
Is Claude's Memory Actually Poor?
What a Controlled Experiment Reveals About Data Architecture, Context Injection, and Where the Gap Actually Lives: A Task Based Experiment

A Concern I Sometimes Hear
“Claude has no persistent memory between sessions”. “Everything is forgotten when the conversation ends.” “The native memory tools are unreliable, and fixing this properly requires third-party databases, vector stores, or external memory services.”
I have heard the above said in different ways, many times. Even just yesterday.
This concern is widely held, and it is not entirely wrong. Claude does not natively remember all previous conversations. But Claude features memory capabilities that allow it to reference previous interactions and build context over time. Instead of operating entirely in isolation, you can enable settings that allow the AI to actively search your chat history and retain personal preferences across new sessions
Logically, with code, without any architecture or “harness” around it, each session begins as a blank slate. The question worth testing is whether the conclusion that follows -- that external memory services are required -- is actually correct. For this - Claude Code.
Continue watching the space for memory research…
I did recently look into three independent research projects on AI memory in April 2026: MEMENTO (Microsoft Research), MemPalace, and AutoResearch (Karpathy). The article was not completed as a published synthesis, however, because I started including them in various experiments (which I will write about more comprehensively, at a later date, as the space evolves).
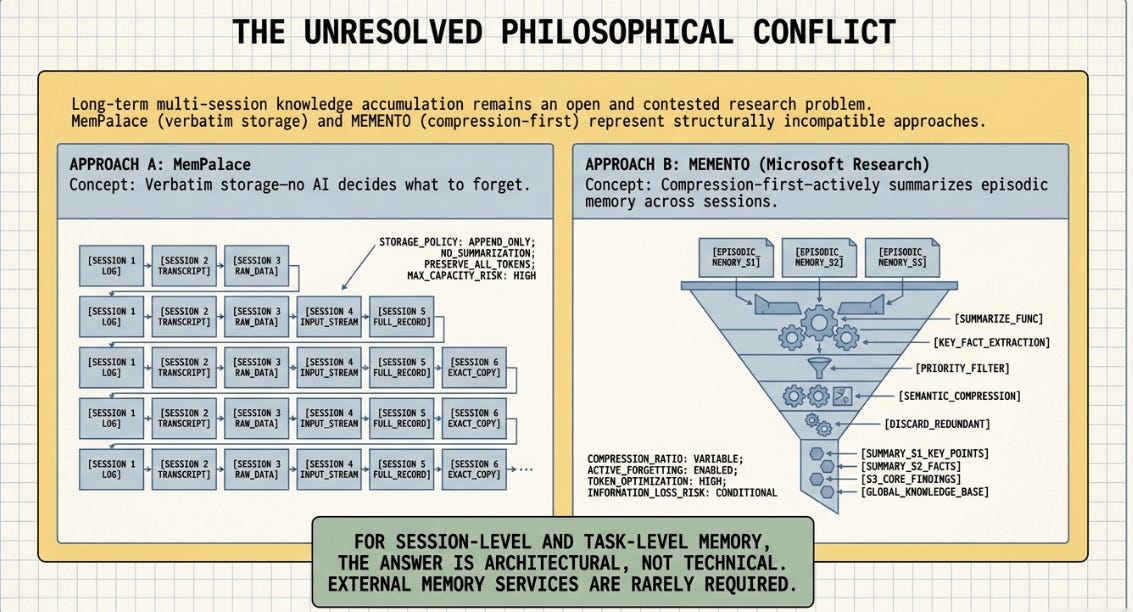
MemPalace is built on the principle that everything should be stored verbatim -- no AI decides what to forget. MEMENTO’s approach is compression-first -- it actively summarises and compresses episodic memory across sessions. These two positions are structurally incompatible. A synthesis presenting them as complementary would have been inaccurate. So I made the decision not to publish (whilst experimenting) rather than publish something misleading or inconsistent.
That conflict is noted here because it is the honest position: long-term AI memory at the level of complex multi-session knowledge accumulation remains an open and contested research problem. Practitioners should be cautious about any tool or article claiming to have resolved it cleanly. For now.
What the experiment below demonstrates is narrower and more immediately useful: for session-level and task-level memory -- the kind needed to do a specific job well -- the answer is more architectural than technical, and the tools are simpler than the concern suggests.
The experiment
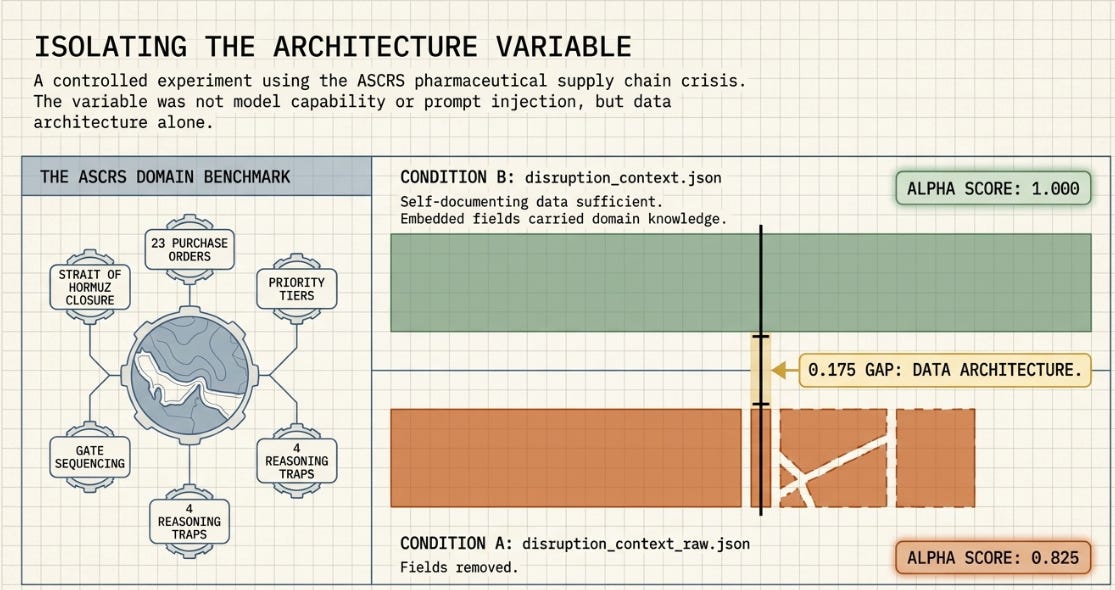
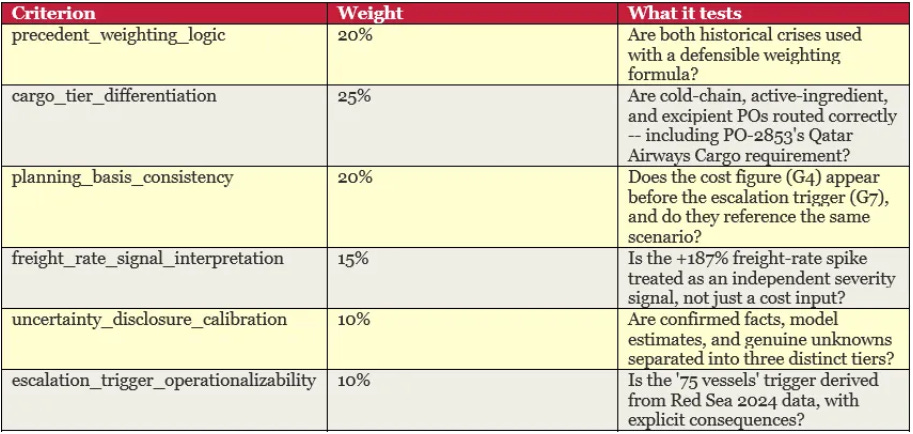
The ASCRS pharmaceutical supply chain crisis task has been used throughout this series as a controlled benchmark domain. A Strait of Hormuz closure scenario. 23 purchase orders across three priority tiers. Carrier availability constraints, financial parameters, gate sequencing rules, and four deliberate reasoning traps embedded in the data. A gold-standard answer -- a full CFO-approvable brief -- prepared in advance, against which all outputs are scored using a six-criterion rubric.
This experiment was designed to test a simple question: does injecting context at session start measurably improve performance against a scored rubric? It ran in Claude Code, in separate sessions, in the experiments/memory-ab/ subfolder of my ascrs-harness-lab project.
What the experiment design revealed
The original design called for a direct comparison between a session with no context and a session with BOOTSTRAP_PROMPT.md injected. But in my case both returned alpha = 1.0.
The first instinct was to treat this as a failed experiment. It was not.
It revealed that the original data file -- disruption_context.json -- was already doing the context work. The file contained embedded _agent_trap fields describing each reasoning trap explicitly, and a weighted_median_derivation section laying out the financial methodology. The data file was self-documenting. It was supplying the domain knowledge that BOOTSTRAP was expected to supply.
So I redesigned the experiment. A stripped version of the data file was created -- disruption_context_raw.json -- with the embedded guidance fields removed. Condition A was re-run using the raw file, with no BOOTSTRAP. Condition B remained as run: the original rich data file, no BOOTSTRAP. The variable between the two conditions was data architecture alone.
Results
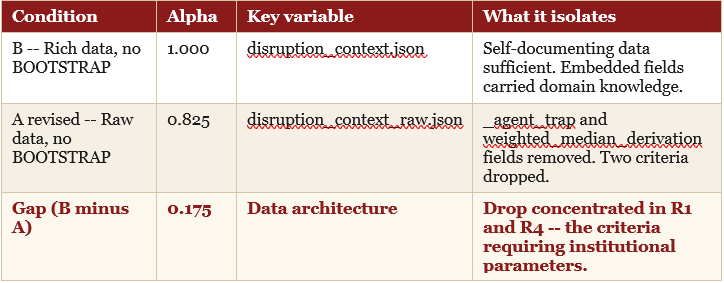
The gap of 0.175 was not uniform across criteria. Four of six criteria held at 1.0 in Condition A. Two dropped to 0.5.
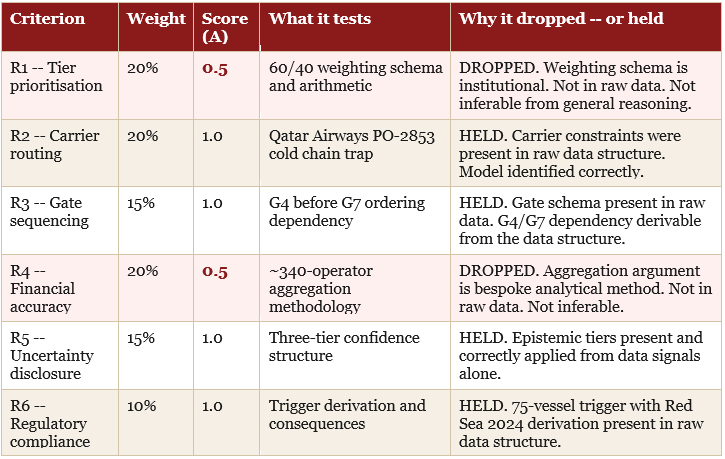
The pattern however, was precise. R1 and R4 dropped because both depend on domain-specific parameters that exist only in institutional practice: a 60/40 tier weighting schema and a ~340-operator aggregation methodology. Neither can be inferred from raw data. Neither is available through general reasoning. The model handled both correctly in Condition B because the original data file had embedded that methodology explicitly.
R2, R3, R5, and R6 held at 1.0 in both conditions because their answers are derivable from data structure. The carrier routing constraint for PO-2853 was present in the raw data. The gate schema and G4/G7 dependency were present in the raw data. The epistemic uncertainty tiers and trigger derivation were present in the raw data. The model did not need institutional guidance to answer those criteria correctly -- it needed the facts, which the raw file contained.
The rubric measured the following:
What this demonstrates
The gap between Condition A and Condition B is not a gap in model capability. The model did not change between conditions. It is a gap in what the model was given to work with -- specifically, the absence of two institutional parameters that exist only in domain-specific practice.
As a quick note, the way I use Claude’s context window, despite the 1m context window: basically beyond 200,000 tokens -- approximately 150,000 words, I start worrying about the “dumb zone” applying. Want to find out more: Dex Horty covers a lot here.
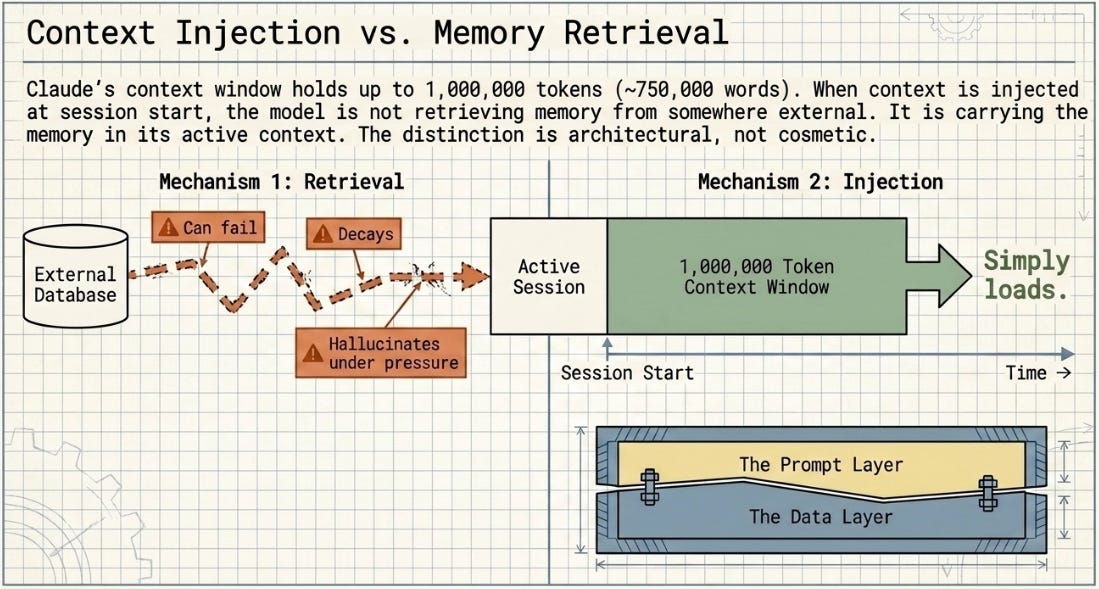
When context is injected at session start, whether via a rich data file or via BOOTSTRAP_PROMPT.md, the model is not retrieving memory from somewhere external. It is carrying the memory in its active context. Retrieval can fail, decay, or hallucinate under pressure. Injection simply loads. The distinction is architectural, not cosmetic.
The experiment also highlights a choice that most practitioners do not realise they have. Context engineering operates at two layers, not just one:
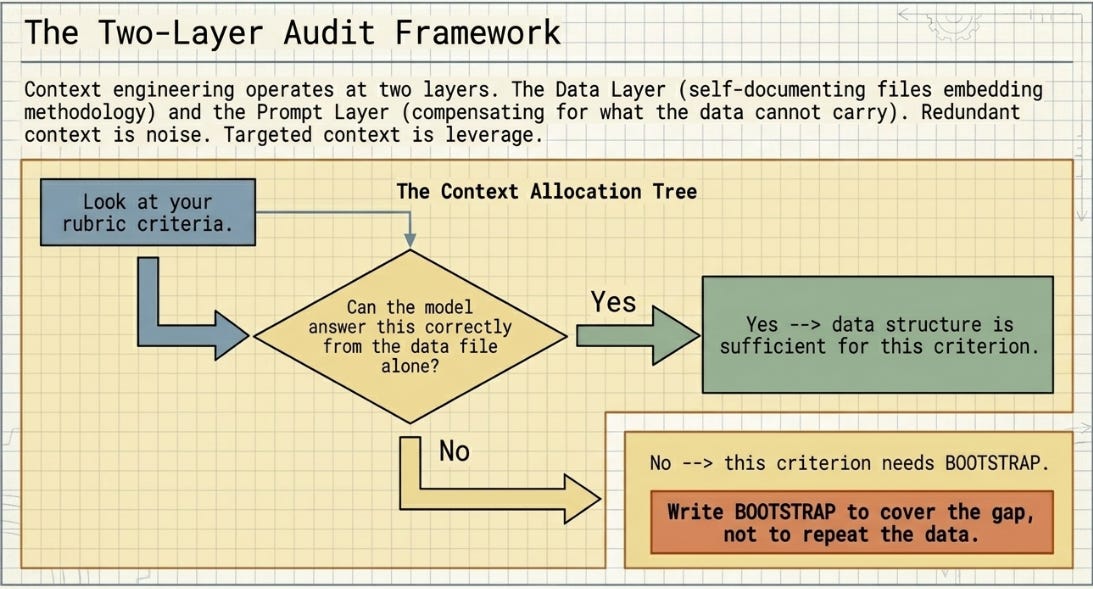
* The data layer -- how your data file is structured (nevermind the where). A self-documenting data file that embeds domain guidance, methodology notes, and constraint descriptions is doing context work before any prompt is written. The model reads it as part of the task and reasons from it correctly.
* The prompt layer -- what you inject at session start (or add as you test) via BOOTSTRAP or a system prompt. This layer compensates for what the data layer cannot or does not carry -- institutional parameters, weighting schemas, bespoke methodologies, business-specific thresholds. Unless of course these were included within the data layer, in the first place.
Both layers are valid. Both compensate for the absence of the other. The choice between them depends on what you control. What needs to persist, or evolve.
If you control how your data is structured -- your own pipelines, your own files -- you can embed domain guidance directly. The model reads it as data and reasons from it without any additional prompt engineering. If your data comes from an external source you cannot modify -- raw exports, third-party feeds, legacy files with no embedded metadata -- then BOOTSTRAP becomes essential because the data layer is not available to you.
The two-layer audit question
Look at your rubric criteria. For each one, ask:
Can the model answer this correctly from the data file alone?
Yes --> data structure is sufficient for this criterion.
No --> this criterion needs BOOTSTRAP.
Write BOOTSTRAP to cover the gap, not to repeat the data.
Redundant context is noise. Targeted context is leverage.
The architecture in practice
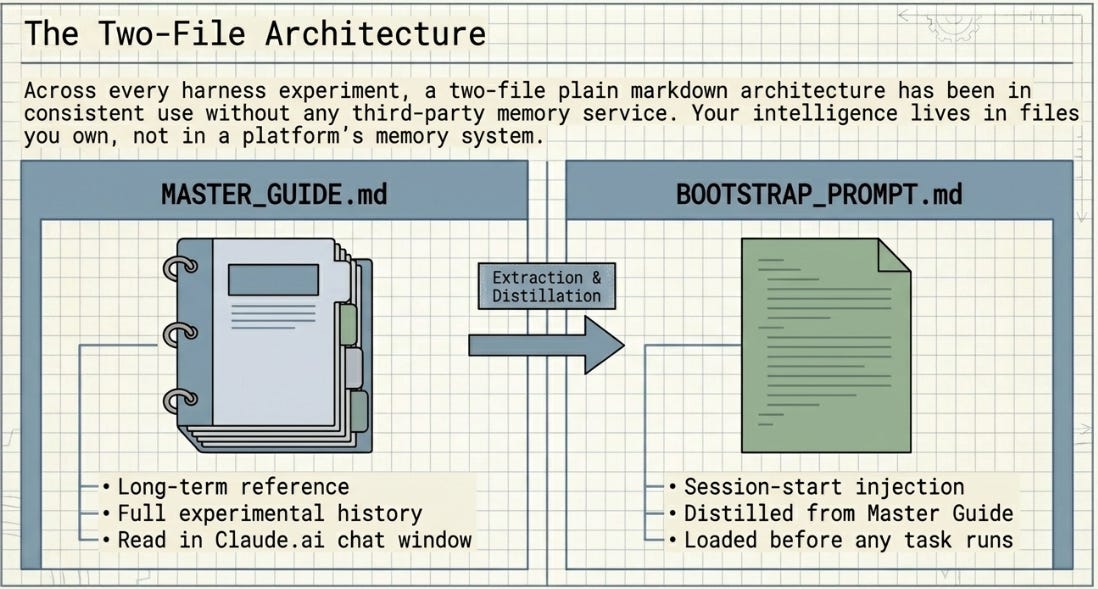
Across every harness experiment in this series, a two-file context architecture has been in consistent use without any third-party memory service:
* MASTER_GUIDE.md -- the long-term reference document. Alsways portable. Full experimental history, domain knowledge, architectural decisions, rubric designs. Updated after every experiment. Read in the Claude.ai chat window for design and analysis work between sessions. Or capture it in CLAUDE.md or AGENTS.md
* BOOTSTRAP_PROMPT.md -- the session-start injection file. Contains only what Claude Code needs for the current task, distilled from MASTER_GUIDE. Loaded at the start of every Claude Code session before any task runs.
Neither file is platform-specific. Both are plain markdown. Both are readable by any AI tool. The pattern is not a Claude workaround -- it is a general principle: your intelligence lives in files you own, not in a platform’s memory system. But it can if you choose.
The experiment adds precision to how BOOTSTRAP should or can be written. The criteria that held at 1.0 in Condition A did not need BOOTSTRAP coverage -- they were handled correctly from data alone. Including them in BOOTSTRAP would have added tokens without adding value. The criteria that dropped -- R1 and R4 -- are exactly what BOOTSTRAP should carry: the 60/40 weighting schema, the aggregation methodology, the institutional parameters the data file cannot provide.
A lean, targeted BOOTSTRAP outperforms a comprehensive one. This connects to a separate finding documented in Article A: every token in CLAUDE.md and BOOTSTRAP is re-sent on every request. Dead weight in those files is a recurring cost, not a one-time investment. Independent benchmarking shows that trimming a context file from 3,847 to 312 tokens -- removing boilerplate and keeping only what the model acts on -- reduces per-session token cost by 91.9%. I did it differently but with the same contextual impact, with The Structure Is Intelligence! The discipline that produces a better experiment also produces a cheaper one.
What this does not solve
My experiment demonstrates session-level context injection. It does not demonstrate long-term autonomous memory accumulation across many sessions without human involvement -- the kind where an agent builds a knowledge base over weeks/months and queries it intelligently. That is a harder problem. At least, for now, most of us have not had that lenght of time to test these very new tools that only just presented themselves in the last quarter of last year. So, time will tell. The research landscape I surveyed offers partial answers but no clean solution, and the philosophical conflict between verbatim storage and compression-first approaches remains unresolved.
The two-file architecture also does not scale indefinitely without maintenance. A MASTER_GUIDE that grows without pruning eventually contains outdated decisions alongside current ones. The discipline is the same as any knowledge management practice: regular review, deliberate pruning, honest updating. The architecture provides the structure. The practitioner provides the upkeep.
So?
The experiment produced an alpha gap of 0.175 between a raw-data-only condition and a self-documenting-data-only condition, concentrated in R1 (tier prioritisation, 0.5) and R4 (financial aggregation methodology, 0.5). Four criteria held at 1.0 regardless of context, because their answers are derivable from data structure alone.
The finding is more specific and more useful than a simple before/after comparison: BOOTSTRAP injection does not improve performance uniformly. It closes the gap precisely on criteria requiring institutional parameters -- weighting schemas, bespoke methodologies, business-specific thresholds -- that neither raw data nor general reasoning can supply. The model’s reasoning capability was present in both conditions. What differed was the availability of the parameters it needed to apply that capability correctly.
The practical implication is an audit, not a prescription. Many things, even memory, are fixable with a little bit of engineering.
Identify which criteria in your rubric depend on institutional knowledge. Ensure your data file or your BOOTSTRAP carries those criteria explicitly. Do not write context that repeats what the data already says. Context engineering is not about loading everything the model might need. It is about identifying the specific gap between what the model can derive and what it needs to be told -- and closing exactly that gap, nothing more.
Note: Anthropic Dreaming shipped May 6, 2026 for Claude Managed Agents (CMA). It is an asynchronous between-session process that reviews session transcripts and existing memory stores, extracts patterns, merges duplicates, replaces stale entries, and writes reorganised memory entries that future sessions can use. Anthropic explicitly models it on hippocampal memory consolidation. So a lot of interesting solutions to a significant issue.
However, the concern that opened this article -- that Claude’s memory is poor and requires third-party tools to fix -- is a real observation about default behaviour. The conclusion here does not support it. The model’s default behaviour may be a blank slate. A good practitioner’s job is to decide how and what needs to go into memory, at which layer, and why in the most (cost) efficient, persistent manner possible. Skills you develop as you get to know your AI better. And technology that enables it - progress of which is evolving in the right direction, fast.
References
ASCRS Harness Lab -- The Integrated Agentic Stack MASTER_GUIDE / BOOTSTRAP architecture in use throughout. Rubric and gold answer design.
The Architecture of Awareness V1-V4 agent design. ASCRS system and file architecture introduction.
The Structure Is The Intelligence Decomposition experiment. Context file efficiency and caching findings.
Hamza Farooq -- Claude Token Optimizer CLAUDE.md trim benchmark: 3,847 to 312 tokens, 91.9% reduction. Context file efficiency.
Agent Memory in 2026 - Dreaming, Memory Bank and The Long Context Shift