
Building On Anthropic's Claude
A retrospective on Complexity, Cost, Memory, Portability, and the Layer(s) where most problems actually live


Why this article exists - A Consolidation of Findings and Tiny Experiments
This will be a consolidation article that takes a perspective or stand on the few recent articles and experiments run with Claude/Claude Code. The experiments were taken from similar actual cases, and then task-oriented down for case study orientation and discussion.
They originally stemmed from a set of concerns that circulate regularly among practitioners and non-practioners alike, people who asked, even friends:
(1) that the product is drifting toward developers,
(2) that native memory is unreliable,
(3) that complex agent systems produce better results,
(4) that vendor lock-in is an inevitable consequence of building on the platform,
(5) that API choice does not matter, and
(6)that automation requires infrastructure that most business users cannot manage.
These concerns are not invented. They reflect real experiences. But across a series of controlled experiments run recently -- with real measured outputs, gold-standard answers, and scored rubrics -- a consistent pattern emerged: the concerns are usually accurate observations about default behaviour, and inaccurate conclusions about what that behaviour means.
All experiments focus on Anthropic’s products, as this is my preference for executing at the Institutional Grade level. That does not mean I do not use other harnesses, models or service providers - because the space evolves fast, and there is always something new to experiment on. But my preferences are strong for Claude.
This article is the retrospective. It pulls the key findings together in one place, addresses each concern directly, and links to the full article for readers who want the detail. The argument is not that Claude is without limitations. It is that:
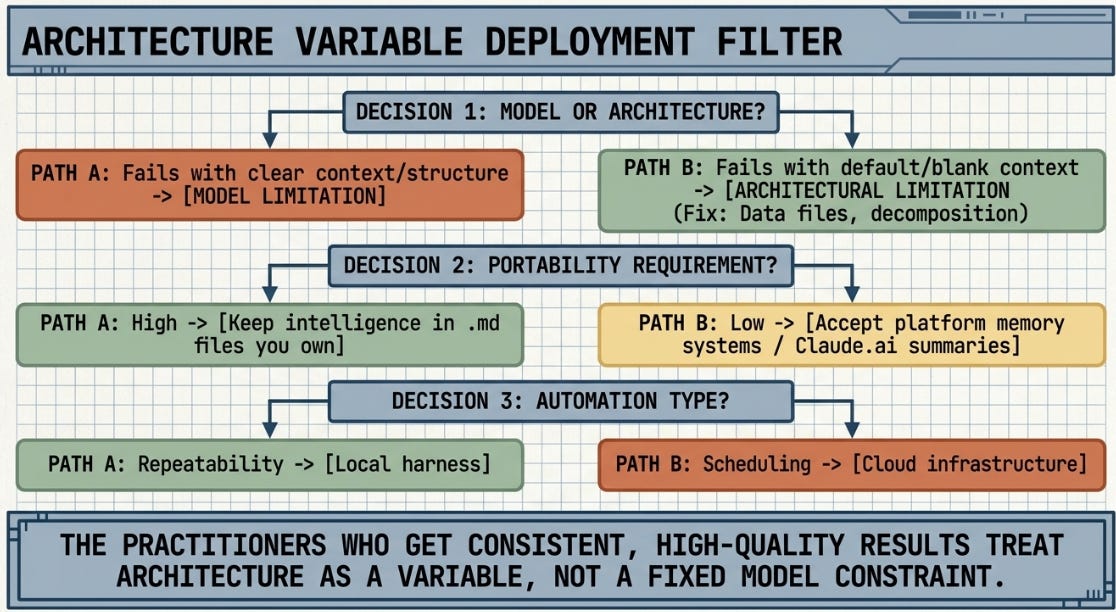
Most of the limitations practitioners describe are architectural, and architecture is something the practitioner controls.
Before the Findings: One Diagram
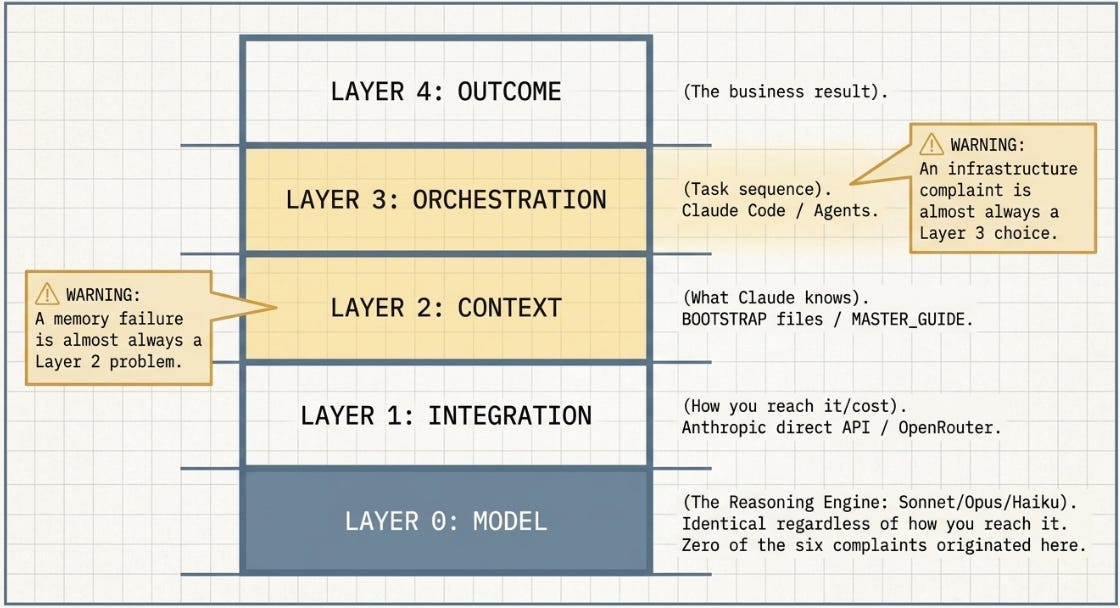
Every finding in this series connects to the same underlying observation. Claude is not a single fixed thing. It is a stack of layers -- and most concerns about it are concerns about one specific layer, misidentified as a concern about the whole.

A memory failure is almost always a Layer 2 problem -- the wrong context was loaded, or none was. An infrastructure complaint is almost always a Layer 3 choice, not a Layer 0 limitation. A cost problem is almost always a Layer 1 or Layer 2 decision. None of the six concerns addressed in this series turned out to be a Layer 0 problem.
Note:
ISR — Intelligence Systems Review. The name I used in the publication series.
ASCRS — AI Supply Chain Response System. The pharmaceutical supply chain case study domain I built as the running experiment environment throughout the series — the Hormuz Strait scenario, the 23 purchase orders, the carrier data, the rubric and gold answer that underpinned H1 through H10 and the memory experiment.
1. If I Build on Claude, Am I Locked In?
Concern: Vendor lock-in and lack of portability
Building around Claude-specific conventions -- CLAUDE.md, Claude Code’s project structure, Anthropic’s hosted environments -- creates dependency. Moving to a different tool would mean rebuilding everything.
The finding
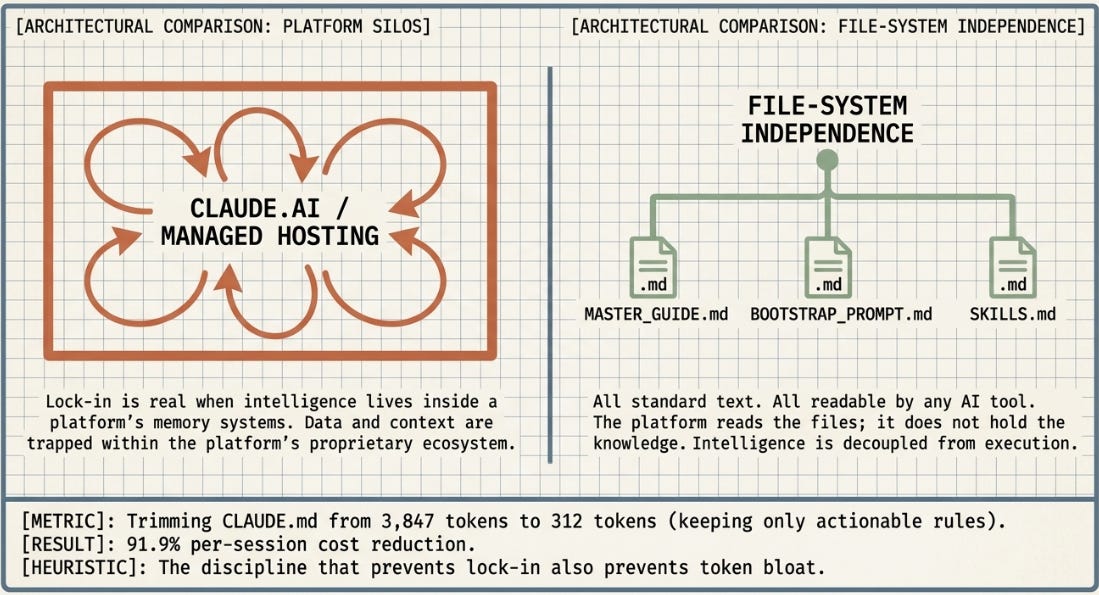
Lock-in is real when your intelligence lives inside a platform. It does not exist when it lives in files you own.
Every ISR experiment was built on plain markdown files: a MASTER_GUIDE containing domain knowledge and experimental history, a BOOTSTRAP_PROMPT containing session-start context, and skill files containing reusable workflow recipes. All of these are standard text. All are readable by any AI tool. The naming convention CLAUDE.md is a convention -- not a format. Changing the filename to AGENTS.md (the Forge convention) takes thirty seconds. The content does not change. The intelligence does not move.
Three cases where lock-in is a genuine risk, not a hypothetical: Claude.ai’s built-in memory summaries (stored in Anthropic’s system, not in your files); Managed Agents hosted environments (the execution environment does not export); and MCP server connections (configured per-tool, not universally portable). These are specific, nameable tradeoffs -- not a general trap.
There is also an efficiency dimension to this. Every token in CLAUDE.md is re-sent on every Claude Code request. Independent benchmarking shows that trimming a context file from 3,847 tokens to 312 tokens -- keeping only rules the model acts on -- reduces per-session cost by 91.9%. The discipline that prevents lock-in and the discipline that reduces cost are the same discipline: keep your intelligence in lean, portable, plain-text files you own.
The rule:

Article Ref Start: The Architecture of Awareness
2. Does Architectural Complexity Produce Better Results?
Concern: Technical drift toward developers / Complex setups outperform simple ones
Two concerns that travel together.
The first: Claude’s product is growing more complex, drifting toward developers and away from business users.
The second: if you invest in building a complex multi-agent system, it must outperform simpler approaches.
The finding
Ten different architectures were tested against the exact same task using the exact same model. A pharmaceutical supply chain crisis. 23 purchase orders, three priority tiers, carrier availability constraints, and four deliberate reasoning traps. A gold-standard answer prepared in advance. A six-criterion rubric. Every architecture was scored against it.
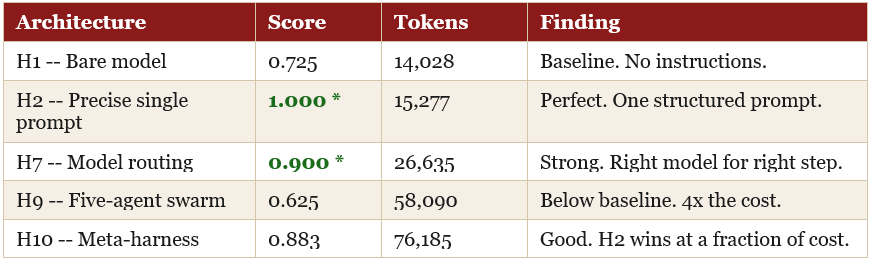
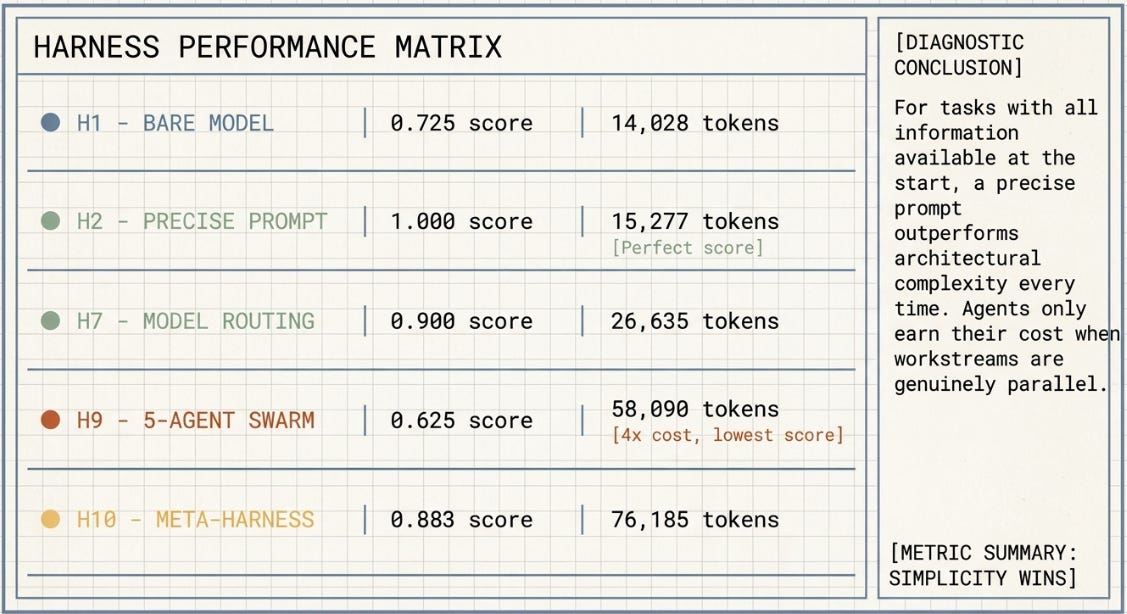
H2 -- a single, well-structured prompt with explicit role, output schema, scoring weights, and anti-hallucination rules -- achieved a perfect score at 15,277 tokens. H9 -- a five-agent swarm with specialised roles for routing, compliance, inventory, commercial analysis, and review -- scored below the bare model at nearly four times the cost.
H9 was predicted to win before the experiment ran. The reasoning was intuitive: five specialised agents coordinating toward a shared answer should outperform a single prompt. What happened instead: each agent produced a partial answer, the coordination layer had to synthesise five partials, and synthesis introduced ambiguity that was not present when a single prompt held the full picture.
H7 -- model routing, directing simpler steps to Haiku at 3.75x lower cost than Sonnet -- achieved 0.900 alpha. This is the result that matters most for practitioners concerned about cost: routing decisions alone recover most of the performance of a complex system at a fraction of the price.
On the technical drift concern: the sophisticated options in Claude’s ecosystem exist for tasks that genuinely need them. This experiment however, showed that they do not need to be the default path. The highest-scoring result used no agents, no infrastructure, and no special features -- just a precise prompt/skill.

Full article: The Harness Experiment
Full article: ASCRS Harness Lab -- The Integrated Agentic Stack
Full article: The Prompt Is Not the Architecture
3. Does or Can Decomposing an Agent Actually Reduce Cost?

Concern: Multi-agent systems are expensive and require complex infrastructure
The harness experiment demonstrated that a single precise prompt outperforms complex architectures on analysis tasks. A separate experiment tested the other direction: what happens to a monolithic agent when you systematically decompose it?
The finding
Anthropic’s StockPilot stock forecasting agent -- from their public workshop repository -- was run through a structured decomposition process across five cycles in Claude Code. Real API costs were measured at every step using Anthropic’s own evaluation suite.
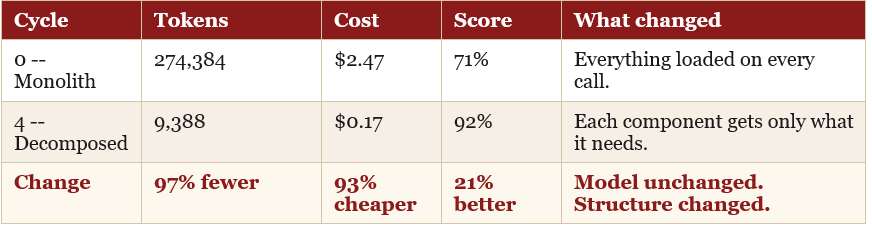
97% token reduction. Accuracy improved from 71% to 92%. The model did not change. The task did not change. Only what each call was asked to carry changed.
A monolithic agent accumulates context it does not need on every call. A system prompt listing 40 tools for a task that uses 3 is paying for 37 unused tools on every single invocation. Decomposition removes the accumulation. Each component receives only what it needs for its specific function. The intelligence does not change. The waste does.
One live discovery during the run: when routing was switched from OpenRouter to Anthropic direct, the score dropped from 92% to 75% with no error message. One sub-agent function had a hardcoded API client that did not update with the environment variable. The function silently failed. The model was fine. The integration layer had a hidden assumption. Finding it required knowing what had changed between runs -- which is the argument for structured, documented experiments over ad hoc iteration.
Full article: The Structure Is The Intelligence
Full article: Every Company Is An Agent Waiting to Be Decomposed
Full article: The Token Tax
4. Does the API Route Matter?
Concern: Integration choices have no meaningful impact on cost or behaviour
The model is the same regardless of which API provider you use to reach it. The route is just a technical detail.
The finding
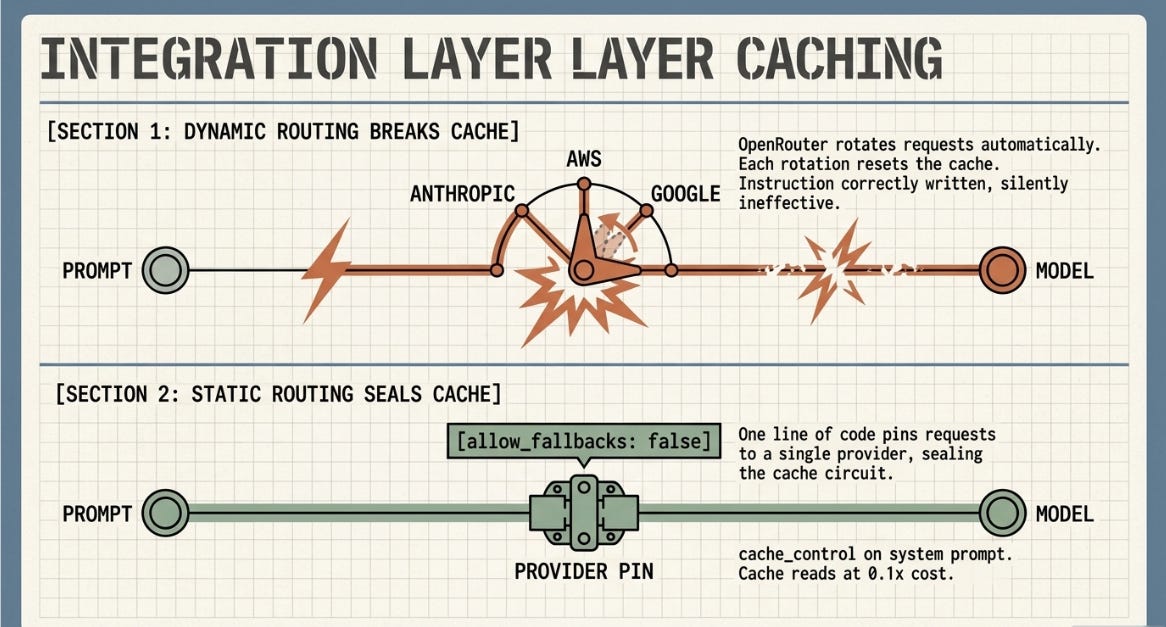
During the StockPilot experiment, prompt caching was configured correctly -- cache_control markers included in the system prompt. The experiment ran through OpenRouter. The savings did not appear.
The investigation found that OpenRouter rotates requests across multiple infrastructure providers -- Anthropic direct, Amazon Bedrock, Google Vertex -- automatically. A prompt cached on one provider is not cached on another. Each rotation resets the cache. The instruction was correctly written and silently ineffective. No error. No warning. The fix is one line: set allow_fallbacks: false in the OpenRouter request, pinning all requests to a single provider.
A second finding: the experiment’s logging captured input_tokens only -- not cache_read_input_tokens or cache_creation_input_tokens. Those are separate fields in the Anthropic API response. If your logging does not read them, you cannot confirm caching is working even when it is. Understanding what your instrumentation captures is as important as understanding what the API reports.
What independent benchmarking shows about stacking
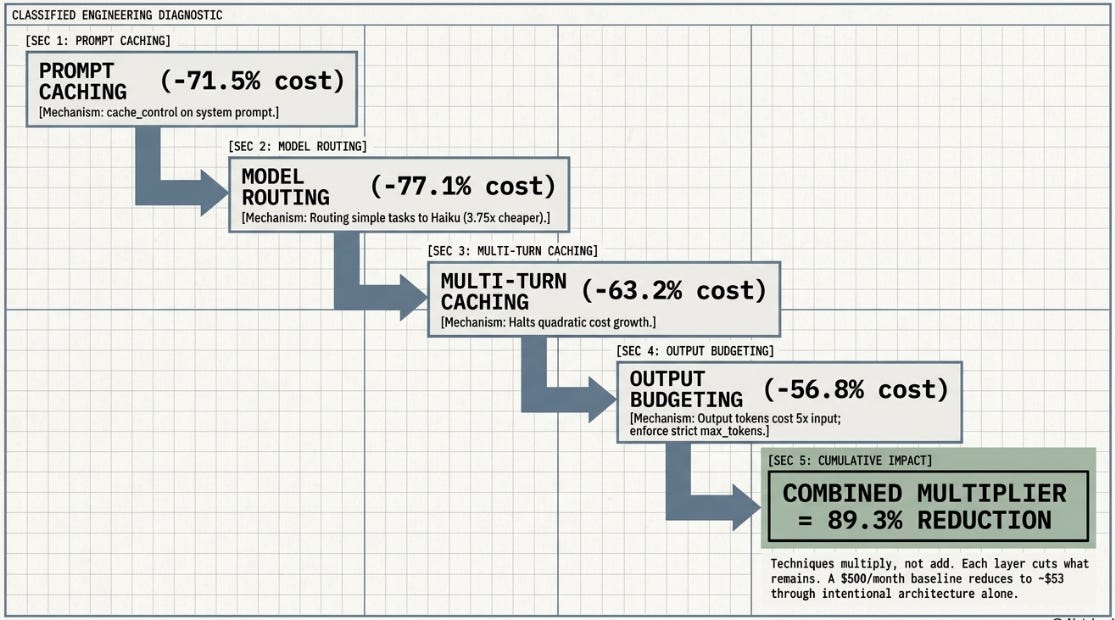
The caching discovery is one finding from one integration path. Independent benchmarking by Hamza Farooq (claude-sonnet-4-6, May 2026, approximately 17,768 requests per month at a $500 base) quantifies four optimisation techniques and what happens when they compound:
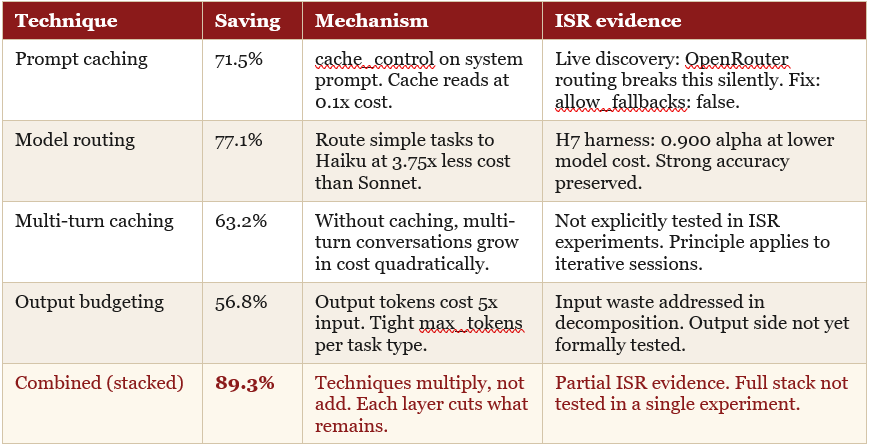
The critical insight from the combined result: optimisation techniques are multiplicative, not additive. Prompt caching alone saves 71.5%. Model routing alone saves 77.1%. Stacked with output budgeting and multi-turn caching, the combined saving reaches 89.3% -- $447 per month on a $500 base. Each layer cuts what remains after the previous layer.
The ISR experiments provide direct evidence for two of the four techniques: the caching discovery (prompt caching) and H7’s model routing result (0.900 alpha at materially lower cost). The multi-turn caching and output budgeting figures are from Farooq’s independent benchmarks and have not been replicated in ISR experiments. They are noted as externally evidenced, not internally verified.
Practical sequence -- four checks, in order of effort

Full article: The Structure Is The Intelligence -- Appendix: Are All APIs Created Equal?
External benchmark: Hamza Farooq -- Claude Token Optimizer -- open-source, claude-sonnet-4-6, May 2026
5. Is Claude’s Memory Actually Poor?
Concern: Native memory is unreliable and requires third-party tools to fix
Claude has no persistent memory between sessions? Everything is forgotten when the conversation ends? Fixing this properly requires third-party databases, vector stores, or external memory services?
A note on the research landscape
Three independent research projects on AI memory were surveyed in preparation for this series: MEMENTO (Microsoft Research, April 2026), MemPalace (April 2026), and AutoResearch (Karpathy, March 2026). I did not complete the analysis as a published synthesis because a direct philosophical conflict was found between the approaches: MemPalace stores everything verbatim, with no AI deciding what to forget; MEMENTO compresses. These positions are structurally incompatible. Publishing a synthesis would have been inaccurate. At least not for now. More testing. And I will come back to this in future.
The honest position: long-term AI memory at the level of complex multi-session knowledge accumulation remains an open and contested research problem. Practitioners should be cautious about any tool claiming to have resolved it cleanly.
The finding
Instead my experiment tested something narrower and more immediately useful: for session-level and task-level memory, does injecting context at session start measurably improve performance against a scored rubric?
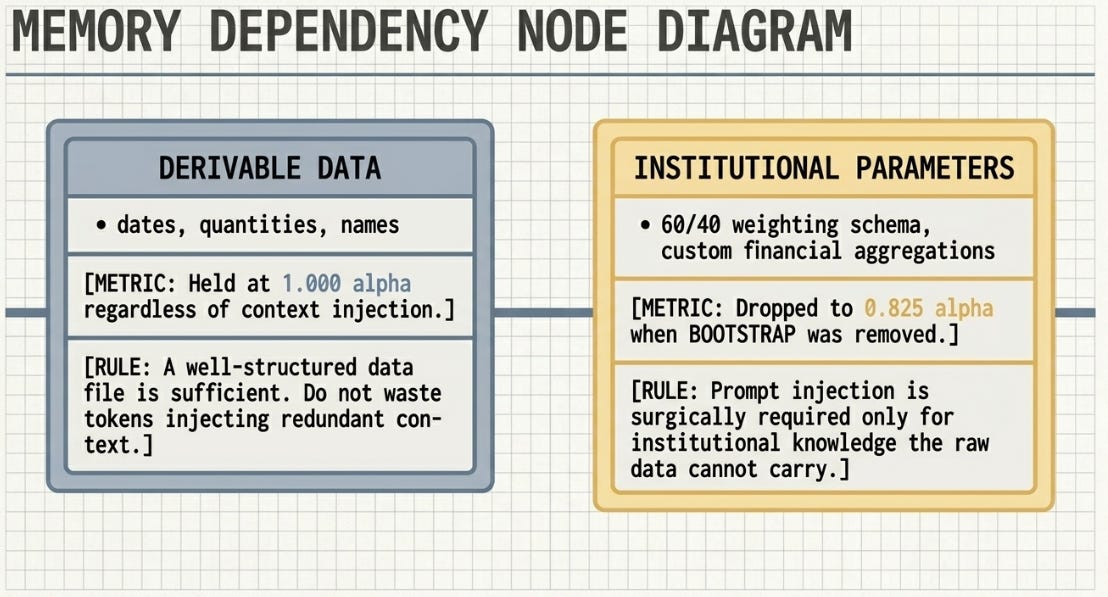
The experiment was designed around two conditions: a rich, self-documenting data file versus a stripped raw version, both run without any prompt-level context injection. The finding was not what the original design anticipated.

The gap of 0.175 was concentrated in exactly two criteria: R1 (tier prioritisation weights, 0.5) and R4 (financial aggregation methodology, 0.5). Four criteria held at 1.0 regardless of context, because their answers are derivable from data structure alone. The two that dropped depend on institutional parameters -- a 60/40 weighting schema and a bespoke aggregation method -- that exist only in organisational practice and cannot be inferred from raw data or general reasoning.
This produced a more precise argument than the original design would have. Context engineering operates at two layers: the data structure you pass to the model, and the prompt context you inject at session start. Both are valid. A well-structured data file can substitute for prompt injection on criteria with objective, derivable answers. Prompt injection is essential on criteria requiring institutional knowledge the data file cannot carry.
The practical implication is an audit, not a prescription: identify which criteria in your task depend on institutional knowledge. Ensure your data file or your BOOTSTRAP_PROMPT carries those criteria explicitly. Do not write context that repeats what the data already says -- that is redundant tokens and noise.
Claude’s context window holds up to 200,000 tokens. When context is injected at session start, the model is not retrieving memory from somewhere external. It is carrying it. The architectural cost of a well-written context file is zero. The only cost is not having written it.
Full article: Is Claude’s Memory Actually Poor?
6. Do You Need Infrastructure to Automate?
Concern: Automation requires cloud infrastructure or 24/7 hardware
Running Claude automatically requires either leaving your computer on 24 hours a day or setting up GitHub repositories, cloud containers, and backend infrastructure? Claude’s routines interface uses developer jargon -- autofix pull requests, pushes, merges -- that has nothing to do with how a business owner thinks about getting a task done? Token-maxxing? Token bloat?
Where the concern is correct
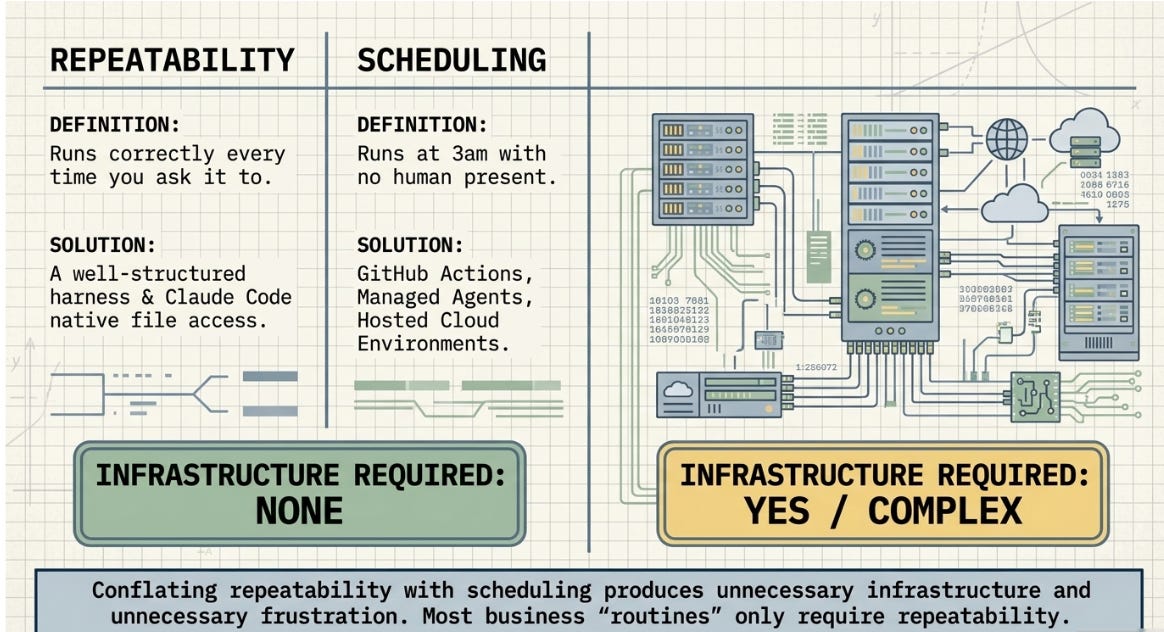
If the requirement is for Claude to run a task at 3am with no human present -- that is scheduling. Scheduling requires infrastructure. A local machine in sleep mode will not trigger the run. Cloud infrastructure solves this and it is genuinely complex to configure. That part of the concern is accurate and should not be dismissed. The GitHub jargon in the routines interface is a real friction point for non-developers, and it reflects a product surface that was designed for development teams first.
The distinction that changes the answer
Most business workflows described as routines are not scheduling problems. They are repeatability problems. The difference matters:

Claude Code’s native file system access -- reading files, writing files, running scripts -- covers the majority of repeatable business workflows without any additional infrastructure layer. MCP connections and managed agents exist for specific integration needs: live databases, external APIs, real-time data feeds. They are not prerequisites for agentic work in general.
A controlled experiment demonstrating this distinction -- a complete weekly review workflow, triggered by a single command with no cloud infrastructure -- is forthcoming. The argument above is logical rather than experimental. It will be updated with measured results when available.
It is also worth noting that Anthropic’s own roadmap is moving in this direction. Dreaming -- an asynchronous between-session memory consolidation process that shipped for Claude Managed Agents (CMA) in May 2026 -- represents Anthropic’s recognition that the infrastructure complexity concern is real and worth solving at the product level. The scheduling problem is a genuine constraint. The field is actively working on it.
What the Series Collectively Demonstrates
Across five controlled experiments and multiple architectural explorations, one pattern appeared consistently: the concerns practitioners raise about Claude are usually accurate descriptions of what the default behaviour produces. They are not accurate descriptions of what the architecture can produce.
Default behaviour -- a blank session context, a monolithic agent, an unoptimised routing configuration -- produces exactly the results the critics describe. Poor recall. High cost. Fragile coordination. Genuine friction for non-developers.

Intentional architecture -- a well-structured data file, a lean BOOTSTRAP prompt, a decomposed agent, a correctly configured caching setup, a precise single prompt instead of a swarm -- produces results that invalidate most of those criticisms. The model has not changed in any of these comparisons. What changed was the structure around it.
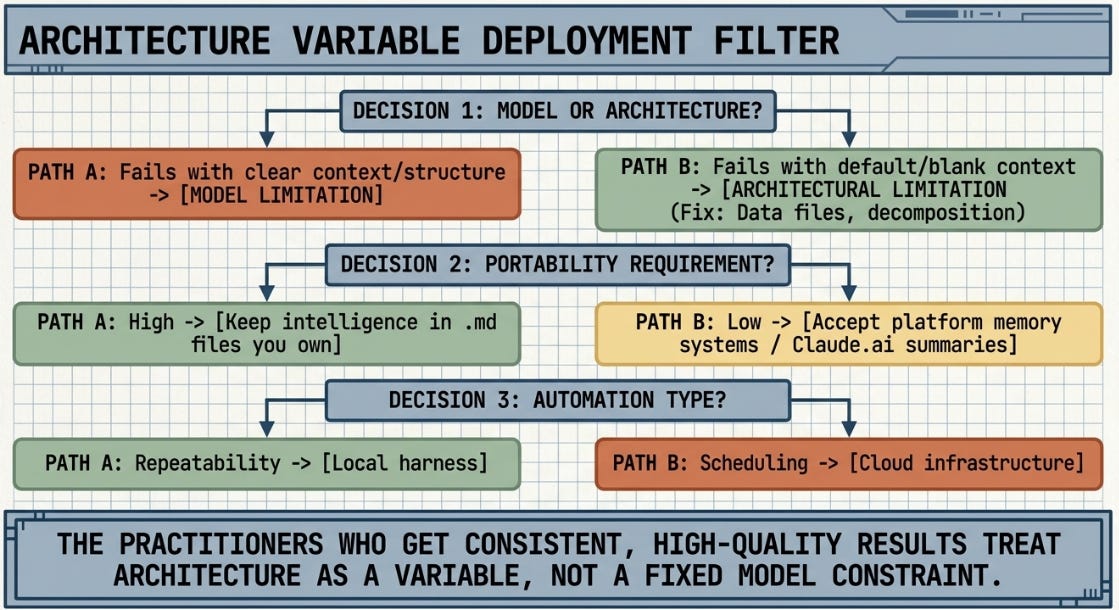
Three questions that serve as a practical filter before any integration decision:
* Is this a model problem or an architecture problem? If Claude produces a poor result when given clear context and a precise task, that is a model issue. If it produces a poor result without context or structure, that is an architecture issue. Almost every concern in this series turned out to be the second kind.
* What is my portability requirement? Keep your intelligence in plain text files. Not in platform memory systems. Not in hosted environments that cannot export. The portability decision is made at file creation, not at migration time.
* Do I need scheduling, or repeatability? These are different requirements with different solutions. Conflating them produces unnecessary infrastructure and unnecessary frustration.
Claude is a flexible system of choices, not a single product with fixed behaviour. The practitioners who get consistent, high-quality results from it are not the ones who found a workaround. They are the ones who treated architecture as a variable -- and measured what changed when they adjusted it.
For now, enjoy the journey.
Series References
V1-V4 agent design, ASCRS system, file architecture
H1-H10 results, ten architectures one task
ASCRS Harness Lab -- The Integrated Agentic Stack
Full rubric, gold answer, scored results
The Prompt Is Not the Architecture
Anthropic Prompting Playbook reconciled with ASCRS findings
Harness Engineering -- Scaffolding A Small Model
Right scaffolding beats upgrading the model
Harness Engineering Part II: performance to efficiency
The Structure Is The Intelligence
97% token reduction, API caching discovery
Every Company Is An Agent Waiting to Be Decomposed
Graph-of-algorithms framework, decomposition principles
Why Multi-Agent AI Systems Break
Updated framework for failure modes
The Geometry of Unpredictability
Agentic workflow failures and polymorphism analogy
Is Claude’s Memory Actually Poor?
Controlled experiment: data architecture vs prompt injection
Hamza Farooq -- Claude Token Optimizer
Four-technique stacking benchmark, claude-sonnet-4-6, May 2026
I have thoroughly enjoyed your series here. Thank you for doing this in a way which is not captured by the standard benchmarks today.