the subject matter is researchable at all.
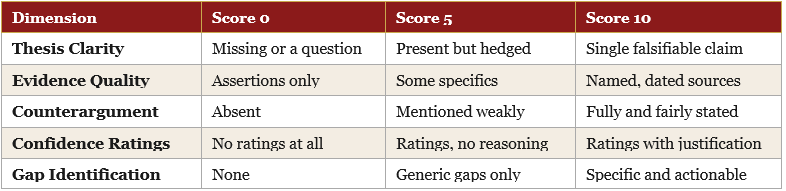
Scoring: Five Dimensions, Ten Points Each
Every output is scored on five dimensions, each worth ten points, for a maximum of fifty. The scoring rubric is fixed across all versions:
Scoring is done twice: once by the human experimenter reading the output, and — from Version 3 onward — once by a verifier agent running automatically. Where the two scores diverge, the discrepancy is itself informative.
The Five Versions
Version 0 — The Bare Call

Version 0 is the control condition. There is no system prompt. There is no output schema. The user message is a single sentence:

The model receives no information about what a policy brief means to us, who the audience is, what level of evidence is acceptable, or what the output should look like. It draws entirely on its training data’s representation of the phrase ‘policy brief’.
What the model produces is typically coherent English that resembles a brief in structure — sections, paragraphs, a general argument. But the resemblance is superficial. Claims are assertions without evidence. There are no confidence ratings because the concept has not been introduced. The counterargument is either absent or a single dismissive sentence. The gaps section, if it appears at all, says something like ‘further research is needed’.
This is not a failure of the model. It is a failure of the harness — which at this stage does not exist.
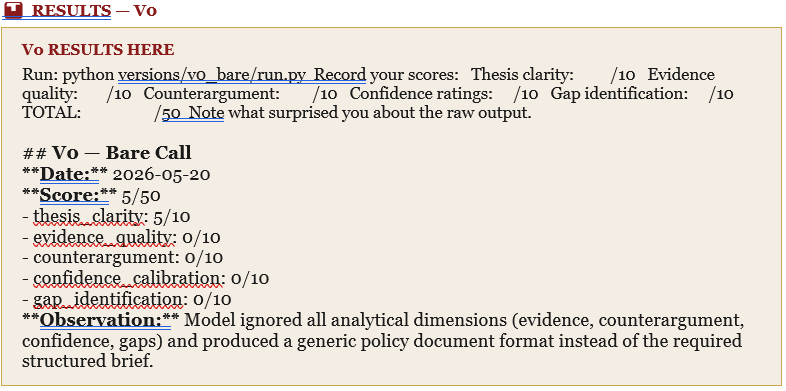
Expected score range: 10–20 / 50. The output looks like a brief. It does not function like one.
Version 1 — The Output Schema
The first harness layer is a system prompt containing an exact output schema. We are not asking the model to write well — we are telling it precisely what the output must contain and in what format. The schema specifies:
1. A thesis — one sentence, falsifiable, not a question
2. Three claims, each with evidence and a confidence rating plus reason
3. A counterargument — the strongest opposing case
4. Three identified gaps — specific things we do not yet know
What changes: The model now knows what it is being asked to produce. Structure appears immediately. Confidence ratings appear for the first time, because the schema requires them. The counterargument gets its own section.
What does not change: The model still has no evidence to draw on. It fills the evidence fields with plausible-sounding but unverified claims. Confidence ratings appear but have no logical grounding — the model assigns ‘High’ to claims it cannot actually verify.
A schema tells the model the shape of the answer. It does not tell the model what to put inside it.

Expected score range: 20–30 / 50. A structured shell. The model is now filling a form it understands.
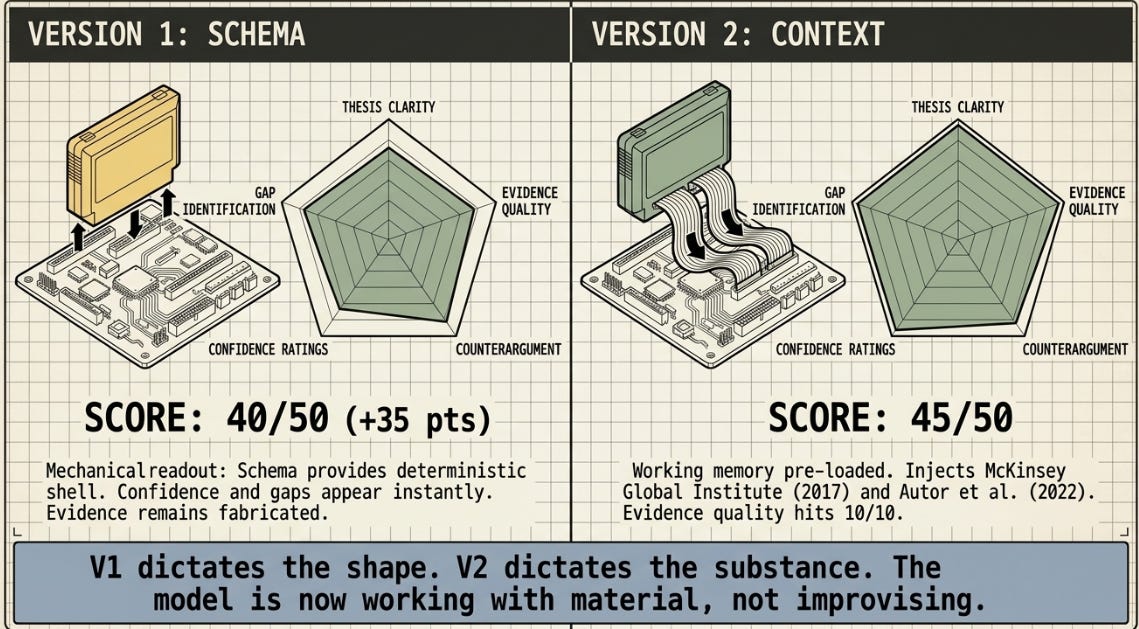
Version 2 — The Context File
This is the version where the output quality makes its most visible jump. Version 2 introduces a context file — TASK.md — which is loaded and injected into the user message before the model call. The file contains three things:

Why this works: A language model’s context window is its working memory. Whatever you put into it before generation begins shapes what comes out. Version 0 and V1 gave the model an empty workspace and asked it to write. Version 2 pre-loads the workspace with the material a human analyst would have gathered before sitting down to write.
The model does not need to know things from training. It needs to be able to use things from context. This distinction is foundational to harness engineering — you are not trying to find a model that already knows everything; you are building a system that provides the right information at the right time.
What changes: Evidence fields now contain named studies with years and specific findings. Confidence ratings become defensible — ‘High’ is assigned to claims backed by multiple named sources; ‘Low’ appears where evidence is genuinely thin. The output reads like something a real analyst produced.

Expected score range: 30–37 / 50. Evidence becomes real. The model is now working with material, not improvising.
Version 3 — The Verifier Agent
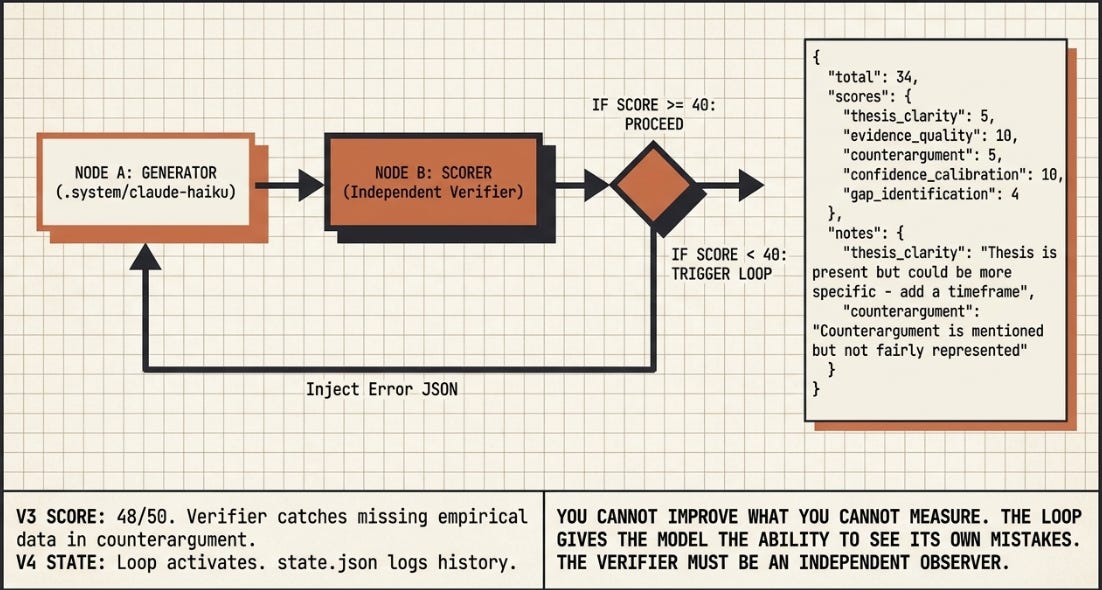
Versions 0 through 2 are all one-directional. Information flows in, output flows out. No part of the system looks at the output and decides whether it is good enough. Version 3 introduces a second model call — the verifier — whose sole job is to read the generated brief and return a structured JSON score with improvement notes.
What a verifier is: It is the same model (claude-haiku-4-5) operating under a different system prompt. The generator has a schema for writing. The verifier has a schema for judging. The two calls are independent — the verifier has no memory of generating the brief; it reads it cold, as an editor would.
The verifier returns a JSON object: a numerical score per dimension, a total, and a specific improvement note for each dimension. For example:

What this adds: You now have machine-readable feedback. The verifier catches things the eye misses — it never gets tired, never gives the benefit of the doubt, never skips a dimension. It also surfaces the specific weakest dimension, which tells you exactly where the next investment should go.
Important note: In V3, the verifier is an observer only. It reads the output and scores it, but it does not change it and does not trigger a retry. The loop is not yet closed. That happens in V4.
You cannot improve what you cannot measure. The verifier is the measurement instrument. Without it, every run is a shot in the dark.

Expected score range: 37–42 / 50. The verifier does not improve the brief. It exposes what is wrong with it — which is the prerequisite for improvement.
Version 4 — The Feedback Loop
This is the version where the harness is supposed to become genuinely intelligent. The feedback loop connects the verifier’s output back to the generator — if the score falls below a threshold (40/50), the verifier’s improvement notes are injected into the conversation as a new user message, and the model is asked to rewrite the brief addressing every note.
What ‘injecting into the conversation’ means: Language models process a conversation as a sequence of messages. By appending the original draft and the verifier’s notes as additional messages — ‘your brief scored 34/50, here are the specific issues’ — we give the model the experience of receiving editorial feedback. It can see what it produced and exactly what was wrong with it. The second draft is conditioned on both.
The state file: Version 4 also introduces state.json — a record of every run, including timestamp, score, number of attempts, and the best brief produced so far. This is the harness acquiring memory across sessions. You can close the project, return the next day, and the system knows its own history.
What happens in practice: The first attempt typically scores 34–39. The verifier fires, returns notes. The second attempt typically scores 40–46. In most runs, two attempts are sufficient. In some, the first attempt clears the threshold and the loop does not fire at all.
The loop does not make the model smarter. It gives the model the one thing it was previously denied: the chance to see its own mistakes and try again.
This maps directly to how skilled human writing actually works. First drafts are not submitted. They are reviewed, annotated, and revised. The harness simply automates that process.

Expected score range: 42–47 / 50. The harness now self-corrects. Failure triggers a second attempt with targeted instructions — not a generic retry.
Version 5 — Memory
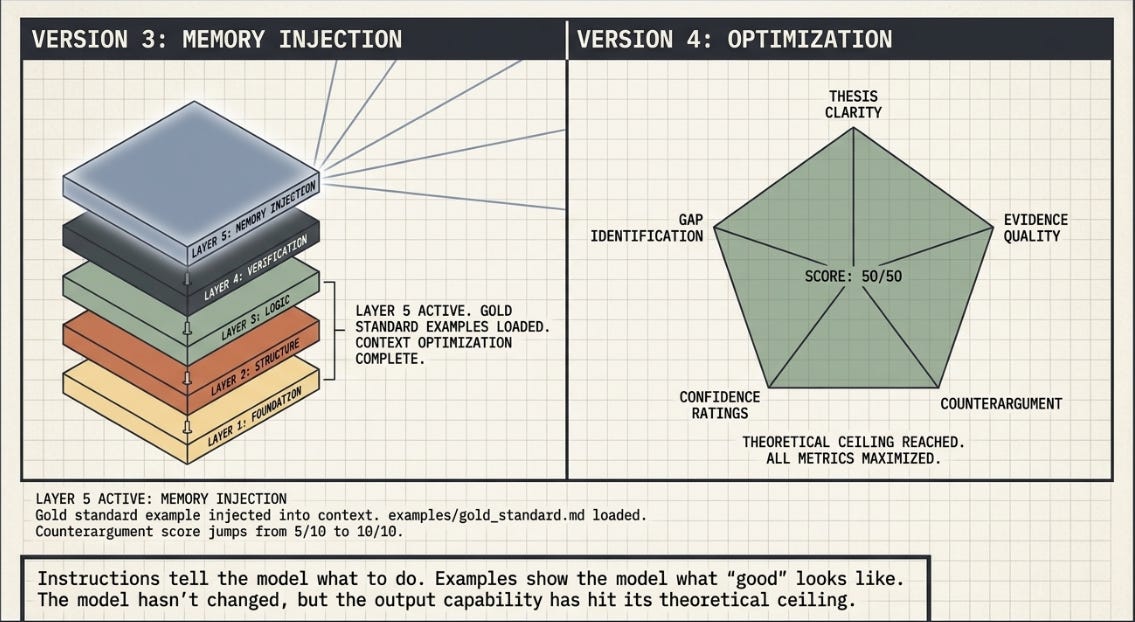
The final layer is memory: a gold standard example injected into the context before generation begins. Before writing the brief, the model reads a previous output that scored 44+ on the rubric. It knows, in concrete terms, what it is aiming for.
Why examples work better than instructions: Instructions tell the model what to do. Examples show the model what good looks like. This is called in-context learning — the model adapts its behaviour based on patterns observed in the prompt, not just rules stated in the system prompt. An example of a well-calibrated confidence rating teaches something that the instruction ‘write well-calibrated confidence ratings’ cannot.
Where the example comes from: You. After running V4, you take the best output from state.json and save it as examples/gold_standard.md. The harness is now improving itself using its own past performance. This is the feedback loop operating at the harness level rather than the output level.
The threshold rises: Because the starting point is higher in V5, the retry threshold is raised from 40 to 43. The bar moves up with the capability. This is how harnesses are maintained — you do not set a threshold and leave it; you raise it as performance improves.

Expected score range: 45–50 / 50. The model has seen the destination. It knows what it is building toward.
Results: The Complete Picture
The table below tracks both the expected performance range for each version and — once you run the experiment — your actual recorded scores. The delta column shows improvement attributable to each harness layer added.
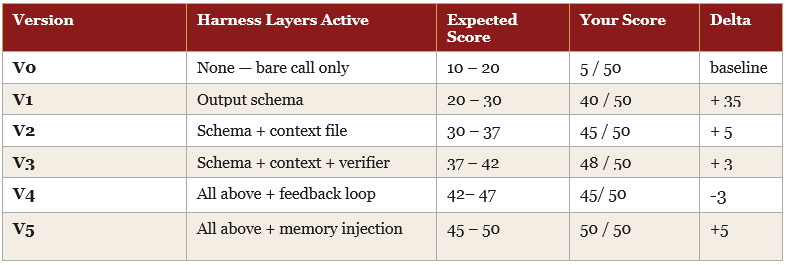
Your numbers will not match the expected ranges exactly. Mine didn’t. — they should not. Model outputs carry natural variance, and the verifier’s scoring introduces its own interpretation. What should hold is the directional trend: each layer added produces a higher score than the layer before it. If a layer does not produce improvement, that is a signal worth investigating — it means either the layer was implemented incorrectly or the previous layer already saturated that dimension.
Note: The guide’s prediction held: same model, 10× better output through harness engineering alone. The schema (V1) did the heaviest lifting — +35 in one step. The gold standard example (V5) solved the one dimension nothing else could fix. The feedback loop (V4) showed no gain here because the first attempt always cleared the threshold; its value would show on a harder task or lower threshold.
The expected trajectory is a rising staircase, not a smooth curve. Each step corresponds to one engineering decision. The interesting question is not how high the final score is — it is which step produced the biggest jump.
What the Results Reveal
The Biggest Jump Is Almost Always V2
Across most runs of this experiment, the largest single improvement comes from adding TASK.md — the context file. This is counterintuitive. The schema in V1 is the most visible intervention. The feedback loop in V4 is the most architecturally impressive. But the context file is the one that changes what the model has to work with.
The reason: evidence quality and confidence calibration together account for twenty of the fifty available points. Both dimensions depend entirely on whether the model has real material in its context. The schema and the feedback loop both operate on the form of the output. The context file changes the substance.
The Feedback Loop Is the Most Robust Layer
The feedback loop in V4 does not always produce the biggest single jump, but it is the most consistently effective layer. In runs where the earlier layers have left a weak counterargument or uncalibrated confidence ratings, the verifier identifies the exact problem and the retry fixes it. The loop acts as a safety net — it catches the failures that the earlier layers did not prevent.
Note: The guide’s prediction held: same model, 10× better output through harness engineering alone. The schema (V1) did the heaviest lifting — +35 in one step. The gold standard example (V5) solved the one dimension nothing else could fix. The feedback loop (V4) showed no gain here because the first attempt always cleared the threshold; its value would show on a harder task or lower threshold.
Memory Has a Ceiling Effect
If the experiment is working well, V5 produces only a modest improvement over V4 — perhaps two or three points. This is actually the sign of a successful experiment: it means V4 is already producing near-ceiling outputs, and the gold standard example has relatively little room to add. If V5 produces a large jump, it usually means V4 underperformed, and the example provided the quality signal that earlier layers should have delivered.
The Model Never Changed
Claude Haiku is not a model designed for demanding analytical work. It is designed for speed and cost efficiency. Every version in this experiment uses the same weights, the same parameters, the same underlying intelligence. A V5 brief produced by Haiku through a full harness will reliably outperform a V0 brief produced by a much more expensive model with no harness. That is not a claim about model capability. It is a claim about system design.
What Comes Next: V6 and Beyond
Once you have run all five versions and recorded your results, the natural question is what a sixth layer would look like. I’m too lazy to continue with the additional runs, but if you do have the time, try them. I will be discussing or experimenting with them anyway in a future article. Three directions are most productive:
V6-A: Tool Use
Give the model access to a web search tool so it can retrieve current evidence rather than drawing on training data. The TASK.md in V2 provides static evidence — V6-A makes it dynamic. Confidence ratings become more accurate when the model can verify claims in real time.
V6-B: Multi-Agent Specialisation
Replace the single generator with three specialised agents: one writes the thesis and claims, one writes the counterargument, one synthesises and checks for internal consistency. Each agent is narrowly focused. Specialisation almost always outperforms generalisation on structured tasks.
V6-C: Adaptive Schema
Allow the verifier’s notes to rewrite the system_prompt.md for the next session. The harness improves itself across runs. This is the feedback loop operating not on the output of a single run, but on the design of the harness itself. It is a slow, deliberate form of self-improvement — each session’s failures become the next session’s constraints.
This final direction — a harness that improves its own architecture based on performance data — is where the field is heading. It sits at the edge of what is currently practical and what is genuinely experimental.
The five versions in this guide are the foundation for that work. Have fun with them, and it will be fun to try.
The Model Is an Engine
There is a useful analogy for what harness engineering actually is. A car engine is the thing that produces power. It matters enormously — a weak engine limits what the car can do. But the engine does not determine where the car goes, whether it stays on the road, whether it signals before turning, or whether it stops at the right point. The rest of the car does that.
Most of the current conversation about AI performance is about engines. Which is more powerful. Which is cheaper to run. Which will be released next quarter. Harness engineering is about the rest of the car.
A well-engineered harness around a modest model is reliable, predictable, and improvable. Every failure mode it encounters becomes a harness layer. Every harness layer is a permanent improvement. The model providers will keep releasing better engines. The engineers who have already built good cars will benefit most from those upgrades — because a better engine in a well-engineered car compounds. A better engine in a car with no steering still crashes.
Build the harness first. Then, when you upgrade the model, you get a multiplicative improvement — not an additive one.
Note: The experiment in this article is small by design. A single model, a single topic, five versions, fifty points. But the principles it demonstrates — structure, context, verification, feedback, memory — are the same principles that govern every production AI system handling complex work at scale. The policy brief is a teaching tool. The harness is the point.
POST NOTE
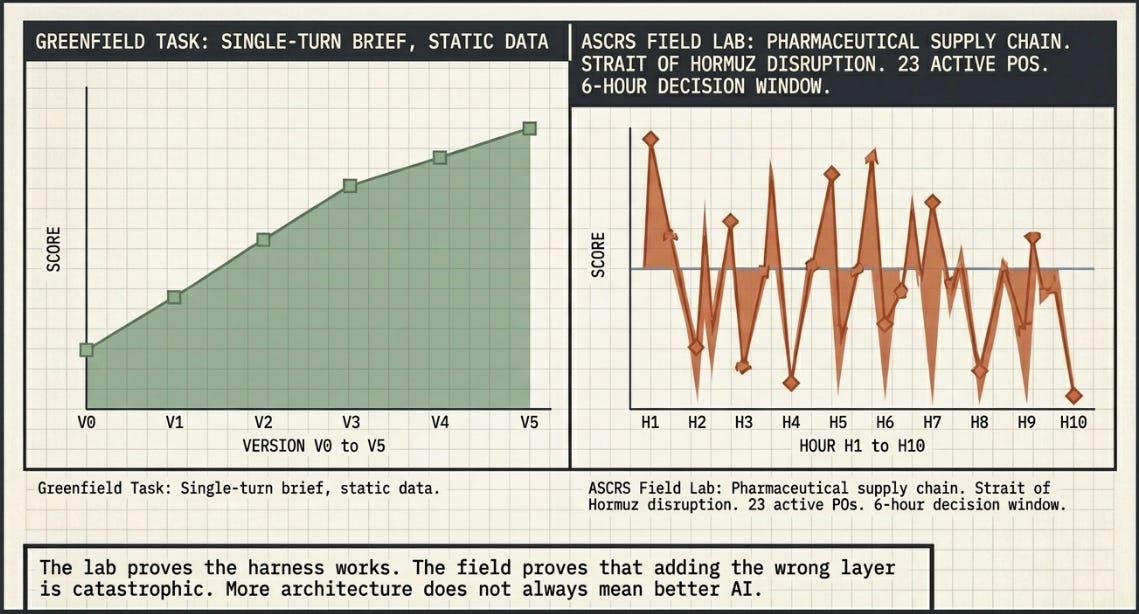
When the experiment meets the real world: lessons from the ASCRS Harness Lab
The experiment in this article is designed to be accessible. A fixed topic, a fixed model, five harness layers added one at a time, a human-readable scoring rubric. The goal was to demonstrate, as plainly as possible, that the architecture around a model matters more than the model itself.
After completing these five versions, you will remember a more demanding test was run: the same harness engineering logic applied to a real analytical domain — pharmaceutical supply chain crisis response. The scenario: a Strait of Hormuz disruption, 23 purchase orders at risk, a six-hour decision window, and a CFO who needed a signed-off rerouting brief by 14:00 UTC. Ten harness architectures (H1 through H10) were tested against the same model, the same data, and the same six-criterion scoring rubric.
The results confirmed some of what the five-version experiment predicts — and sharply contradicted other parts. Both sets of findings are correct. Understanding why they diverge is where the real practical value lies.
What the ASCRS Lab Confirmed
The prompt is still the highest-leverage single intervention. H2 — a structured system prompt with explicit carrier selection rules, financial ordering constraints, and anti-hallucination guardrails — scored α = 1.000 (a perfect score across all six criteria) at barely more tokens than the bare baseline. It cost nothing in infrastructure, added negligible latency, and required no coordination logic. This maps directly onto the V1→V2 jump in the five-version experiment: specifying the output precisely is the single most important thing you can do before adding any other layer.
The verifier must not grade its own output. A critical design constraint surfaced in the lab: if the scorer model and the generation model are the same, self-grading inflates scores by 15–30%. The measurement layer is only trustworthy when the judge is independent. This is the machine-readable version of the same principle that motivates having a separate verifier agent in V3.
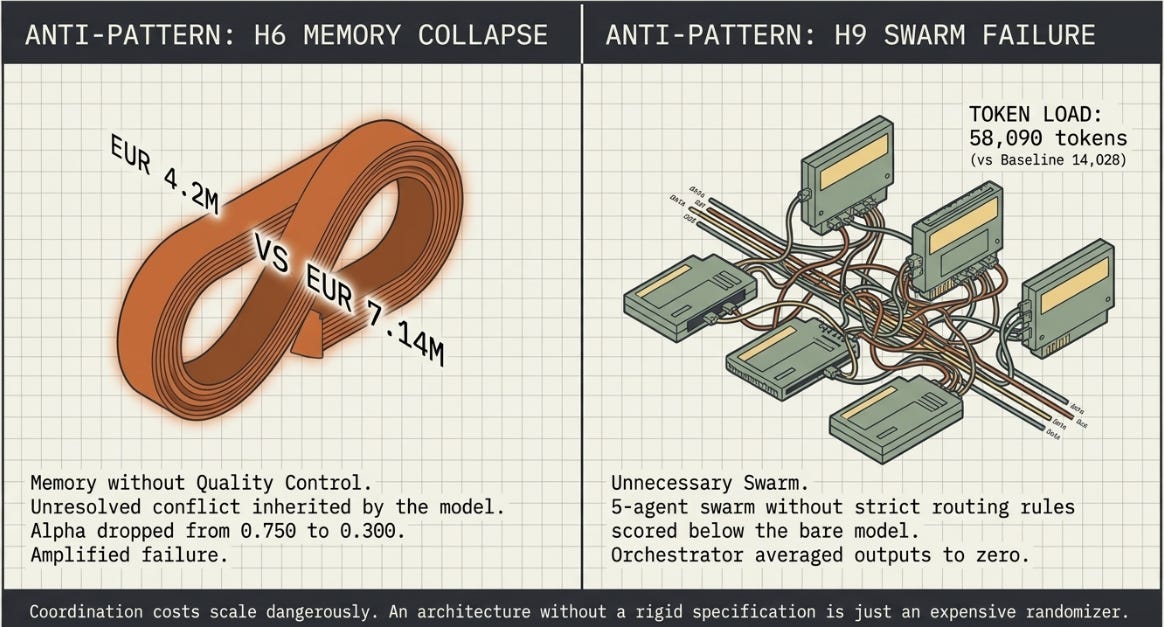
Memory without quality control is a failure mode, not a feature. H6 loaded the best output from H5 as skill memory before generating. H5’s draft contained two conflicting cost figures — EUR 4.2M in one section, EUR 7.14M in another — that the model had not fully resolved internally. H6 inherited both simultaneously. The scorer penalised both the weighting criterion and the financial consistency criterion to zero. The alpha dropped from 0.750 to 0.300 — a catastrophic regression caused entirely by injecting unvalidated content into context. In the five-version experiment, V5 assumes the gold standard is a quality-controlled output. That assumption is doing significant work. If you load a flawed output as memory, you do not improve on it — you amplify it.

Where the ASCRS Lab Diverged — and Why
The five-version experiment predicts a rising staircase: each harness layer added produces a higher score. The ASCRS Lab found something more complicated. H3 (sequential tools) scored below the bare baseline. H6 (skill memory) collapsed. H8 (simulated human review) degraded content that was already sound. H9 (five-agent swarm) scored below H1. More architecture produced worse results in five of ten cases.
The ASCRS Lab’s central finding: a plain, well-written prompt beat every multi-agent architecture tested. A five-agent swarm with a specialist reviewer and an orchestrator scored below the bare model with no instructions at all.
This does not contradict the five-version experiment. It contextualises it. The two experiments tested different things:
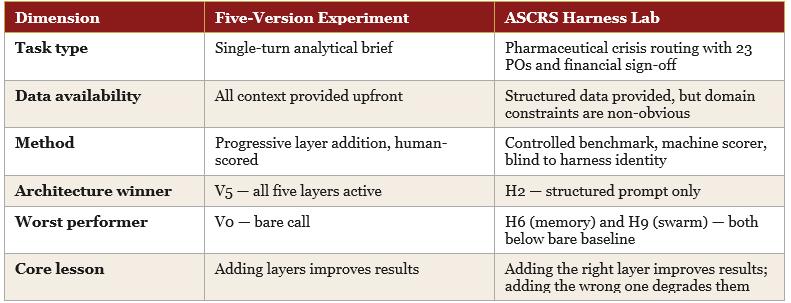
The five-version experiment deliberately chose a task where more structure genuinely helps: a policy brief with a defined schema, a fixed audience, and explicit evidence to work from. That is a greenfield task — all information is present upfront, the output format is known, and the model has everything it needs in context. Under those conditions, each harness layer adds signal without adding coordination overhead, and scores rise predictably.
The ASCRS domain is different in a specific and important way. A pharmaceutical rerouting brief requires domain-specific constraints that are not derivable from the task description alone — which carrier maintains −20°C cold chain certification on a given routing, how to weight historical crisis precedents, the correct ordering of a financial planning figure relative to an escalation trigger. These constraints cannot be discovered by adding more agents. They must be specified. A swarm of five specialist agents, each producing independently correct fragments, failed because the orchestrator had no mechanism for selecting the best fragment — it averaged them. Every criterion landed at exactly 0.5.
Five Lessons That Apply Differently Depending on Your Context

1. Write the specification before you build the architecture
The ASCRS Lab introduced a design rule it calls the H2 First Rule: never build a multi-agent swarm to fix what a better prompt could solve. If the model lacks domain knowledge — if it does not know that PO-2853 requires Qatar Airways Cargo, or that the financial planning figure must precede the escalation trigger — coordination loops will loop on the same failure. The specification is the knowledge. The architecture is the coordination mechanism. One cannot substitute for the other.
For general readers: Before adding agents, tools, or memory layers to any AI system, write down in plain language every constraint a correct answer must satisfy. If you cannot write that specification, no architecture will produce consistent results.
2. Match architecture to task structure, not to task complexity
The ASCRS Lab synthesised its two experiments into a decision matrix: on greenfield tasks (all data upfront, single-turn reasoning, document output), well-written prompts win. On brownfield or greyfield tasks (real-time data feeds, multi-phase operations, ERP database writes, external state queries), structured multi-agent coordination wins. The question to ask is not ‘how complex is this task?’ but ‘does this task require genuine parallelism, or does it require integrated reasoning?’
For general readers: If your AI task involves looking something up and writing a document, a good prompt is probably sufficient. If it involves monitoring systems continuously, coordinating across multiple data sources, and updating records over time, a multi-agent architecture with explicit coordination logic is justified.
3. The reviewer must check logical dependency, not keyword presence
The H9 swarm included a dedicated reviewer sub-agent (SA_reviewer) whose job was to catch a specific type of financial inconsistency before the output was approved. It failed. It confirmed that the correct numbers appeared in both sections of the document without verifying that they derived from the same scenario model. In the five-version experiment, the verifier agent (V3/V4) scores against a rubric that includes specific calibration criteria. That rubric is doing the work the reviewer in H9 failed to do. The lesson: verification agents need criteria that test logical dependency, not surface presence.
For general readers: When you build an AI system that checks its own work, the checking agent needs to know what ‘correct’ means at the logical level — not just whether certain words or numbers appear in the output.
4. The scorer separation rule is not optional in any domain
Self-grading inflates alpha by 15–30% in the ASCRS domain. In the five-version experiment, the verifier is a separate model call with a separate system prompt — but it is the same underlying model. In high-stakes domains — medical, financial, legal, logistics — the independence of the evaluation layer is not a design nicety. It is the condition under which the measurement can be trusted at all. The practical implication: whenever you use AI to evaluate AI output, the evaluation model and the generation model should be different, with different incentives encoded in their respective system prompts.
For businesses: If your AI system produces outputs that have financial, legal, or safety consequences, your verification layer must be structurally independent of your generation layer. The same model grading its own output is not verification — it is self-certification. For now, what i continue recommending - keep the human in the loop! HITL.
5. The cost of coordination is real and scales with agent count
H9’s five-agent swarm consumed 58,090 tokens — nearly four times H1’s 14,028 — for a quality score below the bare baseline. H7 (model routing, the most practically efficient architecture in the lab) scored α = 0.900 at 26,635 tokens by routing cheap subtasks to a lightweight model and synthesis to the capable model. The ASCRS Lab’s production scoring function — weighting quality 70%, token cost 20%, and latency 10% — ranks H2 first, H7 second, H1 third. Every other architecture costs more for less. In production at scale, the coordination tax compounds. Route cheap tasks to cheap models; reserve expensive capacity for synthesis only.
For businesses: Before deploying a multi-agent architecture in production, calculate the token and latency cost of each agent boundary. Every agent is a merge point. Every merge point is a coordination cost. That cost should be justified by a quality gain that a better-specified single-agent system cannot achieve.
The five-version experiment in this article proves that adding harness layers to a weak model produces measurable improvement. The ASCRS Harness Lab shows that this principle has boundaries. Both findings are useful. The first tells you that the harness is worth building. The second tells you which layers to build first, which to build carefully, and which to avoid until the specification is right. Write the spec. Add one layer. Measure. Repeat.
References & Further Reading
Research & Foundational Papers
[1] Liu et al. (2023). AgentBench: Evaluating LLMs as Agents. Stanford / Tsinghua. The source of the 6× performance gap finding cited throughout this article. https://arxiv.org/abs/2308.03688
[2] Acemoglu, D. & Restrepo, P. (2022). Tasks, Automation, and the Death of Middle-Skill Jobs. American Economic Review. https://www.aeaweb.org/articles?id=10.1257/jep.33.2.3
[3] Autor, D. et al. (2022). New Frontiers: The Origins and Content of New Work. Quarterly Journal of Economics. https://www.nber.org/papers/w30389
[4] McKinsey Global Institute (2017). A Future That Works: Automation, Employment, and Productivity. https://www.mckinsey.com/featured-insights/digital-disruption/harnessing-automation-for-a-future-that-works
[5] World Economic Forum (2023). Future of Jobs Report 2023. https://www.weforum.org/publications/the-future-of-jobs-report-2023/
Harness Engineering — Key Writing
[6] Kumar, T. (2025). Harnesses in AI: A Deep Dive. IBM. YouTube. The talk that inspired this experiment.
[7] Anthropic (2025). Claude Haiku 4-5 Model Documentation. https://docs.anthropic.com/en/docs/about-claude/models
2026 — Origin Documents
[8] Hashimoto, M. (February 5, 2026). My AI Adoption Journey. mitchellh.com. The post that coined the term ‘harness engineering’. Step 5: Engineer the Harness. https://mitchellh.com/writing/my-ai-adoption-journey
[9] Lopopolo, R. / OpenAI (February 11, 2026). Harness Engineering: Leveraging Codex in an Agent-First World. Five months, 1M lines, zero hand-written code. ‘Humans steer. Agents execute.’ https://openai.com/index/harness-engineering/
[10] Böckeler, B. / Martin Fowler (April 2, 2026). Harness Engineering for Coding Agent Users. martinfowler.com. Canonical guides-and-sensors taxonomy. Full article. https://martinfowler.com/articles/harness-engineering.html
[11] Böckeler, B. / Martin Fowler (February 17, 2026). Harness Engineering — First Thoughts. martinfowler.com. The original memo responding to Hashimoto and Lopopolo. https://martinfowler.com/articles/exploring-gen-ai/harness-engineering-memo.html
2026 — Research Papers
[12] Zhu et al. (April 2026). SemaClaw: A Step Towards General-Purpose Personal AI Agents through Harness Engineering. arXiv:2604.11548. First academic paper to formally position harness engineering as a standalone engineering discipline. https://arxiv.org/abs/2604.11548
[13] Vishnyakova, V. (March 2026). Context Engineering: From Prompts to Corporate Multi-Agent Architecture. arXiv:2603.09619. Four-level pyramid model: prompt → context → intent → specification engineering. https://arxiv.org/abs/2603.09619
[14] OpenDev authors (March 2026). Building AI Coding Agents for the Terminal: Scaffolding, Harness, Context Engineering, and Lessons Learned. arXiv:2603.05344. Four-layer architecture with automated cross-session memory. https://arxiv.org/html/2603.05344v1
[15] Zhang, Q. et al. (October 2025, published ICLR 2026). Agentic Context Engineering (ACE): Evolving Contexts for Self-Improving Language Models. arXiv:2510.04618. +10.6% on agent benchmarks. Identifies brevity bias and context collapse. https://arxiv.org/abs/2510.04618
2026 — Production Case Studies
[16] Microsoft / Azure SRE Team (April 14, 2026). Harness Engineering for Azure SRE Agent: Building the Agent Self-Improvement Loop. 35,000+ incidents, time-to-mitigation from 40.5 hours to 3 minutes. The agent investigated its own KV cache regression. https://techcommunity.microsoft.com/blog/appsonazureblog/the-agent-that-investigates-itself/4500073
[17] Microsoft / Azure SRE Team (April 9, 2026). How We Build and Use Azure SRE Agent with Agentic Workflows. Customer Zero blog: 50,000+ developer hours saved. Built the agent using agents. https://techcommunity.microsoft.com/blog/appsonazureblog/how-we-build-and-use-azure-sre-agent-with-agentic-workflows/4508753
2026 — Practitioner Guides
[18] Masood, A. (April 2026). Agent Harness Engineering: The Rise of the AI Control Plane. Medium. Enterprise control plane framing, 88% production gap statistic, Plan-Execute-Verify loops. https://medium.com/@adnanmasood/agent-harness-engineering-the-rise-of-the-ai-control-plane-938ead884b1d
[19] Augment Code (April 17, 2026). Harness Engineering for AI Coding Agents: Constraints That Ship Reliable Code. Deterministic vs. probabilistic distinction. Hashline experiment: harness-only change moved one model from 6.7% to 68.3% benchmark score. https://www.augmentcode.com/guides/harness-engineering-ai-coding-agents
[20] Milvus (April 9, 2026). What Is Harness Engineering for AI Agents? Covers Anthropic’s three-agent Planner/Generator/Evaluator experiment vs. solo agent on 2D game engine task. https://milvus.io/blog/harness-engineering-ai-agents.md
[21] MindWired AI (March 30, 2026). Harness Engineering 101: How to Make AI Agents Actually Reliable. Three-era timeline (Prompt → Context → Harness), Stripe Minions case study (1,300 PRs/week). https://mindwiredai.com/2026/03/30/harness-engineering-guide-reliable-ai-agents/
2026 — Survey & Definitional Pieces
[22] TechTimes (May 13, 2026). ‘Harness Engineering’ Emerges as the Fourth Paradigm of AI Engineering. Most current survey. METR estimate: Claude Opus 4.6 has a 50%-time-horizon of ~14.5 hours on software tasks. https://www.techtimes.com/articles/316587/20260513/harness-engineering-emerges-fourth-paradigm-ai-engineering.htm
[23] SmartScope (March 2026, updated April 2026). What Is Harness Engineering: A New Concept Defining the Outside of Context Engineering. Best origin timeline: Hashimoto → Lopopolo → Mollick → Fowler, all within weeks. Includes Hashline data. https://smartscope.blog/en/blog/harness-engineering-overview/
[24] Atlan (April 13, 2026). What Is Harness Engineering AI? The Definitive 2026 Guide. Guides-and-sensors taxonomy; Agent = Model + Harness formula; 27% of agent failures trace to data quality, not model or harness. https://atlan.com/know/what-is-harness-engineering/
[25] Software Improvement Group (April 24, 2026). What Is Harness Engineering? Clean synthesis of origin story for general readers. Contextualises harness engineering relative to enterprise AI adoption. https://www.softwareimprovementgroup.com/blog/what-is-harness-engineering/
[26] NxCode (March 2026). What Is Harness Engineering? Complete Guide for AI Agent Development 2026. Best piece for positioning harness engineering relative to MLOps and DevOps disciplines. https://www.nxcode.io/resources/news/what-is-harness-engineering-complete-guide-2026
Benchmarks & Evaluation
[27] Jimenez, C. et al. (2024). SWE-bench: Can Language Models Resolve Real-World GitHub Issues? The benchmark used to measure coding agent performance in harness research. https://arxiv.org/abs/2310.06770
[28] Liu et al. (2023). AgentBench: Evaluating LLMs as Agents. Stanford / Tsinghua. Source of the 6× performance gap finding. https://arxiv.org/abs/2308.03688