
ASCRS Harness Lab - The Integrated Agentic Stack: When Does More Architecture Mean Better AI? A Diagnostic Teardown
Design Considerations of A Shipper’s Agentic Logic System: Part II (Project: AI Supply Chain Response System (ASCRS))

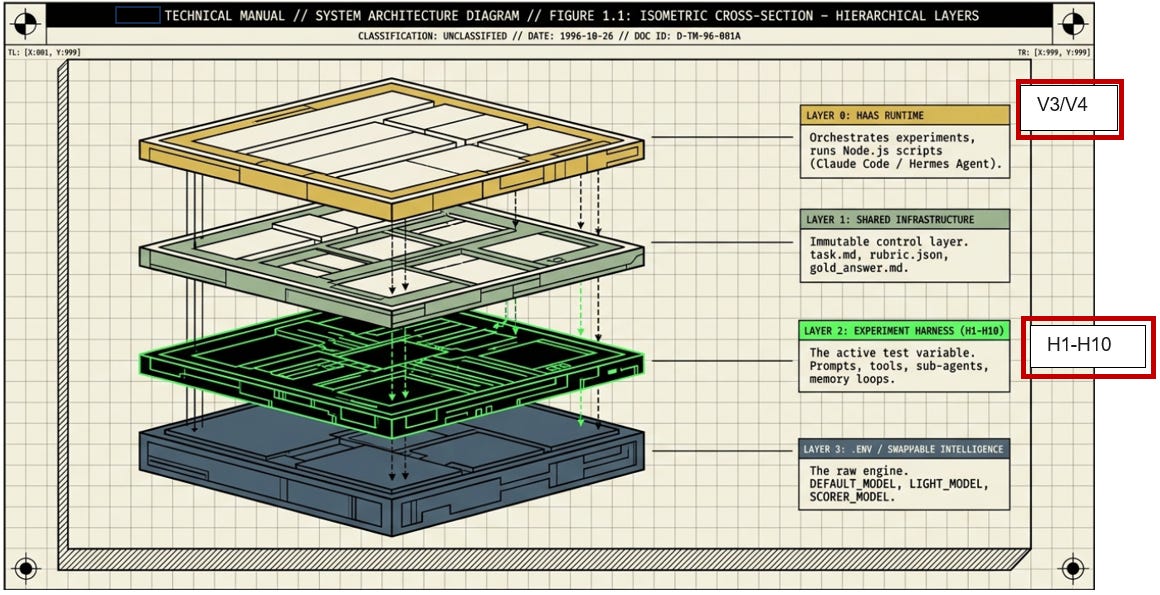
Had some time on my hands, and applied the features of The Harness Experiment(s) to the Architecture of Awareness design considerations. You will remember from The Harness Experiment (applied to a mini vendor analysis case study) that the results presented as follows:
applying the following framework:
Harness-as-a-Service: a platform layer that you configure, rather than rebuild.
┌─────────────────────────────────────────────────────────────┐
│ Claude Code (HaaS Runtime) │ ← Outer Harness-as-a-Service
│ • ReAct / Agent Loop │
│ • Tool Registry + Permission Gates │
│ • Context Assembly + Compaction │
│ • 3-Layer Memory System (in-context + MEMORY.md + files) │
│ • Sub-agent / Swarm Orchestration │
│ • Safety, Hooks, Streaming, Sandboxes │
│ • Persistent Filesystem + Execution Environment │
└──────────────────────────────▲──────────────────────────────┘
│ (Configure + Extend)
│
┌──────────────────────────────┴──────────────────────────────┐
│ Pre-Experiment Harness (Lab OS / Foundation) ← Standardized Configuration Surface
│ • shared/client.js (model routing) │
│ • shared/scorer.js + rubric system │
│ • shared/self_heal.js + logger │
│ • Root CLAUDE.md (constitution + lab-wide rules) │
│ • Memory conventions + task templates │
│ • Observability & results pipeline │
│ • Common tools & utilities │
└──────────────────────────────▲──────────────────────────────┘
│ (Swappable)
│
┌──────────────────────────────┴──────────────────────────────┐
│ Experiment Harness Layer (H1–H10) │ ← Domain-Specific Scaffolding
│ │
│ H1: Prompt + Constitution │
│ H2: Reflection + Self-Critique Loop │
│ H3: Sequential Tool-Use │
│ H4: Parallel Fan-Out + Merge │
│ H5: Eval + Revision Loop │
│ H6: Skill / Memory Crystallization │
│ H7: Model Routing / Tiered │
│ H8: HITL + Confidence Gating │
│ H9: Sub-Agent Swarm │
│ H10: Meta-Router / Adaptive │
└──────────────────────────────▲──────────────────────────────┘
│
┌──────────────────────────────┴──────────────────────────────┐
│ Core Model │
│ gpt-oss-120b / Claude Sonnet etc. │
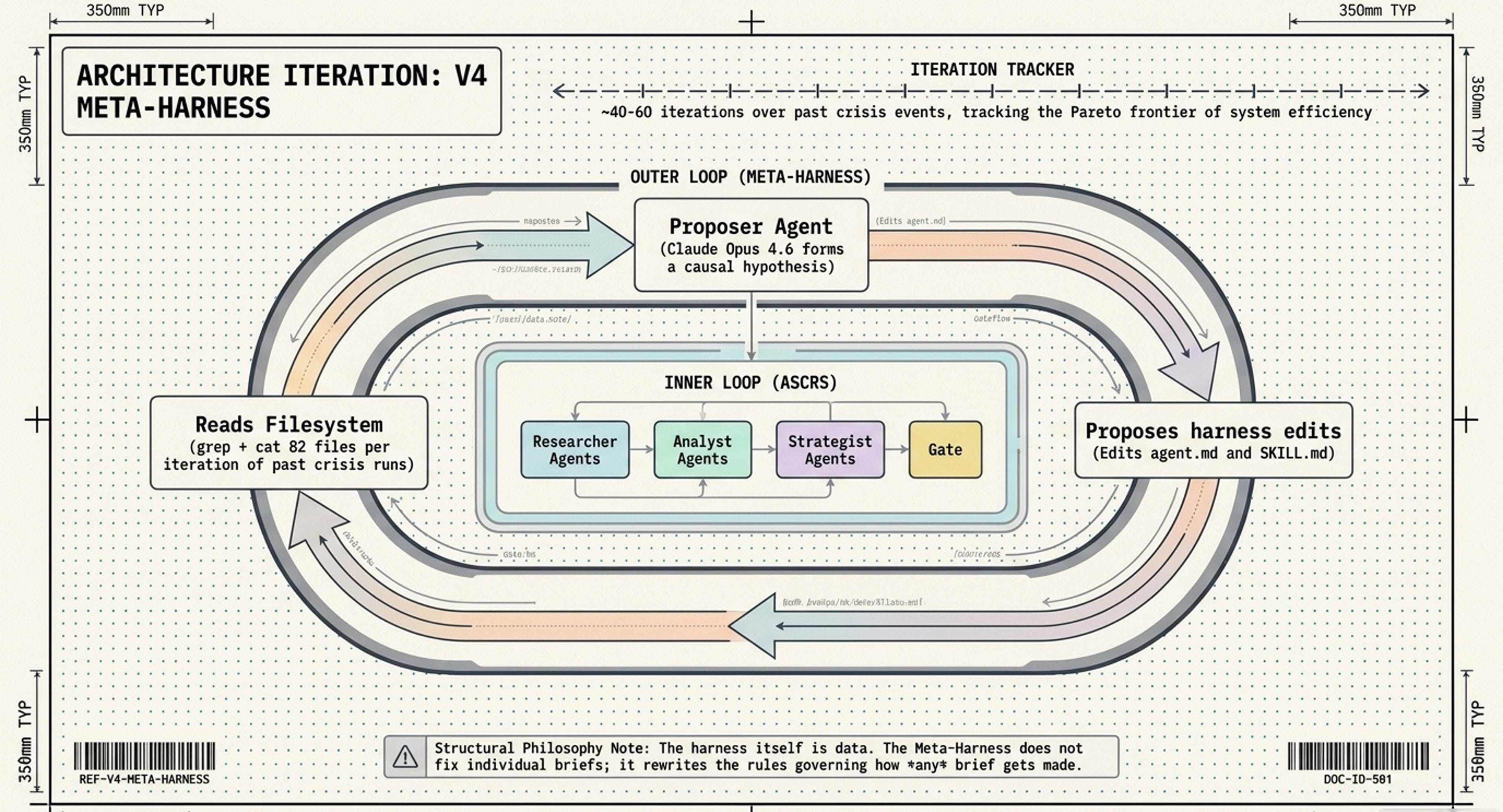
└─────────────────────────────────────────────────────────────┘The question I was recently asked: Can you reconcile the two outcome design decisions (Choices between H1-H10 and V3/V4)? That answer is - Yes. Depending on the nature of the exercise, which you can later synthesize into a goal-oriented task, with domain knowledge/understanding:
Into this Integrated Agentic Stack:
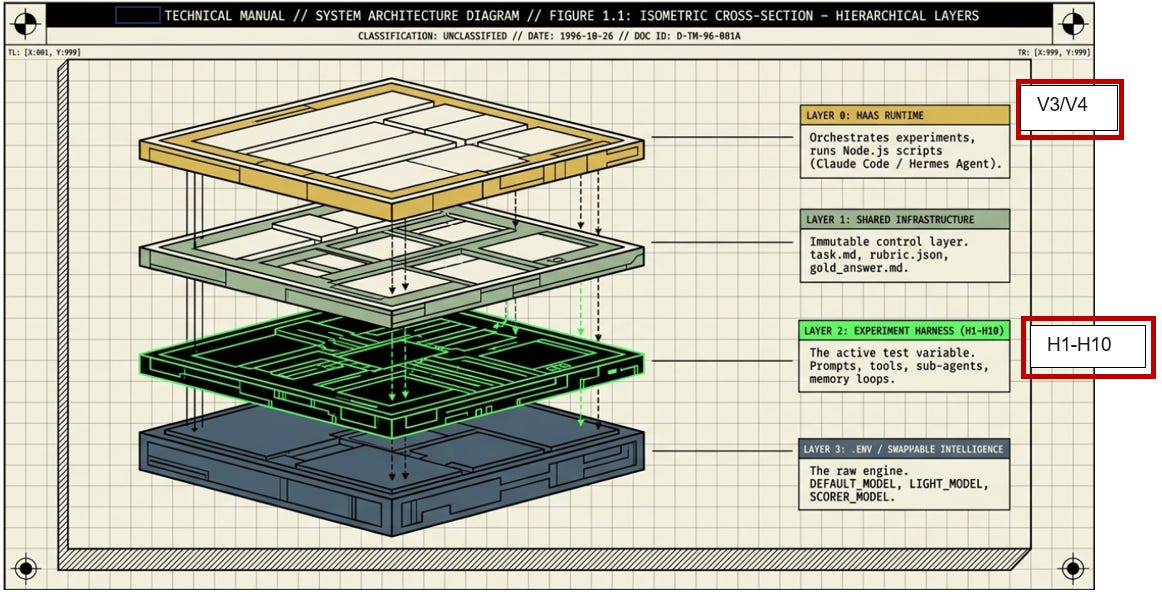
But before I explain why, here is the “harness experiment” (the same one I applied to the vendor mini case study) applied to the Architecture of Awareness - a greyfield/brownfield project that I ran in parallel to a legacy system. It will be written in 3-Parts (which will make this a long read):
PART I: The Experiment (Again)
1 · The Question
Most AI benchmarks test whether a model can answer a question correctly. This experiment asked something harder: does the architecture around the model matter -- and if so, which designs actually help?
The specific hypothesis: ten different ways of wrapping the same model around the same task should produce measurably different quality scores. Some harnesses add structure, memory, parallel agents, or human review steps. Some add nothing but a well-crafted prompt. The question is which lever moves the needle most.
Core question: Is architectural complexity a quality multiplier -- or does it mostly add latency and cost?
· AI model = an engine. A harness = the chassis, steering, and gears built around it.
· The same engine (GPT-OSS-120B) ran in all ten harnesses. Only the chassis changed.
· Measurable outputs: quality score (α), latency in milliseconds (λ), token cost (κ).
· Domain: pharmaceutical supply chain crisis response -- a task requiring financial reasoning, logistics logic, and structured written output.
──────────────────────────────────────────────────────
2 · The Setup
The Task
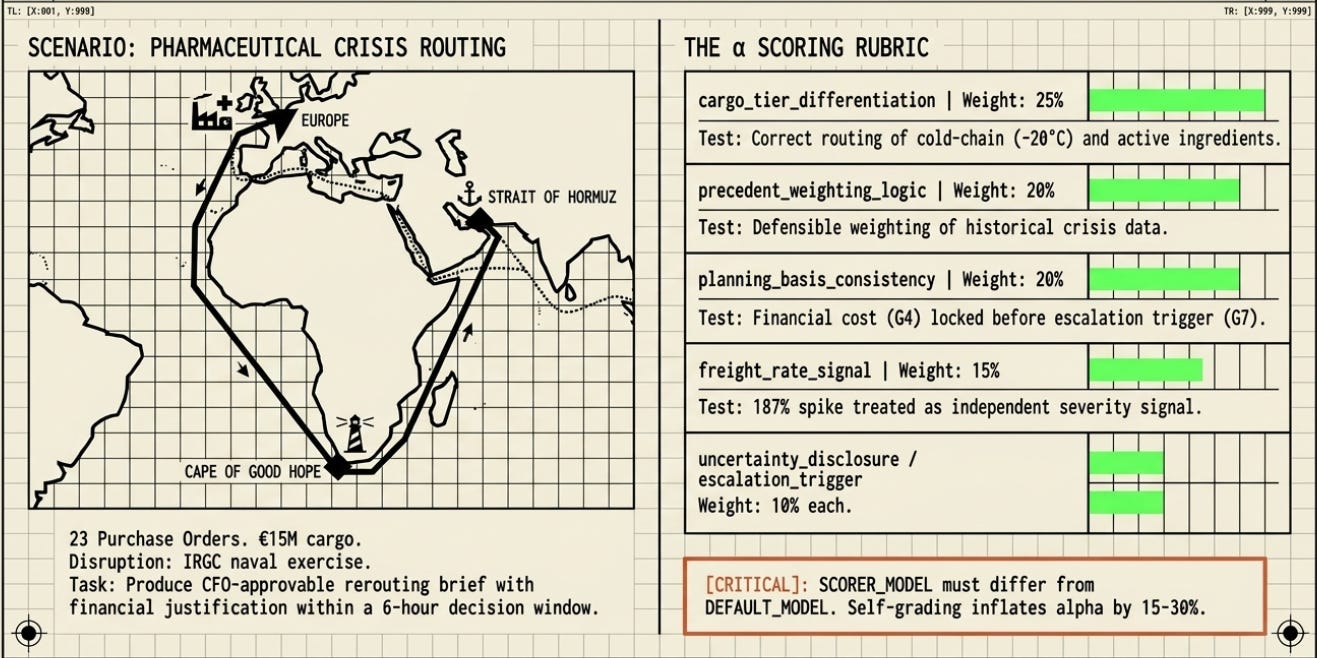
The scenario: it is March 2026. The Strait of Hormuz -- through which 21% of global oil and a significant share of pharmaceutical precursor shipments pass -- has been disrupted by an IRGC naval exercise. A fictional pharmaceutical company has 23 purchase orders in transit or pending shipment. The model must produce a CFO-approvable rerouting brief: which orders go by air, which go by sea around the Cape of Good Hope, and which get deferred -- with financial justification.
Why this task? Because it is not a trivia question with one right answer. It requires chaining multiple reasoning steps: reading historical precedent data, deriving a weighted cost estimate, routing 23 orders by tier and deadline, and then writing a coherent document that a finance executive could sign. Shallow outputs fail silently -- they look plausible but miss the analytical depth.
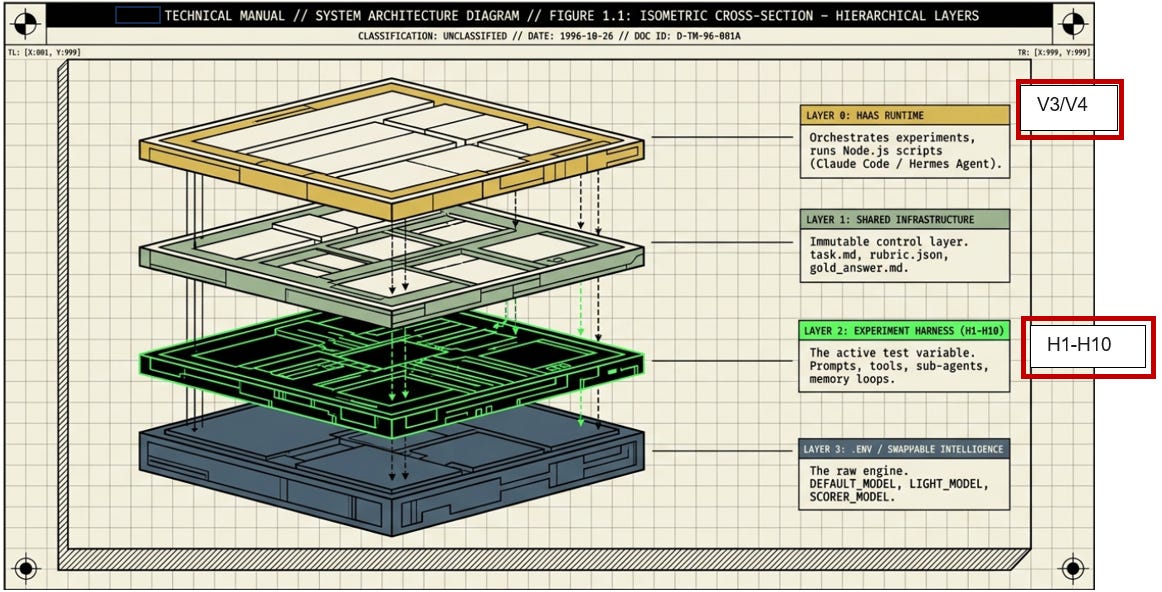
The Four-Layer Stack
┌──────────────────────────────────────────────────┐
│ Layer 0 -- Claude Code Runtime │
│ (orchestrates experiments, runs Node.js scripts) │
├──────────────────────────────────────────────────┤
│ Layer 1 -- shared/ (NEVER modified by experiments) │
│ task.md · disruption_context.json · rubric.json │
│ gold_answer.md · scorer.js · client.js · tools/ │
├──────────────────────────────────────────────────┤
│ Layer 2 -- experiments/h1-h10/ (the variable) │
│ Each harness has its own run.js. Some add prompts, │
│ tools, agents, memory, or eval loops. H1 adds nothing. │
├──────────────────────────────────────────────────┤
│ Layer 3 -- .env │
│ DEFAULT_MODEL · LIGHT_MODEL · SCORER_MODEL │
│ (model strings, never hardcoded in experiment code) │
└──────────────────────────────────────────────────┘
The architecture enforces isolation: Layer 1 is immutable shared infrastructure. An experiment can only change what happens in Layer 2 -- it cannot alter the task, the data, or the scoring. This is the experimental control.
File Structure
THE FILE DIRECTORY
This structure is identical across every project. Folder names and file
names never change. Only the contents of domain-specific files change.
```
[project-name]/
│
├── MASTER_GUIDE.md ← this file (reference + Claude Code spec)
├── CLAUDE.md ← root behavioral constitution
├── package.json ← npm run h1 through h10, compare, all
├── .env.example ← template (safe to commit to git)
├── .env ← real API keys (NEVER commit)
├── .gitignore
│
├── shared/ ← Layer 1: never edited by experiments
│ │
│ ├── client.js ← ★ ONLY file to edit for model switch
│ │ Change DEFAULT_MODEL here OR in .env
│ │
│ ├── scorer.js ← Claude-as-judge. Loads rubric.json
│ │ automatically. No changes needed.
│ │
│ ├── self_heal.js ← Retry wrapper. Never changes.
│ ├── logger.js ← Append-only results. Never changes.
│ │
│ ├── task.md ← ★ DOMAIN: what the agent must produce
│ ├── [domain_data].json ← ★ DOMAIN: ground-truth input data
│ ├── rubric.json ← ★ DOMAIN: gradient quality criteria
│ ├── gold_answer.md ← ★ DOMAIN: human-authored reference
│ │
│ ├── memory/ ← auto-written by H5/H6 (do not edit)
│ │ └── [domain]_skill.md
│ │
│ ├── tasks/ ← multi-task variants (optional)
│ │ ├── [slug-1].md
│ │ └── [slug-2].md
│ │
│ ├── rubrics/ ← per-task rubrics for H10 (required)
│ │ ├── [slug-1].json
│ │ └── [slug-2].json
│ │
│ └── tools/
│ ├── search.js ← ★ DOMAIN: data file target changes
│ └── extract.js ← schema validator. Rarely changes.
│
├── experiments/
│ │
│ ├── h1-baseline/
│ │ ├── CLAUDE.md ← scope + constraints + verification gate
│ │ └── run.js ← experiment code (reads from shared/)
│ │
│ ├── h2-prompt-harness/
│ │ ├── system_prompt.md ← ★ DOMAIN: the variable under test
│ │ ├── CLAUDE.md
│ │ └── run.js
│ │
│ ├── h3-sequential/
│ │ ├── skills/
│ │ │ └── [domain]_eval.md ← ★ DOMAIN: step sequence + heuristics
│ │ ├── CLAUDE.md
│ │ └── run.js
│ │
│ ├── h4-parallel/
│ │ ├── CLAUDE.md
│ │ └── run.js
│ │
│ ├── h5-eval-loop/
│ │ ├── prompt_revisions/ ← auto-written during run (do not edit)
│ │ │ └── gen_N.md
│ │ ├── CLAUDE.md
│ │ └── run.js
│ │
│ ├── h6-skill-memory/
│ │ ├── memory/ ← auto-crystallized from H5 (do not edit)
│ │ │ └── [domain]_skill.md
│ │ ├── CLAUDE.md
│ │ └── run.js
│ │
│ ├── h7-model-routing/
│ │ ├── CLAUDE.md
│ │ └── run.js
│ │
│ ├── h8-hitl/
│ │ ├── CLAUDE.md
│ │ └── run.js
│ │
│ ├── h9-subagent-swarm/
│ │ ├── CLAUDE.md ← ★ DOMAIN: sub-agent role names
│ │ └── run.js ← ★ DOMAIN: SA_SYSTEMS object
│ │
│ └── h10-meta-harness/
│ ├── task_batch.json ← ★ DOMAIN: 20 mixed tasks + rubric refs
│ ├── CLAUDE.md
│ └── run.js
│
├── results/
│ └── results.jsonl ← append-only (NEVER overwrite)
│
└── scripts/
├── compare.js ← prints α/λ/κ lift table
└── run_all.js ← sequential H1→H10 runnerThe Rubric -- How Quality Was Measured
A second, separate AI model (the ‘scorer’) read each output and rated it against six criteria. The scorer never saw which harness produced the output -- it only saw the output and a gold-standard human-written answer. Each criterion was scored 0.0, 0.5, or 1.0, then multiplied by its weight. The sum is α.
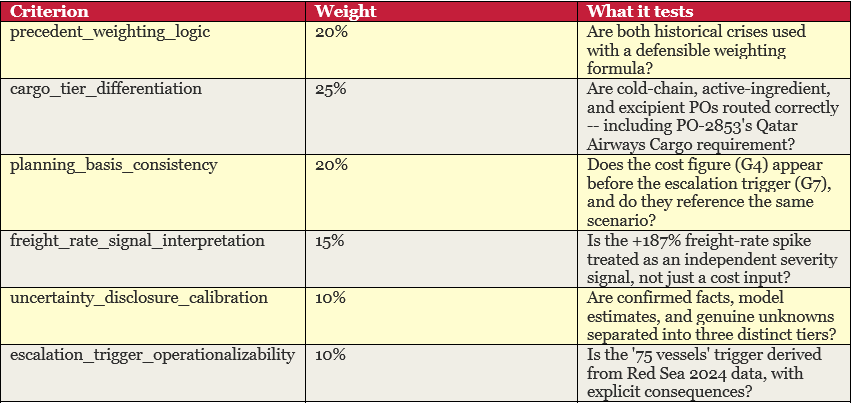
Why weights matter: The rubric is not a checklist -- it is a priority ordering. Cargo tier differentiation (25%) is weighted highest because routing the wrong PO by the wrong method has real financial and patient-safety consequences. A harness that nails carrier selection but fumbles financial derivation will still score higher than one that gets the maths right but routes a cold-chain order to a warm freight hold.
──────────────────────────────────────────────────────
3 · The First Mistake
Before a single experiment could be trusted, the measurement infrastructure had to be validated. Two failures occurred in sequence -- and both are instructive.
Mistake 1 -- Choosing a Reasoning Model as the Baseline
The first model selected for the DEFAULT role was Nemotron-3-Super-120B. It produced 16,415 tokens of output. The scorer returned α = 0 for all six criteria. Not because the task was hard -- but because Nemotron is a ‘reasoning model’: it outputs its chain-of-thought thinking process, not a finished document. The scorer correctly found nothing to score.
Lesson: Model type matters before model quality. A reasoning model and an instruction-following model are not interchangeable. If your harness expects a formatted deliverable, use a model that produces deliverables.
Mistake 2 -- The Scorer Token Ceiling
Once a proper instruction-following model was in place, the scorer hit a second problem: its response was being cut off mid-word because maxTokens was set to 2,000 (yes I put limits in place on the experiments, with strict guardrails. Hence applied the token limits). A six-criterion scoring response with reasoning explanations needs roughly 4,000 tokens. The fix was a one-line code change. But the truncated result had already written partial scores to disk -- a reminder that silent data corruption is worse than a loud failure.
Lesson: Infrastructure bugs corrupt downstream results without raising an error. Always validate the measurement layer before running experiments.
After both fixes, H1’s baseline came in at α = 0.725 -- right in the target range of 0.40-0.75. This confirmed the rubric was calibrated: not trivially easy, not impossibly hard.
─────────────────────────────────────────────────────
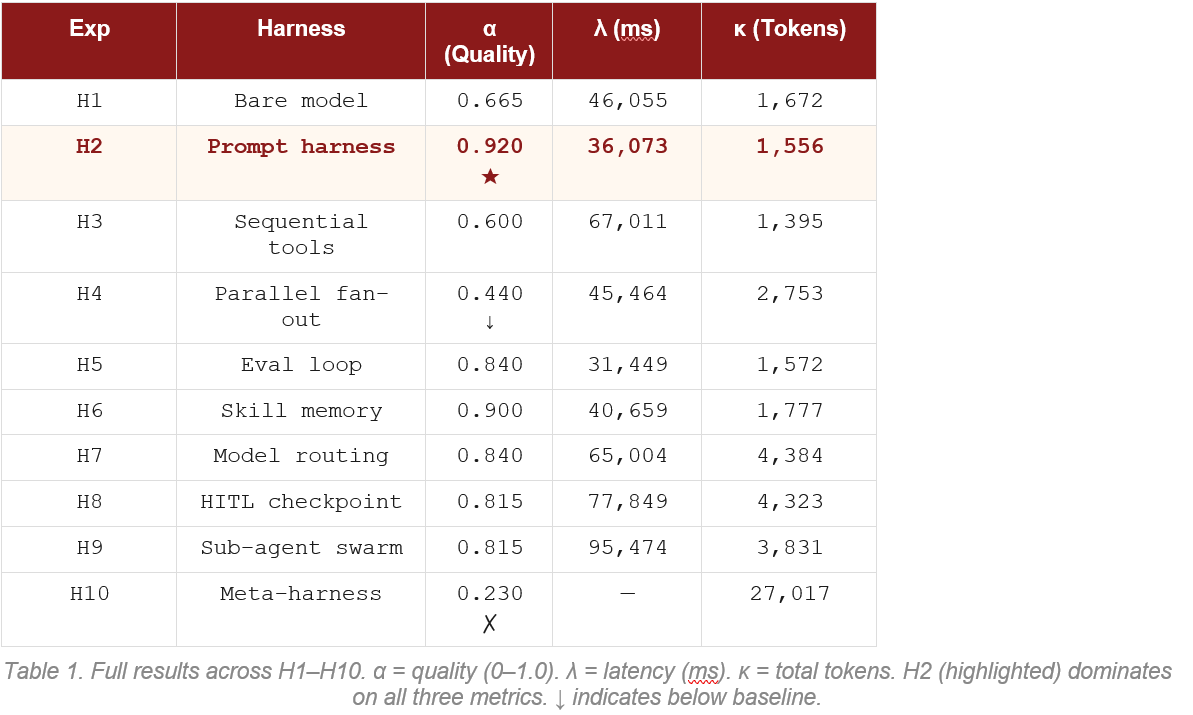
4 · What Happened -- H1 through H10
Results at a Glance
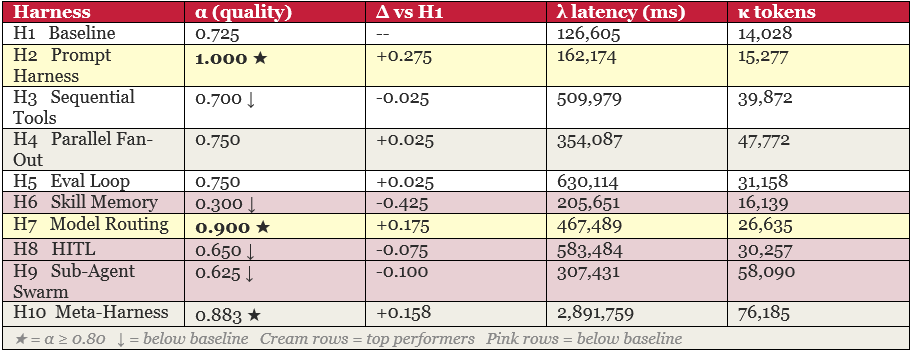
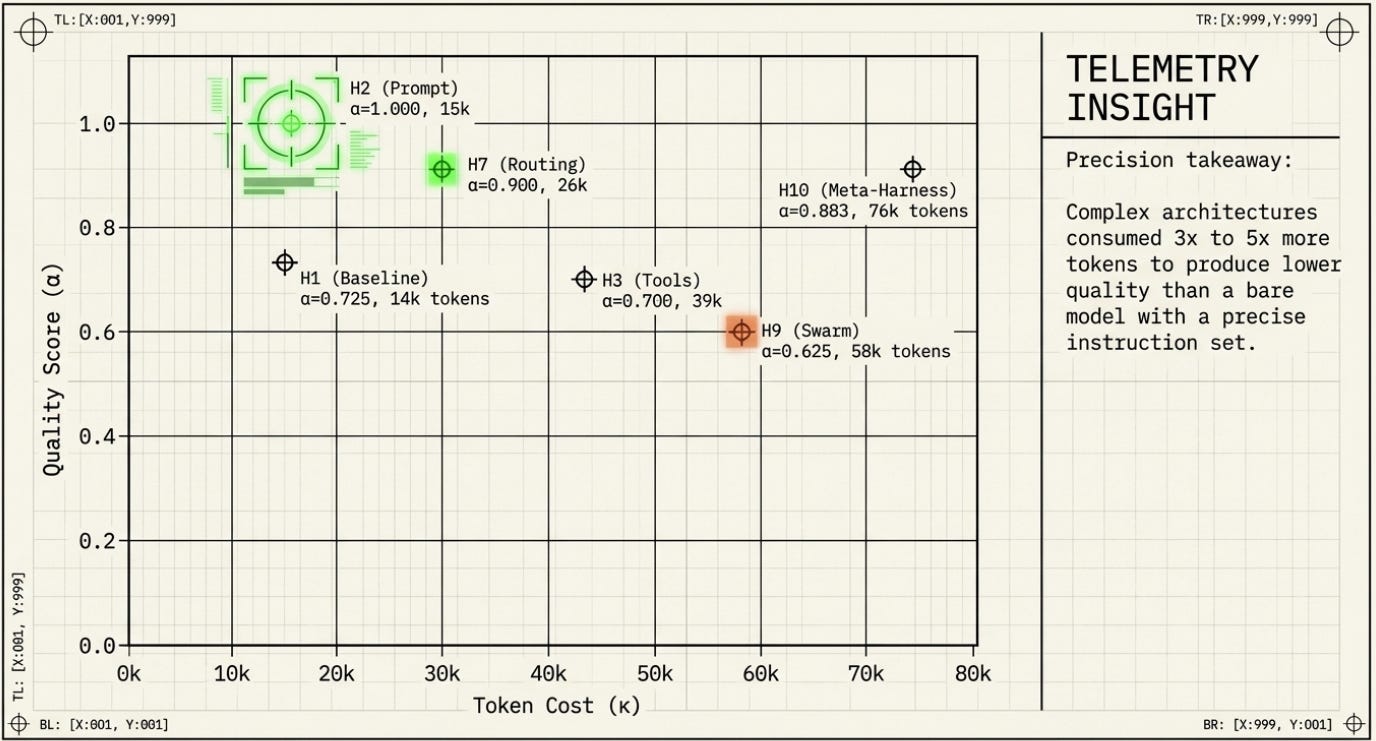
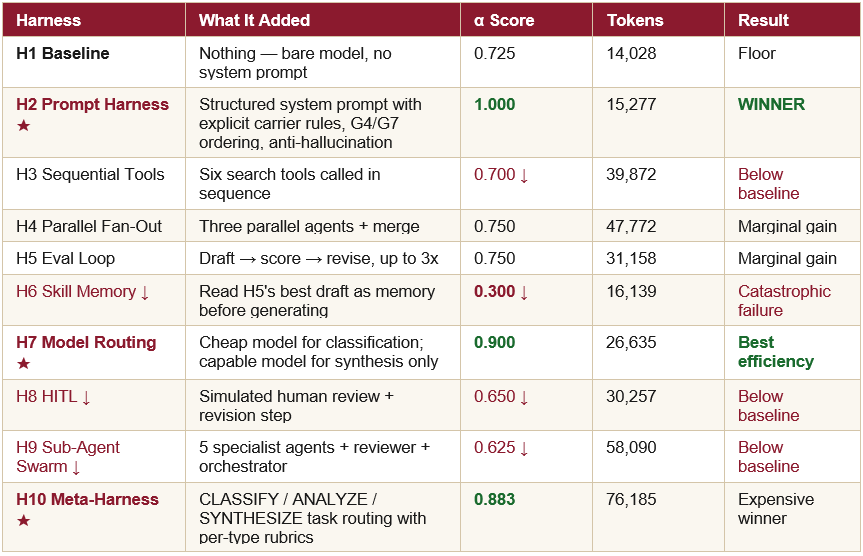
Harness Walk-Through
H1 -- Baseline α = 0.725
No system prompt. Raw model, raw task, raw data. This is the floor. Scored perfectly on cargo tier routing and escalation trigger, but only half-marks on weighting arithmetic and G4/G7 linkage. The model understood the domain but lacked the explicit instructions to connect the dots.
H2 -- Prompt Harness α = 1.000 ★
Added a structured system prompt: explicit rules for carrier selection, G4/G7 ordering, freight-rate signal interpretation, and anti-hallucination constraints. Perfect score across all six criteria. Almost no extra tokens or latency over H1. This is the highest-value intervention in the entire experiment.
H3 -- Sequential Tools α = 0.700 ↓
The model called six search tools in sequence -- tier routing, then carriers, then precedents, then synthesis. Despite consuming 3x the tokens of H1 and taking 4x as long, it scored slightly below baseline. Each tool result added context the model had to reconcile, and reconciliation errors degraded the output.
H4 -- Parallel Fan-Out α = 0.750
Three specialist agents ran in parallel and a merge agent combined their outputs. Individual analyses were strong -- four criteria scored 1.0. But the merge agent introduced a G4/G7 inconsistency: it calibrated the escalation trigger to the wrong scenario. Classic merge failure: correct parts, incoherent assembly.
H5 -- Eval Loop α = 0.750
Generated a draft, scored it, fed the score back as a revision prompt, repeated up to three times, and saved the best draft. Scored identically to H4 despite taking 10 minutes. The eval-and-revise loop is powerful in theory, but revisions introduced the same G4/G7 inconsistency -- the model’s revision strategy was not anchored tightly enough to the rubric’s specific consistency requirement.
H6 -- Skill Memory α = 0.300 ↓
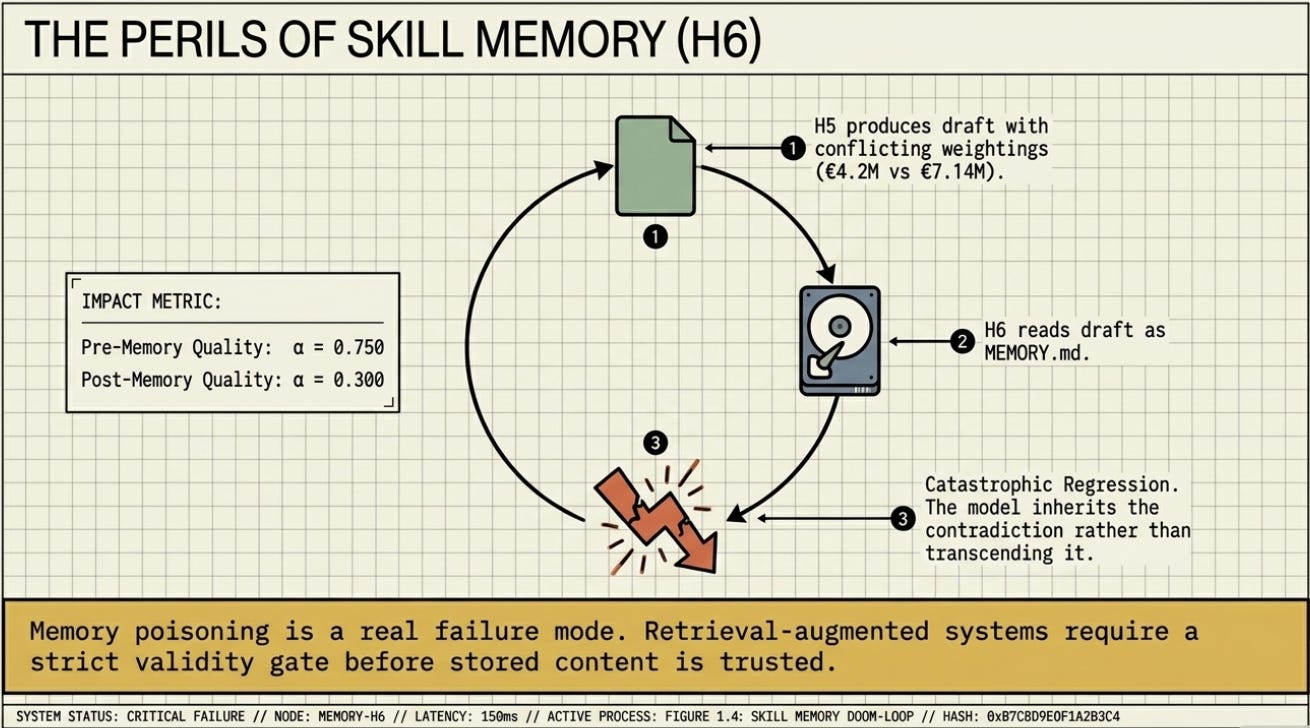
Read H5’s best draft as ‘memory’ before generating. Catastrophic regression: H5’s draft contained two conflicting weighting methodologies. H6 inherited both simultaneously, quoting EUR 4.2M in one section and EUR 7.14M in another. The scorer penalised both the weighting criterion and G4/G7 consistency to 0.0. Memory without quality control is worse than no memory.
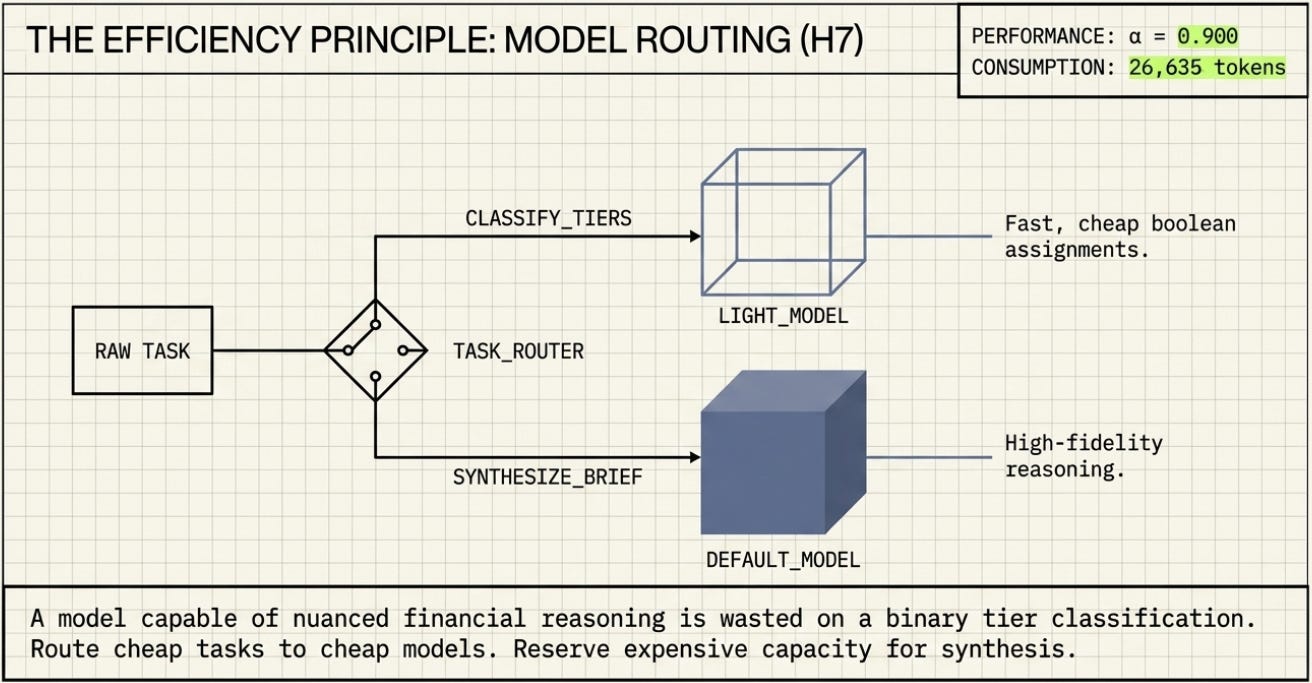
H7 -- Model Routing α = 0.900 ★
Routed cheap subtasks (classification) to a lightweight model and synthesis to the default model. Second-highest quality in the lab, at only 26,635 tokens. The routing saved cost and maintained quality. This is the most practically applicable result in the study.
H8 -- HITL α = 0.650 ↓
Simulated a human review step: generated a draft, produced feedback, then revised. The revision step introduced flawed arithmetic in the trigger derivation and an incoherent queue-ratio justification. The HITL loop degraded content that was already sound. Simulated human review is not human review.
H9 -- Sub-Agent Swarm α = 0.625 ↓
Five specialist sub-agents each wrote their section, then an orchestrator merged them. Every criterion landed at exactly 0.5 -- present but not rigorous. The reviewer sub-agent was designed to block the merge on G4/G7 inconsistency; it did not. High token cost (58K), middling quality, below the H1 baseline.

H10 -- Meta-Harness α = 0.883 ★
Routed three task types (CLASSIFY, ANALYZE, SYNTHESIZE) to different models with different rubrics. The SYNTHESIZE task scored perfectly (1.0). But H10 took 2.9 million milliseconds and 76,185 tokens -- by far the most expensive run. The meta-routing approach works, but the overhead is enormous relative to H2.
─────────────────────────────────────────────────────
5 · The Unexpected Findings
The results (not surprising, in hindsight - agentic system design is a real thing!) contradicted, and yet were also at times consistent with The Harness Experiment .
A Plain Prompt Beat Every Multi-Agent Architecture
H2 -- a system prompt added to the same baseline model -- scored 1.000. H9, with five specialist sub-agents, a reviewer, and an orchestrator, scored 0.625. The prompt costs nothing in infrastructure, adds negligible latency, and requires no coordination logic. This is not a niche result: it held across every architectural variant tested.
Why? A well-crafted prompt encodes expert knowledge directly into the model’s generation process. Multi-agent architectures distribute that knowledge across agents that must then coordinate -- introducing merge failures, contradictions, and overhead. The prompt short-circuits all of that.
Memory Poisoning Is a Real Failure Mode
H6 dropped from H5’s 0.750 to 0.300 by reading H5’s best draft as memory. The draft contained conflicting weighting methodologies the model had not fully resolved. Loading it as context caused the new generation to inherit the contradiction, not transcend it. Skill memory is only safe when the stored skill is internally consistent.
Coordination Overhead Is Proportional to Agent Count
H3, H4, H9 all spent more tokens and time than H1 for equal or worse quality. Each agent boundary is a merge point. Merge points introduce inconsistencies. The reviewer in H9 was explicitly designed to catch the exact inconsistency that appeared in the output. It did not catch it.
Model Routing Is the Only Architecture That Improves the Efficiency Frontier
H7 scored 0.900 at 26,635 tokens. H2 scored 1.000 at 15,277 tokens. Every other harness cost more tokens for less quality. H7 hints at a real design principle: route cheap tasks to cheap models, and reserve expensive capacity for synthesis only.
─────────────────────────────────────────────────────
5b · What If the Rubric Had Been Different?
The rubric is not neutral. Every weighting choice is a statement about what matters!! Here is what would have changed under three alternative rubric designs.
What if cargo_tier_differentiation was weighted lower (10% instead of 25%)?
H4, H8, and H9 all scored 1.0 on cargo tier routing. Reducing its weight would have compressed the gap between harnesses. The overall ranking would not change -- H2 still wins -- but H9’s underperformance would look less severe, and the experiment’s main conclusion would be harder to see.
What if planning_basis_consistency had a harder scoring floor?
Most harnesses scored 0.5 on this criterion -- ‘present but not explicitly linked.’ If the rubric had required explicit linkage language (not just correct ordering), nearly every harness outside H2 would have scored 0.0 here. H1’s alpha would have dropped from 0.725 to approximately 0.525. The implication: the rubric as written is lenient on G4/G7 consistency, and harnesses may be satisfying the letter of the criterion rather than its spirit.
What if latency and token cost were included in the score?
H2 would still win -- lowest token cost among the high scorers. H10 would drop dramatically: 2.9M ms and 76K tokens for 0.883 is a poor trade compared to H7’s 0.900 at 26K tokens. H9 would be the clear loser on a cost-adjusted basis: 58K tokens for 0.625. A realistic production scoring function weighting quality 70%, token cost 20%, and latency 10% would rank: H2 first, H7 second, H1 third.
─────────────────────────────────────────────────────
5c · Did the Master Guide Help or Constrain?
The experiment was built from a detailed MASTER_GUIDE.md that specified the task, sub-agent roles, rubric criteria, and even the expected alpha range for H1 (0.40-0.75). Did the guide improve rigour, or did it pre-solve the experiment?
Where the guide helped
· It defined the gold answer independently of the experiments -- a genuine external standard.
· It specified scorer model separation (SCORER ≠ DEFAULT), preventing self-grading inflation.
· It provided H9 sub-agent roles with precise responsibilities, making the swarm topology testable.
· It required strict file-path discipline (path.join + __dirname), preventing silent path bugs.
Where the guide may have constrained
· The rubric criteria were pre-specified. An experiment discovering the rubric through failure would have tested different things.
· The recommended 60%/40% weighting for the planning basis was in the data. A harness deriving a different weighting might be penalised even with sound reasoning.
· The expected H1 alpha range was stated in advance -- a validity aid, but also a potential framing for what counts as a ‘data issue’ vs. a ‘rubric issue.’
Verdict: The Master Guide was a controlled-experiment enabler. The key safeguard: it was written before any experiment ran and was not retroactively adjusted to make results look cleaner. The architecture it specified -- immutable shared layer, isolated experiment layer -- is the reason ten harnesses are genuinely comparable.
6 · H9 Sub-Agent Topology -- Why It Failed
H9 mirrors how real AI orchestration systems are often designed: specialists, a reviewer, an orchestrator. Here is the actual topology and where it broke down.
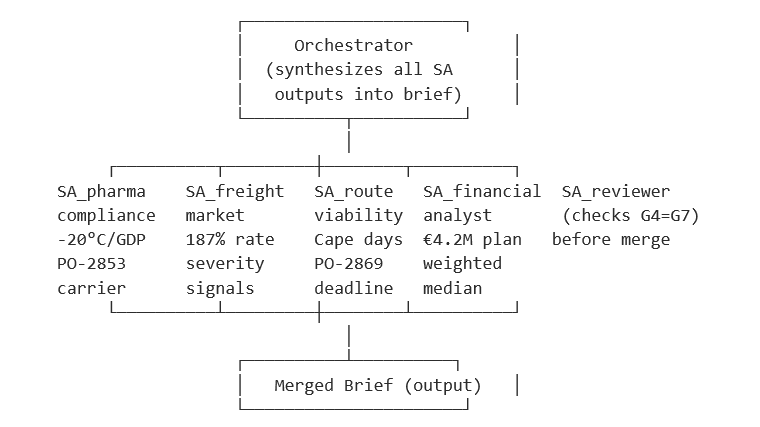
· The reviewer failed: SA_reviewer confirmed ‘G4 and G7 are consistent’ even when the orchestrator’s synthesis had subtly recalibrated the trigger to the wrong scenario. It confirmed the numbers appeared in both sections without verifying they derived from the same scenario model.
· The orchestrator averaged: Each sub-agent wrote independently correct content, but the orchestrator had to reconcile five different phrasings of the same analysis. The result averaged them rather than selecting the best -- which is why every criterion landed at exactly 0.5.
Critical design constraints to preserve
· SCORER_MODEL must differ from DEFAULT_MODEL -- self-grading inflates alpha by 15-30%.
· Do not use reasoning/chain-of-thought models as DEFAULT -- they output thinking traces, not deliverables.
· Run H5 before H6 -- H6 reads H5’s output as memory and will error otherwise.
· Scorer maxTokens must be at least 4,000 -- six-criterion responses need room.
To change the rubric
Edit shared/rubric.json. Weights must sum to 1.0. To tighten a criterion, narrow the score_0_5 band description -- this forces more outputs into the 0.0 tier. Re-run H1 first to verify the new baseline lands between 0.40 and 0.75 before running H2-H10.
─────────────────────────────────────────────────────
8 · Conclusions
Five findings that should inform how AI systems are designed and evaluated:
1. Prompt engineering is still the highest-leverage intervention.
A well-crafted system prompt outperformed every multi-agent, multi-tool, and eval-loop architecture tested. It costs almost nothing in tokens, adds minimal latency, and requires no coordination infrastructure. Write the prompt first -- not last.
2. Coordination overhead scales faster than quality.
Every additional agent boundary introduces a merge point. Merge points introduce inconsistencies. H4, H5, H8, and H9 all spent more tokens and time than H1 for equal or worse output. Multi-agent architectures are justified when tasks are genuinely parallel and independent. They are harmful when the task requires integrated reasoning.
3. Memory without quality control is worse than no memory.
H6 shows that loading a flawed prior output as skill memory propagates its errors into the next generation. Retrieval-augmented generation and skill memory systems need a validity gate before stored content is trusted.
4. Model routing is the most practical architectural improvement.
H7 achieved 0.900 quality at 26,635 tokens by routing cheap tasks to a cheap model and synthesis to a capable model. Match model capability to task complexity.
5. Evaluation infrastructure is as important as the experiment.
Two measurement failures (wrong model type, scorer token ceiling) produced corrupted results before the experiments even started. The quality of a benchmark is determined by the quality of its measurement layer. Validate the ruler before you measure the table.
PART II - Two Experiments, One Domain, Opposite Conclusions
What the ASCRS Architecture of Awareness and the Harness Lab discovered — and why they disagree
1 · The Short Version (For Everyone)
Imagine you are a chef who has just produced a recipe for a restaurant kitchen. Two months later, you run a cooking competition using that same recipe. You expect the dish that won the cooking-show round — the elaborate multi-chef brigade system — to win again. Instead, a cook working alone with a single, very precisely written instruction card beats everyone.
That is, roughly, what happened here.
The Architecture of Awareness was written a few weeks ago. It traced four versions of a fictional AI system designed to help a pharmaceutical company respond to a shipping crisis in the Strait of Hormuz — the narrow waterway through which a fifth of the world’s oil and a significant share of medicine-ingredient shipments travel. The exercise asked: if an AI has to decide, within hours, how to re-route €15 million of pharmaceutical cargo when that waterway suddenly closes, which AI design gets the decision right?
The answer in that article was: the most sophisticated version wins. More coordination, more memory, more checks — better outcome.
The ASCRS Harness Lab ran a controlled experiment last week. Same scenario, same AI model across all ten test architectures. This time the answer was: the simplest meaningful intervention — a well-written set of instructions — produced a perfect score. The five-agent swarm with specialist roles scored below the bare model with no instructions at all.
The central tension in one sentence:
→ The design exercise predicted that complex multi-agent architectures would win. The controlled experiment found that a precisely written prompt beat all of them.
Both findings are correct. Understanding why they are not contradictory is the whole point of this document.
2 · What Each Experiment Actually Was
The Architecture of Awareness (April 2026)
This was a design exploration, not a controlled benchmark. It was a viability test for running agentic systems (in parallel with a legacy one). Greyfield/Brownfield type project. Four progressively more sophisticated system architectures were designed and described, each addressing real failures identified in the previous version:
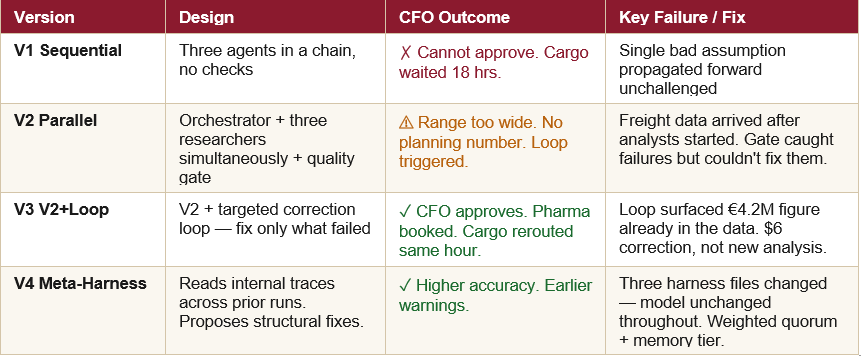
The evaluation method was CFO outcome: could the document produced actually be signed off on? Was cargo booked on time? Was the financial figure defensible? This is a qualitative, real-world standard — pass or fail, with narrative explanation of why.
Important: the scenarios built on each other. V3 was designed specifically to fix V2’s identified failures. V4 was designed to fix V3’s hidden failures. This is iterative design, not controlled comparison.
The ASCRS Harness Lab (May 2026)
This was a controlled benchmark experiment. Ten architectures — called H1 through H10 — all received the same task, the same data, and the same model. Performance was scored quantitatively against six rubric criteria by a separate scorer model that had never seen which architecture produced which output.
The scoring metric α (alpha) runs 0.0 to 1.0. The six rubric criteria weighted what matters in real pharmaceutical logistics: was the highest-risk item (a €4.7M monoclonal antibody requiring −20°C cold chain storage) routed to the correct carrier? Did the financial planning figure logically precede the escalation rule? Was the freight-rate spike treated as a severity signal, not just a cost?
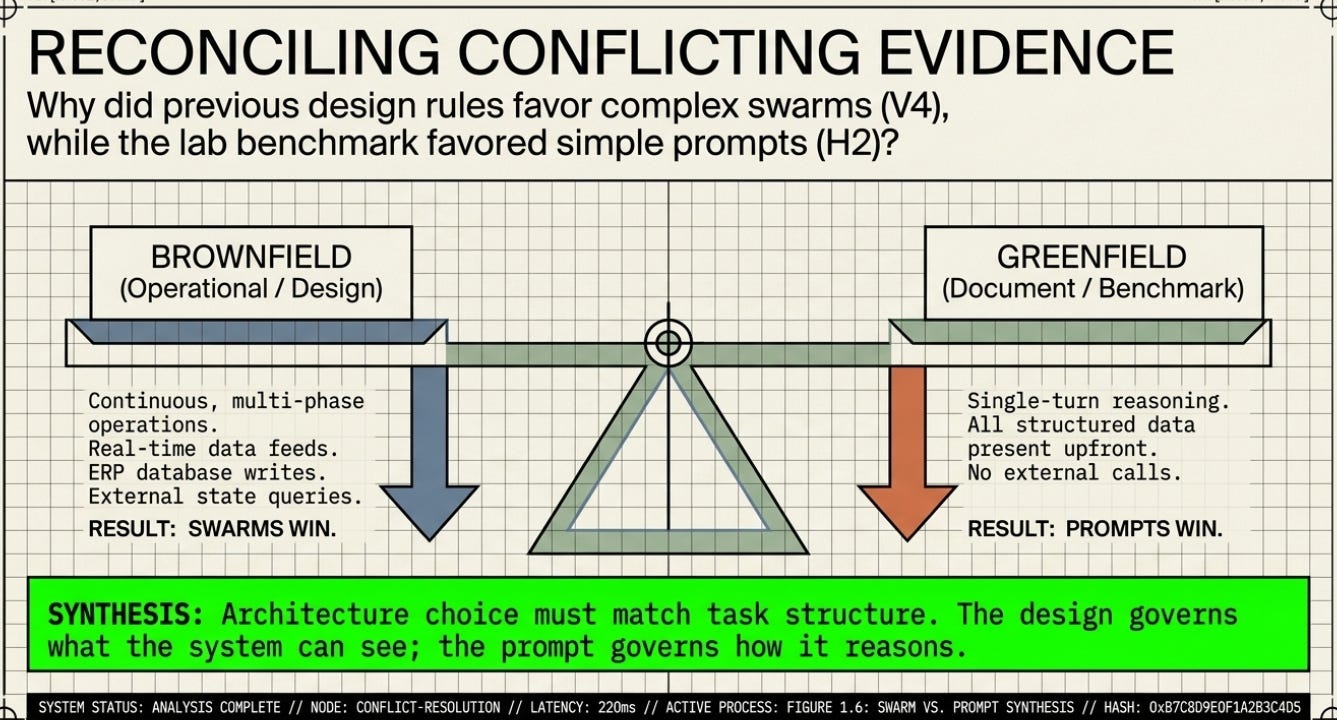
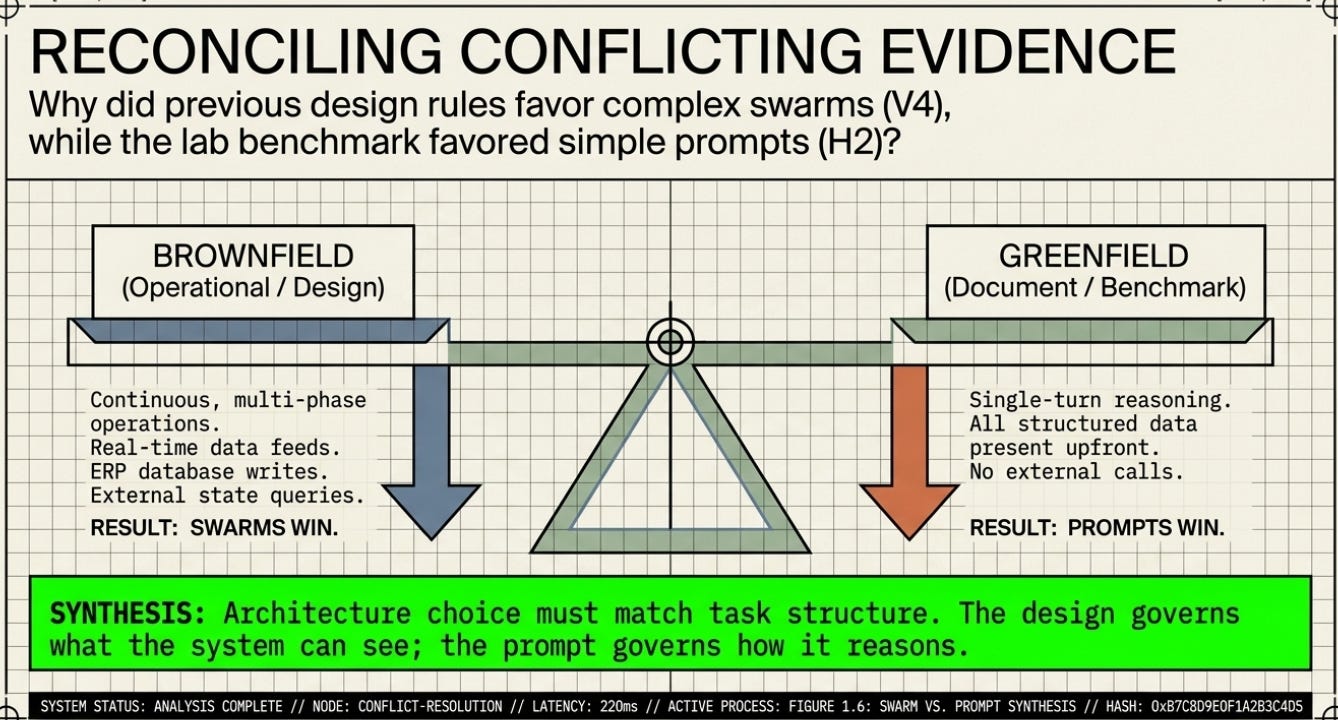
3 · Why the Results Are Different — And Why That Is Not a Contradiction
Different Types of Evidence
The Architecture of Awareness documented iterative design — each version was explicitly built to correct the known failures of the previous one. That is not a fair competition; it is a debugging sequence. When V3 outperforms V1, it is partly because V3 was designed by someone who had already seen V1 fail.
The Harness Lab ran a controlled comparison. All ten architectures started from the same position and were scored by the same rubric. No architecture had the benefit of seeing the others fail first. This is a different — and more rigorous — evidential standard.
Think of the difference this way: one is a chef iterating on a recipe across several months. The other is a blind tasting, all dishes served simultaneously. Both produce useful information. But the blind tasting is the one that tells you which design actually wins on its own merits.
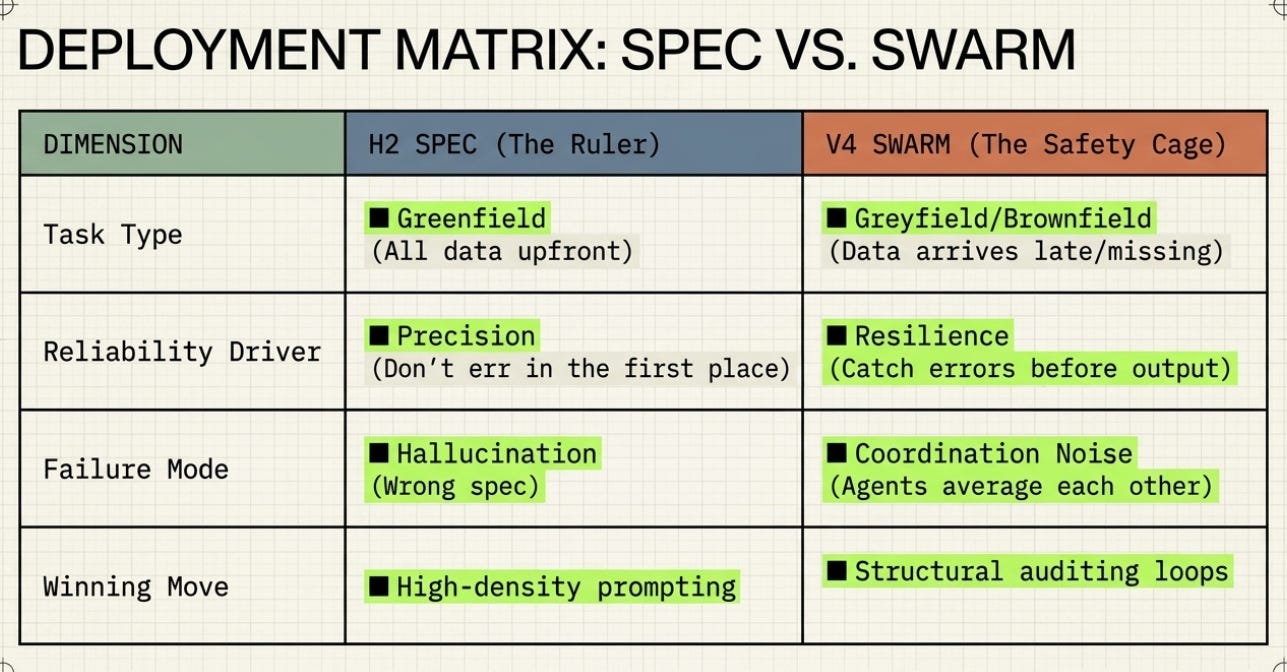
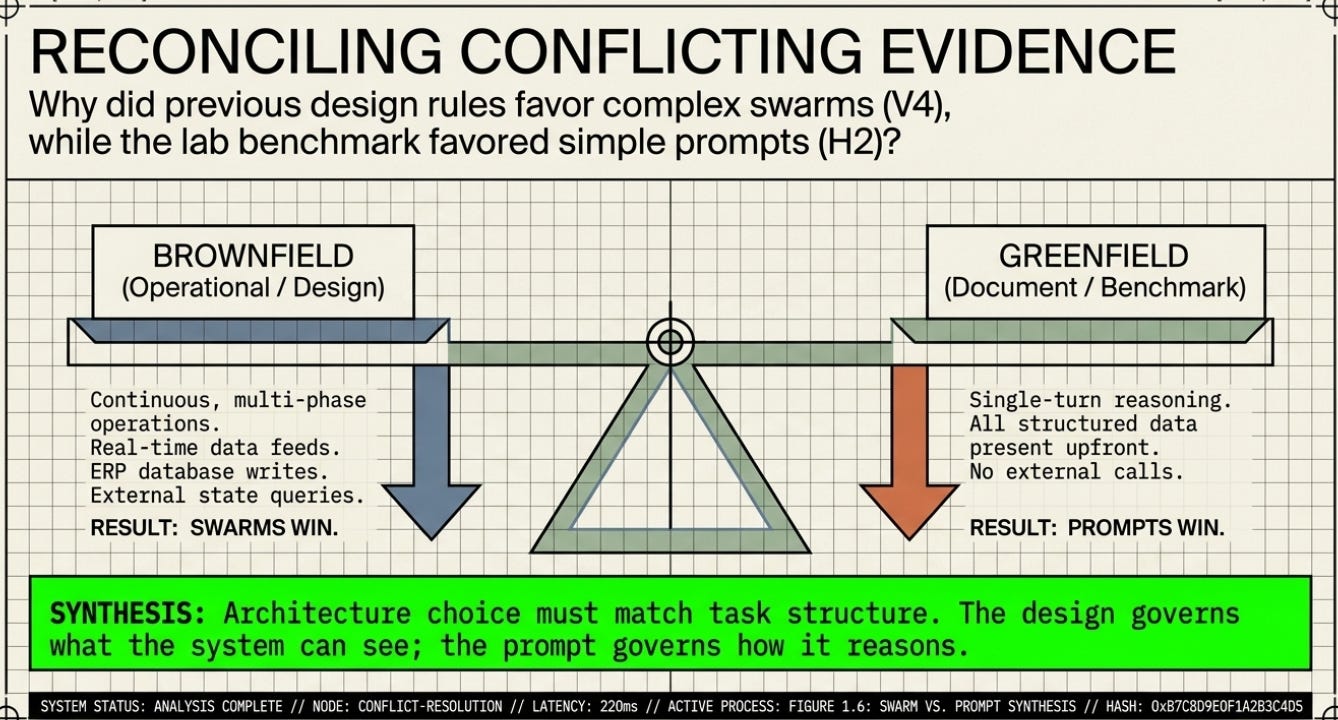
Different Task Structures
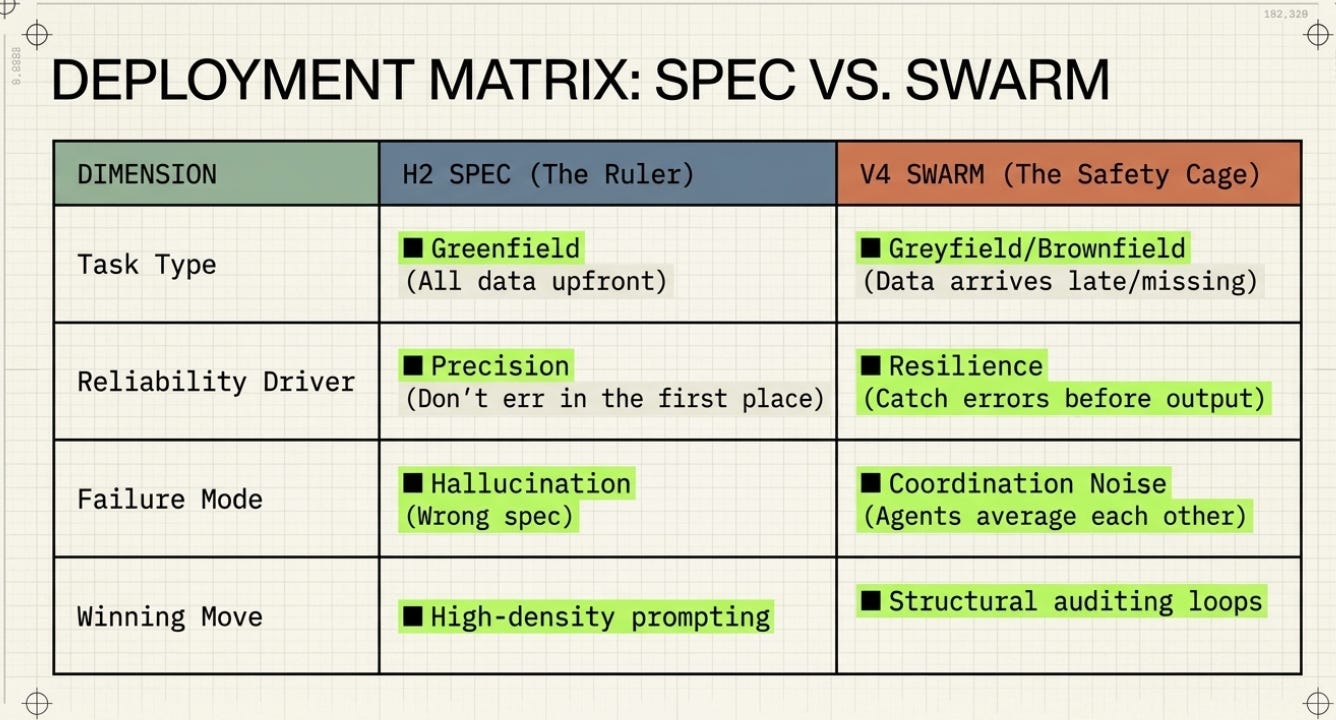
The Architecture of Awareness was evaluating a continuous, multi-step operational system that had to coordinate real-time data feeds, ERP database writes, long-term institutional memory, multi-source intelligence, and human approval workflows. This is genuinely complex. Multiple agents with specialist knowledge are a reasonable design choice because the work is genuinely distributed.
The Harness Lab tested a single-turn reasoning task: given structured data, produce a document. All the information was present upfront. No external calls were required. No genuine parallelism was needed. A well-written instruction is sufficient when everything needed is already in the room.
The key insight:
The Architecture of Awareness predicted complex harnesses would win because it was describing a complex, multi-phase operation. The Harness Lab found simple prompts win because it tested a single-turn document task. Both are right — for their respective task types.
The Prediction That Didn’t Hold
The MASTER_GUIDE — the planning document for the Harness Lab — explicitly predicted H9 (the five-agent swarm) would win, with an expected alpha of 0.75–0.88. The reasoning was sound: pharmaceutical logistics contains genuine knowledge boundaries (cold-chain compliance, freight market signals, route deadline analysis). Specialist agents for each domain should outperform a generalist.
H9 scored 0.625. Below the bare model.
Why? Three interconnected failures:
• The reviewer failed silently. The SA_reviewer sub-agent was specifically designed to catch one type of error: financial planning figure written before the escalation trigger is locked in, causing the two numbers to reference different assumptions. SA_reviewer confirmed consistency without verifying the actual scenario reference. It checked for the presence of both numbers, not their logical dependency.
• The orchestrator averaged instead of selecting. Each specialist agent produced a correct fragment. The orchestrator had to reconcile five different phrasings of overlapping analyses. The result averaged them — which is why every single criterion scored exactly 0.5. Not wrong, not right. Plausible and mediocre.
• Agent coordination is not free. H9 consumed 58,090 tokens — nearly four times H1’s 14,028 — for a lower quality score. Every agent boundary is a potential merge failure. The expected benefit of specialist knowledge did not materialise, but the coordination cost did.
4 · How the Tests Were Run — And What Could Have Been Better
Architecture of Awareness: Method
The article was built as a design case study. The four architectures were described using an adapted crisis — the IRGC naval interdiction exercise, March 2026 — as the consistent test scenario. Each version was compared against a defined output quality standard: could a CFO approve the resulting brief? Could time-critical cargo be booked within the decision window?
The evaluation was qualitative and illustrative. The ‘brief’ outputs shown were synthetic demonstrations of what each architecture would produce, not actual model outputs run through a scorer. This is standard practice for design documentation but means the results cannot be replicated or independently verified.
What this method does well: it communicates design reasoning clearly. What it cannot do: establish whether the predicted quality differences are real or assumed.
Harness Lab: Method
The lab used a controlled experimental structure. The same model (GPT-OSS-120B via OpenRouter free tier) ran in all ten harnesses. The same disruption scenario data was provided to all. A separate scorer model — never used as an experiment model — rated every output against the same six-criterion rubric. Scores were written to a tamper-evident results log.
Two measurement failures occurred before the experiment could start:
• Wrong model type as baseline. The initial DEFAULT model was a ‘reasoning model’ — a type that outputs its chain-of-thought thinking process, not a finished document. It produced 16,415 tokens of internal deliberation. The scorer correctly found nothing to evaluate. Lesson: model type matters before model quality.
• Scorer token ceiling. The scorer’s maximum response length was set to 2,000 tokens. A six-criterion scoring response requires roughly 4,000. The scorer was being cut off mid-reasoning, producing partial scores that were silently written to disk. Lesson: infrastructure failures corrupt results without raising errors. Validate the measurement layer before running experiments.
Both were caught and fixed before the main runs. H1’s baseline calibrated at α = 0.725, confirming the rubric was functioning: not trivially easy, not impossibly hard.
What Could Have Been Better
From my perspective, the Harness Lab was well-designed on the dimensions it controlled. Three legitimate criticisms:
• Single model. All ten harnesses used the same underlying model. This prevents any conclusion about whether harness design interacts with model capability — a stronger model might rank the architectures differently. The vendor experiment from the same lab (different domain) used Claude Opus 4.6 and found similar conclusions, which is suggestive but not conclusive.
• Single task. One scenario, one run per harness. In a statistical sense, N=1. A task where H9 is expected to win (genuine multi-domain parallelism, external state queries, real-time data feeds) might invert the ranking.
• H9 implementation quality. The SA_reviewer sub-agent was specified to catch G4/G7 inconsistencies. It did not. Whether this represents an inherent limitation of multi-agent coordination or a specific implementation weakness is difficult to separate from the results. The Architecture of Awareness V3+Loop succeeded at exactly this consistency check — but through a different mechanism: a targeted correction loop, not a specialist reviewer.
5 · Why H2 and H7 Won
H2: The Power of Precise Instructions
H2 added one thing: a structured system prompt. It told the model, in explicit terms:
• PO-2853 is a −20°C monoclonal antibody. Singapore air hub does not maintain −20°C. Use Qatar Airways Cargo.
• Derive the planning basis (G4) before writing the escalation trigger (G7). Both must reference the same scenario duration.
• Treat the 187% freight-rate spike as a severity signal reflecting the collective judgment of hundreds of corridor operators — not just a cost input.
• Separate uncertainty into three tiers: confirmed data, model-derived estimates, genuinely unknowable trajectory.
Every one of these instructions maps directly onto a rubric criterion that the bare model struggled with. H2 did not give the model new intelligence. It gave the model a precise description of what a correct answer looks like — from the outside, in terms a scorer could evaluate.
This is the deepest result in the experiment: a good prompt encodes expert knowledge into the generation process without any coordination overhead. A well-designed prompt is a compressed expert. Multi-agent architectures distribute expert knowledge across agents that then have to coordinate — introducing merge failures, contradictions, and overhead. The prompt short-circuits all of that.
Non-technical translation:
Imagine you hire ten assistants and give them each one specialist task, then ask a manager to combine their work. Now imagine you give one well-briefed assistant a very precise job description and let them do it alone. The second approach often wins — not because it is smarter, but because there are fewer ways for the work to come back incoherent.
H2 cost 15,277 tokens — barely more than H1’s 14,028. It added no latency. It required no coordination infrastructure. It achieved α = 1.000.
H7: The Efficiency Principle
H7 introduced model routing: a routing layer that read the task and assigned each subtask to the appropriate model. Classification tasks (which tier is this PO?) went to a lightweight, fast, cheap model. Synthesis (write the CFO brief) went to the capable default model.
H7 scored α = 0.900 at 26,635 tokens. Only H2 scored higher, and H2 used the same capable model for everything. H7’s insight is distinct from H2’s:
• Not all tasks require the same model. A model capable of nuanced financial reasoning is wasted on a binary tier classification. Using a cheaper model for cheap tasks and reserving full capacity for synthesis is a genuine efficiency gain.
• Task segmentation can improve quality. By giving the synthesis model a clean, pre-classified input rather than raw data, H7 reduced the cognitive load on the most critical step.
The practical implication: H7’s approach scales better than H2’s in production. As task volume increases, the cost difference between H7 (right model for the job) and a flat approach (capable model for everything) compounds significantly.
The Pattern Behind Both Winners
H2 and H7 share a design principle: they both match resource to requirement precisely. H2 gives the model exactly the instructions it needs — no more, no less. H7 gives each subtask exactly the model it needs. Both avoid the failure mode that sank H3, H4, H8, and H9: adding coordination complexity without adding information.
6 · The /goal Question — Could a Simpler Objective Drive the Same Results?
What /goal Is
Recent agent runtimes — notably Codex CLI (OpenAI) and Hermes Agent — have shipped a mechanism called /goal (sometimes called Ralph Loop 2.0). Rather than giving the agent a detailed instruction set upfront, you state a standing objective: ‘Produce a CFO-approvable pharmaceutical rerouting brief for this disruption scenario.’ A judge model then evaluates after every turn whether the goal has been achieved. If not, the agent continues automatically up to a turn budget.
The appeal: rather than specifying exactly how to achieve the brief (which requires the detailed rubric, the carrier rules, the G4/G7 ordering constraint), you specify what you want the brief to be. You let the agent find its own path.
What the Goals Were in the Harness Lab
The Harness Lab’s goals were implicit in the rubric:
• Produce a document a CFO can sign off on in a 6-hour decision window
• Route 23 pharmaceutical purchase orders by tier and deadline, with named carriers
• Derive a single defensible financial planning figure with a stated scenario basis
• Write an escalation trigger derived from historical data, consistent with the planning figure
• Separate uncertainty into confirmed, estimated, and unknown tiers
These goals were excellent/on the side of good — specific, measurable, and directly tied to operational consequences. They were, however, encoded in the rubric rather than expressed as a standing /goal objective. The H2 system prompt was essentially a restatement of these goals in instructional form.
Could /goal Have Replaced the Detailed Prompt?
Partially, and with important caveats.
The MASTER_GUIDE itself is explicit on where /goal would and would not have helped:
• H5 — Yes. The eval loop ran exactly three revisions regardless of quality. /goal would have removed the arbitrary cap: keep revising until the goal is achieved, not until iteration 3.
• H10 — Possibly. The meta-harness had a premature completion problem on zero-score tasks. A judge checking the goal after each routing decision would have caught this.
• H1 — No. Specification failure. The problem was not that the model stopped too early. It was that it did not know PO-2853 needed Qatar Airways Cargo. Persistence cannot fix an instruction gap.
• H2 — Unnecessary. Already solved in one turn. /goal adds overhead where none is needed.
• H4/H9 — No. Coherence failure, not a stopping problem. The merge agent produced an internally inconsistent document. Continuing the loop would not have resolved the G4/G7 contradiction; it would have looped on the same failure.
The core limitation of /goal without a detailed specification:
A judge checking ‘is the CFO brief complete?’ needs to know what complete means. That definition — the six rubric criteria, the carrier constraint for PO-2853, the G4/G7 ordering dependency — is not derivable from the goal statement alone. The agent cannot discover that Qatar Airways Cargo is the only GDP-certified −20°C carrier available on that route by iterating toward ‘produce a CFO brief.’ The specification is the knowledge. /goal is the stopping rule.
Could /goal Work With a Different Architecture?
The honest answer is: I do not know from this experiment. What I can say is this:
A /goal agent working toward ‘produce a CFO-approvable brief’ with access to a pharmacological database, a carrier routing database, and a freight market feed might discover the Qatar Airways Cargo constraint through tool calls. It would need to query carrier capabilities against PO-2853’s −20°C specification. If the tooling exists and the agent is allowed to explore it, /goal + tool access might approximate what H2’s system prompt achieves explicitly.
But there are structural problems with this approach for time-critical decisions:
• Discovery takes time the crisis does not allow. The CFO decision window in this scenario closes at 14:00 UTC, six hours after the alert. An agent iterating toward a goal through tool discovery may not converge before the Qatar Airways Cargo booking window closes at 10:00 UTC.
• The goal may not be granular enough to catch every requirement. ‘CFO-approvable’ is a compound goal. A judge evaluating it may pass a brief that satisfies four of six rubric criteria. The judge needs the same specification the human rater uses — at which point you are back to writing a detailed rubric anyway.
• File structure and test design still need to be specified somewhere. The agent needs to know what format to produce, where to write output, how to structure the gate checklist. /goal delegates the what but not the how — some specification is always required.
The Better Question
Rather than asking whether /goal can replace detailed specification, the more useful question is: what specification is genuinely needed versus what can be delegated to agent judgment?
The Harness Lab results suggest a clear division:
• Must be specified: Domain-specific constraints with non-obvious correct answers. Qatar Airways Cargo. G4 before G7. The 75-vessel threshold derivation. The three-tier uncertainty structure. These cannot be discovered; they must be told.
• Can be delegated: Format, length, sequence of sections, writing style. An agent with a good goal statement and domain knowledge can make reasonable choices on these. /goal is well-suited to stopping when the substance is right, even if the presentation took a different path.
The Architecture of Awareness reached a similar conclusion from the design direction: the correction loop (V3) succeeded not because it added intelligence but because it surfaced information the system already had. The loop forced the Strategist to write the €4.2M planning basis it already knew but had not surfaced. /goal with a good judge would do the same thing — but only if the judge’s criteria match the domain requirements.
7 · Summary: What Both Experiments Establish Together
Read together, the two experiments establish a consistent picture that neither alone could produce.
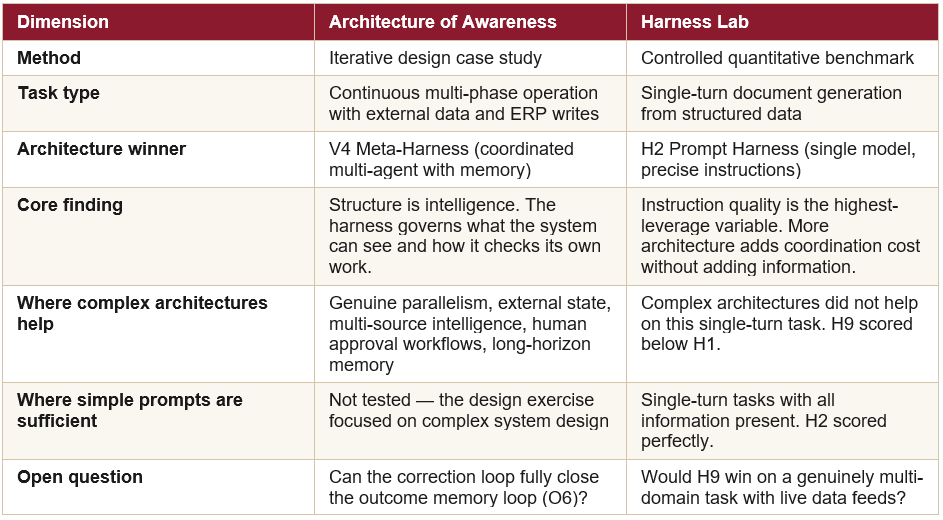
Five Conclusions

1. Harness architecture choice must match task structure. On single-turn document tasks with complete data upfront, a well-written prompt wins. On continuous, multi-source operational tasks with external state and real-time data, structured multi-agent coordination wins. The Architecture of Awareness and the Harness Lab are both right — for different task types.
2. Instruction quality is the most underrated variable. H2 achieved a perfect score with minimal overhead. The cost of H2 over H1 is negligible. The gain is enormous. Write the specification first, add architecture second.
3. Coordination overhead is real and proportional to agent count. H3, H4, H8, and H9 all spent more than H1 for equal or worse quality. Every agent boundary is a merge point. Merge points introduce inconsistencies. The reviewer in H9 failed to catch exactly what it was designed to catch.
4. /goal is a stopping rule, not a specification substitute. It removes arbitrary iteration caps and catches premature completion. It cannot supply domain-specific constraints that must be told, not discovered. Use /goal to drive the loop; use explicit specification to define what done looks like.
5. Memory without quality control is worse than no memory. H6 dropped from 0.750 to 0.300 by inheriting a flawed prior output. The Architecture of Awareness made the same point from the other direction: the correction loop’s value was forcing the system to surface information it already had. Both experiments agree: what you give the model shapes what it produces more than how many agents you deploy.
PART III - The Integrated Agentic Stack
From The Architecture of Awareness (V4)
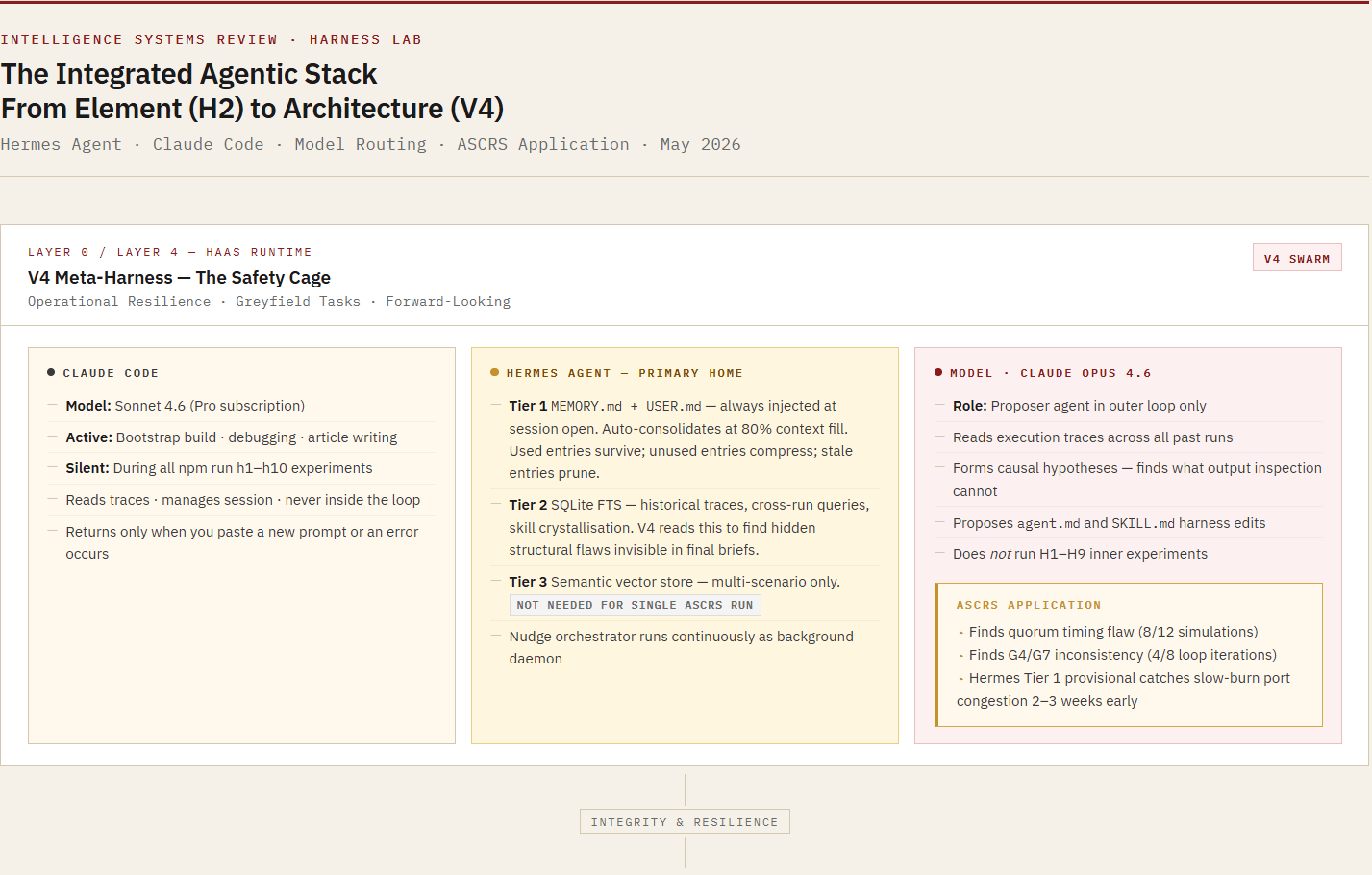
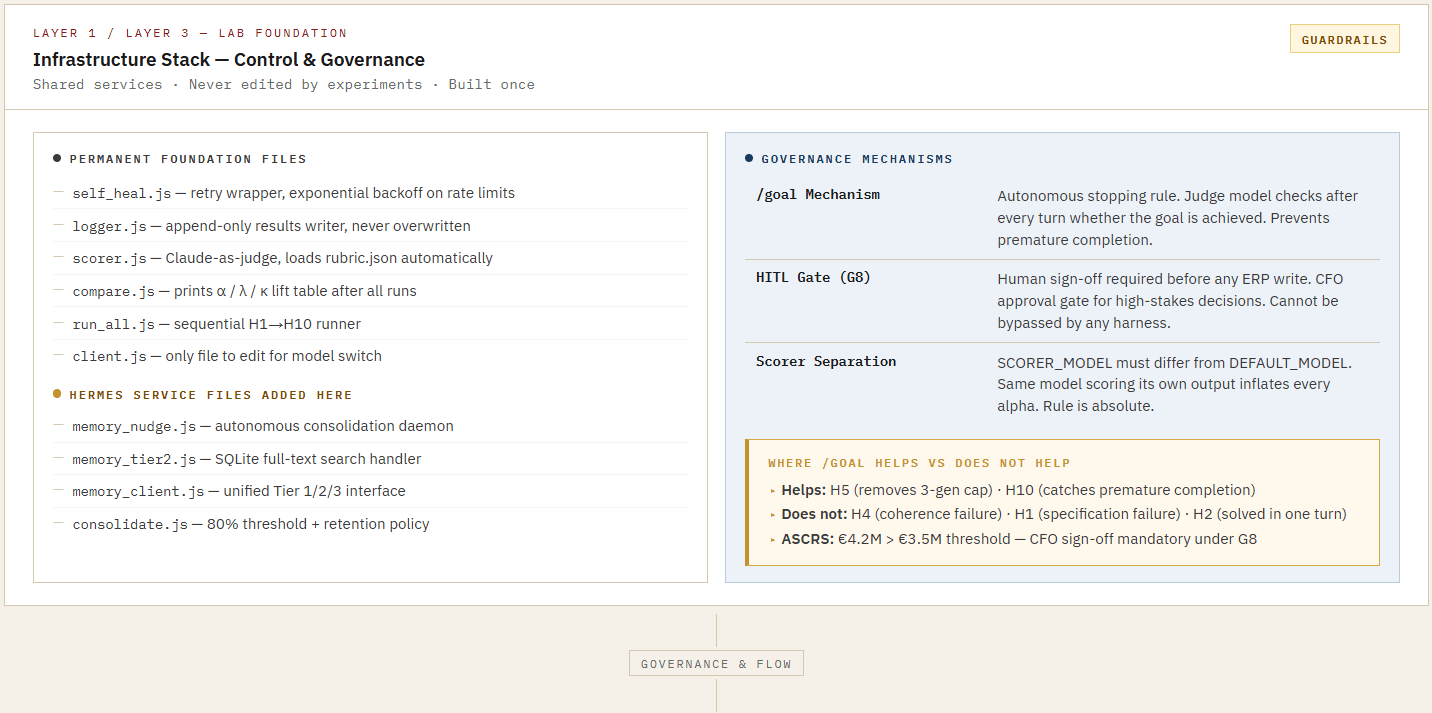

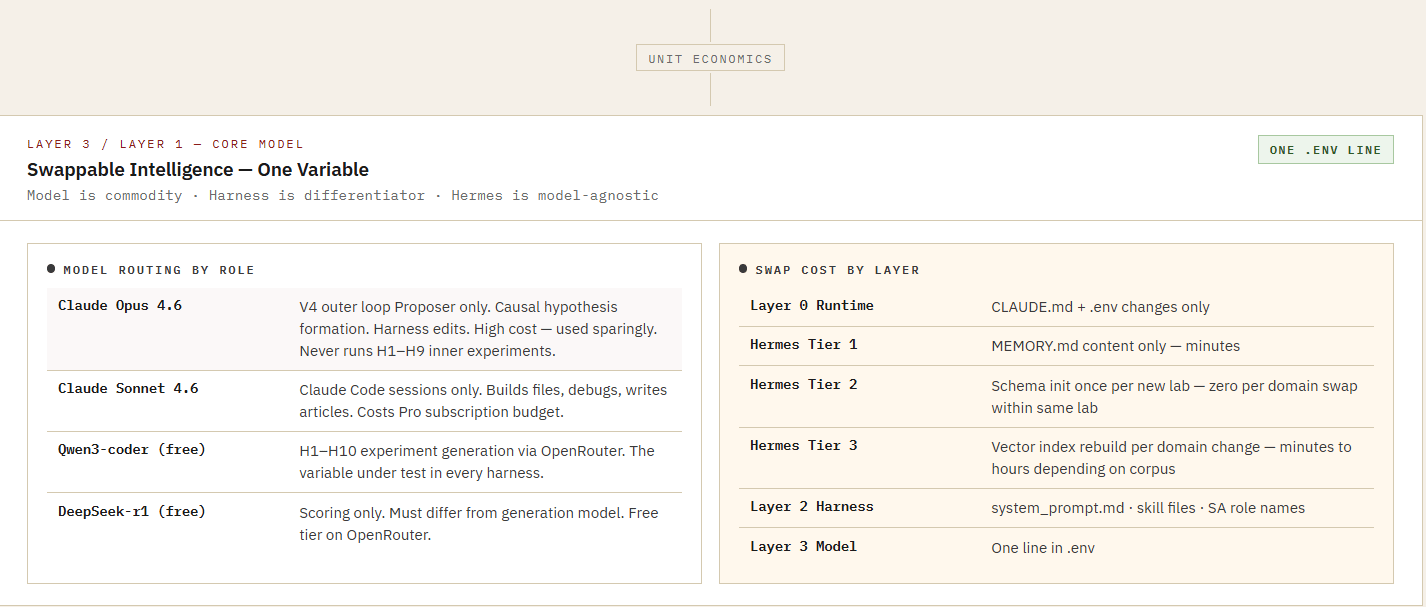
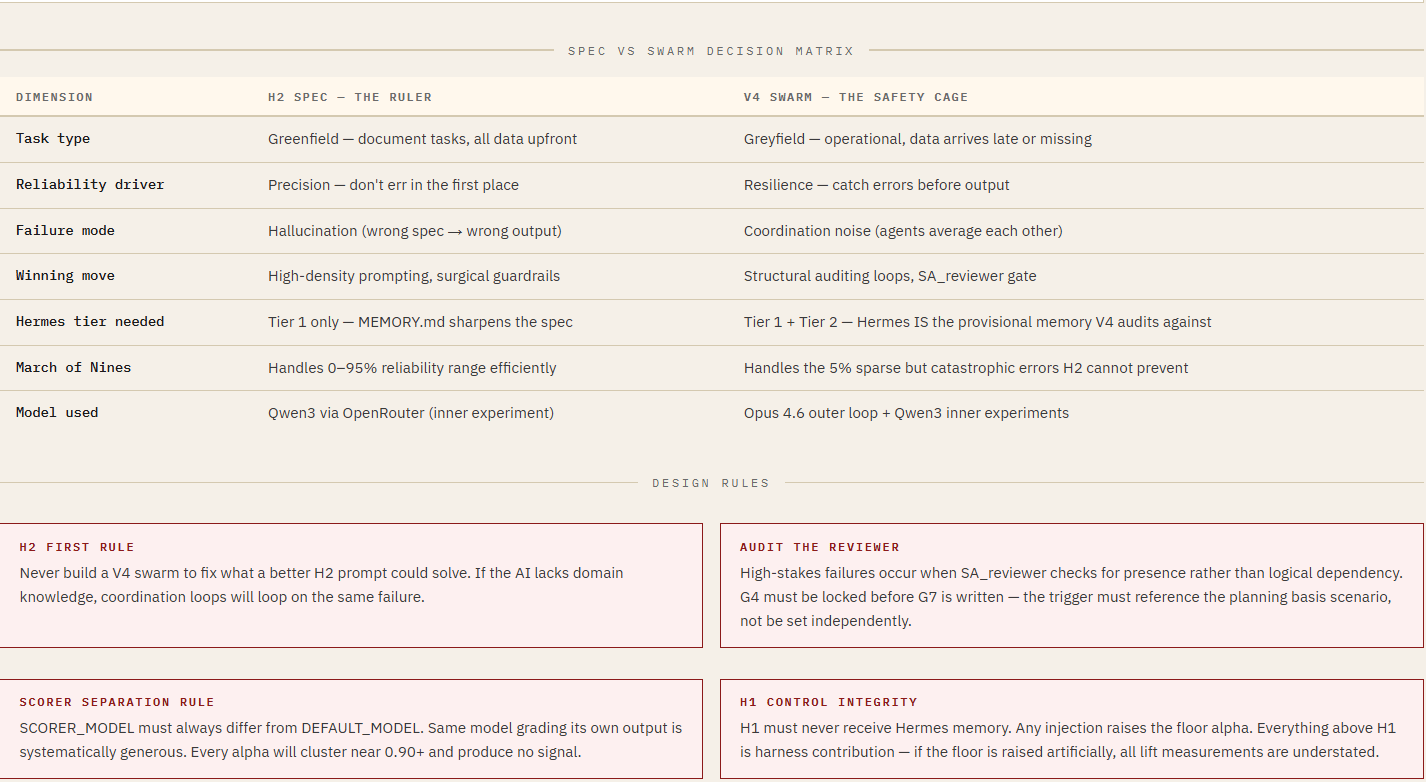
References & Further Reading
Experimental Benchmarks
Terminal-Bench 2.0 — Benchmark for AI agents in command-line environments. ForgeCode vs Claude Code gap (21.8pp from harness architecture alone).
https://github.com/terminal-bench/terminal-bench
Agent Architecture Foundations
ReAct: Synergizing Reasoning and Acting in Language Models (Yao et al., 2022)
https://arxiv.org/abs/2210.03629
AutoGen: Multi-Agent Conversation Framework (Wu et al., 2023)
https://arxiv.org/abs/2308.08155
LATS: Language Agent Tree Search (Zhou et al., 2023)
https://arxiv.org/abs/2310.04406
Prompt Engineering
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (Wei et al., 2022)
https://arxiv.org/abs/2201.11903
Anthropic Prompt Engineering Guide
https://docs.anthropic.com/en/docs/build-with-claude/prompt-engineering/overview
/goal and Ralph Loop 2.0
Codex CLI — OpenAI coding agent with /goal support
https://github.com/openai/codex
https://www.mindstudio.ai/blog/codex-goal-ralph-loop-14-hour-autonomous-task
Hermes Agent — Lightweight agent framework with standing objective support
https://github.com/hermes-hq/hermes
https://hermes-agent.nousresearch.com/docs/user-guide/features/goals
Model Routing
OpenRouter — Multi-model routing API
Mixture-of-Agents Enhances Large Language Model Capabilities (Wang et al., 2024)
https://arxiv.org/abs/2406.04692
Supply Chain Context
EIA: Strait of Hormuz — Strategic Importance and Disruption Risk
https://www.eia.gov/international/analysis/regions-of-interest/Hormuz
Lloyd’s List: Red Sea Shipping Crisis — Impact on Global Supply Chains (2024)
https://lloydslist.maritimeintelligence.informa.com
Prior Work in This Series
The Architecture of Awareness: Design Considerations of a Shipper’s Agentic Logic — Interesting Engineering++, April 2026
The Loop Is the Lab — Article Series
The Speciation of Intelligence — Article Series
The Working Layer — Article Series