
The Memory Stack: From RAG to Cognitive AI
How 7 layers of Machine Memory Reshape Strategies Around AI investment and Agent Autonomy

This article follows up on 2 prior articles - Machine Memory and Memory Systems (both referenced further below).
They bring together a recent blog by Leonie Monigatti on “The Evolution from RAG to Agentic RAG to Agent Memory” and a Survey paper titled, “Toward Efficient Agents: A Survey of Memory, Tool learning, and Planning
The next article will introduce critical paradigm shifts to the existing 0-7 Layer Framework: the transition from probabilistic retrieval to deterministic pattern matching enabled by a Hardware-Aware Passive Context. The architecture will add a “Passive Layer” to relevant levels of the stack.
Key Reader Takeaways
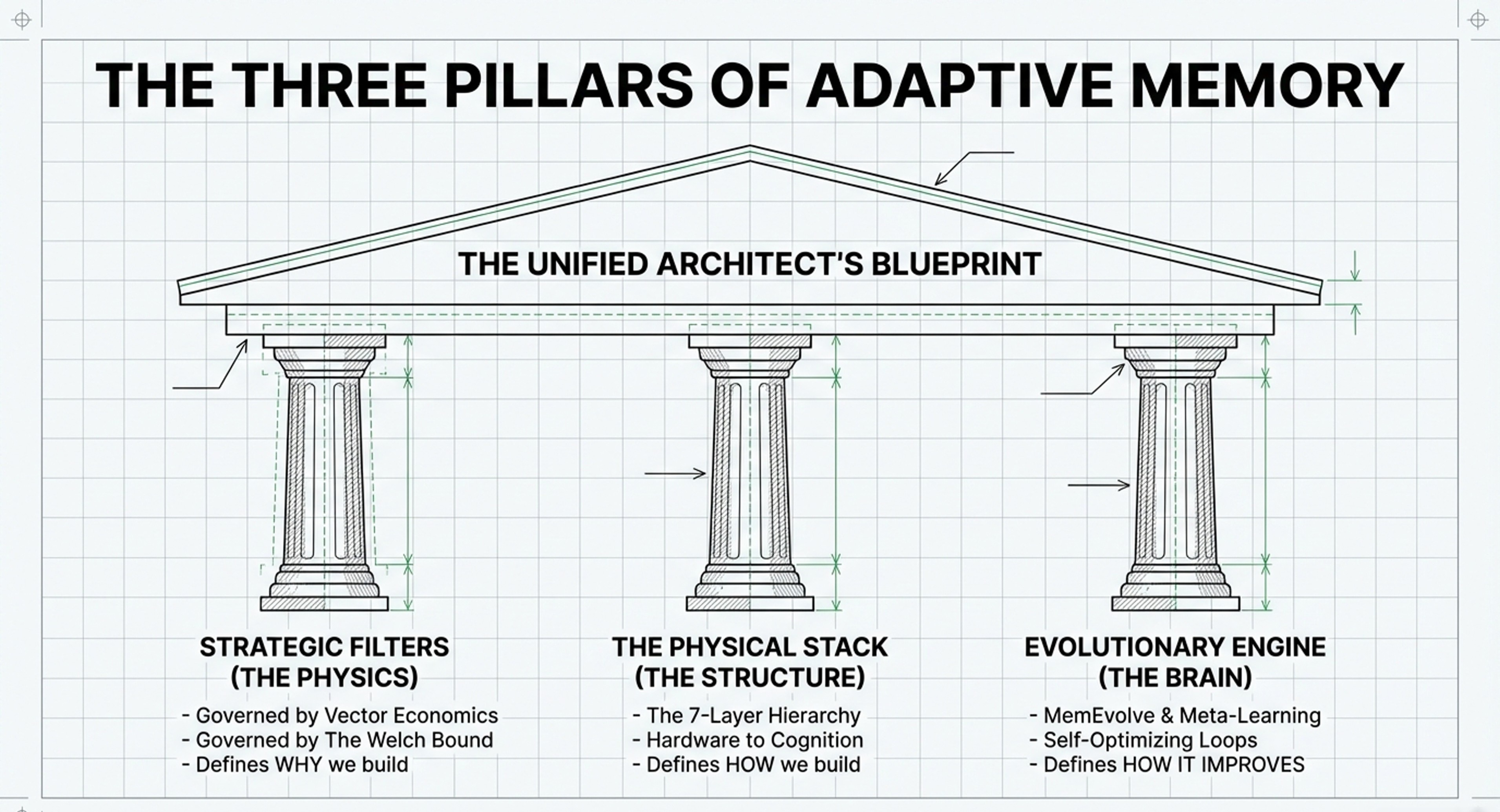
Strategic Framework
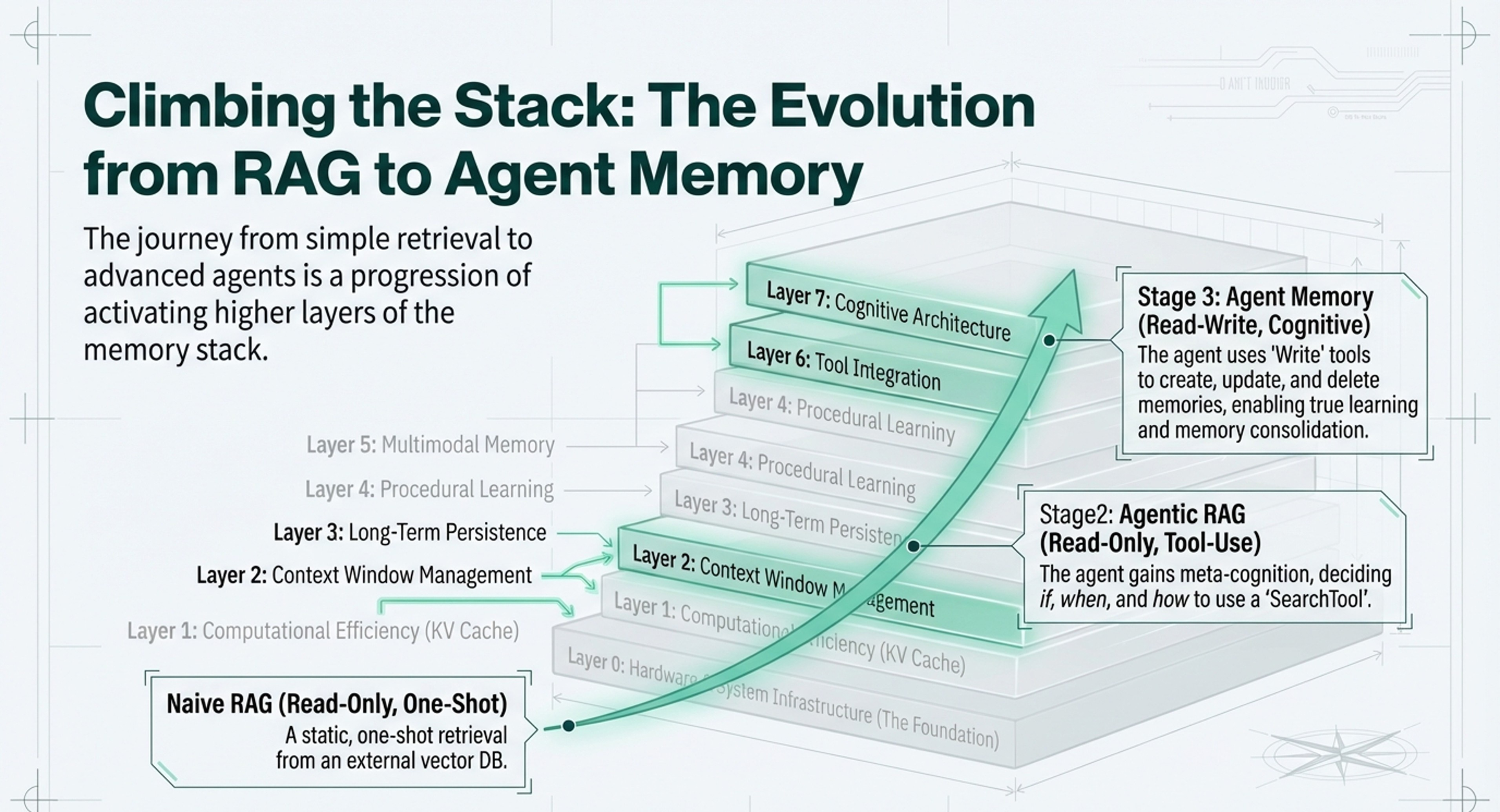
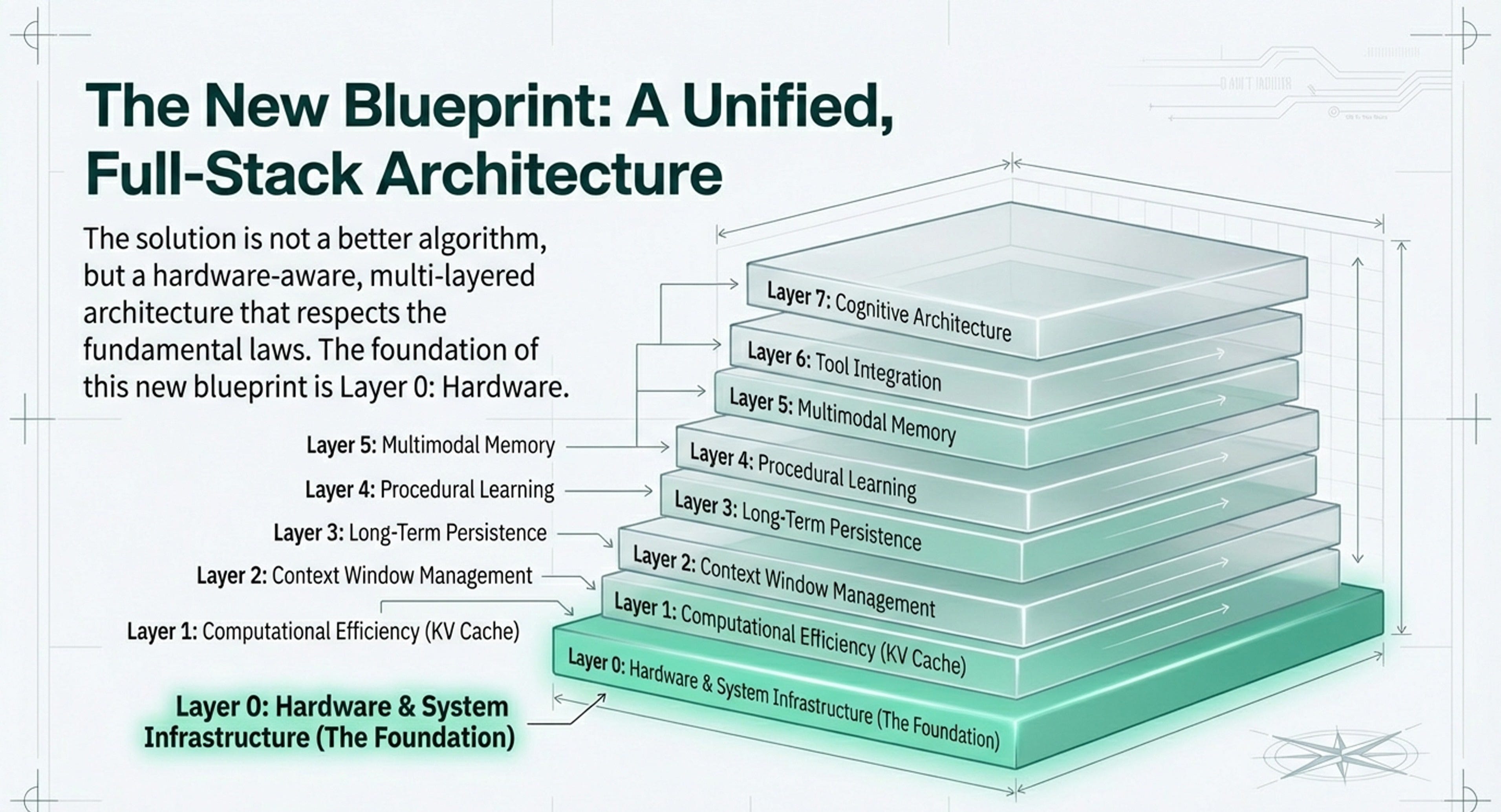
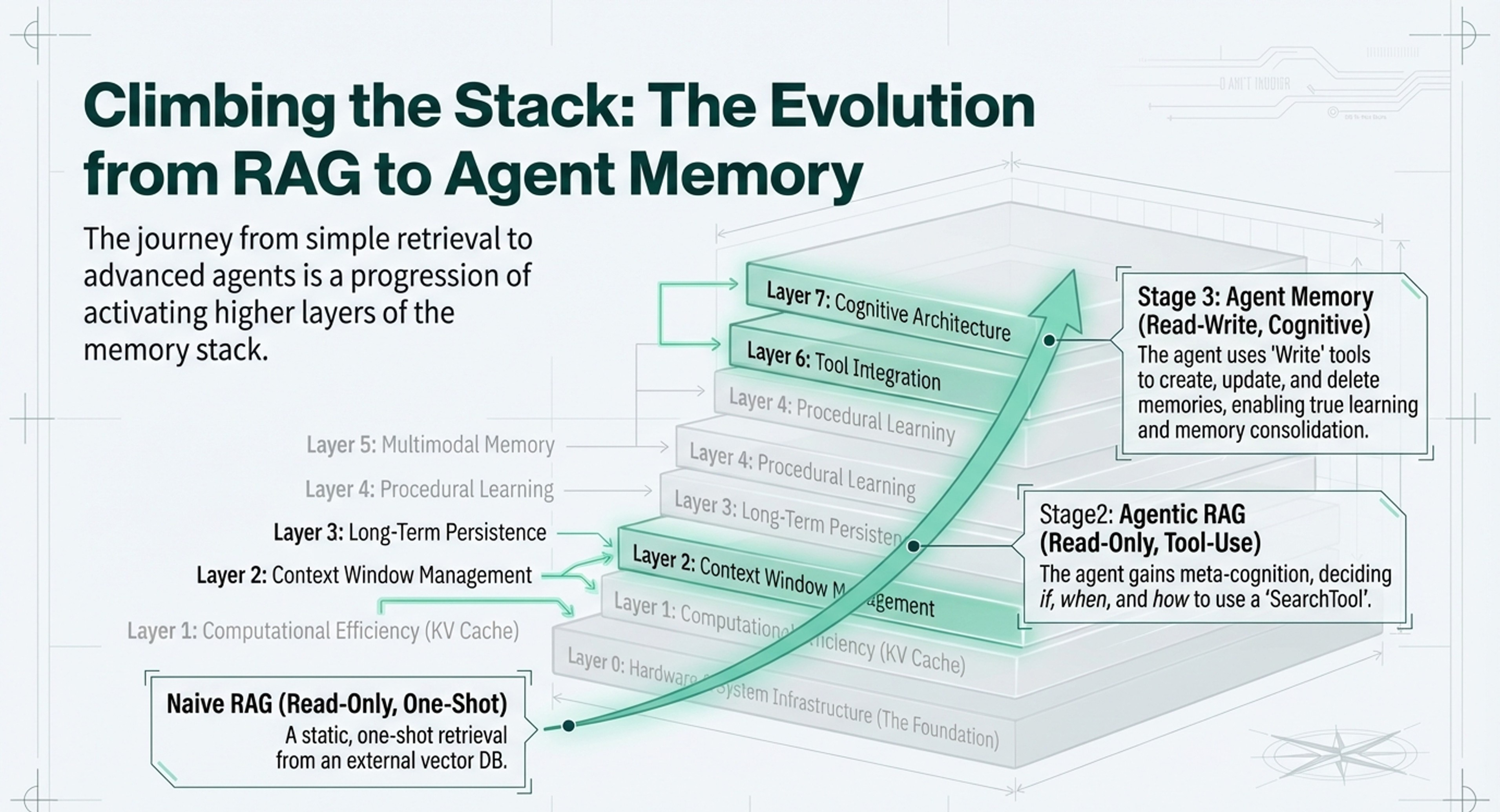
7-layer memory architecture (Hardware → Cognitive Architecture) for understanding AI system capabilities
Evolution path: Naive RAG → Agentic RAG → Agent Memory with read-write operations
The “Memory Triangle” constraint model balancing performance, cost, and latency
Investment Intelligence
Intuition around Tailored capital allocation strategies for 4 distinct scenarios: hyper-datacenters, AI labs, enterprise B2B, and edge/mobile
KV Cache significance varies dramatically by use case—critical for some, negligible for others
BM25 Renaissance: keyword search delivers 99% cost savings at enterprise scale
Technical Depth
Vector Economics vs. Memory Wall: when to prioritize algorithmic efficiency vs. hardware infrastructure
CRUD operations (Create, Read, Update, Delete) as the unlock for autonomous agent memory
Multi-tier hierarchy optimization (GPU VRAM → DRAM → CPU → SSD) for real-world deployment
Competitive Edge
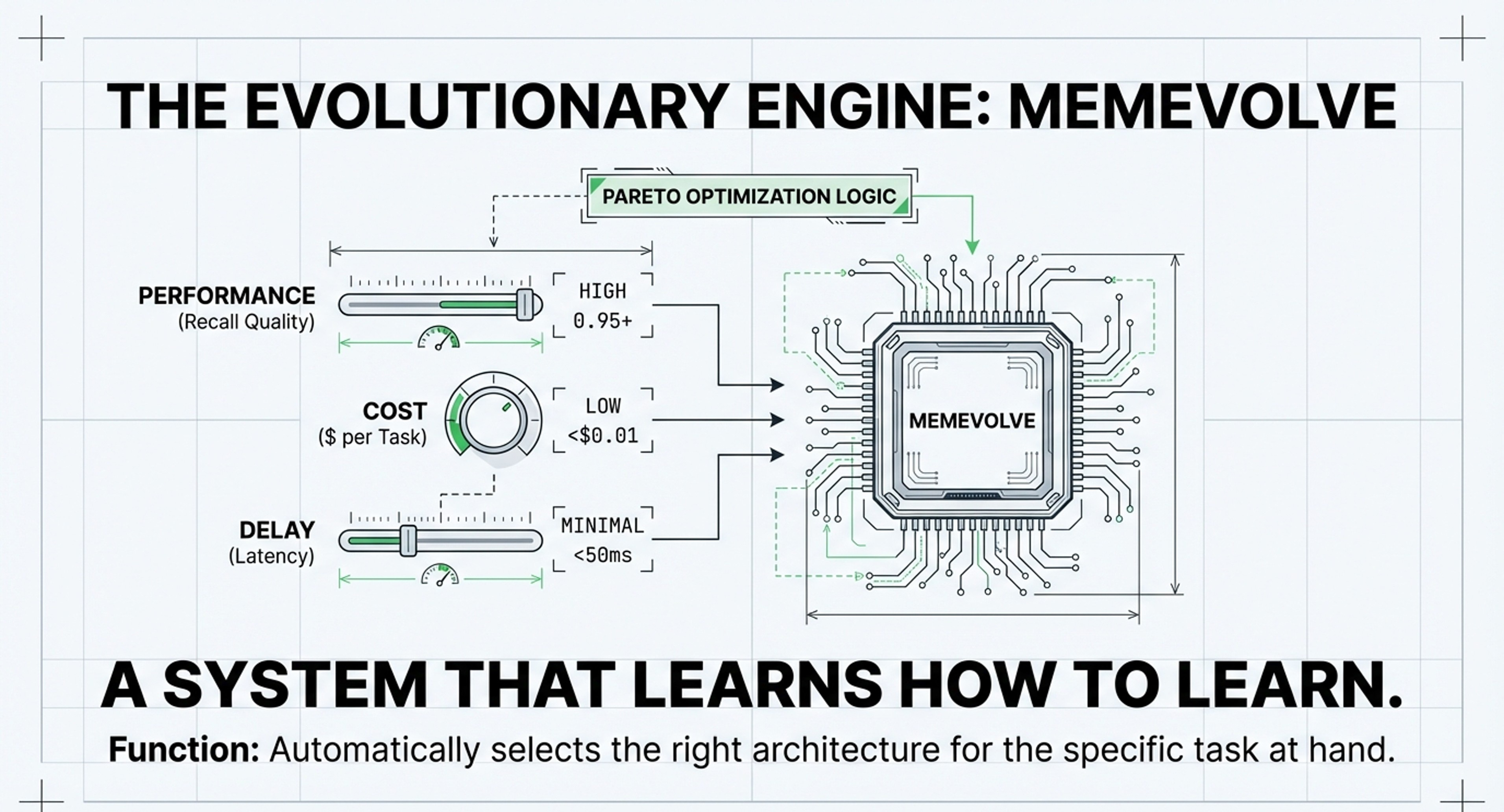
MemEvolve’s dual-evolution approach: systems that automatically tune their encoding, storage, and retrieval
Pareto frontier thinking for balancing effectiveness against tokens, latency, and computational steps
Tool learning + planning integration as the next efficiency multiplier beyond pure memory optimization
The Evolution RAG to Agentic RAG to Agent Memory
Leonie Monigatti’s article, “The Evolution from RAG to Agentic RAG to Agent Memory,” serves as the operational blueprint for how AI systems move through the seven layers of the memory framework.
While “Memory Systems, AI Agents and LLMs” provides the infrastructure (the layers) and “Machine Memory: The Math That Matters”, provides the strategy (the math), Leonie’s work explains the functional transition from simple retrieval to complex, self-managed cognitive architectures.
Below is how Leonie’s evolutionary stages fit within the seven layers of the memory framework:
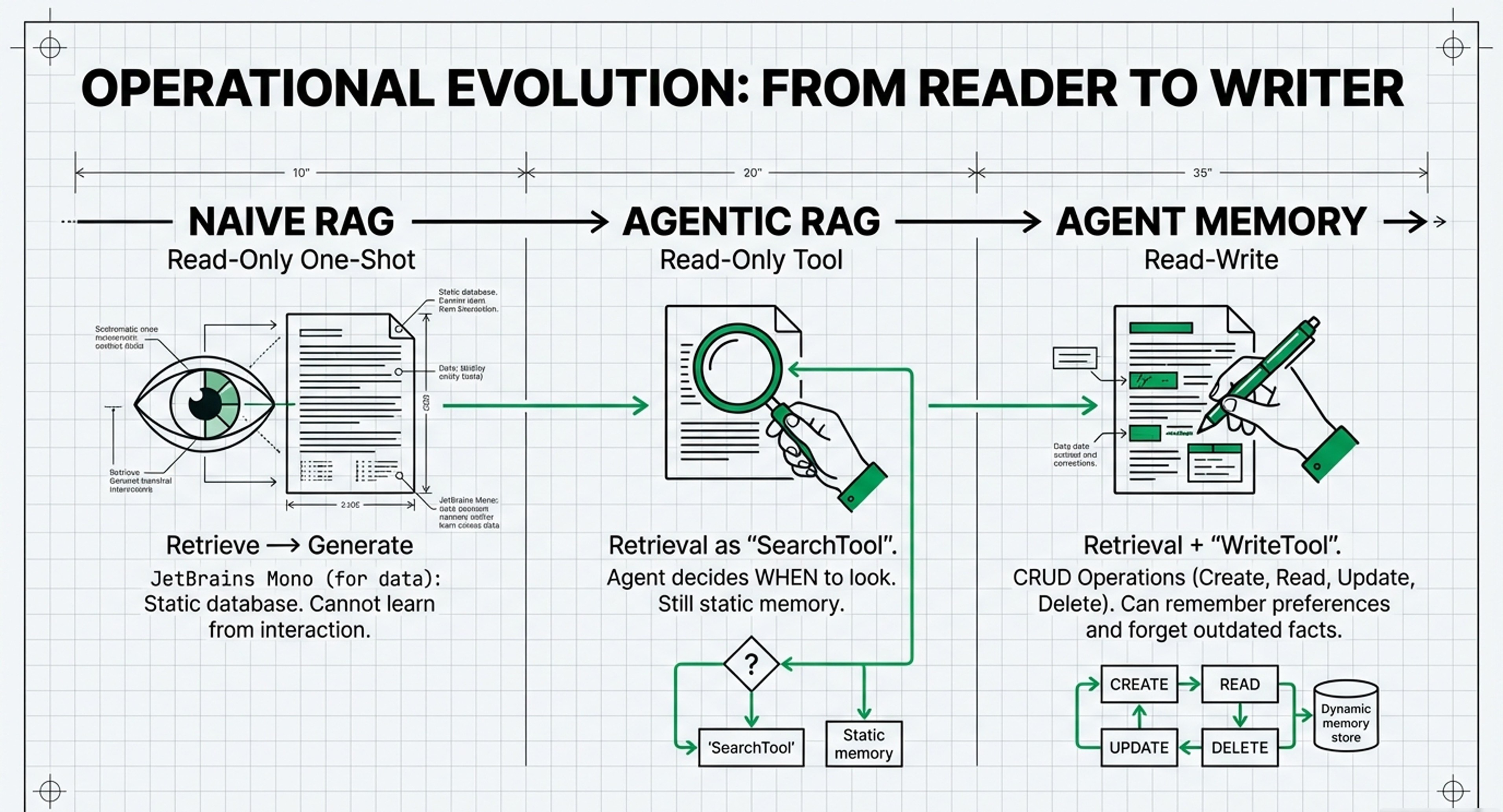
1. Layers 2 & 3: Naive RAG (Read-Only One-Shot)
Leonie defines the starting point as Naive RAG, which primarily addresses Layer 2 (Context Window Management) and Layer 3 (Persistence).
Layer 2: RAG is used to feed retrieved context into the LLM’s limited context window to ground responses.
Layer 3: It relies on an offline indexing stage where documents are stored in a vector database (Long-Term Persistence).
Limitation: In this stage, the system is “one-shot” and “read-only,” meaning it cannot update its own memory during a conversation.
2. Layer 6: Agentic RAG (Read-Only Tool Calls)
The transition to Agentic RAG represents a shift into Layer 6 (Tool Integration).
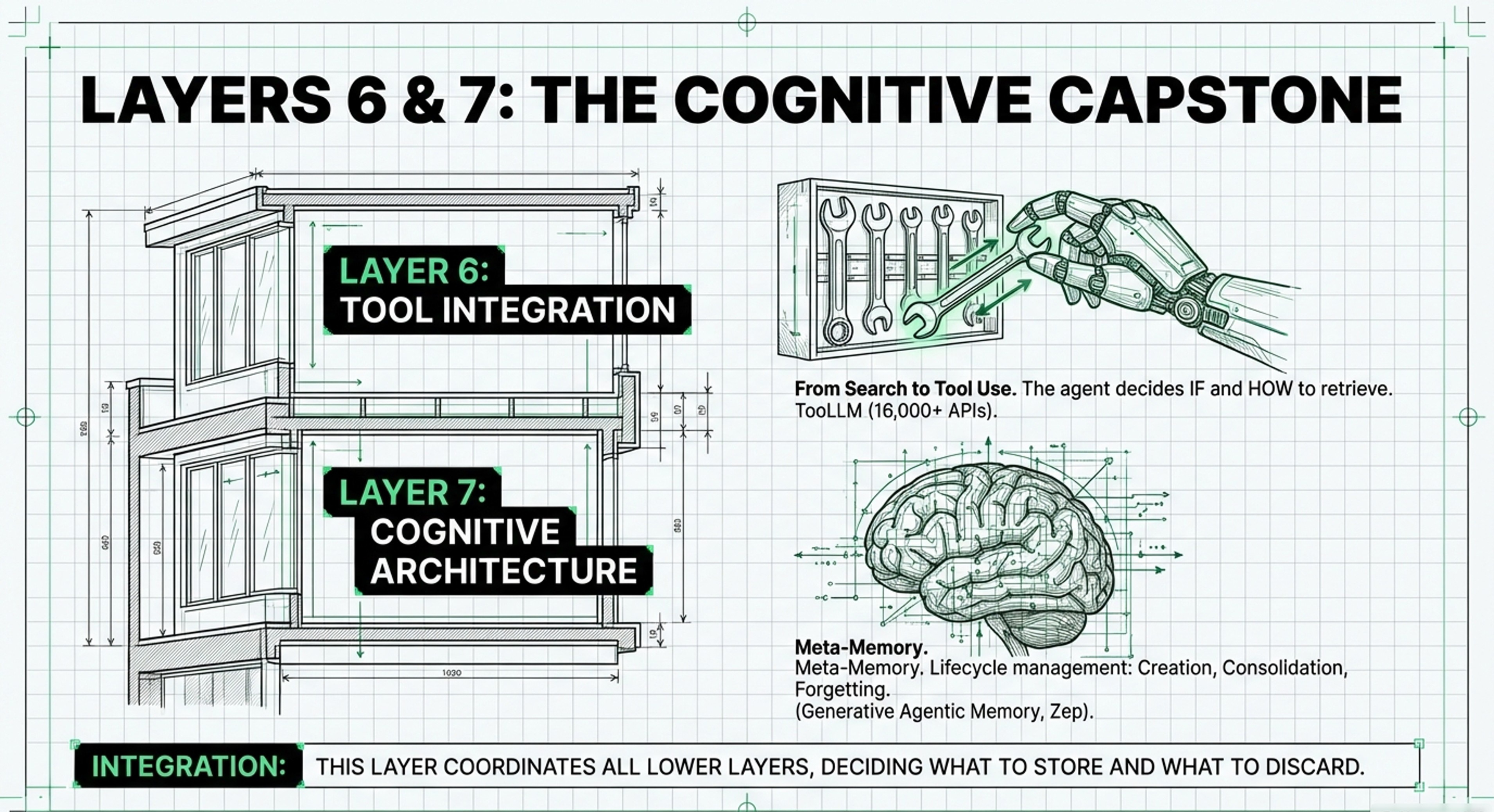
Layer 6: Leonie describes this stage as defining the retrieval step as a “SearchTool”. The agent now has the “meta-cognition” to decide if it needs to look something up and which tool to use (e.g., a proprietary database vs. a web search).
Operational Fit: This aligns with Memory System’s Layer 6, which focuses on how agents use external tools to augment their internal reasoning.
3. Layer 7 & 4: Agent Memory (Read-Write Tool Calls)
The final stage in Leonie’s evolution, Agent Memory, is where the system fully enters Layer 7 (Cognitive Architecture) and Layer 4 (Procedural Learning).
Layer 7: This is the “management” layer. Leonie introduces “Write” tools, allowing the agent to not just read, but also create, update, and delete memories (CRUD operations). This facilitates memory consolidation and “forgetting,” which are key features of cognitive architectures.
Layer 4: Leonie specifically maps her concepts to Procedural Memory (e.g., learning a user’s preference to use emojis). This is the “skill learning” layer where the agent improves its behavior based on past interactions.
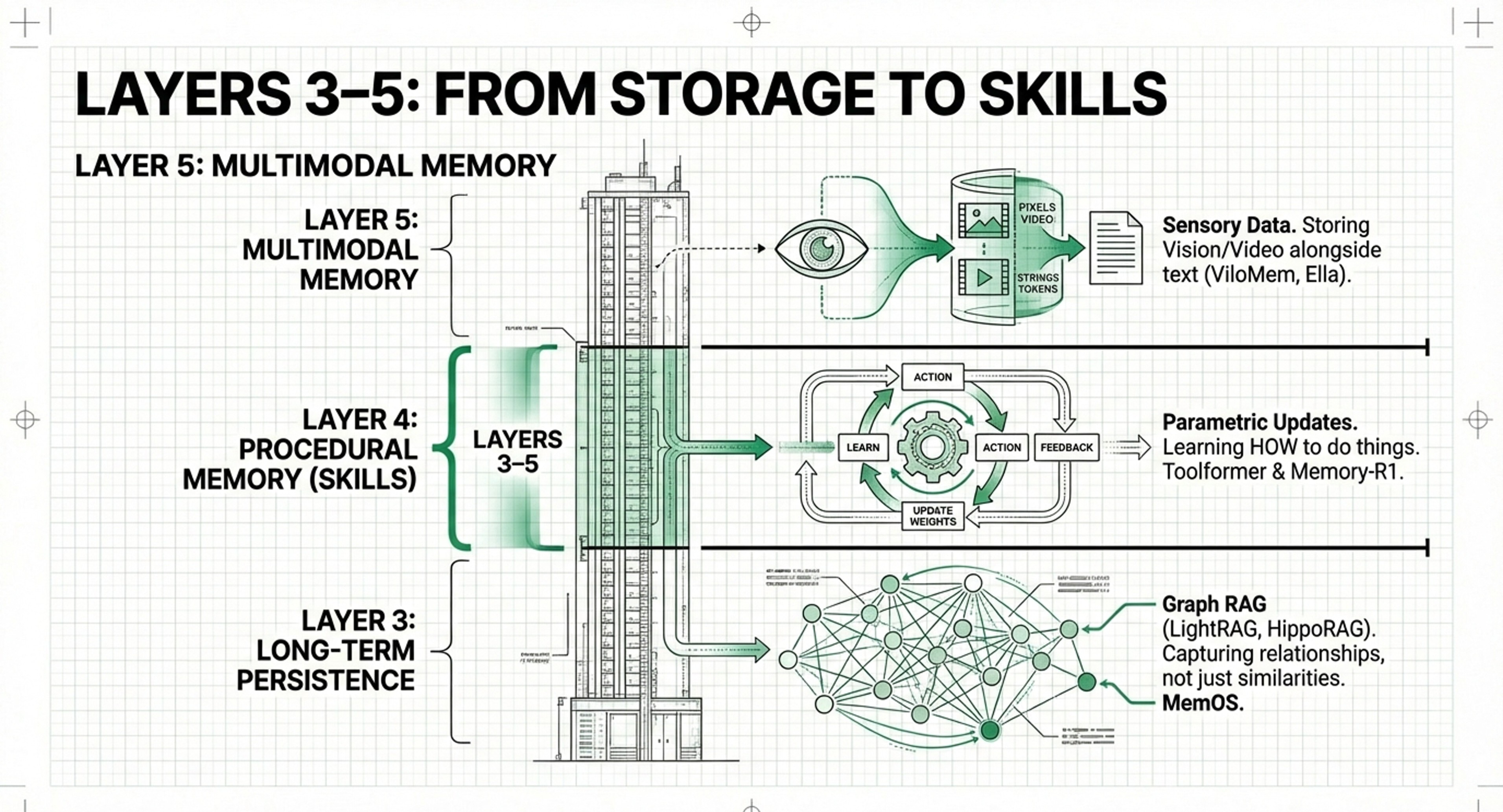
4. Layer 5: Multimodal & Sensory Memory
While Leonie’s pseudo-code focuses on text, she notes that “Agent Memory” is the logical next step for complex interactions, which necessitates separate data collections for different types of memory. This architecture supports Layer 5 (Multimodal Memory) by allowing different “Write” tools to handle different sensory inputs, such as images or video.
Summary of Alignment
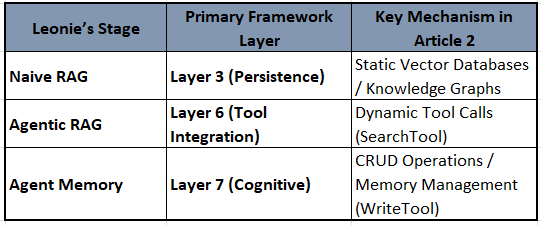
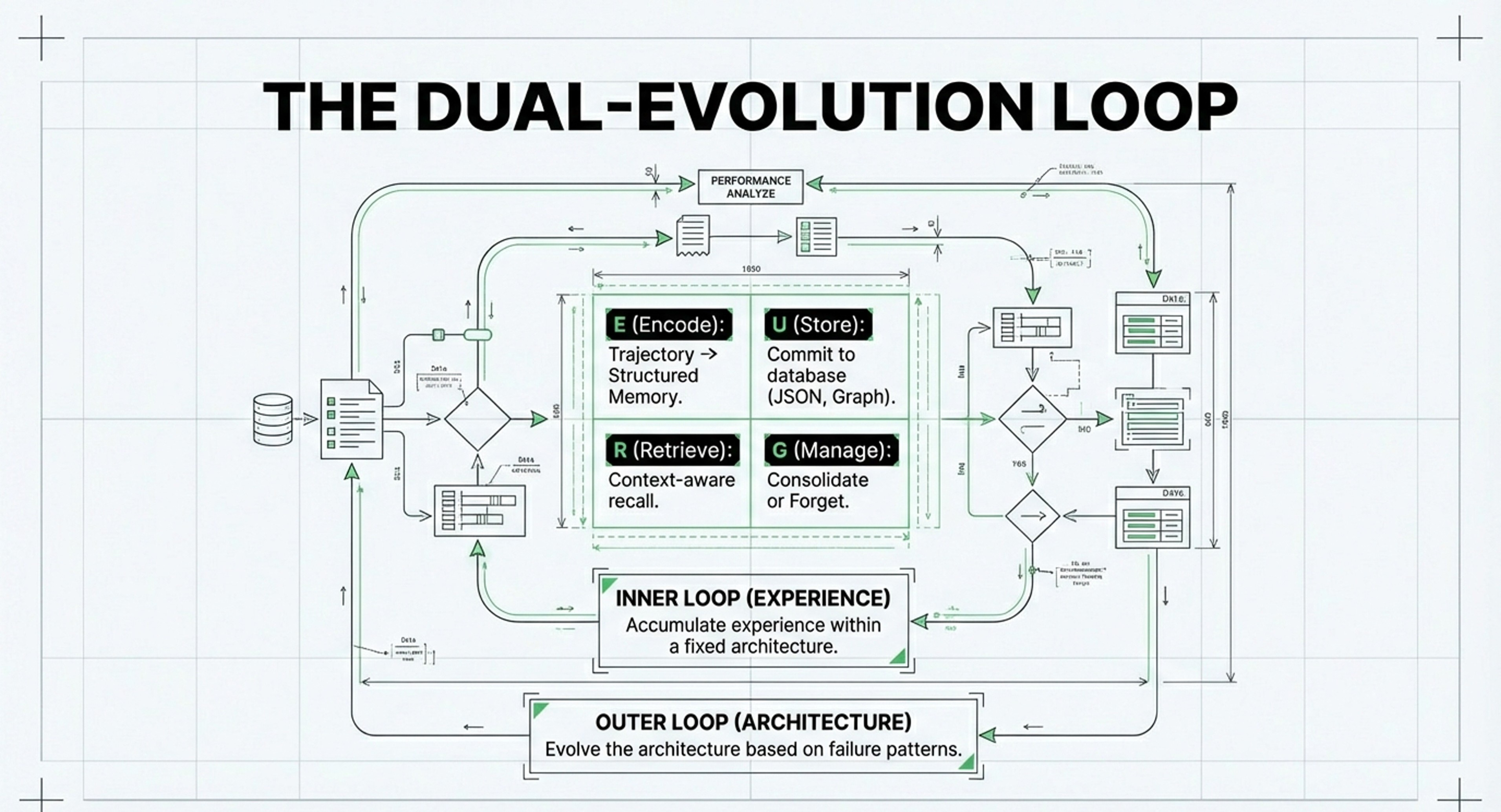
Strategic Integration: Leonie’s article bridges the gap between the Strategic Filters of Machine Memory and the Physical Stack of Memory Systems. She highlights that the core of the transition is moving from “how to retrieve” (Article 1’s Vector Economics) to “how information is managed” (Article 2’s Cognitive Architecture). In many ways, this validates MemEvolve’s concept: her “Agent Memory” stage is the manual version of what MemEvolve seeks to automate through its E-U-R-G (Encode, Store, Retrieve, Manage) loop.
When Investing In Memory Systems, What Considerations Apply?
Investing in machine memory requires a strategic alignment between the physical constraints of the “Memory Wall” and the mathematical laws of Vector Economics. As an investor in an AI lab or hyper-datacenter, your capital allocation should shift across the seven layers depending on whether your goal is infrastructure scale, high-stakes precision, or agentic autonomy.
As a reminder, here is a general framework for investing in memory systems based on use-case significance. Of course, these things are never set in stone and should be used with caution. Many overlaps apply. Business models change over time, also, after all:
1. The Infrastructure Play: Hyper-Datacenters
For investors focused on high-throughput and “Context Maximalism,” the significance lies in the bottom of the stack to break the physical bottlenecks of LLM scaling.
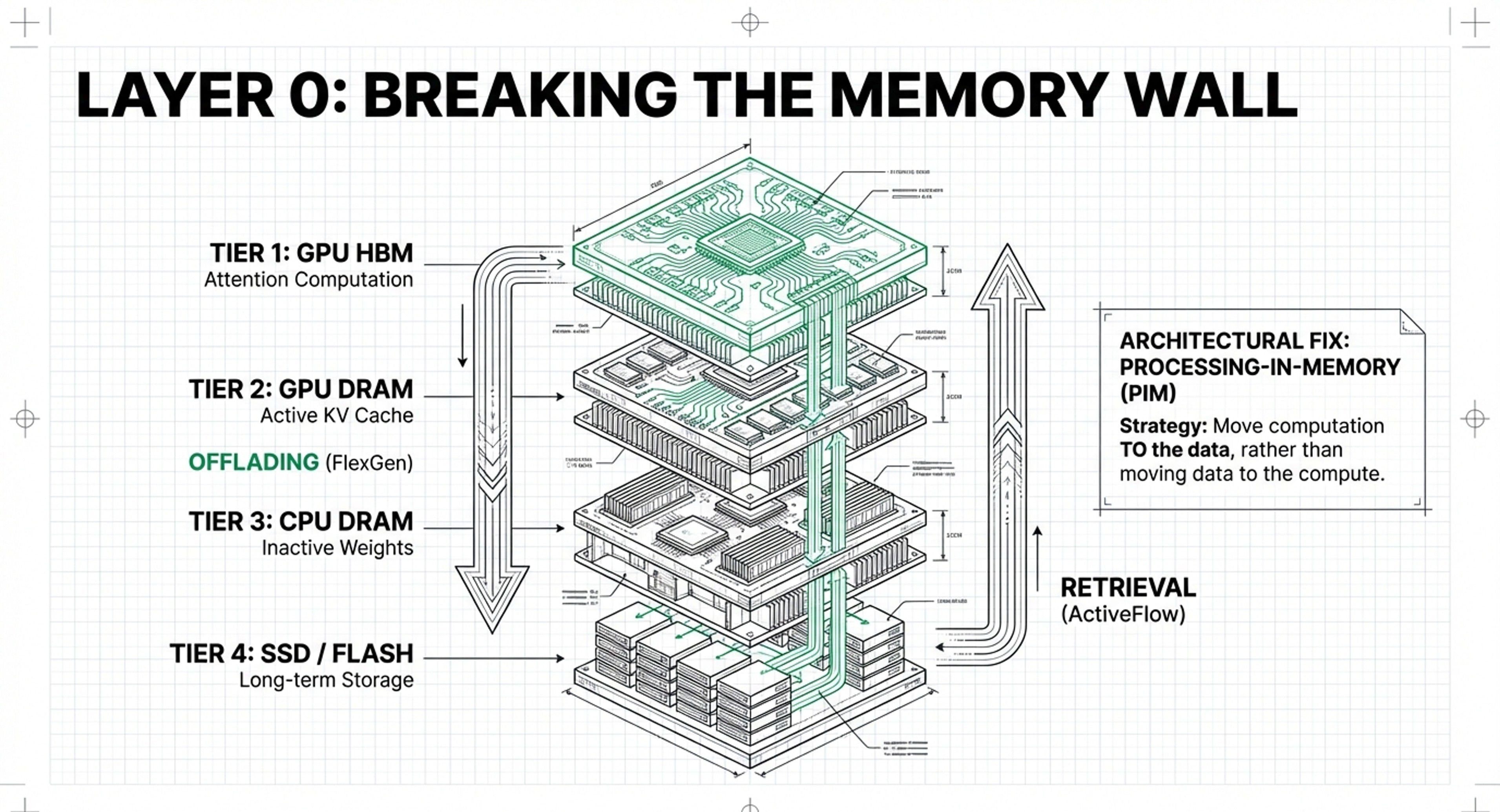
Primary Layers: Layer 0 (Hardware) and Layer 1 (KV Cache).
Investment Focus: Allocate capital toward Processing-in-Memory (PIM) and In-Storage Computing (InstInfer). These technologies move computation to where the data resides, which is critical because memory access currently dominates LLM energy consumption and cost.
Economic Rationale: To support 100M+ token contexts, you must invest in Memory Disaggregation (e.g., DistServe) to separate the “prefill” and “decode” phases, maximizing GPU utilization across heterogeneous clusters.
2. The Strategic Play: AI Labs & Cognitive Agents
For an AI lab building the next generation of “Adaptive Learners,” the investment must move up the stack to enable systems that “learn how to learn”.
Primary Layers: Layer 7 (Cognitive Architecture) and Layer 4 (Procedural Learning).
Investment Focus: Prioritize MemEvolve-style architectures that use “dual evolution” to automatically adjust their Encoding, Storage, and Retrieval (E-U-R-G) based on task feedback.
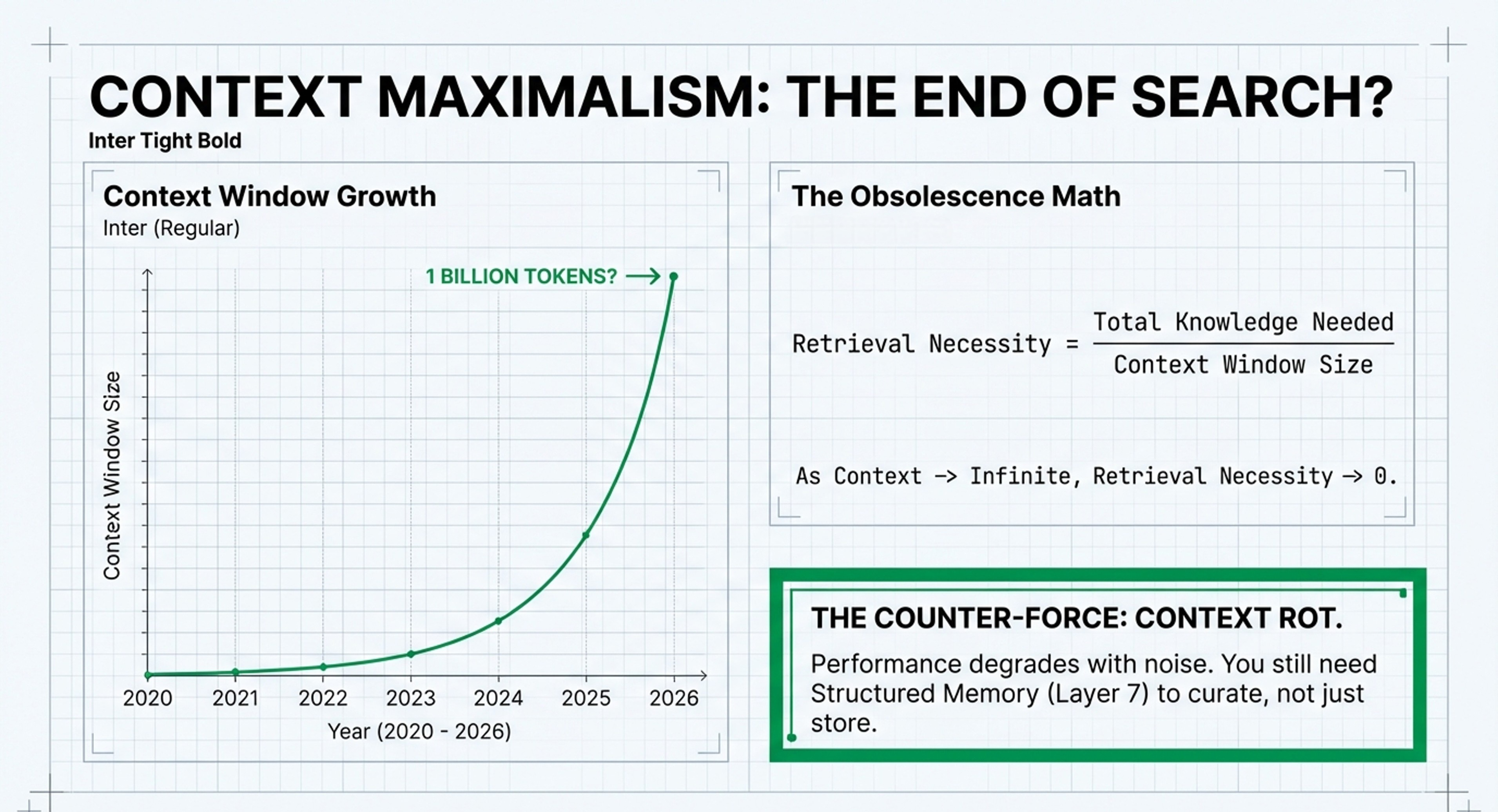
Leonie’s Evolutionary Fit: Invest in transitioning from “read-only” RAG to “read-write” Agent Memory. This involves creating WriteTools that allow agents to consolidate, prune, and “forget” information, which is essential for long-term persistence without “context rot”.
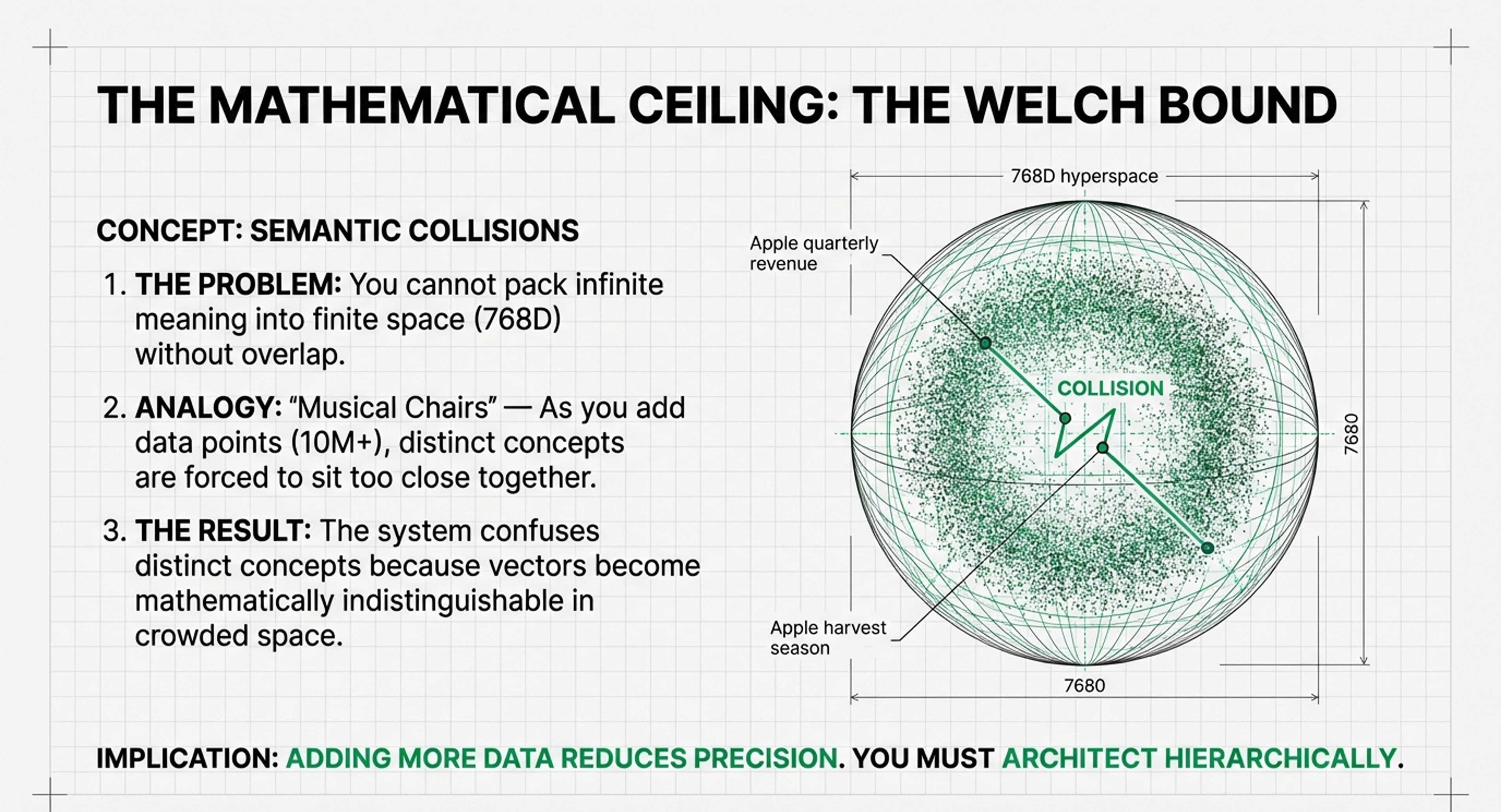
Scientific Goal: Sidestep the Welch Bound (the geometric limit where precision fails) by investing in hierarchical encodings rather than just cramming more data into fixed-dimensional vector spaces.
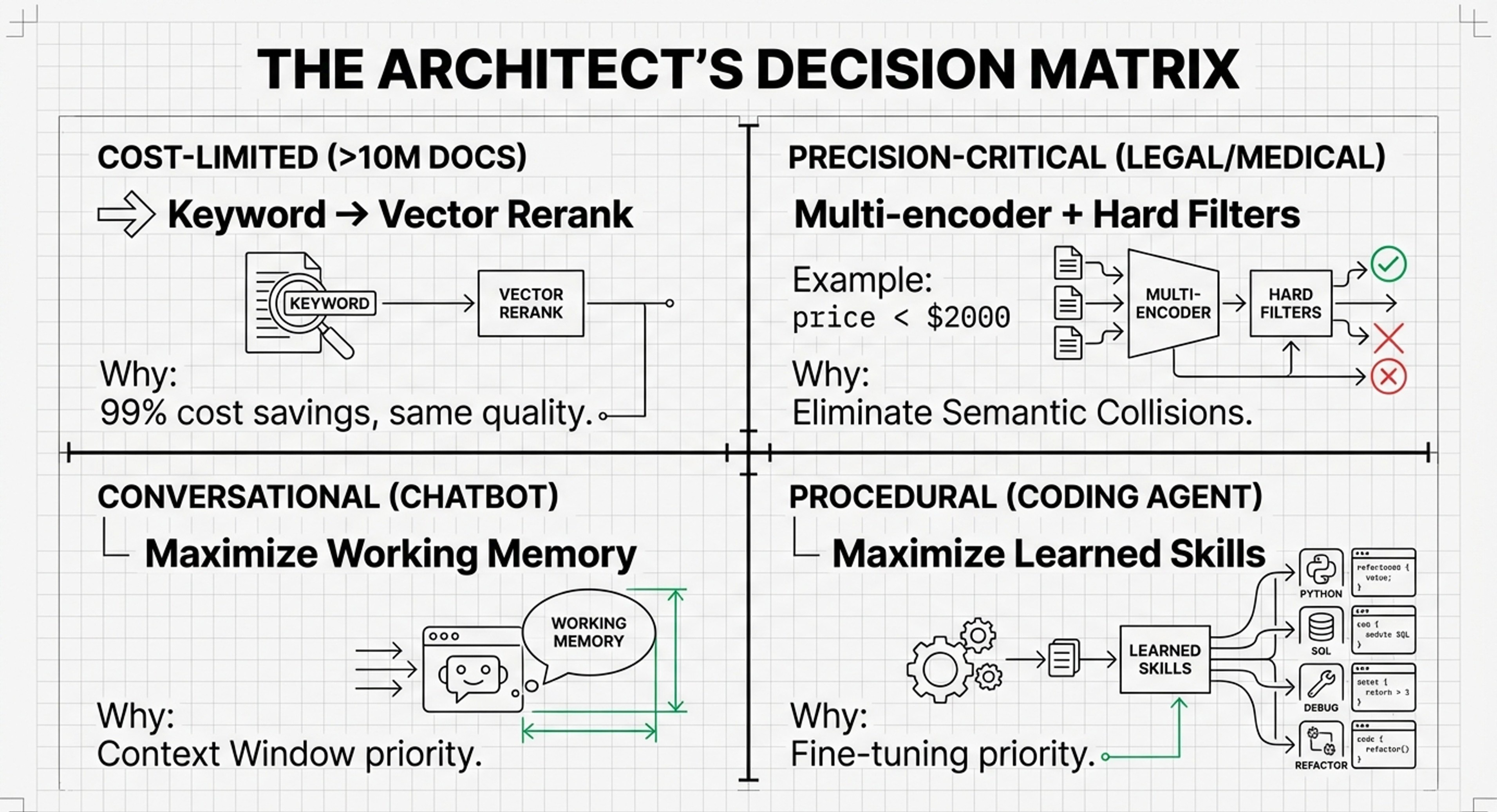
3. The Enterprise Play: High-Stakes B2B (Legal, Medical, Finance)
If the client use-case demands 100% precision and auditability, the investment is a “Hybrid Model” of old and new.
Primary Layers: Layer 3 (Persistence) and Layer 6 (Tool Integration).
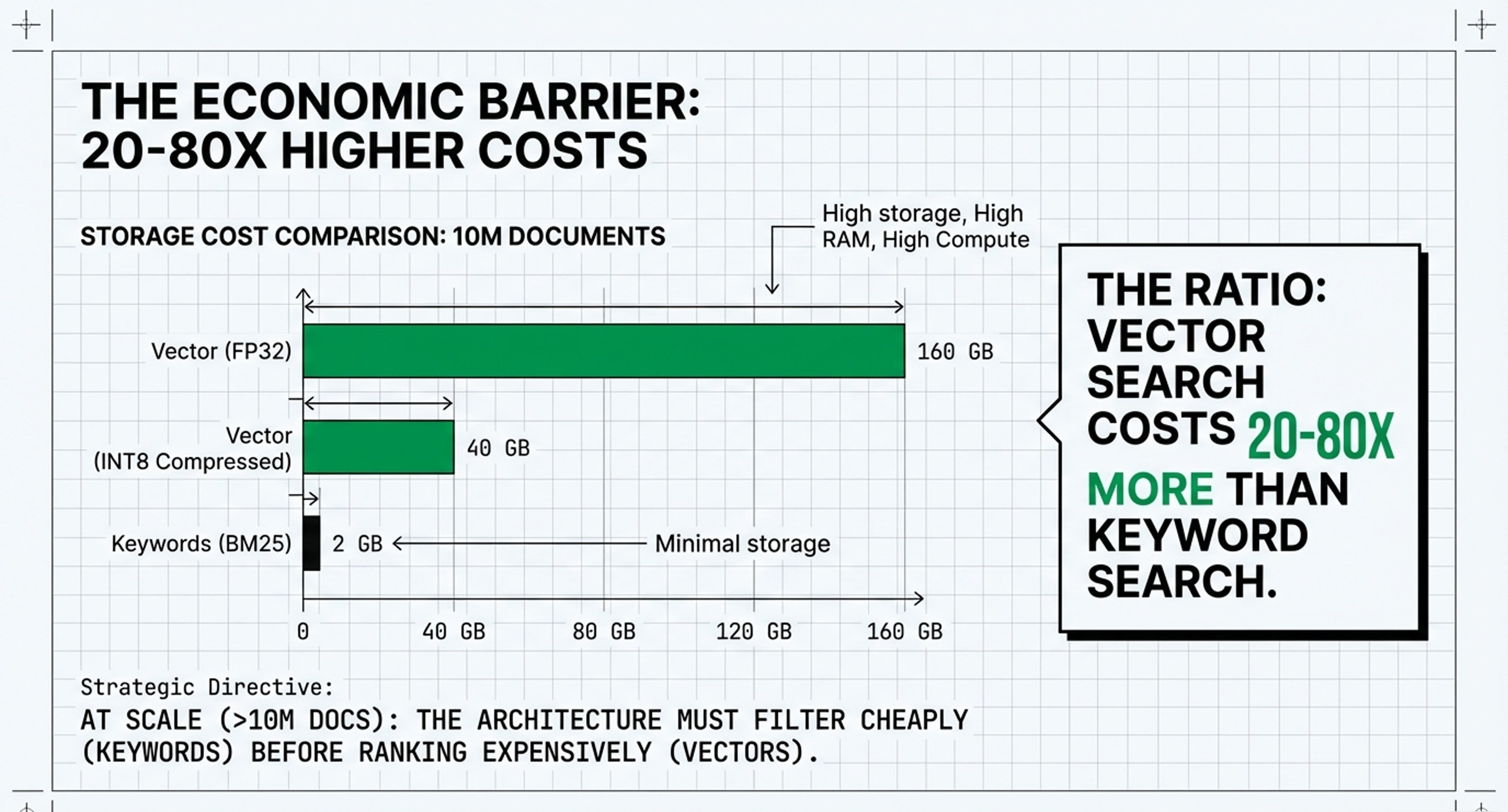
Investment Focus: Rather than a “Vector Gold Rush,” invest in the “BM25 Renaissance.” At the scale of 10M+ documents, vector search is 20-80x more expensive than traditional keyword search.
Decision Framework: Build hybrid architectures where cheap keywords handle the initial 99% of filtering, and expensive, high-dimensional vectors (1,536+D) are used only for the final reranking. This achieves 99% cost savings with minimal quality loss.
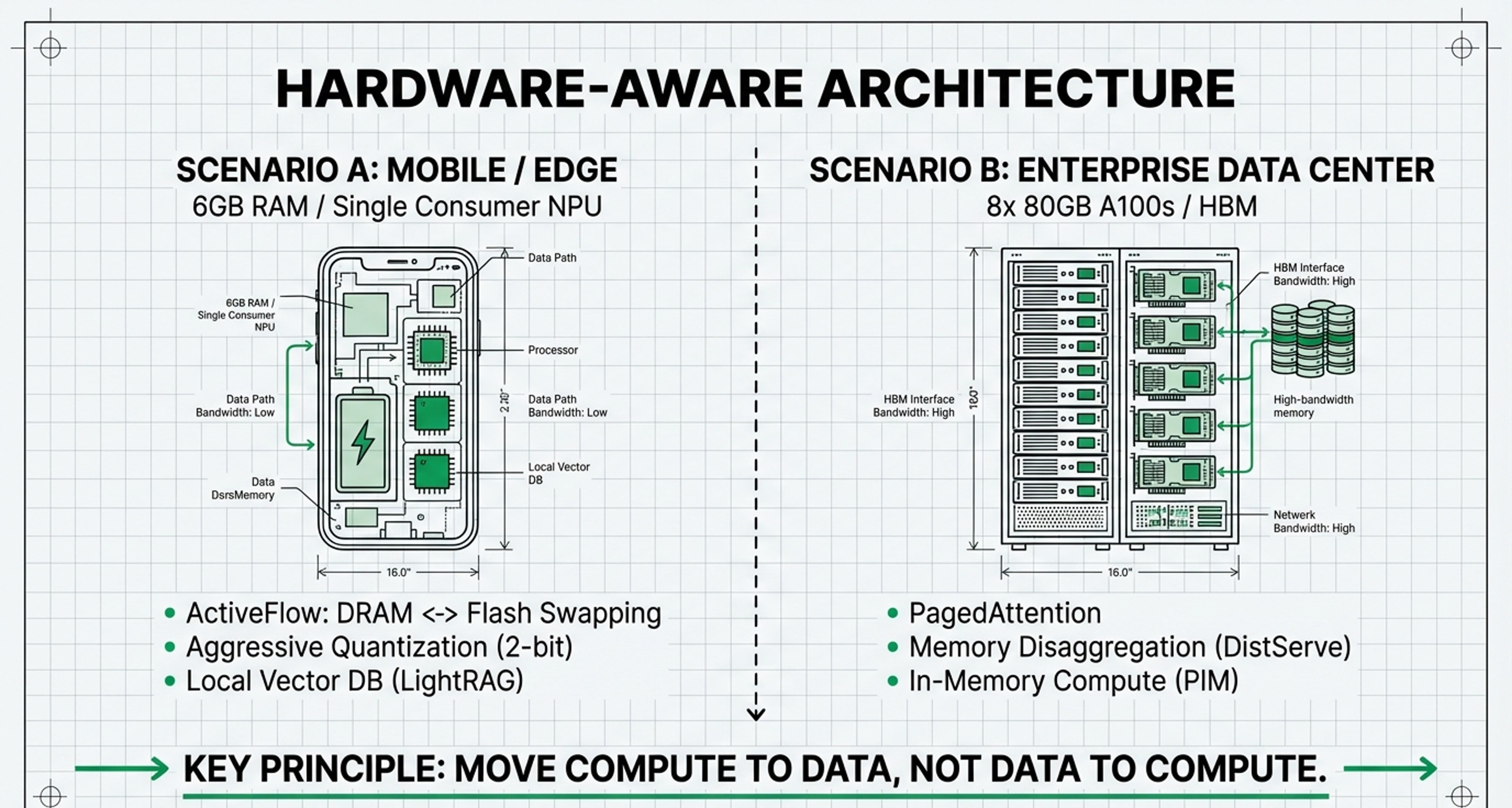
4. The Edge & Mobile Play: Consumer Devices
For clients operating on smartphones or edge devices with limited RAM (e.g., 6GB), the strategy is “Hardware-Aware Software”.
Primary Layers: Layer 0.2 (Heterogeneous Management) and Layer 1 (Efficiency).
Investment Focus: Technologies like Active-Weight Swapping (ActiveFlow) that allow for real-time swapping between DRAM and Flash storage.
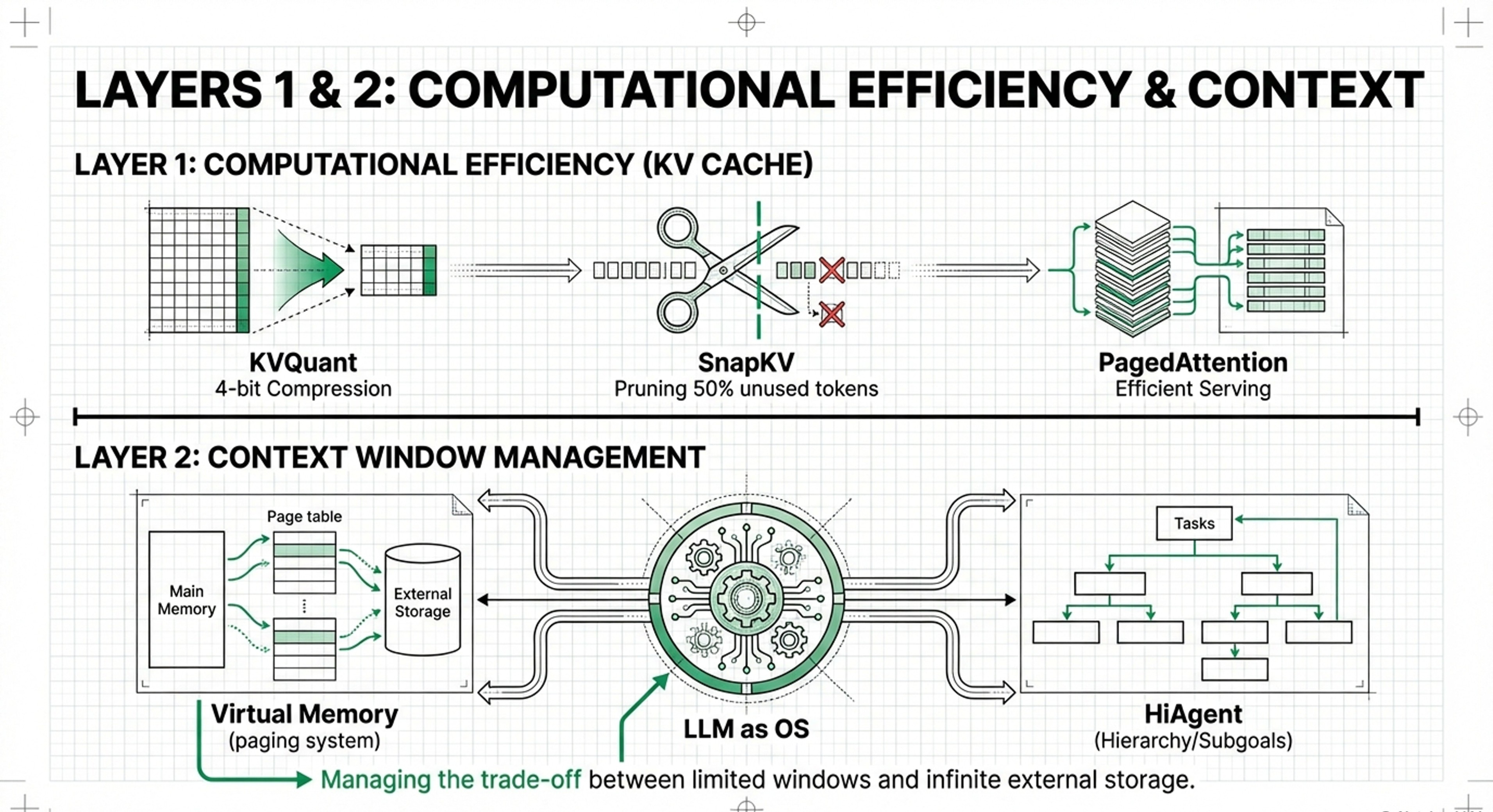
Implementation: Use aggressive 4-bit or 2-bit KV cache quantization (KVQuant) to fit larger models into smaller VRAM footprints.
Summary of Investment Significance
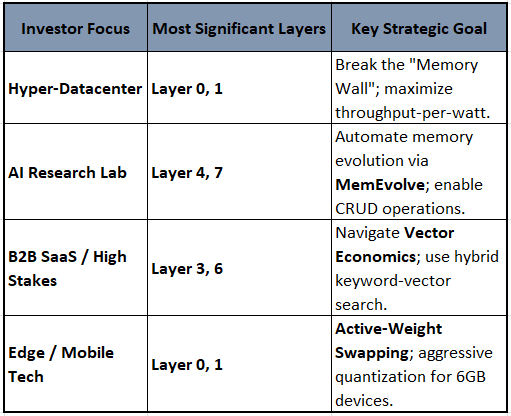
Strategic Insight: As an investor, you should bet on Architecture over Algorithms. The future belongs to systems that treat memory as a 4-tier hierarchy (GPU VRAM → GPU DRAM → CPU DRAM → SSD) and use an Evolutionary Control Plane to move data between those tiers based on cost and performance constraints.
Thinking About The Significance of KV Cache
In the seven-layer taxonomy of machine memory, the KV Cache (Layer 1: Computational Efficiency) represents the active “working memory” needed for LLM inference. Its significance varies drastically across the four investment scenarios, often acting as the primary bottleneck that the other “most significant” layers are designed to solve.
1. Hyper-Datacenter: Primary Throughput Driver
In hyper-datacenters, the KV Cache is equally significant to the previously identified Layer 0 (Hardware).
• The Conflict: While Layer 0 provides the physical foundation (PIM, HPU), the KV Cache is the primary consumer of that hardware’s bandwidth and capacity.
• Significance: To achieve high-throughput deployments, datacenters must prioritize Layer 1 optimizations like PagedAttention (vLLM) and Memory Disaggregation (DistServe) to manage the KV Cache across heterogeneous GPU clusters.
• Combined Goal: The goal is maximizing “goodput,” where Layer 0 hardware improvements are specifically engineered to handle the massive KV Cache footprints of concurrent users.
2. AI Research Lab: A Functional Tool for the Cognitive Engine
For an AI Research Lab, the KV Cache is secondary to the Layer 7 (Cognitive Architecture) and Layer 4 (Procedural Learning).
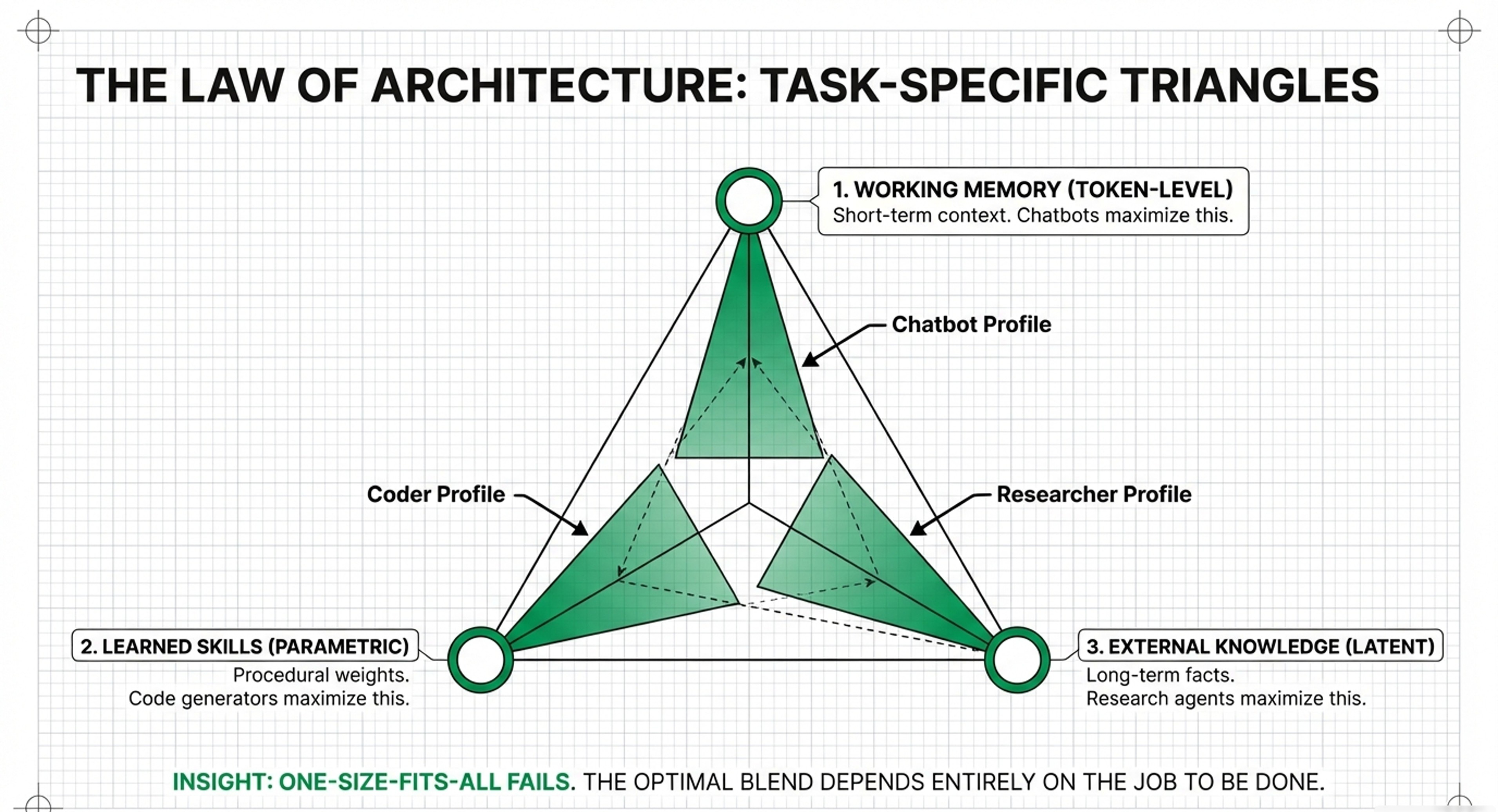
• The Conflict: Researchers view the KV Cache as a component of the “Working Memory” in the Memory Triangle.
• Significance: While Layer 1 is a “peak innovation” area with numerous papers on quantization and pruning, a research lab’s primary interest is in how the MemEvolve engine manages these layers.
• Combined Goal: The focus is on meta-learning; the system evolves to determine if it should compress the KV Cache (Layer 1) or shift information into long-term persistence (Layer 3) to sidestep the Welch Bound.
3. B2B SaaS / High Stakes: Low Significance Relative to Persistence
In high-stakes enterprise environments, the KV Cache has lower significance than Layer 3 (Persistence) and Layer 6 (Tool Integration).
• The Conflict: The “Law of Economics” dictates that at the scale of 10M+ documents, the cost of external storage and retrieval (Layer 3) far outweighs the cost of the active KV Cache.
• Significance: For B2B clients, the focus is on Vector Economics and the “BM25 Renaissance”—reducing the cost of the 99% of work done by cheap search before using the KV Cache for the final 1% of reasoning.
• Combined Goal: Precision and cost-efficiency are achieved by using hybrid search (keywords + vectors) rather than maximizing the expensive active context held in the KV Cache.
4. Edge / Mobile Tech: Critically Significant for Physical Feasibility
On edge and mobile devices, the KV Cache is critically significant, rivaling the importance of Layer 0 (Hardware) for basic functionality.
• The Conflict: Mobile devices are often capped at 6GB RAM, making the KV Cache a lethal bottleneck for LLMs.
• Significance: On-device agents are only possible through aggressive Layer 1 quantization (2-bit) and Layer 0 DRAM-Flash swapping (ActiveFlow).
• Combined Goal: Here, the KV Cache is the “make or break” factor; without extreme Layer 1 efficiency, the model cannot fit within the device’s physical constraints, regardless of the software architecture.
Summary of Comparison Table:
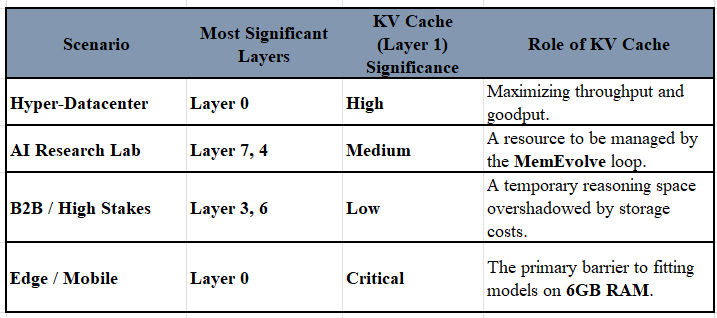
Intuition around KV Cache
Before I get into the intution around KV Cache, here is a summary of the eight layers (Layer 0 through Layer 7), their purposes, and the intuition behind their shifting significancefirst.
The Memory Hierarchy: Purposes and Purposes
• Layer 0: Hardware & System Infrastructure: The physical foundation. Its purpose is to overcome the “Memory Wall” (GPU VRAM capacity and bandwidth bottlenecks). It involves specialized tech like Processing-in-Memory (PIM) and moving computation to where data resides.
• Layer 1: Computational Efficiency (KV Cache): The active “working memory” used during LLM inference. Its purpose is to store the keys and values of previous tokens so they don’t have to be recomputed, which is essential for speed and generating long responses.
• Layer 2: Context Window Management: Acts as “Virtual Memory” for LLMs. It manages what the model can “hold in mind” at any given moment, often using strategies to extend the effective window beyond physical limits.
• Layer 3: Long-Term Persistence: The home of RAG (Retrieval-Augmented Generation). It stores external knowledge, past conversations, and facts in databases to be retrieved on-demand.
• Layer 4: Procedural Learning: The “skill” layer. It focuses on how agents learn patterns, grammar, and reasoning through interactions rather than just storing raw facts.
• Layer 5: Multimodal Memory: Manages sensory data like images, video, and audio, allowing agents to “remember” visual or auditory experiences.
• Layer 6: Tool Integration: The meta-cognitive layer where agents learn to use external tools (like search engines or APIs) to verify facts or perform actions.
• Layer 7: Cognitive Architecture: The “Brain” or Operating System that coordinates the other layers. It handles CRUD operations (Create, Read, Update, Delete) and memory consolidation—deciding what to keep and what to “forget”.
--------------------------------------------------------------------------------
Intuition: Why is KV Cache (Layer 1) Sometimes Critical and Sometimes Not?
The significance of a layer is determined by your constraints (The Memory Triangle) and the scale of your data (Vector Economics).
1. When it is CRITICAL: High Throughput & Hardware Constraints
• Intuition: If you are running an LLM on a device with limited memory (like a phone) or serving thousands of users at once, the KV Cache is the primary bottleneck. If it grows too large, the system crashes or becomes prohibitively slow.
• Operating Example: vLLM (PagedAttention) is now an industry standard because it solved the “fragmentation” of KV Cache, allowing datacenters to handle more users on the same hardware. On mobile, ActiveFlow swaps data between DRAM and Flash in real-time to prevent the KV Cache from overwhelming the phone’s 6GB of RAM.
2. When it is LESS CRITICAL: Massive-Scale Knowledge Retrieval
• Intuition: If you are a large company with 10M+ documents, your main problem isn’t the active cache during one conversation; it’s the cost and accuracy of finding the right document in the first place.
• Operating Example: In the “BM25 Renaissance,” entities like IBM or large legal firms might prioritize Layer 3 (Persistence). Because vector search is 20-80x more expensive than keyword search, they invest in cheaper filtering methods before even worrying about the LLM’s active KV Cache.
3. When it is “SITUATIONAL”: Complex AI Agents
• Intuition: For an autonomous agent, the Cognitive Architecture (Layer 7) is more important than the KV Cache. It doesn’t matter how fast the cache is if the agent can’t “learn” to update its memory.
• Operating Example: MemGPT treats the context window like an Operating System, moving data in and out of the “working memory” (KV Cache) automatically. Here, the KV Cache is just a tool managed by a higher-level logic.
Summary of Operating Entities and Their Layer Focus
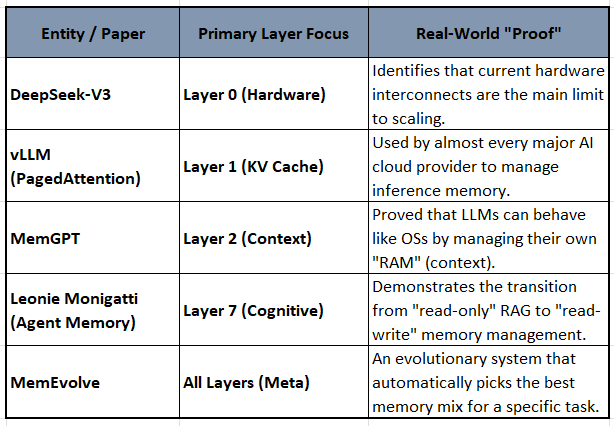
Toward Efficient Agents: A Survey of Memory, Tool learning, and Planning
This recent Survey paper is another excellent read that allows the Framework to be seen in deeper, practical light.
“Toward Efficient Agents: A Survey of Memory, Tool Learning, and Planning,” significantly expands the scope of machine memory research by transitioning from a memory-centric view to a holistic “Efficient Agent” system. While both my articles on Machine Memory and Memory Systems establish the strategic math and infrastructural layers of memory, the survey adds the critical dimensions of Tool Learning and Planning as equal pillars of efficiency.
How the Survey Paper Adds to the IE Articles
1. Broadening the Efficiency Definition While Machine Memory focuses on Vector Economics and Memory Systems on the “Memory Wall,” the survey defines efficiency as a Pareto frontier between effectiveness and three specific resource costs: latency, tokens, and steps. It moves beyond “memory management” to “operational control,” where the system balances the marginal utility of a better plan against its computational cost.
2. Integrating Tool Learning and Planning The survey identifies that tool usage and multi-step planning are the primary drivers of “compounding token accumulation” in agents. It adds:
• Efficient Tool Learning: Strategies to minimize tool calls and reduce external interaction latency (e.g., Vocabulary-based retrieval, where tools are special tokens).
• Efficient Planning: Techniques to prune search trees (e.g., A* search) and distill complex multi-agent coordination into a single-agent “student” model to bypass runtime overhead.
3. Categorizing Multi-Agent Dynamics While Memory Systems mentions multi-agent hardware setups like Jenga, the survey provides a deep technical taxonomy of Multi-Agent Memory (Shared vs. Local vs. Mixed) and Topological Efficiency, showing how to reduce message complexity from O(N2) to O(N) through structured interaction chains.
--------------------------------------------------------------------------------
Framework Contrast: Three Viewpoints
The frameworks across the three sources differ in their “Organizing Logic”:
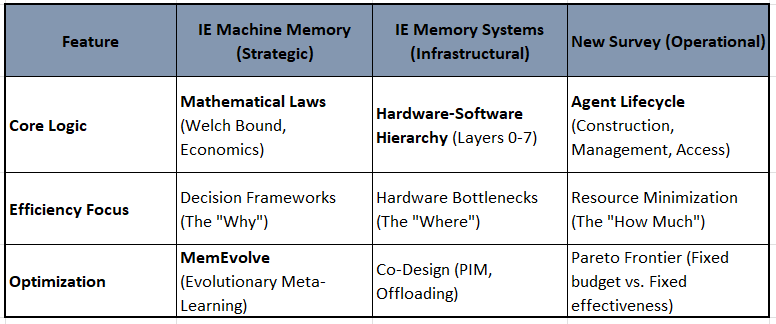
Similarities and Strategic Alignment
Despite different starting points, the frameworks converge on three key principles:
• The Management Mandate (CRUD): All three sources agree that “Naive RAG” (read-only) must evolve into Agent Memory (read-write). The Survey’s “Memory Management” phase (Rule-based vs. LLM-based) mirrors Leonie Monigatti’s transition to “WriteTools” and Memory Systems’s Layer 7 (Cognitive Architecture).
• Compression as an Efficiency Driver: The IE articles discuss context window management to avoid “context rot”. The survey provides the technical roadmap for this through Latent Integration (KV cache compression) and Summarization-based Construction to solve the “lost in the middle” phenomenon.
• MemEvolve as the Bridge: The MemEvolve concept (in Machine Memory) is perfectly validated by the survey. MemEvolve’s “Inner/Outer Loop” approach to navigating performance, cost, and delay is exactly what the survey describes as the Pareto-ranking approach to selecting memory architectures.
Conclusion: I guess intuitively, If Machine Memory is the Architect’s Strategy and Memory Systems is the Contractor’s Blueprint, the Survey paper is the Efficiency Auditor’s Manual. It provides the concrete metrics (token count, API cost, GPU usage) and the expanded toolset (Tooling/Planning) needed to actually build the “Smart Building” envisioned in the combined framework
This piece really made me think, especially after your previous one on Machine Memory. It's so cool how you're tracing the evolution from RAG to Agentic RAG and beyond. The 'Memory Triangle' and multi-tier optimisation parts are super insightful. You've totally nailed the nuance here, really appreciate the depth.