
The Harness Lab, Automated
Using Loops (Dynamic Workflows, Ultracode) to Generate, Test, and Tournament Harness Architectures — All Six Dynamic Workflow Patterns, One Run including LFD

Five Strategic Insights From Workflow Automation - The Harness Lab, Automated

Section 2.5 includes 3 versions of strategies that can be taken with /goal and loop - for observability, follow the experiment way first. I have also included 2 other versions in the section - “ala Boris Cherny” and Loss Function Definition (LFD).

0.1 The H1–H10 Architectures: What Each One Was
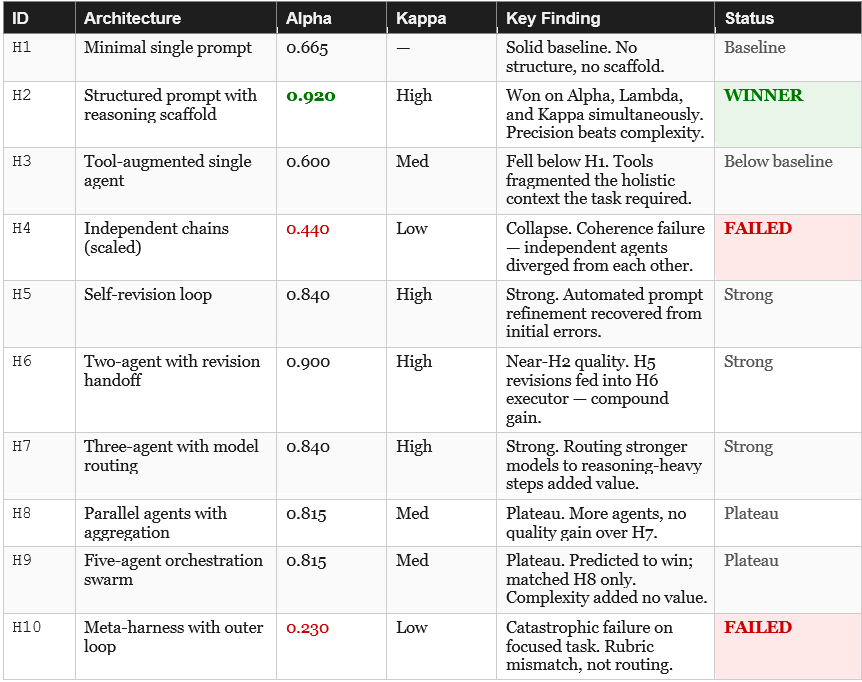
The Harness Lab experiments tested ten progressively complex harness architectures against a common benchmark task. Each harness was a different structural approach to the same problem. The table below summarises all ten, their alpha scores from the vendor evaluation domain, and the key findings for each:

0.2 The ASCRS Finding
The ASCRS experiment applied the H1–H10 taxonomy to a more complex benchmark: a pharmaceutical supply chain disruption in the Strait of Hormuz requiring a 72-hour response plan. H9 was predicted to win — the task was complex enough to justify a five-agent swarm. It did not. H2 and H7 produced the best results. The finding generalised: for well-specified, bounded tasks, precision and appropriate model routing outperform raw agent count.

Key insight: Harness complexity only adds value when the task genuinely requires coordination across separate reasoning streams. A well-specified single-agent prompt is harder to beat than it looks.
0.3 Why I Am Automating This
The H1–H10 evaluation took weeks of coordinated effort between departmental approvals (parallel runs were incorporated for safe measure/risk mitigation): designing each harness, running it, reviewing outputs across separate sessions, comparing results, and deciding what to run next. Every step between stages was manual. The developer — me/claude — played the orchestrator role.
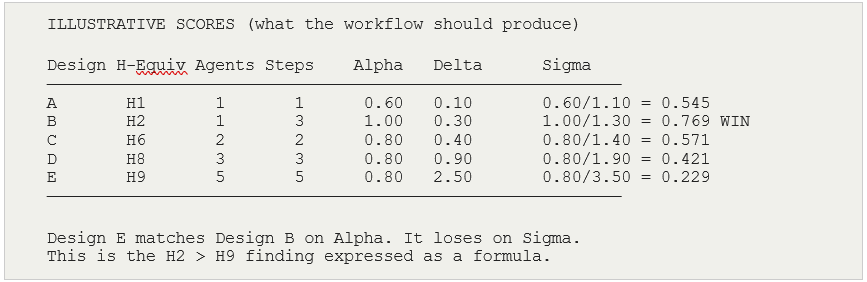
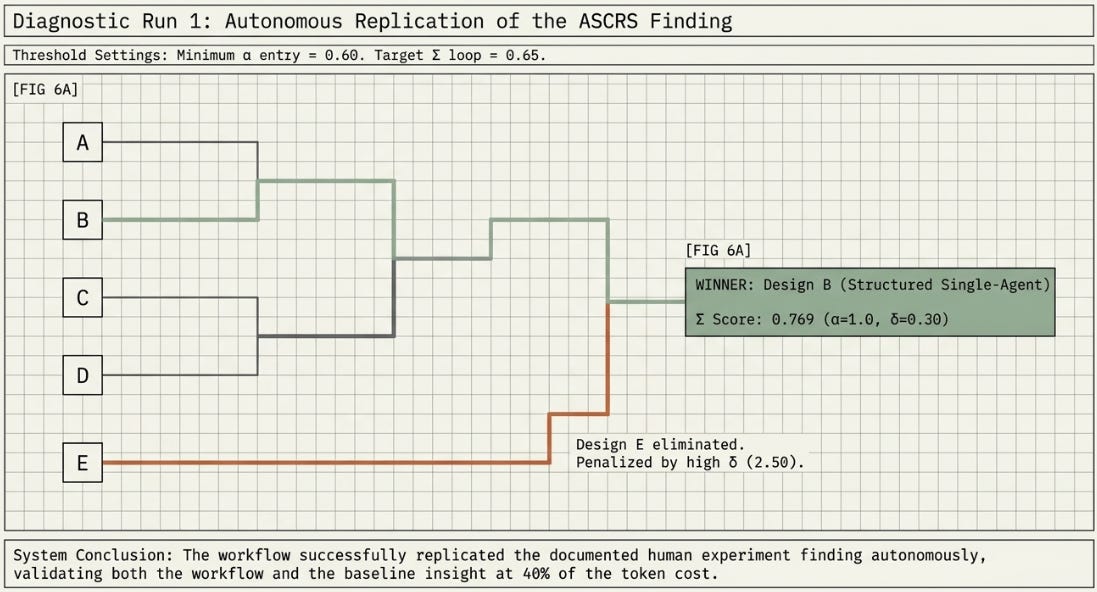
Dynamic workflows, change the cost structure of that process. A workflow can generate harness designs, test them, adversarially probe for failure modes, run a pairwise tournament, and loop until a quality threshold is met — autonomously, in one run - is worth looking into and applying. The Key question this experiment asks is whether the workflow rediscovers the ASCRS finding: does Design B (the H2 equivalent) beat Design E (the H9 equivalent) without human coordination of the comparison?

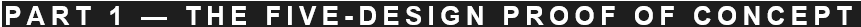
1.1 Why Five Designs First
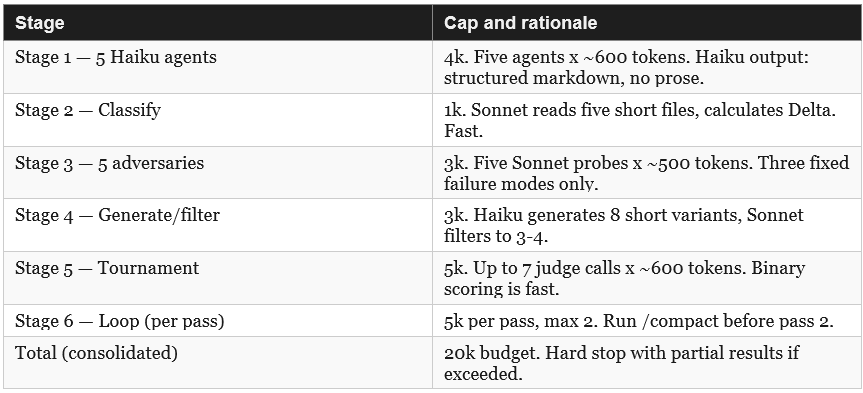
Ten designs through six automated stages — generate, classify, adversarially probe, filter test scenarios, tournament, loop — is expected to run to approximately 30,000 tokens. Five designs sits at approximately 20,000. These are estimates and “control gears” i incorporate within the experiment mechanisms. For a first run, the proof-of-concept (POC) value is in confirming the workflow functions correctly, not in maximising the design range. Five designs cover the structural extremes that matter: minimal single-agent, structured single-agent, two-agent chain, parallel multi-agent, and full swarm.
The five designs (A through E) map directly to the H1–H10 architectures that bracket the original result. If Design B beats Design E in the automated tournament, the workflow has reproduced the core ASCRS finding with 40% of the token cost of the ten-design run.
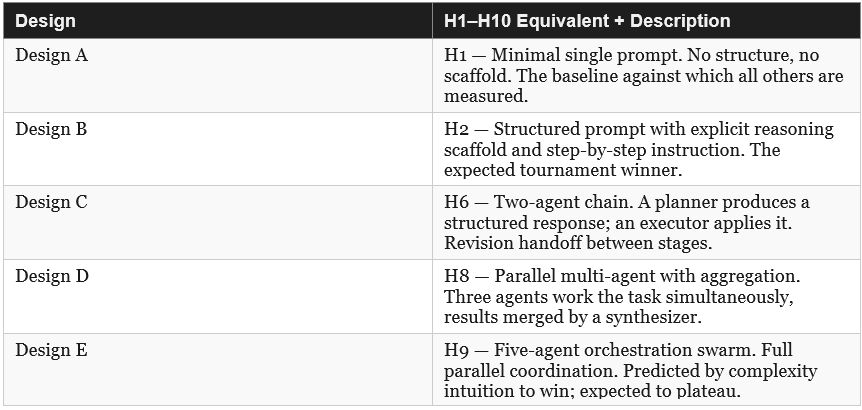

1.2 The Experiment at a Glance

1.3 Six Patterns in Their Natural Roles
The Six Patterns were detailed in the recent: The Prompt Is Still The Work - Dynamic Workflows in Claude Code. Each pattern maps directly and naturally to a stage. These are not forced assignments — the experiment was designed around these patterns, not the other way around.

1.4 The Benchmark
1.4.1 Why the Benchmark Matters More Than the Workflow
The workflow generates designs, tests them, and picks a winner. But winning means whatever the benchmark says it means. A vague gold_answer produces inconsistent scoring. An easy benchmark task makes all designs look identical and the tournament picks noise. The benchmark is the specification — and specification remains the skilled work.
1.4.2 benchmark/task.md

1.4.3 benchmark/gold_answer.md — Five Binary Criteria


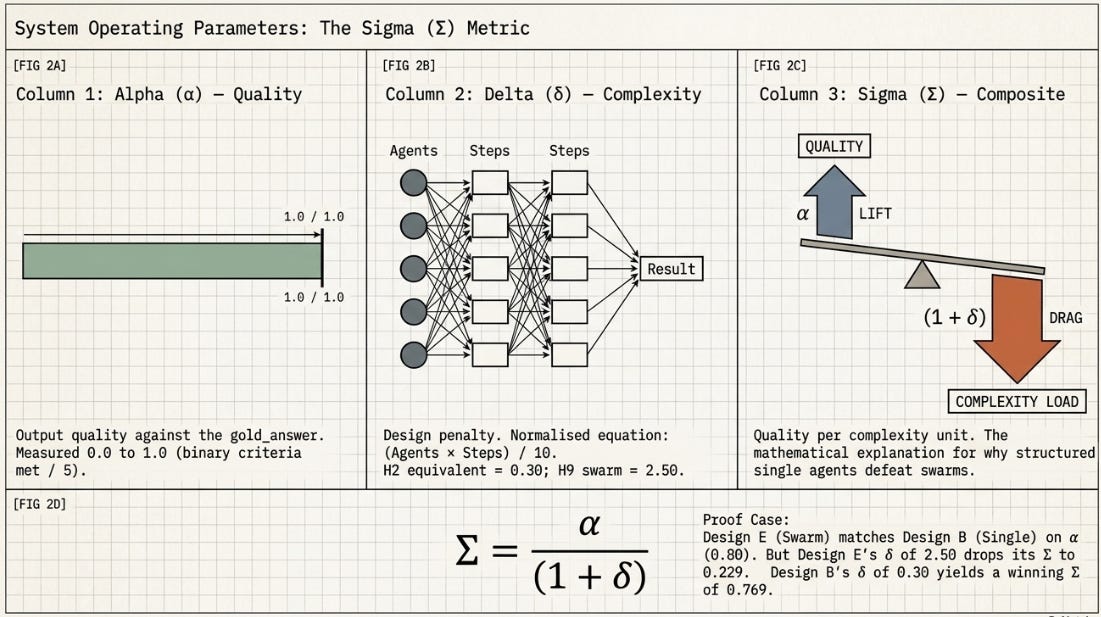
1.5 Three Metrics
I have revised the metrics to add reasonable consideration and build up from the original experiment - it evaluates not only the quality of output but measures it against design complexity:

1.5.1 Why/How Sigma Explains the ASCRS Result
1.6 Folder Structure

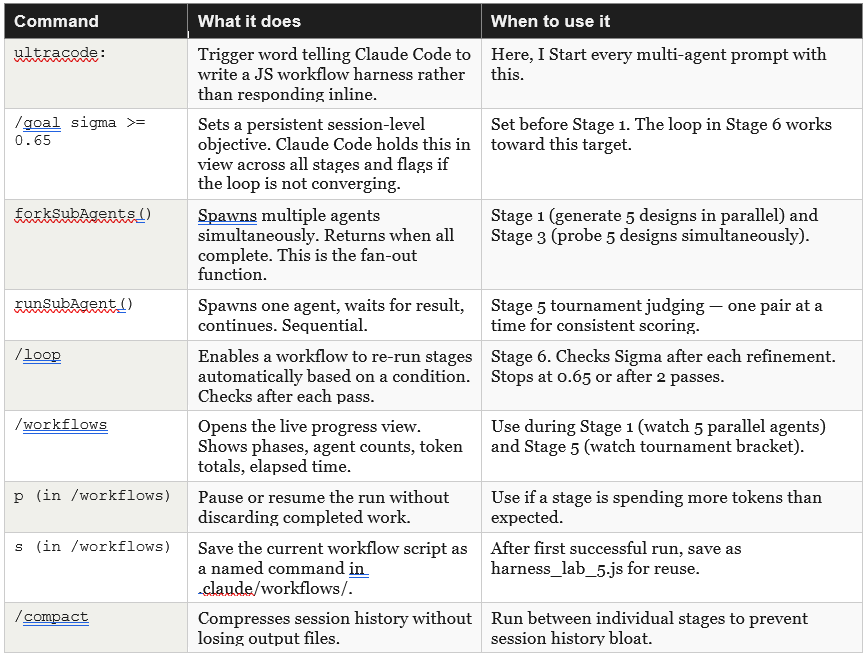
1.7 Claude Code Functions: What They Do
Quick reminder. You do not write the JavaScript. The workflow generates it. But knowing what these functions do helps you write better prompts and interpret the raw script before you approve the run.
1.8 CLAUDE.md — Project Instructions

1.9 Prompts — Step by Step
Step 0: Create the Entire Project Environment

Stage 1: Fan-out Design Generation

Stage 1a: Design Verification (Gate Before Stage 2)
Run this immediately after Stage 1 completes, before Stage 2 begins. It checks whether each generated design actually matches its specified H-equivalent structure. If any design is flagged, fix it before proceeding — a mismatched design wastes all downstream token spend.

Stage 2: Classify-and-Act

Stage 3: Adversarial Verification

Stage 4: Generate-and-Filter Test Scenarios

Stage 5: Tournament

Stage 6: Loop Until Done

1.9.7 Consolidated Prompt — Five Designs

1.10 Token Budget — Five Designs
1.11 What to Expect
I have been surprised by the results of many of the experiments I have run. But when run, and analyzed - they were really logical. The hypothesis, that a good eval system should be able to prove or disprove either way. So this is mine, here. I have made it basic by going back to priors (the evals being key): A successful run produces reports/recommendation.md showing Design B as the winner with Sigma around 0.769, and Design E near the bottom with Sigma around 0.229 despite a similar Alpha score. The adversarial stage flags Design E for at least one failure mode (most likely self-preferential bias — the swarm orchestrator typically reviews sub-agent outputs without an independent checker). The loop refines Design B by adding an explicit completion condition if the adversary flagged it, pushing Sigma above 0.65.


2.1 Conditions for Proceeding
Do not run the ten-design experiment until the five-design run has produced a clean result. Specifically: Design B won or placed in the top two, Design E placed in the bottom two, and the reports/recommendation.md was written correctly. If those conditions are not met, the benchmark or scoring rules need adjustment before scaling up.

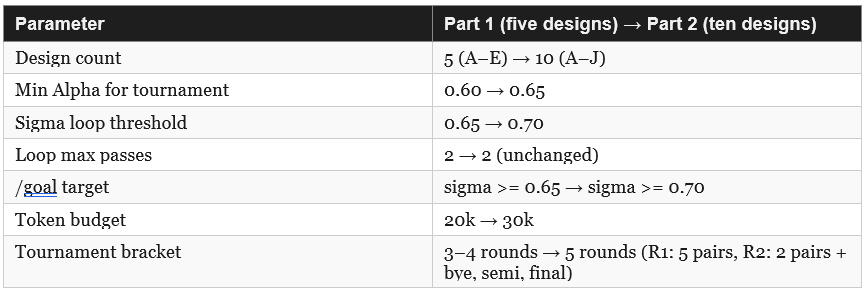
2.2 What the Ten-Design Run Adds
The five designs covered the structural extremes of the H1–H10 taxonomy. The ten designs add the intermediate architectures — the ones that produced the most surprising results in the original series: H3 (fell below H1), H4 (collapsed), H5 (strong self-revision), and H10 (catastrophic failure). These are the most interesting designs to test in an automated evaluation because their outcomes were counterintuitive.

2.3 Updated Folder Structure

2.4 Updated Eval Thresholds
The ten-design run uses higher quality thresholds than the five-design run. The larger design space should produce a better winner — the minimum Alpha to enter the tournament rises from 0.60 to 0.65, and the Sigma target rises from 0.65 to 0.70. This also means Design G (H4 equivalent) and Design J (H10 equivalent) are likely to be eliminated before the tournament bracket if their Alpha falls below 0.65, which matches the original series finding.

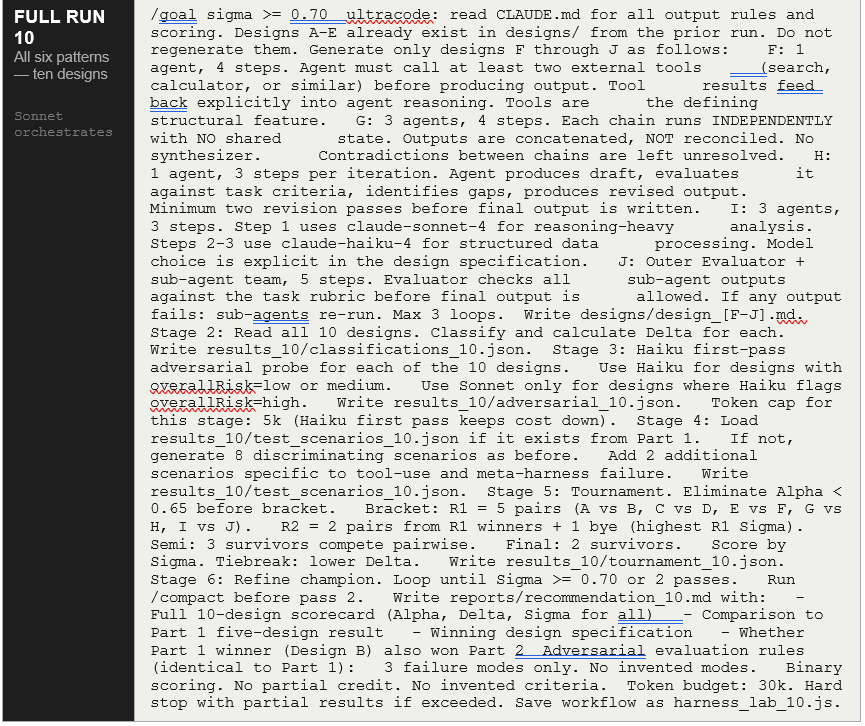
2.5 Consolidated Prompt — Ten Designs
This is the only prompt for Part 2. It assumes the benchmark files exist from Part 1, the Part 1 workflow ran successfully, and you have confirmed Design B won. Run Step 0 only to update CLAUDE.md with the new thresholds — do not recreate benchmark/ files.
FULL RUN 10
→What Difference would there be if we work on Loops ala “Boris Cherny”
Well, everything that was in my 40-line prompt moves into CLAUDE.md. The prompt becomes the goal and the orientation only.
/goal sigma >= 0.70
ultracode: read CLAUDE.md for all rules, scoring,
and constraints. Designs A-E exist in designs/.
Benchmark files exist in benchmark/. Extend to
10 designs and find the best. Save as
harness_lab_10.js.
Thats it! That is the entire prompt.
What makes this work is what is in CLAUDE.md
CLAUDE.md now carries everything my 40-line prompt previously specified:
# CLAUDE.md — Harness Lab Auto
## Goal
Find the harness design with Sigma >= 0.70.
Sigma = Alpha / (1 + Delta).
Alpha = criteria_met / 5.
Delta = (agents x steps) / 10.
## What exists
designs/ contains A-E from prior run.
benchmark/ contains task.md, gold_answer.md,
rubric.md.
## What to produce
10 designs total (add F-J to existing A-E).
Full evaluation of all 10.
Winning design with scorecard.
Write all outputs to results_10/ and reports/.
## Design range for F-J
F: tool-augmented (2+ external tool calls,
tools feed back into reasoning)
G: independent chains, no reconciliation,
contradictions unresolved
H: self-revision loop, minimum 2 passes
I: explicit model routing (Sonnet for reasoning,
Haiku for processing)
J: meta-harness with outer evaluator loop,
max 3 re-runs
## Evaluation rules
Score only against gold_answer.md criteria.
Binary: 0 or 1 per criterion. No partial credit.
Adversarial probe: 3 failure modes only.
Minimum Alpha 0.65 to enter tournament.
Always include Alpha, Delta, and Sigma in output.
## Constraints
Never modify benchmark/ files.
Never recommend suspending a medication.
Token budget: 30k. Stop cleanly if exceeded.
What the agent then does on its own
CHERNY PROMPT AGENT DECIDES
─────────────────────────────────────────────────────────────
/goal sigma >= 0.70 -> I need to generate F-J
I need to classify all 10
I need to probe for failures
I need discriminating scenarios
I need a tournament
I need to refine the winner
I need to loop until done
CLAUDE.md defines -> I know what sigma means
what winning means I know the scoring rules
I know what designs to build
I know what constraints apply
The agent plans its own stages. If it decides to run classification before generation, or combine adversarial probing with scenario generation, it can. You do not care how it gets there — only that the result meets the goal.
The practical difference
My detailed prompt would always produce the same six stages in the same order. If stage 3 turned out to be unnecessary for a particular run, it would run anyway.
The Cherny prompt lets the agent skip stages that are not needed, combine stages that are related, or add a stage you had not thought of. The constraint is the evaluation function, not the method.
The risk is that if CLAUDE.md is underspecified, the agent will make choices I did not intend and the result will be wrong in ways that are hard to trace. Not impossible. Logs help. That is why Cherny’s approach requires a very well-designed evaluation function. The intelligence moves from the prompt into CLAUDE.md — it does not disappear.
→ Applying the LFD Concept


In LFD, all intelligence is concentrated in the loss function definition (LFD).
Applying LFD principles to the Harness Lab automation for better results with less manual prompt engineering would be moving further up from rigid, stage-by-stage prompting (which forces the agent into a fixed path) to defining what winning looks like and letting the agent figure out the how. That’s the core of Elvis’s “Loss Function Development” (LFD). It’s an ML term: instead of telling a model what to do step by step, I define what good looks like and let it find the path. Applied to Agentic Systems: instead of writing “first do X, then do Y, then do Z”, I would write “the goal is Sigma >= 0.75 - here are the constraints, here is the scoring function, here is what disqualifies a solution.”. So I would:
1. Strengthen the Loss Function (The Target + Eval) - My current setup uses Sigma (Alpha / (1 + Delta)) as a composite metric, with binary criteria against gold_answer.md, adversarial probing, and thresholds. Improvements/Tweaks aligned with LFD:
Make the eval large and blind: The benchmark is strong but risks being too small/finite (like Elvis’s early 28–200 item failures). Expand gold_answer.md or test scenarios to hundreds of varied cases (including traps from the original ASCRS series: cold chain, air freight overrides, etc.). Keep the full eval hidden during runs—only reveal misses or aggregate scores post-scoring. This prevents memorization/cheating.
Blind + forced generality: Add instructions in CLAUDE.md like: “You cannot see or enumerate the full eval set. Any solution that appears to target specific known cases (e.g., via keyword lists or exact matches) must be rejected. Prioritize generality.”
Target a direction, not just a threshold: Instead of just “Sigma >= 0.75”, frame it as optimizing Sigma while minimizing vulnerabilities flagged in adversarial stages. This encourages ongoing improvement even after hitting the bar.
This article already notes the benchmark is more important than the workflow—this is exactly right. I could beef up Constraints & Instruments (The Harness). Elvis stresses that constraints without measurement tools are just vibes—the agent will ignore or creatively violate them. Thoughts on what to add/enhance in CLAUDE.md:
Hard time & spend caps: Explicit wall-clock (e.g., “Stop after X hours”), token budget, and API spend limits. Include CLI/tools so the agent can query: “Current spend? Time elapsed? Projected burn?”
Methodology & surface constraints: Spell out allowed models, tools, no modifying benchmark files, domain rules (e.g., “Never recommend suspending medication”).
Instruments: Ensure the agent has easy ways to measure everything (pixel diffs if relevant, timing per step, complexity/Delta calculation, adversarial failure modes). Add self-reflection commands like “Log hypothesis, expected failure, diagnostic.”
Token budget realism: My 20k–30k estimates are already good control gears— which can be tied directly to the goal.
This turns the folder structure + functions into a proper harness the agent can inspect and respect. Add Forced Entropy (Avoid Local Maxima/Stuck Loops). This is a key gap in many detailed workflows (including early versions of my own experiments).In CLAUDE.md or the /goal prompt:
On stall (no metric improvement): “Do not repeat the same idea harder. Make a non-obvious structural jump or explore a new design axis.”
Overfit check every cycle: “Reflect: Are we generalizing or memorizing artifacts? If the latter, remove one eval-shaped element (cap lists, widen scenarios, add noise).”
Iteration log: Force logging of hypotheses and decisions for cross-cycle reflection.
Diversity mandate: When generating new designs (F–J), require meaningful deviation from priors, not incremental tweaks.
I believe the loop-until-done already helps, but entropy prevents the agent from just polishing one knob (e.g., endlessly tweaking a swarm without addressing coordination failures). Practical Prompting Upgrades for future projects:
Lean harder into /goal + context file: The consolidated 10-design prompt is alaready a great step in this direction. I could make the top-level prompt even shorter/minimal: just the goal, reference to CLAUDE.md, existing assets, and output requirements. Move all intelligence (rules, scoring, design specs, constraints) into CLAUDE.md or equivalent. The agent then owns stage planning, skipping, or combining (as in the Cherny example above).
Start with a “meta-goal generator”: Use Elvis’s open-sourced tool or prompt an agent once to refine your loss function for new experiments. Agents are good at writing good loss functions. See:
 Elvis@elvissunhttps://t.co/DotZ3V6XhJ1:07 PM · Feb 23, 2026 · 5.41M Views399 Replies · 1.62K Reposts · 12.6K Likes
Elvis@elvissunhttps://t.co/DotZ3V6XhJ1:07 PM · Feb 23, 2026 · 5.41M Views399 Replies · 1.62K Reposts · 12.6K LikesIterate on the loss function itself: Run short “probe” loops on your eval/benchmark first. If the agent cheats or finds shortcuts, tighten it before full runs (exactly as Elvis did across his 4 loops).
For harness discovery: Since my goal is rediscovering ASCRS findings (precision beats raw complexity on bounded tasks), make the task profile variables (ambiguity, domain depth, stakes, documentation quality) explicit in the loss function. Score designs against multiple task variants.
Expected Benefits for The Harness Lab. So this is really incorporating fine tuning (once you’re comfortable and understand what is going on under the hood)
Less manual work: Fewer fixed stages; agent adapts dynamically.
Better winners: Reduced risk of overfitting to the original H1–H10 insights. Stronger generalization (e.g., Design F/tool-augmented winning on easy benchmarks but getting probed on hard ones).
Scalability: Run bigger design spaces or harder benchmarks with confidence. The outer loop (optimization toward Sigma + generality) compresses what used to take weeks.
Risks to watch (and this is the biggest!): Underspecified CLAUDE.md leads to untraceable choices—keep logs detailed. Always validate the winner manually on fresh traps.
To be fair, the work is already sophisticated courtesy of Claude functionalities (dynamic workflows, Sigma metric, tournament + adversarial). Treating the entire run as LFD—optimizing a well-instrumented, blind, constrained target with entropy—should make results more robust and surprising in good ways. It shifts effort from crafting perfect stage prompts to crafting the right objective function.
LFD Applied:
Here is the complete, ready-to-use LFD (Cherny-style) setup for the Harness Lab (so I have 3 versions - the observable experiment one, “ala Boris cherny”, and LFD all found in this section here).
Folder Structure
harness-lab/
├── CLAUDE.md # The full loss function + harness (ALL intelligence)
├── goal.md # Short top-level prompt (or paste directly)
├── benchmark/ # Sacred - protected
│ ├── task.md
│ ├── gold_answer.md # 5+ binary criteria (expand for blindness)
│ └── rubric.md # Scoring instructions
├── designs/ # Seed + generated designs
│ ├── A.md # Minimal single-agent (H1)
│ ├── B.md # Structured single-agent (H2 - expected winner)
│ ├── C.md
│ ├── D.md
│ ├── E.md # Full swarm (H9)
│ └── F.md ... J.md # Generated in run
├── results/ # Per-design outputs + scorecards
│ ├── A/
│ ├── B/
│ └── ...
├── reports/ # Aggregates
│ ├── scorecards.md
│ ├── tournament.md
│ ├── adversarial_findings.md
│ └── recommendation.md # Final winner + rationale
├── logs/ # Traceability (critical for LFD)
│ ├── run_log.md # Decisions, spend, time
│ └── hypotheses.md # Reflections, overfitting checks
├── tools/ # Any custom functions/helpers
└── harness_lab.js # Generated workflow (latest)Key rules for this structure (in CLAUDE.md):
Never modify anything in benchmark/.
Always log to logs/.
Write outputs to the correct folders.
(1) Exact Top-Level Prompt (goal.md or paste directly)
/goal Optimize to Sigma >= 0.75 (maximize generality + robustness).
ultracode: Read CLAUDE.md completely for ALL rules, metrics, constraints, design guidelines, evaluation logic, and instruments.
Inventory the project (designs A-E exist, benchmark is sacred).
Plan and execute autonomously: generate additional designs, evaluate, adversarially probe, tournament, refine with entropy if needed, and loop until goal or hard constraints hit.
Produce complete reports/recommendation.md. Log everything.(2) That’s the entire prompt. The agent decides the stages, order, skips, and combinations. Full Content of CLAUDE.md (Enhanced LFD Version)
# CLAUDE.md — Harness Lab Loss Function + Harness
## Core Goal (Loss Function)
Find and refine the harness design that achieves **Sigma >= 0.75** while maximizing generality and robustness.
- **Sigma = Alpha / (1 + Delta)**
- **Alpha** = criteria_met / total_criteria (binary 0 or 1 per item in gold_answer.md; no partial credit)
- **Delta** = complexity penalty = (num_agents × num_steps × coordination_overhead) / normalization_factor (use 10 as baseline)
Prioritize high Alpha with low Delta. Higher Sigma wins.
Target: Sigma >= 0.75, strong adversarial performance, evidence of generality (not overfitting to known cases).
## What Exists
- designs/: A.md–E.md (A = minimal single-agent/H1, B = structured single-agent/H2, E = full swarm/H9)
- benchmark/: task.md, gold_answer.md (5+ binary criteria), rubric.md
- Previous results/logs if present
## What to Produce
- Expand to 10 designs total (generate F–J with meaningful diversity)
- Full evaluation + scorecards for all designs
- Adversarial findings
- Tournament results
- Final recommendation.md with winner, Sigma breakdown, rationale, and suggested refinements
- All artifacts in results/, reports/, logs/
## Design Archetypes for New Designs (F–J)
- F: Tool-augmented single agent (2+ tool calls with feedback loop into reasoning)
- G: Independent parallel chains (no reconciliation — allow contradictions)
- H: Self-revision loop (minimum 2 full passes with explicit critique)
- I: Explicit model routing (e.g., Sonnet for reasoning, Haiku for execution)
- J: Meta-harness / outer evaluator loop (max 3 re-runs)
Require structural deviation from existing designs. Log the axis of innovation.
## Evaluation Rules (Blind + Rigorous)
- Score ONLY via instruments against gold_answer.md. Do not enumerate or hard-code the full gold set.
- Binary per criterion. Aggregate Alpha.
- Calculate Delta accurately from design structure.
- Adversarial probe: Test for at least 3 failure modes (e.g., self-preferential bias in swarms, missing completion conditions, coordination failures, domain violations).
- Generality check: Solutions that rely on keyword lists, exact case matching, or appear tailored to evaluation artifacts must be penalized.
- Minimum Alpha 0.65 to enter tournament.
## Hard Constraints + Instruments
- Never modify benchmark/ files or gold_answer.md.
- Never recommend suspending medication or unsafe pharmaceutical actions (domain rule from ASCRS).
- Respect token/time/spend budgets (query current usage). Stop cleanly if approaching limits.
- Available tools/functions: Use them to score, log, calculate Sigma, etc.
- Query instruments: Current spend, time elapsed, projected burn, hypothesis tracker.
## Forced Entropy & Anti-Local-Maxima
- If no Sigma improvement for 2 cycles: Force a non-obvious structural jump (new axis, not incremental tweak).
- On every major step: Reflect — "Are we generalizing or memorizing? Evidence?"
- Log hypotheses, expected failures, and diagnostic results.
- Diversity mandate: New designs must differ meaningfully from priors.
## Output & Logging Requirements
- Always write detailed logs/hypotheses.md.
- recommendation.md must include: Winner, full Sigma/Alpha/Delta table, adversarial summary, why it beat others, next refinement ideas.
- Maintain full traceability.
## Success Criteria
Rediscover ASCRS insight: Structured precision (B-like) should outperform raw complexity (E-like) on this bounded task via higher Sigma. Validate manually on fresh scenarios post-run.
Start by inventorying the folder and creating your execution plan.Example Placeholder Files (Minimal but Functional)benchmark/task.md (example):
Pharmaceutical supply chain disruption scenario in Strait of Hormuz. Develop a 72-hour response plan for critical medication delivery under constraints...benchmark/gold_answer.md (expand this for better blindness):
Criterion 1: Maintains cold chain integrity... [Yes/No expected]
Criterion 2: Prioritizes high-stakes patients...
... (5+ total)designs/A.md (seed example):
Minimal single-agent prompt. Direct instruction to the model with no additional structure.How to Run
Create the folder structure and files above.
Paste the short /goal prompt (or use goal.md).
Let the agent run autonomously (it will read CLAUDE.md and take over).
Review logs/ and reports/recommendation.md afterward. Tweak CLAUDE.md (e.g., add more traps to gold set) if needed and rerun.
!!!!! This setup moves all intelligence into the loss function (CLAUDE.md), adds strong LFD elements (blind eval, instruments, entropy, hard constraints), and makes runs more adaptive and robust.
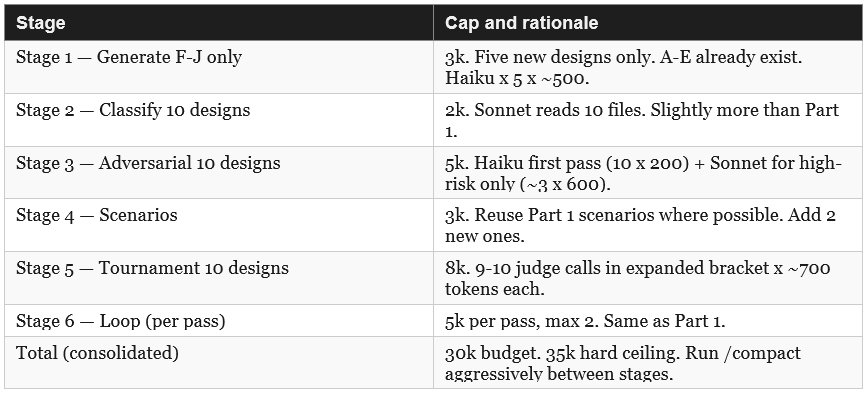
2.6 Token Budget — Ten Designs


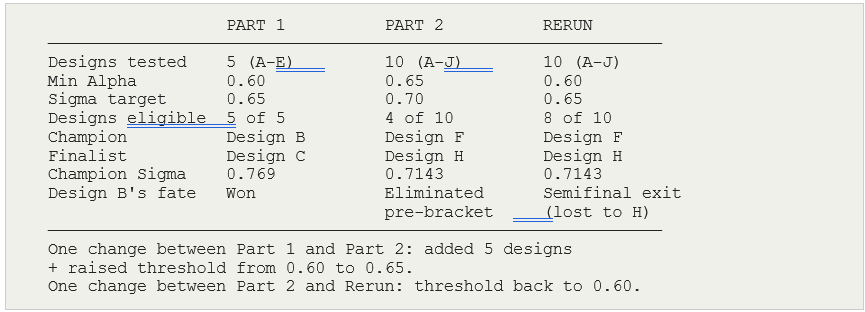
3.1 The Three Experiments at a Glance
Three runs were completed. The table below shows what was set, what changed, and what came out. Read this before anything else.
My folder structure changed slightlly to facilitate the Rerun:

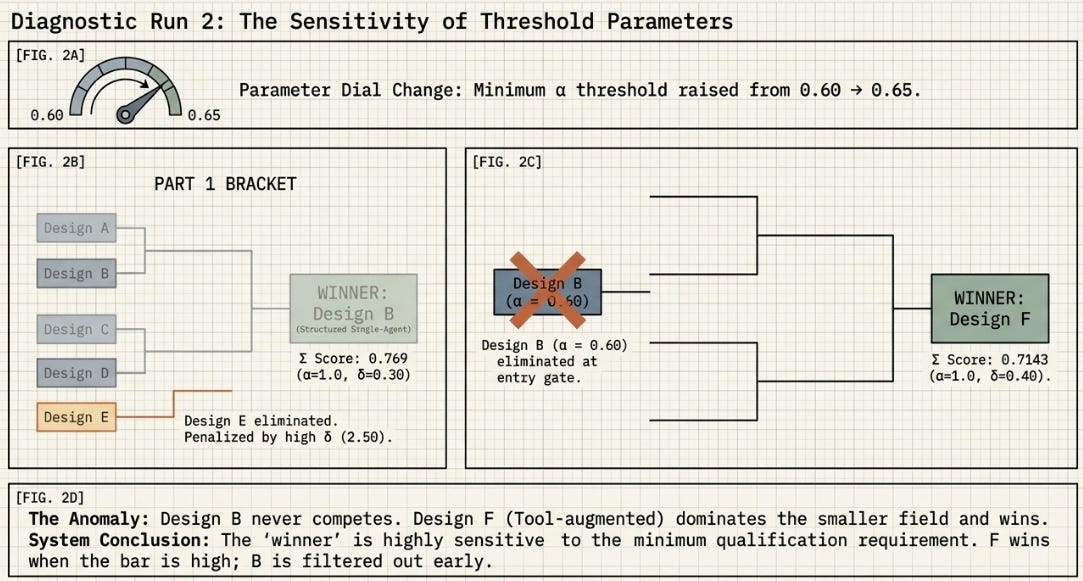
3.2 What Happened to Design B
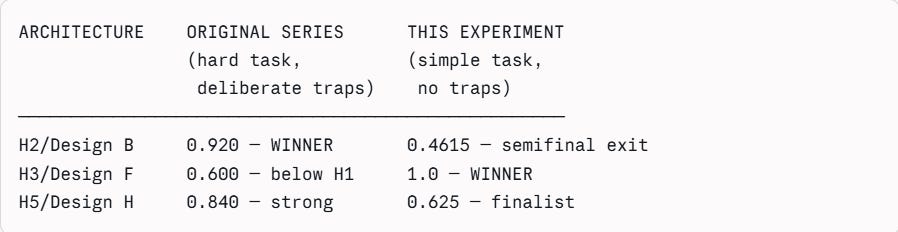
Design B was the Part 1 winner and the H2 equivalent — the architecture the original series found most effective. Its fate across the three runs shows why the Alpha threshold is the most sensitive parameter in the experiment.


3.3 Why Design F Won
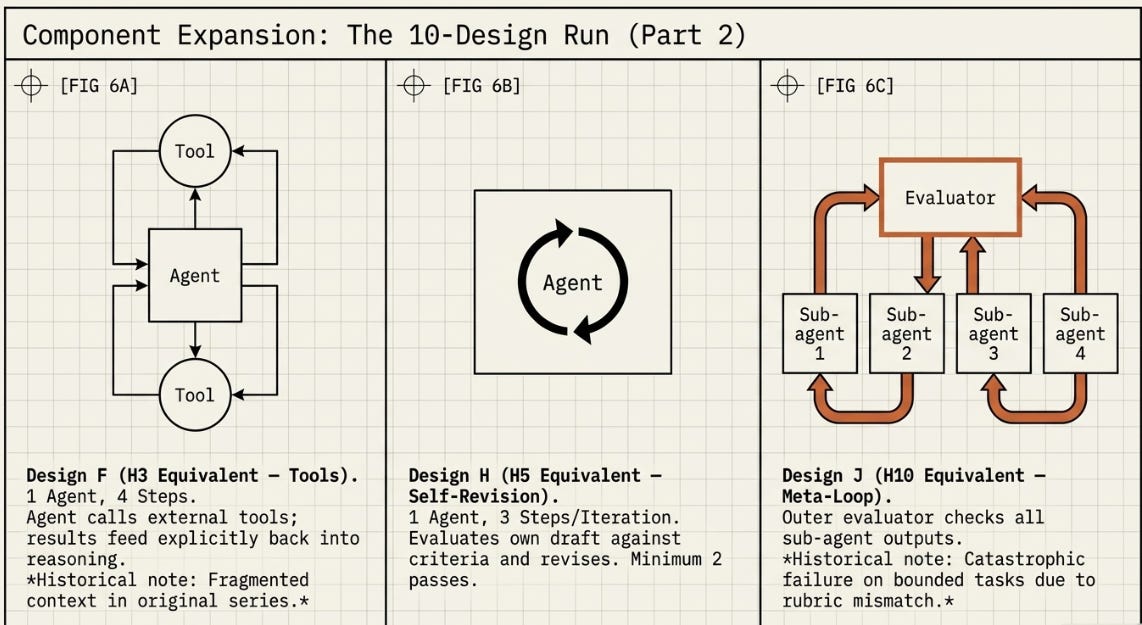
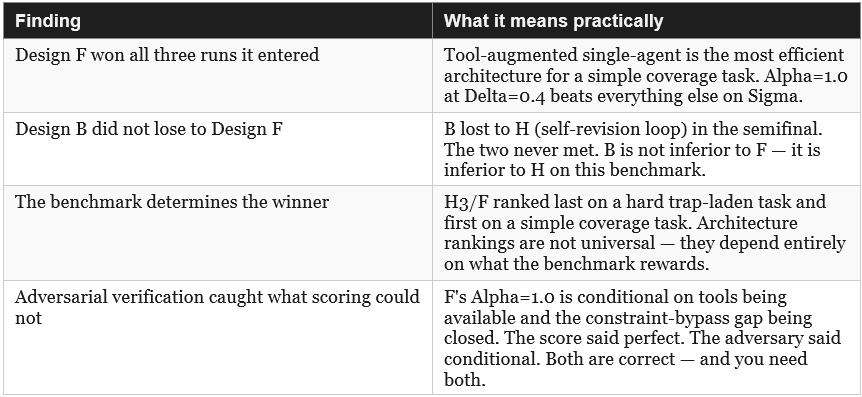
Design F is the H3 equivalent — tool-augmented single agent. In the original series H3 scored 0.600 and fell below the H1 baseline. Here it won all three stages it entered. The reason is in the numbers, not the architecture.

3.4 Why the Same Architecture Ranked Differently
H3 scored below H1 in the original series. Design F (H3 equivalent) won this experiment. Same architecture type, opposite result. The benchmark explains the difference entirely.

3.5 What the Adversarial Stage Caught
Design F scored Alpha=1.0 in both Part 2 and the Rerun. The tournament declared it champion. The adversarial agent found something the score could not show.

3.6 The Four Findings in Plain Terms

4.1 What the Automated Results Should Tell You
The experiment is designed to reproduce three findings from the original H1–H10 series. If all three appear in the automated results, the workflow is functioning correctly and the benchmark is valid. If they do not appear, either the benchmark needs adjustment or the workflow has a specification gap.

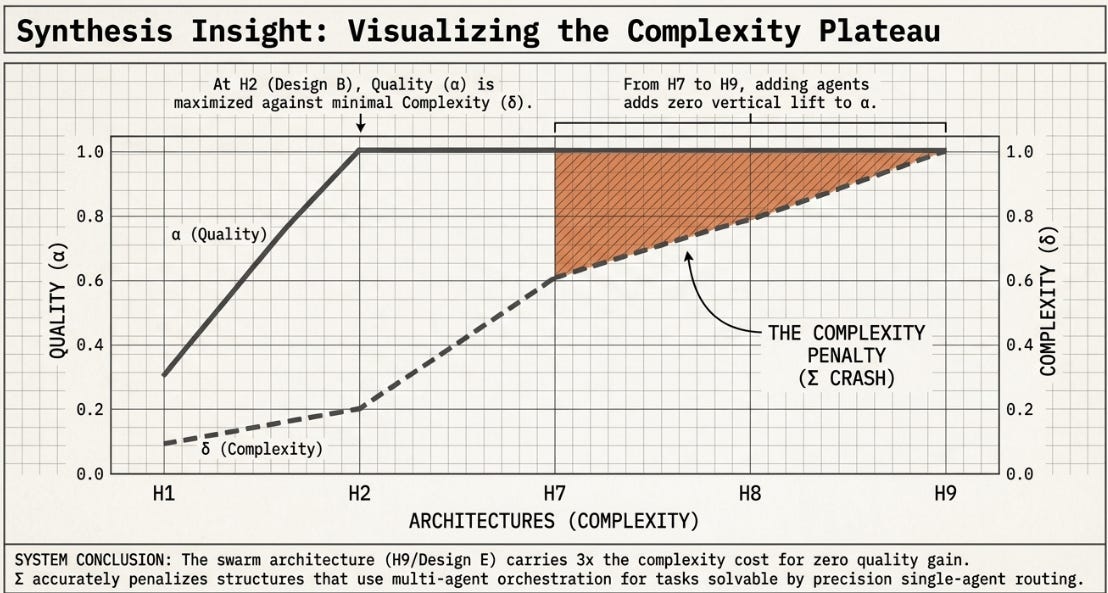
4.2 What Sigma Adds That Alpha Could Not
The original H1–H10 series measured Alpha and Kappa but had no complexity penalty metric. The H2 > H9 result was observed but not fully explained: H9 achieved similar quality but lost. Sigma provides the explanation post-hoc — H9’s Delta of 2.5 reduces its Sigma to less than a third of H2’s Sigma despite similar Alpha. The automated experiment makes this comparison explicit and generates it systematically rather than as a retrospective observation.

4.3 Automated vs Manual: The Real Comparison
The weeks spent on the original H1–H10 series were not wasted effort. They produced the benchmark, the gold answer, the scoring rubric, and the insight that precision beats parallelism on bounded tasks. The automated experiment cannot produce those — it consumes them.
What the automated experiment adds is reproducibility and scale. The same benchmark can now be run against any new harness design in minutes rather than sessions. The /goal and Loop Until Done patterns mean the evaluation continues until a quality threshold is met, not until the developer decides to stop. And the Sigma metric, introduced here, can be applied retrospectively to the original H1–H10 results to explain them more precisely.

4.4 What to Do With the Results
Before acting on the results, it helps to understand what the three experiments were actually doing together. Each run was not an isolated test — it was a sensitivity check. When you change a parameter and run again, you are asking: does this result hold, or was it a product of the settings I chose?
Think of the threshold as a filter on a job interview
The Alpha minimum threshold works like a minimum qualification requirement for a job. Set it at 0.60 and most candidates get an interview. Set it at 0.65 and stricter standards apply — some candidates who would have competed well never get a chance. The question is not which threshold is correct. The question is whether your winner would win under either setting.

Think of the benchmark as the exam question
The benchmark task is the question every design has to answer. If the question is easy, designs that are good at covering ground broadly will score well. If the question has deliberate traps, designs that reason carefully and precisely will score well. The same student can top the class on one exam and fail another — not because the student changed, but because the exam changed.
This is exactly what happened across the original series and this experiment. The original series used a hard exam with traps. H2 (careful, precise structure) aced it. H3 (uses tools, covers ground broadly) failed it. This experiment used a simpler exam with no traps. H3/Design F aced it. H2/Design B only partially passed. Neither result is wrong. Both are correct answers to different questions.

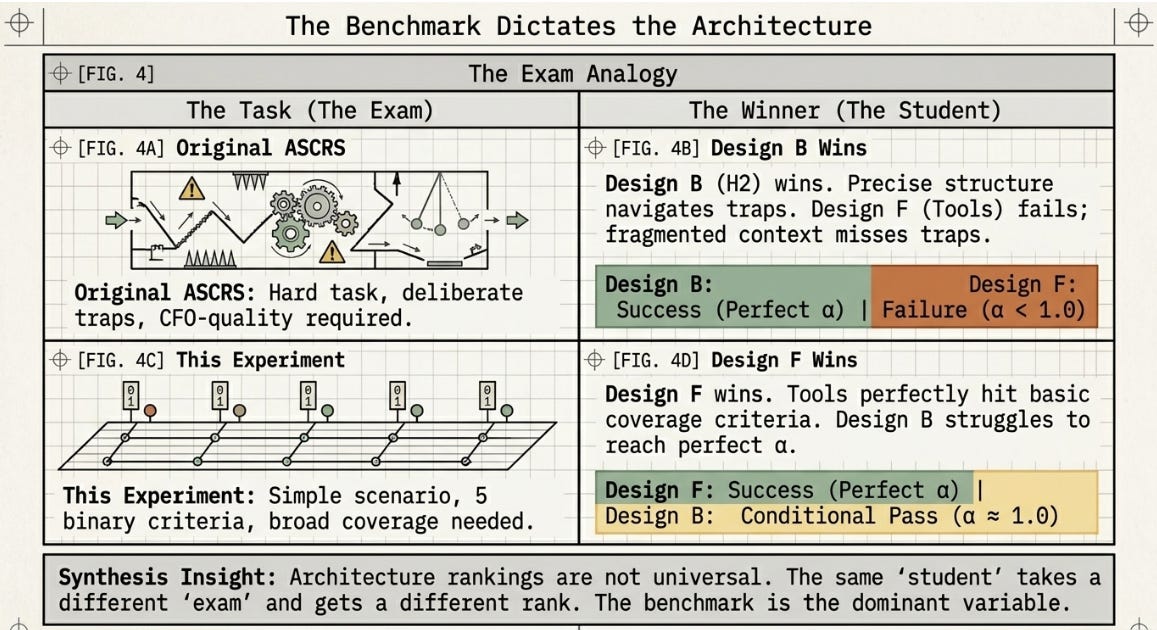
Think of the three runs as turning a dial
Running the same workflow with one parameter changed is more valuable than running it once with the best possible settings. Each run answers a different version of the question. Part 1 asked: does the workflow rank correctly on a small field? Part 2 asked: does it still work when the field is larger and the bar is higher? The Rerun asked: was Design F’s win genuine, or an artefact of Design B being excluded?

Design F won Parts 2 and the Rerun with identical Sigma. That means the result is robust — it does not depend on the threshold setting. Design B’s performance varied across runs — that means B’s result is threshold-sensitive. Knowing the difference between a robust finding and a threshold-sensitive one is what multiple runs are for.
Three practical things to do
• Compare the Sigma ranking from these runs against the original Alpha ranking from H1–H10. Broadly they should agree — H2 and H7 were the top performers in the original series, and their equivalents (B and I) should rank above H9/E on Sigma. Where they diverge, check whether the benchmark rewarded a different capability than the original task did.
• Use the winning design specification as a starting point, not a final answer. Design F won but carries a conditional Alpha — the constraint-bypass vulnerability the adversarial stage found. Apply the zero-Delta patch (add the no_suspension_recommended field) before treating F as a production design. A machine-generated winner that cleared a quality threshold is a useful first draft, not a finished architecture.
• Run the workflow again with a harder benchmark — one that includes deliberate traps modelled on the original ASCRS design (the PO-2853 cold chain requirement, the PO-2869 air freight override). This is the most direct way to test whether Design B or Design F holds up when the task actually requires careful precision rather than broad coverage. That run would resolve the central open question: which architecture wins when the benchmark is genuinely hard?
4.5 A Framework for Harness Selection in Practice
These experiments tested workflow mechanics and benchmark sensitivity — not the full complexity of a real deployment. The original ASCRS series used a hard, trap-laden task with precise criteria. This experiment used a simplified version of the same scenario. The winning architecture changed completely between them. That gap is not a failure of the methodology. It is the most practical finding of the series.
In real deployments, the task profile varies significantly depending on the organisation, the industry, the quality of documentation, and where in the value chain the agent is operating. The four variables below determine which harness architecture is likely to perform best before you run a single experiment. I apply them as general guidelines. Suitability really depends on application requirements. But I have found these useful. Generally, I try not to overcomplicate. Replicability and consistent Evaluation measures, make this necessary. However if I am unsure, and especially if starting with clean-slate, unburdened-legacy-workflows, allowing loops to run, with /goal and/or ultracode on xhigh is very helpful


Where the Experiments Sit on This Framework
The original ASCRS series sat at the hard end of all four variables: a complex, trap-laden task requiring specialist pharmaceutical supply chain knowledge, against a precisely authored gold answer with six gate criteria, at regulatory-consequence stakes. H2 won because that task profile rewards precision above everything else.
The automated experiment here sat at the easy end: a simplified version of the same scenario, five binary criteria, no traps, no deliberate constraints requiring specialist knowledge. Design F won because that task profile rewards broad coverage above precision. The same organisation running the same workflow on both task profiles would get different recommended architectures — correctly.

The Practical Implication
H2 remains the right starting point for any well-run organisation with clear processes and a bounded, well-specified task. As the task becomes more ambiguous, the domain deeper, the documentation thinner, or the stakes higher, the architecture needs to change — not because H2 is wrong, but because the task is asking something different. The experiments here did not disprove the original finding. They showed the boundaries of where it applies.
The framework above is not a prescriptive ranking. It is a set of questions to ask and consider before running an experiment. Answer the four variables honestly for your specific task and organisation and you will have a defensible starting hypothesis for which harness architecture to test first — rather than discovering it only after running ten designs through a tournament.

The following ASCII topology diagrams document the ten harness architectures from the original Harness Lab series, including their actual Alpha scores. These serve as the reference for comparing what the automated workflow generates in Designs A–J. If the generated designs differ structurally from these, Stage 1a (Design Verification) will flag the discrepancy.
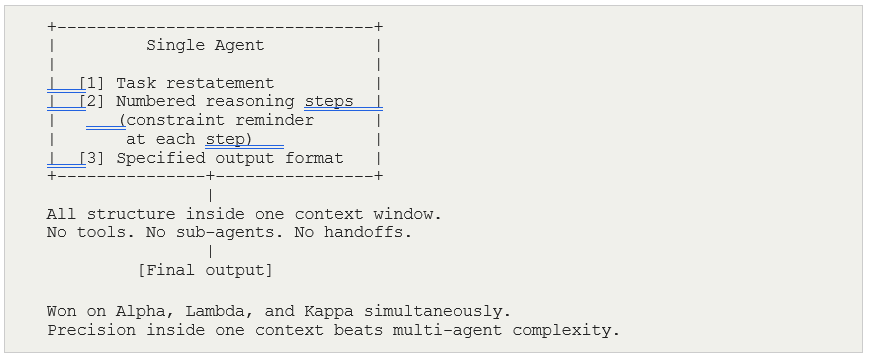
H1 — Minimal Single Prompt Alpha: 0.665 Baseline

H2 — Structured Prompt with Reasoning Scaffold Alpha: 0.920 WINNER
H3 — Tool-Augmented Single Agent Alpha: 0.600 Below Baseline

H4 — Independent Chains Alpha: 0.440 FAILED (coherence collapse)

H5 — Self-Revision Loop Alpha: 0.840 Strong

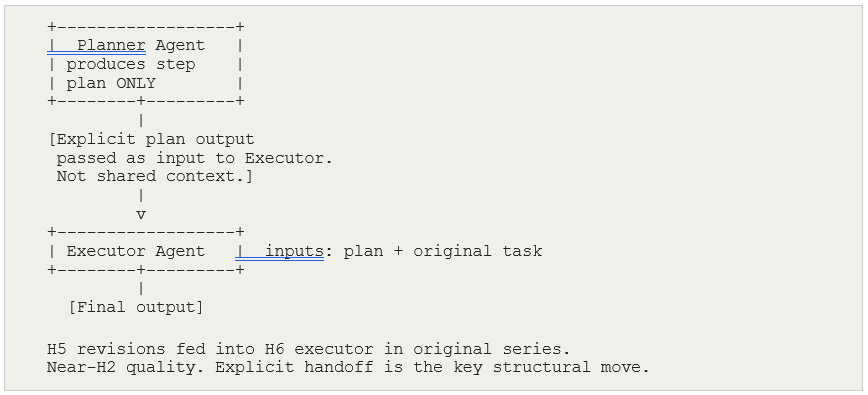
H6 — Two-Agent Chain with Revision Handoff Alpha: 0.900 Strong
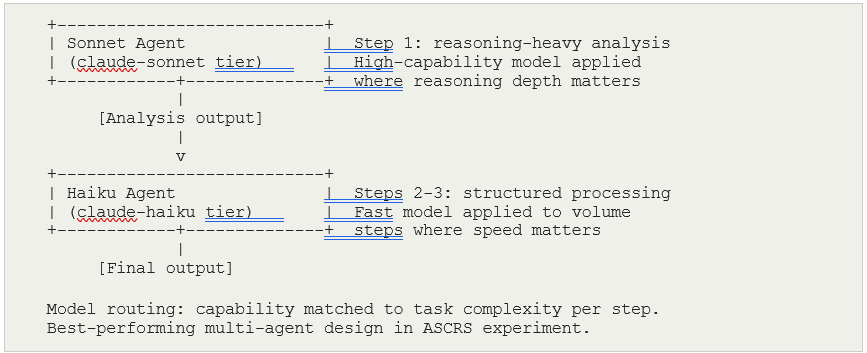
H7 — Three-Agent with Model Routing Alpha: 0.840 Strong
H8 — Parallel Agents with Aggregation Alpha: 0.815 Plateau
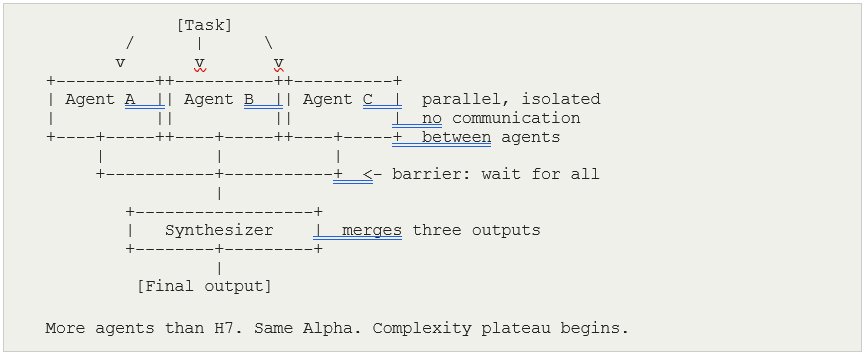
H9 — Five-Agent Orchestration Swarm Alpha: 0.815 Plateau (predicted to win)

H10 — Meta-Harness with Outer Evaluation Loop Alpha: 0.230 FAILED

A.1 How These Map to the Automated Designs
References
• Anthropic (2026). ‘A harness for every task: dynamic workflows in Claude Code.’ Thariq Shihipar & Sid Bidasaria. June 2026. claude.com/blog/a-harness-for-every-task-dynamic-workflows-in-claude-code
• Anthropic (2026). ‘Orchestrate subagents at scale with dynamic workflows.’ Claude Code documentation. code.claude.com/docs/en/workflows
• ‘The Prompt Is Still the Work: Dynamic Workflows in Claude Code.’ Interesting Engineering++. interestingengineering.substack.com
• ASCRS Harness Lab. H1–H10 architecture evaluation against Hormuz Strait pharmaceutical supply chain disruption scenario. Alpha scores: H1=0.665, H2=0.920, H3=0.600, H4=0.440, H5=0.840, H6=0.900, H7=0.840, H8=0.815, H9=0.815, H10=0.230.
• ‘Architecture of Awareness Experiments.’ V1–V4 progressive agent designs for the ASCRS domain.
• ‘The Geometry of Unpredictability.’ Bounded vs unbounded agent tracks, circuit breaker at iteration 3 (4,042 tokens vs 91,379 tokens). Harness Engineering Series.
• ‘The Structure Is the Intelligence.’ StockPilot CMA Cycles 0–4, structural layer separation, Policy/State/SOPs/Action, 97% token reduction. Harness Engineering Series.