
The Structure Is The Intelligence
What a 97% Token Reduction Reveals About How Multi-Agent Systems Can Actually Work

What This Experiment Was and Why It Was Run
Most writing about AI agents describes what they could do. This document describes what actually happened when one was built, broken, rebuilt, and measured — across four improvement cycles, three different API configurations, and enough failure modes to fill a postmortem. If you are new to AI agents or to the tooling described here, and have not read either my prior articles or those experimenting/shipping in the “agentic space”, this section is for you. If you are already familiar, you can skip to the Abstract. The results:


Quick Overview: What Is an AI Agent?
An AI agent is a software system built around a language model that can take actions, not just produce text. Where a standard language model answers a question in one step, an agent can run a sequence of steps: look something up, write and execute a piece of code, call an external service, check its own output, revise it, and repeat. The model is the reasoning engine. Everything around it — the instructions it receives, the tools it can use, the memory it can access, the rules governing when it stops — is the architecture.
📖 Plain language — Language model
A language model (like Claude or GPT) is an AI system trained to understand and generate text. It reads your input and produces a response. On its own it does one thing at a time. An ‘agent’ is software built around a language model that lets it take multiple actions in sequence — like a person following a to-do list rather than answering a single question.
The central question in agentic AI design is not which model is smarter. It is how you build the architecture around the model so that the system does useful work reliably and at a cost that makes operational sense. That is what this experiment examined.
The Experiment: StockPilot
StockPilot is a fictional inventory management agent built by Anthropic as a teaching example. It was designed to represent a realistic failure mode: an agent that started as a reasonable prototype and grew over six months as requirements accumulated. Many of us have similar experiences. New rules were added to its instructions. New tools were bolted on. A 20-line prompt became a 402-line one. Three sub-agents were added to handle specialist tasks. By the time the experiment began, StockPilot was a monolith — a single tightly coupled system where everything happened in one place and every task, however simple, carried the full weight of the entire accumulated architecture.
📖 Plain language — System prompt
The system prompt is the set of standing instructions given to the AI at the start of every conversation. Think of it as a job description handed to a new employee on their first day — it tells the AI who it is, what it is allowed to do, and how it should behave. A short, focused system prompt keeps the AI on task. A 402-line one is like handing someone a 40-page manual before every single meeting, whether or not any of it is relevant.
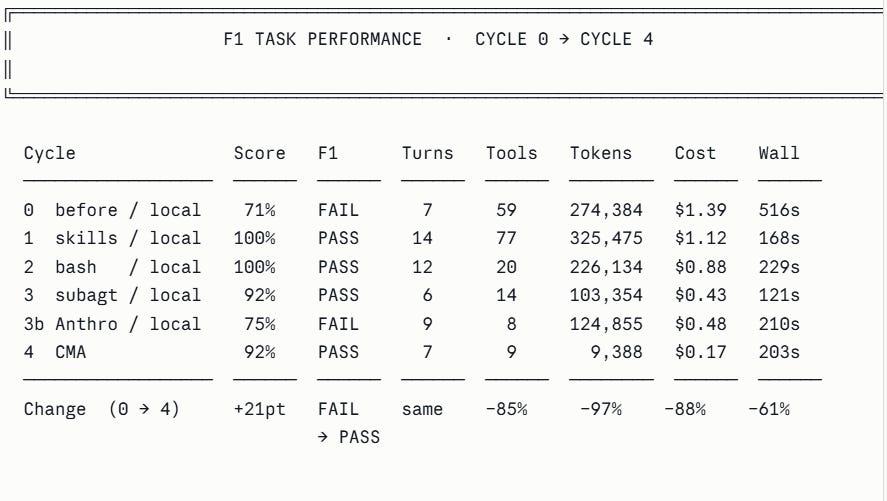
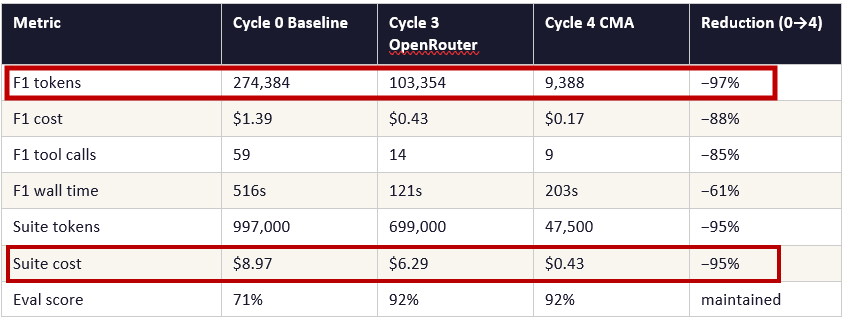
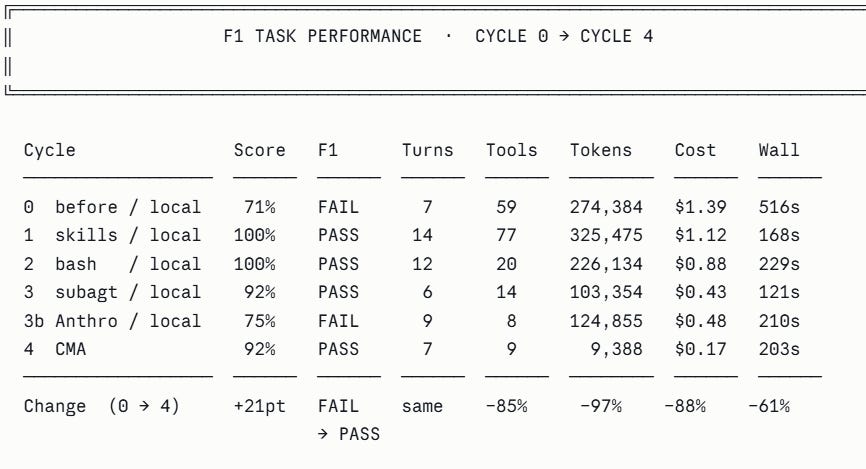
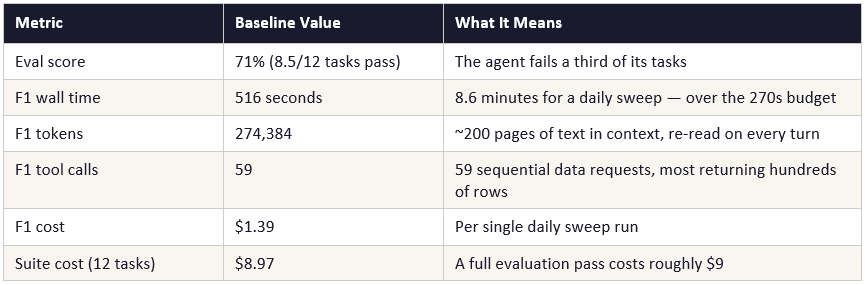
Running StockPilot’s daily inventory sweep took 8.6 minutes, consumed the equivalent of approximately 200 pages of text in model context on a single run, made 59 separate data requests, and cost $1.39. It failed its quality evaluation 29% of the time. The experiment asked: what happens if you systematically take this apart and rebuild it properly?
The Method: Progressive Decomposition
Rather than rebuilding from scratch, the experiment applied a structured decomposition over four cycles. Each cycle changed one thing, measured the result, and documented both what improved and what broke. The improvement framework used three diagnostic questions:
Is this tool returning raw data when it should be returning a filtered answer?
Is this policy instruction always loaded even when it is irrelevant to the current task?
Is this sub-agent running unconditionally when it should only run when needed?
The answer to each question pointed to a specific architectural fix. The fixes were applied in sequence and measured with a real evaluation suite of 12 tasks.
The Complication: Three Different API Configurations
While the experiment borrows heavily from the one Anthropic ran, it has been adapted to emphasize particular issues faced commonly in large organizations. It has variations in terms of how it was run, initially because of legacy systems already in place, preferences of those running these experiments, and operating manuals that dictated particular flows. I will not justify them. Because of it, however, the observations and evolutions that arose ended up giving some fascinating results, so my focus will be on this.
For reference if you have the time:
Experiment Source
Anthropic cwc-workshops — Agent Decomposition: github.com/anthropics/cwc-workshops/tree/main/agent-decomposition
Workshop video walkthrough: youtu.be/mWvtOHlZM-I
While Sonnet 4.6 was applied consistently throughout, the experiment ran without an Anthropic API key (directly from Anthropic), initially. Instead it used Anthropic’s API Key via OpenRouter. Legacy operating, compliance and workflows systems, added constraints and limitations. Understandably, some of it had something to do with rate limits, auth failures, regional issues etc. So Anthropic’s API Key via OpenRouter was deployed as fallback. If you want to understand why anybody does this, read Pawel Jozefiak.
Becuase of this, most if not all model calls (for this exercise) were routed through OpenRouter — a third-party service providing access to AI models via a unified API. When a direct Anthropic key became available mid-experiment (after compliance approval), a second configuration was tested. Then, with Claude Managed Agents, a third was tested. Each configuration produced meaningfully different results — not because the model changed, but because the execution infrastructure changed.
📖 Plain language — API
An API (Application Programming Interface) is a standardised way for software systems to talk to each other. When this experiment calls Claude, it sends a request to Anthropic’s API — essentially a structured message over the internet — and receives a structured response back. OpenRouter is a service that sits in the middle: you send your request to OpenRouter, it forwards it to one of several AI providers (Anthropic, Amazon Bedrock, Google Vertex), and returns the result - see below sample runs. This is convenient for reliability — if one provider is down, another takes over — but it adds complexity when features like caching behave differently across providers.
Prior Context: The ASCRS Experiments
This experiment does not exist in isolation. It was preceded by a series of architecture design exercises and controlled benchmark experiments run against a pharmaceutical supply chain scenario — the ASCRS series (Architecture of Awareness, April 2026; ASCRS Harness Lab, May 2026). That series explored similar questions about agent architecture from a different angle: rather than decomposing a failing system, it compared ten different architectural patterns on a fresh task. Its headline finding — that a well-written single prompt outperformed a five-agent specialist swarm — appears to contradict the StockPilot findings.
The apparent contradiction dissolves once the task types are distinguished. Section 7 addresses this directly.
Key Results & Learnings at a Glance
If you have no time and for those who want the conclusions before the evidence, the twelve most important findings from this experiment are listed below. Each is explained in full in the relevant following sections. The results are summarized and the evolution:






The Evaluation Suite: What Was Being Tested and How
Before examining what the experiment found, it is worth understanding how the experiment measured anything at all. The quality of a finding depends entirely on the quality of the measurement. This section explains the 12-task evaluation suite used in the StockPilot experiment, and — for context — how evaluating an AI agent differs structurally from evaluating a standard language model.
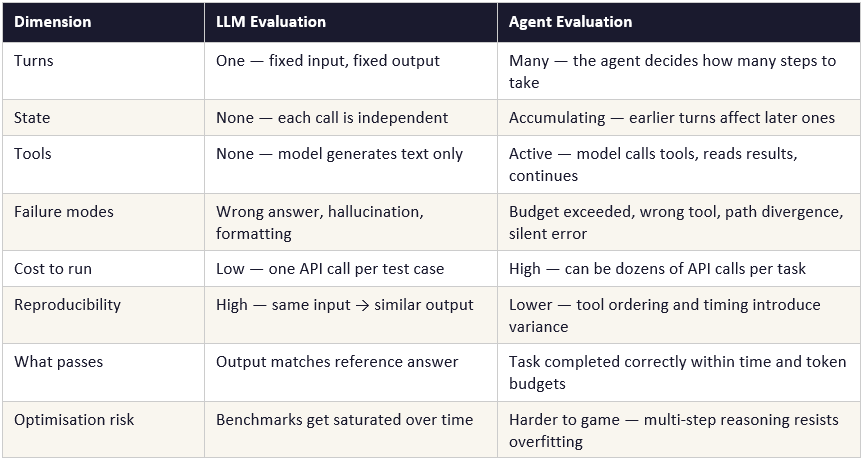
Evaluating Language Models vs Evaluating Agents: The Structural Difference
When researchers benchmark a language model — testing whether GPT-5.5 or Claude Opus 4.7 is better at summarising legal documents, or answering medical questions — the methodology is relatively straightforward. You feed the model a fixed input, collect its output, and compare that output against a known correct answer. One turn. Fixed context. Deterministic measurement.
📖 Plain language — Benchmark
A benchmark is a standardised test used to compare AI models. Like a driving test that every candidate takes under the same conditions, a benchmark gives every model the same questions so you can compare scores fairly. The limitation is that models can effectively ‘study for the test’ — if a benchmark is used long enough, the companies building models start optimising specifically for that test rather than for genuine capability.
Evaluating an AI agent is structurally different in almost every dimension.
📖 Plain language — Hallucination
When an AI model produces information that sounds plausible but is factually wrong — often stated with full confidence — this is called a hallucination. The model is not lying; it is pattern-matching to what a correct answer would look like without actually knowing the correct answer. In agent systems, hallucinations are particularly dangerous because the agent may act on false information rather than just stating it.
The last point in the table is significant. Language model benchmarks have become increasingly unreliable as a signal of genuine capability because frontier models effectively train on benchmark distributions. An agent eval suite is harder to saturate — the agent must navigate a multi-step task correctly, which requires genuine reasoning rather than pattern matching to a fixed answer format.
The cost, however, can be substantially higher, when scalled. In this case, running a 12-task agent eval suite in this experiment cost $8.97 at baseline. Running a comparable LLM benchmark would cost a fraction of that. This is why agent eval suites tend to be smaller, more carefully curated, and more domain-specific than language model benchmarks — each test case is expensive, so each must be individually informative.
⚠ The Budget Constraint: Why Agents Need Hard Limits
Standard LLM evaluation has no concept of a budget — the model produces an answer or it doesn’t.
Agent evaluation requires explicit budget constraints because agents can loop indefinitely.
StockPilot’s eval harness enforces two hard limits per task:
• Turn budget: a maximum number of agent-model exchanges (typically 5–10 depending on task)
• Wall time budget: a maximum clock time (270 seconds for the F1 daily sweep)
If either limit is exceeded, the task fails — regardless of the quality of work done so far.
F1 failed at baseline not because the agent gave a wrong answer, but because it took 516 seconds to produce an answer the eval harness never received.
📖 Plain language — Wall time
Wall time is the actual elapsed clock time from when a task starts to when it finishes — named after a clock on the wall. This is distinct from the processing time inside the computer. Wall time includes network round trips, waiting for API responses, and any pauses between steps. An agent that takes 516 seconds of wall time has kept the user waiting 8.6 minutes for a daily task that should complete in under 5.
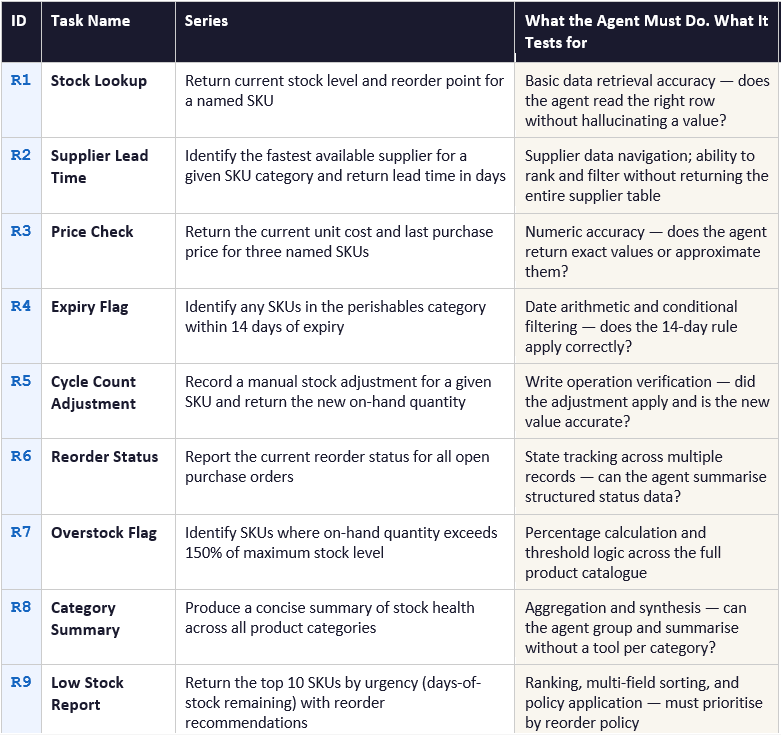
The 12 Tasks: What Each One Tests
The evaluation suite is divided into two series. The R-series (nine tasks) tests retrieval and reporting operations — shorter, lower-token tasks that verify the agent can correctly read, interpret, and communicate inventory information. The F-series (three tasks) tests fulfillment and decision-making operations — complex multi-step tasks requiring the agent to reason across multiple data sources, apply policies, and produce actionable output.
📖 Plain language — SKU
SKU stands for Stock Keeping Unit — it is simply the unique code that identifies a specific product in an inventory system. When a supermarket tracks how many tins of a particular brand of soup it has, each size and variety gets its own SKU. StockPilot manages 250 SKUs, meaning 250 distinct products, each with its own stock level, reorder point, and supplier information.

📖 Plain language — Purchase order / PO
A purchase order is a formal request from a buyer to a supplier asking them to provide a specific quantity of goods at an agreed price. In inventory management, when stock runs low, the agent should generate a purchase order to trigger restocking. Think of it as the AI equivalent of a manager filling in a requisition form — but instead of pen and paper, it produces a structured data record.
How the Evaluation Harness Scores the Agent
Each task has a pass/fail outcome determined by the eval harness — a separate piece of code that runs the agent, monitors its resource usage, and inspects its output. The harness uses deterministic rules where possible and structured output inspection where not:
R1 passes if the returned stock value matches the CSV to within rounding tolerance
R9 passes if the top-10 list is correctly ordered and each entry includes a reorder recommendation flag
F1 passes if it completes within 270 seconds and produces recommendations for all critical SKUs
F3 passes if the output file exists at the expected path and contains the correct number of notification records in the correct format
📖 Plain language — Eval harness
An eval harness is the testing framework that runs an AI agent through a set of tasks and measures the results. Like a laboratory test rig, it controls the conditions, records what happens, and reports the outcome. It is separate from the agent itself — importantly, the harness does not use the same AI model to score the results, because a model grading its own outputs would be like a student marking their own exam.
The Plusses and Minuses of Agent Evaluation
What agent evals do well
Capture real operational failure modes: Budget overruns, path mismatches, silent tool errors, and environment-dependent behaviour are invisible to standard model benchmarks. Agent evals surface the failures that matter in production.
Harder to game: Multi-step task completion requires genuine reasoning. It is difficult to improve an agent’s score by memorising answer patterns.
Measure efficiency alongside correctness: Token count, wall time, tool calls, and cost are first-class metrics. A language model eval has no equivalent — there is no concept of a correct answer that cost too much to produce.
Reveal architectural failures that unit tests miss: F3’s consistent local failure was invisible to code review. Only the eval caught it — and only because the eval ran in the intended execution environment.
What agent evals do poorly
Cost: At baseline, 12 tasks cost $8.97. Running this suite in a CI/CD pipeline on every code change is economically impractical without significant optimisation.
Variance: Agent behaviour is not fully deterministic. The same agent on the same task may take different numbers of turns or call tools in a different order. A single-run eval score is a point estimate, not a reliable measure.
Environment sensitivity: Eval results can be invalidated by environment mismatches that have nothing to do with agent quality — as F3 demonstrated.
Interpretability: When a task fails, the reason requires manual investigation of the execution trace. An agent failure might be a reasoning error, a tool failure, a budget overrun, a path mismatch, or a silent exception.
Coverage cost: Designing a high-quality agent eval suite requires domain expertise. The StockPilot suite was provided by Anthropic as part of the workshop. Building an equivalent from scratch is a significant investment.
📖 Plain language — CI/CD pipeline
CI/CD stands for Continuous Integration / Continuous Deployment — a software engineering practice where every code change is automatically tested before it goes live. Running agent evals as part of a CI/CD pipeline would mean that every time a developer changes the agent’s code, the full 12-task suite runs automatically to check nothing broke. At $8.97 per run, that adds up quickly if code changes happen dozens of times per day.
Abstract/Overview
This document is a technical teardown of a five-cycle agent decomposition experiment run against Anthropic’s StockPilot workshop codebase — a monolithic inventory management agent with a 402-line system prompt and 12 tools. The experiment was conducted across three API configurations: OpenRouter proxy, direct Anthropic API, and Claude Managed Agents (CMA). Every failure is documented alongside the fix.
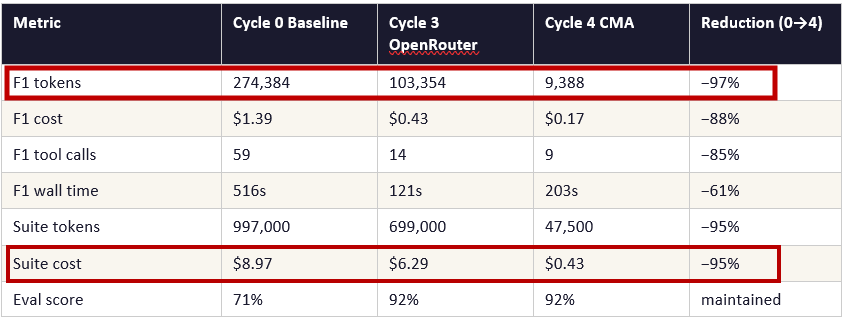
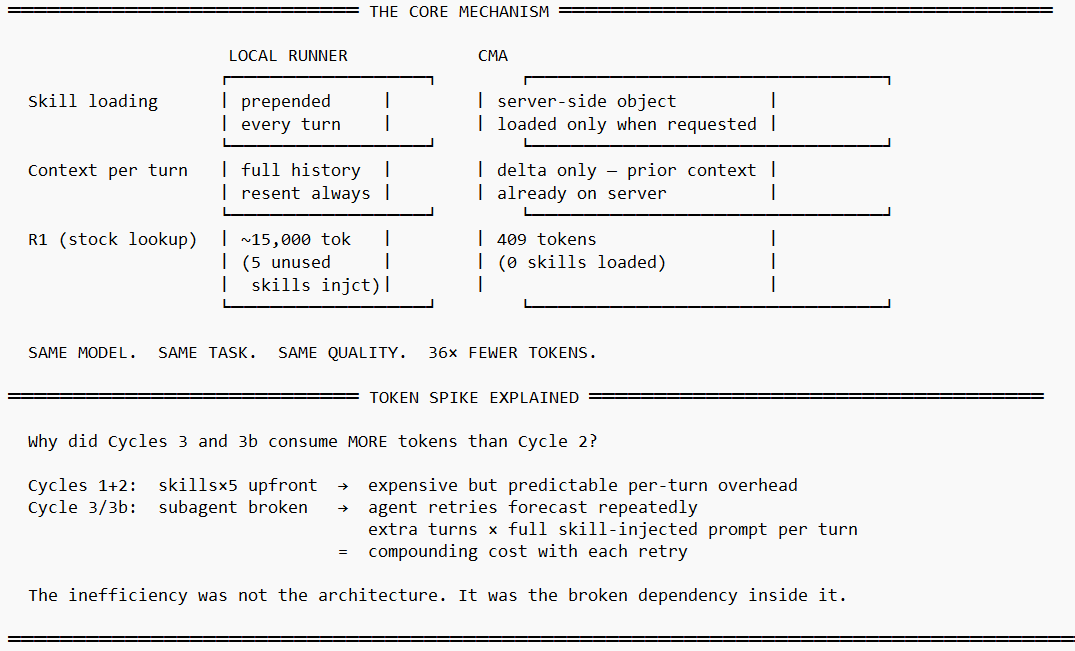
The headline finding is not so much the 97% token reduction — though that number is real and the mechanism is explained. The more significant finding is structural: Claude Managed Agents is not, as many misunderstand - only a cloud hosting service or an inference wrapper. It is a purpose-built agent runtime with server-side session state, native tool execution, sandboxed per-session containers, and an on-demand skill loading architecture that makes context cost proportional to task complexity rather than to the total knowledge the agent holds. And you have to have something break, to appreciate it’s optimizations.
This distinction matters because the common reading of ‘managed agents’ assumes the ‘managed’ part refers to only compute management. More imporantly it refers to execution state management. The difference in token economics between a local runner and CMA is not primarily model-level; it is infrastructure-level. That gap does not close by adding prompt caching to a stateless API wrapper. It closes by changing the execution model.
A note on prior context: these findings are in dialogue with the ASCRS Harness Lab, which ran ten harness architectures against a pharmaceutical supply chain scenario using OpenRouter throughout. That experiment found that a well-written prompt (H2, α=1.000) outperformed a five-agent swarm (H9, α=0.625) on a single-turn document task. Both findings are correct and complementary. The distinction — greenfield document task versus brownfield operational agent — is addressed in Section 7.
1. The Starting Condition: What a Monolithic Agent Costs
The StockPilot baseline is not a contrived worst case. It represents how agentic systems actually grow in organisations: a prototype that worked, to which requirements were added one at a time without reconsidering the core architecture. Over six months the system prompt grew to 402 lines. The tool count reached 12. Three sub-agents were hardcoded to run on every invocation regardless of whether the task needed them.
📖 Plain language — Token
A token is the basic unit of text that a language model processes — roughly three-quarters of a word, or about four characters. ‘Hello world’ is approximately 2–3 tokens. Processing tokens costs money: the more tokens in context on each turn, the higher the per-turn cost. 274,384 tokens is roughly equivalent to a 220,000-word document — about two average novels — being re-read by the model on a single task run.
The 402-line prompt as a liability
The system prompt contained genuinely useful domain knowledge — reorder logic, supplier scoring, notification templates, forecast contracts — embedded as prose the model re-parsed on every turn of every task. A stock level lookup was preceded by 15,000 tokens of policy context it would never use.
Tools that return data instead of answers
The most expensive tool was list_low_stock, which returned a 400-row CSV table directly into the model’s context window. The agent then reasoned across all 400 rows to find the 8–12 that required action. By turn 15 of an F1 run, the context contained several complete tables the model had already processed — billed again at full price on every subsequent turn.
📖 Plain language — Context window
The context window is the total amount of text a model can ‘hold in mind’ at once — everything it can see when formulating its next response. This includes the system prompt, the entire conversation history, and all tool results so far. Think of it as working memory. A large context window means the model can handle longer conversations — but every token in context costs money on every turn, even if most of it is irrelevant to the current step.
Hardcoded sub-agents as unconditional overhead
Three sub-agents ran on every task regardless of whether the task needed their specialisation. A sub-agent is a separate model call — a second AI process invoked inside the first. Each added a full API round trip, its own context initialisation, and its output as prose into the parent agent’s context. For tasks that needed none of this, the overhead was pure cost with no quality benefit.
📖 Plain language — Sub-agent
A sub-agent is a separate AI model call made from within the main agent’s execution. The main agent (’orchestrator’) delegates a specific task to a sub-agent, receives the result, and continues. Think of it as a manager who, instead of doing everything themselves, sends individual questions to specialists and collects their answers. The benefit is isolation — the specialist only sees what it needs to. The cost is an additional API call and the risk that the specialist’s answer needs to be merged coherently with the main agent’s work.
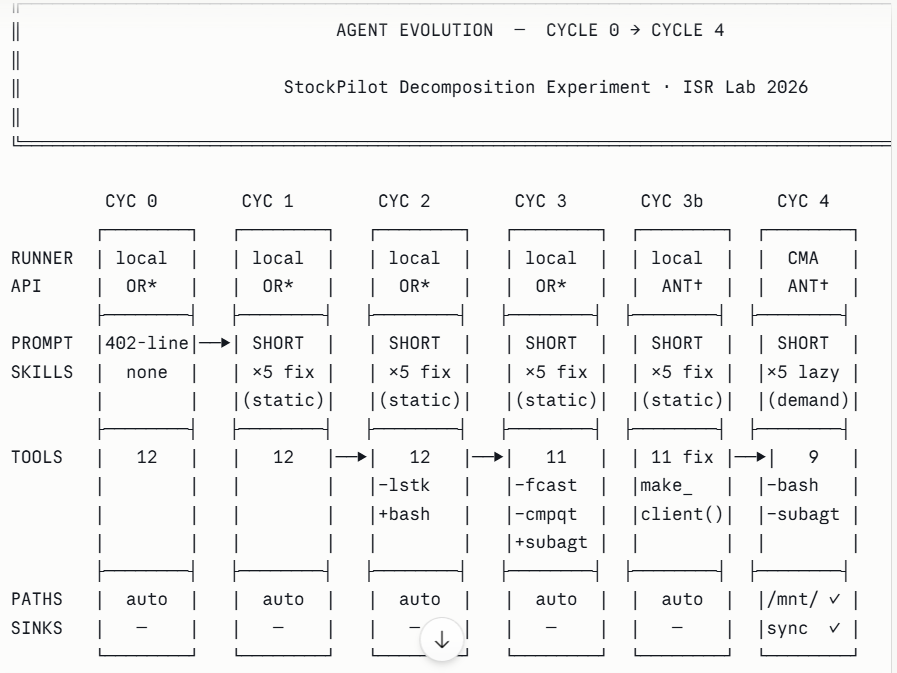
2. The Decomposition Progression: Cycle by Cycle
The experiment ran four improvement cycles. Each cycle applied one architectural change, measured the result, and logged both the gain and any new failure mode introduced.
🔍 The Three Diagnostic Questions
1. Does this tool return more than ~2,000 tokens of raw data?
Replace with a code execution tool that filters at source.
2. Is this policy instruction only relevant to some tasks?
Extract from the system prompt into a skill file loaded on demand.
3. Does this sub-agent run regardless of whether the current task needs it?
Convert to an explicit callable with a typed output contract, invoked conditionally.
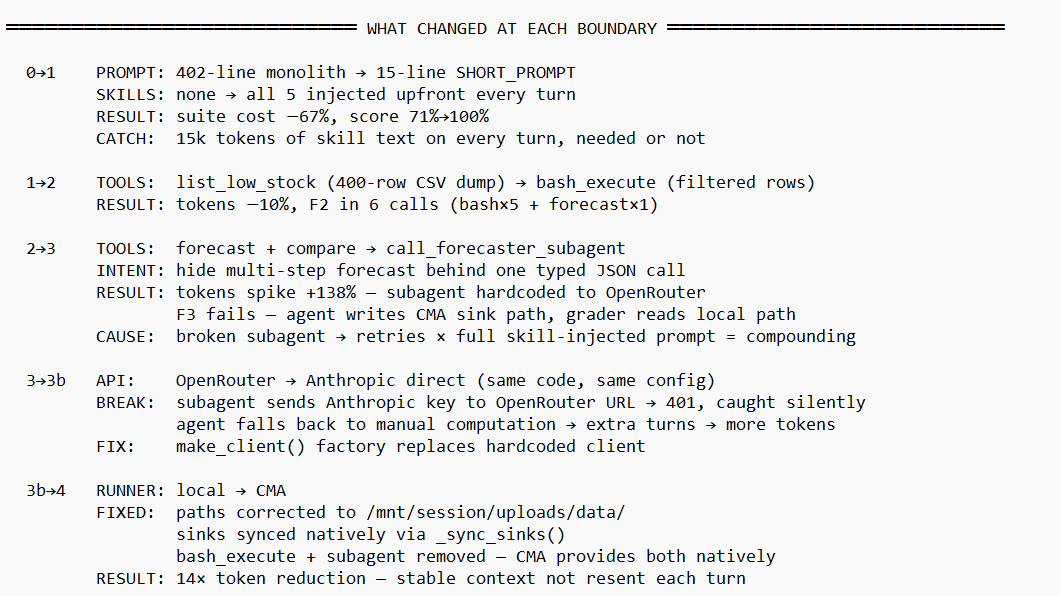
Cycle 1 — Policy as Skills
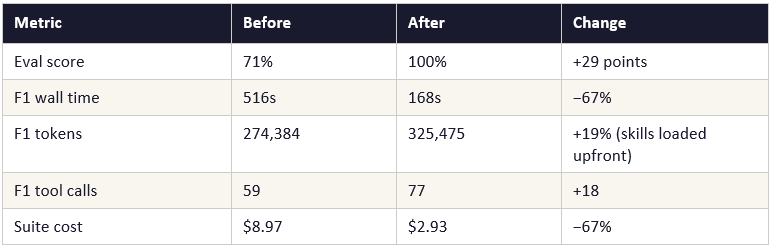
The 402-line prompt was replaced with a 15-line orientation prompt. Domain policies were extracted into five skill files. Score jumped to 100% immediately — not from token optimisation but from eliminating policy confusion. F1 tokens increased because all skill files were injected upfront into the system prompt, carrying 15,000 tokens of context per turn per task whether needed or not. Quality improved; cost did not yet.
📖 Plain language — Skill file
A skill file is a document containing specialised instructions or policy rules that an agent loads only when it needs them. Instead of the system prompt listing every possible rule the agent might ever need, the system prompt simply lists which skill files exist. When the agent encounters a task that requires the reorder policy, it reads that file. Simple tasks never load any skill files at all. This is the difference between giving an employee a 400-page manual to carry everywhere versus telling them where the manuals are stored and letting them look things up when needed.
Cycle 2 — Compute Over Context
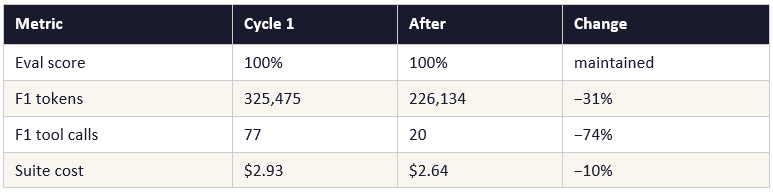
list_low_stock replaced with bash_execute — a tool that runs a Python filter script and returns only the rows that matter. Tool calls for F1 dropped from 77 to 20. The principle: a tool whose return value exceeds ~2,000 tokens is a context liability. Replace it with code that filters at source.
📖 Plain language — Bash / Python script
Bash and Python are programming languages. Bash is used to run commands in a terminal; Python is a general-purpose language commonly used for data processing. In this context, instead of the agent asking ‘give me all 400 rows of inventory data’, it now writes a small Python program that asks ‘give me only the 8 rows where stock is below the reorder point’ — and only those rows come back. The filtering happens in code, not in the model’s head.
Cycle 3 — Explicit Sub-agent Delegation
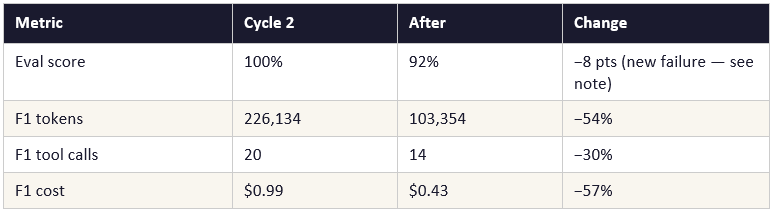
Two hidden sub-agents replaced with one explicit sub-agent returning structured JSON. The parent agent’s context received the answer only — never the reasoning chain. F1 tokens dropped 54% in a single cycle. F3 began failing because the agent wrote output to the CMA sandbox path while the local eval grader read from a different location. This is the correct signal that the architecture had reached the boundary of what a stateless subprocess can reproduce.
📖 Plain language — JSON
JSON (JavaScript Object Notation) is a standardised text format for structured data. Instead of returning a paragraph of prose — ‘I recommend ordering 200 units of SKU-0183 from Supplier A’ — the sub-agent returns {”SKU-0183”: 200, “supplier”: “A”}. This is machine-readable, unambiguous, and cannot accidentally include stray reasoning text that would inflate the parent agent’s context. The parent agent reads the number, not the explanation.
3. The OpenRouter Interlude: What a Proxy API Costs You
Cycles 1 through 3 ran on OpenRouter — a multi-model routing service providing access to Claude via a unified API. This is a common starting configuration. The experiment made the practical costs concrete.
SDK format mismatch
The workshop code was written using Anthropic’s Python library. OpenRouter uses the OpenAI message format. A compatibility adapter had to be written to translate every request and response between the two formats — adding maintenance surface and creating failure points invisible until the environment changes.
📖 Plain language — SDK
An SDK (Software Development Kit) is a pre-built library of code that makes it easier to interact with a specific service. Anthropic’s SDK handles the details of formatting requests, sending them, and parsing responses so developers don’t have to write that plumbing from scratch. The problem here is that Anthropic’s SDK speaks one format and OpenRouter expects a different format — requiring a translation layer between them.
Model naming
Anthropic model names use hyphens: claude-sonnet-4-6. OpenRouter prefixes the provider: anthropic/claude-sonnet-4-6. Using a dot — claude-sonnet-4.6 — returns a 404 error as raw HTML rather than a structured error message. The kind of failure that surfaces as a confusing library-level exception.
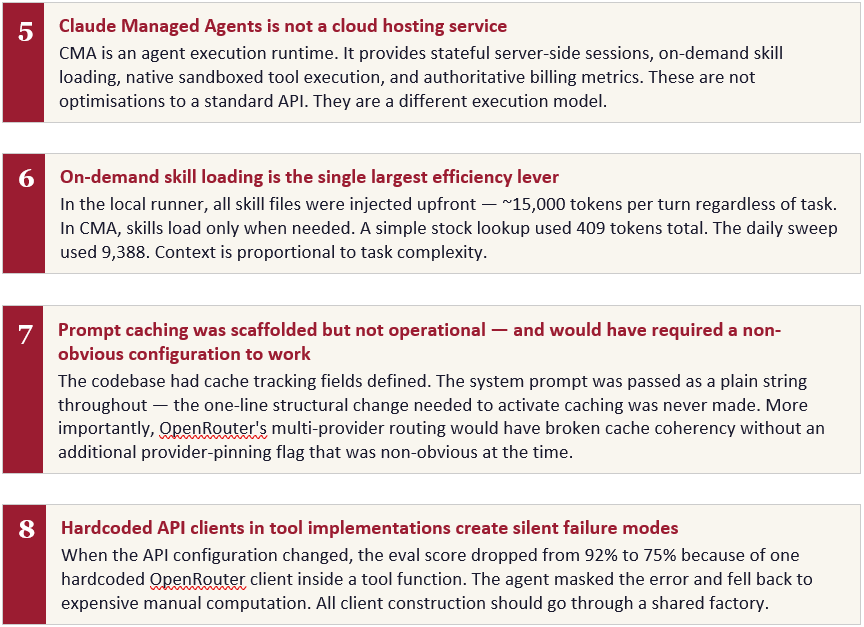
Prompt caching: scaffolded but not operational
What we had right: cache_control: {"type": "ephemeral"} in the code. That is the correct implementation. On its own, that should have worked.
What undermined it: OpenRouter’s default behaviour was routing requests across Anthropic direct, Amazon Bedrock, and Google Vertex AI — rotating between providers for resilience. Prompt cache entries are provider-specific and session-specific. A cache written on an Anthropic-routed turn is invisible on the next turn if OpenRouter routes that request to Bedrock or Vertex. So the sequence looked like this:
Turn 1 → Anthropic direct → cache written at 1.25× cost
Turn 2 → Bedrock → cache miss, full price paid, new cache written at 1.25×
Turn 3 → Vertex → cache miss again, full price paid
Net result: paying cache write cost repeatedly with near-zero cache reads
The missing piece — allow_fallbacks: false: Pinning all requests to a single provider via allow_fallbacks: false in the extra_body would have fixed this. That is the configuration decision that was non-obvious — it requires knowing that OpenRouter’s multi-provider routing breaks cache coherency, which is documented but not prominently. This may give you pause when considering vendor lock-in.
The honest summary: The cache_control implementation was correct. The provider rotation silently neutralised it. The fix required a separate configuration flag whose necessity was not apparent from the caching documentation alone. A developer following Anthropic’s caching guide correctly, then routing through OpenRouter without reading the provider-pinning documentation, would hit exactly this outcome.
Caching was implemented but silently broken by provider rotation, and the fix required knowing to set a flag that the caching documentation does not mention.
The correct configuration — cache_control on the system prompt block plus provider pinning — was available and would have worked. In cycles 1 and 2, where five skill files were injected into the system prompt on every turn (approximately 15,000 stable tokens), the reduction from turn 2 onward on that portion alone would have been approximately 92%. The total suite reduction for those cycles would have been in the range of 40–60%.
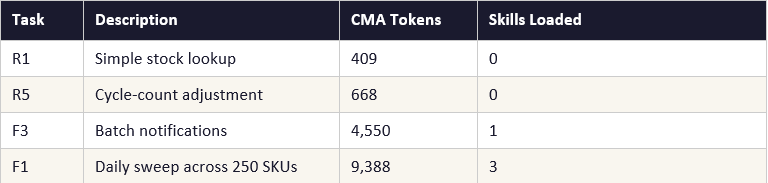
The reason this still falls well short of CMA’s 93% suite-level reduction is structural rather than implementation. Explicit prompt caching requires transmitting the full context on every turn and paying 10% of the standard rate to re-read the cached portion. CMA’s stateful sessions do not re-transmit stable context at all — it is already on the server. For a multi-turn agent running 10–15 turns per task, that difference compounds. The R1 task landed at 409 tokens on CMA precisely because the agent received only the new user message — not the system prompt plus skill files on every turn.
📖 Plain language — Prompt caching
Prompt caching is a cost-saving mechanism where repeated text that appears in multiple API calls is stored temporarily so the model does not have to process it from scratch each time. If a 15,000-token system prompt is sent on every turn of a 15-turn task, you normally pay for 15,000 tokens × 15 turns = 225,000 tokens. With caching, turns 2–15 read that text from cache at 10% of the standard rate — effectively paying for it once at full price and then 14 more times at a 90% discount. The catch is that the cache is only valid for the same provider, and only for 5 minutes to 1 hour depending on the configuration chosen.
4. The Hidden Hardcoding Problem: Cycle 3b
When a direct Anthropic key replaced OpenRouter, the eval score dropped from 92% to 75%. The cause: a hardcoded OpenRouter client inside the forecaster tool function. With the OpenRouter key absent, the function sent the Anthropic key to OpenRouter’s server — which rejected it with a 401. The agent’s error handler caught this silently, returned a structured error, and the main agent fell back to expensive manual computation. F1 went from 6 turns and 103,354 tokens to 9 turns and 232,000 tokens.
📖 Plain language — 401 error / Authentication error
HTTP 401 means ‘unauthorised’ — the server received a request but rejected it because the credentials (the API key) were wrong or missing. In this case the Anthropic key was valid, but it was being sent to OpenRouter’s server, which does not accept Anthropic keys. The server’s response was essentially ‘I don’t recognise this key’ — but because the error was caught and swallowed silently by the code, the main agent never knew its sub-agent had failed.
Fix: replace the hardcoded client with the shared factory function. One import change. Tokens returned to 124,000. Principle: all API client construction should go through a shared factory that reads from the environment. Hardcoded clients create failure modes that only surface when the environment changes — the worst possible moment for silent degradation.
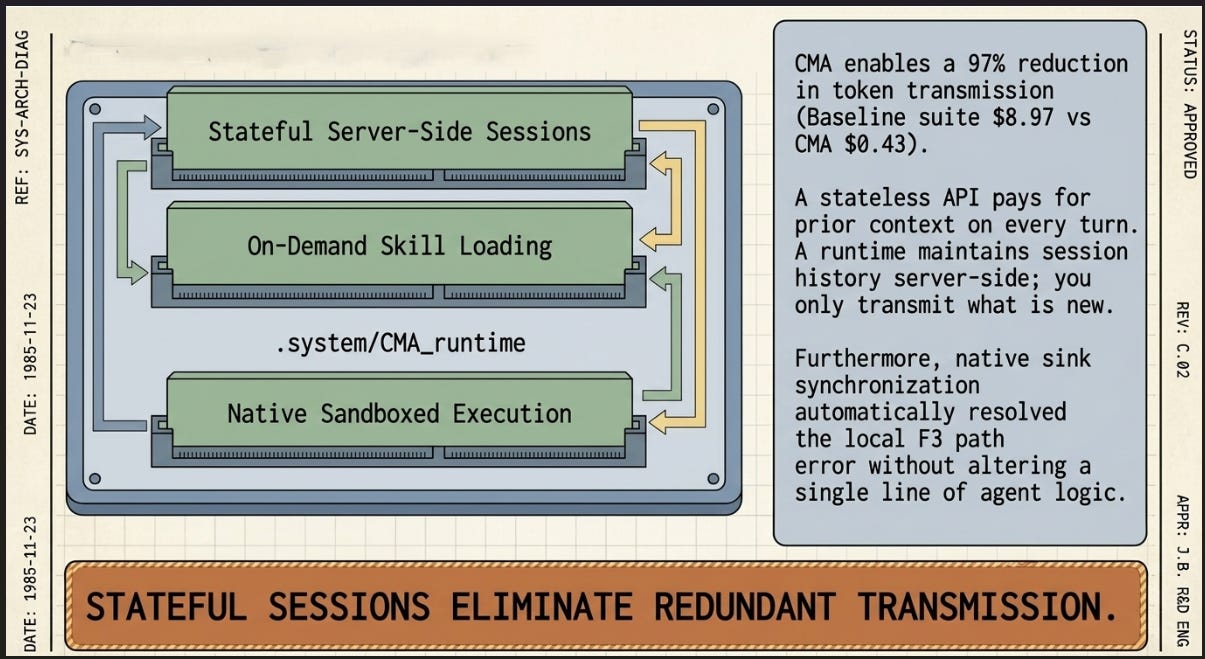
5. What Claude Managed Agents (CMA) Actually Is
The reasonable assumption — the one this experiment started with — is that ‘managed’ refers to compute management: Anthropic hosts the model, handles scaling, manages infrastructure. CMA is a premium API tier.
That reading is wrong. CMA is not a hosting service. It is an agent execution runtime.
💡 Plain Language: What ‘Execution Runtime’ Means
A standard API call is stateless. You send everything the model needs to know — the full history, the system prompt, all prior tool results — on every turn. The server processes it and forgets.
Next turn: send everything again. The context window grows; you pay for all of it each time.
An execution runtime is different. It maintains the session between turns. The history stays on the server. You send only what is new. The prior context is already there. For agents running many turns across complex tasks, this distinction has large cost implications.
Every turn of a stateless API call pays for all prior context again.
A runtime pays only for the new.
1. Stateful sessions — no history resending
In a standard API loop, the context window grows with every turn and the billing system charges for everything sent each time. By turn 15 of an F1 run, the system re-reads 30,000 tokens the model has already processed 14 times. CMA sessions are stateful server-side — only the new delta is transmitted. Prompt caching reduces the cost of resending context. Stateful sessions eliminate the resending. These are different mechanisms.
📖 Plain language — Stateful vs stateless
Stateless means the server keeps no memory between requests — each call starts fresh. Stateful means the server remembers the session. A good everyday analogy: calling a customer service number where you have to re-explain your problem from scratch every time you’re transferred is stateless. A dedicated account manager who already knows your history is stateful. For AI agents, stateless is cheap to implement but expensive at scale; stateful requires infrastructure but pays back in efficiency.
2. On-demand skill loading — context proportional to task
In the local runner, skill files were injected into the system prompt at session start — 15,000 tokens of context per turn regardless of task. In CMA, skills are server-side objects loaded by the agent only when needed:
3. Native sandboxed tool execution
The local bash_execute tool was a Python subprocess wrapper — functionally correct for evaluation, not appropriate for production. CMA provides a native Bash tool running inside a per-session ephemeral container with no network access and read-only data mounts. No subprocess security risk; no shared state between sessions.
📖 Plain language — Sandbox / Ephemeral container
A sandbox is an isolated execution environment — like a locked room where the AI can run code but cannot access anything outside it. ‘Ephemeral’ means it exists only for the duration of the task and is discarded afterwards. This matters for security: if an agent writes code that has unintended consequences, those consequences are contained within the sandbox and disappear when the session ends. It also matters for consistency: each task starts with a clean slate, not leftover state from previous runs.
4. Authoritative billing metrics
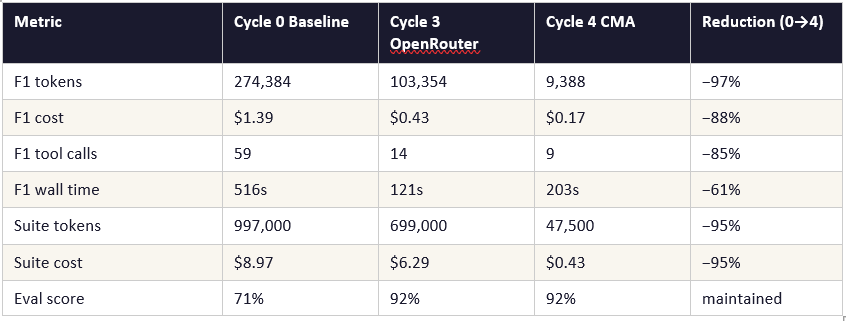
The local runner summed raw tokens sent per turn — transmission cost, not billing cost. CMA retrieves the authoritative billed total post-session including all cache effects. Cycle 3 local: 103,354 reported tokens. Cycle 4 CMA: 9,388 billed tokens. One is what was sent; the other is what was charged.
6. Cycle 4 — CMA: The Full Numbers
With CMA available and a direct Anthropic key active, one configuration correction was required: the system prompt specified a data path for the local runner. In the CMA sandbox, files are at a different absolute path. Without correcting this, the agent spent three tool calls searching for data before doing any actual work — bringing F1 wall time to 368 seconds (budget exceeded). After the path correction: 203 seconds.
🔶 Hypothetical: What prompt caching would have recovered
The table above shows three actual configurations. A fourth scenario — cycles 1 and 2 with prompt caching correctly applied — would have sat between the OpenRouter and CMA columns:
Cycle 1-2 suite cost with caching: ~$1.20–$1.75 (vs $2.64–$2.93 without, vs $0.43 on CMA)
F1 token reduction on stable skill content: ~92% on re-read turns (15k token skill block at 0.1× from turn 2 onward)
Total suite reduction vs baseline: ~40–60% (vs CMA’s 95%)
Why it falls short of CMA: caching still requires transmitting the full context every turn — you pay 10% to re-read the cached portion rather than 100%, but you still send it. CMA’s stateful sessions eliminate the transmission entirely. That structural difference accounts for the remaining gap.
The missing precondition: caching would also have required pinning requests to a single provider via allow_fallbacks: false. Without that pin, OpenRouter’s multi-provider routing (Anthropic / Bedrock / Vertex) would have written cache entries on one provider and missed them on the next — net result: slightly higher cost than no caching at all.
F3 passed cleanly in CMA without any change to agent logic — CMA’s native sink synchronisation resolved the path mismatch automatically. F1 wall time is slightly longer on CMA (203s) than cycle 3 locally (121s) due to approximately 40 seconds of container provisioning overhead per session. For the suite as a whole this adds roughly 8 minutes of initialisation time across 12 tasks.
📖 Plain language — Session overhead
Session overhead is the setup cost paid at the start of each task run. CMA provisions a fresh, isolated container for every session — essentially spinning up a clean temporary computer for the agent to work in. This takes approximately 40 seconds. For a task that runs for 5 minutes, 40 seconds of setup is a small fraction of total time. For a very short task, the overhead is proportionally larger. It is the price of the clean-room isolation that makes CMA’s per-session guarantees possible.
7. In Dialogue: The ASCRS Harness Lab
The ASCRS Harness Lab ran ten harness architectures against a pharmaceutical supply chain crisis task — producing a CFO-approvable rerouting brief within six hours when the Strait of Hormuz shipping corridor was disrupted. H2 (a well-structured prompt, α=1.000 at 15,277 tokens) outperformed H9 (a five-agent swarm, α=0.625 at 58,090 tokens).
📖 Plain language — α (alpha) score
In the ASCRS Harness Lab experiments, α (the Greek letter alpha) is the quality score: a number between 0.0 and 1.0 measuring how well the agent’s output met the defined criteria. α=1.000 means a perfect score; α=0.625 means the output met about 63% of the quality criteria. The score is produced by a separate AI model that reads the output and grades it against a rubric — crucially, this scorer model is different from the model that produced the output, to prevent self-grading inflation.
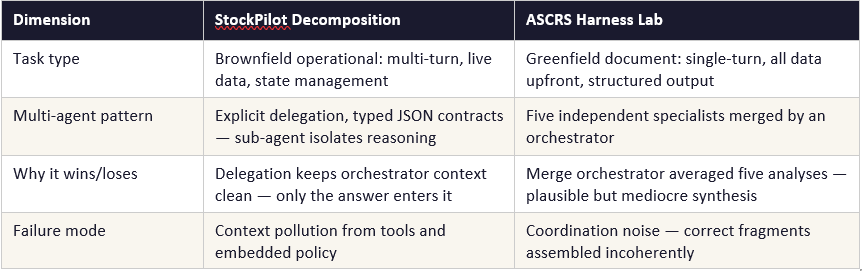
The StockPilot decomposition shows multi-agent architecture outperforming a monolith. The ASCRS experiment shows a single prompt outperforming a multi-agent architecture. How can both be true? Task structure.
📖 Plain language — Brownfield vs greenfield
In software and engineering, greenfield means starting from scratch with no legacy constraints — a clean field with nothing built on it yet. Brownfield means working within or alongside an existing system — a field that already has buildings on it. In AI agent terms: a greenfield task has all the data available upfront and requires producing a single well-formed output. A brownfield task is an ongoing operational system that must interact with live data, existing databases, and real-world state that changes as the agent works.
The ASCRS swarm (H9) failed because the orchestrator reconciled five independent analyses by averaging them — every quality criterion scored exactly 0.5. The StockPilot sub-agent delegation worked because it produced a typed JSON answer consumed directly by the parent agent. No merge step. No coordination noise. Architecture must match the task’s coordination requirements.
8. Thoughts
CMA is an execution runtime, not a hosting service: The 97% token reduction is attributable to stateful sessions, on-demand skill loading, native tool execution, and authoritative billing metrics — a different execution model, not API-level optimisations.
Prompt caching on a stateless API does not replicate CMA’s state management: Caching reduces the cost of resending context. Stateful sessions eliminate the resending. Even with correct implementation and provider pinning, caching would have recovered ~40–60% in cycles 1–2. CMA recovered 95%.
Skills improve reasoning quality immediately — but token cost only when loading is on-demand: Cycle 1 improved score from 71% to 100% without reducing tokens. The mechanism for quality improvement is separate from the mechanism for cost improvement. Both require different implementation choices.
Hardcoded API clients in tool implementations create silent failure modes: One hardcoded client in one tool function caused a 17-point score regression when the API configuration changed. The failure was masked by error handling. All client construction should go through a shared factory.
Agent evals surface failures that LLM benchmarks cannot: Budget overruns, path mismatches, silent tool errors, and environment-dependent behaviour are invisible to standard model benchmarks. Agent eval suites are more expensive to run but capture the failure modes that matter in production.
Architecture must match task structure: Multi-agent delegation with typed contracts outperforms monolithic prompts on brownfield operational tasks. A well-written single prompt outperforms multi-agent swarms on greenfield document tasks. The question is what kind of coordination the task actually requires.
The measurement layer is as important as the experiment layer: Token counts from OpenRouter, direct Anthropic API, and CMA measure different things. A finding is only as reliable as the measurement that produced it.
Source (cma.py): github.com/anthropics/cwc-workshops/blob/main/agent-decomposition/agents/cma.py
CMA general documentation: platform.claude.com/docs/en/managed-agents/overview
Reading both side by side is the fastest way to see the gap between what the docs describe and what practice requires.
What in the Code Made This Work?
Three specific patterns in cma.py produced the efficiency gains. None of them are CMA-specific. All of them are transferable to any agent codebase.
1. _build_system() — the single assembly point
The function that constructed the system prompt before each API call was the single highest-leverage point in the codebase. Everything the model saw on every turn passed through _build_system(). When this function was changed from ‘inject all skill files upfront’ to ‘load skills on demand’, the entire token cost structure changed — not through dozens of edits scattered across the codebase, but through one function in one place. If your codebase has one function responsible for assembling what the model sees, that function is your primary optimisation target. If context assembly is scattered — built piece by piece in five different places — creating a single assembly point is the first refactor worth doing, before any other optimisation.
2. make_client() — the shared factory
Every tool that called make_client() from agents/common.py instead of building its own API connection survived the OpenRouter-to-Anthropic switch without breaking. The one tool that hardcoded its own connection — call_forecaster_subagent — caused a 17-point score regression and 232,000 tokens of wasted computation when the environment changed. The agent’s error handling caught the authentication failure silently and fell back to expensive manual computation rather than raising an error. A shared client factory is not just good software practice. In agent systems where every wasted token is a direct cost, it is the difference between an environment change costing one line and costing a debugging session.
3. The typed return contract
The explicit sub-agent returned {”SKU-XXXX”: qty_int} only. No prose. No reasoning. No explanatory text. The parent agent consumed a number and moved on. The sub-agent’s entire chain of thought stayed in its own isolated context and was never seen by the orchestrator. This single boundary definition produced the largest token reduction in the experiment — 54% in one cycle. The boundary between agents is defined by what crosses it. The smaller and more structured that boundary is, the cleaner the context on both sides, and the lower the cost of every subsequent turn. Prose crosses boundaries and inflates context. Typed JSON crosses boundaries and disappears.
💡 Why These Three Patterns Matter at Scale
These patterns are the structural reason the same model produced a 97% token reduction from cycle 0 to cycle 4 — without any change to the model itself, and without any change to the quality of reasoning. The model’s capability was constant throughout. What changed was the structure around it: how much it had to read before it could think, how reliably it could reach external services, and how much it had to carry across turns.
An agent running 15 turns per task, 250 tasks per day, accumulates these inefficiencies at scale. A system costing $8.97 per evaluation suite today will cost $89.70 in six hours if usage scales by 10× and nothing changes. Within the day, continuous run >$350. And before you know it - $10k/month. And this was such a simple, one department exercise.
Fixing the structure is not optimisation — it is the difference between a system that is economically viable and one that is not.
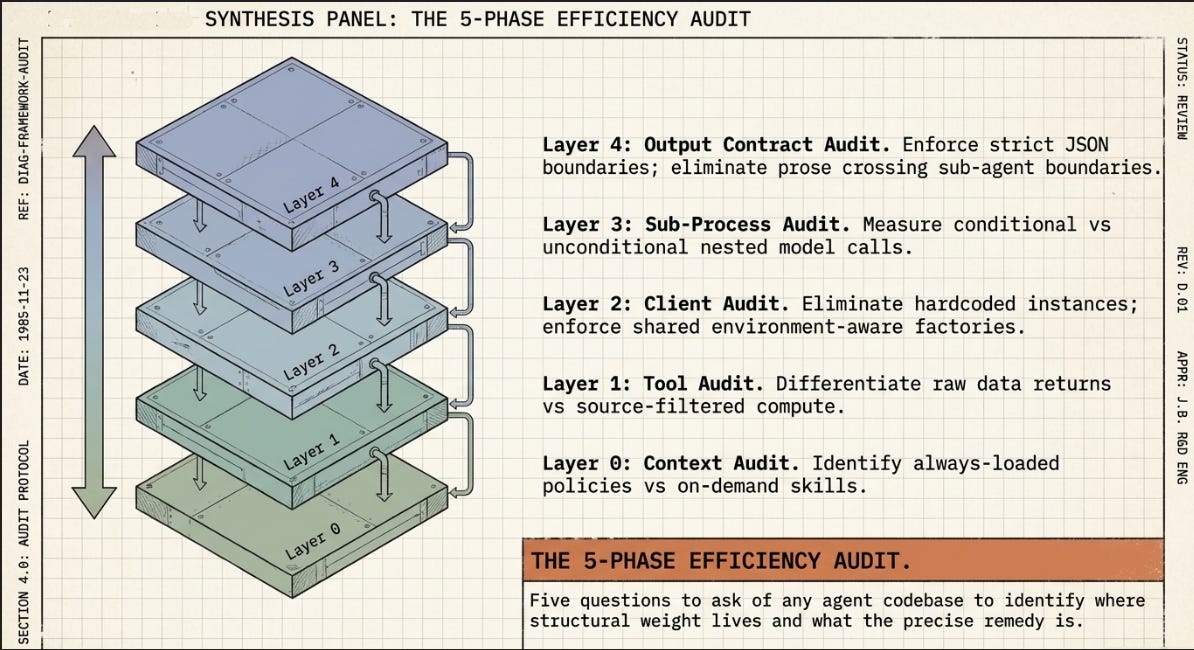
The Replicable Audit: This can be applied to Any Codebase
The following prompt can be pasted directly into Claude Code for any project — your own or someone else’s. Adjust depending on context etc. It runs in report-only mode: Claude Code identifies the specific files, functions, and lines that match each failure pattern, ranks them by estimated impact, and waits for your confirmation before changing anything. This is the same discipline the lab experiment used: one cycle at a time, measure before proceeding, never touch the baseline.
The five phases map to the five failure modes this experiment surfaced. They are not inventory-management-specific. They occur in any system that grew incrementally without periodic architectural review.
You are performing an architecture efficiency audit on this codebase.
PHASE 1 — CONTEXT AUDIT
Scan all files for anything that assembles or constructs what
gets sent to the model (system prompts, message builders,
context assembly functions). For each one report:
- How many tokens does it inject on every call?
- Is any of that content only relevant to some tasks?
- Is any of that content static/repeated across all calls?
- Where is it assembled — one function or scattered?
PHASE 2 — TOOL AUDIT
List every tool or function that makes an external call or
reads data. For each one report:
- What does it return, and approximately how many tokens?
- Does it return raw data or a filtered answer?
- If it returns more than ~2,000 tokens, what is the minimum
the caller actually needs from it?
PHASE 3 — CLIENT AUDIT
Find every location where an API client, HTTP client, or
external service connection is instantiated. Report:
- Is it hardcoded or does it read from a shared factory?
- Would it break silently if an environment variable changed?
- Is there a single factory function, or multiple
instantiation points scattered across files?
PHASE 4 — SUB-PROCESS AUDIT
Find any function that makes a nested model call, spawns a
subprocess, or delegates to a secondary process. For each:
- Does it run conditionally or unconditionally?
- What does it return — prose or structured data?
- Does the parent context see the sub-process reasoning,
or only its conclusion?
PHASE 5 — OUTPUT CONTRACT AUDIT
Find every location where the agent writes output, files,
or results. Report:
- Is the output path hardcoded or environment-aware?
- Would the output path work identically in a different
runtime (local vs cloud vs container)?
- Is there a single known drop location or multiple?
PHASE 6 — REPORT
Produce a prioritised list of changes ranked by estimated
impact. For each item state:
- The specific file and function
- The smell test it fails (data dump / always-loaded policy /
unconditional sub-process / hardcoded client / brittle path)
- The specific change that would fix it
- Estimated token or cost reduction if applicable
Do not rewrite anything yet. Report only.
Ask me which items to proceed with before changing any code.
The Significance
This experiment ran one codebase through four improvement cycles and produced a 97% token reduction, a 95% cost reduction, and a quality score that held steady. Those numbers are striking.
What they represent is more important than the numbers themselves.
Every AI agent system that exists today will accumulate the same failure modes this experiment identified. Add scale. Instructions grow. Tools proliferate. Sub-processes multiply. Nobody plans for this — it happens one reasonable addition at a time. The system that costs $8.97 per evaluation suite today will become economically unsustainable as usage scales, unless someone asks the five questions in the right order.
The lab’s lasting contribution is not the specific fixes it applied to StockPilot. It is the diagnostic framework: five questions you can ask of any agent codebase, at any point in its lifecycle, to identify exactly where the inefficiency lives and what the precise remedy is. That framework is independent of the model, the domain, the programming language, and the deployment environment.
The audit prompt above encodes that framework as a replicable instruction. Run it on a new codebase before building on top of it. Run it on an existing system before scaling it. Run it on your own code before deploying it. The five phases are the five questions the lab asked — and answered with real numbers — in the experiment documented here.
Source: github.com/anthropics/cwc-workshops/tree/main/agent-decomposition
CMA overview: platform.claude.com/docs/en/managed-agents/overview
Skills in CMA: platform.claude.com/docs/en/managed-agents/skills
Multi-agent sessions: platform.claude.com/docs/en/managed-agents/multi-agent
✦
References
Experiment Source
Anthropic cwc-workshops — Agent Decomposition: github.com/anthropics/cwc-workshops/tree/main/agent-decomposition
Workshop video walkthrough: youtu.be/mWvtOHlZM-I
Prior Work in This Series
The Architecture of Awareness — Interesting Engineering++, April 2026: interestingengineering.substack.com
ASCRS Harness Lab: The Integrated Agentic Stack — Interesting Engineering++, May 2026: interestingengineering.substack.com
Anthropic Documentation
Claude Managed Agents: docs.anthropic.com/en/docs/agents
Prompt caching (generally available December 2024): docs.anthropic.com/en/docs/build-with-claude/prompt-caching
Prompt engineering overview: docs.anthropic.com/en/docs/build-with-claude/prompt-engineering/overview
OpenRouter
Prompt caching documentation: openrouter.ai/docs/guides/best-practices/prompt-caching
Claude Sonnet 4.6 provider page: openrouter.ai/anthropic/claude-sonnet-4.6/providers
Model catalogue: openrouter.ai/models
Agent Architecture Research
ReAct: Synergizing Reasoning and Acting in Language Models (Yao et al., 2022): arxiv.org/abs/2210.03629
AutoGen: Multi-Agent Conversation Framework (Wu et al., 2023): arxiv.org/abs/2308.08155
Chain-of-Thought Prompting Elicits Reasoning in LLMs (Wei et al., 2022): arxiv.org/abs/2201.11903