
Banco Santander's Open Stack
What Banco Santander’s GitHub Release Means for Mid to Large-Size Financial Institutions — and a Revised (Deployment) Framework

A note on this companion piece
The previous articles, “Two Economies, One Technology,” and “The Funnel, The Floor and The Structure” argued that regulated financial services institutions occupy a distinctive position in the agentic AI landscape: near-term cost-side gains that are real but bounded by compliance overhead, and the fastest demonstrated ROI of any industry quadrant on narrow, well-specified, document-heavy tasks with clear success criteria. It concluded that the binding constraint is organisational and architectural as much as it is technical.
Well, Banco Santander’s AI Labs just published a suite of ten open-source repositories under the SantanderAI GitHub organisation. I like it a lot! Also very well done to the team that brought this together, and have openly shared this! The repos are what I would deem fairly small, tightly scoped, and technically unpretentious — which is precisely why they are worth examining in detail. They are, collectively, an implicit answer to the question: what does the actual deployment stack look like for a regulated financial institution that has moved past piloting and into operational AI?
This companion piece explains what each repository does, who within a mid to large-size institution would use it, what you need before you start, how to deploy it, and — where relevant — how to integrate it. I maintain details of the deployment guide, which is far too long for this article, and it will not be included at this point. When I have the time, I will append a detailed appendix to include it. For now, as has been the case in the past, I continue to run all experiments and exercises via Claude Code. My API calls typically run through OpenRouter, and sometimes directly via Anthropic itself. Section 5 should give you a good high level overview over intial deployment, and guide. The article assumes you are a practitioner, not a procurement committee: the language is implementation-level, not executive-summary level.
1. Banco Santander: institutional context
For those who may not know, Santander is one of the largest commercial banks in the world by total assets — approximately €1.8 trillion as of early 2026 — with major retail and commercial banking operations across Spain, the UK, Brazil, Mexico, the United States, Poland, and most of continental Europe. It is simultaneously supervised by the ECB, the Bank of England, the Federal Reserve (for its US subsidiary), Banco de España, and local regulators in over a dozen jurisdictions. Its AI research function is centralised in an AI Labs organisation based in Madrid, with applied work distributed across business lines.
Several features of Santander’s institutional profile matter for interpreting the repo suite. First, Santander operates retail banking at enormous scale — hundreds of millions of accounts across geographies — which means fraud detection, KYC/AML screening, and credit decisioning are not edge-case problems but core volume operations running continuously. Second, the bank is simultaneously subject to overlapping model risk regulatory frameworks: the OCC’s SR 11-7 and its Comptroller’s Handbook equivalents in the US, the ECB’s Guide to Internal Models, the EBA’s Guidelines on Internal Governance and their emerging ML-specific guidance, and the EU AI Act’s risk-tier classification for credit and biometric systems. Third, Santander has made explicit public commitments to Responsible AI, which in practice means AI decisions must be explainable, auditable, and tested for discriminatory outcomes — not just accurate. This explainability is an issue I understand well, whenever you deal with “new(ish) technologies which are required to clear regulatory hurdles. These are fair responsibilities involved.
A mid to large-size financial institution — say, a regional/global bank with $30–500B in assets, a retail lending book, multi-state or multi-country operations, and a primary regulatory relationship with the OCC or a state banking regulator — faces a structurally identical problem set, at smaller scale. The compliance constraints are the same. The need for model explainability is the same. The task taxonomy (fraud, KYC, credit, customer communications) is nearly identical. The Santander tooling was built for their environment; it maps onto this smaller institutional profile with surprisingly few adjustments, although these can quite easily be adapted.
One further contextual note: every public repo in this suite cleared Santander’s two-track Open Source Programme Office review — Fast Track for generic tools and tutorials, Full Track (OSPO Lead + Legal + CISO + Architect, 2–4 week SLA) for anything touching AI models, frameworks with IP, or code that touched internal data. What cleared that review is informative. These are not experimental notebooks. They are tools that passed enterprise security and legal review at one of the world’s most heavily regulated financial institutions. To say I was impressed to see this release, is putting it mildly.
2. Why this release is a signal
Open-source releases from regulated financial institutions are rare. Selection is never arbitrary — everything in this suite is something Santander built, used internally, and then made the deliberate decision to publish. Reading across all ten repos, the consistent theme is: infrastructure for governed, explainable, domain-specific AI. No repo attempts to build a better language model. No repo implements a general-purpose agent. Every repo assumes you already have an LLM (or multiple LLMs, routed through a provider) and asks: how do you deploy it safely in a regulated context?
Three sub-themes run through the suite. The first is synthetic data for training without PII exposure: gen-fraud-graph and sota-stressed-datasets both generate or transform data so that you can train and validate models at scale without touching real customer records — a critical requirement under GDPR, CCPA, and standard data governance frameworks. The second is governance and policy compliance: mech-gov-framework, autoguardrails, and mutatis-mutandis together constitute an end-to-end governance stack covering decision governance, policy red-teaming, and discrimination testing. The third is infrastructure for vendor flexibility and iterative improvement: llm_bridge, genetic-algorithm, and ralph are the plumbing that makes everything else model-agnostic and continuously improvable.
The framing in my prior articles — that the institutions realising fastest ROI from agentic AI esp in regulated industries are those tackling “narrow, well-specified, document/data-heavy tasks with measurable success criteria” — maps exactly onto the tool selection in this suite. The lessons embedded in those choices are worth carrying through the rest of this piece.
For those who would like a quick review/recap, read these 3 prior articles:

Two Economies, One Technology

This is the second in a series, and a companion piece to "What Is Any Agentic Architecture Worth Anyway. PharmaCo International: An Agentic AI Case Study" Where I have gone deep with this case study, the material below takes a wider scope on the impact of AI and Agentic AI structures to industry.
The Funnel, the Floor, and the Structure

This article follows Two Economies, One Technology, and is part of a series of articles that begins with What Is Any Agentic Architecture Worth Anyway? Many of the questions, experiments, analysis and issues raised have arisen at the Board Level, Management & Strategy meetings. Results, experiments, and comments shared have been anonymized where relevan…
3. The repository suite: explained and deployed
What follows covers all ten public repositories released todate (Jun 26). For each: a plain-language description of what it does, the institutional context in which it would be deployed, prerequisites (what you need before you start), and a note on Claude Code integration where relevant. The repos are grouped loosely by the layer of the deployment stack they occupy — Foundation, Task, Governance, or Evolution — matching the framework in Section 4.
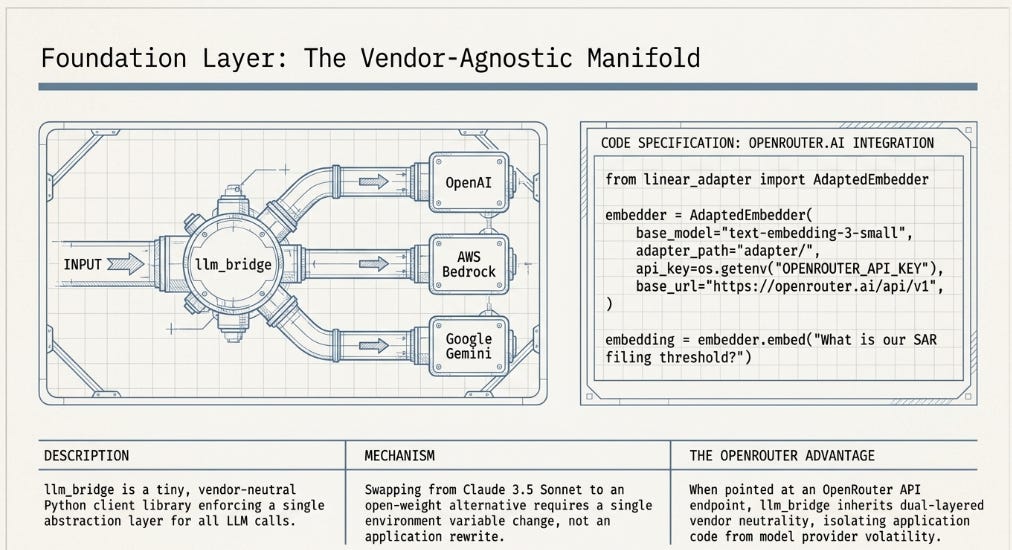
■ llm_bridge
A tiny, vendor-neutral Python LLM client library. One interface class (LLMClient) with pluggable adapters for OpenAI’s API, AWS Bedrock, and Google Gemini — with a documented “bring your own backend” extension path. Your application code calls LLMClient.complete() and does not care which model or provider sits behind it. Swapping providers means changing one environment variable, not rewriting your application.
For anyone routing through OpenRouter (which is what i do): OpenRouter exposes an OpenAI-compatible API endpoint (https://openrouter.ai/api/v1), so the OpenAI adapter works directly with OpenRouter as the backend. This means llm_bridge becomes the abstraction layer between your application code and OpenRouter, which itself abstracts over the underlying model providers (Anthropic, Mistral, Meta, Google, and others). You get two levels of vendor neutrality for the price of one config change.
Deploy this first, before any other tool in the stack. It is the single point through which all LLM calls will flow. Wiring it correctly at the start means every subsequent tool inherits provider flexibility automatically.

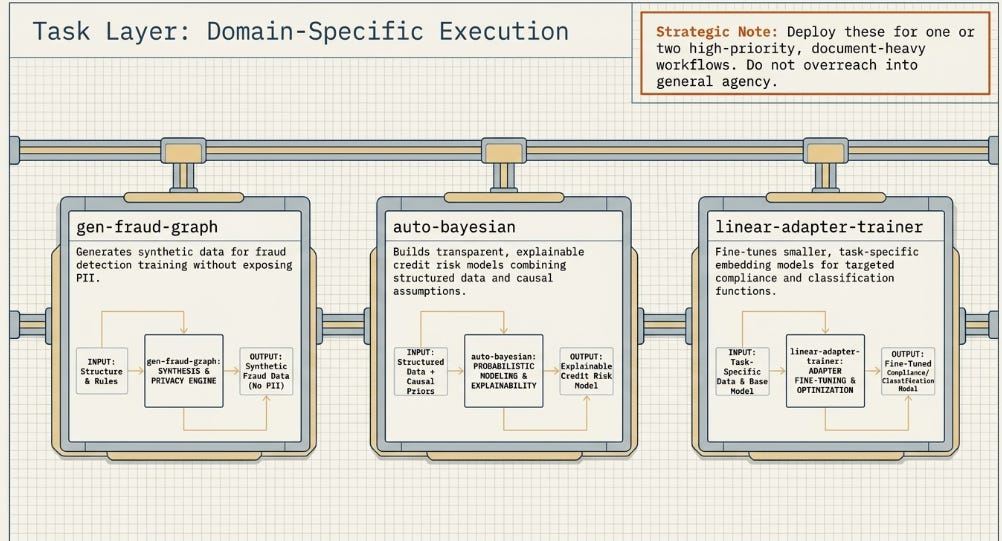
■ gen-fraud-graph
Generates synthetic transaction graphs that mimic the structural patterns of real-world financial fraud — ring networks, mule account chains, money-laundering layering structures — at scale up to 100 million accounts. Output is a graph-structured dataset (nodes = accounts, edges = transactions) that can be used to train and benchmark graph-based fraud detection models without any exposure to real customer data.
The core insight is that fraud is relational. A single transaction viewed in isolation may appear benign; the same transaction embedded in a network of linked accounts with suspicious velocity patterns looks very different. Graph Neural Networks (GNNs) have shown materially better recall on organised fraud than feature-based approaches — but they require graph-structured training data, which is difficult to obtain at sufficient quantity and variety without PII risk. Synthetic graph generation solves this problem. The scale ceiling (100M+ accounts) is specifically designed to produce training sets large enough to be statistically credible for production model development, not just toy experiments.

■ auto-bayesian
Config-driven training of Bayesian networks on relational tabular data. You provide a dataset and a YAML config that specifies your variables, their types (continuous, discrete, ordinal), and an assumed causal structure between them. The framework trains a Bayesian network — a probabilistic graphical model that encodes conditional dependencies — and returns a model you can query for conditional probabilities and causal explanations.
Bayesian networks are particularly well-suited to regulated financial services for two reasons. First, they are inherently interpretable: you can trace precisely why a model reached a given output by following the conditional probability path through the graph. This satisfies SR 11-7’s model explainability requirement in a way that a gradient-boosted tree or neural network cannot easily match. Second, they encode causal assumptions explicitly — the YAML config is itself a documented model assumption, which auditors and model risk reviewers can examine and challenge. The model doesn’t just produce a probability; it produces a probability with a visible reasoning chain.

■ linear-adapter-trainer
Trains a linear embedding adapter using triplet loss to align a pre-trained embedding model with your institution’s specific query-document distribution. The problem it solves: you have a general-purpose embedding model (OpenAI’s text-embedding-3-small, or an equivalent open-weight model), and you want it to retrieve your internal documents more accurately for queries that are specific to your institutional context — regulatory filings, internal policy documents, credit product terms, procedure manuals.
A linear adapter is a small matrix transformation applied on top of the frozen embedding model. Training uses triplet loss: for each query, you provide a relevant document (positive pair) and an irrelevant document (negative pair); the adapter learns to pull relevant pairs closer in embedding space and push irrelevant pairs apart. Training is fast — minutes, not hours — and requires no GPU infrastructure or foundation model fine-tuning budget. The result is a domain-tuned retrieval layer for your RAG system that costs almost nothing to build.

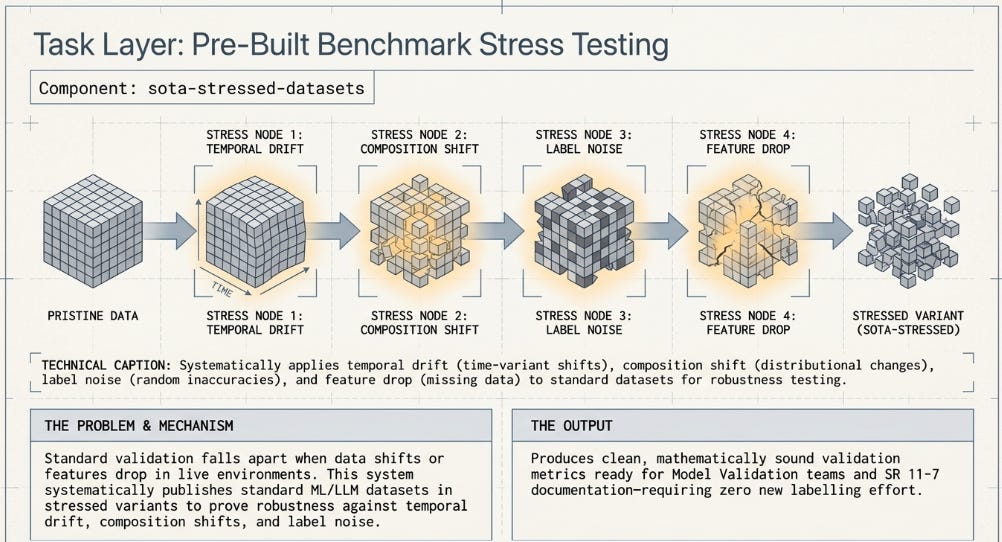
■ sota-stressed-datasets
Takes standard ML and LLM benchmark datasets and republishes them in “stressed” form — systematically modified versions designed to evaluate model robustness under conditions that deviate from the training distribution. The stress types Santander describes include temporal drift (data drawn from a different time window), composition shift (different proportions of demographic or product subcategories), label noise (a controlled fraction of labels corrupted), feature drop (key features made missing at evaluation time), and adversarial perturbation (small input changes designed to probe decision boundaries).
The regulatory value is direct. SR 11-7 and its equivalents require that model risk management include stress testing — demonstrated evidence that model performance degrades gracefully rather than catastrophically under adverse conditions. Running your models against pre-built stressed benchmark variants provides documented, reproducible evidence of robustness that satisfies this requirement, and tends to be more informative than validation on clean held-out data alone. The “stressed” framing also maps cleanly onto the vocabulary regulators use in model examinations.

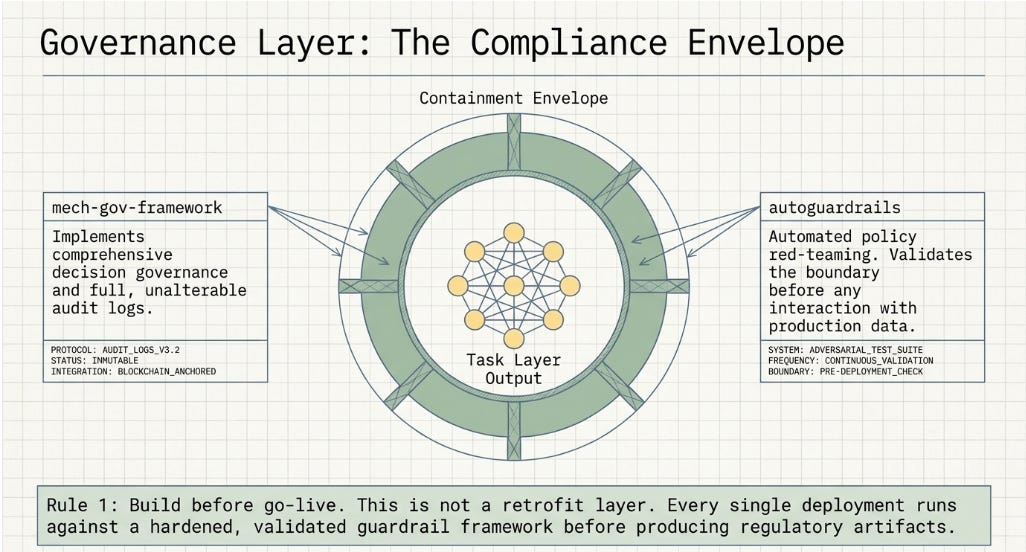
■ mech-gov-framework
Mechanical Governance for LLM Decisions. This is the most architecturally significant repo in the suite. It provides a Python framework for wrapping LLM calls in governance regimes that enforce policy programmatically — not by prompting the model to be compliant, but by structurally constraining what outputs it is permitted to produce and what actions it is permitted to trigger.
Three regime types. R1 (Advisory): LLM output is logged and surfaced for decision-support, but a human makes the decision. R2 (Supervised): LLM output is actioned, but a human can override within a defined time window. R3 (Autonomous): LLM output is actioned immediately, subject to hard gates that block specific action types regardless of model output. Hard gates are the framework’s key enforcement mechanism: absolute blocks that fire on defined conditions (output contains a protected attribute reference; decision amount exceeds threshold; model confidence below floor) before any action is taken.
The entropy commit-reveal mechanism is worth noting separately: before receiving the full decision context, the LLM commits to a decision hash. This prevents hindsight-biased rationalisation — the model cannot see the outcome and work backwards to construct a justification. Governance metrics produce an audit trail for every decision, with decision provenance logged to a persistent store.
The connection to the Harness Lab taxonomy is direct. Mech-gov-framework is an implementation of the Govern primitive from the eight-primitive framework (Perceive, Remember, Reason, Act, Evaluate, Mutate, Coordinate, Govern). H2’s consistent outperformance of H9 in the ASCRS benchmarks reflected, in part, that simple governed architecture outcompetes sophisticated multi-agent coordination when the task demands it. This framework operationalises that lesson at the production engineering level.

■ autoguardrails
An autoresearch-style scaffold for LLM guardrail testing. The core idea is borrowed from AI alignment research: instead of manually writing test cases to probe where your LLM policy fails, you run a search process over your policy surface that automatically finds edge cases where a compliant-seeming model would violate your stated policy.
The target is a policy.md file — a structured document describing what your LLM is and is not permitted to do in a given deployment context. The scaffold reads this document and searches for adversarial prompts that would cause your LLM to violate each policy clause while appearing to comply. Output is a structured report of discovered violation modes, ranked by severity. Think of it as automated red-teaming that runs against your own policy document rather than requiring a human red team.
The genetic-algorithm repo (below) is the search engine underlying this scaffold — autoguardrails and genetic-algorithm are two components of the same autoresearch pattern, where the GA evolves the attack prompts and the policy document is the fitness surface.

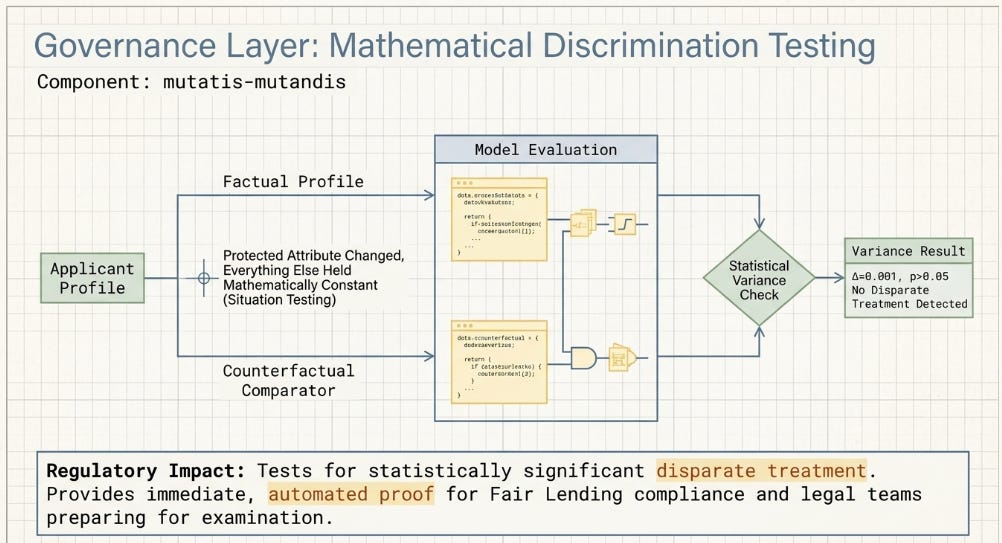
■ mutatis-mutandis
Research code for discrimination analysis using counterfactual comparators — a method known as situation testing in the fair lending literature. The procedure: take an applicant record, change only the protected attribute (race, gender, age, national origin), hold all other attributes constant, run both the original and counterfactual record through your model, and compare outcomes. Statistically significant divergence constitutes evidence of disparate treatment.
“Mutatis mutandis” (Latin: changing only what needs to be changed) is the legal standard for a legitimate comparator in discrimination testing — the counterfactual applicant should differ from the original only in the attribute being tested. The repo operationalises this legal standard in Python, with statistical testing (two-sample proportion test or equivalent) for whether observed outcome differences exceed chance. The companion paper (”Mutatis Mutandis: Revisiting the Comparator in Discrimination Testing”) provides the methodological basis; the repo is the implementation.
For any institution subject to the Equal Credit Opportunity Act (ECOA / Regulation B), the Fair Housing Act, or EU/UK equivalents on algorithmic discrimination, documented situation testing is increasingly required — not merely recommended — as part of model risk management and fair lending examination preparation.

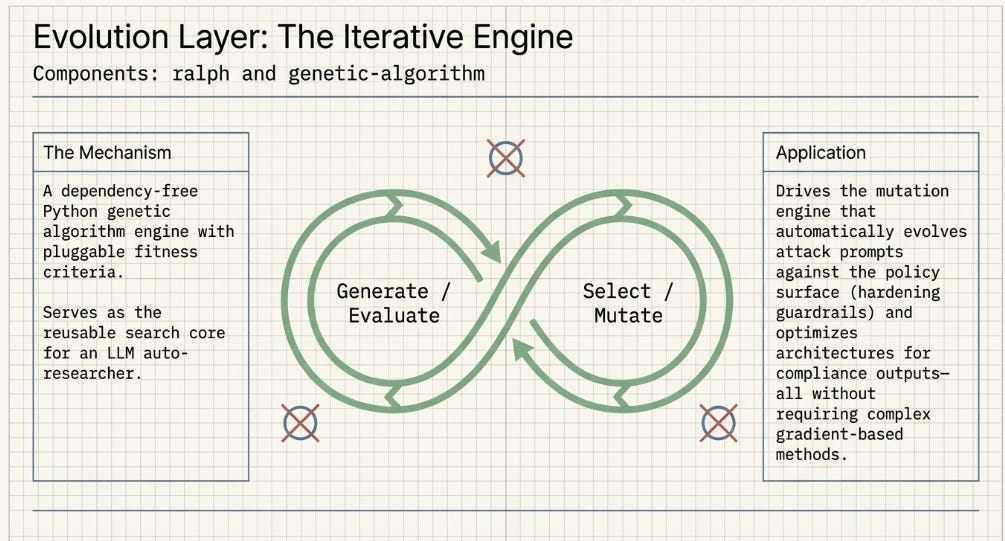
■ genetic-algorithm
A dependency-free Python genetic algorithm engine with pluggable fitness criteria. No external libraries — it is a self-contained importable module. Santander describes it explicitly as “the reusable search core for an LLM/AI autoresearcher,” meaning it is the optimisation primitive that underlies autoguardrails (where it evolves attack prompts against the policy surface) and can be used independently for any optimisation problem where you can define a measurable objective but cannot use gradient-based methods.
A genetic algorithm works by maintaining a population of candidate solutions (chromosomes), evaluating each against a fitness function, selecting the fittest via a selection strategy, and producing a new generation via crossover and mutation. The fitness function is the only part that requires domain knowledge — everything else (population management, selection pressure, crossover, mutation) is handled by the framework. Practical applications in financial services: prompt optimisation, hyperparameter search, trading rule discovery, governance config tuning, and — most relevant here — systematic improvement of the prompts running in your mech-gov-framework-wrapped LLM calls.

■ ralph
A configurable Bash/PowerShell loop that runs an AI coding CLI — such as Claude Code — with a fresh session each iteration. Ralph is the outer loop of an evolutionary code-generation workflow: each iteration starts Claude Code with a clean context, preventing context window degradation across long generation runs, while inheriting the output files (Python modules, JSON results, config files) from all previous iterations. The state is in the filesystem, not in the context window.
Santander describes ralph as infrastructure for their internal agentic development workflows — implying they run Claude Code (or an equivalent) in iterative generation loops for their own Python tooling. For ISR’s purposes, ralph is the same primitive as the AlphaEvolve-style mutation engine documented in the Harness Lab experiment series: the loop that drives generate-evaluate-select-mutate cycles. The difference is that ralph is a clean, production-quality implementation rather than a one-off experiment wrapper.
The most productive use of ralph is in combination with genetic-algorithm: the GA evolves parameters or prompt variants, ralph runs Claude Code with each variant as input, the GA receives the evaluation output as fitness signal. Together they implement a continuous improvement loop over any Claude Code-managed system — including, for the institutional practitioner, the prompts and configs running in the rest of the Santander stack.

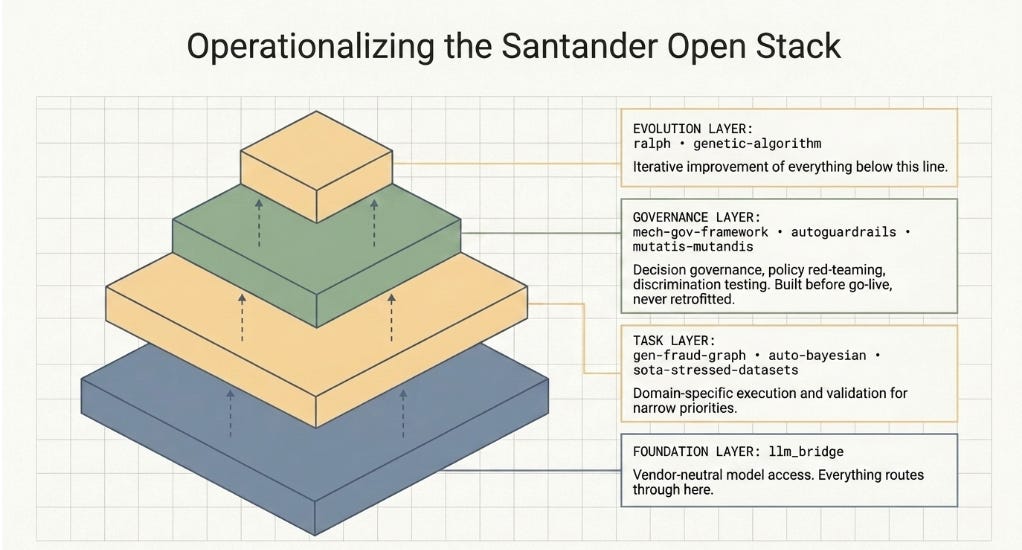
4. A revised deployment framework: the Three-Layer Stack
The “Two Economies” essay’s 2×2 (regulated/unregulated × cost-side/revenue-side) identifies where your institution sits in the broader AI impact landscape.
The framework below is about how you build once you know where you sit. For a mid to large-size regulated financial institution, the Santander suite organises naturally into three operating layers, with two meta-tools that span and improve all three.

Foundation Layer: llm_bridge
Install this before anything else. It is the single point through which all LLM calls flow. Wiring OpenRouter at this layer means you can swap from Claude Sonnet to Opus, to a smaller task-specific model, or to an open-weight alternative by changing one environment variable. Every other tool in the stack inherits this flexibility automatically. Institutions that wire vendor-specific API calls directly into application code end up with a refactoring problem at precisely the moment — a new model release, a pricing change, a performance improvement — when they most want to move quickly.
Task Layer: start narrow
These are the tools that do actual domain-specific work: fraud graph generation, interpretable credit modelling, embedding alignment for RAG, robustness benchmarking. The Harness Lab finding — H9 losing to H2 because complexity compounded coordination cost faster than it added capability — applies directly here. Pick the one or two tasks that represent your highest-volume, highest-compliance-burden back-office operations and deploy those first. The MIT NANDA finding that two-thirds of AI pilot successes came from specialised domain vendors (versus one-third from in-house builds) is, in effect, the same lesson applied at the organisational level: depth before breadth.
Governance Layer: before go-live, not after
The most common governance failure in regulated AI deployment is treating the governance layer as a post-deployment audit rather than a structural precondition. Mech-gov-framework should be in your production architecture from the first live API call, not added retroactively when a regulator asks. Autoguardrails should run before every new model or system prompt deployment. Mutatis-mutandis should run during model validation, not in response to a fair lending examination. The practical difference between “building in” and “bolting on” is whether you arrive at the regulatory examination with documented artefacts that predate the examination — or with a remediation plan.
The compliance overhead the “Two Economies” essay identified as bounding near-term cost-side gains is real. But the Santander suite reframes it slightly: compliance overhead is a constraint that can be engineered around by building governance infrastructure first. An institution that has mech-gov-framework in production with full audit logs, autoguardrails run on every deployment, and mutatis-mutandis results in its model documentation is not only more defensible — it deploys new AI capabilities faster, because the regulatory conversation about each new deployment starts from a baseline of demonstrated governance rather than from scratch.
Evolution Layer: after stability, not instead of it
Ralph and genetic-algorithm are not for your initial deployment. They are for once you have a working, governed, task-layer stack and want to improve it systematically over time. The instinct to add continuous optimisation infrastructure before the foundational stack is operational is the organisational equivalent of H9: sophisticated-seeming, but premature. Deploy ralph and genetic-algorithm in month six or later, once you have baseline metrics from a stable production system to use as fitness signals.
Thoughts on (slow) deployment sequence
1. Months 1–2 — Foundation: Install llm_bridge, configure OpenRouter. Select one Task Layer tool matching your highest-priority use case. Deploy on synthetic or test data only.
2. Months 2–4 — Governance: Implement mech-gov-framework around your Task Layer deployment before any production traffic. Write policy.md and run autoguardrails. Run mutatis-mutandis during model validation. Document everything.
3. Months 4–6 — Production and expand: Go live with one governed task. Add sota-stressed-datasets for model validation on the second task candidate. Do not deploy Task Layer tool #2 until Tool #1 is stable.
4. Month 6+ — Evolution: Introduce ralph and genetic-algorithm. Define fitness functions based on observed production metrics. Run the first GA-guided optimisation cycle. Evaluate before committing.
5. Integration with Claude Code
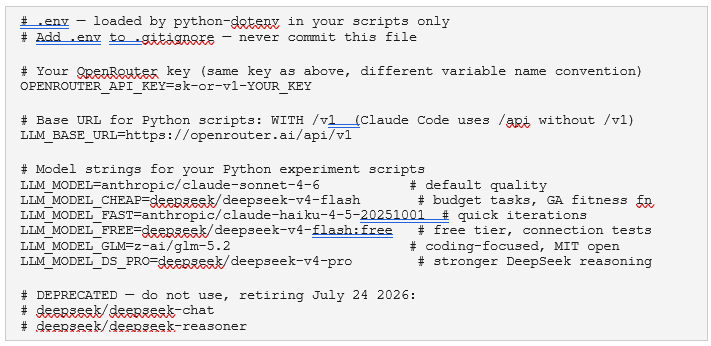
The following assumes Claude Code installed, and API calls routed through OpenRouter. The canonical credential/config separation: credentials live in .env (gitignored), project configuration lives in .claude/settings.local.json (*safe to commit).
Relevant Folder Structure

.claude/settings.local.json
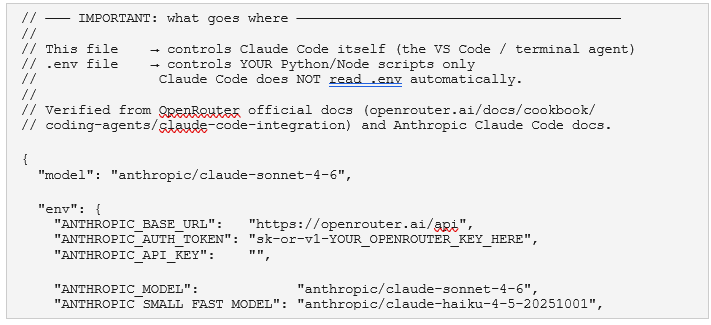

.env — for Python / Node scripts ONLY
This file is loaded by python-dotenv in your experiment scripts. Claude Code does not read it. Keep the two completely separate.
Using third-party models in Claude Code itself
Claude Code is designed for Anthropic models. You can point it at any OpenRouter model via ANTHROPIC_MODEL, but tool use, extended thinking, and prompt caching behaviour vary. Non-Anthropic models may not support all Claude Code features. For experiments and scripts, use third-party models via LLM_MODEL in .env. For Claude Code itself, stick to anthropic/ models for reliability.

The following prompts are written to be saved as .md files in .claude/commands/ and invoked as slash commands in the Claude Code chat panel. Each is self-contained and references paths from the folder structure above.
/scan-policy — autoguardrails red-team run

setup-governance — mech-gov-framework regime config

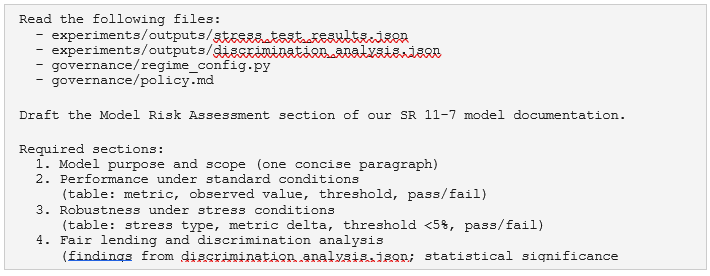
/draft-risk-doc — auto-draft SR 11-7 model risk section

/gen-causal-config — auto-bayesian YAML from domain description

/run-evolution — set up GA-guided prompt optimisation with ralph

6. What this confirms about two economies
The previous essays argued that regulated financial services institutions sit in the top-left cell of the impact matrix: real near-term cost-side gains, bounded by compliance overhead, but with the fastest demonstrated ROI of any sector on narrow, well-governed, task-specific deployments. The Santander suite confirms the first part of that claim and extends the second.
What the suite confirms: the path to realised ROI in regulated financial services runs through narrow, governed, explainable task automation — exactly the profile the “Two Economies” essay identified as where agentic AI reliably delivers results. Every tool in this suite is narrow by design. None attempts to do everything. The compliance overhead is not fought; it is engineered around, systematically and explicitly, in the form of the Governance Layer described above.
What the suite extends: the previous essay framed compliance overhead primarily as a tax — a constraint that bounds how much of the back office can be automated and slows the realisation of cost-side gains. The Santander release suggests a refinement. Compliance overhead remains a real constraint on deployment speed. But for institutions that build the governance infrastructure first and properly — mech-gov-framework in production from day one, autoguardrails as a CI step, mutatis-mutandis as a model validation requirement — that infrastructure becomes a competitive asset rather than just a cost. These institutions deploy subsequent AI capabilities faster, because the regulatory conversation about each new deployment starts from a documented baseline of demonstrated governance, not from an empty page.
A final observation connecting this back to the Harness Lab findings. The ASCRS benchmarks found H2 outperforming H9 consistently: simple, task-fit, well-governed architecture beats sophisticated multi-agent coordination when the task profile favours it. The Santander suite is ten H2s — ten simple, governed, task-specific tools, each doing one thing well, each designed to be auditable. No H9 in sight. The organisation that built these tools has arrived, through production experience, at the same conclusion the ISR experiments demonstrated in controlled conditions: complexity is a liability until governance is a capability. And governance, it turns out, is something you can open-source.
If you have the time:
The Harness Lab, Automated

Five Strategic Insights From Workflow Automation - The Harness Lab, Automated
ASCRS Harness Lab - The Integrated Agentic Stack: When Does More Architecture Mean Better AI? A Diagnostic Teardown

Had some time on my hands, and applied the features of The Harness Experiment(s) to the Architecture of Awareness design considerations. You will remember from The Harness Experiment (applied to a mini vendor analysis case study) that the results presented as follows: