
Two Economies, One Technology
Why Agentic AI's Impact Will Diverge by Industry, Function, and Regulatory Regime

This is the second in a series, and a companion piece to "What Is Any Agentic Architecture Worth Anyway. PharmaCo International: An Agentic AI Case Study" Where I have gone deep with this case study, the material below takes a wider scope on the impact of AI and Agentic AI structures to industry.
A note on what this is. Everything that follows is opinion backed by recent data on AI adoption and actual successes, where it may likely be found — informed by the PharmaCo case study, by the Harness Lab experiments (H1–H10) that underpin it, and by a broader read of where the agentic AI market actually stands in mid-2026. It is not a forecast with confidence intervals. Where the view here contrasts with mainstream market enthusiasm, or with the more cautious findings of recent research, both sides are presented — the goal is to give readers the material to form their own judgment, not to win an argument. Whilst my use and practical application of the findings here have been helpful to me, you could have differing views, based on industry task-specific application.
1. The cost-side ceiling
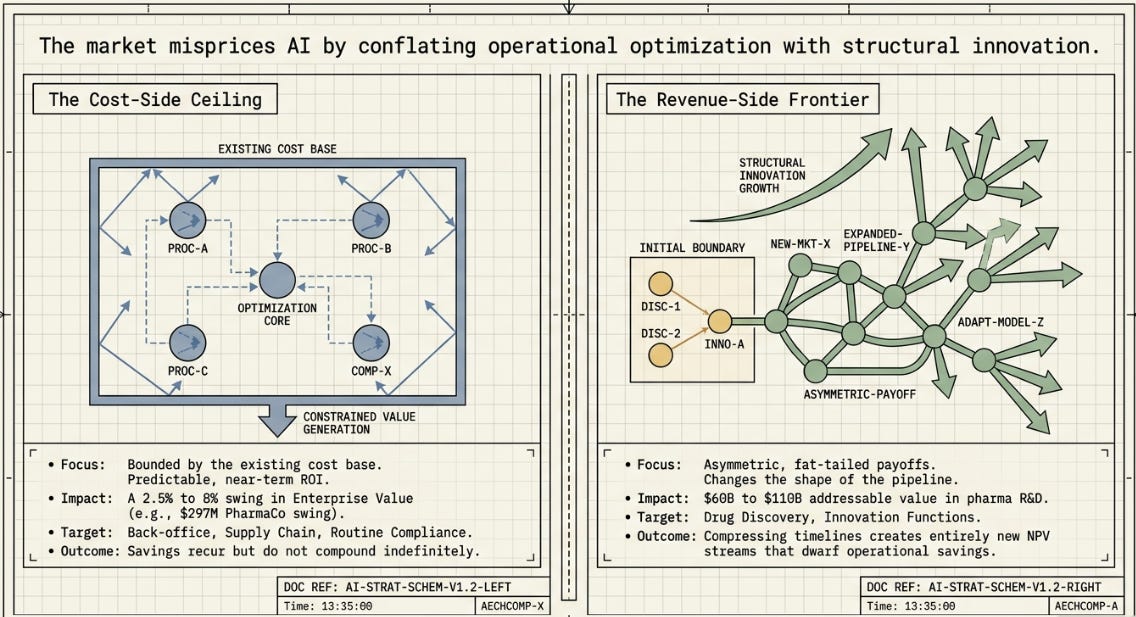
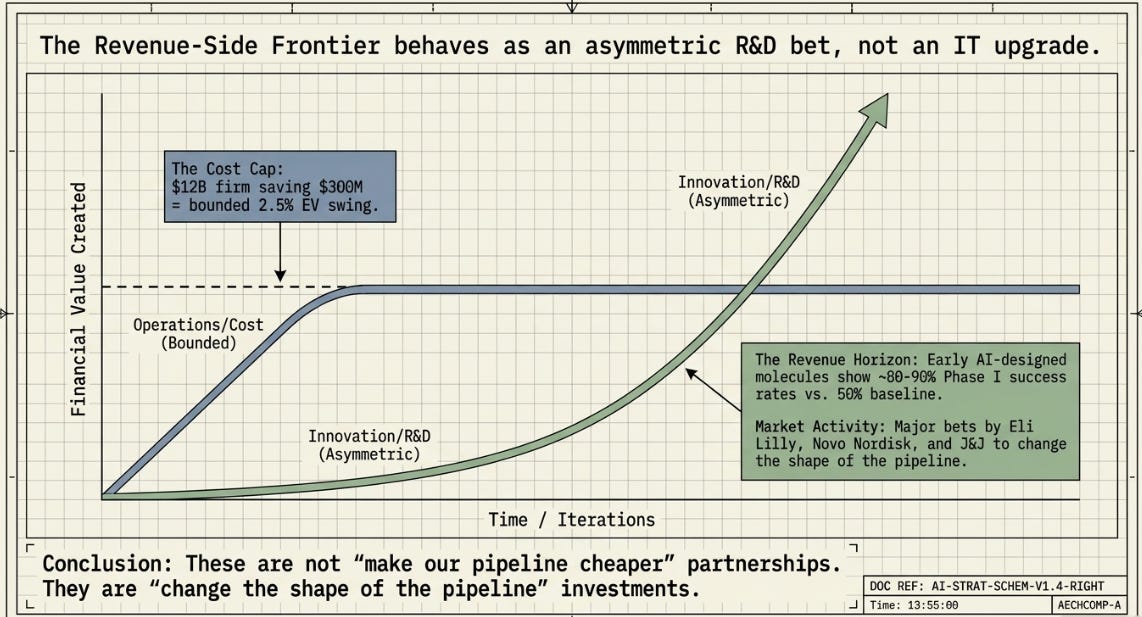
The PharmaCo case study, on its own numbers, makes an unglamorous point: choosing the right harness architecture for disruption response was worth roughly $297M in enterprise value versus the “wrong-but-plausible” alternative, and getting it badly wrong (H4) was worth nearly $1B in destroyed value versus the recommended choice (H2). Against a $12B company, that’s a 2.5–8% potential swing in enterprise value from one operational decision.
That is a real number. It is also, deliberately, the ceiling of what a cost-avoidance story can deliver — because cost savings are bounded by the size of the cost base you’re optimizing. PharmaCo’s disruption-response function is a sliver of its total operating cost. Even a dramatic improvement to a sliver is, by construction, a small improvement to the whole.
This is the part of the agentic AI story that’s easiest to model, easiest to benchmark (it’s exactly what the H1–H10 experiments measured), and — I’d argue — the part most over-indexed in how the market currently talks about AI’s impact on individual companies. “We deployed agents and cut costs by X%” is a real, fundable, board-defensible story. It is also a story with a visible end-state: once the process is automated, the savings don’t compound indefinitely, they just recur. That could be good enough for companies in steady state, dividend plays. But….
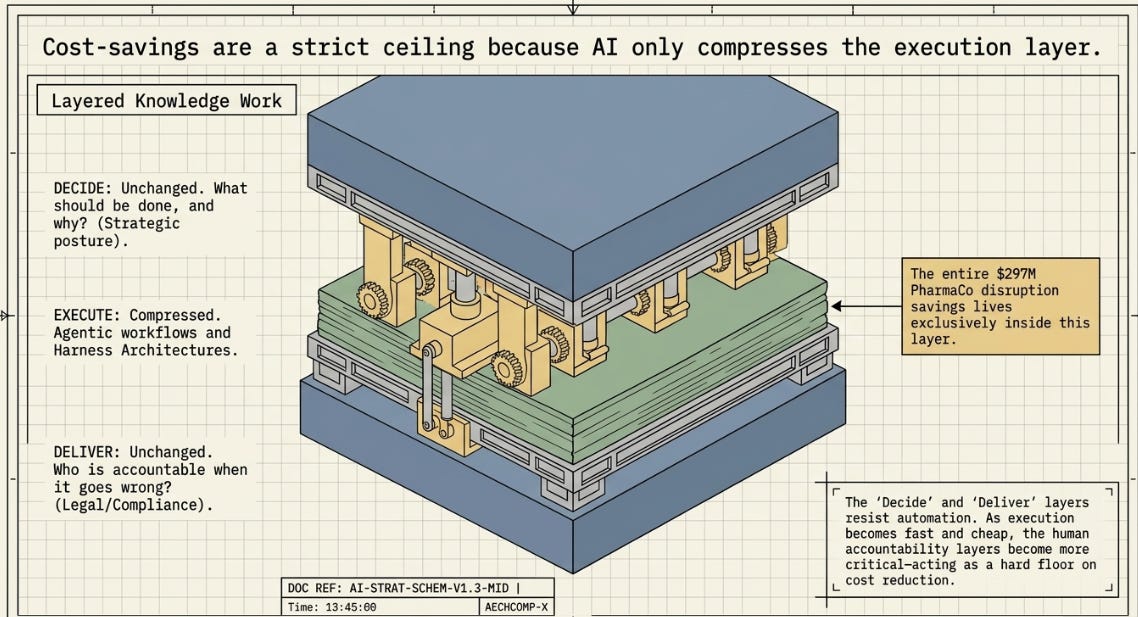
A useful way to see why this ceiling exists comes from a framework Arvind Narayanan and Sayash Kapoor proposed for knowledge work generally: most jobs are a “decide-execute-deliver sandwich,” where AI compresses the execute layer in the middle but leaves the decide layer (what should be done, and why) and the deliver layer (who’s accountable for whether it was done right) largely untouched. Read through that lens, H2’s win over H9 is squarely an execute-layer story — which architecture responds fastest and most coherently to a disruption PharmaCo’s leadership has already decided is worth responding to, and for which someone remains accountable regardless of which architecture ran the response. The $297M–$986M swing is real, but it’s a swing within the execute layer; it doesn’t touch who decides PharmaCo’s disruption-response posture or who’s accountable when a plan goes wrong. That’s the structural reason the ceiling exists — not merely an artifact of this particular cost base being small.
2. The revenue-side frontier
The more interesting — and much harder to model — story is what happens when agentic AI touches the top of the income statement rather than the cost lines underneath it. Drug discovery is the cleanest illustration, because the economics of pharma R&D are already asymmetric and option-like before AI enters the picture: most programs fail, a small number succeed enormously, and the entire industry’s economics are built around that distribution.
The numbers being floated for AI’s effect on that distribution are large enough that they’re worth taking seriously even with a generous discount for hype. McKinsey-style estimates put the addressable annual value of generative AI across the pharma value chain in the $60–110B range, with some forecasts running considerably higher when R&D productivity gains are included. The AI-in-drug-discovery tooling market itself is still small (low single-digit billions in 2025–26) — the action is in what the tools enable, not in the tools as a line item. Exscientia has pushed multiple AI-designed candidates into clinical trials in under a year, a process that historically takes years. Insilico Medicine’s AI-designed candidate has progressed toward Phase III. Early data on AI-designed molecules entering Phase I shows success rates well above the historical industry average (roughly 80–90% versus a long-run baseline near 50%), though the sample sizes are still small and no AI-originated drug has yet completed the full approval pipeline — most forecasts put the first such approval in 2026–2028. Note: Takeda's zasocitinib (covered in my separate Funnel/Floor/Structure piece) has since cleared Phase III and is pending an FDA filing within fiscal 2026.
What’s striking is the deal activity this is attracting from companies that are not AI companies: Eli Lilly’s multi-billion-dollar partnership with Insilico Medicine, Novo Nordisk’s R&D-and-manufacturing partnership with OpenAI, Johnson & Johnson’s multi-target collaboration with Isomorphic Labs, GSK’s infrastructure partnership with Noetik. These are revenue-side bets by companies that already have functioning, profitable cost structures — the rationale isn’t “make our existing pipeline cheaper,” it’s “change the shape of the pipeline itself.”
This is the asymmetry that a cost-avoidance model like PharmaCo’s disruption-response case structurally cannot capture. Compressing a discovery timeline by even a year, or modestly improving a Phase II success probability, doesn’t show up as a percentage on an existing cost line — it can mean an entire additional revenue stream that wouldn’t otherwise exist, at NPV magnitudes that dwarf the $297M–$986M range from Section 10 of the PharmaCo case.
2.1 A third axis: when the payoff isn’t cost or revenue, but capability
The framing above already brushes up against something worth pulling out and naming on its own. Some of history’s technologies with the largest eventual economic impact looked, for years after their invention, like poor investments by any cost-or-revenue test — not because the technology had failed, but because “what does this save, or what does this sell” was the wrong question to be asking yet. GPS spent decades as a defense programme before it became a civilian product category. Genome sequencing absorbed a multi-billion-dollar, decade-long public investment before it produced anything resembling a return. Early integrated circuits had nothing like the cost or performance advantage that would later make them ubiquitous. In each case the technology wasn’t expanding a margin or opening a revenue line yet — it was making something previously impossible now possible, and a cost/revenue lens only became the right one to apply once that capability already existed.
Pharma R&D is the cleanest current illustration of this third axis, but it isn’t unique to pharma. Semiconductor design is arguably just as strong a case: the more consequential AI-driven outcome there isn’t “design existing chips more cheaply” — a Floor-type claim — but whether AI-assisted exploration of interconnect topologies, packaging techniques, or photonic architectures turns up designs no human engineering team would have proposed on its own. That’s the same fat-tailed, capability-expanding logic as drug discovery, applied to an entirely different industry. Read this way, AI’s most consequential role in both fields starts to resemble less a labour-saving tool and more a scientific instrument in the lineage of the microscope or the telescope — something that doesn’t make existing inquiry cheaper so much as it opens an entirely new field of inquiry. Whether agentic AI eventually belongs in that category, rather than the labour-automation category this essay otherwise treats it as, is one of the more consequential open questions this framework doesn’t resolve on its own.
This third axis lives inside the Funnel described in Section 1 above and developed further in “The Funnel, the Floor, and the Structure” — the Funnel was already described as capable of changing which bets enter a pipeline, not merely speeding up existing-style ones. What this subsection adds is a name for the most extreme version of that tail, because “capability expansion” describes a meaningfully different kind of bet than “a marginally better version of an existing product”: one where, in the years before the new capability proves out, the honest answer to “what’s the ROI” may legitimately be poor, unclear, or negative — without that being evidence the bet is failing.
2.2 A scope boundary worth naming: this framework doesn’t explain state-funded capability bets
One place this matters concretely: government and defense investment in exactly this kind of capability-expanding technology — nuclear research, early aerospace, GPS’s own military origins, internet infrastructure — has historically continued despite weak or unclear near-term ROI, for a reason this essay’s framework doesn’t capture. A state funding a capability bet isn’t optimising for enterprise value or profit margin at all; the payoff currency is strategic position or security, which doesn’t convert into the kind of multiple-based valuation Section 10 of the PharmaCo case uses, or the enterprise-value language this essay has used throughout. A “poor” dollar-denominated ROI can be the expected and accepted outcome of that kind of bet, not evidence it is failing.
This is worth flagging explicitly rather than leaving it implicit, because the companion piece “Does Agentic AI Matter?” leans on Nicholas Carr’s argument that universally available technology stops conferring competitive advantage — a claim specifically about firms competing against other firms for advantage measured in profit or market position. That argument was never built to explain why a state keeps funding a capability with unclear near-term returns, and it shouldn’t be read as implying such investment is irrational simply because it doesn’t show up favourably on this essay’s cost/revenue axis. Where this series’ frameworks are scoped to firm-level competitive strategy, state-level capability investment is a different actor optimising for a different currency entirely — outside this series’ scope by construction, not by oversight.
3. One company, two economies
Here’s where I think the PharmaCo case study is most useful as a diagnostic, even though it deliberately stayed on one side of this divide: the same company can be living in both economies simultaneously, and the three drugs in that case — Lisinopril, Metformin, Salbutamol — are the tell. All three are decades-old, off-patent, generic small molecules. No real innovator pharma builds its strategic narrative around a generic API supply disruption; that’s a generics manufacturer’s problem (Teva, Viatris, Sandoz, and similar companies operate exactly this kind of import-dependent, thin-margin, operationally-driven business).
A pure generics manufacturer is, almost by definition, living entirely in the cost-side economy — there’s no R&D pipeline to accelerate, no patent-protected revenue to expand, just margin to defend against exactly the kind of supply shock PharmaCo modeled. For that company, the PharmaCo case study’s framing is close to the whole story: harness architecture choice is a capital allocation decision measured in tens to low hundreds of millions of enterprise value.

An innovator pharma with a real R&D pipeline is a different company wearing the same SIC code. Its back office, supply chain, and compliance functions face exactly the same cost-side calculus as the generics manufacturer — but its R&D division is playing the revenue-side game described in Section 2, where the numbers are an order of magnitude larger and far less certain. Pfizer’s CFO described 2026 R&D productivity gains from AI as freeing up capacity to “take on more substrate” for future medicines — note that this is explicitly framed as a productivity reallocation story (do more with the same budget), not a cost-cutting story; the $11B R&D budget for 2026 didn’t shrink.
If I had to state the view plainly: regulated industries will likely see smaller near-term cost-side gains than unregulated ones (because compliance overhead bounds how much of the back office can actually be automated, and regulatory review timelines are exogenous to how fast your internal systems run), but potentially much larger long-run revenue-side gains in their R&D/innovation functions specifically — because that’s where the bottleneck is internal throughput rather than external approval timelines, and where the payoff distribution is fat-tailed enough that even modest probability shifts are worth enormous amounts.
The counter-view, and it’s a serious one: AI-discovered molecules still have to clear the same Phase I/II/III gauntlet as everything else, and as of mid-2026 zero have done so. FDA guidance on AI use in regulatory submissions (the January 2025 draft and the January 2026 “Guiding Principles” follow-up) is explicitly risk-based and incremental — regulators are not going to compress review timelines just because the candidate was AI-designed. It’s entirely possible the revenue-side story takes the rest of this decade to show up in actual approved-drug revenue, in which case the cost-side story — unglamorous as it is — remains the only one with a near-term P&L impact, for pharma specifically.
4. Where cost and revenue collapse into the same line: software
Pharma’s cost-side and revenue-side stories are separable because R&D and operations are organizationally separate. Software — and SaaS in particular — is the industry where I think this separation breaks down entirely, which is also why I’d guess it’s where most of the current Silicon Valley enthusiasm is actually anchored, even when the framing is about AI “in general.”
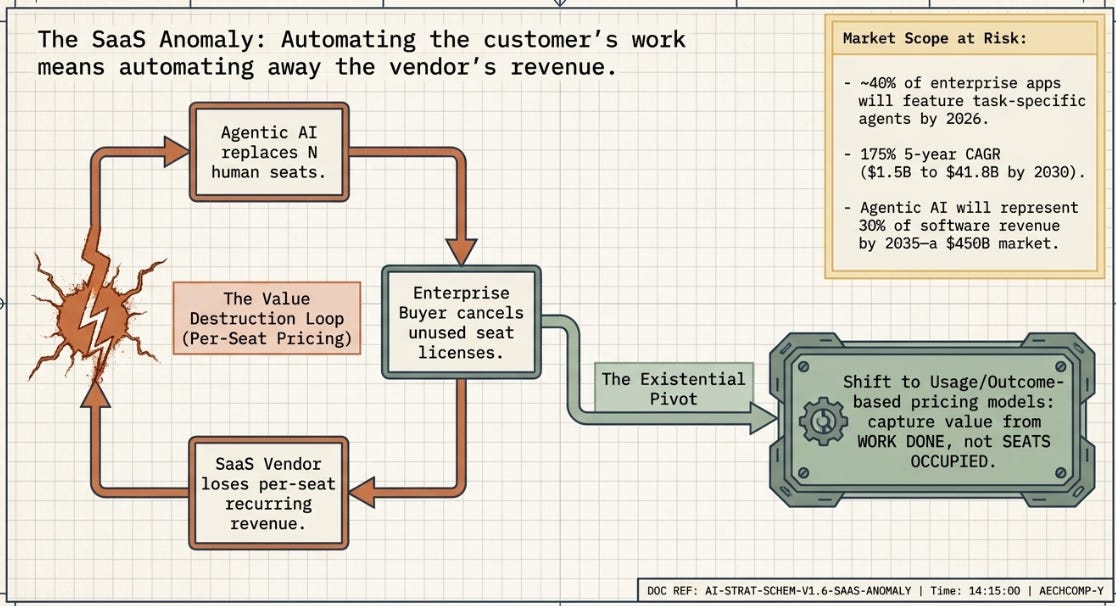
The mechanism is structural: SaaS revenue has historically been priced per seat — you pay for the number of humans who use the software. If an agentic AI system can do the work that used to require N human seats, two things happen to the same line item simultaneously: the buyer’s cost structure improves (fewer seats needed) and, if the vendor doesn’t change its pricing model, the vendor’s revenue declines — automating away your customers’ need for seats is, under per-seat pricing, automating away your own revenue. This is being described candidly in the industry press as an existential pricing problem, not a hypothetical one, and it’s why 2026 has seen a rapid, real shift toward usage-based and outcome-based pricing — vendors are trying to reposition themselves to capture value from the work done by agents rather than the seats occupied by humans, before their customers do the arbitrage for them.
Gartner’s numbers on this are aggressive but illustrative of the direction: roughly 40% of enterprise applications expected to ship with task-specific agents by the end of 2026 (up from under 5% in 2025), with a best-case long-run projection of agentic AI representing something like 30% of enterprise application software revenue by 2035 — a market north of $450B. Omdia’s estimate of the enterprise agentic AI software market itself growing from roughly $1.5B (2025) to $41.8B (2030) — a five-year CAGR around 175%, far outpacing generative AI’s earlier growth curve — is one of several data points suggesting investors are pricing this as a structural shift in how software is bought and sold, not an incremental feature.
This is, I think, the closest thing to a single coherent answer to “what is Silicon Valley so excited about”: not drug discovery specifically (too slow, too regulated, too far from most VC portfolios), and not generic cost-cutting (too small per company, as Section 1 shows) — but the prospect of an entire industry’s revenue model being re-architected around metered agent output, with the companies that reposition first capturing share from those that don’t. It’s a revenue-side story for the software industry as a whole, even though for most of software’s customers it shows up as a cost-side story (fewer seats, lower software spend, redeployed headcount).
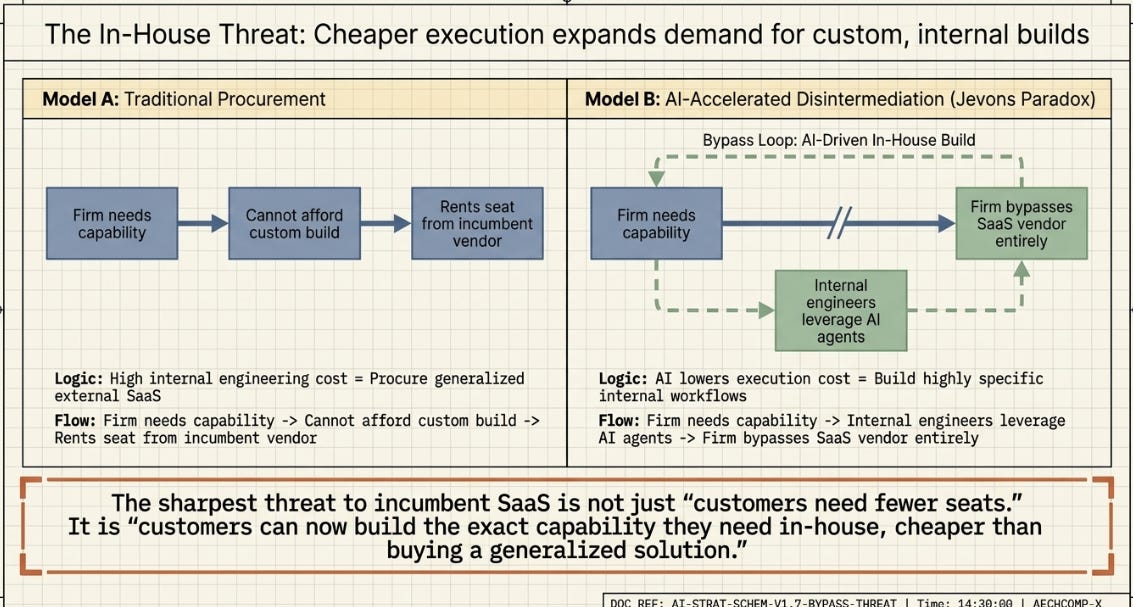
There’s a sharper version of this threat worth naming. Narayanan and Kapoor point out that most software engineers already work in-house, inside non-software companies, not at software vendors — and argue that share may grow as AI makes building software cheaper (their version of Jevons’ paradox: cheaper execution doesn’t shrink total demand for software, it expands it, including demand for software that previously wasn’t worth building at all). If that’s right, the risk to incumbent per-seat SaaS vendors isn’t only “our customers need fewer seats of our product” — it’s “our customers increasingly build the equivalent capability in-house, because their own engineers can now execute on it cheaply too.” That’s a harder problem than a pricing-model change can fix, because it’s not about how the vendor charges for a given capability — it’s about whether the vendor remains the cheapest place to get that capability at all.
5. The adoption gap: why most of this isn’t happening yet
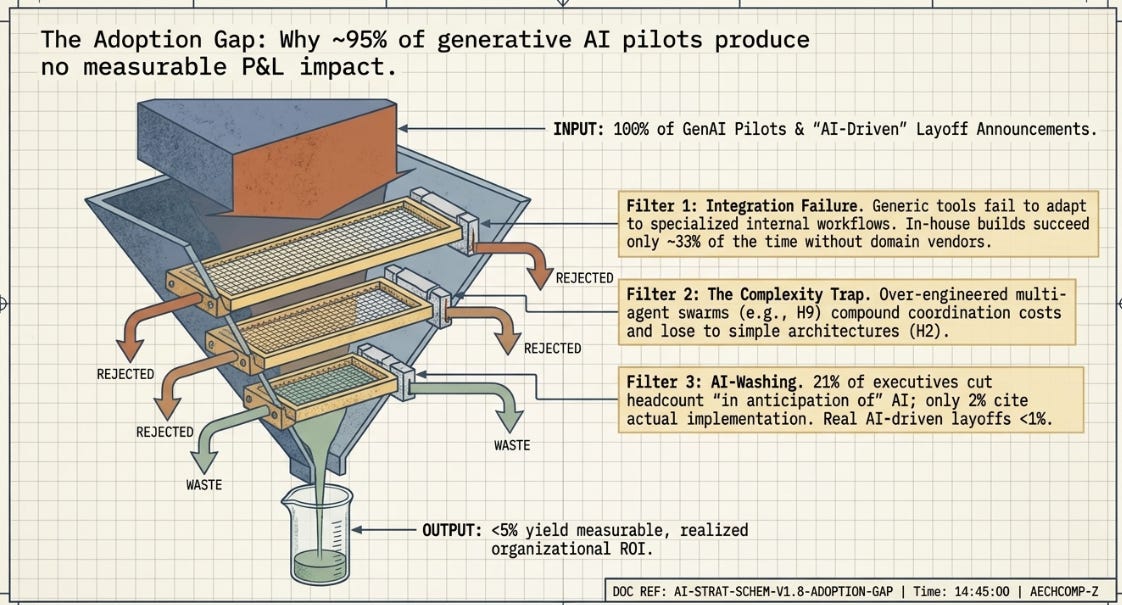
Everything above describes potential — and the gap between potential and realized impact, in 2026, is large. MIT’s NANDA initiative published research in mid-2025 (and follow-on work has largely confirmed the pattern into 2026) finding that roughly 95% of generative AI pilots inside large organizations produce no measurable P&L impact. The headline number gets cited a lot; the more useful detail is why: the research attributes this overwhelmingly to organizational and integration failures rather than model limitations — generic tools that don’t adapt to specific workflows, budgets concentrated in high-visibility sales/marketing pilots rather than the back-office automation where MIT found the actual ROI was concentrated, and a strong success-rate gap between buying from specialized vendors with domain expertise (roughly two-thirds success) versus building in-house (roughly one-third).
A second, more pointed strand of evidence makes a related point even more directly: a lot of what gets reported as “AI replaced these jobs” doesn’t hold up under scrutiny. Narayanan and Kapoor walk through several high-profile 2026 layoff announcements — Block, Snap, Intuit — where executives cited AI capability gains as the rationale, but the underlying drivers (investor pressure, financial strain, organizational restructuring) told a different story; in Intuit’s case, the CEO explicitly pushed back on the AI framing the press had attached to the cuts. They cite a survey finding that a majority of US hiring managers admit to citing AI for layoffs because it plays better with stakeholders than citing financial constraints, and an HBR survey where 21% of executives had already made large headcount cuts “in anticipation of” AI, versus only 2% citing actual AI implementation as the cause — roughly a tenfold gap between anticipated and realized impact. New York’s first full year of WARN Act AI-disclosure data shows a similarly small realized-impact figure: well under 1% of recorded layoffs checked the AI box, though the authors note this could understate the true figure given asymmetric incentives around how companies report.
This doesn’t contradict the MIT NANDA finding — if anything it sharpens it. NANDA measures whether AI pilots produce measurable P&L impact (mostly no); the layoffs evidence suggests that even where job cuts are happening, the causal story attached to AI is often a convenient narrative for decisions that would have happened anyway. Two different ways of arriving at the same conclusion: the realized labor-market impact of agentic AI, as of mid-2026, is consistently smaller than the headlines suggest — across both “did the pilot work” and “did the layoff actually happen because of AI.”
This maps remarkably cleanly onto the Harness Lab findings that underpin the PharmaCo case study. H9 — the five-agent swarm that looked most sophisticated on paper — lost to H2, a simpler structured single agent, specifically because complexity compounded coordination costs faster than it added capability. The MIT findings about internal builds underperforming vendor partnerships are, in effect, the same lesson at the organizational level: more moving parts, more integration surfaces, more places for a “looks sophisticated” approach to lose to a “fits the actual task” approach. Gartner’s own projection that over 40% of agentic AI projects will be cancelled by 2027 — despite (or because of) rapid adoption — reads as the market-wide version of H4: enthusiasm for “more agents, more coverage” outrunning the harder discipline of matching architecture to task.
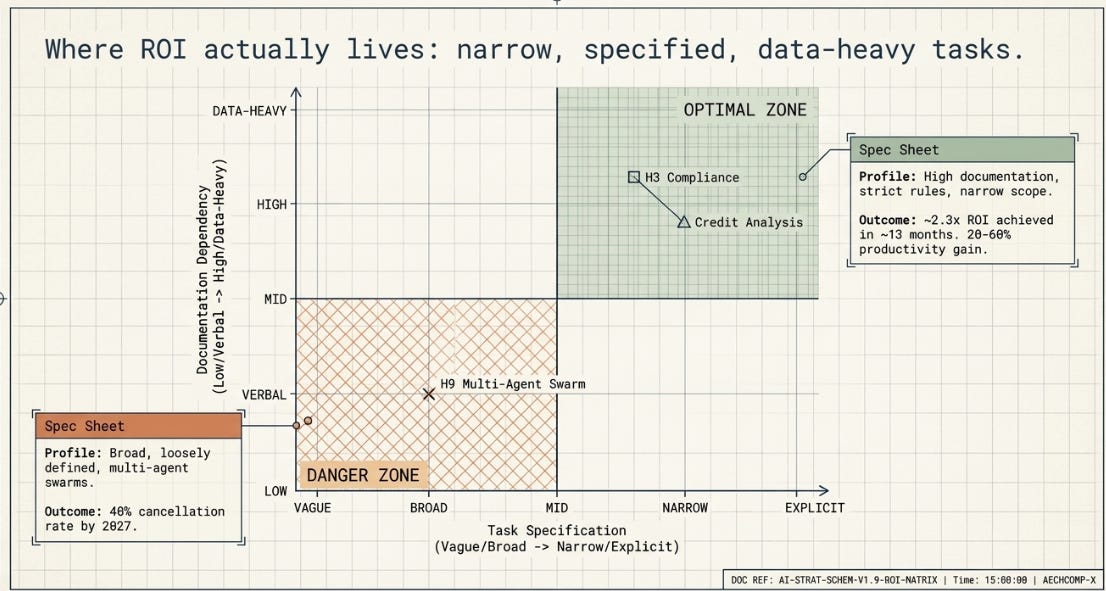
The financial services data offers a useful counter-data-point on what does work: KPMG and IDC both report roughly 2.3x average ROI on agentic AI investments within about 13 months for institutions with strong governance, and McKinsey found 20–60% productivity improvements in credit analysis specifically — a narrow, well-specified, document-heavy task with clear success criteria, which is exactly the profile that the H3 compliance-monitoring scenario in the PharmaCo case (and the “Harness Lab, Automated” follow-up benchmark) suggests should favor simpler, tool-augmented architectures over elaborate ones. The pattern across all of this research, for what it’s worth, seems to be: narrow, well-specified, document/data-heavy tasks with measurable success criteria are where agentic AI reliably delivers ROI today, regardless of industry — and the industries that will see the fastest realized impact are the ones with the most tasks fitting that profile, not the ones with the most dramatic AI narratives.
6. A birds-eye framework
Putting the above together, here’s the 2×2 I’d use to think about where agentic AI’s impact lands, and roughly how fast:
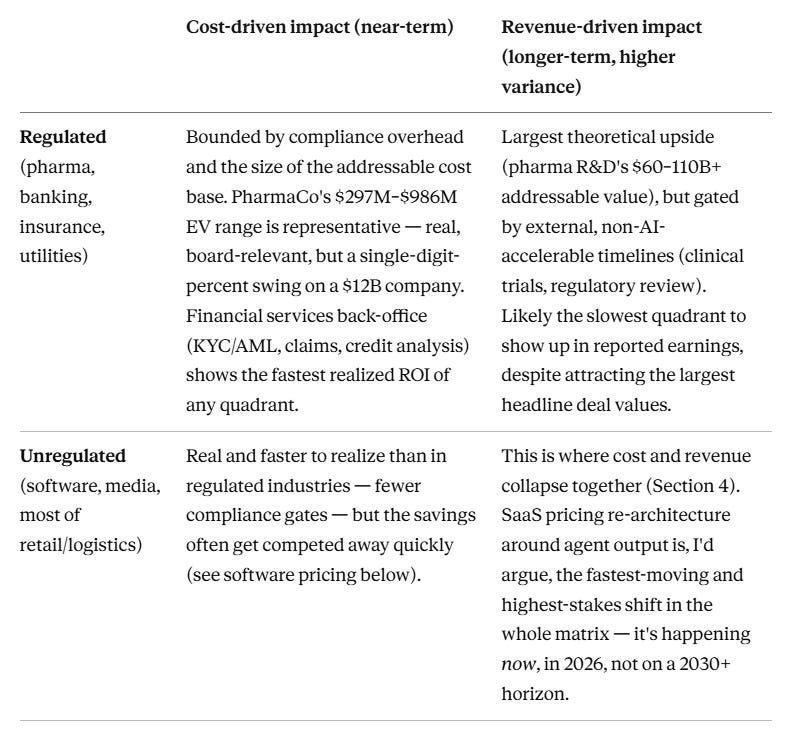
The PharmaCo case study sits squarely in the top-left cell — which is precisely why, on its own, it “doesn’t seem as impactful as markets make out”: markets, when they talk about AI broadly, are mostly pricing in the bottom-right and top-right cells, which this case study was never designed to address. Two things sit outside this 2×2 entirely rather than inside any single cell: Section 2.1’s capability-expansion axis, which describes a tail extreme enough that “revenue” isn’t quite the right word for it either, and Section 7’s composition shift in who does the execute-layer work, with consequences that arrive years after the cost/revenue effects above.

7. The junior pipeline problem
One thread the framework above doesn’t address: even if aggregate demand for a given role holds steady — which Narayanan and Kapoor argue is the likely outcome for software engineering specifically, given how price-elastic demand for software has historically been — the composition of that demand can still shift in ways that matter a lot for individuals, and for organizations five-plus years out. A reader comment on their piece (from Vitaly Osipov) makes a sharp point: execution-layer work is precisely where junior people have historically built the judgment they’ll need to become senior decide/deliver people later. If AI absorbs most execution-layer work, junior hiring could fall even while senior demand stays robust — creating a pipeline problem that’s invisible today and only becomes visible years later, when there aren’t enough experienced people left to do the deciding and delivering that AI still can’t do.
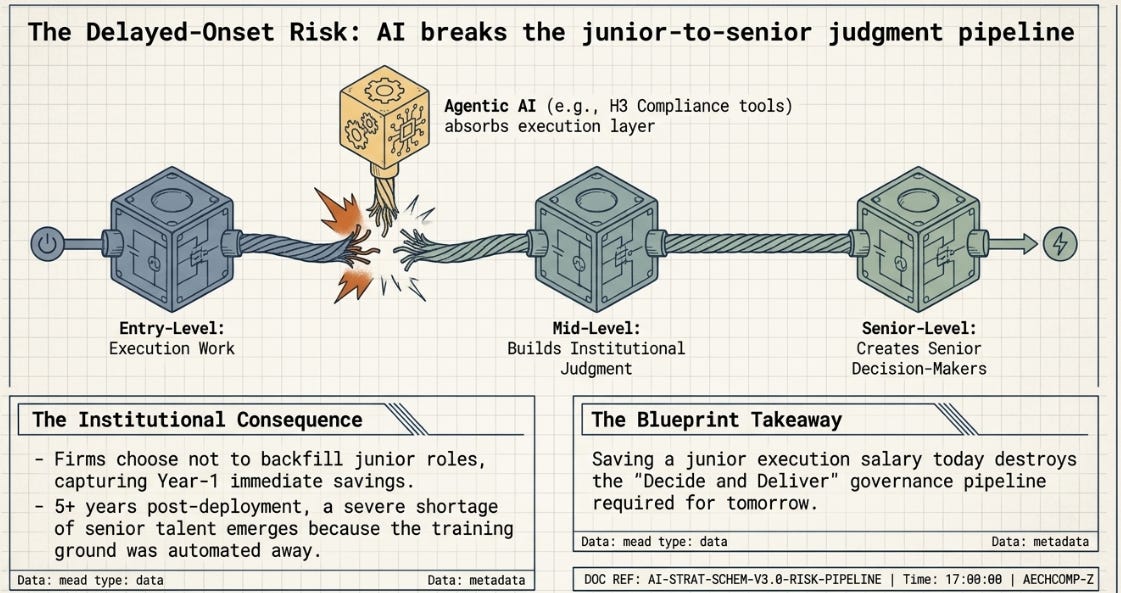
This connects directly to Section 11.3 of the PharmaCo case, which discussed redirecting compliance-analyst capacity toward higher-value work following H3’s adoption. The framing there was optimistic — three analysts’ time freed up for more strategic work. But if that pattern repeats at the entry-level hiring decision — don’t backfill the junior compliance-monitoring role at all, since H3 now does that work — the org saves the junior salary today and loses a training pipeline for tomorrow’s senior compliance hires. Neither this essay nor the PharmaCo case modeled that cost, because it doesn’t show up on any single year’s income statement. It shows up later, as a senior-talent shortage that’s slow and expensive to fix once visible.
This is arguably the most under-priced risk in the entire framework above: it’s invisible in every quadrant of Section 6’s matrix at the time horizon a board typically acts on, and yet it’s exactly the kind of structural shift that compounds the way the revenue-side stories in Sections 2 and 4 do — just in the wrong direction.

8. What would change this view
A few things that would update me away from the framing above, in either direction:
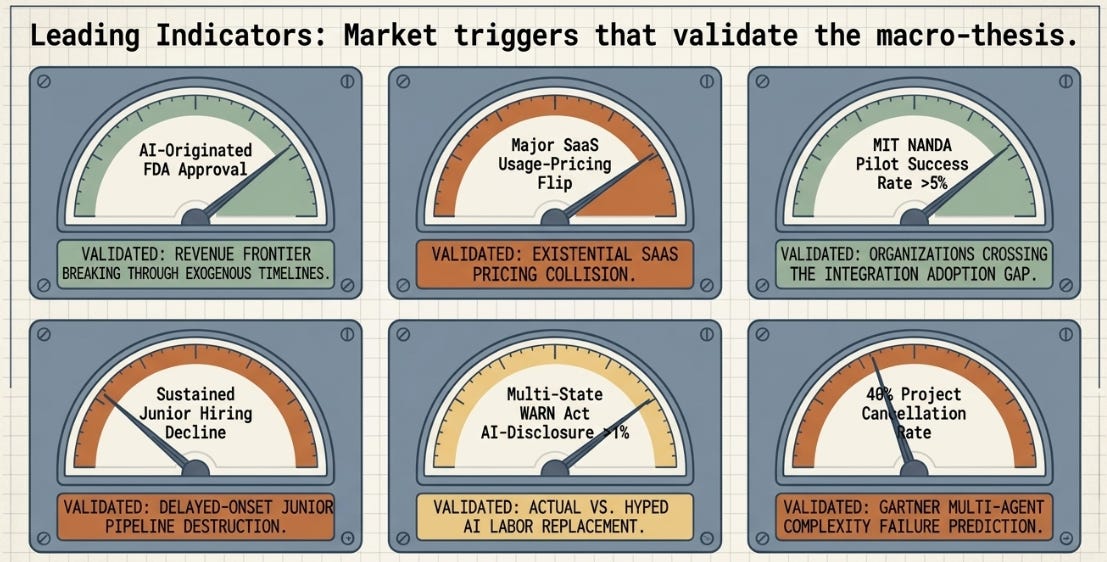
An AI-originated drug receiving full FDA approval (projected by various analysts at roughly 60% probability for 2026–2028) would be the first hard evidence that the revenue-side pharma story is converting from pipeline activity into realized value — and would likely accelerate the deal-making already underway. As mentioned earlier, I note this recent development and will watch the space: Takeda’s zasocitinib (covered in my separate Funnel/Floor/Structure piece) has since cleared Phase III and is pending an FDA filing within fiscal 2026.
A SaaS company reporting a quarter where usage/outcome-based AI revenue materially offset a decline in per-seat revenue would confirm the Section 4 thesis is playing out on the timeline I’d guess, rather than the slower 2030+ timeline some forecasts imply.
A second or third independent study replicating MIT NANDA’s ~95% pilot-failure finding with a meaningfully lower number would suggest the “learning gap” is closing faster than the 2025–26 data suggests — which would matter enormously for how quickly any of the cells in Section 6 move from potential to realized.
Conversely, if Gartner’s 40%+ project-cancellation prediction for 2027 lands roughly on target, it would suggest the gap between agentic AI’s demonstrated architecture-level potential (the H1–H10 results) and most organizations’ ability to actually capture it remains the dominant constraint — in which case the PharmaCo case study’s core message (architecture-and-task-fit matters more than raw capability) becomes, if anything, more relevant, not less, as the bottleneck shifts from “can the model do this” to “did the organization build the right harness around it.”
Entry-level hiring data specifically (not just aggregate headcount) showing a sustained decline in junior roles across software, compliance, and similar execution-heavy entry points would be the earliest leading indicator for Section 7’s pipeline concern — well before any senior-talent shortage became visible in P&L terms.
A second capability-expansion case outside pharma converting from research activity into a deployed, valuable result (Section 2.1) — for instance, an AI-discovered semiconductor interconnect or packaging technique reaching production — would be the clearest sign the third axis generalises beyond drug discovery rather than being a pharma-specific artifact of how option-like that industry’s economics already were.
A second state adopting New York’s WARN Act AI-disclosure checkbox, showing a similarly low realized-AI-layoff percentage, would reinforce the AI-washing finding in Section 5 as a general pattern rather than a New York-specific artifact (or a reporting quirk of that particular dataset).
Sources and further reading
Anthropic, Economic Index — series of reports tracking real-world Claude usage, Jan/Mar 2026 editions cited in Section 5 and Section 7’s WARN Act discussion context: anthropic.com/economic-index · Jan 2026 report · Mar 2026 report
Massenkoff, M. & McCrory, P., “Labor market impacts of AI: A new measure and early evidence” (Anthropic, March 5, 2026) — source for the “slower hiring rather than increased separations” finding referenced in Section 5: anthropic.com/research/labor-market-impacts
McKinsey Global Institute, “Generative AI in the pharmaceutical industry: Moving from hype to reality” — original source of the $60–110B annual addressable-value estimate for pharma cited in Section 2: mckinsey.com
AllAboutAI, “AI in Drug Development Statistics 2026” — source for AI-discovered-drug Phase I success-rate figures (80–90% vs. a lower traditional baseline) referenced in Section 2: allaboutai.com/resources/ai-statistics/drug-development
IntuitionLabs, “Accelerating Drug Development with AI in the U.S. Pharmaceutical Industry” — source for the Exscientia/DSP-1181 12-month-to-clinic example referenced in Section 2: intuitionlabs.ai/articles/accelerating-drug-development-ai-pharma
IntuitionLabs, “Measuring AI ROI in Drug Discovery: Key Metrics & Outcomes” (Apr 2026) — source for Eli Lilly’s $2.75B Insilico partnership figure referenced in Section 2: intuitionlabs.ai/articles/measuring-ai-roi-drug-discovery
DrugPatentWatch, “AI in Drug Discovery 2026: What Actually Works, What Remains Hype, and Where the IP Value Sits” — corroborates the Phase I success-rate figures and notes Phase II/III as the still-pending validation event for AI-discovered candidates, referenced in Section 2: drugpatentwatch.com
BioSpace, “AI Is Changing Pharma’s Bottom Line Now—But Not Through Splashy Drug Discovery” (Feb 2026) — source for the framing that AI’s clearest near-term pharma impact runs through development speed rather than discovery itself, referenced in Section 2: biospace.com
FierceBiotech, “From R&D to M&A: Big Pharmas showcase ‘measurable impact’ of AI” (May 2026) — source for AstraZeneca’s and GSK’s earnings-call AI commentary referenced in Section 3: fiercebiotech.com
Gartner, “Gartner Predicts 40% of Enterprise Apps Will Feature Task-Specific AI Agents by 2026, Up from Less Than 5% in 2025” (Aug 2025) — source for the 40%-by-2026 and $450B-by-2035 figures cited in Section 4, and the 40%+ agentic-project-cancellation-by-2027 prediction cited in Section 8: gartner.com
RSM US, “SaaS vendors must adjust pricing models as agentic AI transforms the industry” (Mar 2026) — source for the “engineering its own revenue decline” framing cited in Section 4: rsmus.com
Omdia, “New Omdia Analysis Shows Agentic AI Outpacing Growth Rates of Traditional Generative AI” (Sep 2025) — source for the $1.5B (2025) to $41.8B (2030) enterprise agentic AI software market forecast and 175% five-year CAGR cited in Section 4: businesswire.com
MIT NANDA / Project NANDA, The GenAI Divide: State of AI in Business 2025 (Aug 2025) — source of the ~95% pilot-failure finding and the “learning gap” diagnosis cited in Section 5: full report PDF · widely covered, incl. Fortune
Ellvero Insights, “AI ROI in 2026: Why 95% of Pilots Fail to Deliver and How to Measure What Actually Matters” (citing Boston Consulting Group’s 2026 AI at Scale survey) — corroborating 2026 follow-up data cited in Section 5: ellvero.com
Narayanan, A. & Kapoor, S., “Why AI hasn’t replaced software engineers, and won’t: Coding agents as normal technology” (AI as Normal Technology, June 11, 2026) — source for the “decide-execute-deliver sandwich” framework, the Block/Snap/Intuit “AI washing” cases, the WARN Act and HBR anticipated-vs-realised figures cited in Sections 1 and 5, and the junior-pipeline discussion in Section 7: normaltech.ai/p/why-ai-hasnt-replaced-software-engineers
Azilen Technologies, “Agentic AI in Financial Services [2026 Definitive Guide]” (citing KPMG and McKinsey) — source for the 2.3x ROI within 13 months and 20–60% credit-analysis productivity figures cited in Section 5: azilen.com/blog/agentic-ai-in-financial-services
Neurons Lab, “Agentic AI in Financial Services: A Research Roundup for 2026” (citing IDC, McKinsey, PwC, Deloitte) — corroborating source for the same 2.3x ROI figure cited in Section 5: neurons-lab.com/articles/agentic-ai-in-financial-services-2026
What Is Any Agentic Structure Actually Worth? InterestingEngineering++
Perhaps AI can make a dent in the US military budget. Every engineer that has worked on military programs has scratched their heads about MIL specs. AI could be used to review all these specifications and revise or eliminate those that technology has by-passed. AI could also be used to improve testing standards for specifications that remain. These things may significantly lower development cost and/or speed up projects. The purpose for these specs has always been to improve and extend useful life of materials in severe environments.
Yes Meridith. You know.. At the end of the day, objectives, still very much human. I hope we have the gentle beings in our midst - who consider the country sequences of actions taken today and what they mean for future generations. And then, there is Silicon Valley