
Memory Systems, AI Agents and LLMs
A Unified Framework for Strategy & Silicon

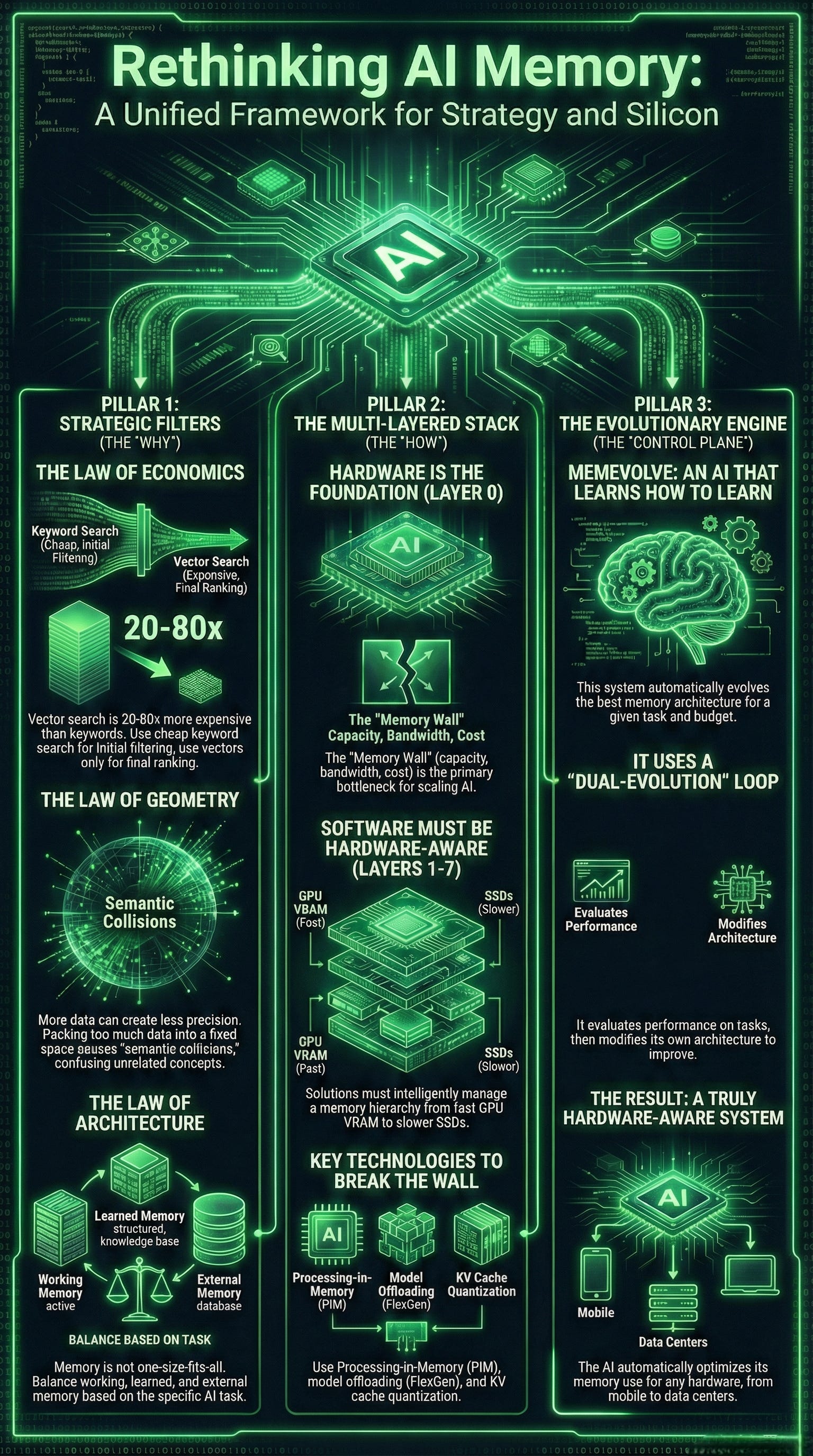
My previous article will serve as a reference point from which this one builds. Due to the high volume of research releases, this will be written and continue, in near note form. The repository of reference (helpful to me) is segregated to be hopefully useful for relevant applications, as you deem fit. Consider this a Part II to Machine Memory: The Math That Matters:
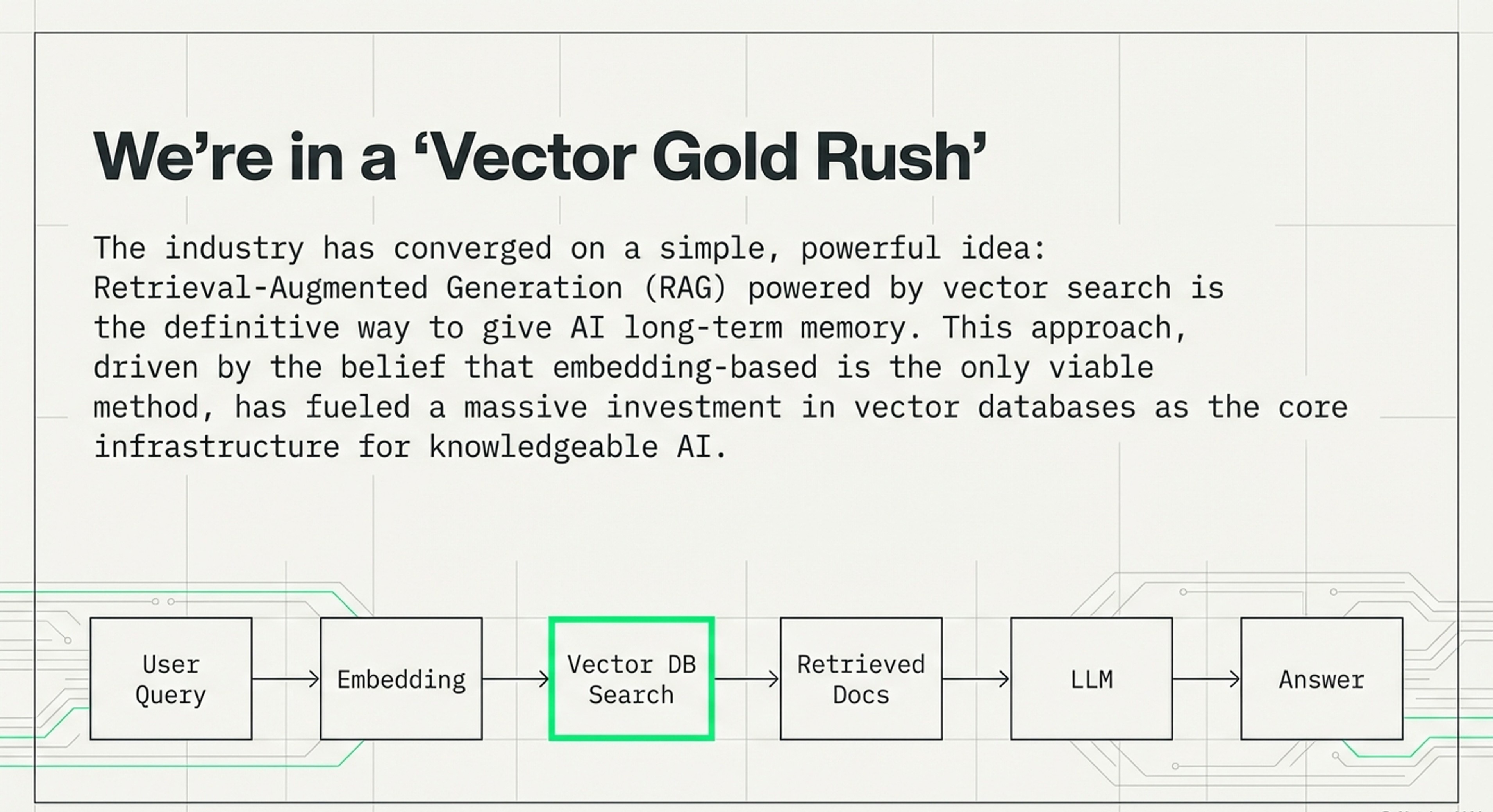
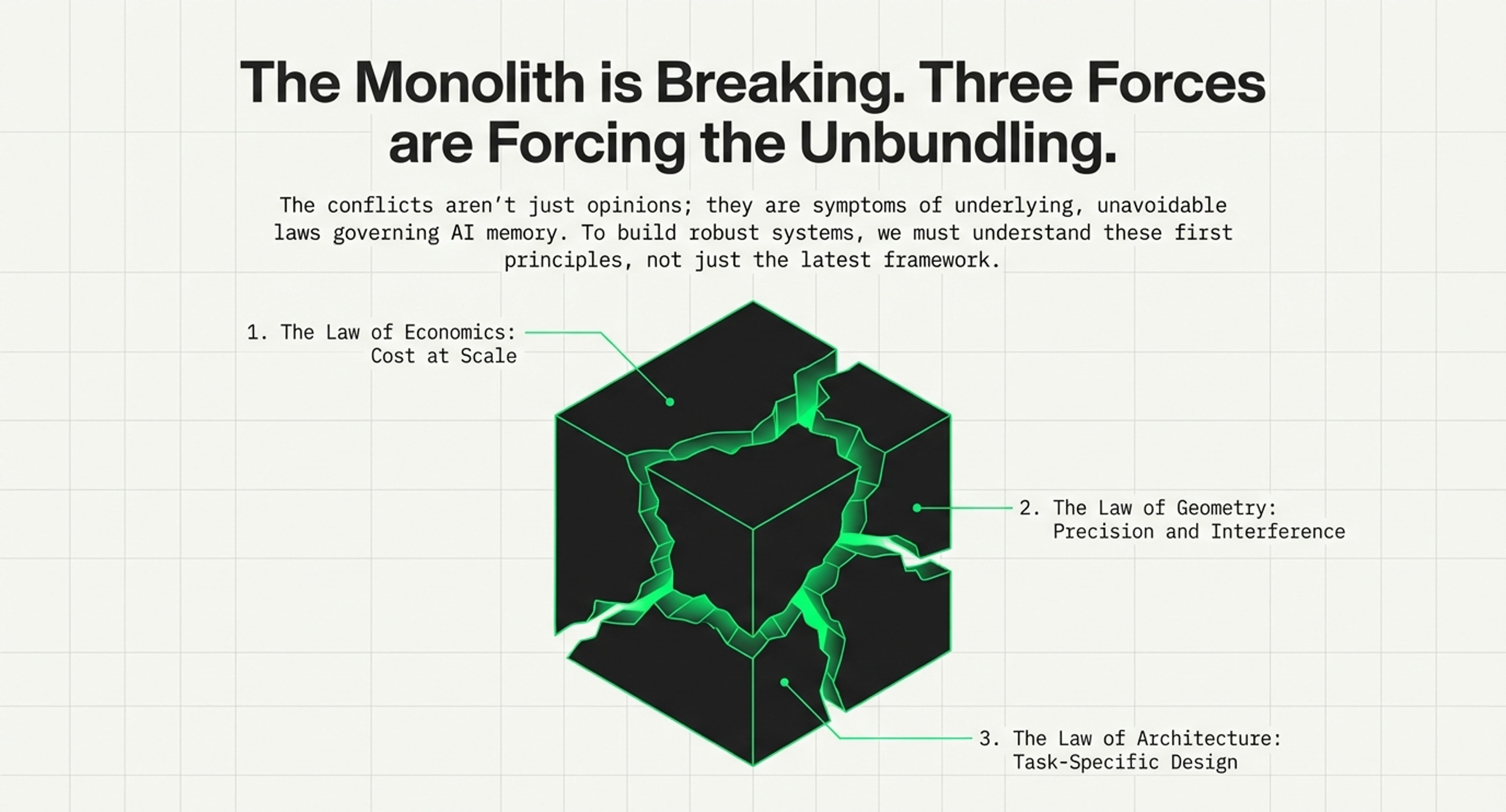
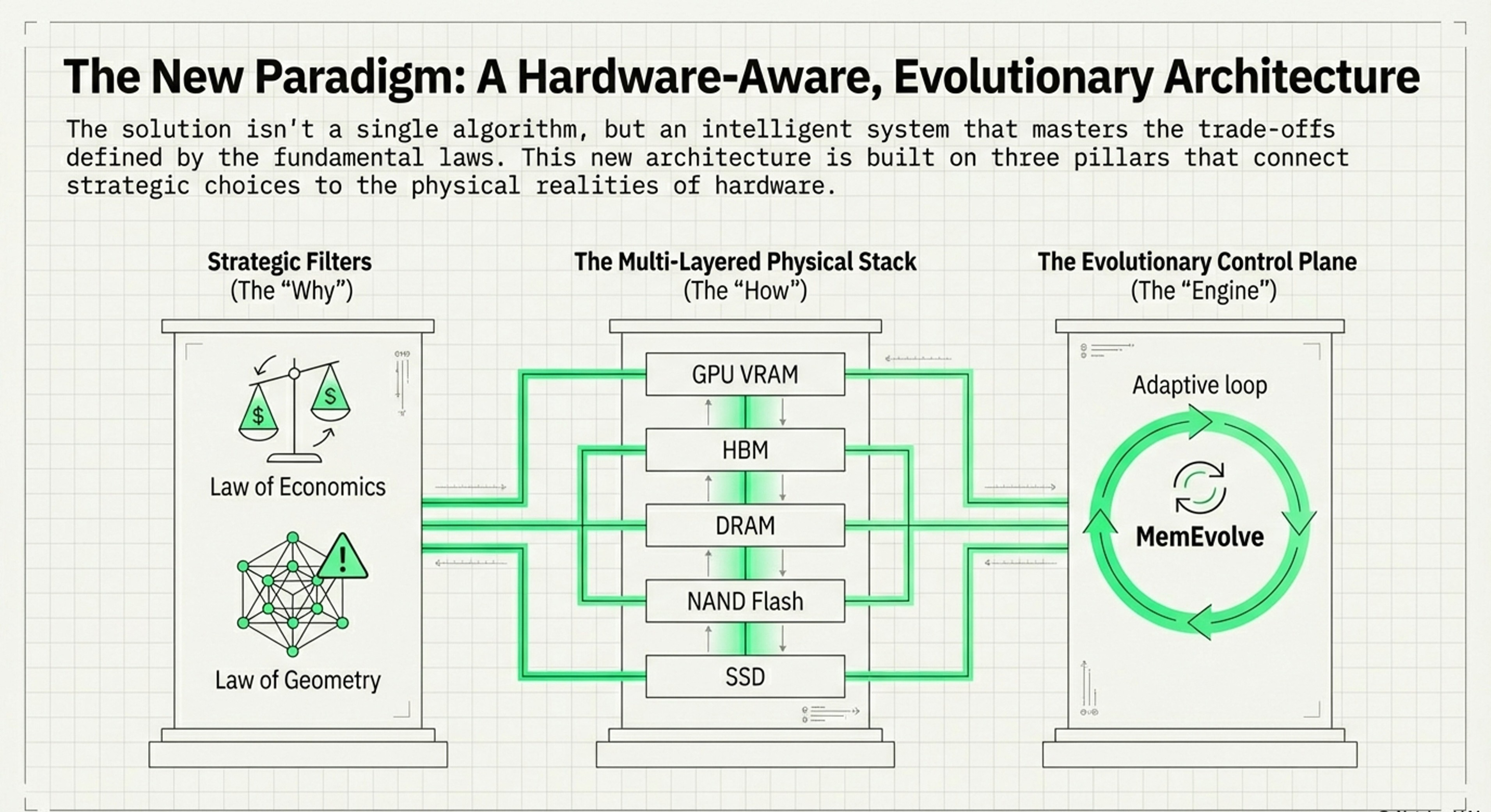
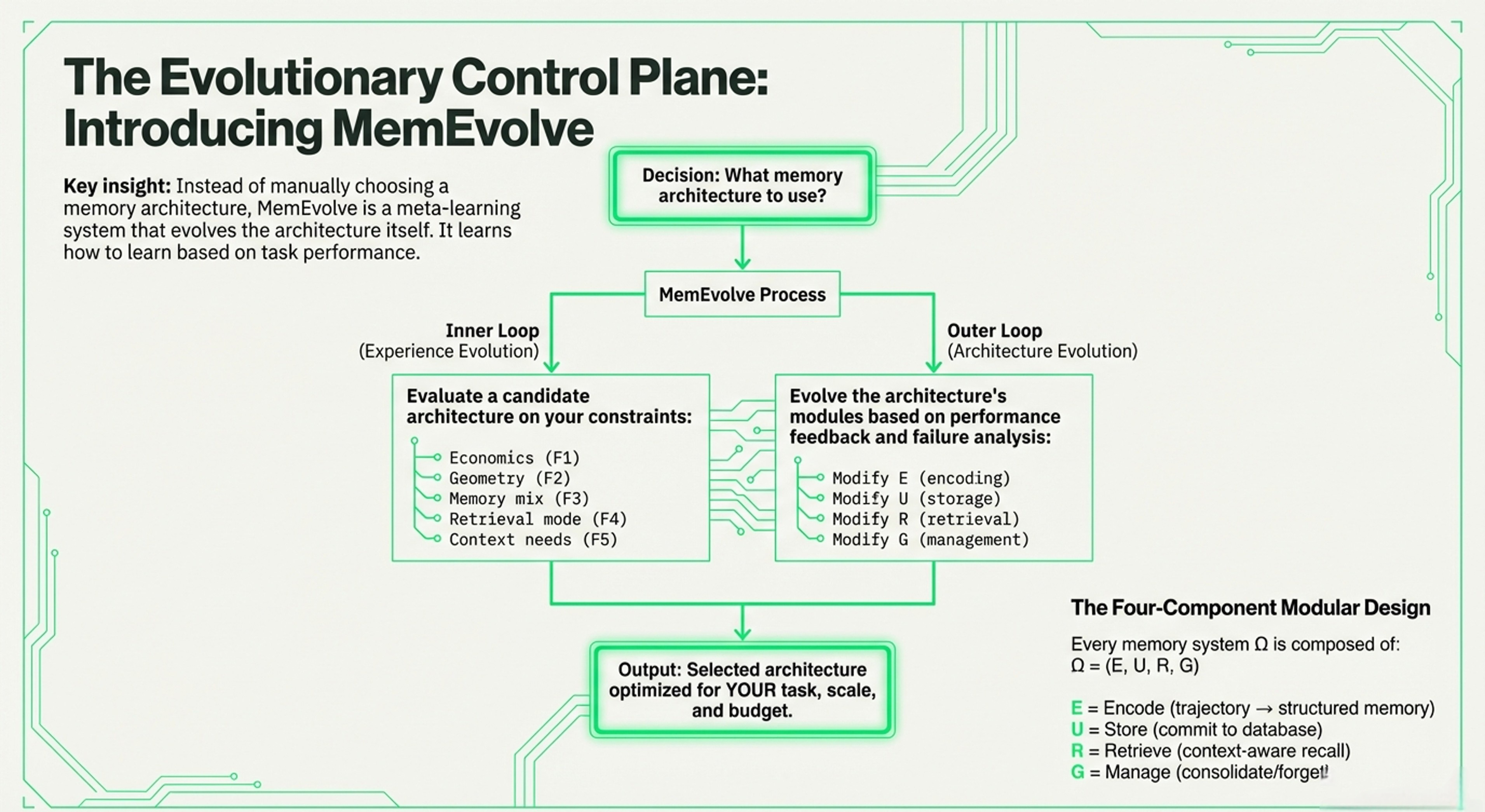
Combined, both explore the evolution of AI memory architectures, moving beyond the initial "vector gold rush" toward more hardware-aware and adaptive systems. They establish fundamental economic, geometric, and architectural laws that highlight the high costs and mathematical limitations of traditional vector searches. To address these constraints, I had highlighted and introduced MemEvolve, a meta-evolutionary engine that automates the design of memory modules by learning from performance failures.
Though an exciting and ever-evolving space, a comprehensive layered taxonomy is presented, mapping out a research landscape that spans from physical hardware infrastructure to complex cognitive architectures. This integrated approach encourages developers and planners to balance computational efficiency with task-specific needs, such as managing the "memory wall" through heterogeneous storage hierarchies.
Ultimately, and I hope, logically, to argue that the future of AI depends on adaptive learning strategies and structured memory rather than just increasing raw context size. This note also therefore refers:
Distinguishing Both Articles
At a high level, the two articles provide distinct but complementary perspectives on machine memory. While one focuses on the strategic and mathematical laws governing memory architecture, this article provides a comprehensive technical taxonomy centered on the hardware-software hierarchy.
Coverage and Contrast
Article 1 (”Machine Memory: The Math That Matters”)
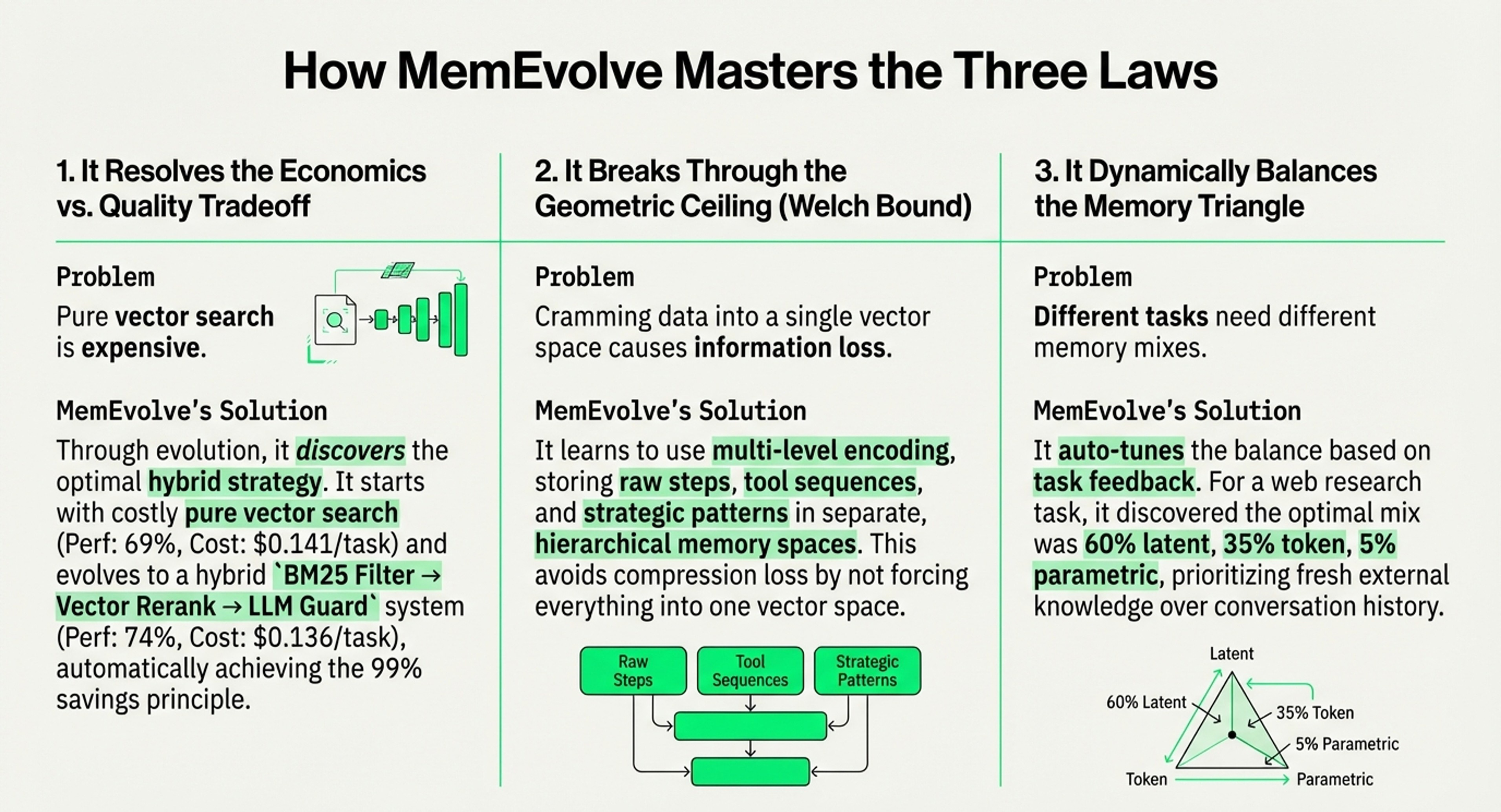
Strategic Focus: This article is oriented toward decision-making frameworks. It outlines five specific frameworks (Vector Economics, Welch Bound, Memory Triangle, Continuous Retrieval, and Context Maximalism) to help developers and planners guide choices of the right architecture for their specific constraints and timelines.
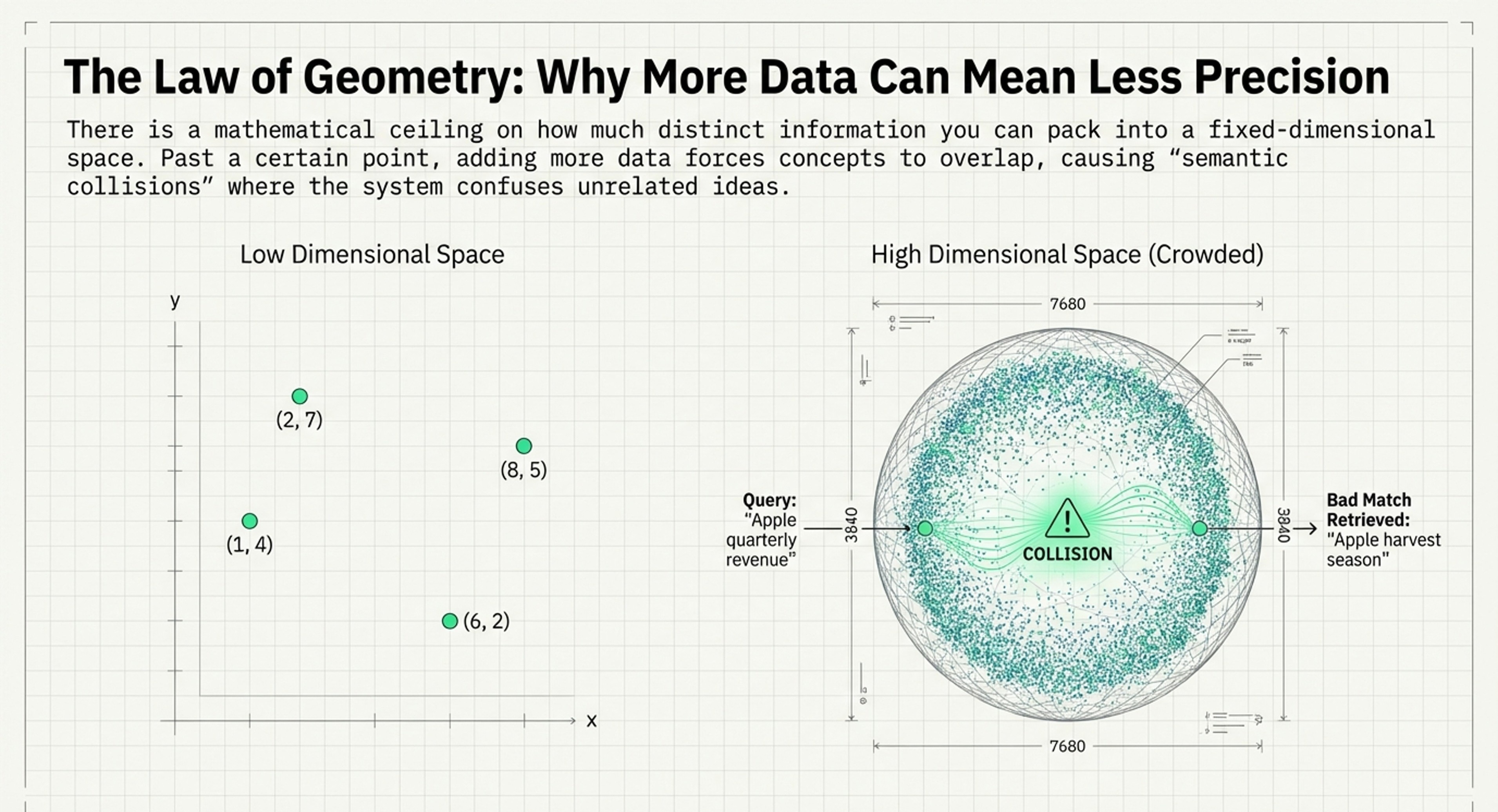
Mathematical Limits: It emphasizes the “geometric ceiling” of vector spaces, specifically citing the Welch Bound, which explains why cramming too much data into a fixed vector space leads to “semantic collisions” and reduced precision.
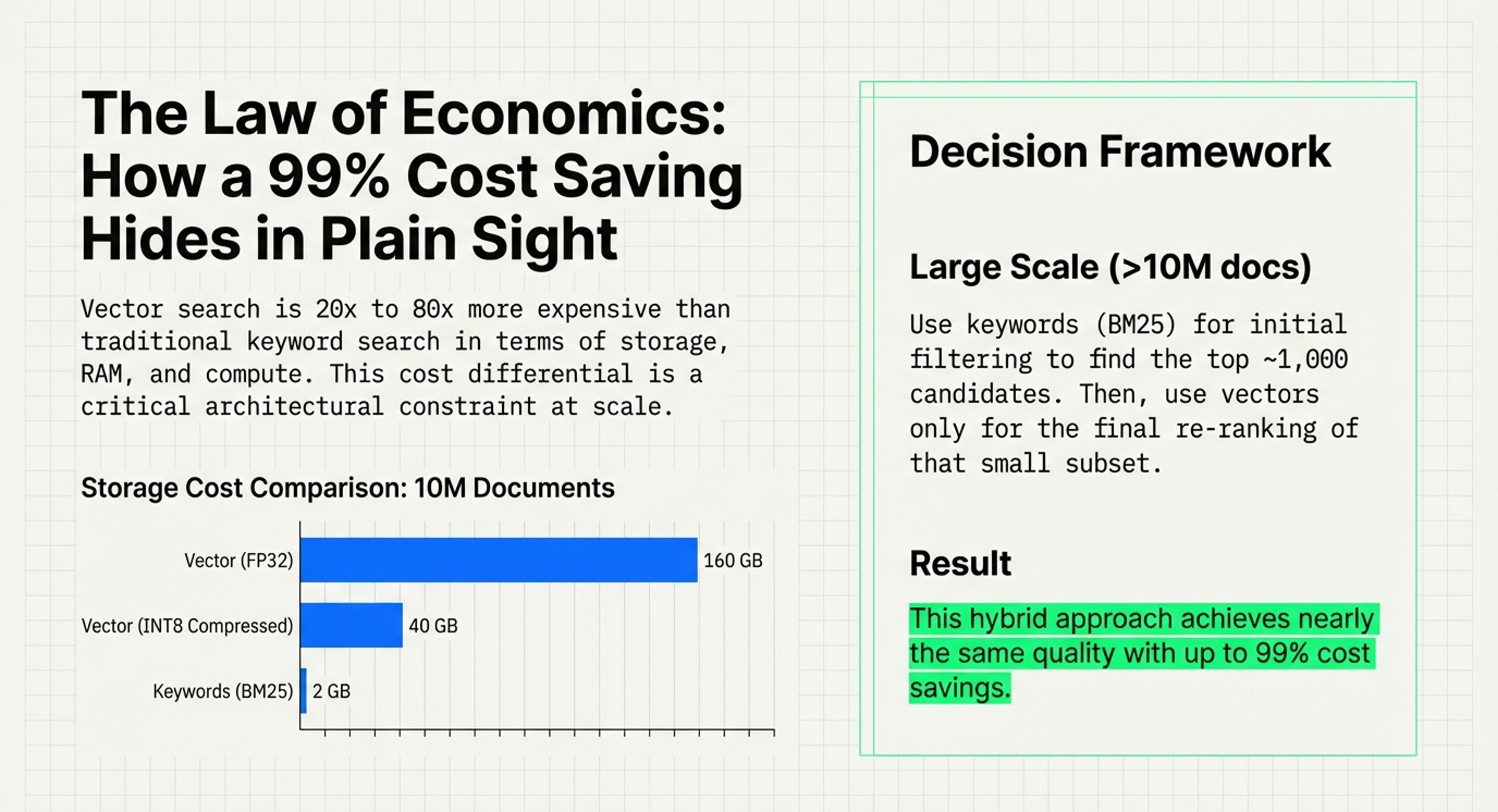
Economic Realism: It highlights a 20-80x cost difference between vector search and traditional keyword search (BM25), arguing for a “BM25 Renaissance” in large-scale systems.
Meta-Learning: It introduces MemEvolve, a system that uses “dual evolution” to automatically navigate the trade-offs between performance, cost, and delay by evolving the memory architecture itself based on task feedback.
Article 2, This Article (”Memory Systems AI Agents and LLMs”)
Infrastructural Focus: This article focuses more on a layered taxonomy (Layer 0 to Layer 7), with a heavy emphasis on Layer 0: Hardware & System Infrastructure.
Hardware Bottlenecks: It dives deeply into the “Memory Wall,” discussing GPU VRAM capacity, bandwidth limitations, and the necessity of “Processing-in-Memory” (PIM) and “In-Storage Computing”.
Comprehensive Taxonomy: It categorizes 84 research papers across eight functional layers, including KV cache efficiency, multimodal memory, and tool integration.
Implementation Guides: It provides (I hope) a practical guide for deploying agents on different hardware tiers, such as mobile/edge (6GB RAM) versus enterprise (8x80GB GPU) setups.
To wit, to understand the difference between these two articles, imagine you are building a professional kitchen. Article 1 is the Executive Chef’s Strategy, focusing on how to balance the menu (the Memory Triangle) and when to buy pre-chopped ingredients versus fresh ones to save money (Vector Economics). Article 2 is the Kitchen Engineer’s Blueprint, focusing on how many ovens the electrical grid can support, where the pipes are located, and how to keep the refrigerators from overheating (Hardware Infrastructure).
Unified Framework: Hardware Foundation + Memory Solutions
This framework integrates memory architectures (what types exist) with bottleneck solutions (what problems they solve), creating a comprehensive map of the research landscape.
Framework Structure
BOTTLENECK LAYER → MEMORY TYPE SOLUTION → SPECIFIC IMPLEMENTATIONSLayer 0: Hardware & System Infrastructure ⭐ NEW
Bottleneck: The “Memory Wall”
Problem: GPU memory capacity, bandwidth, and cost constrain model size, context length, and deployment scalability.
0.1 Hardware-Software Co-Design & Processing-in-Memory (PIM)

Hardware-Software Co-Design & PIM
L3: DIMM-PIM Integrated Architecture and Coordination for Scalable Long-Context LLM Inference (2024)
HPU: High-Bandwidth Processing Unit for Scalable, Cost-effective LLM Inference via GPU Co-processing (2024)
Reimagining Memory Access for LLM Inference: Compression-Aware Memory Controller Design (2024)
InstInfer: In-Storage Attention Offloading for Cost-Effective Long-Context LLM Inference (2024)
Key Innovation: Moving computation to where data resides, rather than moving data to computation.
0.2 Model Offloading & Heterogeneous Memory Hierarchies
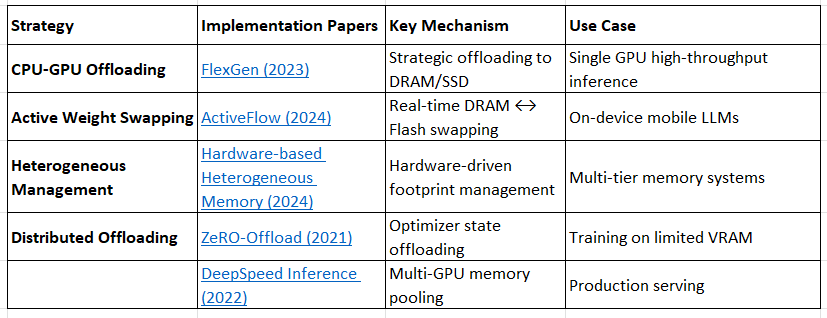
Model Offloading & Heterogeneous Memory
FlexGen: High-Throughput Generative Inference of Large Language Models with a Single GPU (2023)
Scaling Up On-Device LLMs via Active-Weight Swapping Between DRAM and Flash (2024)
Hardware-based Heterogeneous Memory Management for Large Language Model Inference (2024)
ZeRO-Offload: Democratizing Billion-Scale Model Training (2021)
DeepSpeed Inference: Enabling Efficient Inference of Transformer Models at Unprecedented Scale (2022)
Key Innovation: Treating memory as a hierarchy (GPU VRAM → CPU DRAM → SSD/Flash) with intelligent orchestration.
0.3 Inference System Optimizations
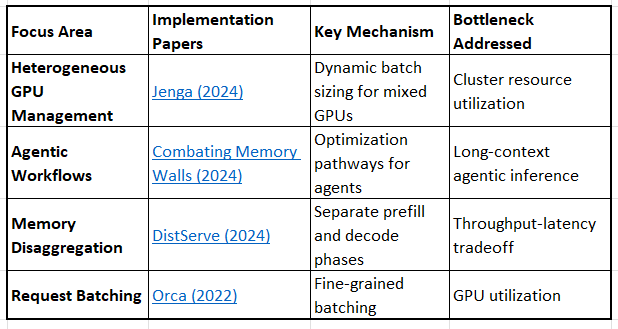
Inference System Optimizations
Jenga: Effective Memory Management for Serving LLM with Heterogeneity (2024)
Combating the Memory Walls: Optimization Pathways for Long-Context Agentic LLM Inference (2024)
DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving (2024)
Orca: A Distributed Serving System for Transformer-Based Generative Models (2022)
Key Innovation: System-level orchestration that maximizes existing hardware capabilities.
0.4 Hardware Analysis & Future Directions
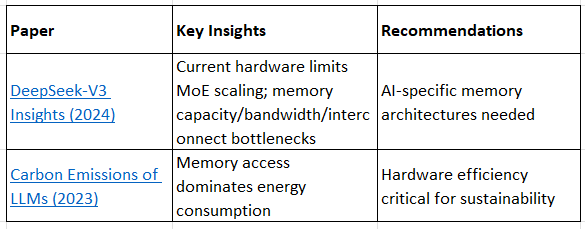
Hardware Analysis
Insights into DeepSeek-V3: Scaling Challenges and Reflections on Hardware for AI Architectures (2024)
Counting Carbon: A Survey of Factors Influencing the Emissions of Machine Learning (2023)
Layer 1: Hardware & Computational Efficiency
Bottleneck: KV Cache Memory Consumption
Problem: GPU memory grows linearly with sequence length, limiting batch size and context windows.
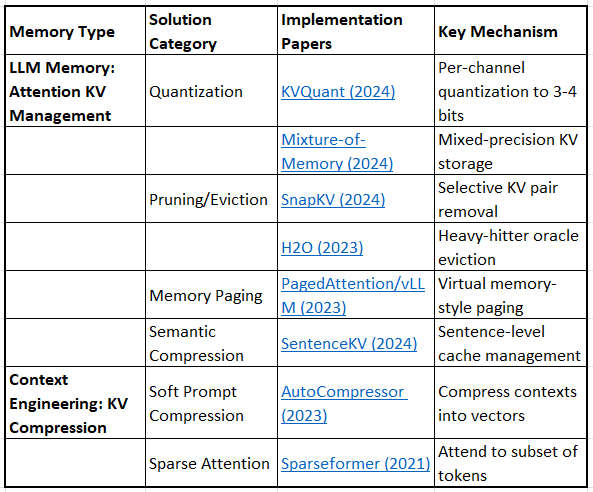
Layer 1: Computational Efficiency (KV Cache)
Quantization
KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization (2024)
Mixture-of-Memory: Reformulating Self-Attention with Mixture of Experts (2024)
Pruning & Eviction
SnapKV: LLM Knows What You are Looking for Before Generation (2024)
H2O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models (2023)
Memory Management
Efficient Memory Management for Large Language Model Serving with PagedAttention (2023) - vLLM paper
SentenceKV: Efficient LLM Inference via Sentence-Level Semantic KV Caching (2024)
Compression
AutoCompressor: Compressing Context into Summary Vectors (2023)
Sparseformer: Efficient Transformer via Learnable Sparsification (2021)
Survey Coverage:
Layer 2: Context Window & Working Memory Constraints
Bottleneck: Limited Context Window
Problem: Fixed-size context causes “lost in the middle” and forces constant information eviction.
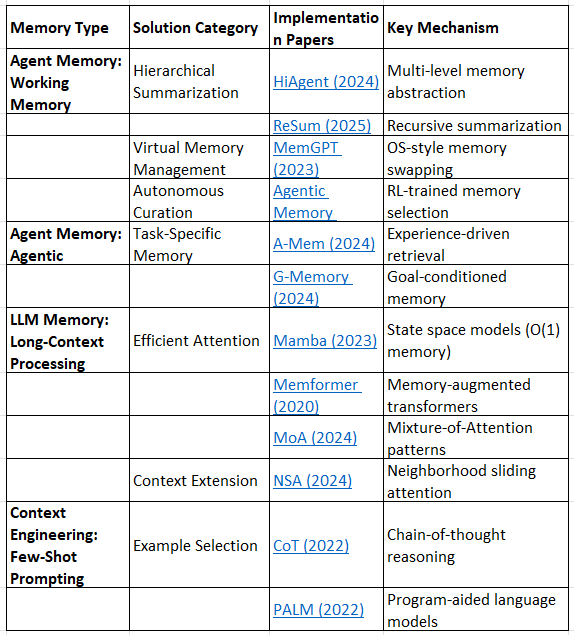
Layer 2: Context Window & Working Memory
Hierarchical Memory Management
HiAgent: Hierarchical Working Memory Management for Solving Long-Horizon Agent Tasks (2024)
ReSum: Recursive Summarization for Long Context Language Models (2025)
Agentic Memory Systems
A-Mem: Adaptive Memory for Long-Context Language Understanding (2024)
G-Memory: Goal-Conditioned Memory for Autonomous Agents (2024)
Long-Context Processing
Mamba: Linear-Time Sequence Modeling with Selective State Spaces (2023)
Memformer: A Memory-Augmented Transformer for Sequence Modeling (2020)
MoA: Mixture of Sparse Attention for Automatic Large Language Model Compression (2024)
Few-Shot Prompting
Survey Coverage:
Layer 3: Long-Term Persistence & Episodic Memory
Bottleneck: Information Persistence Across Sessions
Problem: No standardized way to store, retrieve, and evolve memories across episodes.
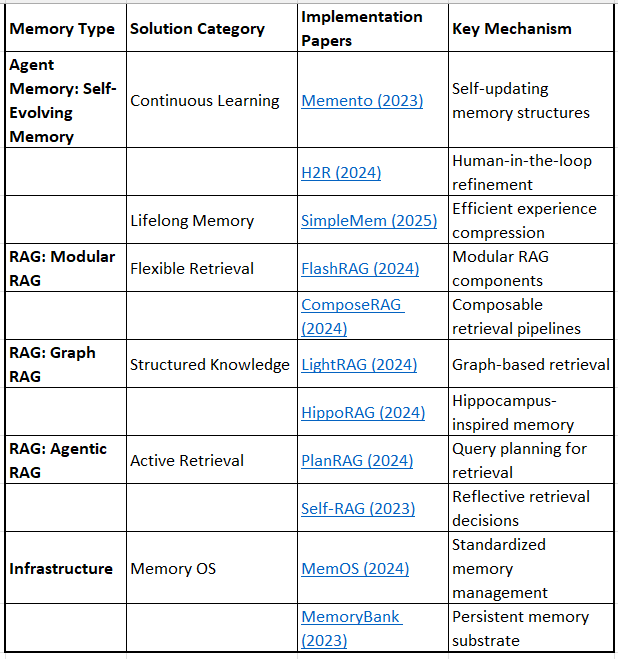
Layer 3: Long-Term Persistence & Episodic Memory
Self-Evolving Memory
Memento: Facilitating Long-Horizon Memory in LLM-based Agents (2023)
H2R: Human-in-the-Loop Hierarchical Memory for Long-Horizon Robotic Tasks (2024)
Modular RAG
FlashRAG: A Modular Toolkit for Efficient Retrieval-Augmented Generation Research (2024)
ComposeRAG: Composable Retrieval-Augmented Generation (2024)
Graph RAG
LightRAG: Simple and Fast Retrieval-Augmented Generation (2024)
HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models (2024)
Agentic RAG
Infrastructure
Survey Coverage:
Layer 4: Procedural Memory & Skill Learning
Bottleneck: Cannot Learn “How To” from Experience
Problem: Agents rely on static prompts and don’t evolve procedural knowledge.
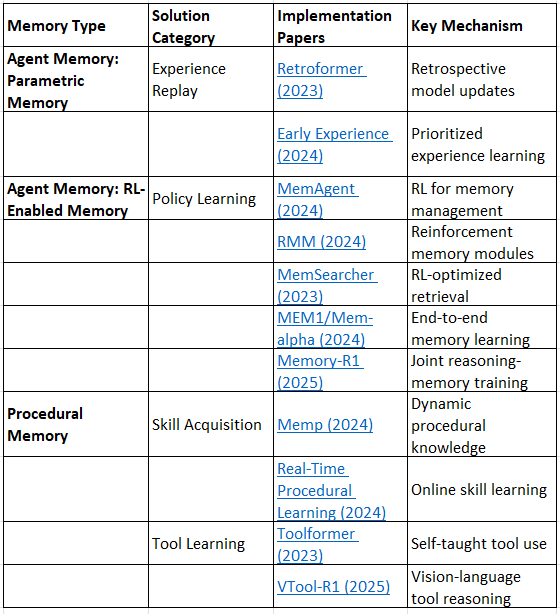
Layer 4: Procedural Memory & Skill Learning
Parametric Memory
Retroformer: Retrospective Large Language Agents with Policy Gradient Optimization (2023)
Leveraging Early Experiences for Efficient Policy Learning in Multi-Agent Systems (2024)
RL-Enabled Memory
MemAgent: Towards Adaptive Memory Management for LLM-based Agents (2024)
RMM: Reinforced Memory Management for Class-Incremental Learning (2024)
MemSearcher: Reinforcement Learning Based Memory Searcher for Large Language Models (2023)
MEM1: Memory-Augmented Reinforcement Learning with Task-Specific Embedding (2024)
Memory-R1: Joint Training of Memory and Reasoning for Long-Horizon Tasks (2025)
Procedural Learning
Tool Learning
Toolformer: Language Models Can Teach Themselves to Use Tools (2023)
VTool-R1: Vision-Language Tool Reasoning and Execution (2025)
Layer 5: Multimodal & Sensory Memory
Bottleneck: Text-Only Memory is Insufficient
Problem: Real-world agents need visual, auditory, and sensory memories.
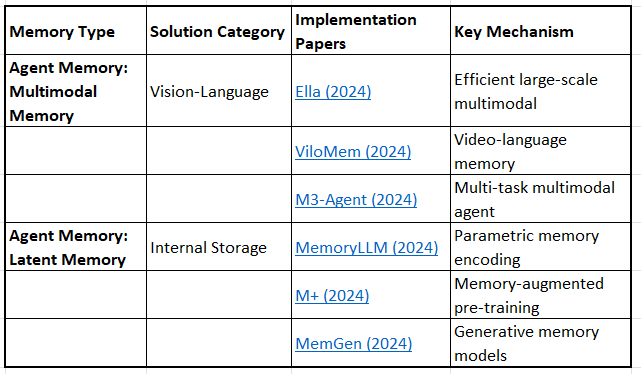
Layer 5: Multimodal & Sensory Memory
Vision-Language Memory
Ella: Efficient Large-Scale Vision-Language Representation Learning (2024)
ViloMem: Video-Language Memory for Long-Form Video Understanding (2024)
Latent Memory
MemoryLLM: Towards Self-Updatable Large Language Models (2024)
M+: Memory-Augmented Pre-training for Language Models (2024)
MemGen: Generative Memory for Long-Context Language Models (2024)
Layer 6: Tool Integration & Meta-Cognition
Bottleneck: Disconnected Tools and Reasoning
Problem: Tools, reasoning, and memory operate in silos.
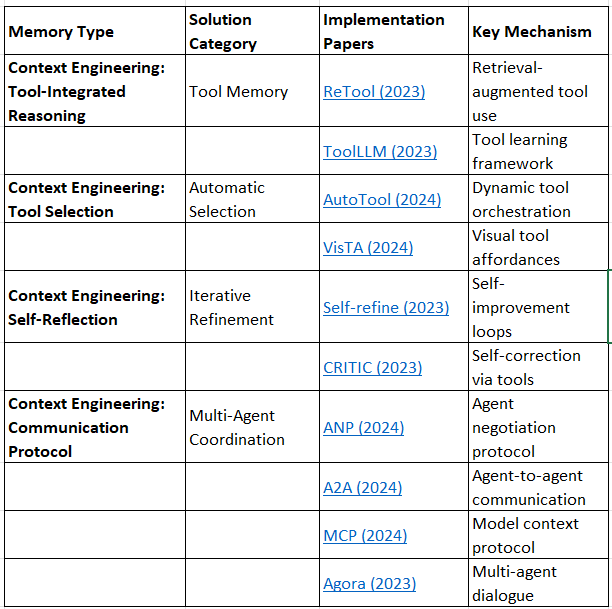
Layer 6: Tool Integration & Meta-Cognition
Tool-Integrated Reasoning
Tool Selection
Self-Reflection
Communication Protocols
Layer 7: Cognitive Architecture & Meta-Memory
Bottleneck: Lack of Systematic Memory Design
Problem: No unified theory connecting memory representations, operations, and human cognition.
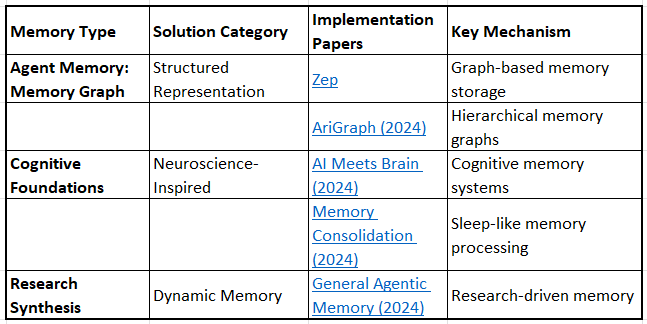
Layer 7: Cognitive Architecture & Meta-Memory
Memory Graph Structures
Cognitive Foundations
AI Meets Brain: Memory Systems from Cognitive Neuroscience to Autonomous Agents (2024)
Memory Consolidation for Continual Learning in Neural Networks (2024)
Dynamic Memory Systems
Survey Coverage:
Cross-Cutting Infrastructure
Hardware-Level Optimization
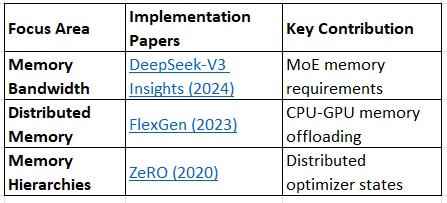
Comprehensive Surveys
A Survey on Large Language Model Acceleration based on KV Cache Management (2024)
Rethinking Memory in LLM based Agents: Representations, Operations, and Emerging Topics (2024)
A Survey of Context Engineering for Large Language Models (2024)
A Survey on the Memory Mechanism of Large Language Model based Agents (2024)
Quick Access by Problem Type
“I need to reduce GPU memory usage”
→ Layer 0: FlexGen, ActiveFlow, Jenga
→ Layer 1: KVQuant, PagedAttention, SnapKV
“I need longer context windows”
→ Layer 0: L3, PIMphony
→ Layer 1: SentenceKV, AutoCompressor
→ Layer 2: MemGPT, Agentic Memory
“I need persistent agent memory”
→ Layer 3: MemOS, LightRAG, HippoRAG
→ Layer 4: Memp, Real-Time Procedural Learning
“I need agents that learn skills”
→ Layer 4: MemAgent, Memory-R1, Toolformer
→ Layer 6: ToolLLM, AutoTool
“I need multimodal agents”
→ Layer 5: ViloMem, M3-Agent, MemoryLLM
“I want to understand the field”
→ Surveys: Memory in the Age of AI Agents, KV Cache Survey


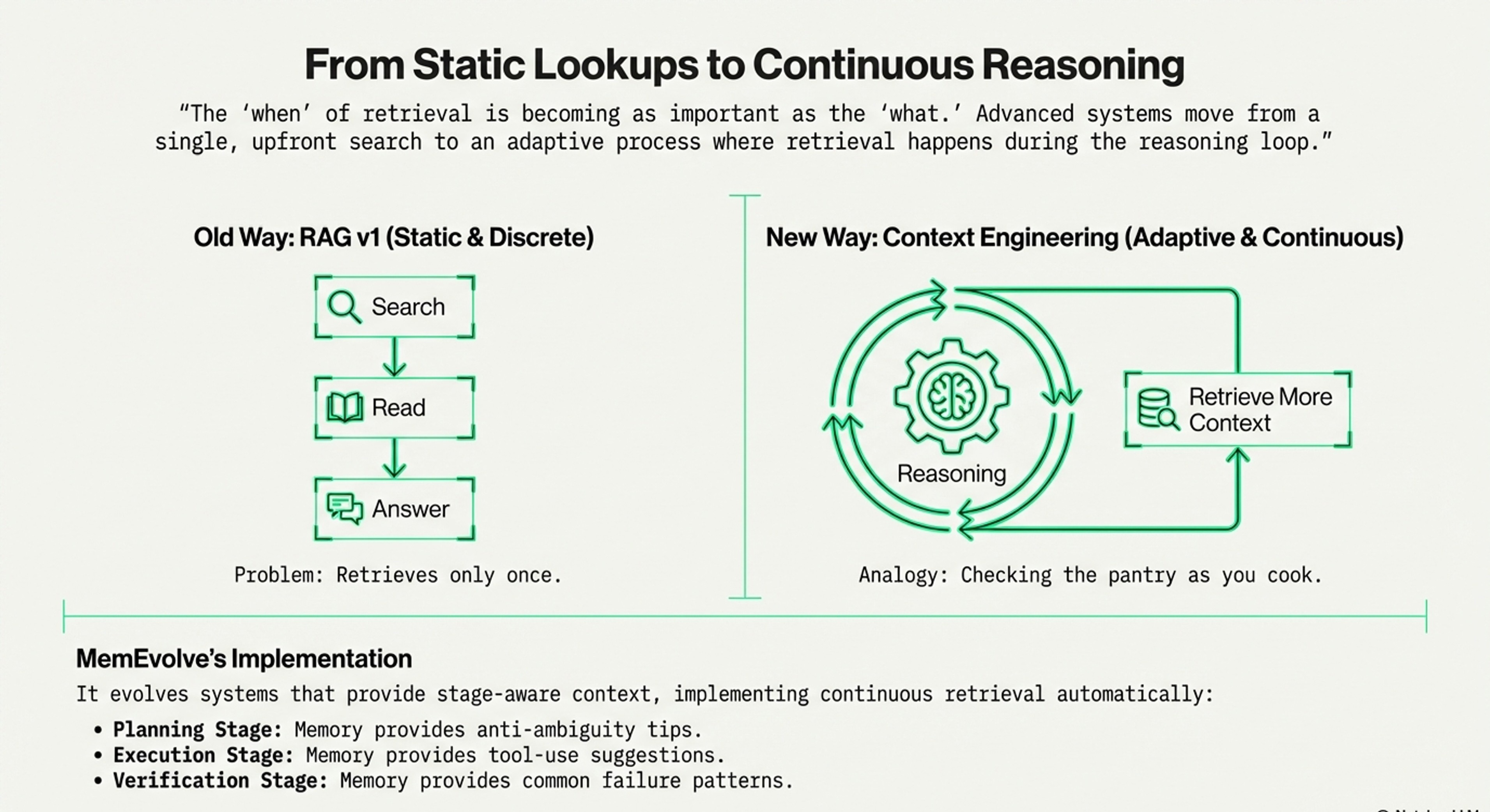
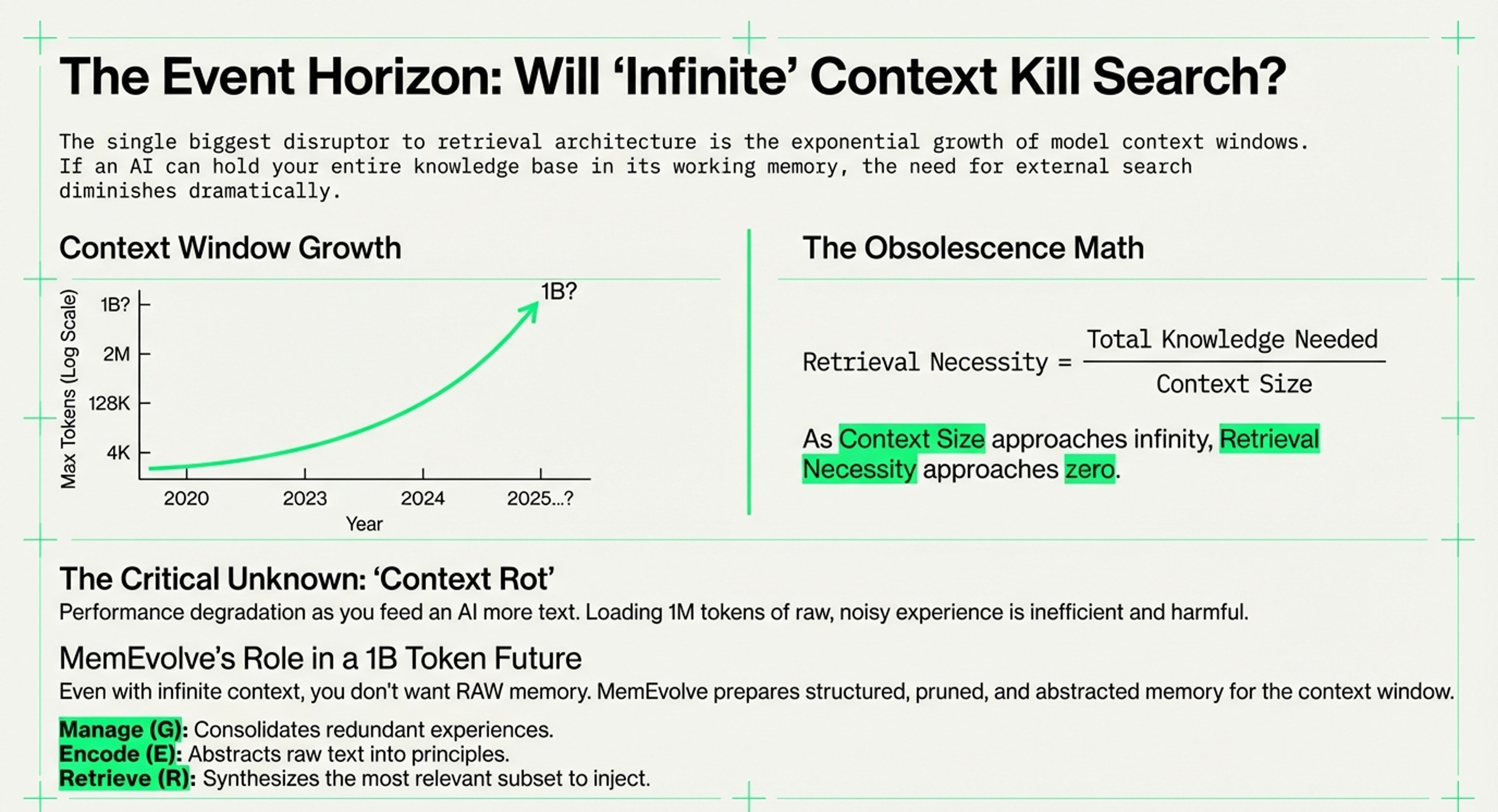
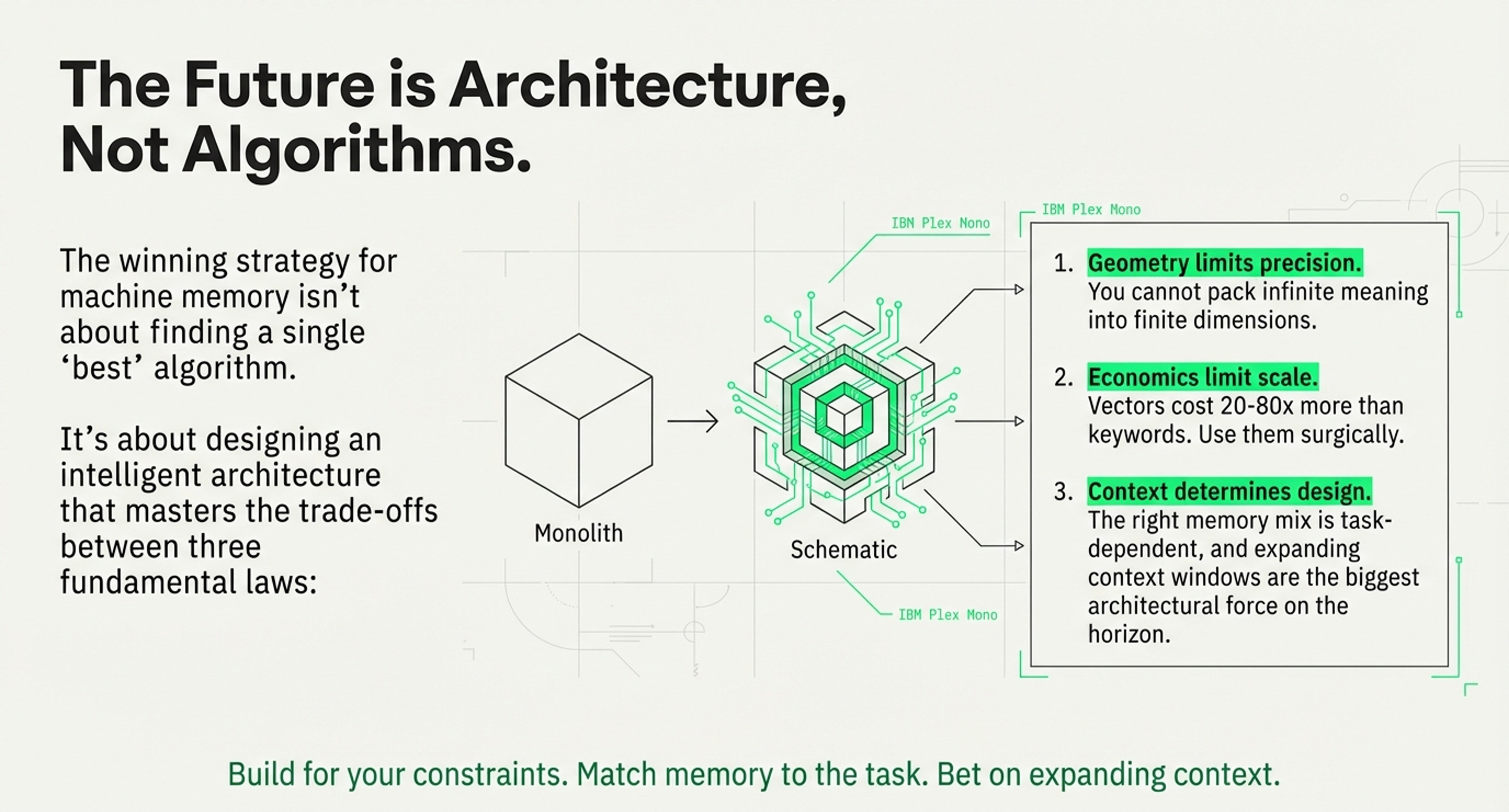
Meta-Analysis: Memory Type × Bottleneck Matrix
Cross-Layer Integration Map
Layer 0: Hardware Infrastructure (NEW)
↓ Enables ↓
Layer 1: Computational Efficiency (KV Cache)
↓ Feeds into ↓
Layer 2: Context Window Management
↓ Supports ↓
Layer 3: Long-Term Persistence
↓ Enables ↓
Layer 4: Procedural Learning
↓ Integrates ↓
Layer 5: Multimodal Memory
↓ Coordinates ↓
Layer 6: Tool Integration
↓ Informs ↓
Layer 7: Cognitive Architecture
Hardware × Software Co-Design Examples
Example 1: Long-Context Inference Stack
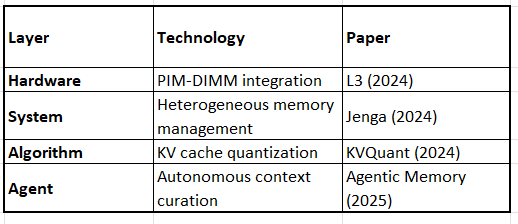
Result: 10M+ token contexts on consumer hardware
Example 2: On-Device Mobile Agents
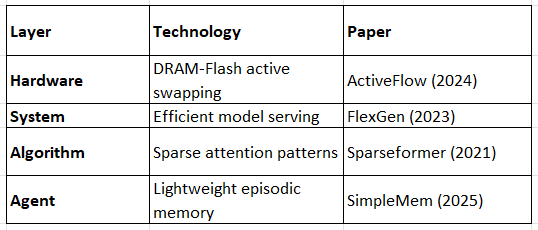
Result: 7B+ parameter agents on smartphones
Example 3: Data Center Agentic Systems
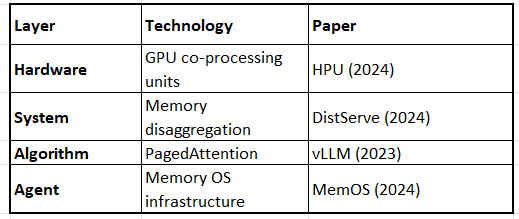
Result: Cost-effective multi-agent deployments
Hardware Bottleneck × Memory Type Solutions
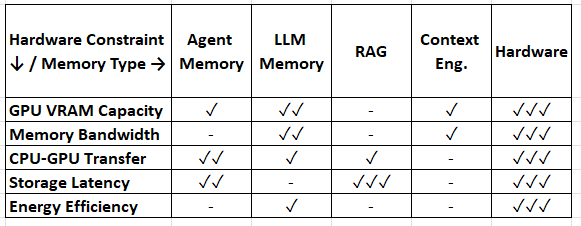
Meta-Analysis: Memory Type × Bottleneck Matrix
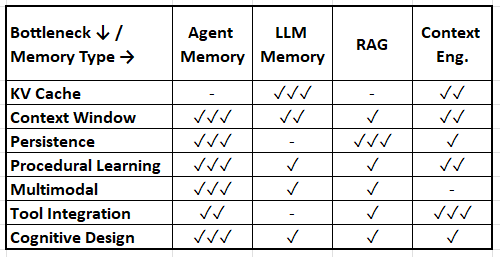
Legend: ✓✓✓ Primary solution space | ✓✓ Secondary | ✓ Emerging | - Minimal coverage
Key Research Insights: Hardware Layer
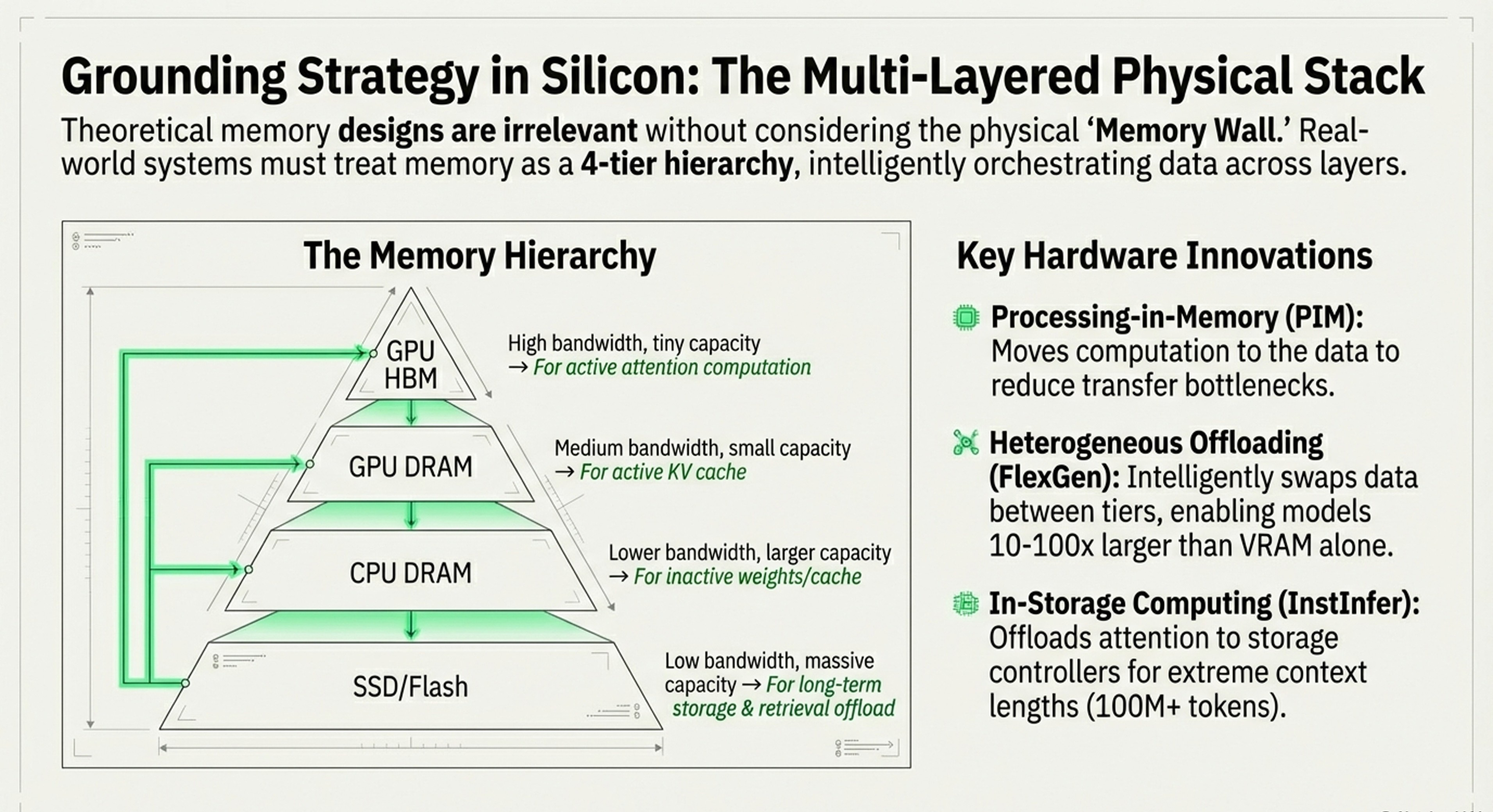
1. The Memory Hierarchy is Critical
Modern solutions treat memory as a 4-tier hierarchy:
GPU HBM (high bandwidth, tiny capacity) → Attention computation
GPU DRAM (medium bandwidth, small capacity) → Active KV cache
CPU DRAM (lower bandwidth, larger capacity) → Inactive weights/cache
SSD/Flash (low bandwidth, massive capacity) → Long-term storage
Papers like FlexGen and ActiveFlow show that intelligent orchestration across these tiers enables models 10-100x larger than GPU VRAM alone.
2. Hardware Specialization is Emerging
PIM (L3, PIMphony): Reduces data movement by computing in memory
HPU: Dedicated units for low-intensity operations
In-storage computing (InstInfer): Offloads attention to storage controllers
This mirrors the historical shift from general-purpose CPUs to specialized GPUs—we’re now seeing memory-specialized accelerators.
3. Software Must Be Hardware-Aware
Most agent memory papers ignore hardware constraints. This creates a gap:
Agent designers assume infinite memory (e.g., “store all experiences”)
Hardware has strict VRAM limits (24-80GB consumer GPUs)
Papers like Combating Memory Walls and DeepSeek-V3 Insights call for hardware-aware agent design.
4. The “Memory Wall” is Multi-Dimensional
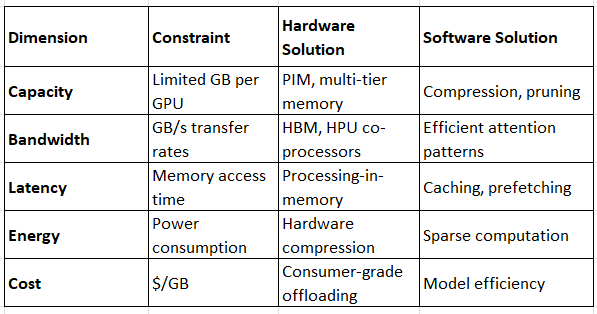
Solutions must address multiple dimensions simultaneously.
Research Gaps: Hardware × Memory
Critical Missing Areas:
Hardware-Aware Agent Architectures
Most agent papers (MemGPT, Agentic Memory) don’t specify hardware requirements
Need: Agent memory systems that adapt to available hardware
Unified Benchmarking
No standard for measuring memory performance across hardware tiers
Proposed: Memory-throughput-latency Pareto curves for different systems
Cross-Layer Optimization
Hardware and software optimized independently
Need: Co-designed systems (e.g., PIM hardware + agent memory manager)
Mobile/Edge Agent Hardware
Most work focuses on data center GPUs
Gap: Specialized hardware for on-device agents (NPUs, edge accelerators)
Energy-Efficient Memory
Memory access dominates LLM energy consumption
Need: Sustainability metrics in memory system design
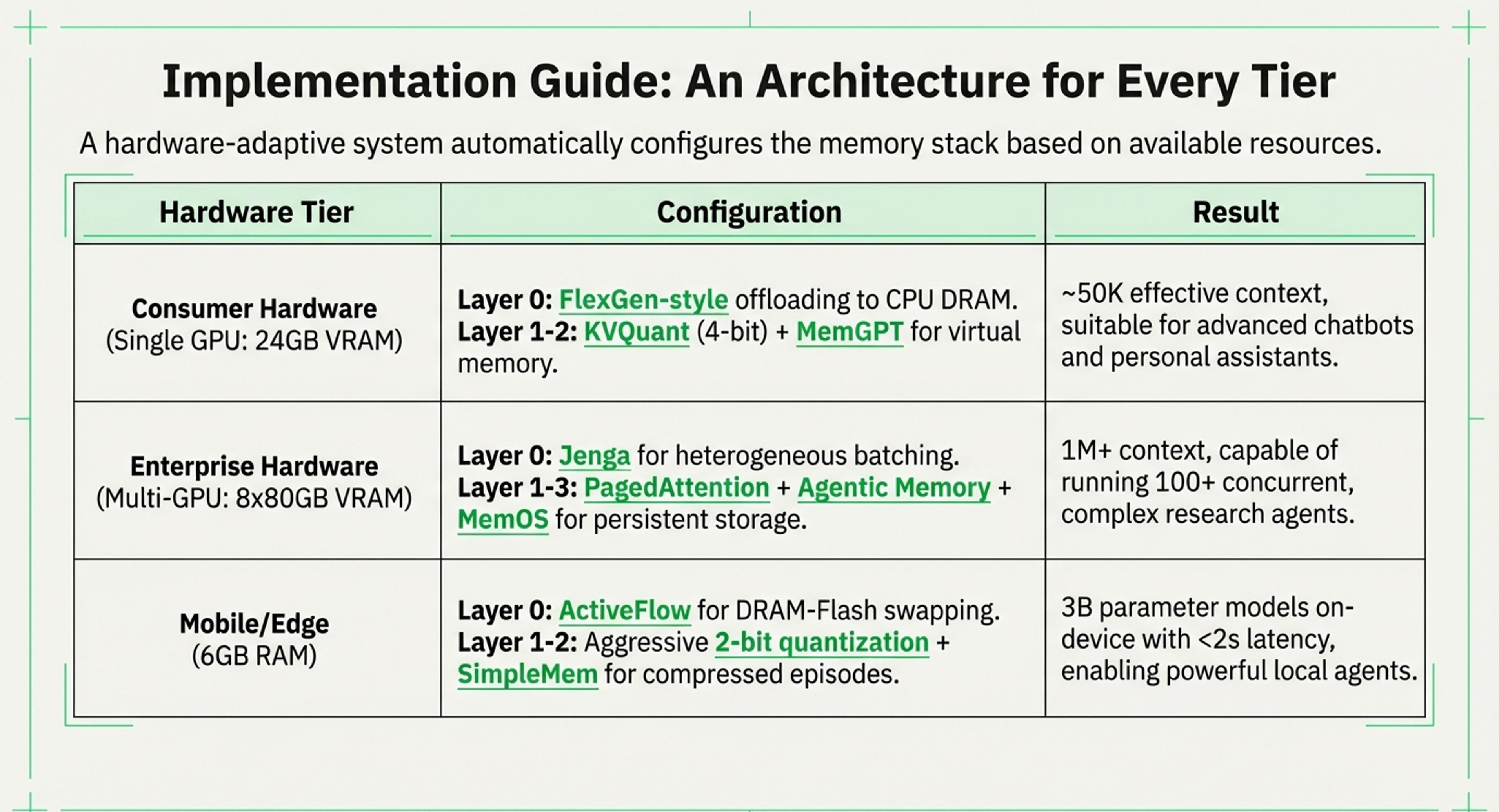
Practical Implementation Guide: Hardware-Aware Memory Systems
For Developers:
Consumer Hardware (Single GPU: 24GB)
Layer 0: FlexGen-style offloading to CPU
Layer 1: KVQuant (4-bit) + SnapKV (50% pruning)
Layer 2: MemGPT (4K main, vector disk)
Layer 3: LightRAG (local vector DB)
Achieves: ~50K effective context, 10 req/min throughput
Enterprise Hardware (Multi-GPU: 8x80GB)
Layer 0: Jenga (heterogeneous batching)
Layer 1: PagedAttention + SentenceKV
Layer 2: Agentic Memory (trained curation)
Layer 3: MemOS (persistent storage)
Achieves: 1M+ context, 100+ concurrent agents
Mobile/Edge (6GB RAM)
Layer 0: ActiveFlow (DRAM-Flash swapping)
Layer 1: Aggressive quantization (2-bit)
Layer 2: SimpleMem (compressed episodes)
Layer 3: Local-only RAG
Achieves: 3B model, 8K context, <2s latency
For Researchers:
High-Impact Research Directions:
Hardware-Adaptive Agent Memory
Agents that detect available hardware and configure memory systems accordingly
Example: Automatically switch between MemGPT (high VRAM) and SimpleMem (low VRAM)
PIM + Agent Co-Design
Design agent architectures that natively leverage PIM
Example: Episodic memory stored in PIM-enabled DIMMs with in-memory search
Energy-Aware Memory Management
Memory systems that optimize for energy, not just latency/throughput
Example: Sleep-like memory consolidation that reduces active DRAM usage
Cross-Platform Memory Standards
Portable agent memory that works across cloud, edge, and mobile
Example: MemOS-style API with hardware abstraction layer
Hardware Benchmarking Suite
Standardized tests for memory system performance
Metrics: tokens/sec, $/token, watts/token, memory efficiency (GB_effective/GB_physical)
Key Insights from the Unified Framework: Software/Hardware
1. Complementary Solutions
KV cache bottlenecks require LLM-level and hardware solutions (quantization, paging)
Context limits need both agent-level curation (working memory) AND architectural improvements (long-context models)
Persistence is primarily solved by RAG and agent memory systems
2. Emerging Integration
Recent papers increasingly combine multiple memory types:
Agentic Memory (2025) = Working Memory + Self-Evolving + RL-enabled
MemOS (2024) = Infrastructure bridging Agent, LLM, and RAG memory
Memory-R1 (2025) = Parametric + RL-enabled + Procedural
3. Research Gaps
Multimodal procedural memory: How do agents learn skills from video/sensory data?
Hardware-aware agent memory: Most agent papers ignore GPU constraints
Standardization: No universal API for memory operations (MemOS attempts this)
4. Timeline Evolution
2023: Foundation (MemGPT, PagedAttention, Mamba)
2024: Specialization (Graph RAG, Multimodal, RL-enabled)
2025: Unification (Agentic Memory, SimpleMem, Memory-R1)
Practical Implementation Pathways
For Developers Building Agents:
Start with Layer 2+3: Implement working memory (MemGPT-style) + RAG persistence
Add Layer 4 if needed: Incorporate procedural learning for skill-based tasks
Optimize Layer 1 last: KV cache optimization once context becomes bottleneck
For Researchers:
Focus on gaps: Multimodal procedural memory, hardware-agent co-design
Cross-layer solutions: Systems that address multiple bottlenecks simultaneously
Standardization: Contribute to memory OS frameworks
Final Integration: Hardware Enables Everything
The hardware layer is foundational but often ignored in agent/LLM memory research. This creates a dangerous disconnect:
Theoretical capability (agent papers): “Store all experiences indefinitely”
Practical reality (hardware constraints): 24GB VRAM on consumer GPUs
The most impactful future work will bridge this gap through:
Hardware-aware agent design
Agent-aware hardware design
Unified benchmarking and standards. This unified framework shows that memory bottlenecks require solutions across all layers—from hardware optimization to cognitive architecture design. The most promising recent work (2025) focuses on unified systems that integrate multiple memory types to solve problems holistically rather than in isolation.
The holy grail: An agent memory system that seamlessly scales from mobile phones (6GB) to data centers (terabytes) without algorithmic changes—just like modern operating systems handle memory across diverse hardware.
To this extent, if it hasn’t sunk in yet - Nvidia always wins!!
“Unified benchmarking and standards. This unified framework shows that memory bottlenecks require solutions across all layers—from hardware optimization to cognitive architecture design. The most promising recent work (2025) focuses on unified systems that integrate multiple memory types to solve problems holistically rather than in isolation
I definitely agree here. I've seen a couple of design solutions showing multiple agents with the shared memory architecture and I'm pretty interested in seeing how that would perform.
A lot of agent research quietly assumes infinite memory.
Hardware doesn’t.
As long as we design agents that ignore physical constraints,
we’re doing philosophy, not engineering.
The next real advantage won’t be “better reasoning.”
It will be memory systems designed to fail well.